1. 文本处理基本方法(★)
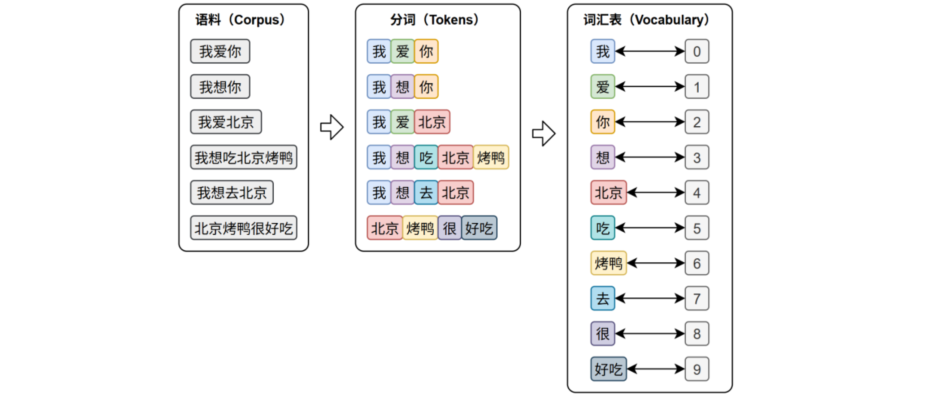
文本表示的第一步通常是分词 和词表构建
1.1 分词(★)
分词的任务是将原始文本切分为若干具有独立语义的最小单元(token),分词 是所有NLP任务的起点。
词表 则是由语料库构建出来的、包含着模型可以识别的token的集合。词表中的每个token都分配有唯一的ID,并且支持token与ID之间的双向映射
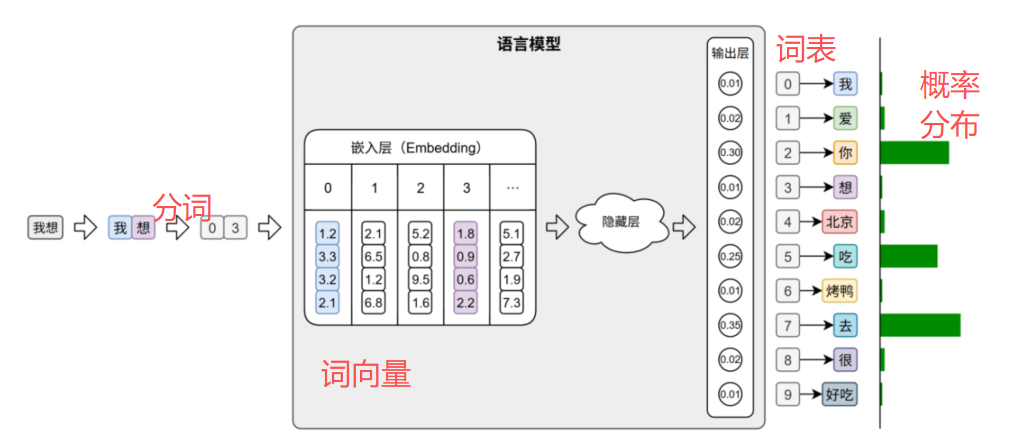
在后续的训练预测的过程中,模型会首先进行分词,再通过词表将每个token映射为其对应的ID(索引)
。这些ID会被嵌入层转换为低维稠密向量(词向量 )。即词向量是根据索引生成的
在文本生成任务中,模型的输出层会针对词表中的每个token生成一个概率分布 ,用来表示下一个词的可能性
1.1.1 英文分词
按照分词粒度的大小,可分为词级分词、字符级分词、子词级分
1.1.1.1 词级分词
指的是将文本按照词语进行切分,是最传统、最直观的分词方式。在英文中,空格和标点往往是天然的分隔符
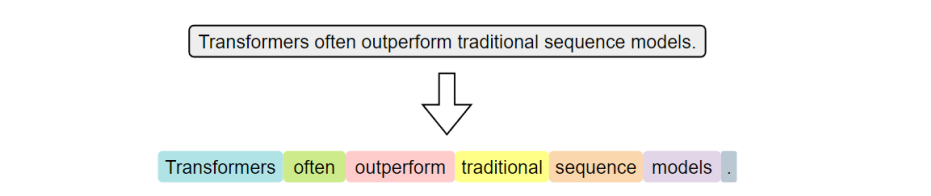
词级分词虽然便于理解和实现,但在实际中容易出现OOV (Out-Of-Vocabulary)问题,即"未登录问题"。这个问题是指在模型使用阶段,输入文本中出现了不再预先构建词表中的词语,由于模型无法识别这些词,通常会将其统一替换为特殊标记,从而导致语义信息的丢失,最终影响模型的理解与预测能力
1.1.1.2 字符级分词
指的是以单个字符为最小单位进行分词的方法,文本中的每一个字母、数字、标点、空格都会被视作一个独立的token
 这种分词形式,词表的颗粒度非常小,因此几乎不存在OOV问题。但是相反地它的语义表示能力就会非常弱,此时就必须依赖更长的上下文来推断词义和语句结构,这无疑会增加模型构建难度和训练成本。此外,输入序列也会变得很长,影响模型效率。
这种分词形式,词表的颗粒度非常小,因此几乎不存在OOV问题。但是相反地它的语义表示能力就会非常弱,此时就必须依赖更长的上下文来推断词义和语句结构,这无疑会增加模型构建难度和训练成本。此外,输入序列也会变得很长,影响模型效率。
1.1.1.3 子词级分词
指的是介于词级分词和字符级分词之间的分词方法,它主张将词语切分为更小的单元--字词。它的基本思想是:即使一个完整的词没有出现在词表中,只要它可以被拆分为词表中存在的字词单元,就可以被模型识别和表示,从而避免整体被替换为< UNK >

1.1.2 中文分词
尽管英文分词具有天然的优势,但是我们仍然可以借助"分词粒度"的视角,对中文的分词方式进行归类和分析
1.1.2.1 字符级分词
字符级分词是中文处理中最简单的一种方式,即将文本按照单个汉字进行切分,文本中的每一个汉字都被视为一个独立的 token。

由于汉字本身通常具有独立语义,因此字符级分词在中文中具备天然的可行性。相比英文中的字符分词,中文的字符分词更加"语义友好"。
1.1.2.2 词级分词
词级分词是将中文文本按照完整词语进行切分的传统方法,切分结果更贴近人类阅读习惯。
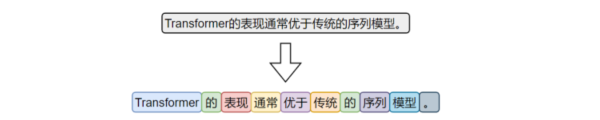
由于中文没有空格等天然词边界,词级分词通常依赖词典、规则或模型来识别词语边界。
1.1.2.3 子词级分词
虽然中文没有英文中的子词结构(如前缀、后缀、词根等),但子词分词算法(如 BPE)仍可直接应用于中文。它们以汉字为基本单位,通过学习语料中高频的字组合(如"自然"、"语言"、"处理"),自动构建子词词表。这种方式无需人工词典,具有较强的适应能力。
在当前主流的中文大模型(如通义千问、DeepSeek)中,子词分词已成为广泛采用的文本切分策略。
1.1.3 jieba分词库
"结巴"分词是中文分词领域中应用广泛的开源工具之一,具有接口简洁、模式灵活、词典可扩展等特点,在各类传统 NLP 任务中依然具备良好的实用价值。
1.1.3.1 精确模式(默认模式)
精确模式分词可使用jieba.cut或者jieba.lcut方法,前者返回一个生成器对象,后者返回一个list。具体代码如下:
python
import jieba
text = "小明毕业于北京大学计算机系"
words_generator = jieba.cut(text) # 返回一个生成器
for word in words_generator:
print(word)
words_list = jieba.lcut(text) # 返回一个列表
print(words_list)输出

1.1.3.2 全模式
全模式分词可使用jieba.cut或者jieba.lcut,并将cut_all参数设置为True,具体代码如下:
python
import jieba
text = "小明毕业于北京大学计算机系"
words_generator = jieba.cut(text, cut_all=True) # 返回一个生成器
for word in words_generator:
print(word)
words_list = jieba.lcut(text, cut_all=True) # 返回一个列表
print(words_list)输出

1.1.3.3 搜索引擎模式
可使用jieba.cut_for_search或者jieba.lcut_for_search,具体代码如下:
python
import jieba
text = "小明毕业于北京大学计算机系"
words_generator = jieba.cut_for_search(text) # 返回一个生成器
for word in words_generator:
print(word)
words_list = jieba.lcut_for_search(text) # 返回一个列表
print(words_list)输出

1.1.3.4 自定义词典模式
- 使用用户自定义词典
- 添加自定义词典后,jieba能够准确识别词典中出现的词汇,从而提升整体的识别准确率
- 词典格式:每一行分三部分:词语、词频、词性,用空格隔开,顺序不可颠倒
在项目根目录创建一个文件:userdict.txt ,内容如下:
text
火锅底料 5 n
我讲礼貌 6 n
拿去比较 7 nz代码
python
import jieba
# 原始句子
sentence = """老子吃火锅 你吃火锅底料 火锅底料
对你笑呵呵 因为我讲礼貌 我讲礼貌
狠货有好多 个人拿去比较 拿去比较"""
# === 情况1:不使用自定义词典 ===
print("【未加载自定义词典】")
mydata = jieba.lcut(sentence, cut_all=False)
print('mydata -->', mydata)
# === 情况2:加载自定义词典后分词 ===
# 加载用户词典(确保路径正确)
jieba.load_userdict("./userdict.txt")
print("\n【加载自定义词典后】")
mydata2 = jieba.lcut(sentence, cut_all=False)
print('mydata2 -->', mydata2)输出

1.2 词性标注(★)
词性标注是指:给句子中的每个词赋予一个对应的词性标签,比如名词(Noun)、动词(Verb)、形容词(Adjective)、副词(Adverb)等。
jieba词性标注案例:
python
import jieba.posseg as pseg
# 输入句子
sentence = "小明在清华大学学习人工智能,他非常喜欢自然语言处理。"
# 使用 jieba 的 posseg 模块进行分词 + 词性标注
words = pseg.cut(sentence)
# 打印结果
for word, flag in words:
print(f"{word}\t{flag}")jieba 词性标注对照表(基于 ICTCLAS 标准)
| 标签 | 中文名称 | 英文解释 | 示例 |
|---|---|---|---|
| Ag | 形语素 | Adjective morpheme | (如"美"在"美丽"中) |
| a | 形容词 | Adjective | 美丽、高效、绿色 |
| ad | 副形词 | Adjective as adverbial | 突然("他突然出现") |
| an | 名形词 | Adjective as noun | 创新("推动创新") |
| b | 区别词 | Distinguisher | 男、女、大型、初级 |
| c | 连词 | Conjunction | 和、但是、如果 |
| d | 副词 | Adverb | 非常、已经、马上 |
| df | 趋向副词 | Directional adverb | 上、下、进来、出去 |
| dg | 副语素 | Adverbial morpheme | (构词语素,较少单独出现) |
| e | 叹词 | Interjection | 哎呀、哦、嗯 |
| f | 方位词 | Locative noun | 上、下、左边、中间 |
| g | 语素 | Morpheme (general) | (多用于未登录词语素) |
| h | 前接成分 | Prefix | 阿(阿明)、老(老虎) |
| i | 成语 | Idiom | 画龙点睛、一举两得 |
| j | 简称略语 | Abbreviation | 北大、GDP、WTO |
| k | 后接成分 | Suffix | 子(桌子)、头(石头) |
| l | 习用语 | Fixed expression | 换句话说、总而言之 |
| m | 数词 | Numeral | 三、一百、2025 |
| n | 普通名词 | Common noun | 苹果、技术、想法 |
| ng | 名语素除 | Noun morpheme | (如"民"在"人民"中) |
| nr | 人名 | Proper noun -- person | 小明、李白、张伟 |
| ns | 地名 | Place name | 北京、杭州湾、亚洲 |
| nt | 机构团体名 | Organization | 清华大学、联合国、腾讯 |
| nz | 其他专有名词 | Other proper noun | 人工智能、区块链、iPhone |
| o | 拟声词 | Onomatopoeia | 哗啦、咚咚、喵喵 |
| p | 介词 | Preposition | 在、从、关于、对于 |
| q | 量词 | Quantifier / Measure word | 个、次、公斤、年 |
| r | 代词 | Pronoun | 他、我们、自己、什么 |
| s | 处所词 | Space/Location word | 附近、周围、这里 |
| t | 时间词 | Time word | 今天、昨天、2025年 |
| tg | 时间语素 | Time morpheme | (如"春"在"春天"中) |
| u | 助词 | Auxiliary particle | 的、了、着、过、吗 |
| v | 动词 | Verb | 学习、喜欢、运行 |
| vd | 副动词 | Verb as adverbial | 互相、努力("努力学习") |
| vg | 动语素 | Verb morpheme | (如"学"在"学习"中) |
| vi | 不及物动词 | Intransitive verb | 睡觉、咳嗽 |
| vn | 名动词 | Verb as noun | 研究、发展、投资 |
| vq | 趋向动词 | Directional verb | 上来、下去、进去 |
| w | 标点符号 | Punctuation | ,。!?;:""''()【】 |
| x | 非语素字 / 未知词 | Non-morpheme / Unknown | 字母、数字、乱码、表情符号 |
| y | 语气词 | Modal particle | 吗、呢、吧、啊 |
| z | 状态词 | Status word | 雪白、通红、冰凉 |
1.3 命名实体识别(★)
放洋屁叫做"Named Entity Recognition,简称NER"
- 命名实体: 通常我们将人名, 地名, 机构名等专有名词统称命名实体. 如: 周杰伦, 黑山县, 孔子学院, 24辊方钢矫直机.
- 顾名思义, 命名实体识别(Named Entity Recognition,简称NER)就是识别出一段文本中可能存在的命名实体.## 1.2 文本张量表示
案例:
鲁迅, 浙江绍兴人, 五四新文化运动的重要参与者, 代表作朝花夕拾.
==>
鲁迅(人名) / 浙江绍兴(地名)人 / 五四新文化运动(专有名词) / 重要参与者 / 代表作 / 朝花夕拾(专有名词)
同词汇一样, 命名实体也是人类理解文本的基础单元, 因此也是AI解决NLP领域高阶任务的重要基础环节.
1.4 窗口
什么是
"窗口"(Window)在自然语言处理(NLP)中,尤其是在词向量模型(如 Word2Vec 的 CBOW 和 Skip-gram)中,是一个非常核心的概念。
窗口(Context Window) 是指:
在一个句子中,围绕目标词(中心词)的一段局部上下文范围,通常用一个固定长度的"滑动窗口"来定义。
这个窗口决定了:哪些词会被当作当前词的"上下文"(context words)。
·
✅ 举个例子 🌰
假设有一句话:
"愿你自由成长"
我们把每个字看作一个词(为简化),词汇序列是:
愿, 你, 自, 由, 成, 长
情况1:以"自"为中心词(target word)
- 向左看 2 个词:愿, 你
- 向右看 2 个词:由, 成
- 所以上下文词是:愿, 你, 由, 成
💡 注意:如果靠近句首或句尾,窗口会自动截断(比如"愿"左边没词,就只取右边)。
情况2:以"你"为中心词
- 左边1个:愿
- 右边2个:自, 由
- 上下文:愿, 自, 由(因为左边不够2个)
✅ 窗口大小怎么选?
- 小窗口(如 1~2):
捕捉语法/局部结构(比如"strong tea"、"make decision") - 大窗口(如 5~10):
捕捉语义/主题相似性(比如"car"和"drive"、"engine"可能出现在较远位置)
Word2Vec 论文中常用窗口大小为 5~10。

为什么
- 不是所有词都和当前词相关(比如相隔很远的词可能无关)
- 降低计算复杂度:不用考虑整句
- 符合语言局部性假设:一个词的含义主要由其邻近词决定("You shall know a word by the company it keep s" --- J.R. Firth)
3. 文本张量表示
3.1 one-hot
✅ 定义
将每个词表示为一个长度等于词汇表大小的二进制向量,只有一个位置是 1,其余都是 0。
🧪 示例
假设词汇表:"我", "爱", "猫", "狗",共 4 个词。
- "我" → 1, 0, 0, 0
- "爱" → 0, 1, 0, 0
- "猫" → 0, 0, 1, 0
- "狗" → 0, 0, 0, 1
🌟 生动比喻
想象你有 4 个抽屉,每个抽屉放一个词。
当你说"我",就打开第一个抽屉,其他都关着。
这就是 one-hot ------只亮一个灯!
⚠️ 缺点
- 维度爆炸(词汇表大时向量很长)
- 无法表达语义相似性:比如"猫"和"狗"在向量中距离很远,但它们都是动物!
- ❌ "猫"和"狗"在 one-hot 中完全不相关!
代码案例
python
# 导包
# 1.准备数据
vocabs = ["周杰伦", "陈奕迅", "王力宏", "李宗盛", "鹿晗", '邓超']
# 2.构建词表
word2index = {name: i for i, name in enumerate(vocabs)}
print(word2index)
# 3.开始one-hot编码
for name in vocabs:
# 初始化一行全0的列表
zero_list = [0] * len(vocabs)
# 同时设置name对应位置为1
name_idx = word2index[name]
zero_list[name_idx] = 1
print(f"{name}的one-hot编码是:{zero_list}")3.1.1 Tokenizer
✅ 作用
把原始文本切分成基本单位(token),供模型处理。
🧩 不同语言不同策略
| 语言 | 分词方式 |
|---|---|
| 英文 | 空格分词 ("I love NLP" → "I", "love", "NLP") |
| 中文 | 需要分词工具 (jieba, HanLP) |
| 其他 | 有些用字符级(如 BERT) |
⚠️ 重要性
- 分词错误 → 向量化失败 → 模型学不到东西
- 所以:Tokenizer 是 NLP 的第一道关口
代码案例
python
import jieba
# 导入keras中的词汇映射器Tokenizer : pip install tensorflow
from tensorflow.keras.preprocessing.text import Tokenizer
# 导入用于对象保存与加载的joblib
import joblib
# 思路分析 生成onehot
# 1 准备语料 vocabs
# 2 实例化词汇映射器Tokenizer, 使用映射器拟合现有文本数据 (内部生成 index_word word_index)
# 2-1 注意idx序号-1
# 3 查询单词idx 赋值 zero_list,生成onehot
# 4 使用joblib工具保存映射器 joblib.dump()
def dm_onehot_gen():
# 1 准备语料 vocabs
vocabs = {"周杰伦", "陈奕迅", "王力宏", "李宗盛", "吴亦凡", "鹿晗"}
# 2 实例化词汇映射器Tokenizer, 使用映射器拟合现有文本数据 (内部生成 index_word word_index)
# 2-1 注意idx序号-1
mytokenizer = Tokenizer()
mytokenizer.fit_on_texts(vocabs)
# 3 查询单词idx 赋值 zero_list,生成onehot
for vocab in vocabs:
zero_list = [0] * len(vocabs)
idx = mytokenizer.word_index[vocab] - 1
zero_list[idx] = 1
print(vocab, '的onehot编码是', zero_list)
# 4 使用joblib工具保存映射器 joblib.dump()
mypath = './mytokenizer'
joblib.dump(mytokenizer, mypath)
print('保存mytokenizer End')
# 注意5-1 字典没有顺序 onehot编码没有顺序 []-有序 {}-无序 区别
# 注意5-2 字典有的单词才有idx idx从1开始
# 注意5-3 查询没有注册的词会有异常 eg: 狗蛋
print(mytokenizer.word_index)
print(mytokenizer.index_word)
# 思路分析
# 1 加载已保存的词汇映射器Tokenizer joblib.load(mypath)
# 2 查询单词idx 赋值zero_list,生成onehot 以token为'李宗盛'
# 3 token = "狗蛋" 会出现异常
def dm_onehot_use():
vocabs = {"周杰伦", "陈奕迅", "王力宏", "李宗盛", "吴亦凡", "鹿晗"}
# 1 加载已保存的词汇映射器Tokenizer joblib.load(mypath)
mypath = './mytokenizer'
mytokenizer = joblib.load(mypath)
# 2 编码token为"李宗盛" 查询单词idx 赋值 zero_list,生成onehot
token = "李宗盛"
zero_list = [0] * len(vocabs)
idx = mytokenizer.word_index[token] - 1
zero_list[idx] = 1
print(token, '的onehot编码是', zero_list)
if __name__ == '__main__':
# 函数不调用不执行
dm_onehot_gen()
dm_onehot_use()3.2 word2vec(★)
✅ 目标
解决 one-hot 的问题:让相似词在向量空间中靠得近。
例如:"猫"和"狗"应该离得很近,"吃"和"喝"也该靠近。
🤔 原理
基于一个简单假设:
上下文决定词义 ------ 出现在相同语境中的词,意义相近。
它有两种方式:CBOW 和 skip-gram
3.2.1 CBOW(★)
CBOW(Continuous Bag of Words)
用上下文预测中心词
输入:我, 爱, 狗 → 预测中间词:"爱"
👉 就像你在玩"猜词游戏":看到"我"和"狗",你能猜出中间可能是"爱"或"养"。
代码案例
python
import torch
import torch.nn as nn
# 语料(一句话)
text = "I like NLP and I like coding".split()
# 构建词表
vocab = list(set(text))
word_to_idx = {w: i for i, w in enumerate(vocab)}
idx_to_word = {i: w for i, w in enumerate(vocab)}
vocab_size = len(vocab)
print("词表:", vocab)
# 超参数
embed_dim = 5
window = 2
# 准备训练数据:(上下文, 目标词)
data = []
for i in range(window, len(text) - window):
context = [text[i - 2], text[i - 1], text[i + 1], text[i + 2]]
target = text[i]
data.append((context, target))
# 模型
class CBOW(nn.Module):
def __init__(self, vocab_size, embed_dim):
super().__init__()
self.embed = nn.Embedding(vocab_size, embed_dim)
self.proj = nn.Linear(embed_dim, vocab_size)
def forward(self, ctx_idxs):
emb = self.embed(ctx_idxs) # [4, embed_dim]
avg = torch.mean(emb, dim=0) # [embed_dim]
out = self.proj(avg) # [vocab_size]
return out
model = CBOW(vocab_size, embed_dim)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
# 训练
for epoch in range(200):
total_loss = 0
for ctx, tgt in data:
ctx_ids = torch.tensor([word_to_idx[w] for w in ctx])
tgt_id = torch.tensor([word_to_idx[tgt]])
optimizer.zero_grad()
output = model(ctx_ids)
loss = criterion(output.unsqueeze(0), tgt_id)
loss.backward()
optimizer.step()
total_loss += loss.item()
if epoch % 50 == 0:
print(f"Epoch {epoch}, Loss: {total_loss:.2f}")
# 查看词向量
print("\n学到的词向量(每个词的向量):")
with torch.no_grad():
for word in vocab:
vec = model.embed.weight[word_to_idx[word]]
print(f"{word}: {vec.numpy().round(2)}")3.2.2 skip-gram(★)
用中心词预测上下文
输入:中心词"爱" → 预测上下文:"我"、"狗"
👉 就像你读了一句话:"我爱狗",然后问自己:"'爱'这个词通常跟哪些词一起出现?"
✅ 实际中,skip-gram 效果更好,尤其对低频词。
python
import torch
import torch.nn as nn
# 语料(一句话)
text = "I like NLP and I like coding".split()
# 构建词表
vocab = list(set(text))
word_to_idx = {w: i for i, w in enumerate(vocab)}
idx_to_word = {i: w for i, w in enumerate(vocab)}
vocab_size = len(vocab)
print("词表:", vocab)
# 超参数
embed_dim = 5
window = 2
# 准备训练数据:(中心词, 上下文词) ------ 一个中心词对应多个上下文
data = []
for i in range(window, len(text) - window):
center = text[i]
for j in [i - 2, i - 1, i + 1, i + 2]:
context = text[j]
data.append((center, context))
# 模型:输入中心词,输出预测的上下文词
class SkipGram(nn.Module):
def __init__(self, vocab_size, embed_dim):
super().__init__()
self.embed = nn.Embedding(vocab_size, embed_dim)
self.proj = nn.Linear(embed_dim, vocab_size)
def forward(self, center_idx):
emb = self.embed(center_idx) # [embed_dim]
out = self.proj(emb) # [vocab_size]
return out
model = SkipGram(vocab_size, embed_dim)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
# 训练
for epoch in range(200):
total_loss = 0
for center, context in data:
center_id = torch.tensor([word_to_idx[center]])
context_id = torch.tensor([word_to_idx[context]])
optimizer.zero_grad()
output = model(center_id)
loss = criterion(output, context_id)
loss.backward()
optimizer.step()
total_loss += loss.item()
if epoch % 50 == 0:
print(f"Epoch {epoch}, Loss: {total_loss:.2f}")
# 查看学到的词向量
print("\n学到的词向量(每个词的向量):")
with torch.no_grad():
for word in vocab:
vec = model.embed.weight[word_to_idx[word]]
print(f"{word}: {vec.numpy().round(2)}")3.3 word embedding(★)
✅ 定义
word embedding 是一个广义术语,指将词语映射为连续向量的过程。
所以:word2vec 是一种实现 word embedding 的方法。
🧠 举个栗子
"国王" - "男人" ≈ "女王" - "女人"
在 embedding 空间中,这个等式成立!
→ 说明模型学到了性别、角色的关系。
代码案例
python
import torch
import torch.nn as nn
# 1. 准备语料(一句话)
sentence = "I love natural language processing".split()
print("句子:", sentence)
# 2. 构建词表(含 <PAD> 和 <UNK> 更规范,这里简化)
vocab = ["<PAD>"] + list(set(sentence)) # 加一个填充符(可选)
word_to_idx = {word: i for i, word in enumerate(vocab)}
idx_to_word = {i: word for i, word in enumerate(vocab)}
vocab_size = len(vocab)
embed_dim = 8 # 每个词用 8 维向量表示
print("\n词表:", vocab)
print("词到索引:", word_to_idx)
# 3. 创建 Embedding 层(随机初始化词向量)
embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=embed_dim)
# 4. 把句子转成索引
input_ids = torch.tensor([word_to_idx[word] for word in sentence])
print("\n输入索引:", input_ids.tolist())
# 5. 获取词向量
word_vectors = embedding(input_ids) # shape: [seq_len, embed_dim]
print("\n词向量形状:", word_vectors.shape)
print("第一个词 'I' 的向量:\n", word_vectors[0].detach().numpy().round(3))3.4 fasttext(★)
✅ 由 Facebook 提出,扩展了 word2vec
🎯 特色功能
-
支持子词(subword)
→ 把词拆成更小单元,比如 "unhappy" → "un", "happ", "y"
-
特别适合稀疏词和拼写错误
→ 即使没见过"unhappiness",也能根据"un", "happ"推测含义
中文也适用(虽然不如英文明显)
🌟 举个例子
"跑步" → 可分解为 "跑" + "步"
即使没学过"跑步",只要见过"跑"和"步",就能理解
✅ fasttext 在低资源语言和拼写纠错场景中表现优异!
window系统安装指令
python
pip install fasttext-wheel3.6 小结
| 方法 | 是否稠密 | 能否表达语义 | 是否考虑上下文 | 适合场景 |
|---|---|---|---|---|
| one-hot | ❌ 稀疏 | ❌ 完全不行 | ❌ 不考虑 | 初学者、小数据集 |
| word2vec | ✅ 稠密 | ✅ 很好 | ✅ 强依赖 | 大规模文本、语义分析 |
| fasttext | ✅ 稠密 | ✅ 更强(子词) | ✅ 强依赖 | 拼写错误、罕见词、多语言 |
扩展:画图 - Transorboard
4. 文本数据分析
4.1词云
"词云"不是什么魔法,它是把文本中出现频率高的词,用大小不一的字体展示出来------字越大,越热门!
✅ 举个例子:
你写了一篇关于"人工智能"的文章,生成词云后发现:"深度学习"、"模型"、"数据"这几个词特别大,说明它们是核心话题。
💡 实现思路(简化版):
python
from wordcloud import WordCloud
import matplotlib.pyplot as plt
text = "人工智能 机器学习 深度学习 自然语言处理"
# Windows 中文黑体路径(几乎每台 Windows 都有)
font_path = "C:/Windows/Fonts/simhei.ttf"
wordcloud = WordCloud(
font_path=font_path,
background_color='white',
width=800,
height=400
).generate(text)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()输出

🧠 小贴士:词云常用于文本分析可视化,比如社交媒体情绪分析、用户评论挖掘等。
4.2 回顾API(★)
4.2.1 可变参数,可变参数键值对(★)
python
def demo(*args, **kwargs):
print("args:", args) # 位置参数 → 元组
print("kwargs:", kwargs) # 关键字参数 → 字典
demo(1, 2, name="Alice", age=25)4.2.2 join()
把列表拼成字符串 → 字符串
python
",".join(['a', 'b', 'c']) # "a,b,c"4.2.3 split()
把字符串按分隔符切开 → 列表
python
"a,b,c".split(",") # ['a', 'b', 'c']4.2.4 set和list
set 无序,去重神器
list 有序,可重复
python
lst = [1, 2, 2, 3]
s = set(lst) # {1, 2, 3}4.2.5 推导式
把循环写成一行,提升效率
python
# 普通方式
squares = []
for i in range(5):
squares.append(i**2)
# 推导式(更 Pythonic)
squares = [i**2 for i in range(5)]4.2.6 生成器
不是一次性全算完,而是边走变算,节省内存。适合处理大数据流,比如读取超大文件时进行逐行处理
python
def my_gen():
yield 1
yield 2
yield 3
g = my_gen()
next(g) # 1
next(g) # 24.2.7chain
将多个对象"连接起来"当一个使用
python
from itertools import chain
lists = [[1, 2], [3, 4], [5]]
flat = list(chain(*lists)) # [1, 2, 3, 4, 5]4.2.8 zip打包和zip解包
将两个列表"拉链式"配对,常用于数据对齐、批量处理
python
names = ["张三", "李四"]
scores = [90, 85]
# 打包:配对
for name, score in zip(names, scores):
print(f"{name}: {score}")
# 解包:还原
unzipped = zip(*zip(names, scores))4.2.9 map与lambda
map 对每个元素"统一加工"
lambda 简单计算就用它
python
numbers = [1, 2, 3]
squared = list(map(lambda x: x**2, numbers)) # [1, 4, 9]⚠️ 注意:map() 返回的是 map 对象,需要 list() 转换。
💡 lambda 通常和 map, filter, sorted 一起用
4.2.10 列表拼接extend 和 +
会修改原列表
python
a = [1, 2]
b = [3, 4]
# 方法1:+
c = a + b
# 方法2:extend(原地修改)
a.extend(b)
# 方法3:*解包
d = [*a, *b]4.2.11 串联为一行代码
⚠️ 提醒:别为了"一行"牺牲可读性,适度才是王道!
python
# 传统写法
result = []
for i in range(10):
if i % 2 == 0:
result.append(i**2)
print(result)
# 一行搞定(推导式 + 条件)
print([i**2 for i in range(10) if i % 2 == 0])
# 用 lambda + map + filter
print(list(map(lambda x: x**2, filter(lambda x: x % 2 == 0, range(10)))))4.2.12 seaborn
Seaborn 是建立在 Matplotlib 之上的"高级画笔"------它把枯燥的数据绘图变成像杂志封面一样精致的图表。你可以把它想象成一个"视觉设计师",专为统计分析量身定制。
它特别擅长处理数据框(DataFrame),支持自动配色、样式美化和统计模型可视化。
🔧 核心特点
- 基于 Pandas DataFrame
- 内置主题和调色板
- 支持常见统计图:热力图、箱线图、散点图、回归图等
- 与 matplotlib 兼容
代码
python
import seaborn as sns
import matplotlib.pyplot as plt
# 加载内置数据集
iris = sns.load_dataset("iris")
# 设置绘图风格(可选)
sns.set(style="whitegrid")
# 1. 散点图 + 分类颜色(pairplot 自动分组)
sns.pairplot(iris, hue="species")
plt.show()
# 2. 相关性热力图
plt.figure(figsize=(8, 6))
sns.heatmap(iris.corr(), annot=True, cmap="coolwarm", center=0)
plt.title("Iris 特征相关性热力图")
plt.show()4.3 文本数据分析案例
4.3.1 情感分析
情感分析是一种自然语言处理技术,用来判断一段文字的情绪倾向,比如:
- 正面(开心)✅
- 负面(生气)❌
- 中性(无感)😐
💡 举个例子:
输入:"这部电影太棒了,演员演技炸裂!"
输出:"情感:正面,置信度:0.98"
4.3.2 案例流程
1)获取标签数量分布
2)获取句子长度分布
3)获取正负样本长度散点分布
4)获取不同词汇总数统计
5)获取训练集高频形容词词云
6)获取验证集形容词词云
python
# -*- coding: utf-8 -*-
import re
import jieba # 分词工具(需先安装:pip install jieba)
from collections import Counter
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import numpy as np
# ================================
# 📌 模拟数据:训练集和验证集评论(中文)
# ================================
train_texts = [
"这部电影太好看了,演员演技很棒,剧情也很精彩。",
"我觉得一般般,节奏有点慢,但音乐不错。",
"非常推荐!特效震撼,导演功力深厚。",
"无聊透顶,浪费时间,完全不值得一看。",
"画面很美,情感真挚,看完哭了。"
]
val_texts = [
"这部剧太燃了,看得我热血沸腾!",
"平平无奇,没有亮点,建议别看。",
"剧情反转太多,有点混乱,但还算好看。",
"演员表现不错,可惜剧本拖沓。",
"太感人了,是我今年看过最好的电影。"
]
# 标签:正面 / 负面 / 中性
train_labels = ['正面', '中性', '正面', '负面', '正面']
val_labels = ['正面', '负面', '中性', '中性', '正面']
# ================================
# 🔹 1. 获取标签数量分布
# ================================
print("=== 1. 标签数量分布 ===")
label_count = Counter(train_labels)
print(label_count)
# 可视化
plt.figure(figsize=(6, 4))
plt.bar(label_count.keys(), label_count.values())
plt.title("训练集标签分布")
plt.ylabel("数量")
plt.show()
# ================================
# 🔹 2. 获取句子长度分布
# ================================
print("\n=== 2. 句子长度分布 ===")
sentence_lengths = [len(text) for text in train_texts]
print(f"长度列表: {sentence_lengths}")
# 绘制直方图
plt.figure(figsize=(8, 5))
plt.hist(sentence_lengths, bins=5, edgecolor='black')
plt.title("训练集句子长度分布")
plt.xlabel("字符数")
plt.ylabel("频次")
plt.show()
# ================================
# 🔹 3. 获取正负样本长度散点分布
# ================================
print("\n=== 3. 正负样本长度散点分布 ===")
positive_lengths = [len(text) for text, label in zip(train_texts, train_labels) if label == '正面']
negative_lengths = [len(text) for text, label in zip(train_texts, train_labels) if label == '负面']
print(f"正面样本长度: {positive_lengths}")
print(f"负面样本长度: {negative_lengths}")
# 散点图
plt.figure(figsize=(8, 5))
plt.scatter(range(len(positive_lengths)), positive_lengths, color='green', label='正面')
plt.scatter(range(len(negative_lengths)), negative_lengths, color='red', label='负面')
plt.title("正负样本句子长度对比")
plt.xlabel("样本序号")
plt.ylabel("句子长度")
plt.legend()
plt.show()
# ================================
# 🔹 4. 获取不同词汇汇总统计
# ================================
print("\n=== 4. 不同词汇汇总统计 ===")
# 使用 jieba 进行中文分词
all_words = []
for text in train_texts + val_texts:
words = jieba.lcut(text) # 分词
all_words.extend(words)
# 去除停用词(可选)
stopwords = {'的', '了', '是', '在', '我', '有', '这', '就', '也', '很', '都', '一', '个'}
filtered_words = [word for word in all_words if word not in stopwords and len(word) > 1]
# 统计词频
word_freq = Counter(filtered_words)
print("前10高频频词:")
for word, freq in word_freq.most_common(10):
print(f"{word}: {freq}")
# ================================
# 🔹 5. 获取训练集/验证集形容词词云
# ================================
print("\n=== 5. 形容词词云 ===")
# 提取形容词(简单规则:常见形容词列表)
adjectives = {
'好', '棒', '精彩', '震撼', '燃', '感人', '无聊', '差', '一般', '普通',
'优秀', '出色', '失望', '失望', '失望', '感动', '喜欢', '讨厌', '推荐'
}
# 提取训练集中的形容词
train_adjectives = [word for word in filtered_words if word in adjectives]
train_text = " ".join(train_adjectives)
# 提取验证集中的形容词
val_adjectives = [word for word in jieba.lcut(" ".join(val_texts)) if word in adjectives]
val_text = " ".join(val_adjectives)
# 设置字体路径(Windows 示例)
font_path = "C:/Windows/Fonts/simhei.ttf" # 修改为你的系统路径!
# 生成词云
plt.figure(figsize=(12, 5))
# 训练集词云
plt.subplot(1, 2, 1)
wc_train = WordCloud(font_path=font_path, background_color='white').generate(train_text)
plt.imshow(wc_train, interpolation='bilinear')
plt.axis("off")
plt.title("训练集形容词词云")
# 验证集词云
plt.subplot(1, 2, 2)
wc_val = WordCloud(font_path=font_path, background_color='white').generate(val_text)
plt.imshow(wc_val, interpolation='bilinear')
plt.axis("off")
plt.title("验证集形容词词云")
plt.tight_layout()
plt.show()5. 文本特征处理
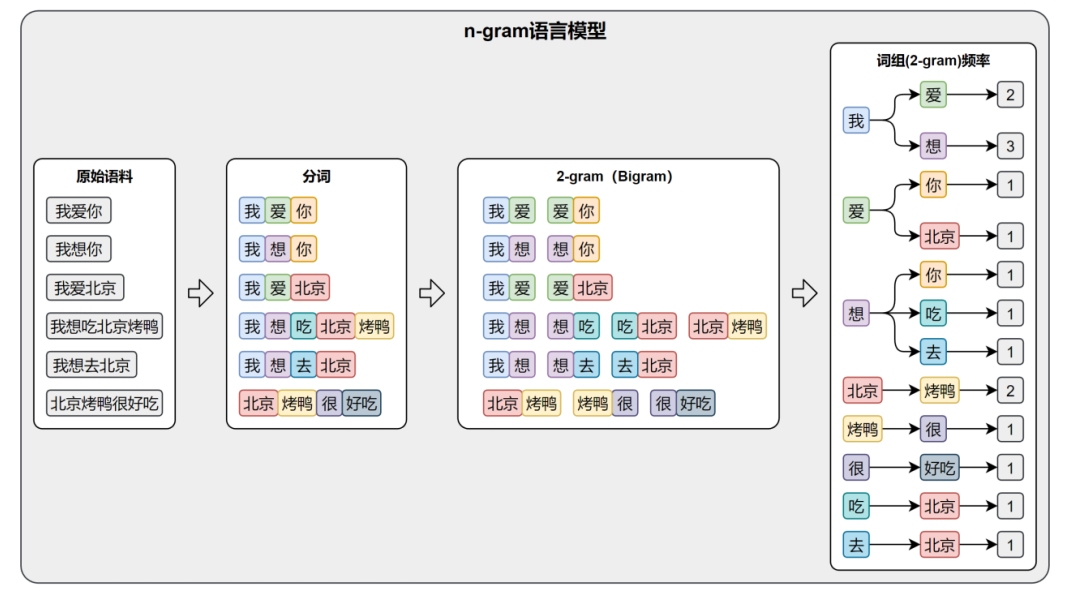
5.1 n-gram(★)
定义:n-gram 是一种基于统计的语言模型,通过计算连续 n 个词(或字)共同出现的概率,来建模语言的规律。
想象你是个刚学说话的小孩,只会听大人讲话,但还不懂语法。
有一天你听到大人说:
"今天天气真__。"
你会猜下一个词是什么?
"好"?"差"?"热"?......大概率不会是"冰箱"或"火箭"对吧?
为什么?因为你潜意识里记住了"天气真"后面常跟什么词------这就是 n-gram 的核心思想!
🔢 具体例子:
- 1-gram(unigram):只看单个词。
→ "好" 出现很多次,所以概率高。但它完全不管上下文!(太孤僻) - 2-gram(bigram):看两个词的组合。
→ "天气 真" → 下一个词很可能是"好"。
模型会记录:"真" 后面接 "好" 的频率特别高。 - 3-gram(trigram):看三个词。
→ "今天 天气 真" → 更准!可能90%后面是"好",5%是"热",剩下乱码忽略。
💡 所以:n 越大,上下文越丰富,预测越准------但代价是数据稀疏(很多组合根本没见过)!
🛠️ 它能干啥?(应用场景)
输入法预测:你打"人工",它弹出"智能"------背后就是 bigram/trigram 在算概率。
拼写纠错:"我吃苹国" → "苹国"很少和"吃"一起出现,但"苹果"很常见 → 自动纠正。
早期机器翻译 & 语音识别:用 n-gram 评估哪句话更"像人话"。
文本生成(原始版):给定开头,不断选概率最高的下一个词------虽然容易跑偏成"天气真好好好好......"
⚠️ 小缺点 :
短视:n=5 也就看5个词,长距离依赖搞不定(比如指代:"小明...他...")。
数据饥渴:要覆盖所有 n-gram,语料库得超级大,否则全是"零概率"。
没理解语义:它只知道"猫吃鱼"常见,但不知道猫为啥不吃石头 😅
✅ 所以后来有了 RNN、Transformer------它们才是"读心高手"。但 n-gram?是它们的启蒙老师!
📝 小结(板书重点):
| 名称 | 看几个词 | 优点 | 缺点 |
|---|---|---|---|
| unigram | 1 | 简单 | 忽略上下文 |
| bigram | 2 | 能抓局部搭配 | 长程关系不行 |
| trigram+ | 3+ | 更准 | 数据稀疏、计算量大 |
硅谷的图:描述的是2-gram语言模型
6. 文本数据增强
6.1 回译数据增强法
回译(Back-Translation) 是一种常用的文本数据增强技术,通过将源语言句子翻译成另一种语言,再翻译回来,从而生成语义相近但表达不同的新句子。
原始中文:我爱人工智能
→ 翻译成英文:I love artificial intelligence
→ 再翻译回中文:我喜欢人工智能
👉 得到一个同义但不同表达的新样本!
💡 为什么有效?
- 保留原意(因为是来回翻译)
- 改变措辞(如"爱" → "喜欢")
- 扩充训练数据,提升模型泛化能力
- 特别适合小样本 NLP 任务(如情感分析、命名实体识别)
缺点是翻译过程中会产生损失
在"中文 → 英文 → 中文"的过程中,可能出现:
| 原句 | 回译结果 | 问题 |
|---|---|---|
| "他打了电话。" | "He made a call." → "他打了一个电话。" | ✅ 可接受(轻微变化) |
| "苹果发布了新 iPhone。" | "Apple released a new iPhone." → "苹果公司推出了一款新的 iPhone。" | ✅ 信息保留 |
| "我有点不舒服。" | "I feel a little unwell." → "我觉得不太舒服。" | ⚠️ 语气弱化 |
| "禁止吸烟!" | "No smoking!" → "不要吸烟。" | ❌ 语气丢失、指令弱化 |
| "张三涉嫌贪污。" | "Zhang San is suspected of embezzlement." → "张三被怀疑有贪污行为。" | ❌ 法律语义模糊化 |
📉 这种语义偏移、细节丢失、语气弱化,就是 回译损失(Back-Translation Noise / Semantic Drift)。
✅ 那么,如何解决或缓解这种损失?
方法一:✅ 人工筛选 + 质量过滤(最可靠)
- 对回译结果做置信度评分
- 使用 BLEU、BERTScore、COMET 等指标衡量与原文的相似度
- 设定阈值,只保留高相似度样本
python
from bert_score import score
def is_high_quality(original, back_translated, threshold=0.85):
P, R, F1 = score([back_translated], [original], lang="zh", verbose=False)
return F1.item() > threshold
# 示例
if is_high_quality("禁止吸烟!", "不要吸烟。"):
print("保留")
else:
print("丢弃") # 实际会丢弃,因为语义强度变了💡 适用场景:小规模高质量数据增强(如医疗、法律 NLP)
方法二:🔄 多语言回译 + 投票融合
不只用"中→英→中",而是走多条路径:
中文
→ 英文 → 中文
→ 法文 → 中文
→ 日文 → 中文
然后:
- 保留出现多次的回译结果
- 或取语义最接近原始句的版本
🌐 利用不同语言的表达习惯"互相校正"
| 任务类型 | 是否建议回译 |
|---|---|
| 情感分析(正面/负面) | ✅ 可用(只要极性不变) |
| 医疗诊断文本分类 | ⚠️ 谨慎 |
| 法律条款识别 | ❌ 不建议 |
| 命名实体识别(NER) | ✅ 可用(实体通常保留) |
| 问答系统(答案生成) | ❌ 高风险 |
方法三:🚫 避免在敏感任务中使用回译
有些任务绝对不能容忍语义损失:
📌 原则:如果任务对精确语义、语气、否定词、程度副词敏感,慎用回译!
✅ 一句话总结:
回译确实会带来语义损失,但我们可以通过"质量过滤 + 多路径校验 + 大模型修正 + 任务适配"来有效控制它,让它从"有损压缩"变成"智能扩增"。
补充内容
tensorboard
seaborn
pyecharts