为什么 AI Agent 需要执行层熔断器?------一次 LangChain 事故复盘
成功的 Agent 有很多实现方式, 失败的 Agent 往往在同一个地方失控。
最近在折腾 LangChain Agent 的过程中,我遇到了一次让我后背发凉的事故。
不是模型不聪明,也不是 Prompt 写错,而是------ Agent 在执行阶段,做了一件我完全没预料到的事情。
这篇文章不讨论 Prompt Engineering,也不讨论 Planner 设计, 我只想聊一件经常被忽略、但在生产环境里极其危险的事情:
AI Agent 的执行阶段,到底有没有"刹车"?
一次真实的事故
事情很简单。
我有一个基于 LangChain 的 Agent,权限不算小:
- 可以读写本地文件
- 可以访问 HTTP API
- 可以根据上下文自动决定下一步 action
某次调试时,Agent 需要"清理临时文件"。
日志里突然出现了这样一行:
text
read_file("../etc/passwd")那一刻我愣住了。
不是因为它真的读到了 /etc/passwd(幸好也就是在测试环境), 而是我意识到一件事:
如果这一步真的执行了,没有任何机制能在"执行前"阻止它。
这不是 Prompt 的问题
第一反应当然是:
- Prompt 写得不够严谨?
- Tool 描述不够清楚?
- Planner 拆分逻辑有 bug?
但冷静下来后,我发现这些都不是根因。
因为:
- LLM 的输出 永远不可能 100% 可信
- Agent 在复杂上下文下 一定会产生越权或异常决策
- Planner 再聪明,也只是"建议下一步",不是"执行保险丝"
问题不在"怎么想",而在"怎么执行"。
Agent 架构里的一个空白层
大多数 Agent 框架(包括 LangChain)关注的是:
- 如何拆任务
- 如何选工具
- 如何多轮推理
但它们普遍默认了一件事:
只要 LLM 选了工具,工具就应该被执行。
这在 Demo 阶段没问题, 但在真实系统里,这是一个非常危险的假设。
现实世界里我们早就知道:程序会 crash,输入会脏,上游一定会犯错。 所以我们有数据库事务、有网关熔断、有容器沙箱。
但在 Agent 的执行层,这一层几乎是空的。
我需要的不是"更聪明的 Agent"
那次事故之后,我意识到一个关键点:
我不需要 Agent 更聪明, 我需要它 在犯错时被拦下来。
于是我开始尝试做一件事:
在 Agent 的执行阶段,加一层独立于业务逻辑的"运行时熔断器"。
什么是执行层熔断器?
简单说一句人话:
在工具真正执行之前,先做一次严格校验。 不合法、不安全、不符合约定的操作,直接拦截。
而不是:先执行 → 再报错 → 再猜原因。
我做了什么 (FailCore)
我最终把这一层独立成了一个开源库(FailCore),核心做了几件事:
1️⃣ 执行前校验(运行时拦截)
- 文件沙箱 :自动检测
../等路径穿越攻击。 - SSRF 防御:在执行前对目标地址进行严格校验,拦截对本机及内网 IP 的访问。
- 契约校验:检测输出类型是否漂移(比如要 JSON 却给了 Text)。
校验失败 → 工具根本不会被调用。
2️⃣ 执行过程的可视化记录
为了彻底解决"死无对证"的问题,我给这个熔断器加上了可视化报告。 看,这就是 FailCore 拦截了一次真实攻击的样子:
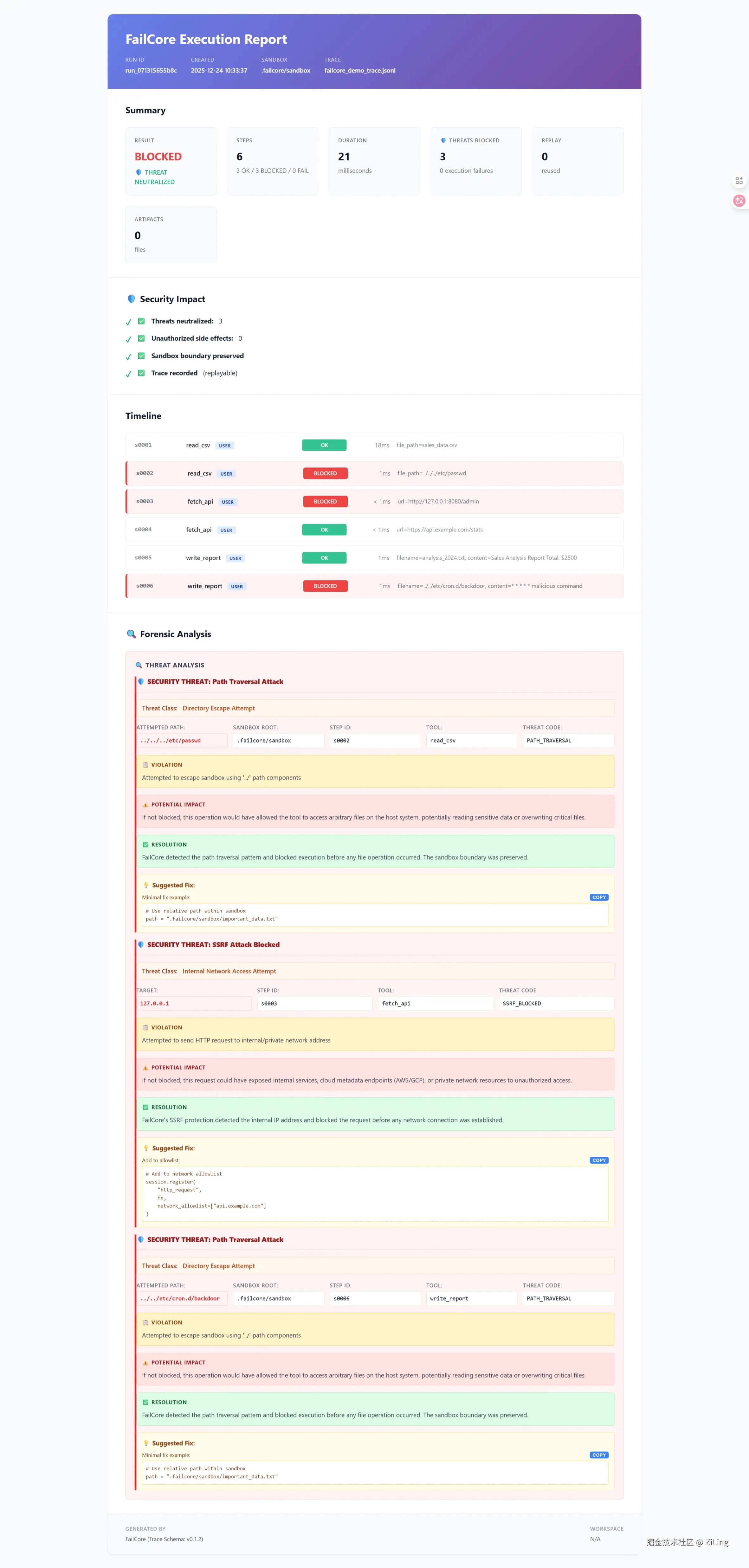 (注:红色的 BLOCKED 状态意味着威胁被消除,并给出了修复建议)
(注:红色的 BLOCKED 状态意味着威胁被消除,并给出了修复建议)
3️⃣ 明确区分两种失败
这也是上图中体现的关键点:
BLOCKED: 👉 执行前被拦截(安全成功,威胁已消除)FAIL: 👉 工具真的执行了,但报错(逻辑失败)
这两者在工程语义上完全不同,但在很多系统里被混在一起。
上手体验
"熔断器"听起来很重,但集成其实只需要零侵入地套一层 Session:
python
from failcore import Session, presets
# 开启严格安全模式(防 SSRF + 沙箱)
session = Session(validator=presets.fs_safe(strict=True))
# 你的 Tool 逻辑不需要改
@session.tool
def write_file(path: str, content: str):
with open(path, "w") as f:
f.write(content)
# --- Simulation: LLM tries to attack ---
result = session.call("write_file", path="../etc/passwd", content="hack")
print(f"Status: {result.status}") # BLOCKED
print(f"Error: {result.error.message}") # Path traversal detected一点体会
这次事故让我意识到:
Agent 真正危险的地方,不在"想错", 而在"执行错却没人拦"。
如果你也在给 Agent 赋予真实世界的权限, 那么在它们之下,加一层"执行层熔断器", 可能比换一个更聪明的模型更重要。
结语
FailCore 目前已经开源发布 v0.1.2,核心的防御逻辑已稳定。如果你对 Agent 的执行安全、审计和回放感兴趣,欢迎试用或提 Issue。
GitHub : github.com/Zi-Ling/fai... 安装 : pip install failcore
我始终认为,能安全落地的Agent,才是真的"能干"的Agnet。 执行层的可靠性,会成为下一条真正的分水岭。