一、问题背景:CPU飙高场景的典型特征
某电商平台在"双十一"大促期间突发CPU使用率100%告警,核心交易接口响应延迟超过5秒。运维团队需要快速定位问题根源,此时面临两种工具选择:传统命令行工具jstack与阿里开源诊断工具Arthas。本文将通过完整案例对比两者的诊断流程与效率差异。
二、工具特性对比矩阵
| 维度 | jstack | Arthas |
|---|---|---|
| 数据获取方式 | 需手动执行命令生成快照文件 | 支持动态实时采样(采样间隔可配置) |
| 线程信息完整性 | 仅显示线程状态与堆栈 | 额外提供CPU耗时占比、锁竞争详情、方法调用追踪等增强信息 |
| 交互性 | 离线分析(需配合文本处理工具) | 交互式命令行(支持管道操作、正则过滤) |
| 学习成本 | 基础命令易学,但高级分析需脚本辅助 | 提供类Unix风格命令体系,内置帮助文档 |
| 生产环境适用性 | 低侵入性,但需协调运维权限 | 支持非侵入式诊断(无需重启应用) |
三、实战案例:死循环导致的CPU飙高
场景描述
某订单服务出现单节点CPU 100%异常,业务逻辑中存在定时任务代码缺陷:
scss
// 问题代码:定时任务未正确终止
ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);
scheduler.scheduleAtFixedRate(() -> {
while(true) { // 死循环
calculateOrderDiscount();
}
}, 0, 1, TimeUnit.HOURS);四、诊断流程对比
方案A:jstack传统诊断
步骤1:定位Java进程
perl
$ jps -l | grep OrderService
12345 com.example.OrderService步骤2:捕获高CPU线程
css
$ top -H -p 12345
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
12346 appuser 20 0 3456789 123456 98765 R 99.9 1.2 0:10.01 java步骤3:转换线程ID
perl
$ printf "%x\n" 12346
c0a2步骤4:分析线程快照
perl
$ jstack 12345 | grep -A 20 c0a2
"pool-1-thread-1" #1234 prio=5 os_prio=0 tid=0x00007f8b5c00f000 nid=0xc0a2 runnable [0x00007f8b54a9f000]
java.lang.Thread.State: RUNNABLE
at com.example.OrderService.lambda$init$0(OrderService.java:42)
at com.example.OrderService$$Lambda$1/0x0000000800060840.run(Unknown Source)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)关键发现 :线程pool-1-thread-1在OrderService.java:42陷入死循环
方案B:Arthas智能诊断
步骤1:动态附加诊断
scss
$ java -jar arthas-boot.jar
* [1] com.example.OrderService (12345)
`--- attach success步骤2:实时监控CPU热点
less
[arthas@12345](@ref)thread -n 3
"pool-1-thread-1" Id=1234 cpuUsage=99.9% deltaTime=1000ms
at com.example.OrderService.lambda$init$0(OrderService.java:42)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)步骤3:深度方法追踪
less
[arthas@12345](@ref)trace com.example.OrderService calculateOrderDiscount
TRACE com.example.OrderService calculateOrderDiscount
`---ts=2025-12-24 15:00:00; [cost=1000000000] result=@Integer[0]
└─java.lang.Thread.sleep(Native Method)
└─com.example.OrderService.lambda$init$0(OrderService.java:42)关键发现 :calculateOrderDiscount方法持续执行且无休眠,结合trace结果确认死循环
五、工具优势深度解析
1. jstack的核心价值
-
离线分析能力:适合需要长期保存诊断记录的场景
bash# 生成带时间戳的诊断包 jstack 12345 > /var/log/jstack_$(date +%s).log -
批量处理支持 :可结合
ps/top实现自动化监控脚本perl# 示例:自动捕获TOP3高CPU线程 top -H -b -n 1 -p 12345 | awk '/java/{print $1}' | xargs -I{} printf "%x\n" {} | uniq | xargs -I{} jstack 12345 | grep -A 20 {}
2. Arthas的革新突破
-
实时火焰图生成:可视化呈现热点方法调用链
less[arthas@12345](@ref)profiler start --event cpu --interval 1000 [arthas@12345](@ref)profiler stop --file cpu_profile.svg -
智能过滤机制:通过正则表达式精准定位问题代码
less[arthas@12345](@ref)thread -n 5 --state RUNNABLE | grep -E 'calculate|discount' -
动态热更新:无需重启即可修复问题(需配合JVM参数)
less[arthas@12345](@ref)jad --source-only com.example.OrderService > OrderService.java # 修改代码后热更新 [arthas@12345](@ref)redefine OrderService.java
六、适用场景决策树
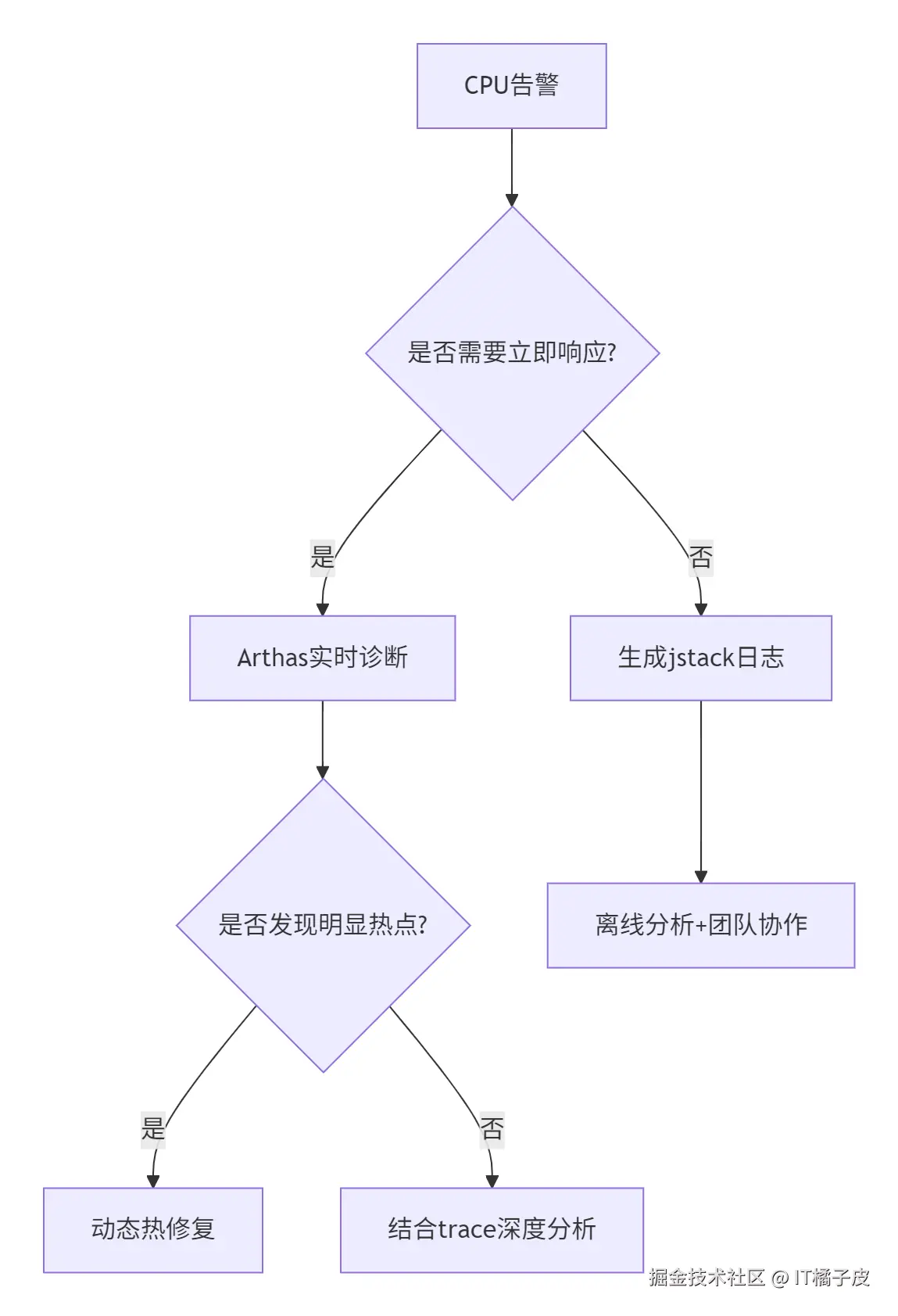
七、生产环境最佳实践
-
防御性配置
bash# Arthas安全加固 java -jar arthas-boot.jar --tunnel-server ws://arthas.example.com -
监控体系整合
yaml# Prometheus监控配置 - job_name: 'arthas-profiler' static_configs: - targets: ['127.0.0.1:9090'] metrics_path: '/actuator/prometheus' -
故障演练机制
bash# 模拟CPU飙高场景 stress-ng --cpu 4 --timeout 60s
八、总结:工具选择的黄金法则
-
优先Arthas的场景:
需要实时交互、快速定位、复杂调用链分析的生产环境故障
-
选择jstack的场景:
需要长期存档诊断记录、配合CI/CD流水线进行批量分析的场景
终极建议:在微服务架构下,推荐采用Arthas+Prometheus+ELK的立体监控体系,实现从问题发现到根因分析的闭环。对于核心交易系统,应建立Arthas的自动化诊断预案,确保黄金救援时间的有效利用。