前言:从本篇文章开始学习一个人脸识别开源项目face-api.js。
tensorflow 是一个用于使用 JavaScript 进行机器学习开发的库。不得不说,JavaScript真的潜力无穷啊!我觉得最好的学习方式,就是基于开源项目学习。所以找了一个挺有意思的开源项目,face-api.js研究一下。
一、项目启动
face-api.js 文档还是挺齐全的,Github里面demo网站、相关的学习文档非常的全,star数量也很高,生态很完善,预计是很有趣的学习之旅~~
下载到本地之后,我是macbook m1电脑,安装依赖有一些报错,有以下几个小问题
- 1、 @tensorflow/tfjs-node 的旧版本不支持 darwin-arm64
更换版本:"@tensorflow/tfjs-node": "^4.15.0", - 2、依赖冲突:rollup-plugin-uglify@6.0.4 需要 rollup < 2
① 更换版本:"rollup-plugin-terser": "^7.0.2",
② 更新rollup.config.js,将rollup-plugin-uglify替换为rollup-plugin-terser:- 将
import { uglify } from 'rollup-plugin-uglify';改成import { terser } from 'rollup-plugin-terser'; - 将
].concat(minify ? uglify() : []),改成].concat(minify ? terser() : []),
然后删除npm缓存sudo chown -R $(whoami) ~/.npm、sudo npm cache clean --force,并且重新安装依赖npm i,即可安装成功。
安装依赖之后,还需要安装express,这个开源库是用node做的服务端,Express.js 是目前最流行的 Node.js Web 应用程序框架。
通过npm i express安装
然后需要进入到examples/examples-browser文件夹,这个文件夹是启动服务的文件夹。
通过npm run start启动项目,在3000端口开启神奇的机器学习之旅
- 将
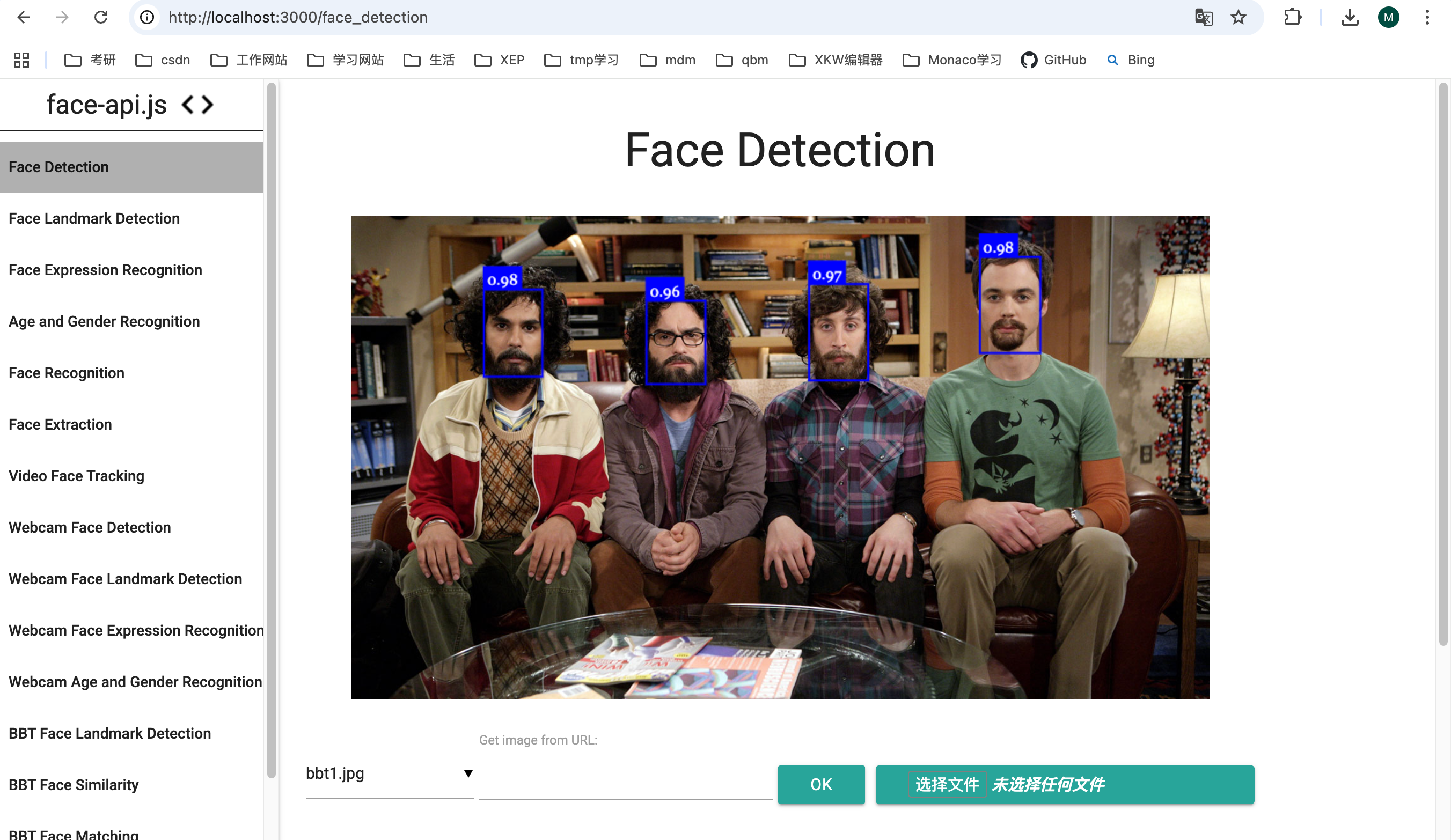
二、Face Detection
我们先来看最上面的这个模块Face Detection,根据这个模块整体熟悉一下代码结构。
这个项目是通过 express 的路由实现的各模块,HTML页面都在 examples/examples-browser/views 文件夹中
文件通过script标签导入需要的功能模块
javascript
<script src="face-api.js"></script>
<script src="js/commons.js"></script>
<script src="js/faceDetectionControls.js"></script>
<script src="js/imageSelectionControls.js"></script>图片部分的HTML:
html
<div style="position: relative" class="margin">
<img id="inputImg" src="" style="max-width: 800px;" />
<canvas id="overlay" />
</div>img标签是图片本身,canvas是绘制到图片上的脸上的框框或者识别眼睛的点点等内容
HTML加载的时候,会先执行下面的方法
javascript
$(document).ready(function() {
// 渲染HTML
renderNavBar('#navbar', 'face_detection')
initImageSelectionControls()
initFaceDetectionControls()
run()
})前三句代码,是用来渲染DOM以及绑定事件的。这个项目用的是原生DOM,所以操作DOM的代码还挺多的。
咱们看一下 run() 方法都干了什么
三、run()
js
async function run() {
// 加载面部识别模型
await changeFaceDetector(SSD_MOBILENETV1)
// 开始处理图像
updateResults()
}-
changeFaceDetector()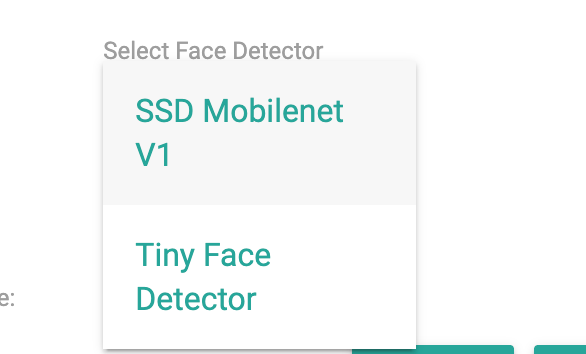
是这里用来修改模型的,默认是第一个。
-
updateResults()这是处理图像获取检测结果的关键方法。
javascript
async function updateResults() {
if (!isFaceDetectionModelLoaded()) {
return
}
const inputImgEl = $('#inputImg').get(0)
// 获取面部检测选项
const options = getFaceDetectorOptions()
// 进行面部检测
const results = await faceapi.detectAllFaces(inputImgEl, options)
console.log("results")
console.log(results)
const canvas = $('#overlay').get(0)
// 调整图像尺寸
faceapi.matchDimensions(canvas, inputImgEl)
// 绘制面部检测框
faceapi.draw.drawDetections(canvas, faceapi.resizeResults(results, inputImgEl))
}我们看一下控制台的输出,也就是面部检测的结果:

这个方法是调API进行面部识别的关键所在,所以下面看一下这个方法的内部是如何运行的
四、detectAllFaces
这个代码是在dist/face-api.js里面,经过ts编译器编译过的代码,src中是源码。我们在src里看源码,改完之后,需要在项目根目录下执行 npm run build 重新构建,然后在 examples/examples-browser 目录执行 npm run start 重启启动项目。
我们直接看源码里的代码,构建之后的太难看了
可以把下面这个命令,写到根目录的 package.json 里面,在源码里修改代码之后直接在根目录下执行npm run restart,一步到位重新构建+重启服务
js
"restart": "npm run build && cd examples/examples-browser && node server.js",src/globalApi/detectFaces.ts
javascript
export function detectAllFaces(
input: TNetInput,
options: FaceDetectionOptions = new SsdMobilenetv1Options()
): DetectAllFacesTask {
return new DetectAllFacesTask(input, options)
}主要返回了一个检测的任务 DetectAllFacesTask(input, options),这个任务是通过类的形式来定义的。
先来看一下这个类长什么样子吧。
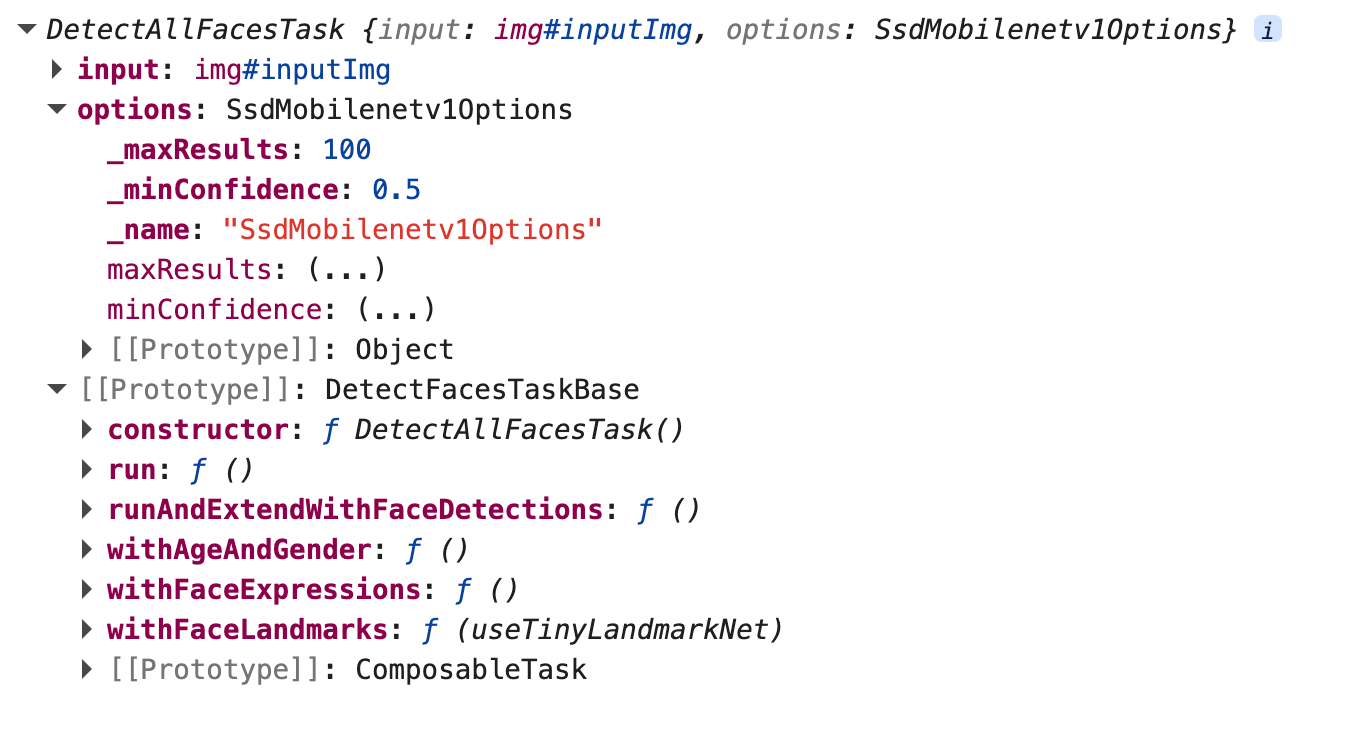
包括输入的图片、参数、和定义到原型链上的方法。
这里面的代码稍微有一丢丢复杂。
人脸识别的工具类在 src/globalApi/DetectFacesTasks.ts 里面定义。
代码有点多,一点点的看功能吧。
① run()
javascript
public async run(): Promise<FaceDetection[]> {
// 获取图片和选项
const { input, options } = this
console.log(input, options)
if (options instanceof MtcnnOptions) {
return (await nets.mtcnn.forward(input, options))
.map(result => result.detection)
}
const faceDetectionFunction = options instanceof TinyFaceDetectorOptions
? (input: TNetInput) => nets.tinyFaceDetector.locateFaces(input, options)
: (
options instanceof SsdMobilenetv1Options
? (input: TNetInput) => nets.ssdMobilenetv1.locateFaces(input, options)
: (
options instanceof TinyYolov2Options
? (input: TNetInput) => nets.tinyYolov2.locateFaces(input, options)
: null
)
)
if (!faceDetectionFunction) {
throw new Error('detectFaces - expected options to be instance of TinyFaceDetectorOptions | SsdMobilenetv1Options | MtcnnOptions | TinyYolov2Options')
}
return faceDetectionFunction(input)
}看一下获取的图片和选项

run() 方法最终返回了一个 faceDetectionFunction() 方法的返回值。
这个方法的内部,会对option进行判断,根据选项选择不同的处理方法。目前的选项会执行 nets.ssdMobilenetv1.locateFaces(input, options) 方法。
五、nets.ssdMobilenetv1.locateFaces(input, options)
检测图像中的人脸并返回 FaceDetection 对象数组
src/ssdMobilenetv1/SsdMobilenetv1.ts
主要步骤:
- 输入预处理:将各种输入类型转换为 NetInput
- 神经网络推理:执行前向传播获取原始检测结果
- 批次处理:提取第一个批次的检测结果
- 非极大值抑制(NMS):去除重叠的边界框
- 坐标转换:将归一化坐标转换为实际像素坐标
- 结果封装:创建 FaceDetection 对象数组
- 内存清理:释放不再使用的张量
① 输入预处理:将各种输入类型转换为 NetInput
js
// ========== 步骤1:解析选项参数,输入预处理 ==========
const { maxResults, minConfidence } = new SsdMobilenetv1Options(options)
// 将各种输入类型(HTMLImageElement、Canvas、Tensor等)统一转换为 NetInput 格式
// 这会等待媒体元素加载完成,并进行输入验证
const netInput = await toNetInput(input)NetInput 是用来统一数据类型的,具体的功能后面再看,咱们先整体看一下面部识别的流程。统一成 NetInput 可以批次处理数据,可以提高数据处理效率。
② 神经网络推理:执行前向传播获取原始检测结果
前向传播的意思就是从输入获取输出
javascript
// ========== 步骤2:神经网络前向传播 ==========
// 执行 SSD MobileNet v1 的前向传播,获取原始检测结果
// 返回:
// - boxes: tf.Tensor2D[] - 边界框数组(每个批次一个张量)
// 形状:[numBoxes, 4],格式:[y_min, x_min, y_max, x_max](归一化坐标,范围 [0, 1])
// - scores: tf.Tensor1D[] - 置信度分数数组(每个批次一个张量)
// 形状:[numBoxes],值范围 [0, 1]
const {
boxes: _boxes,
scores: _scores
} = this.forwardInput(netInput)先大致看一下
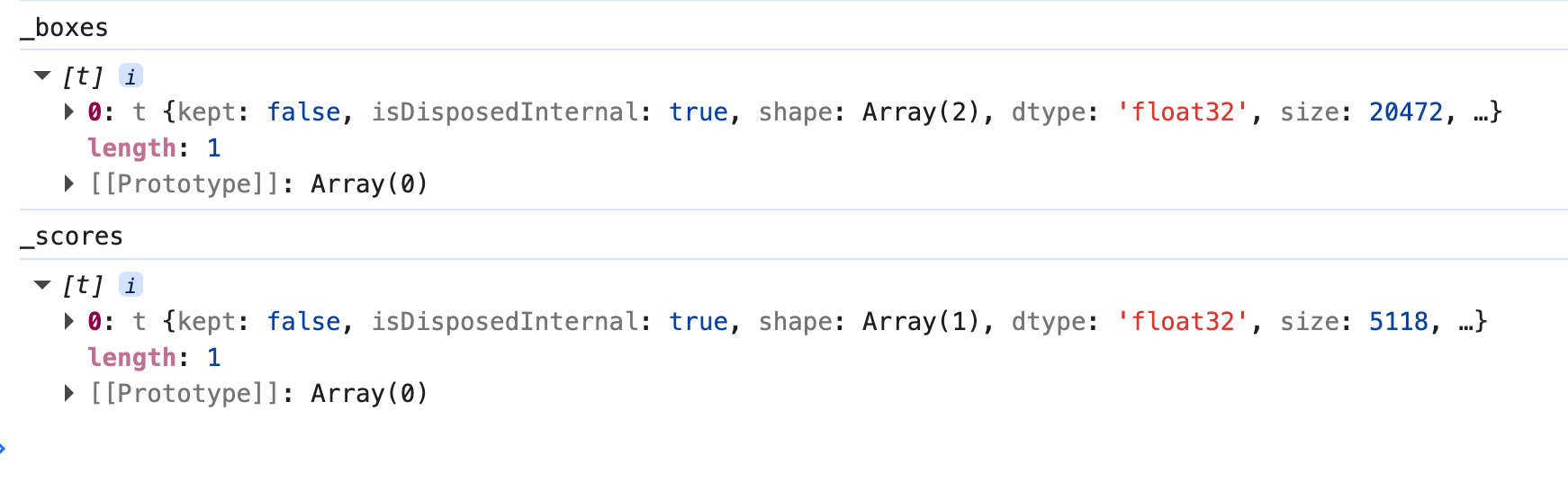
这个方法是SSD MobileNet v1 模型的核心推理方法,这个理解起来就更复杂了呀哈哈哈,后面写一篇文章专门研究一下吧。
③ 批次处理:提取第一个批次的检测结果
提取第一个批次进行处理。不过当前只处理一个批次。如果有多张图片的话,需要处理多个批次。
javascript
// ========== 步骤3:批次处理 ==========
// 提取第一个批次的检测结果(当前实现只处理单个输入)
// 注意:虽然 forwardInput 支持批量输入,但 locateFaces 目前只处理第一个批次
const boxes = _boxes[0] // tf.Tensor2D: [numBoxes, 4]
const scores = _scores[0] // tf.Tensor1D: [numBoxes]
// 释放其他批次的张量,避免内存泄漏
// 如果输入是批量输入,其他批次的结果会被丢弃
for (let i = 1; i < _boxes.length; i++) {
_boxes[i].dispose()
_scores[i].dispose()
}④ 非极大值抑制(NMS):去除重叠的边界框
javascript
// ========== 步骤4:非极大值抑制(NMS)==========
// 将 TensorFlow 张量转换为 JavaScript 数组,便于后续处理
// scores.data() 返回 TypedArray,需要转换为普通数组
const scoresData = Array.from(await scores.data())
console.log("scoresData")
console.log(scoresData)
// 非极大值抑制(Non-Maximum Suppression,NMS)的作用:
// 1. 去除重叠的边界框:当多个边界框检测到同一个人脸时,只保留置信度最高的
// 2. 过滤低置信度结果:移除置信度低于 minConfidence 的检测结果
// 3. 限制结果数量:最多返回 maxResults 个结果
//
// IOU(Intersection over Union,交并比)详解:
//
// 什么是 IOU?
// IOU = 交集面积 / 并集面积
//
// 值范围:[0, 1]
// - IOU = 0.0:两个框完全不重叠(检测到不同的人脸)
// - IOU = 0.5:两个框有 50% 重叠(可能检测到同一个人脸)
// - IOU = 1.0:两个框完全重叠(检测到同一个人脸)
//
// IOU 阈值(iouThreshold = 0.5)的作用:
// - IOU > 0.5:认为两个框检测到同一个人脸,保留置信度更高的,丢弃另一个
// - IOU ≤ 0.5:认为两个框检测到不同的人脸,都保留
//
// 为什么选择 0.5 作为阈值?
// - 0.5 是一个经验值,在准确率和召回率之间取得平衡
// - 如果阈值太低(如 0.3):可能误删不同的人脸
// - 如果阈值太高(如 0.7):可能保留重复的检测结果
//
// 示例:
// 框1: 置信度 0.95,位置 [100, 100, 200, 200]
// 框2: 置信度 0.87,位置 [110, 110, 210, 210]
// IOU = 0.75(高度重叠)
// 结果:保留框1(置信度更高),丢弃框2
//
// 算法流程:
// 1. 按置信度从高到低排序所有候选框
// 2. 选择置信度最高的框
// 3. 计算该框与其他框的 IOU
// 4. 移除 IOU > threshold 的框(保留置信度更高的)
// 5. 重复步骤2-4,直到达到 maxResults 或没有更多候选框
const iouThreshold = 0.5
const indices = nonMaxSuppression(
boxes, // 边界框张量
scoresData, // 置信度数组
maxResults, // 最大结果数
iouThreshold, // IOU 阈值(0.5)
minConfidence // 最小置信度阈值
)
console.log("indices")
console.log(indices)
// 返回:indices 数组,包含保留的边界框索引上一步中得到的 _scores 有一个 size 属性,值为 5118,转换为数组后,就是一个一维数组,元素个数为 5118,它是一个置信度数组。这里可以获取能框住脸脸的边界框索引。

⑤ 坐标转换:将归一化坐标转换为实际像素坐标
javascript
// ========== 步骤5:坐标转换 ==========
// 将归一化坐标(范围 [0, 1])转换为实际像素坐标
//
// 为什么需要坐标转换?
// - 神经网络输入是固定尺寸(512x512),但原始图像可能是任意尺寸
// - 检测结果是在 512x512 坐标系下的归一化坐标
// - 需要转换回原始图像的像素坐标
//
// 缩放因子计算:
// - padX, padY: 输入尺寸与原始图像尺寸的比例
// - 用于将归一化坐标映射回原始图像尺寸
const reshapedDims = netInput.getReshapedInputDimensions(0) // 原始图像尺寸
const inputSize = netInput.inputSize as number // 网络输入尺寸(512)
const padX = inputSize / reshapedDims.width // X 轴缩放因子
const padY = inputSize / reshapedDims.height // Y 轴缩放因子
// 将边界框张量转换为 JavaScript 数组
// boxesData 形状:[numBoxes, 4]
// 格式:[y_min, x_min, y_max, x_max](归一化坐标)
const boxesData = boxes.arraySync()
console.log("boxesData")
console.log(boxesData)获得所有坐标组成的张量,也就是一个二维数组 5118*4

⑥ 结果封装:创建 FaceDetection 对象数组
javascript
// ========== 步骤6:创建 FaceDetection 对象 ==========
// 遍历 NMS 筛选后的索引,为每个检测结果创建 FaceDetection 对象
const results = indices
.map(idx => {
// 提取边界框坐标(归一化坐标,范围 [0, 1])
const [yMin, xMin, yMax, xMax] = boxesData[idx]
// 坐标转换:归一化坐标 → 像素坐标
// 1. 限制坐标范围在 [0, 1] 内(防止越界)
// 2. 乘以缩放因子,转换为像素坐标
// 3. 计算相对于原始图像的位置
const [top, bottom] = [
Math.max(0, yMin), // 确保 yMin >= 0
Math.min(1.0, yMax) // 确保 yMax <= 1.0
].map(val => val * padY) // 转换为像素坐标
const [left, right] = [
Math.max(0, xMin), // 确保 xMin >= 0
Math.min(1.0, xMax) // 确保 xMax <= 1.0
].map(val => val * padX) // 转换为像素坐标
// 创建 FaceDetection 对象
return new FaceDetection(
scoresData[idx], // 置信度分数
new Rect(
left, // 左上角 X 坐标
top, // 左上角 Y 坐标
right - left, // 宽度
bottom - top // 高度
),
{
height: netInput.getInputHeight(0), // 原始图像高度
width: netInput.getInputWidth(0) // 原始图像宽度
}
)
})
⑦ 内存清理:释放不再使用的张量
javascript
// ========== 步骤7:内存清理 ==========
// 释放不再使用的张量,避免内存泄漏
boxes.dispose()
scores.dispose()最终返回的是 FaceDetection 对象数组。
六、FaceDetection 对象
src/classes/FaceDetection.ts
类继承关系
FaceDetection extends ObjectDetection implements IFaceDetection核心属性
1. score: number
- 类型 :
number - 范围 :
[0, 1] - 含义: 置信度分数,表示检测到人脸的可靠程度
- 示例 :
0.95表示 95% 确定是人脸
2. box: Box
- 类型 :
Box对象 - 含义: 边界框,包含人脸的位置和尺寸信息
- 坐标系统: 相对于原始图像的像素坐标
Box 对象的属性:
| 属性 | 类型 | 说明 | 示例 |
|---|---|---|---|
x |
number |
左上角 X 坐标 | 100 |
y |
number |
左上角 Y 坐标 | 150 |
width |
number |
边界框宽度 | 200 |
height |
number |
边界框高度 | 200 |
left |
number |
左边界(= x) | 100 |
top |
number |
上边界(= y) | 150 |
right |
number |
右边界(= x + width) | 300 |
bottom |
number |
下边界(= y + height) | 350 |
area |
number |
面积(width × height) | 40000 |
topLeft |
Point |
左上角点 | Point(100, 150) |
topRight |
Point |
右上角点 | Point(300, 150) |
bottomLeft |
Point |
左下角点 | Point(100, 350) |
bottomRight |
Point |
右下角点 | Point(300, 350) |
3. imageDims: Dimensions
- 类型 :
Dimensions对象 - 含义: 原始图像的尺寸
- 属性 :
width: 图像宽度height: 图像高度
4. imageWidth: number
- 类型 :
number - 含义: 原始图像宽度(快捷属性)
- 等价于 :
imageDims.width
5. imageHeight: number
- 类型 :
number - 含义: 原始图像高度(快捷属性)
- 等价于 :
imageDims.height
6. relativeBox: Box
- 类型 :
Box对象 - 含义: 相对坐标边界框(归一化坐标,范围 0, 1)
- 用途: 用于在不同尺寸的图像间转换坐标
7. classScore: number
- 类型 :
number - 含义: 类别分数(对于 FaceDetection,等于 score)
- 注意 : 在 FaceDetection 中,
classScore === score
8. className: string
- 类型 :
string - 含义 : 类别名称(对于 FaceDetection,为空字符串
'') - 注意: 因为只检测人脸这一种类别,所以为空
主要方法
1. forSize(width: number, height: number): FaceDetection
- 功能: 将检测结果转换为指定尺寸图像的坐标
- 参数 :
width: 目标图像宽度height: 目标图像高度
- 返回值 : 新的
FaceDetection对象,坐标已按比例缩放 - 使用场景: 在不同尺寸的图像上绘制检测结果
Box 类提供的方法(通过 box 属性访问)
坐标转换方法
1. box.round(): Box
- 功能: 将坐标四舍五入为整数
- 返回: 新的 Box 对象
2. box.floor(): Box
- 功能: 将坐标向下取整为整数
- 返回: 新的 Box 对象
3. box.toSquare(): Box
- 功能: 将边界框转换为正方形(以较大边为准)
- 返回: 新的 Box 对象
4. box.rescale(scale: IDimensions | number): Box
- 功能: 按比例缩放边界框
- 参数 :
scale: 缩放因子(可以是数字或 Dimensions 对象)
- 返回: 新的 Box 对象
5. box.pad(padX: number, padY: number): Box
- 功能: 在边界框周围添加填充
- 参数 :
padX: X 方向的填充量padY: Y 方向的填充量
- 返回: 新的 Box 对象
6. box.clipAtImageBorders(imgWidth: number, imgHeight: number): Box
- 功能: 将边界框裁剪到图像边界内,防止越界
- 参数 :
imgWidth: 图像宽度imgHeight: 图像高度
- 返回: 新的 Box 对象
7. box.shift(sx: number, sy: number): Box
- 功能: 平移边界框
- 参数 :
sx: X 方向的偏移量sy: Y 方向的偏移量
- 返回: 新的 Box 对象
8. box.calibrate(region: Box): Box
- 功能: 根据区域校准边界框
- 返回: 新的 Box 对象
数据结构示例
typescript
// 创建一个 FaceDetection 对象
const detection = new FaceDetection(
0.95, // score: 置信度 95%
new Rect(100, 150, 200, 200), // relativeBox: 归一化坐标
{ width: 800, height: 600 } // imageDims: 原始图像尺寸
)
// 对象结构:
{
score: 0.95,
box: {
x: 100,
y: 150,
width: 200,
height: 200,
left: 100,
top: 150,
right: 300,
bottom: 350,
area: 40000,
topLeft: Point(100, 150),
topRight: Point(300, 150),
bottomLeft: Point(100, 350),
bottomRight: Point(300, 350)
},
imageDims: {
width: 800,
height: 600
},
imageWidth: 800,
imageHeight: 600,
relativeBox: Box(...), // 归一化坐标
classScore: 0.95,
className: ''
}使用示例
示例1:基本属性访问
typescript
const detections = await detectAllFaces(image)
const detection = detections[0]
// 访问置信度
console.log('置信度:', detection.score) // 0.95
// 访问位置
console.log('位置:', detection.box.x, detection.box.y) // 100, 150
console.log('尺寸:', detection.box.width, detection.box.height) // 200, 200
// 访问边界
console.log('左边界:', detection.box.left) // 100
console.log('上边界:', detection.box.top) // 150
console.log('右边界:', detection.box.right) // 300
console.log('下边界:', detection.box.bottom) // 350
// 访问图像尺寸
console.log('图像尺寸:', detection.imageWidth, detection.imageHeight) // 800, 600示例2:使用 Box 方法
typescript
const detection = await detectAllFaces(image)[0]
// 转换为正方形
const squareBox = detection.box.toSquare()
// 四舍五入坐标
const roundedBox = detection.box.round()
// 裁剪到图像边界
const clippedBox = detection.box.clipAtImageBorders(800, 600)
// 添加填充
const paddedBox = detection.box.pad(10, 10)
// 缩放
const scaledBox = detection.box.rescale(0.5) // 缩小到 50%示例3:坐标转换
typescript
const detection = await detectAllFaces(originalImage)[0]
// detection.box.x = 200(原始图像 800x600)
// 转换到不同尺寸的图像
const resized = detection.forSize(400, 300)
// resized.box.x = 100(缩放后的图像 400x300)示例4:绘制检测结果
typescript
const detections = await detectAllFaces(image)
detections.forEach(detection => {
// 获取边界框
const { x, y, width, height } = detection.box
// 在 Canvas 上绘制
ctx.strokeRect(x, y, width, height)
ctx.fillText(
`置信度: ${(detection.score * 100).toFixed(1)}%`,
x,
y - 5
)
})属性访问方式对比
Rect 格式(x, y, width, height)
typescript
detection.box.x // 左上角 X
detection.box.y // 左上角 Y
detection.box.width // 宽度
detection.box.height // 高度BoundingBox 格式(left, top, right, bottom)
typescript
detection.box.left // 左边界
detection.box.top // 上边界
detection.box.right // 右边界
detection.box.bottom // 下边界点坐标
typescript
detection.box.topLeft // Point(100, 150)
detection.box.topRight // Point(300, 150)
detection.box.bottomLeft // Point(100, 350)
detection.box.bottomRight // Point(300, 350)总结
FaceDetection 的核心信息:
- ✅ 置信度 :
score(0-1) - ✅ 位置和尺寸 :
box(包含 x, y, width, height 等) - ✅ 图像尺寸 :
imageDims(用于坐标转换)
常用操作:
- 访问位置:
detection.box.x,detection.box.y - 访问尺寸:
detection.box.width,detection.box.height - 坐标转换:
detection.forSize(width, height) - 边界处理:
detection.box.clipAtImageBorders()