!!!经验总结-常识
- 数据挖取最好在【早上】进行,最大程度避免影响业务
- 数据挖取必须走【读库】,因为我们是读写分离,读库哪怕当前比较卡顿也不会影响主业务
- 必须分段挖取数据!!! 一次性返回数据会导致数据库卡死,千万不能怎么做
- 挖取数据之前最好先在【读库】测试一下执行情况,以及执行时间
- 根据本次的优化,发现了比较好的挖取方式是:!!!
串行执行->每次挖取2000行数据->挖取间隔 100ms->挖取完成的数据立刻写入redis管道(满2000条推送到redis执行)
5.1本次耗时总共一个钟左右,大部分耗时是卡在登陆日记表总共花了26分钟;当时是1000行读取一次,一百万行,也就是当时平均每次执行sql+go处理+redis推送花了1.56s;这个完全是合理的,后面查看sql耗时发现不大;如果采用读2000行应该能省10分钟左右。
5.2其实还有一个礼物日志表十二个分表加一起有一亿多数据,但是因为不需要返回所有数据,只需要 分段聚合,其实性能消耗并不高,一次查询20w行数据,返回的数据可能不到500行,加上插入redis其实消耗不会超过2s; 所以哪怕一亿行数据统计花的时间不到2分钟(用到的是where id n between n+200000; 只要索引命中速度非常的快)
!!!经验总结-查询命令优化 :(本次只是挖取数据,尽量用到已有的索引,所以不考虑新加索引)
-
查询命令使用前可以用explain 查看是否有用到索引,比如这里就用到 索引 playerId,且不需要回表
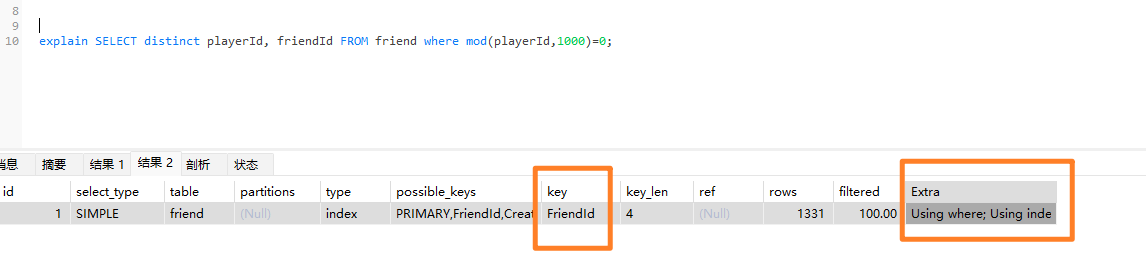
-
Sql 的where 条件能用索引就一定用索引,多个条件先把索引放前面,速度会快很多倍!!
-
Order by,group by 的对象也必须是索引,不然会触发 Using filesort(MySQL 没法按索引顺序直接吐数据,只能把结果先拿出来,再自己"额外排一次序"),Using temporary(临时表)
-
分段查询的性能语句对比:从优到劣
id > a limit m 的性能 (扫描到a后就停止,然后开始匹配m条数据,更灵活)
略大于
id between a,b 等于 id >=a and id <= b (扫描到a之后不会停止,会扫描到b才停止,开始匹配数据,扫描的数据未必都是命中数据)
远大于
mod(id, m)=nn=0...m-1 (这个的意义在于并行分片读取,扫描的行数是 m*总行数)
远大于
Limit m offest n(需要先扫描n行在获得m行,越到后面扫描越多, 扫描的行数是 总行数的平方!!!)
第六总结:从上看出第一第二充分了索引检索定位到指定位置,性能优异!
而第三还是需要读取所有行,如果不是为了并行计算,没啥意义
而第四是绝对不能取得,越到后面越爆炸
--看测试 id >m limit n 只扫描了指定得行数,而 mod需要扫描所有行数
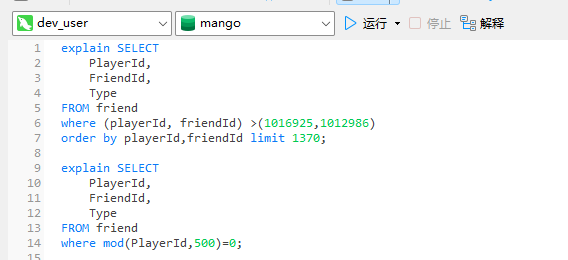


如何判断一个myql查询命令的好坏:
首先 :避免 使用limit offset, 还有对 非索引字段进行order by( Using filesort),
对非索引字段进行group by(Using temporary; Using filesort)

然后 ,善用explain执行看参数:
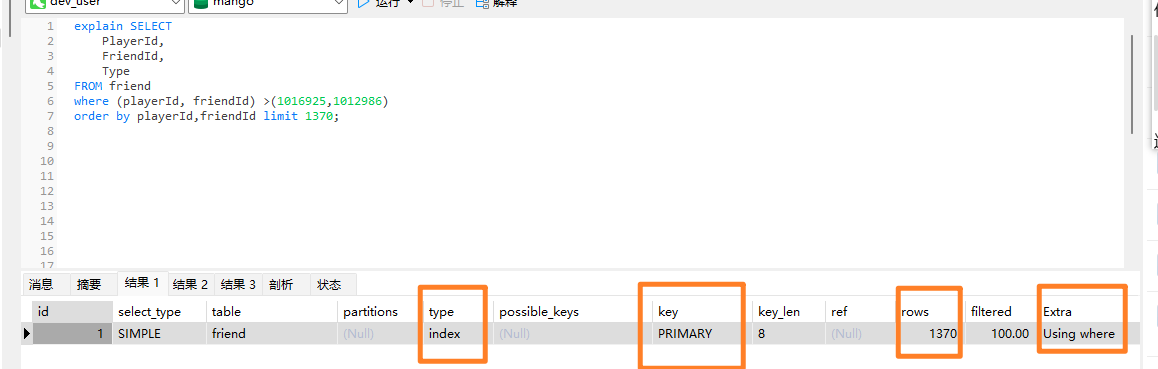
主要看四个地方:(按查看顺序 )
type: index 说明用了索引
Extra: Using Where(where 用到了索引),但是注意用到索引不一定是高效的,比如mod用到索引但是还是要扫描全表
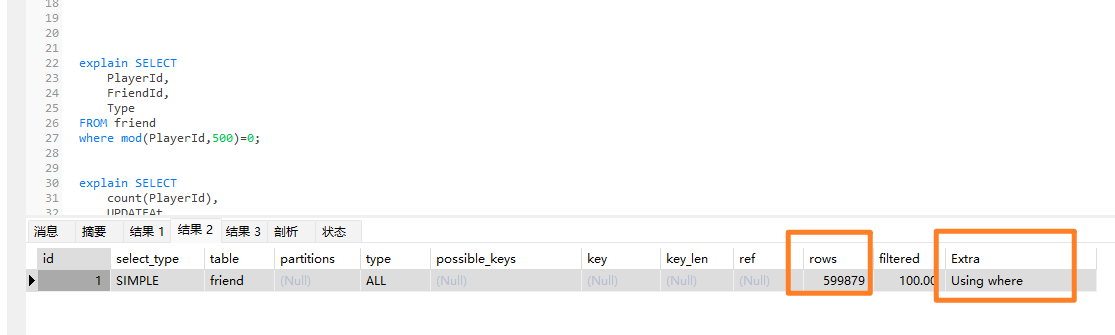
Extra: Using Index(用到覆盖索引,不需要回表查询)
Rows: 扫描行数,看上图就是很明显例子, mod用上了索引,但是 row扫描了全表;(rows 约等于 limit的语句才是好语句)
key:PRIMARY (使用了主键key,或者用具体索引字段)