原文发表在知乎,辛苦移步:《RLinf强化学习框架试用》
最近一直在看强化学习算法,跑起来的demo模型都很小,(例如:《具身智能hil-serl强化学习算法在lerobot机械臂上复现》)所以可以在单机上很容易跑起来。但针对具身智能的VLA模型,可能动辙就是几个B的参数量,如果只是模仿学习的话,也有很多分布式训练框架,例如deepspeed, fsdp等可很方便的引入,这样多卡/多机训练也很简单。但对于强化学习训练,涉及的模块较多,最常见的在仿真环境中训练,就要与仿真环境进行交互(rollout),又要对较大的VLA模型进行同步训练,复杂性会较高,所以一个基础设施(inf)就会比较重要了。
RLinf就是这么一个基础设施,它内部已经封装好了一些仿真环境,例如libero/maniskill,也封装好了一些经典的VLA模型,例如openvla/openvla-oft/π 0/π 0.5(pi0/pi0.5)等,同时也封装了主流的强化学习算法,如PPO/GRPO。RLinf是清华大学今年9月份刚推出的一个框架,最新的πRL(piRL)方案的代码实现也是基于RLinf框架,笔者深入的研究并试用了一下此框架,过程记录如下。
一些介绍的文档链接:
RLinf官方文档:https://rlinf.readthedocs.io/zh-cn/latest/rst_source/tutorials/user/yaml.html
RLinf介绍:统一高效VLA+RL训练平台RLinf-VLA!
mainskill仿真:【免费下载】 ManiSkill 机器人仿真环境快速入门指南, ManiSkill - ManiSkill 3.0.0b22 documentation
安装
安装文档:链接,硬件条件:官方测试的比较充分的是8个H100的环境。硬件依赖较高,对学习者不友好。笔者在云端算力平台(gpufree平台)上可以稳定的跑起来,所使用的环境是6个L40显卡,每个显存48G,内存共120*6=720G。其实笔者测试的openvla-oft是一个7B的模型,如果用lora微调的话(配置已打开),一个24G的显存的显卡就够了,但不太清楚为什么RLinf的代码需要这么大的显存,可能是全量微调了吧,后续抽时间再细研究一下。
笔者以前总用autodl平台,这次没用是因为仿真需要用户界面,autodl上不支持,而gpufree平台支持。大家可以扫下面的码注册,可以获得小量算力额度。

官方提供了docker和命令行两种方式,因为gpufree平台不支持docker环境,所以就直接用命令行安装了,直接按流程安装就没有问题。在gpufree平台上笔者选择的镜像是:noVNC/ubuntu24.04,注意,要选择带界面的镜像。
quick start
安装完成后,可直接运行官方的:快速上手,是用PPO算法在仿真maniskill3环境中训练openvla-oft模型。
修改配置
文件如下,核心的配置都没改,就改了一个卡的分配策略。actor就是训练进程,使用前4张卡(笔者多次尝试经验,这4张卡如果与rollout/env复用的话,会显存OOM,所以在此单独使用)。env就是仿真进程,使用第5张卡。rollout就是交互进程,里面最重要是一个动作generator,它里面运行openvla-oft模型的infer流程生成动作,使用了第6张卡。当然也可以将env和rollout合在一起:env,rollout: 4-5,笔者测试后整体的rollout时间会从以前的48秒缩短到37秒左右,效率更高一些。另外,也可以把micro_batch_size调大一些(资源允许情况下),笔者把它从1调到2,训练时间从45秒减到28秒。
--- a/examples/embodiment/config/maniskill_ppo_openvlaoft_quickstart.yaml
+++ b/examples/embodiment/config/maniskill_ppo_openvlaoft_quickstart.yaml
@@ -15,7 +15,9 @@ hydra:
cluster:
num_nodes: 1
component_placement:
- actor,env,rollout: 0-0
- actor: 0-3
- env: 4
- rollout: 5
- val_check_interval: -1
- val_check_interval: 2 # 打开eval
- enable_offload: True
- enable_offload: False # 如果打开的话,参数会频率的加载与卸载,因为这里的资源是隔离的,所以没必要打开
- model_path: "/path/to/model/Openvla-oft-SFT-libero10-trajall/"
- model_path: "/root/gpufree-data/hf/"
- enable_offload: True
-
enable_offload: False
tokenizer:
tokenizer_type: "HuggingFaceTokenizer"
- tokenizer_model: "/path/to/model/Openvla-oft-SFT-libero10-trajall/"
- tokenizer_model: "/root/gpufree-data/hf/"
extra_vocab_size: 421
use_fast: False
trust_remote_code: True
@@ -134,7 +136,7 @@ actor:
Override the default values in model/openvla_oft
model:
- model_path: "/path/to/model/Openvla-oft-SFT-libero10-trajall/"
-
model_path: "/root/gpufree-data/hf/"
model_type: "openvla_oft"
unnorm_key: bridge_orig
@@ -142,7 +144,7 @@ actor:
add_value_head: True
is_lora: True
aka RLinf-OpenVLAOFT-ManiSkill-Base-Lora. It can be downloaded from https://huggingface.co/RLinf/RLinf-OpenVLAOFT-ManiSkill-Base-Lora
- lora_path: /path/to/models/oft-sft/lora_004000/
- lora_path: /root/gpufree-data/hf/lora_004000/
然后执行命令
bash examples/embodiment/run_embodiment.sh maniskill_ppo_openvlaoft_quickstart
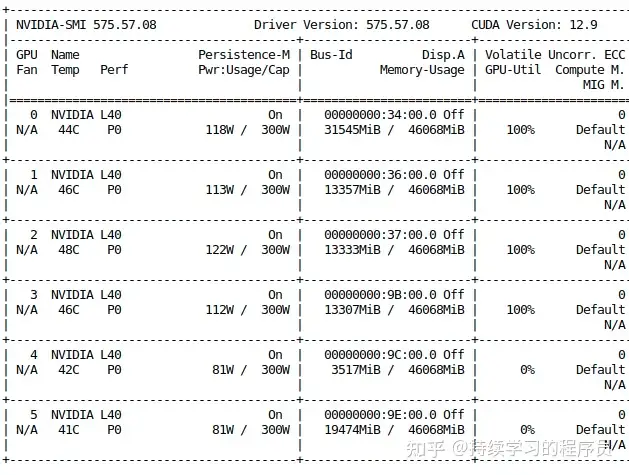
gpu的使用情况如下
(此时正在训练流程中,所以第4,5张卡没有使用,下文会有原理分析):
日志输出
默认配置会运行1000个step(配置:max_epochs: 1000),每个step会输出日志如下:
可以发现,每个step运行时长78秒,其中同步权重(将actor训练中的最新的weight同步给rollout)用了7.7秒,生成rollout(与仿真环境交互产生动作轨迹)的时间是38.8秒,训练时间是32.3秒。
笔者训练了1个小时,评测成功率从初始18%涨到30%,在训练过程中这个评测成功率不是特别稳定。
Global Step: 0%| | 1/1000 [01:18<21:51:39
78.78s/it
time/time/sync_weights=7.7
time/time/generate_rollouts=38.8
time/time/cal_adv_and_returns=0.0084
time/time/actor_training=32.3
time/time/step=78.8
env/success_once=0.0 #任务成功率
env/return=0.025
env/episode_len=80.0
env/reward=0.0003125
rollout/rewards=0.000127
rollout/advantages_mean=1.49e-9
rollout/advantages_max=2.89
rollout/advantages_min=-2.74
rollout/returns_mean=-0.0071
rollout/returns_max=0.0905
rollout/returns_min=-0.0344
train/actor/approx_kl=0.0651
train/actor/clip_fraction=0.096
train/actor/clipped_ratio=0.999
train/actor/dual_cliped_ratio=0
train/actor/grad_norm=2.93
train/actor/lr=0.0001
train/actor/policy_loss=0.0443
train/actor/ratio=1.02
train/critic/explained_variance=-3.65e+3
train/critic/lr=0.003
原理简介
在试用过程中,也看了很多文档,阅读了部分代码,对RLinf的设计原理有了一些初步的认知。
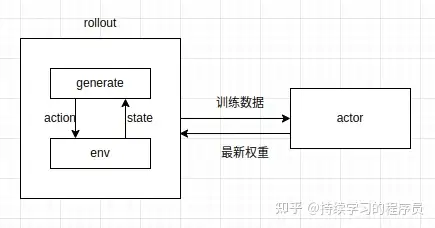
整体上核心的几部分如上图所示,generate就是VLA模型输出仿真环境所需要的动作,env就是仿真环境,它给generate模块提供state信息输入。generate+env就整体上组成了rollout模块。actor模块就是训练模块,它负责分布式环境中的训练。rollout为其提供训练数据,在每个step开始的时候,actor也会将最新模型权重同步给rollout模块。
通过上文的quick start案例代码和配置研究(下面的配置分析使用代码库中默认配置,非上面笔者更新的配置),具体到此案例中来说,rollout_epoch: 1/total_num_envs: 8/max_steps_per_rollout_epoch: 80这几个配置的意思是并行8个仿真环境,rollout模块每个step生产1×8=8条轨迹,每条轨迹最长不超过80步。rollout生产完成数据后,给到actor进行训练,此时rollout模块就停止了。也就是rollout与actor之间是一个串形的关系。而rollout内部的generate和env之间可以并行,依赖pipeline_stage_num: 1参数,若是1的话,就是串形,若大于1就是有一定的并行度。
这些模块的串形和并形关系是通过代码阅读+实验验证(上文的gpu截图和日志)可得到此结论,同时,笔者让cursor和gemini大模型阅读代码也会有同样的结论,其中cursor输出如下,可参考:
- 环境 ↔ rollout 内部的流水线并行
在 huggingface_worker.generate() 中,按 rollout_epoch 和 n_chunk_steps 迭代,每一步会循环 stage_num = pipeline_stage_num 条"stage"。每条 stage 都是:recv_env_output → predict → append_result → send_chunk_actions。
在 env_worker.interact() 里同样按 stage_num 分多条环境流水线:先把各 stage 的初始观测发给 rollout,然后每个 chunk_step 依次收动作、步进环境、再把新的观测发回。
这样单个 rollout worker 内形成多条并行流水线,减少某一条环境阻塞 GPU 推理的情况,提升吞吐(stage_num>1 时一份 rollout 进程同时服务多条 env-推理流)。
- rollout ↔ actor 数据流的并行/交错
EmbodiedRunner.generate_rollouts() 一次性触发三个 future:env.interact()、rollout.generate()、actor.recv_rollout_batch(),它们并行运行,最后 wait() 收集结果。也就是说,采样阶段(env+rollout)与 actor 接收 rollout 数据是并行的。
rollout 侧发送数据:send_rollout_batch() 把 buffer_list(按 stage_num 收集的 chunk)按 compute_split_num 切分,写入 replay_buffer 队列;actor 侧 recv_rollout_batch() 异步从同一通道取齐数据,拼成训练 batch。
但在 EmbodiedRunner.run() 的主循环里,采样完成后才执行 compute_advantages_and_returns() 和 actor.run_training(),训练与下一轮采样没有重叠(未做训练与采样同时进行的双缓冲)。
- actor 训练与 rollout 推理是否同时执行?
同一个 global step 内:先并行完成采样(env+rollout+actor接收),然后才进入 actor 训练。主循环是串行的,因此训练与采样不重叠。
这意味着当前框架的"流水线并行"主要体现在"多 stage 的 env↔rollout 交互"和"采样阶段各组件并行",并没有把训练阶段也并行起来。
总结
pipeline_stage_num 让 env 和 rollout 在单个进程内多条 stage 并行,提升采样吞吐。
采样阶段(env+rollout)与 actor 端接收 rollout 数据是并行触发的。
采样完成后训练再开始,训练与采样未重叠。如果要进一步并行,需要改 Runner 做采样/训练双缓冲或多进程训练。
今天先写这么多,后续会持续试用修改,有新的认知再同步到此文章。
开启送礼物