你是一名Java开发者,跟着行业迭代的脚步写并发代码。从最开始手动控制线程,写一行错一行;到后来调用现成工具,轻松搞定复杂协作;再到现在,哪怕要支撑百万级并发,也能优雅编码------这背后,正是Java并发编程"遇坑填坑、持续进化"的完整历程。
今天,我们就以"开发者视角",沿着"遇到问题→解决问题"的思路,把Java并发的进化故事讲透。
一、蛮荒时代(Java 1.0-1.4):线程管理全靠手,同步锁重还易错

遇到的问题:想多线程干活?先踩3个致命坑
在Java刚诞生的年代,如果你想写一个多线程程序(比如同时处理多个用户请求),会发现手里的"工具"少得可怜,每一步都在踩坑:
- 线程创建销毁成本高:只能通过new Thread()手动创建线程,用完就销毁。这就像工地干活,每次有任务都要重新招聘工人、培训上岗,任务结束就解雇,效率极低还浪费资源;
- 同步手段简陋还笨重:只有synchronized关键字和Object的wait()/notify()方法。synchronized就像一把"重型铁门",不管人多人少,只要有人用,其他人都得排队,而且这把锁一旦锁上,只能等里面的人主动开门(notify),稍不注意就会导致线程"卡死";
- 无线程安全容器可用:用HashMap、ArrayList存数据时,多线程一操作就会出现数据错乱(比如ArrayList扩容时线程并发导致数组越界),只能自己手动加锁保护,代码又乱又容易错。
当时的解决方案:凑活能用的"原始工具"
没办法,只能用最基础的API硬扛,代码写出来又丑又脆弱。我们看个示例:用Thread+Runnable实现简单的多线程计数,还要手动用synchronized保证线程安全:
java
public class PrimitiveConcurrency {
// 共享计数器
private static int count = 0;
// 手动加锁对象
private static final Object LOCK = new Object();
public static void main(String[] args) {
// 每次任务都new Thread,成本高
for (int i = 0; i < 5; i++) {
new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < 1000; j++) {
// 重型锁保护计数
synchronized (LOCK) {
count++;
}
}
}
}).start();
}
// 等待所有线程结束(此处逻辑不严谨,仅为示例)
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("最终计数:" + count);
}
}这段代码看似能跑,但有很多隐患:比如线程创建太多导致资源耗尽,synchronized性能差,wait/notify使用不当会导致死锁。这一阶段的并发编程,就像"徒手攀岩",全靠开发者的经验和细心,门槛极高。
二、革命时刻(Java 5):JUC横空出世,并发工具"全家桶"到位

遇到的问题:原始工具效率低、易出错,复杂协作搞不定
随着业务发展,开发者需要处理更复杂的并发场景:比如控制同时执行的线程数量、等待多个任务完成后再汇总结果、高效处理并发数据存储等。用Java 1.4及之前的API实现这些需求,就像"用小刀建房子",不仅麻烦,还容易出问题。
核心痛点:缺乏统一的并发工具框架,所有逻辑都要"重复造轮子",开发效率低、维护成本高。
解决思路:提供标准化、高性能的并发工具,让开发者"开箱即用"
Java 5(2004年)推出了java.util.concurrent(简称JUC)包,相当于给开发者送了一套"专业施工工具",彻底改变了并发编程的模式。我们用"工地施工"类比JUC的核心组件,再看对应的代码示例:
1. 线程池:相当于"施工队管理处",复用线程不浪费
不再每次任务都招聘工人,而是组建固定的施工队,任务来了直接派工人上,任务结束工人回到队里待命,大幅降低资源消耗。
代码示例:用ThreadPoolExecutor创建线程池,替代手动new Thread:
java
public class ThreadPoolDemo {
public static void main(String[] args) {
// 创建固定大小的线程池(3个核心线程,相当于3个固定工人)
ExecutorService executorService = Executors.newFixedThreadPool(3);
// 提交5个任务
for (int i = 0; i < 5; i++) {
int taskId = i;
executorService.submit(new Runnable() {
@Override
public void run() {
System.out.println("任务" + taskId + "由线程" + Thread.currentThread().getName() + "执行");
try {
Thread.sleep(500); // 模拟任务执行
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
// 任务执行完后关闭线程池
executorService.shutdown();
}
}输出会发现,5个任务仅由3个线程交替执行,线程被复用,避免了频繁创建销毁的开销。
2. 并发容器:相当于"线程安全的工具箱",存数据不用手动加锁
之前用的HashMap是"普通工具箱",多个人同时拿工具会乱;JUC提供的ConcurrentHashMap是"带锁的工具箱",自动保证多线程操作安全,而且是"分段锁"------相当于把工具箱分成多个格子,每个人可以同时用不同格子的工具,性能比synchronized全局锁高得多。
代码示例:用ConcurrentHashMap实现并发数据存储:
java
public class ConcurrentContainerDemo {
public static void main(String[] args) {
// 线程安全的ConcurrentHashMap
Map<Integer, String> concurrentMap = new ConcurrentHashMap<>();
ExecutorService executorService = Executors.newFixedThreadPool(3);
// 3个线程同时往map里存数据
for (int i = 0; i < 3; i++) {
int key = i;
executorService.submit(() -> {
concurrentMap.put(key, "value" + key);
System.out.println("线程" + Thread.currentThread().getName() + "存入:" + key + "-" + concurrentMap.get(key));
});
}
executorService.shutdown();
}
}无需手动加锁,就能保证数据存储安全,代码简洁又高效。
3. 同步工具类:相当于"施工协作工具",解决复杂线程配合问题
比如CountDownLatch(倒计时门闩):像"工地开工仪式",必须等所有领导都到场(倒计时结束),仪式才能开始(主线程继续执行)。
代码示例:用CountDownLatch等待3个任务完成后,主线程再汇总结果:
java
public class CountDownLatchDemo {
public static void main(String[] args) throws InterruptedException {
// 倒计时门闩,计数3(等待3个任务完成)
CountDownLatch countDownLatch = new CountDownLatch(3);
ExecutorService executorService = Executors.newFixedThreadPool(3);
for (int i = 0; i < 3; i++) {
int taskId = i;
executorService.submit(() -> {
System.out.println("任务" + taskId + "执行完成");
countDownLatch.countDown(); // 任务完成,计数减1
});
}
// 主线程等待,直到计数变为0(所有任务完成)
countDownLatch.await();
System.out.println("所有任务都完成,主线程开始汇总结果");
executorService.shutdown();
}
}4. 原子类:相当于"线程安全的计数器",无锁实现高效计数
之前用synchronized计数是"一个人拿着计数器,其他人排队用";原子类(如AtomicInteger)是"每个人都能同时操作计数器,内部自动保证计数准确",基于CAS(比较并交换)机制,无锁且性能更高。
代码示例:用AtomicInteger替代synchronized计数:
java
public class AtomicDemo {
// 原子类计数器,线程安全且无锁
private static AtomicInteger atomicCount = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(5);
for (int i = 0; i < 5; i++) {
executorService.submit(() -> {
for (int j = 0; j < 1000; j++) {
atomicCount.incrementAndGet(); // 原子操作,相当于count++
}
});
}
executorService.shutdown();
executorService.awaitTermination(1, TimeUnit.SECONDS);
System.out.println("最终计数:" + atomicCount.get()); // 必然是5000,无误差
}
}Java 5的JUC包,就像给开发者"装备升级",从"徒手攀岩"变成了"用专业工具登山",不仅降低了并发编程的门槛,还大幅提升了代码的性能和可靠性。这是Java并发编程的第一次"革命"。
三、优化升级(Java 6-8):性能再提升,编程更简洁
遇到的问题:JUC虽好用,但仍有优化空间
JUC解决了"有无"问题,但随着多核CPU的普及和业务复杂度的提升,新的问题又出现了:
- synchronized还是太笨重:虽然JUC的Lock性能更好,但synchronized是Java原生支持的,使用更简单,开发者希望synchronized也能有高性能;
- 大数据分治任务难处理:比如要计算1000万条数据的总和,用普通线程池需要手动拆分任务,代码繁琐;
- 异步任务获取结果麻烦:用Future获取异步任务结果时,只能通过get()方法阻塞等待,无法实现"任务完成后自动回调",异步协作不灵活。
解决思路:优化原有机制,新增高级工具,简化并发编程
1. Java 6:synchronized锁优化,"重型铁门"变"智能门"
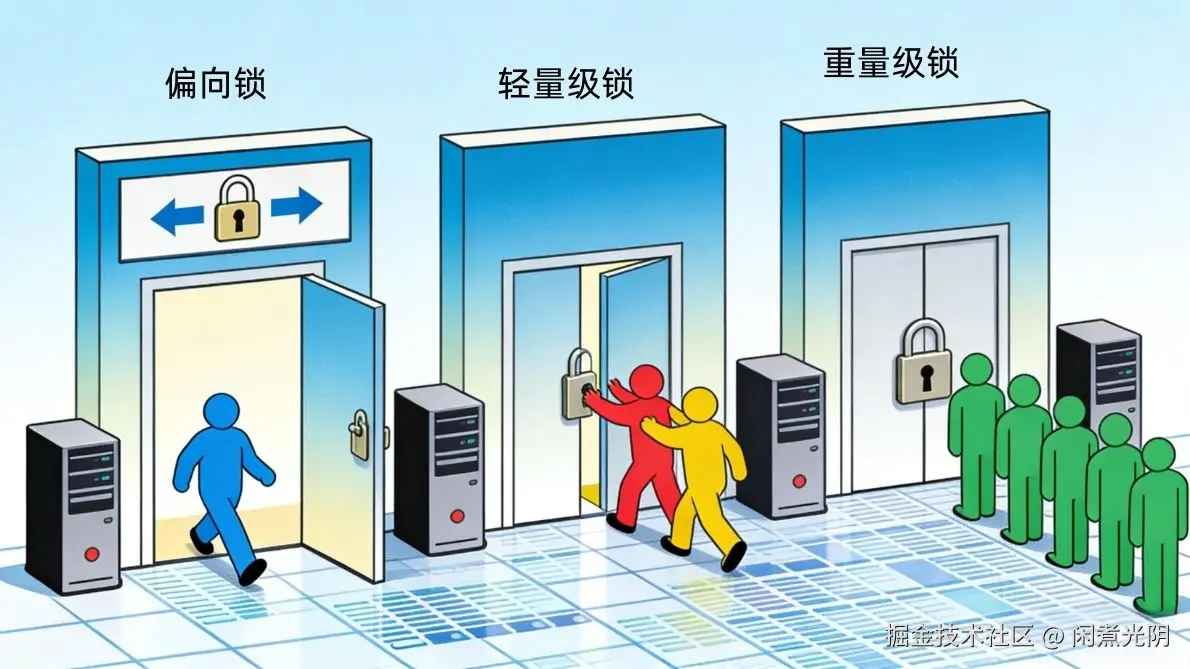
Java 6对synchronized进行了重大优化,引入了"偏向锁、轻量级锁、自旋锁"的升级机制,就像把"重型铁门"改成了"智能门":
- 偏向锁:如果只有一个线程用锁,就"偏向"这个线程,不用每次都加锁解锁,相当于门一直开着,只有这一个人用;
- 轻量级锁:如果有少量线程竞争,就用CAS机制实现轻量级锁,不用进入内核态,相当于几个人轻轻推搡着抢门;
- 重量级锁:只有竞争激烈时,才升级成原来的重量级锁,相当于门被锁死,大家排队依次进。
这次优化让synchronized的性能接近ReentrantLock,开发者不用再为了性能刻意选择Lock,用synchronized就能写出简洁又高效的代码。
2. Java 7:Fork/Join框架,"分治任务"自动拆分合并
就像工地拆大工程,Fork/Join框架会自动把大任务拆成多个小任务(Fork),分配给不同线程执行,最后再把小任务的结果合并(Join),不用手动拆分。
代码示例:用Fork/Join计算1到1000万的总和:
java
// 定义分治任务
class SumTask extends RecursiveTask<Long> {
private static final int THRESHOLD = 10000; // 阈值,小于这个值就直接计算
private long start;
private long end;
public SumTask(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
if (end - start < THRESHOLD) {
// 小任务,直接计算
long sum = 0;
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
} else {
// 大任务,拆分
long mid = (start + end) / 2;
SumTask leftTask = new SumTask(start, mid);
SumTask rightTask = new SumTask(mid + 1, end);
leftTask.fork(); // 执行左任务
rightTask.fork(); // 执行右任务
// 合并结果
return leftTask.join() + rightTask.join();
}
}
}
public class ForkJoinDemo {
public static void main(String[] args) {
// 创建Fork/Join线程池
ForkJoinPool forkJoinPool = new ForkJoinPool();
// 提交大任务
SumTask sumTask = new SumTask(1, 10000000);
Long result = forkJoinPool.invoke(sumTask);
System.out.println("1到1000万的总和:" + result);
forkJoinPool.shutdown();
}
}Fork/Join框架会自动利用多核CPU资源,让任务执行更高效,大幅简化了分治类并发任务的代码。
3. Java 8:CompletableFuture+并行流,异步编程"丝滑"到底
Java 8之前,用Future获取异步结果需要阻塞等待,就像"点外卖后一直盯着手机等送达";而CompletableFuture支持链式回调,就像"点外卖时设置送达提醒,不用盯着手机,送达后自动通知你",异步协作更灵活。
代码示例:用CompletableFuture实现"异步查询用户信息→异步查询用户订单→合并结果":
java
public class CompletableFutureDemo {
// 模拟异步查询用户信息
private static CompletableFuture<String> queryUserInfo(String userId) {
return CompletableFuture.supplyAsync(() -> {
System.out.println("异步查询用户信息,线程:" + Thread.currentThread().getName());
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "用户" + userId + ":张三";
});
}
// 模拟异步查询用户订单
private static CompletableFuture<String> queryUserOrder(String userId) {
return CompletableFuture.supplyAsync(() -> {
System.out.println("异步查询用户订单,线程:" + Thread.currentThread().getName());
try {
Thread.sleep(300);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "用户" + userId + "的订单:订单123";
});
}
public static void main(String[] args) throws InterruptedException {
String userId = "1001";
// 链式调用,合并两个异步任务的结果
CompletableFuture<String> resultFuture = queryUserInfo(userId)
.thenCombine(queryUserOrder(userId), (userInfo, userOrder) -> {
return userInfo + "\n" + userOrder; // 合并结果
});
// 异步获取结果,不阻塞主线程
resultFuture.whenComplete((result, ex) -> {
if (ex == null) {
System.out.println("最终结果:\n" + result);
} else {
System.out.println("查询失败:" + ex.getMessage());
}
});
// 主线程继续做其他事
System.out.println("主线程执行其他任务...");
Thread.sleep(1000); // 等待异步任务完成
}
}除此之外,Java 8的Stream API还支持parallelStream(并行流),不用手动处理线程,只需在stream()后加parallel(),就能实现集合的并行计算,底层自动基于Fork/Join框架。
示例:用并行流计算集合中偶数的总和:
java
public class ParallelStreamDemo {
public static void main(String[] args) {
List<Integer> list = IntStream.rangeClosed(1, 1000000).boxed().collect(Collectors.toList());
// 并行流计算偶数总和,自动利用多线程
long evenSum = list.parallelStream()
.filter(num -> num % 2 == 0)
.mapToLong(Long::valueOf)
.sum();
System.out.println("1到100万偶数总和:" + evenSum);
}
}Java 8的这些特性,让并发编程从"手动管理线程"升级到"声明式编程"------开发者只需告诉程序"要做什么",不用关心"线程怎么分配",代码简洁度和可读性大幅提升。
四、虚拟线程(Java 21):突破OS线程限制,实现百万级并发
传统Java线程直接绑定OS线程,创建成本高、内存占用大(每个线程约1MB栈空间),一个JVM最多只能创建几千个线程,根本无法支撑百万级并发请求;即便用线程池优化,也需要开发者精心调优核心线程数、队列大小等参数,门槛高且易出错。
解决思路:JVM层面轻量级线程,脱离OS线程束缚
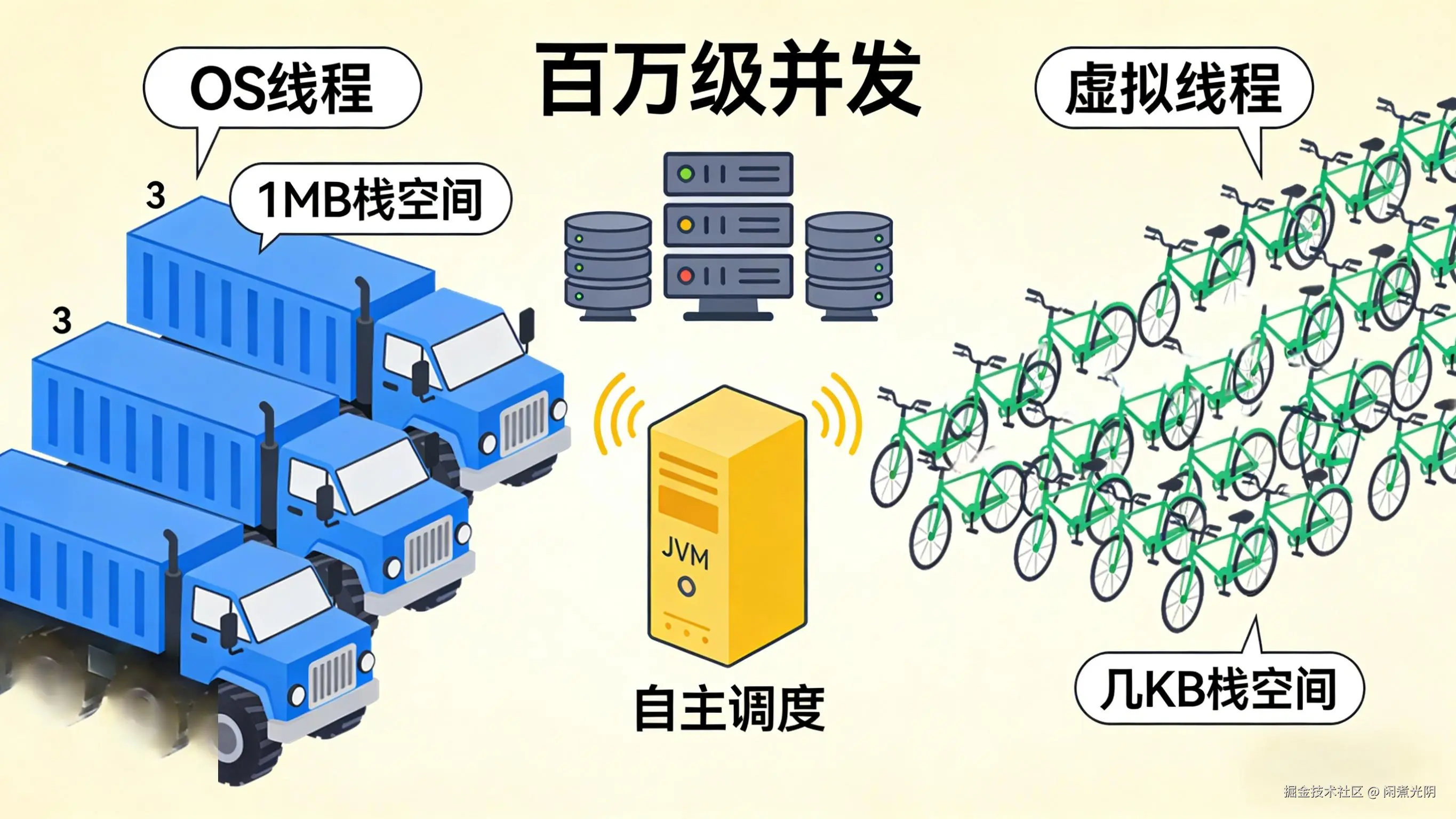 Java 19预览、Java 21正式发布的虚拟线程(Project Loom),彻底改变了线程的实现逻辑。虚拟线程是JVM层面的轻量级线程,不直接绑定OS线程,由JVM自主调度,栈空间仅几KB且可动态伸缩,创建成本极低------一个JVM可轻松创建百万级甚至千万级虚拟线程,彻底突破OS线程的资源限制。
Java 19预览、Java 21正式发布的虚拟线程(Project Loom),彻底改变了线程的实现逻辑。虚拟线程是JVM层面的轻量级线程,不直接绑定OS线程,由JVM自主调度,栈空间仅几KB且可动态伸缩,创建成本极低------一个JVM可轻松创建百万级甚至千万级虚拟线程,彻底突破OS线程的资源限制。
传统OS线程是"重型卡车",载重量大但数量少、启动慢,适合长途重载;虚拟线程是"电动自行车",轻便灵活、启动快,数量可极多,适合短途高频的并发任务(如HTTP请求处理)。
解决方案:极简API实现百万级并发
虚拟线程的使用方式与普通线程几乎一致,开发者无需学习新API,只需将"new Thread()"替换为"Thread.startVirtualThread()",即可快速实现高并发。代码示例如下:
java
public class VirtualThreadDemo {
public static void main(String[] args) throws InterruptedException {
// 记录开始时间
long start = System.currentTimeMillis();
// 创建100万个虚拟线程(传统线程会直接OOM)
for (int i = 0; i < 1_000_000; i++) {
int taskId = i;
Thread.startVirtualThread(() -> {
// 模拟简单任务(如处理一个HTTP请求)
if (taskId % 100000 == 0) {
System.out.println("虚拟线程处理任务:" + taskId);
}
});
}
// 等待所有虚拟线程执行完成(简化处理)
Thread.sleep(2000);
long end = System.currentTimeMillis();
System.out.println("100万个虚拟线程执行完成,耗时:" + (end - start) + "ms");
}
}虚拟线程的核心价值是"降低高并发实现门槛":开发者无需关注线程池调优,只需专注业务逻辑,就能写出支撑百万级并发的代码,是Java并发编程的"划时代突破"。
五、结构化并发(Java 19+ 预览):虚拟线程的"配套管家",解决任务管理隐患
遇到的问题:虚拟线程普及后,任务生命周期管理混乱
虚拟线程降低了并发任务的创建成本,但随之带来新问题:主线程启动大量虚拟子线程后,若自身被中断或异常退出,这些子线程可能沦为"孤儿线程",持续占用CPU和内存资源;开发者需手动编写大量代码协调子任务启停,确保所有子任务完成后再释放资源,代码繁琐且易出现资源泄漏。比如处理用户请求时,若请求超时被中断,对应的虚拟子线程若未及时终止,会成为"僵尸任务"。
解决思路:任务生命周期与代码结构绑定,自动管控子任务
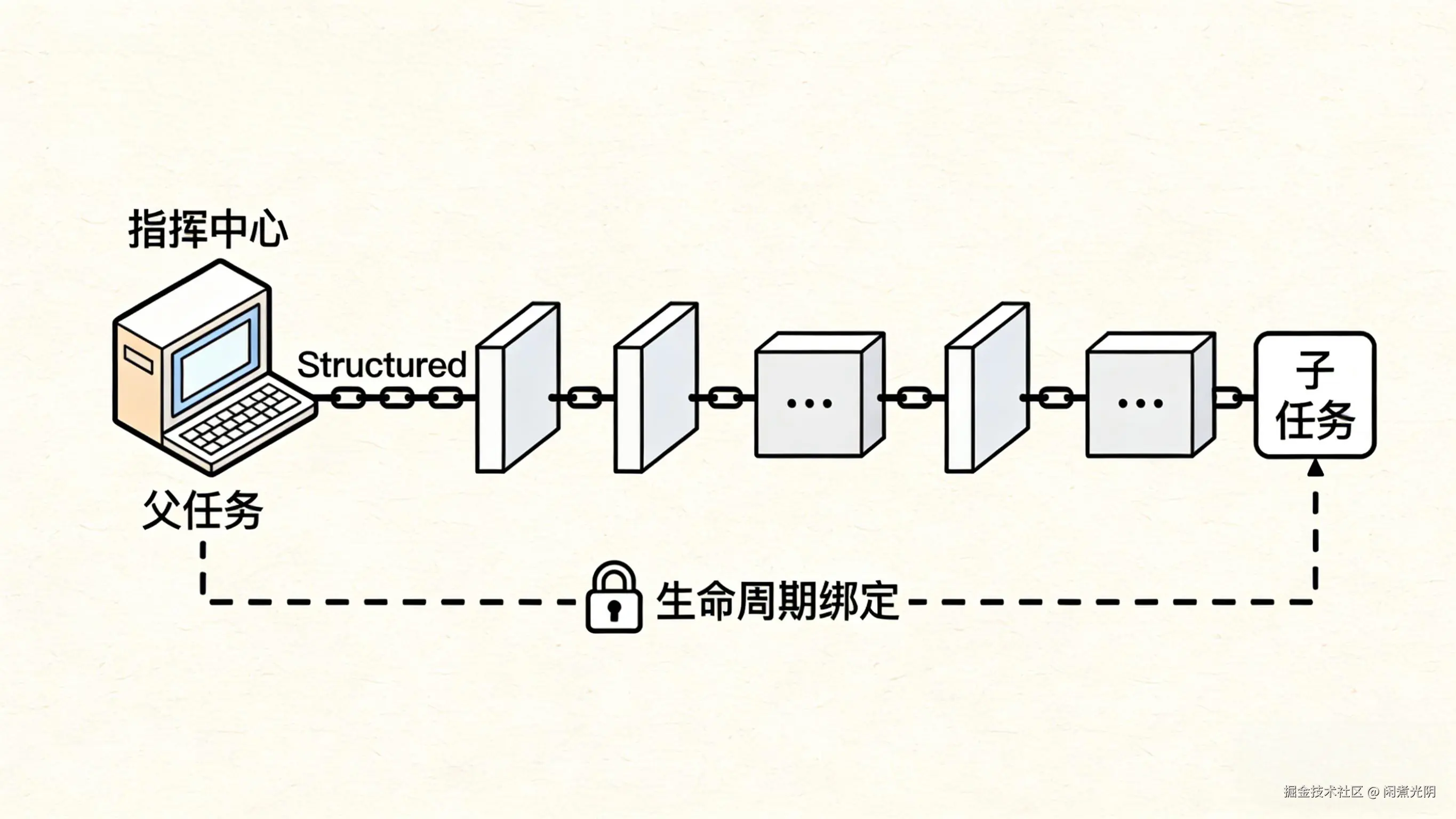
Java 19引入结构化并发(预览特性,Java 25继续预览),核心是"结构化管控任务生命周期"------将父任务与子任务的生命周期绑定到代码块,实现"父存子存、父亡子亡"的自动管理,从根源上避免孤儿线程和资源泄漏。需注意:当前仍为预览特性,生产环境使用需谨慎。
结构化并发就像"组织团队出差",父任务是"出差负责人",子任务是"团队成员"。负责人出发(父任务启动)时,成员一起出发(子任务启动);负责人返程(父任务结束)时,无论成员是否完成工作,都必须一起返程(子任务终止);若负责人遇意外(父任务异常),会立即通知成员集合(子任务中断),避免成员失联(孤儿线程)。
解决方案:StructuredTaskScope+try-with-resources实现自动管控
通过StructuredTaskScope类结合try-with-resources语法,让子任务的创建、执行、中断、资源释放全流程自动化,代码示例如下:
java
public class StructuredConcurrencyDemo {
// 模拟子任务1:查询用户信息
private static String queryUserInfo(String userId) throws InterruptedException {
Thread.sleep(300); // 模拟任务耗时
return "用户" + userId + ":李四";
}
// 模拟子任务2:查询用户订单
private static String queryUserOrder(String userId) throws InterruptedException {
Thread.sleep(500); // 模拟任务耗时
return "用户" + userId + "的订单:订单456";
}
public static void main(String[] args) {
String userId = "1002";
// 结构化任务作用域,采用ShutdownOnSuccess策略:任一子任务成功则中断其他子任务
try (StructuredTaskScope<String> scope = new StructuredTaskScope.ShutdownOnSuccess<>()) {
// 提交两个子任务(默认运行在虚拟线程中)
Future<String> userInfoFuture = scope.fork(() -> queryUserInfo(userId));
Future<String> userOrderFuture = scope.fork(() -> queryUserOrder(userId));
// 等待所有子任务完成(或任一子任务成功/失败)
scope.join();
// 获取子任务结果
String userInfo = userInfoFuture.resultNow();
String userOrder = userOrderFuture.resultNow();
System.out.println("查询结果:\n" + userInfo + "\n" + userOrder);
} catch (InterruptedException e) {
System.out.println("父任务被中断,子任务已同步终止");
}
}
}代码说明:try-with-resources语法确保作用域自动关闭,scope.join()让父线程等待子任务完成,若父线程被中断,scope会自动中断所有子任务。结构化并发是虚拟线程的"配套增强",两者结合让高并发任务的实现既高效又安全。
总结:Java并发进化的核心逻辑------让开发者"少踩坑、多聚焦业务"
回顾Java并发编程的进化史,本质是一部"精准解决开发者痛点"的迭代史,核心围绕三个方向展开:
- 降低门槛:从手动控制线程到JUC工具类,再到CompletableFuture、虚拟线程、结构化并发,抽象层级持续提升,开发者无需关注底层线程细节和生命周期管理,只需聚焦业务逻辑;
- 提升性能:从重量级synchronized到锁升级、CAS无锁机制,再到虚拟线程,持续降低并发性能开销,从"千级并发"突破到"百万级并发";
- 适配场景:从通用并发到分治任务、异步编程、高并发请求处理、任务结构化管控,不断覆盖更复杂的业务场景。
从"徒手攀岩"到"坐缆车登山",Java并发的进化始终遵循"封装复杂逻辑、简化开发流程"的原则。了解这段历史,不仅能帮你快速选对并发工具,更能理解"遇到问题→分析问题→解决问题"的技术迭代思维------这正是开发者成长的核心逻辑。