引言
Spring AI 与向量数据库的组合,为构建企业级智能问答系统提供了理想解决方案。Spring AI 依托 Spring 生态的成熟性与易用性,将复杂的 AI 能力封装为标准化组件,大幅降低了 AI 应用的开发门槛,同时确保了系统与企业现有 Spring 技术栈的无缝集成;向量数据库则解决了传统结构化数据库无法高效处理语义检索的痛点,能够将文本、文档等非结构化数据转化为高维向量并进行快速匹配,为检索增强生成(RAG)提供了核心的数据检索能力。两者的结合,既保证了系统开发的高效性与稳定性,又确保了问答结果的准确性与时效性,成为企业级 RAG 系统构建的优选技术路径。


- 引言
- 目录
- 一、核心技术解析
-
- [1.1 检索增强生成(RAG):提升问答准确性的核心架构](#1.1 检索增强生成(RAG):提升问答准确性的核心架构)
- [1.2 Spring AI:简化 AI 应用开发的标准化框架](#1.2 Spring AI:简化 AI 应用开发的标准化框架)
- [1.3 向量数据库:语义搜索的核心引擎](#1.3 向量数据库:语义搜索的核心引擎)
- [二、 实施步骤:构建企业级 RAG 智能问答系统](#二、 实施步骤:构建企业级 RAG 智能问答系统)
-
- [2.1 环境准备](#2.1 环境准备)
-
- [2.1.1 依赖配置(pom.xml)](#2.1.1 依赖配置(pom.xml))
- [2.1.2 配置文件(application.yml)](#2.1.2 配置文件(application.yml))
- [2.2 核心代码实现](#2.2 核心代码实现)
-
- [2.2.1 数据准备:企业知识库样本数据](#2.2.1 数据准备:企业知识库样本数据)
- [2.2.2 向量入库:将知识库数据转化为向量并存储到 Weaviate](#2.2.2 向量入库:将知识库数据转化为向量并存储到 Weaviate)
- [2.2.3 RAG 核心服务:检索增强生成问答](#2.2.3 RAG 核心服务:检索增强生成问答)
- [2.2.4 接口暴露:Web 接口供前端调用](#2.2.4 接口暴露:Web 接口供前端调用)
- [2.2.5 测试验证](#2.2.5 测试验证)
- 三、任务流可视化
- 四、优化策略与挑战
-
- [4.1 优化策略](#4.1 优化策略)
-
- [4.1.1 向量数据库索引优化](#4.1.1 向量数据库索引优化)
- [4.1.2 检索策略优化](#4.1.2 检索策略优化)
- [4.1.3 模型与提示词优化](#4.1.3 模型与提示词优化)
- [4.1.4 缓存优化](#4.1.4 缓存优化)
- [4.2 挑战与应对措施](#4.2 挑战与应对措施)
-
- [4.2.1 知识库数据更新与同步挑战](#4.2.1 知识库数据更新与同步挑战)
- [4.2.2 语义歧义与多义词问题](#4.2.2 语义歧义与多义词问题)
- [4.2.3 性能与并发挑战](#4.2.3 性能与并发挑战)
- [4.2.4 数据安全与隐私挑战](#4.2.4 数据安全与隐私挑战)
- 五、总结
目录
一、核心技术解析
1.1 检索增强生成(RAG):提升问答准确性的核心架构
检索增强生成(Retrieval-Augmented Generation,RAG)是一种融合了信息检索与生成式 AI 的技术架构,其核心目标是解决纯生成式模型在企业场景下的"知识滞后"与"事实性错误"问题。传统生成式模型依赖训练数据中的知识,若训练数据未覆盖企业最新业务数据(如内部政策、产品更新、行业动态等),则无法生成准确答案;而 RAG 通过在生成答案前,先从企业私有知识库中检索与问题最相关的信息,并将这些信息作为"上下文"输入给生成模型,引导模型基于权威、最新的信息生成答案,从而大幅提升问答的准确性与可信度。
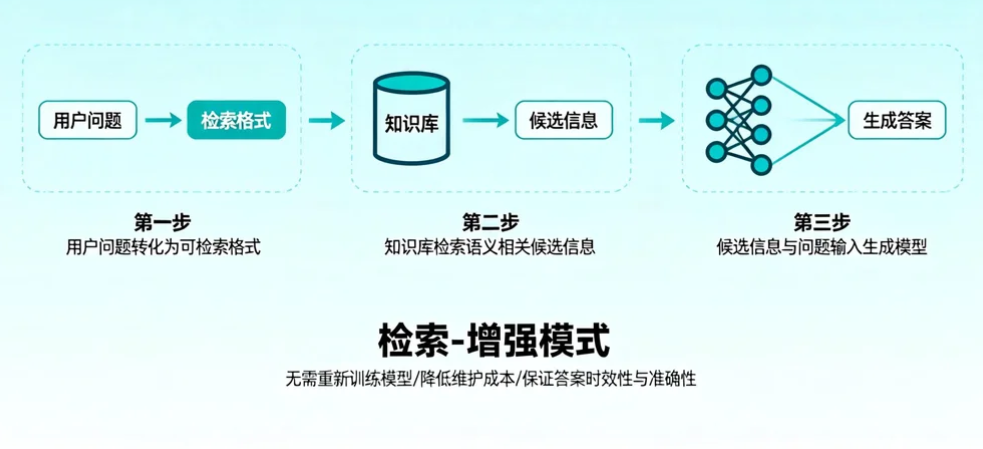
RAG 的工作逻辑可概括为三步:
- 首先,将用户问题转化为可检索的格式;
- 其次,从知识库中检索与问题语义相关的候选信息;
- 最后,将候选信息与问题一同输入生成模型,生成针对性答案。这种"检索-增强"的模式,使得系统无需重新训练模型即可同步企业最新数据,显著降低了模型维护成本,同时保证了答案的时效性与准确性。
1.2 Spring AI:简化 AI 应用开发的标准化框架
Spring AI 是 Spring 生态下的 AI 开发框架,其核心定位是"让 AI 应用开发像 Spring 应用开发一样简单"。它通过对主流 AI 模型(如 OpenAI、Claude、本地开源模型等)、向量数据库、检索工具等能力进行抽象与封装,提供了标准化的 API 与组件,开发者无需关注底层 AI 模型的调用细节、向量转换的复杂逻辑,即可快速构建 AI 应用。
Spring AI 的关键模块包括:
-
模型抽象模块:对生成式模型(Generative Model)、嵌入模型(Embedding Model)进行统一抽象,支持快速切换不同厂商的模型(如从 OpenAI Embeddings 切换为本地化的 BERT 嵌入模型),降低了对特定 AI 服务的依赖。
-
检索模块(Retrieval):提供了检索器(Retriever)接口,封装了与各类向量数据库的交互逻辑,支持语义检索、过滤检索等多种检索方式,可直接集成到 RAG 架构中。
-
提示词工程模块(Prompt Engineering):提供了 Prompt 模板、Prompt 增强等工具,帮助开发者规范化提示词设计,提升生成模型的响应质量。
-
集成与适配模块:无缝集成 Spring Boot、Spring Cloud 等现有 Spring 组件,支持配置化管理 AI 模型密钥、向量数据库连接信息等,适配企业级应用的部署与运维需求。

1.3 向量数据库:语义搜索的核心引擎
向量数据库是专门用于存储、管理与检索高维向量数据的数据库系统。在 RAG 系统中,它的核心作用是实现"语义搜索"------即基于文本的语义含义而非关键词进行匹配,这是传统关系型数据库(如 MySQL)无法高效完成的。
其基本原理可分为三步:
-
向量转换:通过嵌入模型(Embedding Model)将非结构化文本(如企业文档、知识库文章)转化为固定维度的高维向量(嵌入向量),向量的每一个维度都对应文本的一个语义特征,语义相近的文本会转化为距离相近的向量。
-
向量存储与索引:向量数据库将生成的嵌入向量存储起来,并构建专门的向量索引(如 IVF、HNSW 等)。这些索引结构能够大幅提升高维向量的检索效率,避免全量向量比对带来的性能问题。
-
语义匹配检索:当用户提出问题时,系统先将问题转化为嵌入向量,然后通过向量数据库的检索接口,计算问题向量与数据库中所有文本向量的相似度(如余弦相似度),快速返回相似度最高的候选文本。
主流的向量数据库包括 Weaviate、Pinecone、Chroma、Milvus 等,它们各自具备不同的优势:Weaviate 支持丰富的过滤条件与 GraphQL 查询,适合复杂业务场景;Pinecone 提供全托管服务,无需关注底层运维;Chroma 轻量易用,适合开发与测试环境;Milvus 则具备高扩展性与高并发处理能力,适合大规模企业级部署。
二、 实施步骤:构建企业级 RAG 智能问答系统
本部分将以 Java 语言为例,结合 Spring Boot 与 Spring AI,实现一个完整的 RAG 智能问答系统。选用 Weaviate 作为向量数据库(开源、易部署),嵌入模型选用 OpenAI Embeddings(也可替换为本地化模型如 BERT),生成模型选用 OpenAI GPT-3.5。
2.1 环境准备
2.1.1 依赖配置(pom.xml)
xml
<!-- Spring Boot 核心依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!-- Spring AI 核心依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-core</artifactId>
</dependency>
<!-- Spring AI OpenAI 依赖(生成模型 + 嵌入模型) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai</artifactId>
</dependency>
<!-- Spring AI Weaviate 依赖(向量数据库集成) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-weaviate</artifactId>
</dependency>
<!-- 测试依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>2.1.2 配置文件(application.yml)
yaml
spring:
# Spring AI 配置
ai:
# OpenAI 配置
openai:
api-key: ${OPENAI_API_KEY} # 替换为你的 OpenAI API Key
embedding:
model: text-embedding-3-small # 嵌入模型
chat:
model: gpt-3.5-turbo # 生成模型
temperature: 0.3 # 控制生成文本的随机性,0.3 更偏向精准
# Weaviate 配置
weaviate:
endpoint: http://localhost:8080 # Weaviate 服务地址(本地部署)
api-key: ${WEAVIATE_API_KEY} # Weaviate 访问密钥(若未设置则留空)
schema:
name: EnterpriseKnowledge # 向量数据库中的数据模式(类似表名)
vector-property: contentEmbedding # 存储嵌入向量的字段名2.2 核心代码实现
实现流程:数据准备 → 嵌入向量生成与入库 → 问题预处理 → 向量数据库检索 → 生成答案。
2.2.1 数据准备:企业知识库样本数据
这里以企业内部政策文档为例,模拟知识库数据(实际场景中可从 PDF、Word、数据库等来源加载)。
java
import org.springframework.stereotype.Component;
import java.util.List;
/**
* 企业知识库数据提供类
*/
@Component
public class EnterpriseKnowledgeBase {
/**
* 获取知识库样本数据
* @return 文档列表(含文档内容与标题)
*/
public List<Document> getKnowledgeDocs() {
return List.of(
new Document("员工考勤政策", "员工每日上下班需打卡,早班打卡时间为 8:30 前,晚班打卡时间为 17:30 后;每月允许 2 次迟到,单次迟到不超过 15 分钟,超过则按事假处理;旷工 1 天扣除当日工资的 2 倍。"),
new Document("差旅费报销标准", "国内出差交通费用:高铁二等座、飞机经济舱可全额报销;住宿费用:一线城市(北京、上海、广州、深圳)每日不超过 800 元,二线城市每日不超过 500 元,三线及以下城市每日不超过 300 元;报销需在出差结束后 7 个工作日内提交材料。"),
new Document("员工培训政策", "企业为正式员工提供年度培训补贴,最高 5000 元/人;培训结束后需提交培训总结,若培训费用超过补贴金额,超出部分需个人承担 30%;培训期间的考勤按正常上班处理。"),
new Document("绩效考核制度", "绩效考核分为季度考核与年度考核,权重分别为 30% 与 70%;考核指标包括工作业绩(60%)、工作态度(20%)、团队协作(20%);考核结果分为优秀、合格、不合格三个等级,优秀员工可获得年终奖金 10% 的额外奖励。")
);
}
/**
* 文档实体类(封装文档标题与内容)
*/
public static class Document {
private String title;
private String content;
public Document(String title, String content) {
this.title = title;
this.content = content;
}
// getter 与 setter
public String getTitle() { return title; }
public void setTitle(String title) { this.title = title; }
public String getContent() { return content; }
public void setContent(String content) { this.content = content; }
}
}2.2.2 向量入库:将知识库数据转化为向量并存储到 Weaviate
java
import org.springframework.ai.embedding.EmbeddingClient;
import org.springframework.ai.weaviate.WeaviateClient;
import org.springframework.ai.weaviate.WeaviateDocument;
import org.springframework.boot.CommandLineRunner;
import org.springframework.stereotype.Component;
import java.util.Map;
/**
* 知识库数据初始化(应用启动时执行,将文档转化为向量并入库)
*/
@Component
public class KnowledgeBaseInitializer implements CommandLineRunner {
private final EmbeddingClient embeddingClient; // Spring AI 嵌入客户端(生成向量)
private final WeaviateClient weaviateClient; // Weaviate 客户端(向量存储与检索)
private final EnterpriseKnowledgeBase knowledgeBase; // 知识库数据
// 构造函数注入依赖(Spring 自动装配)
public KnowledgeBaseInitializer(EmbeddingClient embeddingClient, WeaviateClient weaviateClient, EnterpriseKnowledgeBase knowledgeBase) {
this.embeddingClient = embeddingClient;
this.weaviateClient = weaviateClient;
this.knowledgeBase = knowledgeBase;
}
@Override
public void run(String... args) throws Exception {
// 1. 获取知识库文档
var docs = knowledgeBase.getKnowledgeDocs();
// 2. 遍历文档,生成嵌入向量并入库
for (var doc : docs) {
// 2.1 生成文档内容的嵌入向量(语义特征提取)
var embedding = embeddingClient.embed(doc.getContent()).getResult();
// 2.2 构建 Weaviate 文档(封装文档属性与向量)
WeaviateDocument weaviateDoc = WeaviateDocument.builder()
.withProperty("title", doc.getTitle()) // 文档标题(用于后续展示)
.withProperty("content", doc.getContent()) // 文档内容(原始文本)
.withVector(embedding) // 嵌入向量
.build();
// 2.3 存入 Weaviate(若已存在则更新)
weaviateClient.createOrUpdate(weaviateDoc);
}
System.out.println("知识库数据初始化完成,共入库 " + docs.size() + " 篇文档");
}
}2.2.3 RAG 核心服务:检索增强生成问答
java
import org.springframework.ai.chat.ChatClient;
import org.springframework.ai.chat.ChatResponse;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.weaviate.WeaviateClient;
import org.springframework.ai.weaviate.WeaviateDocument;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Map;
/**
* RAG 核心服务:整合检索与生成,实现智能问答
*/
@Service
public class RagQAService {
private final WeaviateClient weaviateClient; // 向量数据库检索客户端
private final ChatClient chatClient; // 生成模型客户端(GPT-3.5)
// 构造函数注入依赖
public RagQAService(WeaviateClient weaviateClient, ChatClient chatClient) {
this.weaviateClient = weaviateClient;
this.chatClient = chatClient;
}
/**
* 智能问答核心方法
* @param userQuestion 用户问题
* @return 精准回答
*/
public String answer(String userQuestion) {
// 步骤 1:检索与问题最相关的文档(语义检索)
List<WeaviateDocument> relevantDocs = retrieveRelevantDocs(userQuestion, 2); // 获取Top 2 最相关文档
// 步骤 2:构建提示词(将检索到的文档作为上下文传入生成模型)
String promptTemplate = """
请基于以下企业内部文档内容,回答用户的问题。
若文档内容无法回答用户问题,请直接说明"无法找到相关信息",不要编造答案。
文档内容:
{context}
用户问题:{question}
""";
// 拼接所有相关文档的内容作为上下文
String context = relevantDocs.stream()
.map(doc -> doc.getProperty("content", String.class))
.reduce("", (a, b) -> a + "\n" + b);
// 填充提示词模板
PromptTemplate promptTemplateObj = new PromptTemplate(promptTemplate,
Map.of("context", context, "question", userQuestion));
Prompt prompt = promptTemplateObj.create();
// 步骤 3:调用生成模型,生成精准回答
ChatResponse response = chatClient.call(prompt);
return response.getResult().getOutput().getContent();
}
/**
* 语义检索:从 Weaviate 中获取与问题最相关的文档
* @param question 用户问题
* @param topK 获取前 K 个最相关文档
* @return 相关文档列表
*/
private List<WeaviateDocument> retrieveRelevantDocs(String question, int topK) {
// Weaviate 语义检索:基于问题的语义向量匹配相关文档
return weaviateClient.similaritySearch(
question, // 检索查询词(会自动转化为向量)
topK, // 返回 Top K 结果
"content" // 检索的字段(文档内容)
);
}
}2.2.4 接口暴露:Web 接口供前端调用
java
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
/**
* 智能问答 Web 接口
*/
@RestController
public class QAController {
private final RagQAService ragQAService;
public QAController(RagQAService ragQAService) {
this.ragQAService = ragQAService;
}
/**
* 问答接口
* @param question 用户问题(通过请求参数传入)
* @return 回答结果
*/
@GetMapping("/qa")
public String qa(@RequestParam String question) {
return ragQAService.answer(question);
}
}2.2.5 测试验证
启动 Spring Boot 应用后,通过浏览器或 Postman 调用接口进行测试:
请求地址:http://localhost:8080/qa?question=员工出差住宿费用一线城市最高多少
预期响应:一线城市(北京、上海、广州、深圳)每日住宿费用不超过 800 元。
三、任务流可视化
以下使用 Mermaid 语法绘制 RAG 智能问答系统的完整任务流程图,清晰展示从用户提问到输出回答的全流程:
- 清洗问题(去空格、特殊字符) 2. 通过 Spring AI 嵌入模型转化 3. 计算问题向量与文档向量相似度,获取 Top K 相关文档 4. 将相关文档作为上下文拼接至提示词模板 5. 调用 GPT-3.5 等模型,基于上下文生成答案 用户提出问题
文本预处理
生成问题嵌入向量
向量数据库语义检索
构建增强提示词
生成模型推理
输出最终回答
四、优化策略与挑战
4.1 优化策略
4.1.1 向量数据库索引优化
向量数据库的检索效率直接影响系统响应速度,合理的索引设计是关键:
-
选用合适的索引类型:对于中小规模知识库(10 万条以内数据),可选用 HNSW(Hierarchical Navigable Small Worlds)索引,兼顾检索速度与准确性;对于大规模数据(100 万条以上),可选用 IVF(Inverted File)索引,通过聚类降低检索复杂度。
-
调整索引参数:例如 HNSW 索引的
efConstruction(构建索引时的探索深度)与ef(检索时的探索深度)参数,增大参数可提升准确性,但会降低速度,需根据业务需求平衡(建议efConstruction=200,ef=100为默认最优值)。
4.1.2 检索策略优化
-
动态 Top K 调整:根据问题复杂度动态调整返回的相关文档数量(简单问题 K=1-2,复杂问题 K=3-5),避免过多无关文档干扰生成模型。
-
过滤检索增强:结合文档的元数据(如文档类型、发布时间、部门归属)进行过滤,例如用户询问"销售部门的差旅费标准",可先过滤出归属"销售部"的文档再进行语义检索,提升检索精准度。
4.1.3 模型与提示词优化
-
嵌入模型选型:对于企业私有数据,可选用本地化的开源嵌入模型(如 BERT、Sentence-BERT 的企业定制版),避免数据外泄,同时通过微调模型提升对企业特定术语的语义理解能力。
-
提示词模板优化:设计更精准的提示词规则,例如明确要求模型"只使用提供的上下文信息""回答简洁,不超过 3 句话""若上下文冲突,以最新发布的文档为准",提升生成答案的质量与一致性。
4.1.4 缓存优化
对于高频重复问题(如"员工考勤打卡时间"),可添加缓存层(如 Redis),将检索结果与生成答案缓存起来,后续相同问题直接从缓存获取,大幅降低向量数据库与生成模型的调用成本,提升响应速度。
4.2 挑战与应对措施
4.2.1 知识库数据更新与同步挑战
企业知识库数据会持续更新(如政策调整、产品迭代),如何确保向量数据库中的数据与原始知识库同步,是系统长期稳定运行的关键。
应对措施:
-
建立增量更新机制:通过监听知识库的文件变更(如 PDF 新增/修改)或数据库变更,触发增量向量生成与入库,避免全量重新生成向量。
-
定期全量校验:每周/每月执行一次全量知识库与向量数据库的比对,发现不一致数据(如原始文档修改后未同步向量),自动触发向量更新。
4.2.2 语义歧义与多义词问题
用户问题中可能存在语义歧义或多义词(如"打卡"可能指考勤打卡,也可能指工作任务打卡),导致检索到不相关文档,影响回答准确性。
应对措施:
-
问题意图识别增强:在文本预处理阶段,引入意图识别模型(如基于 BERT 的分类模型),对用户问题进行意图分类(如"考勤咨询""报销咨询""培训咨询"),结合意图进行检索过滤。
-
多轮对话澄清:对于存在歧义的问题,生成模型可主动向用户澄清,例如"你询问的'打卡'是指考勤打卡还是任务打卡?",提升回答精准度。
4.2.3 性能与并发挑战
企业级应用可能面临高并发查询(如高峰期 1000+ 并发请求),向量数据库检索与生成模型调用的性能瓶颈会导致系统响应延迟。
应对措施:
-
向量数据库集群部署:通过 Weaviate/Milvus 的集群模式,实现负载均衡与高可用,提升并发检索能力。
-
生成模型批量调用:对于相似的并发问题,进行批量合并后调用生成模型(如 OpenAI 支持批量请求),降低模型调用次数,提升处理效率。
-
多级缓存架构:引入 L1(本地缓存)+ L2(分布式缓存 Redis)缓存,高频问题直接从 L1 缓存获取,进一步提升并发处理能力。
4.2.4 数据安全与隐私挑战
企业知识库包含大量敏感数据(如财务政策、核心业务流程),使用第三方生成模型(如 OpenAI)时,存在数据外泄风险。
应对措施:
-
本地化部署:将嵌入模型与生成模型(如开源的 Llama 3、Qwen)部署在企业内网,避免数据传输至第三方服务。
-
数据脱敏:对知识库中的敏感信息(如员工姓名、部门编号、金额细节)进行脱敏处理后,再生成向量与调用生成模型。
-
权限控制:在接口层添加用户权限校验,不同部门用户只能查询本部门相关的知识库内容,避免敏感数据跨部门泄露。
五、总结
Spring AI 与向量数据库的结合,为企业级 RAG 智能问答系统的构建提供了高效、可靠的技术路径。Spring AI 通过标准化的组件封装,大幅降低了 AI 模型调用、语义检索等复杂功能的开发门槛,确保了系统与企业现有 Spring 技术栈的无缝集成;向量数据库则突破了传统结构化数据库的语义检索瓶颈,实现了基于文本含义的精准匹配,为 RAG 架构提供了核心的数据检索能力。
这种技术组合带来的优势显而易见:一是提升了问答准确性,通过检索企业最新、最权威的私有数据作为上下文,避免了纯生成模型的事实性错误与知识滞后问题;二是降低了开发与运维成本,Spring AI 的标准化 API 与向量数据库的全托管/开源部署模式,简化了系统搭建与长期维护;三是保障了系统的扩展性与安全性,支持模型与向量数据库的集群部署,同时可通过本地化部署与数据脱敏满足企业数据安全需求。
在数字化转型的浪潮中,企业对智能问答系统的需求将持续增长。Spring AI 与向量数据库的深度融合,不仅能够帮助企业快速落地智能问答应用,更能为后续的 AI 赋能业务(如智能客服、智能决策支持、知识管理系统)奠定坚实基础,成为企业数字化转型的核心技术支撑之一。
✨ 坚持用 清晰易懂的图解 + 代码语言, 让每个知识点都 简单直观 !
🚀 个人主页 :不呆头 · CSDN
🌱 代码仓库 :不呆头 · Gitee
📌 专栏系列 :
💬 座右铭 : "不患无位,患所以立。"
