启动paddlelabel:
python
(ppocrlabelpy310) C:\develop\PythonEnvs\anaconda3\envs\ppocrlabelpy310>PPOCRLabel --lang ch > error.log 2>&1会等几分钟才能启动,我的挺慢的
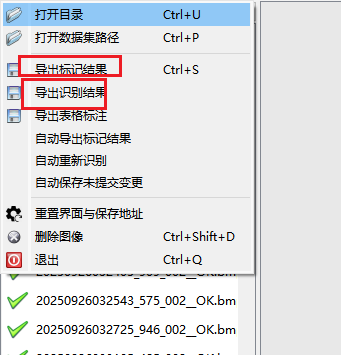
标注好之后,点导出标记结果和导出识别结果
开始划分数据集:
直接执行也可:
python
python gen_ocr_train_val_test.py --trainValTestRatio 6:2:2 --datasetRootPath ./train_data/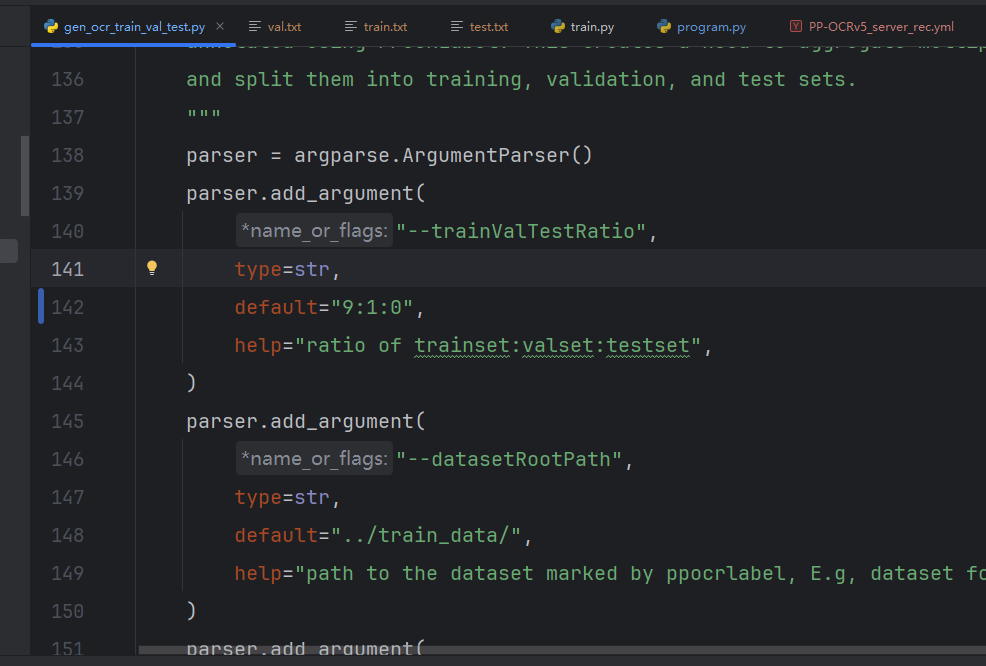
训练脚本:
python
python tools/train.py -c pretrain_models/PP-OCRv5_server_rec.yml -o Global.pretrained_model=pretrain_models/PP-OCRv5_server_rec_pretrained.pdparams Global.print_batch_step=1导出识别模型:
python
python tools/export_model.py -c pretrain_models/PP-OCRv5_server_rec.yml -o Global.pretrained_model=D:\Projects_Datas\HIMA15\ppocrpro\PaddleOCR\output\PP-OCRv5_server_rec\best_model\model.pdparams Global.save_inference_dir="./inference_model/rec/"