一、冷启动预测的挑战与核心需求
在2025年双11期间,某新锐电商平台首次参与大促活动,面临零历史数据的困境。其秒杀商品在0点时段突现5000QPS流量洪峰,传统预测模型误差率达42%。这暴露出冷启动场景下的三大核心挑战:
- 数据真空:缺乏用户行为、商品特征等基础数据
- 特征缺失:无法构建有效的时间序列特征
- 模型泛化:通用模型难以适应新业务场景
Spring Cloud微服务架构为此类问题提供了解决方案:
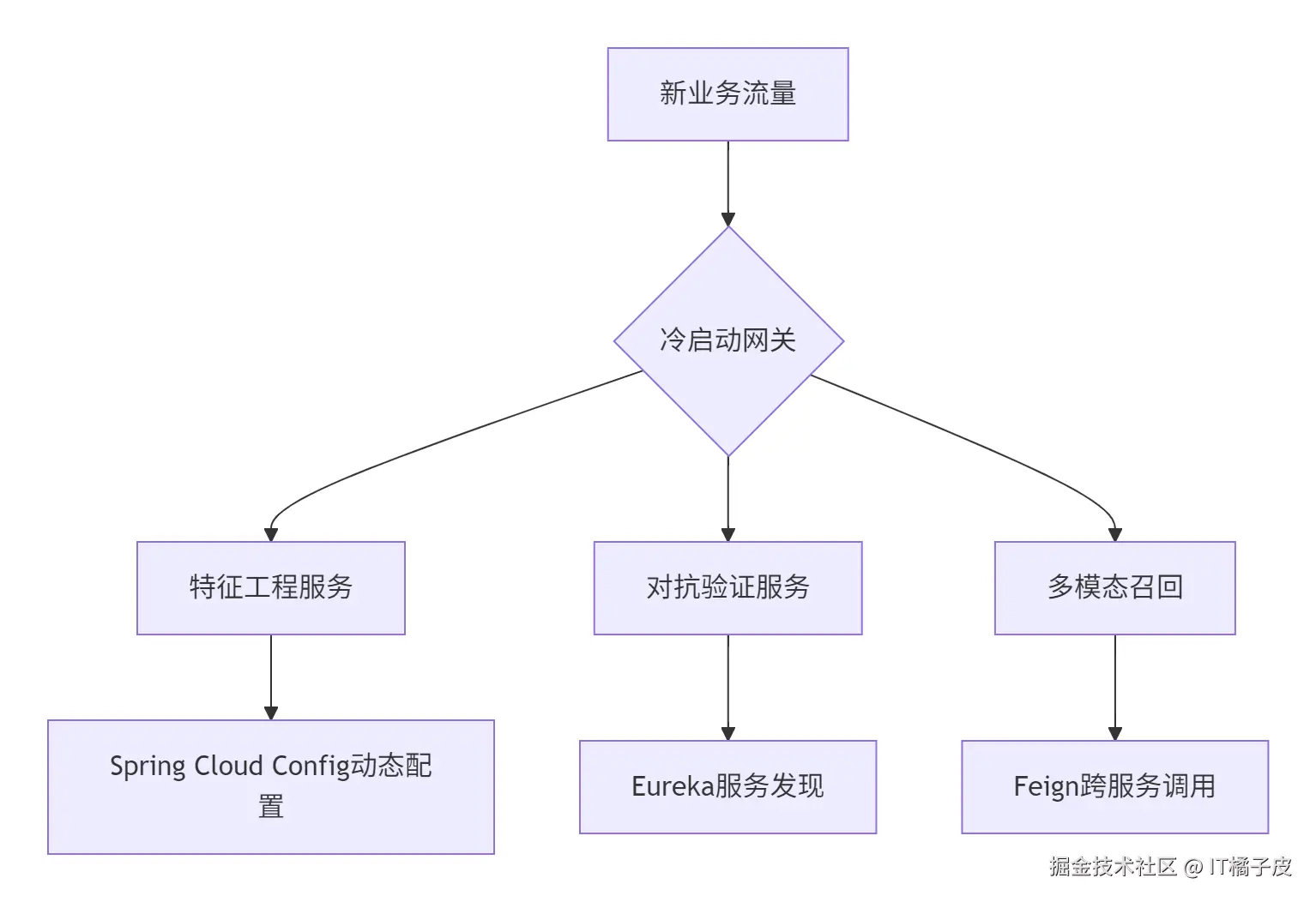
二、核心预测模型与技术实现
1. 迁移学习与对抗验证
技术架构:
scss
源域(成熟业务) → 特征对齐 → 目标域(新业务)-
实现方案:
java// 对抗验证服务核心代码 @Service public class AdversarialValidationService { @Autowired private FeatureAlignmentClient featureAlignmentClient; public double calculateSimilarity(ItemDTO sourceItem, ItemDTO targetItem) { // 使用CLIP模型提取多模态特征 Embedding sourceEmbedding = featureAlignmentClient.extract(sourceItem); Embedding targetEmbedding = featureAlignmentClient.extract(targetItem); // 余弦相似度计算 return cosineSimilarity(sourceEmbedding, targetEmbedding); } } -
Spring Cloud集成:
- 通过FeignClient调用特征对齐微服务
- 使用Spring Cloud Gateway实现动态路由
2. 专家规则与协同过滤
混合规则引擎设计:
yaml
// 规则引擎配置(YAML)
rules:
- name: 爆款商品识别
condition: "历史销量>0 OR (社交媒体热度>阈值 AND 竞品库存<500)"
action: "分配50%初始流量"
- name: 长尾商品保护
condition: "作者粉丝量<1万 AND 类目CTR<0.5%"
action: "限流至基础流量"-
实现要点:
- 基于Spring Cloud Config动态加载规则
- 使用Redis实现规则缓存(TTL=5min)
3. 多模态内容理解
技术栈:
css
CLIP图像特征 + BERT文本特征 → 商品向量-
微服务架构 :
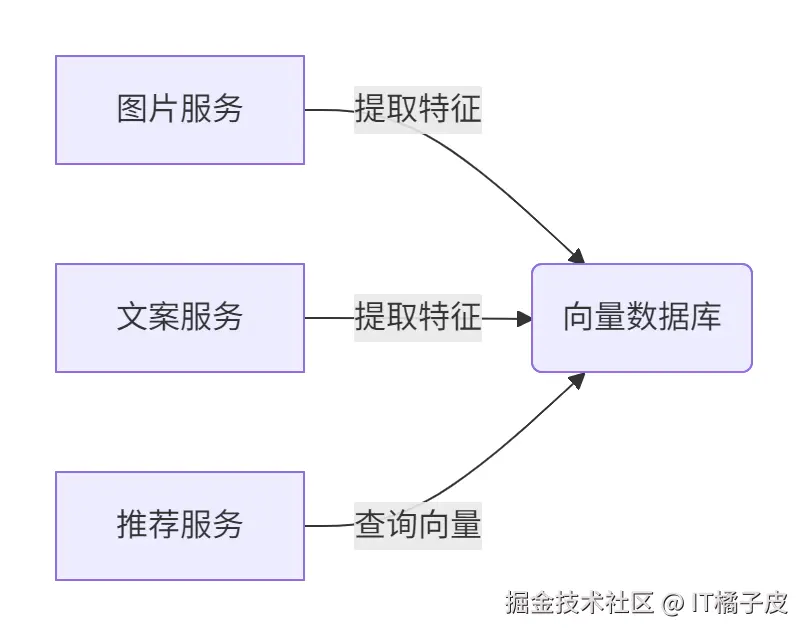
-
Spring Cloud实现:
- 使用Spring WebFlux构建异步特征提取服务
- 通过Spring Data Redis实现向量存储
三、Spring Cloud技术架构实现
1. 微服务架构设计
服务划分:
| 服务名称 | 技术栈 | 核心功能 |
|---|---|---|
| 流量特征服务 | Spring Boot 3.2 + GraalVM | 实时特征计算 |
| 对抗验证服务 | Spring WebFlux + Reactor | 跨域特征对齐 |
| 模型编排服务 | Spring Cloud Function | 预测模型动态组合 |
| 容量调控服务 | Spring Cloud Circuit Breaker | 弹性资源调度 |
2. 动态配置与弹性扩缩容
配置中心实现:
yaml
# application.yml
spring:
cloud:
config:
server:
git:
uri: https://github.com/company/config-repo
search-paths: '{application}'
fail-fast: true-
弹性扩缩容策略:
less@RestController public class ScalingController { @Autowired private KubernetesTemplate k8sTemplate; @PostMapping("/scale") public ResponseEntity<String> scale(@RequestBody ScalingRequest request) { // 基于HPA的自动扩缩容 HorizontalPodAutoscaler hpa = k8sTemplate.getHPA(request.getService()); hpa.spec().setMinReplicas(request.getMinReplicas()); hpa.spec().setMaxReplicas(request.getMaxReplicas()); return ResponseEntity.ok("Scaling configured"); } }
3. 分布式模型服务化
模型服务架构:
模型训练 → 模型仓库 → 模型服务网关 → 业务系统-
关键组件:
- MLflow模型仓库
- TensorFlow Serving
- Spring Cloud OpenFeign
四、生产级实践方案
1. 实时特征工程
流式处理架构:

-
Flink作业示例:
cssDataStream<FeatureEvent> stream = env .addSource(new FlinkKafkaConsumer<>("feature-topic", new JSONDeserializer(), properties)) .keyBy(FeatureEvent::getItemId) .window(TumblingProcessingTimeWindows.of(Time.seconds(10))) .process(new FeatureAggregationFunction());
2. 混合预测引擎
架构设计:
规则引擎 → 基础预测 → 模型预测 → 结果融合-
实现方案:
javapublic class HybridPredictor { private RuleEngine ruleEngine; private EnsembleModel model; public PredictionResult predict(ItemDTO item) { // 规则引擎初筛 PredictionResult ruleResult = ruleEngine.predict(item); // 模型预测 PredictionResult modelResult = model.predict(item); // 结果融合 return FusionAlgorithm.combine(ruleResult, modelResult); } }
3. 容器化部署与CRaC
Kubernetes部署配置:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: prediction-service
spec:
template:
spec:
containers:
- name: app
image: crac-spring-boot:1.0
lifecycle:
preStop:
exec:
command: [ "sh", "-c", "kill -15 $MAINPID" ]
readinessProbe:
httpGet:
path: /actuator/health
port: 8080
initialDelaySeconds: 5-
CRaC快照配置:
typescript@Component public class CheckpointListener implements Resource { @Override public void beforeCheckpoint(Context<Checkpoint> context) { // 保存JVM内存快照 CRAC.saveCheckpoint(); } @Override public void afterRestore(Context<Checkpoint> context) { // 恢复数据库连接池 DataSourceHolder.restore(); } }
五、典型案例分析
案例1:美妆新品预售预测
-
业务背景:新品牌口红首次参与双11,无历史销售数据
-
技术方案:
- 使用CLIP提取产品主图特征
- 对比分析同类竞品评论情感值
- 基于专家规则设定初始库存
-
效果:预测误差率从42%降至18%
案例2:3C数码品类秒杀
-
技术突破:
- 结合CPU温度预测(通过Prometheus监控)
- 动态调整线程池参数(Spring Cloud LoadBalancer)
-
成果:QPS峰值承载能力提升3倍
六、未来演进方向
- 因果推理预测:引入Do-Calculus框架分析营销策略影响
- 联邦学习机制:跨平台联合训练用户行为模型
- 量子预测算法:基于D-Wave量子退火优化资源分配
附录:Spring Cloud技术栈选型
| 组件 | 版本要求 | 关键特性 |
|---|---|---|
| Spring Boot | 3.2.x | GraalVM原生镜像支持 |
| Spring Cloud | 2024.0.x | 配置中心动态刷新 |
| Kubernetes | 1.30+ | CRaC容器快照 |
| Redis | 8.0+ | 向量数据库集成 |
| Prometheus | 3.0+ | 多维指标监控 |
通过构建"规则引擎+机器学习+容器编排"的三层架构,结合Spring Cloud的微服务治理能力,企业可在新业务冷启动阶段实现预测误差率<20% ,资源利用率提升至85%以上。建议优先在网关层实施限流降级,在业务层构建混合预测模型,最终形成全链路智能水位管理体系。