
导读:
构建一台"测试用例生成引擎"------驱动质量左移的智能飞轮
软件质量不是终点,而是一个持续加速的飞轮。
传统测试像靠人力推车,缓慢且迟滞;而 AI 辅助的用例开发,则是为这个飞轮装上一台智能引擎。
这台引擎由七大核心组件驱动:专属数据输入、智能需求解析、测试场景建模、用例迭代生成、变更动态感知、标准化输出适配、自动化执行集成。
当七者协同运转,引擎轰鸣启动------用例自动生成、风险提前暴露、反馈闭环加速,真正实现"质量内建,左移落地"。
一、背景
QA同学一定懂这个痛点:长期使用固定测试用例集或同一测试方法,软件会像生物抗药性一样产生"测试免疫力",缺陷发现效率越来越低------这就是测试领域的"杀虫剂悖论"。
为了应对这个问题,我们一直靠持续迭代用例、动态扩充数据、组合交叉测试等方法维持有效性。但随着项目快速迭代,业务场景和功能模块越来越多,新的难题又冒了出来:
-
需求分析、用例开发维护复杂度飙升:既要精准对齐新增功能细节,又要兼顾回归用例兼容性,有限时间里得反复梳理新旧场景关联;
-
用例库累积成负担:日常维护要耗费大量精力更新适配,需求紧急时还容易陷入"旧用例覆盖不到新场景、新用例兼顾不到老逻辑"的被动;
-
"测试免疫力"问题放大:高频迭代下,传统方法的局限性越来越明显,拖慢测试节奏的同时,缺陷漏测风险也在增加。
在AI技术爆发的当下,我们决定跳出传统框架,打造**「QA智绘」**项目,用智能破解"抗药性",从根本上杜绝"雪球测试"中的杀虫剂效应。
二、「QA智绘」之Feature测试用例生成:三层架构搞定自动化
传统测试用例开发,QA要走完"需求分析→用例设计→评审优化→管理维护"全流程。考虑到用例评审是产研测三方对齐逻辑的关键节点,因此我们优先聚焦另外三个环节,结合大模型能力搭建了"输入-生成-输出"三层AI自动生成架构,再依托Dify基建能力做全链路支撑。
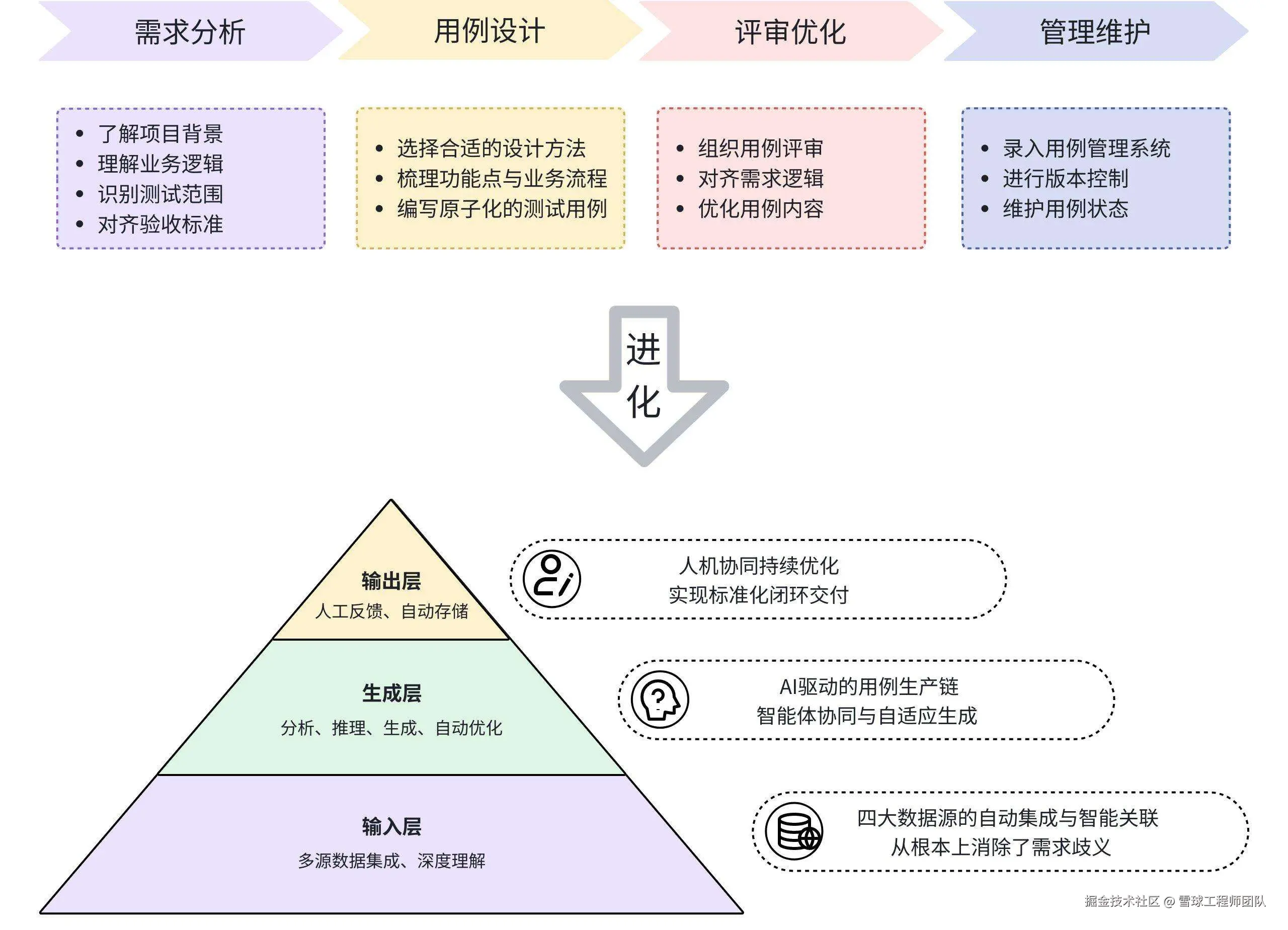
-
输入层完成对数据源的自动集成与智能关联,从根源消弭需求传递中的歧义;
-
生成层以 Dify 提供的工作流引擎、多模型调度、Prompt+思维链架构为底座,搭配接入的工具适配能力,驱动核心模块完成从需求分析、需求点分解到用例生成与优化的全流程自动化;
-
输出层通过人机协同机制,实现测试用例的持续迭代与标准化闭环交付。

Feature用例生成的三层架构
简单说,这个体系的核心就是一套智能增强决策系统:接收需求后,会按严密的"思考链"做任务分解、逻辑推理和结果验证,最终实现用例的自动化生成与标准化交付。下面我们逐层拆解核心逻辑:
1. 输入层:智能化的数据整合分析
高质量用例的前提是完整的需求分析,但人工分析很容易出问题:对业务逻辑理解不到位、需求变更跟进滞后、个人经验局限导致风险判断不足......为了解决这些痛点,我们整合了四大数据源,搭配Prompt工程+思维链,打造了一个"会思考"的测试数据中枢。
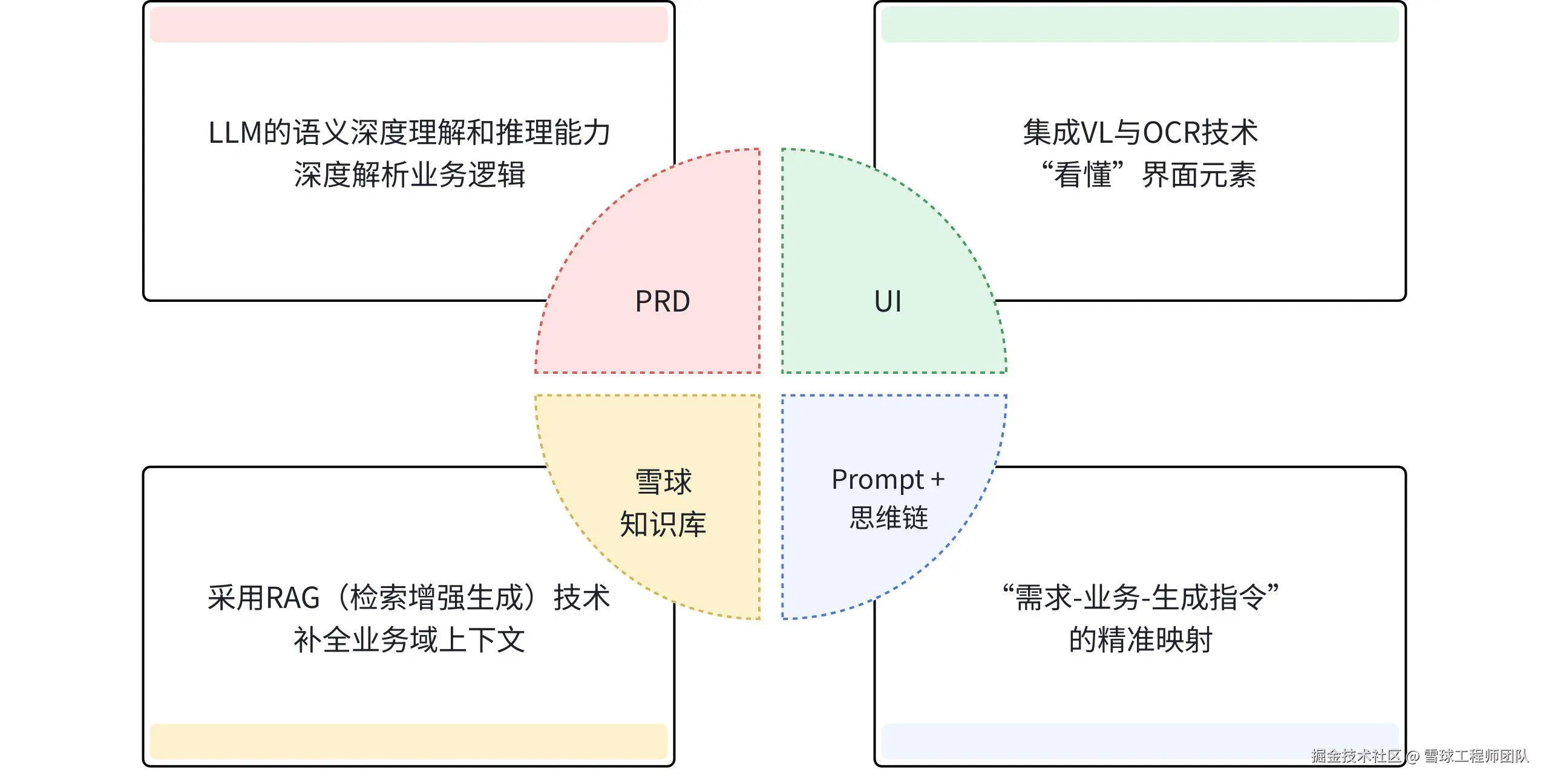
这个中枢的核心能力有4个:
-
语义深度推理与风险预判 :利用LLM(大语言模型)深度解析业务逻辑、用户旅程与复杂规则(如"支付流程中手续费计算规则");自动标识高风险功能点(如资损相关操作);
-
视觉化上下文理解 :集成VLM(视觉大模型)与OCR技术,让AI"看懂"UI界面,识别元素状态与设计冲突,为交互测试与视觉兼容性测试构建像素级判定基线;
-
历史经验的知识化复用 :通过用RAG(检索增强生成)技术检索雪球知识库与历史用例,补全业务背景、映射功能模块关联,为AI装配上"资深测试专家的记忆库";
-
**Prompt +思维链:**以 "需求分析→业务拆解→用例生成" 为核心框架,按业务特征差异化定制各模块的核心侧重点、输入输出规范及 Prompt 逻辑。通过模块化降低模型认知负担,精准适配业务风险,避免用例覆盖不全或冗余。
输入层作为一个智能化的**数据整合分析中心,**将原本孤立、静态的数据资产,转化为动态可推理的"活化知识图谱",使测试设计从源头就立足于全面精准的数据支撑;并将分散的需求信息、技术背景与历史经验,转化为可落地、可量化的测试策略,从根源上化解需求歧义、打破数据孤岛、填补覆盖盲区,为后续用例生成筑牢基础。
2. 生成层:AI驱动的用例智能生产链
完成上游多源信息的智能融合后,流程即进入核心的测试用例生成阶段。该阶段将系统性落地 "需求分析→需求点分析与分组→用例初步生成→用例评分→用例优化" 全流程,确保每一步衔接有序、闭环可控。
以其中的用例生成环节为例: 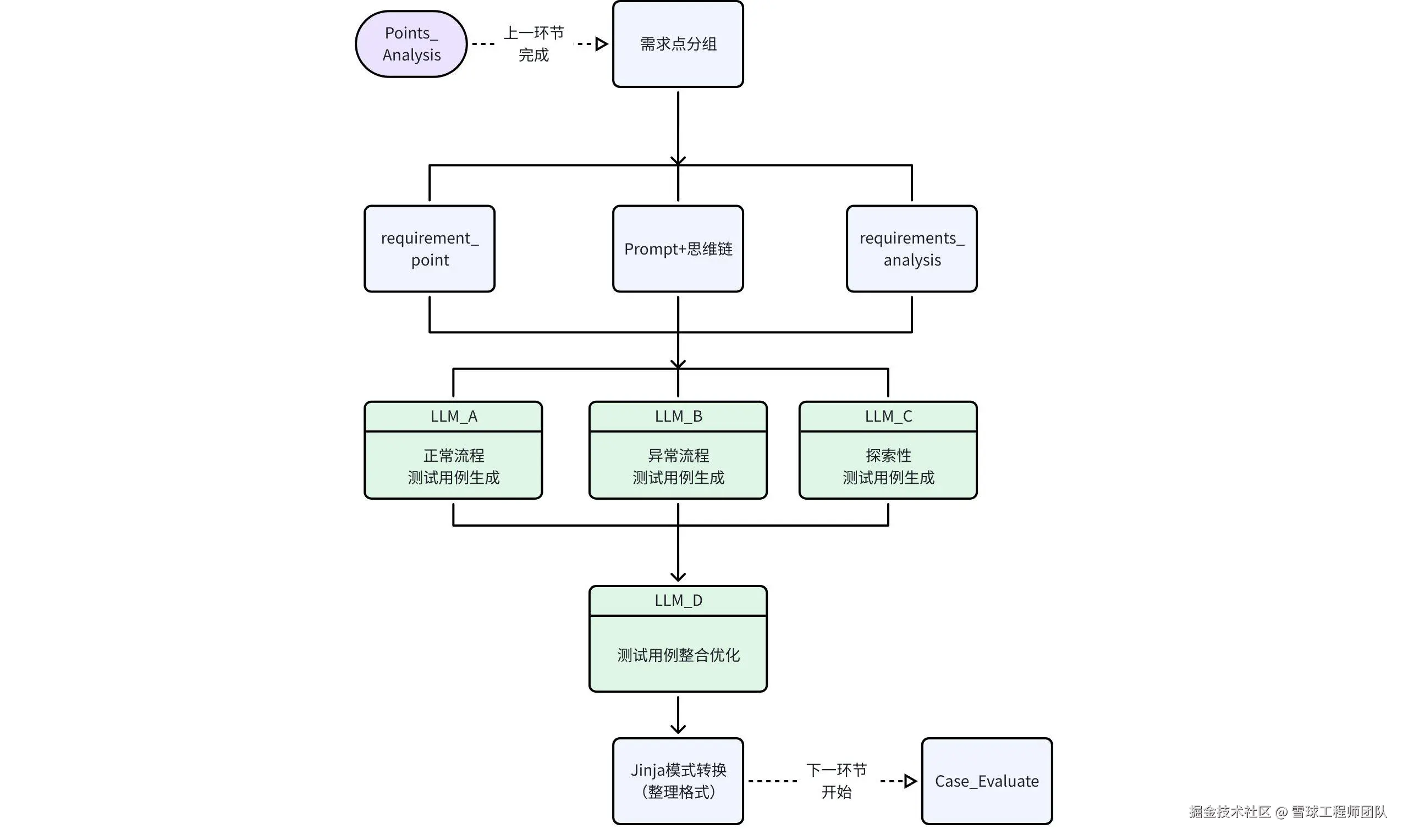
-
需求点预分组,规避输入过载与输出截断:用DAG分析把复杂需求拆分成多个高内聚的"需求点包",再序列化输入,解决大模型上下文过载问题,避免逻辑遗漏与输出截断;
-
**多模型协同,提升用例思维的深度与广度:**结合不同模型优势,生成覆盖正常、异常、探索性场景的多样化用例,避免单一模型遗漏深层隐匿的缺陷;
-
**标注模板约束,确保用例产出的标准化:**以JSON Schema定义数据模型,确保用例包含"前置条件→操作步骤→预期结果"等要素,再借助 Jinja 模板转换为标准格式,提升后续评审、执行、维护效率;
-
**反思(Reflection)模式,驱动用例循环强化:**内置多维度质量量化评分算法,从完整性、准确性、可执行性、覆盖度等维度打分,低于阈值自动打回重生成,形成"评估-反馈-优化"闭环,保障用例质量。
3. 输出层:标准化闭环交付
经过生成层的拆解、评估、优化,用例最终在输出层完成交付。输出层的核心目标是确保AI生成的测试用例能够安全、可靠地融入现有工具链,实现从生成到可用的"最后一公里"闭环。其运作依赖于两大关键机制:
-
人机协同审核:建立"AI初筛-人工复核"的协作模式。人工重点校验上下文一致性(确保用例对应需求节点)和业务规则准确性,规避AI"幻觉"风险,给用例质量兜底;
-
结构化分发 :审核通过的用例会被自动赋予丰富的结构化标签 (如关联需求ID、测试类型、优先级P0-P2),完成"资产化"封装。随后,通过预定义的API接口,将用例同步到飞书、MeterSphere、雪峰后台等目标平台,实现测试资产的无缝集成 与端到端可追溯。
至此,Feature测试用例自动生成系统已正式落地交付。在社区平台业务的实际应用中,自动生成用例的有效率达70%以上,显著节省了人工投入、提升了测试效率。后续我们将持续精进这一能力,并逐步拓展至更多业务场景。
搞定功能级用例生成后,我们把目光投向了前后端协作的核心纽带------接口层。毕竟接口的稳定性直接关系业务流程可靠性,「QA智绘」的智能生成能力也随之延伸到了接口测试领域。
三、 「QA智绘」之接口用例自动化:双核思路破解测试痛点
做接口测试,最头疼的两件事:一是用例容易覆盖不全、分支漏测;二是用例维护难,代码迭代一次就要维护半天。这正是我们设计「QA智绘」之接口用例自动化系统的直接原因。为了彻底解决这些痛点,我们带来了一套可落地的完整方案:通过深挖调用链吃透接口代码,实现用例的代码级全覆盖;再借助AI闭环自优化,让用例越用越精准,从而真正摆脱重复低效的手动操作。该设计已在系统的四层架构中全面落地,形成从问题识别到自主优化的完整闭环。如图所示: 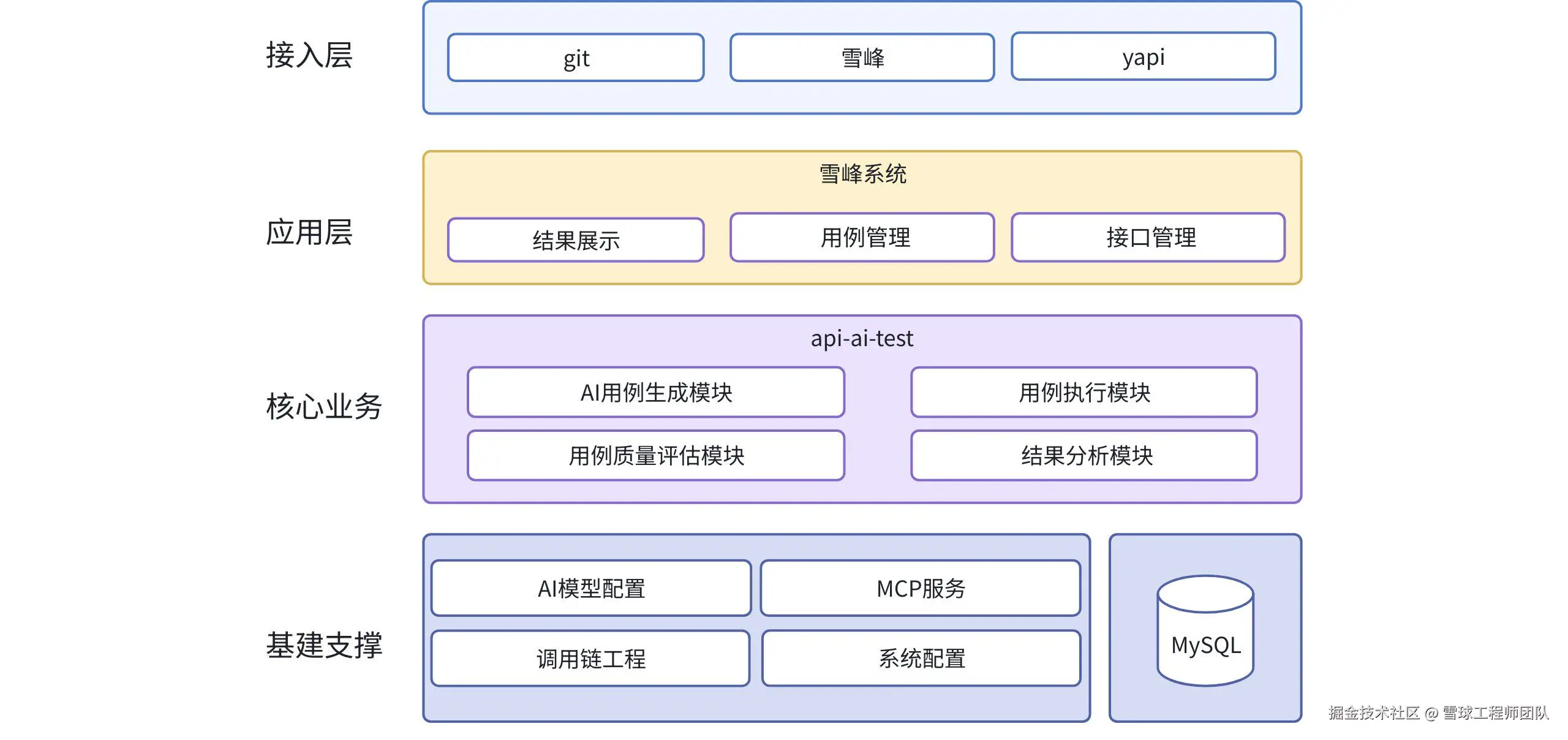
整个系统采用清晰的分层设计,各层各司其职又紧密协同:
-
**基建支撑层:打下坚实的"地基" ,**包含调用链工程、AI模型配置与MCP服务、MySQL与系统配置,为上层能力提供核心支撑;
-
**核心业务层:承载核心解决方案,**这是系统的"大脑"和"中枢"。包含AI用例生成模块、用例执行模块、结果分析模块、用例质量评估模块,让用例库"越用越精准",从而解决"维护难"的挑战;
-
**应用层:统一治理与可视化平台,**通过雪峰系统,我们将核心能力转化为用户可便捷操作的产品界面,包含接口管理、用例管理、结果展示,让技术能力适用所有QA和研发同学;
-
**接入层:接入研发生态,**通过对接Git、YAPI、雪峰等现有研发工具链,系统能够自动获取接口定义、代码变更等关键信息,实现流程的无缝集成,让测试左移和持续测试成为自然流程。
基于以上对系统架构的分层解析,我们可以看到,整个系统并非简单的功能堆砌,而是为彻底解决文章开头提出的痛点,所精心构建的一条技术实现路径,这条路径在架构中清晰可见,并最终凝结为支撑「QA智绘」高效运行的三个核心议题。
1. 用例全覆盖:代码+调用链双驱动
很多时候需求文档里只有接口的表面规则,那些隐性校验、异常分支、模块依赖,根本无从知晓。而"代码+调用链"的双驱动模式,就能把这些隐藏的逻辑全挖出来。核心目标很简单:让每一行核心代码都有对应的测试用例,每一个分支逻辑都被覆盖。
之前我们在《代码"蝴蝶效应"终结者:Al Review+AST联展,构建智能测试防御新体系》一文中,已经搭建好了代码导航系统,能清晰梳理出每个方法之间的调用关系。基于这个系统,我们就能获取接口从上到下的完整调用链代码,再让AI按规则一键生成代码全覆盖用例 。如图所示:「QA智绘」之接口用例自动化项目系统性地通过 "多源数据整合→ 多模型独立探索 → 智能融合仲裁" 三步法,来最大化逼近测试用例的全覆盖。 
-
多源数据整合,构建全景认知(数据驱动):流程始于对接口的360度深度透视。自动化地从多个关键数据源同步获取信息,形成一份整合的Prompt,从源头确保生成用例的输入信息是全面、立体且准确的;
-
多模型独立探索,激发思维多样性(智能驱动):这是确保覆盖范围、避免单一模型思维局限的关键设计。系统并行发起三次异步调用,从不同视角独立构思测试方案,从而汇集多样化的测试想法,有效避免了因单一AI思路固化导致的覆盖盲区;
-
智能融合仲裁,生成最优集(闭环优化):并行探索产出了三份各有侧重、可能存在冗余或冲突的用例草案。系统引入了关键的第四次模型调用,扮演"首席测试架构师"的角色,确保最终入库的用例集是"1+1+1 > 3"的高质量、高可信度成果。
2. 覆盖率可视化:代码染色直观验证
AI生成用例后,怎么确认是不是真的全覆盖了?答案是「代码染色」。
通过可视化界面,被覆盖的代码会标注一种颜色,未覆盖的标注另一种颜色,哪些地方没测到、哪些地方已达标,一目了然。不用再手动核对,效率直接拉满!
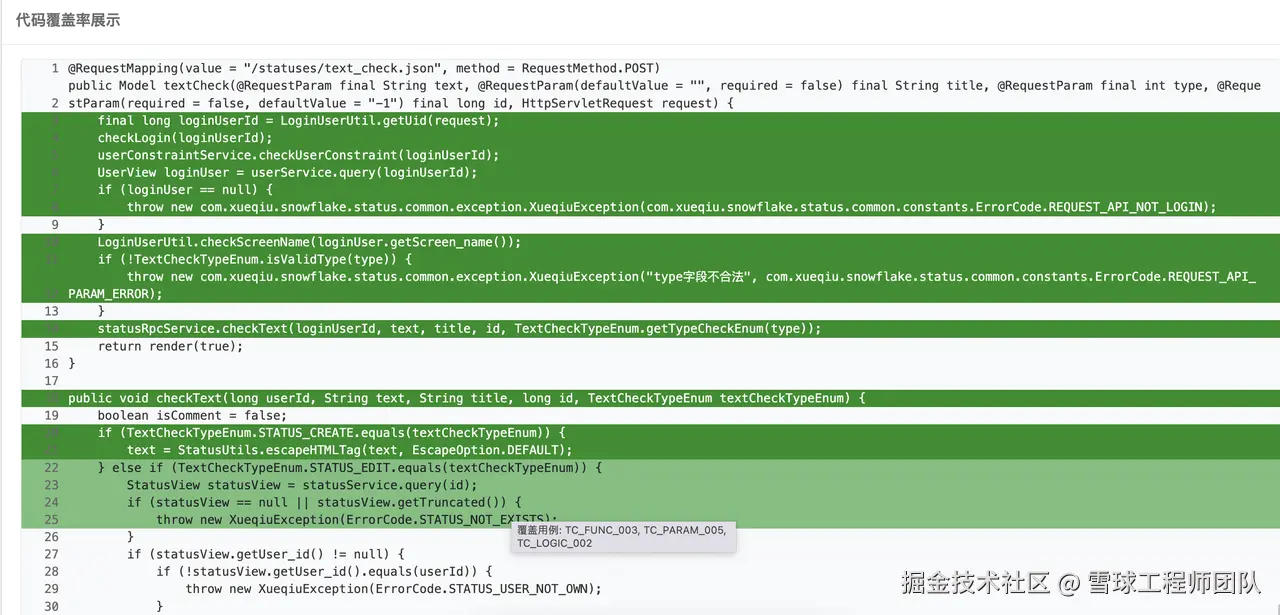
这正是我们"代码+调用链"双驱动模式价值的直观体现。通过调用链分析,AI能够精准生成触及深层逻辑的用例;而通过代码染色的可视化验证,覆盖结果变得一目了然。让质量保障从生成到验证,形成一个完整、可信的闭环。
3. AI用例自优化:闭环驱动,告别手动维护
解决了漏测问题,再来看用例维护难的痛点。核心思路是搭建「生成→执行→反馈→优化」的闭环,靠MCP模型协作、人工审核、调试结果反哺,让用例越用越精准,彻底告别手动修改。 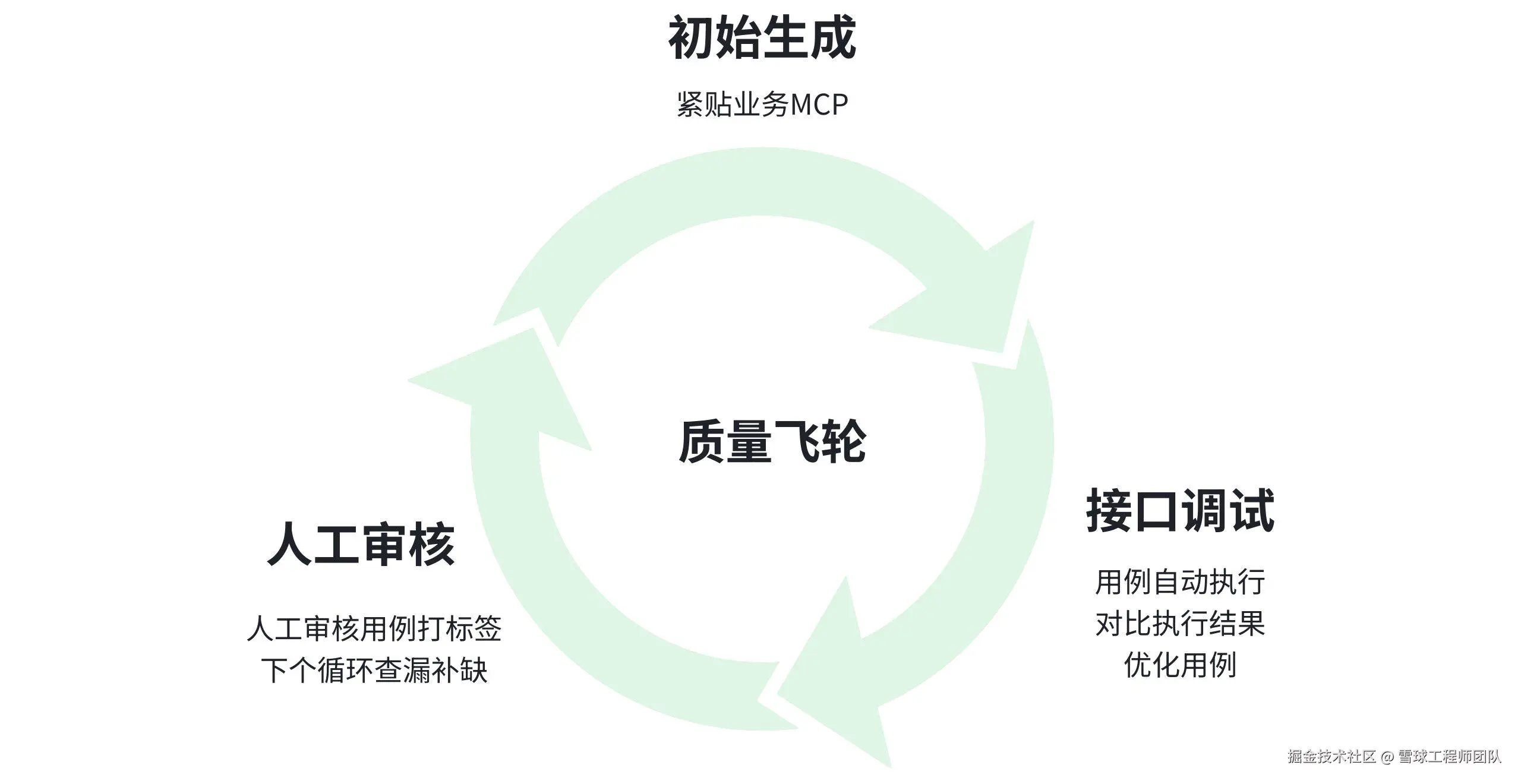
-
MCP服务:贴合业务,生成高质量初始用例。初始用例的质量很关键,直接影响后续优化效率。我们结合MCP服务,让AI能精准匹配业务场景,生成的初始用例不仅覆盖全面,还能贴合实际业务逻辑,不用再从零开始打磨。
-
调试结果反哺:自动修正,用例"自我迭代"。用例生成后会自动执行,系统会对比实际执行结果与预期结果。如果出现偏差,就会自动分析原因,修正用例中的参数、断言等内容------相当于用例在"自我迭代",不用人工逐个修改。
-
人工审核迭代:精准打磨,查漏补缺。当然,AI优化也需要人工辅助把关。我们可以对用例进行审核打标签,比如"有效""无效""重复"等。这些标签会反哺给AI,后续生成用例时,就能针对性地查漏补缺,让用例质量越来越高。
四、小结
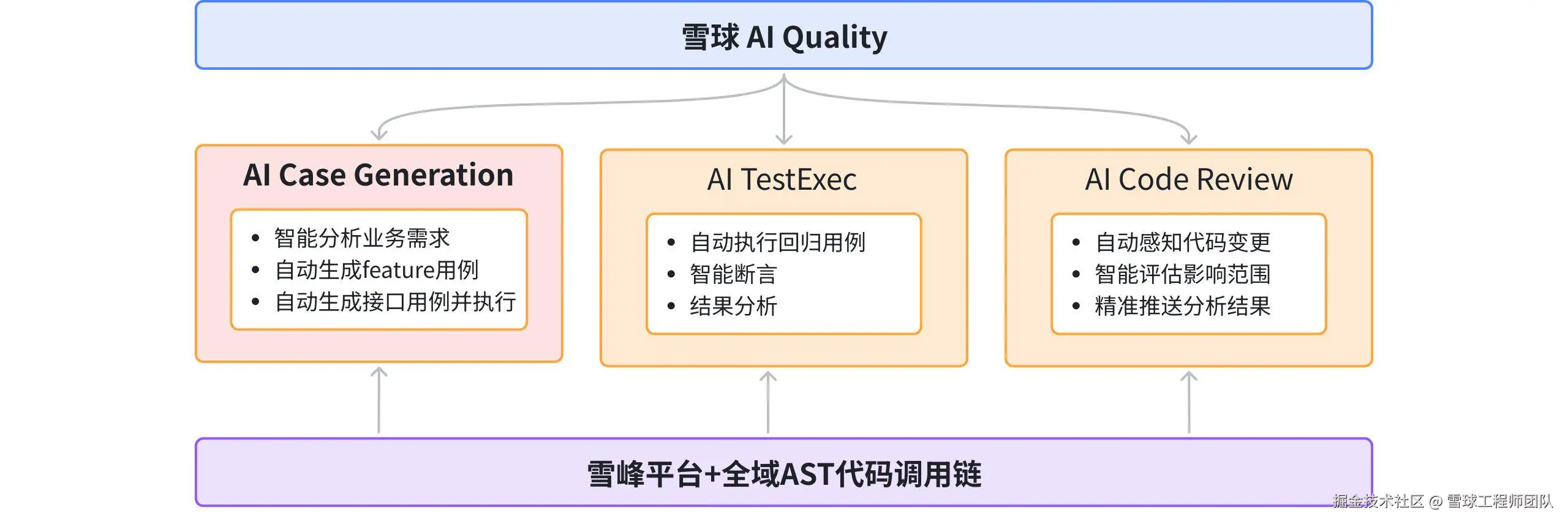
随着「QA智绘」-AI Case Generation 的正式落地,叠加持续建设的 AI TestExec、AI Code Review 能力,再依托雪峰系统和全域 AST 代码调用链的底层技术支撑,雪球 AI Quality 项目已初步搭建起质量域的智能闭环体系。
在核心的智能质量环节,实现 "用例自动生成-测试自动执行-代码自动检测" 的全流程自动化:
✅ AI Case Generation:可基于业务需求智能拆解测试点,自动生成 Feature 用例与接口用例并直接执行;
✅ AI TestExec:承接用例执行任务,完成回归测试的自动调度、智能断言与结果分析;
✅ AI Code Review:依托 AST 调用链感知代码变更,自动评估影响范围并将分析结果精准推送至对应负责人;
这一系列能力的联动,已推动雪球的质量保障模式从 "人工主导的重复劳动" 向 "智能驱动的精准保障" 完成了初步转型。
未来,雪球 AI Quality 将围绕 "能力深化+流程打通+生态协同" 三个方向持续迭代:
一方面,细化三大核心能力的精度,夯实智能化基础;
另一方面,打通各模块数据流转链路,构建 "业务需求-测试用例-执行结果-代码风险" 的联动反馈机制 ------ 用例迭代反哺需求分析完整性,执行失败自动关联代码变更,代码风险同步更新用例补充清单,实现双向闭环;
同时,推动三大能力与研发协作工具深度对接,融入产研全流程,形成 "智能质量保障+研发协作" 的一体化生态。 