一键克隆你的声音,还能自由调节情绪,AI配音从未如此简单
在日常生活中,我们常常遇到这样的场景:想要为视频配上解说,却找不到合适的声音;制作有声书时,希望不同角色有不同声音表达;或者只是想用朋友的声音生成一段有趣的祝福语。现在,这些需求只需一个工具就能轻松实现------这就是B站语音团队开源的IndexTTS2。

1.IndexTTS2简介
IndexTTS2是B站语音团队开发的新一代零样本语音合成模型。简单来说,它是一个能够模仿任何人声音,并自由控制语音情感的AI工具。
与传统语音合成系统最大的不同是,IndexTTS2解决了长期困扰行业的情感表达缺失 和时长控制不精准两大难题,让生成的语音不再是冰冷的机器发音,而是充满情感色彩的"表演"
- 极简声音克隆:5秒音频即可复刻声音
- 情感音色分离:自由组合声音与情绪
- 多模态情感输入:用文字描述控制情绪
- 精准时长控制:音画同步不再是难题
IndexTTS2的突破性在于它成功解决了自回归TTS模型的时长控制难题 ,同时实现了情感与音色的解耦建模
开源地址:https://github.com/index-tts/index-tts/blob/main/docs/README_zh.md

2.本地部署
2.1 环境
| 环境 | 版本 |
|---|---|
| ubuntu-24.04.3 Server | release 10.0 |
| Cuda | 12.8 |
| 显卡 RTX 2080 Ti 22G | 驱动 NVIDIA-Linux-x86_64-580.105.08 |
| uv | 0.9.13 |
| 内存 | 32G |
请提前安装好 显卡驱动,cuda版本最好是 12.8。
不要用conda环境,要使用UV,这是官方给的建议,确保依赖环境可靠。
如果你现在处于conda环境中,使用下面命令退出conda环境
shell
conda deactivate2.2 安装UV
shell
# 安装UV 或者 pip install -U uv
curl -LsSf https://astral.sh/uv/install.sh | sh
# 查看python版本
uv python list
# 配置PyPI仓库为国内源
vim ~/.config/uv/uv.toml
[registries.pypi]
index = "https://mirrors.aliyun.com/pypi/simple/"
default = true2.3 下载源码
确保已经安装了 git 和 git-lfs. 因为源码中的声音样本文件并真正的声音二进制文件,它需要使用 git-lfs 下载实际的声音二进制文件。git-lfs 是用来下载大文件的工具。

我的机器上开了代理,使用git的时候,要设置git的代理地址:
shell
git config --global https.proxy http://127.0.0.1:7897
git config --global https.proxy http://127.0.0.1:7897
git clone https://github.com/index-tts/index-tts.git
cd index-tts
# 用来下载大文件
git lfs install
git lfs pull # 开始下载大文件,这样完成之后,仓库中的文件如果是二进制文件,才会真正被下载下来,否则内容并不是真正的文件内容2.4安装依赖
shell
# 目录下会生成 .venv 隐藏目录,所有依赖都在这个目录下
uv sync --all-extras --default-index "https://mirrors.huaweicloud.com/repository/pypi/simple"
# 激活环境
source .venv/bin/activate2.5 下载模型权重
这里从 modelscope下载模型权重文件。注意要将模型权重文件下载到 项目的 checkpoints文件夹中。因为项目启动的时候,会到 checkpoints文件夹中加载权重文件。
shell
uv tool install "modelscope"
# 确保当前路径在你的项目根目录下,根目录下有checkpoints 文件夹
modelscope download --model IndexTeam/IndexTTS-2 --local_dir checkpoints下载完成后,需要检查一下checkpoints目录中是否包含了bpe.model,gpt.pth这两个文件,如果没有下载下来,需要手动下载 ,地址: https://modelscope.cn/models/IndexTeam/IndexTTS-2/files
后面系统启动的时候,还会到 huggingface上下载文件,国内不能直接正常访问,所以设置一下环境变量,指定镜像地址:
shell
export HF_ENDPOINT="https://hf-mirror.com"2.6检测 PyTorch GPU
可运行脚本检测机器是否有GPU,以及是否安装了GPU版本的PyTorch。(如PyTorch版本不对,可能使用CPU启动,推理会非常慢)
shell
uv run tools/gpu_check.py如果检查没有问题,就可以直接启动了。
3.启动程序
启动后会开启7860端口
shell
uv run webui.py默认界面是英文的,我修改了 webui.py文件,第54 行,让它以中文启动:
然后就看到了界面,长这样:
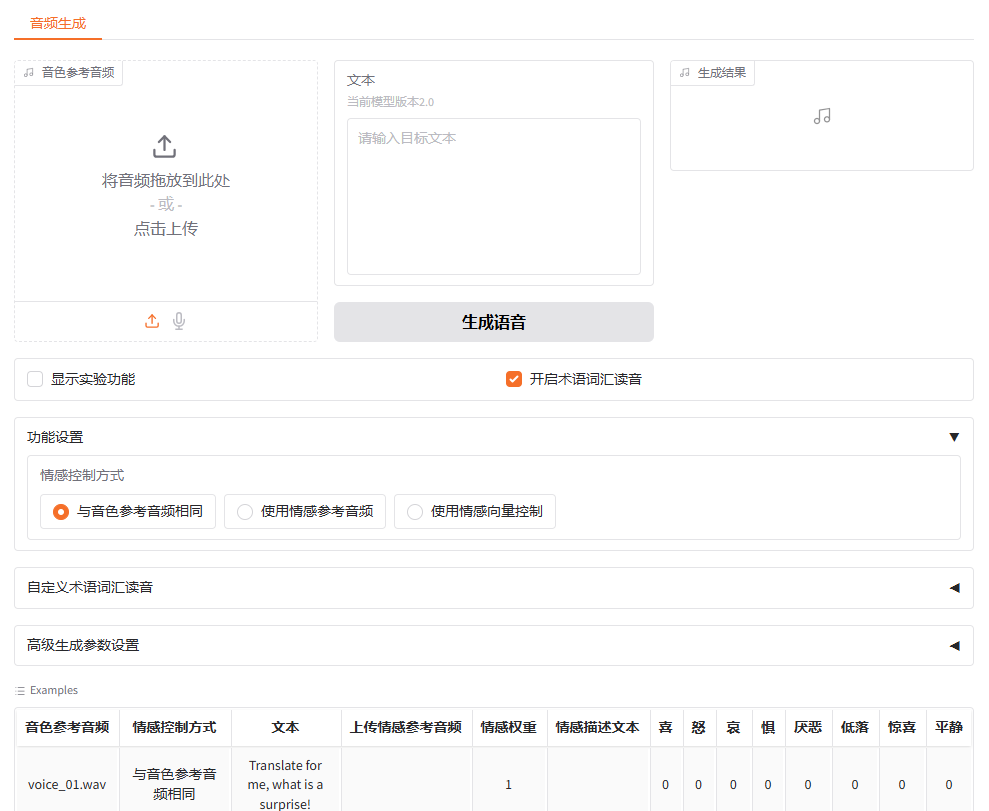
4.体验
页面最下面有一些示例,你可以点击voice_01.wav 这一行,表示你要使用这个声音作为样本来合成。点击后,最上面是这样:

你可以点击播放来听听样本的声音。 中间的文本是你要合成的文字,你可以修改。点击生成语音后,右边就开始合成。此时你可以在服务器上看GPU的占用情况:
shell
# 安装命令 查看硬件 nvidia-smi -l 1
sudo apt-get install nvtop
# 执行命令
nvtop
在合成之前,你可以上传你自己的声音样本,也可以调整音色情感参数,默认使用的与参考音频相同的音色
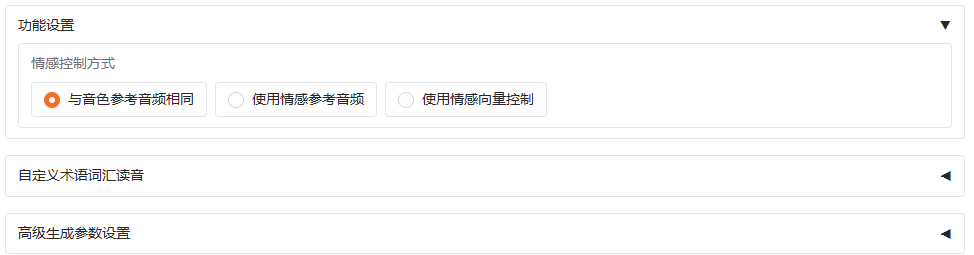
有些词你如果怕它读错,你可以自定义词汇读音:

5.结语
IndexTTS2的出现,将曾经专业且昂贵的语音合成技术变成了人人可用的创作工具。它不仅免费开源,而且操作简单,极大地降低了高质量语音内容的制作门槛
随着IndexTTS2这样的技术不断发展,未来我们可能会看到更多由AI配音的高质量内容,而语音合成技术也必将进一步融入我们的日常生活和创作过程中。