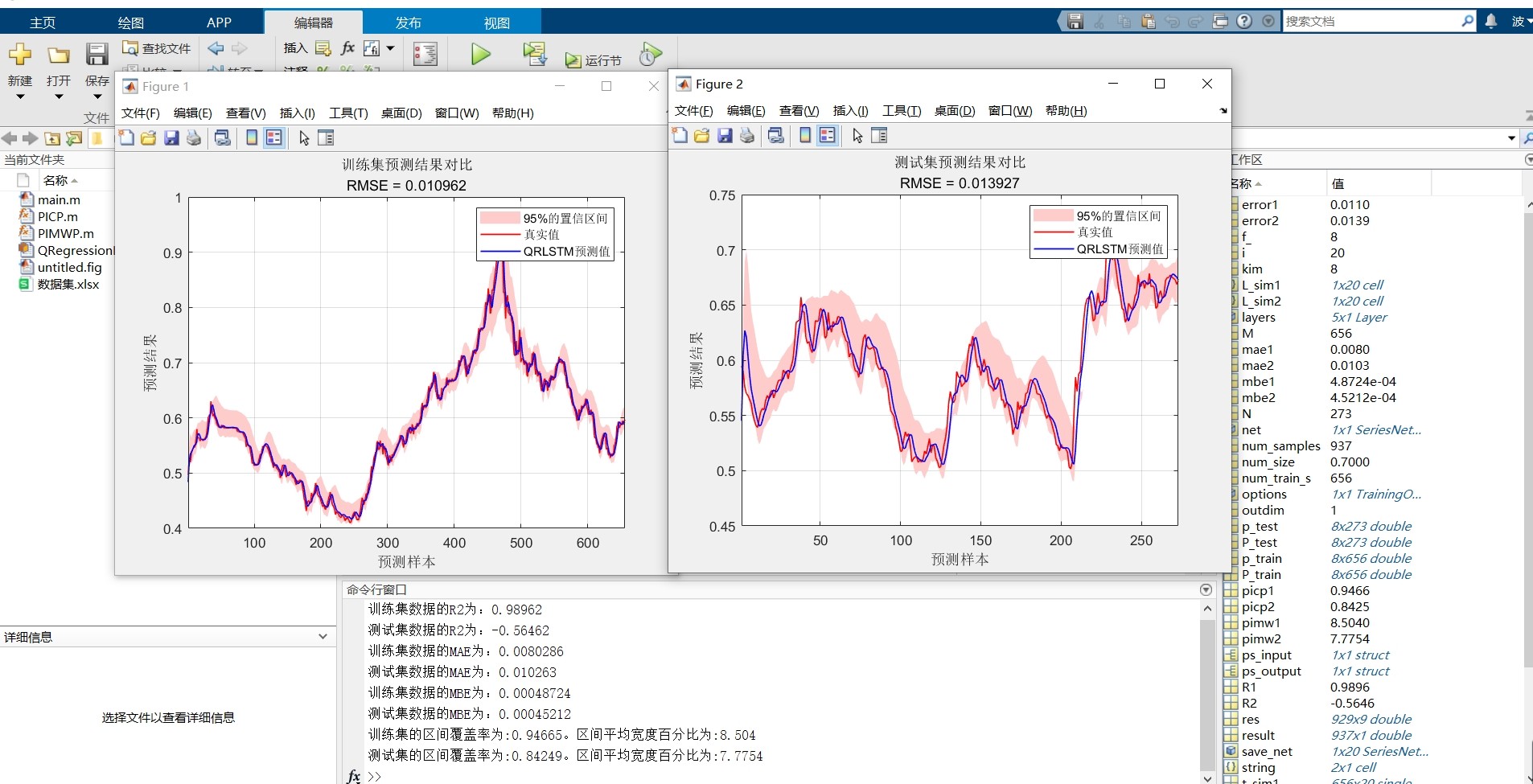
QRLSTM基于分位数回归的长短期记忆网络QRLSTM时间序列区间预测。 (主要应用于风速,负荷,功率) 包含评价指标R2,MAE,MBE,区间覆盖率,区间平均宽度。
最近在捣鼓电力负荷预测的项目,传统LSTM的点预测总让人心里不踏实。偶然发现分位数回归和LSTM还能搞CP,这QRLSTM有点东西。咱们今天就来盘一盘这个能直接输出预测区间的黑科技,手把手教你怎么用代码把它玩起来。
先上段模型核心结构代码镇楼:
python
import torch
import torch.nn as nn
class QRLSTM(nn.Module):
def __init__(self, input_size, hidden_size, quantiles=[0.1, 0.5, 0.9]):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
self.quantiles = quantiles
self.heads = nn.ModuleList([
nn.Sequential(
nn.Linear(hidden_size, 32),
nn.ReLU(),
nn.Linear(32, 1)
) for _ in quantiles
])
def forward(self, x):
out, _ = self.lstm(x)
out = out[:, -1, :] # 只要最后一个时间步
return torch.cat([head(out) for head in self.heads], dim=1)这代码妙就妙在给每个分位数都配了个专属输出头(heads列表),相当于让模型同时学习多个分位点的预测。比如咱们设定了0.1,0.5,0.9三个分位数,模型就能同时给出10%、50%、90%分位数的预测值,形成预测区间。
关键在损失函数的设计,传统MSE可不行。看这个分位数损失函数:
python
def quantile_loss(y_true, y_pred, quantiles):
losses = []
for i, q in enumerate(quantiles):
error = y_true - y_pred[:, i:i+1]
losses.append(torch.max((q-1)*error, q*error).mean())
return sum(losses)这函数处理多个分位数损失的方式很讲究------对于每个分位点q,当预测值低于真实值时,损失权重是q,反之是(1-q)。比如对于0.9分位数,模型更在意不要低估真实值(低估时惩罚更大)。
训练时要注意数据标准化,别让不同量纲把模型搞懵了。这里用鲁棒标准化更抗异常值:
python
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
scaled_data = scaler.fit_transform(raw_data.reshape(-1, 1))预测结果要还原尺度时,记得逆转换:
python
y_pred_original = scaler.inverse_transform(y_pred)评估指标才是重头戏,这几个指标必须安排:
python
coverage = np.mean((y_test >= lower_bound) & (y_test <= upper_bound))
# 区间平均宽度
width = np.mean(upper_bound - lower_bound)
# 点预测精度
r2 = r2_score(y_test, median_pred)
mae = mean_absolute_error(y_test, median_pred)
mbe = np.mean(median_pred - y_test) # 平均偏差覆盖率太高可能意味着区间太宽,太窄又容易漏掉真实值。好的模型应该在保证覆盖率(比如90%)的前提下,让区间宽度尽可能小。
实际跑电力负荷数据时发现个有趣现象:工作日的预测区间明显比节假日窄,毕竟用电模式更规律嘛。这时候可以给模型加上日期特征,效果立竿见影:
python
# 添加星期几作为特征
df['day_of_week'] = df.index.dayofweek / 7 # 归一化到0-1调参时有个小技巧:先调中间分位数(0.5相当于中位数预测),稳定后再调两侧分位数。学习率也别太大,建议从1e-3开始尝试。
最后说点实战经验:当预测区间突然变宽,八成是系统要搞事情。有次模型突然把凌晨时段的区间宽度拉高30%,结果当天还真遇到设备故障导致负荷异常。这QRLSTM不光能做预测,还能当异常检测器用,算是买一送一的惊喜了。