在人工智能和大数据时代,高效准确处理海量多模态数据成为一个挑战。
Aurelio Labs开源的Semantic Chunkers库应运而生,针对文本、视频和音频进行智能分块。
https://github.com/aurelio-labs/semantic-chunkers
https://github.com/aurelio-labs/semantic-router
1 应用场景
对于海量非结构化数据,Semantic Chunkers提供智能和高效的数据切分方案,为数据挖掘和分析提供基础。通过语义化的分块,Semantic Chunkers可以提高搜索引擎的精准度,使用户能够更快速地找到所需的信息片段。
具体如下:
1.1 自然语言处理
Semantic Chunkers用于预处理大规模文本数据。
智能地将长文本分割成语义连贯的片段,有利于后续的文本分类、命名实体识别等任务。
1.2 视频内容分析
对于视频,Semantic Chunkers根据场景变化或语义转折点进行智能分段。
这对于视频摘要、内容检索和视频推荐系统都有重要意义。
1.3 语音识别和处理
在语音处理,Semantic Chunkers帮助识别语音中语义单元,便于后续语音转文字或语音理解。
2 技术实现
Semantic Chunkers核心是智能分块算法,主要包括以下关键步骤。
1)编码(Encoding)
将输入的文本、视频或音频内容转换为向量表示。这一步通常使用预训练的神经网络模型来完成。
2)相似度计算
计算相邻内容片段之间语义相似度。通过计算向量之间的余弦相似度或其他相似度度量来实现。
3)边界检测
根据相似度的变化趋势,识别出语义边界。通常,相似度的显著下降表示可能存在一个语义边界。
4)自适应阈值
使用动态阈值来决定是否在某个位置进行分块。这个阈值会根据内容的整体特征自动调整。
5)后处理
对初步的分块结果进行优化,例如合并过短的块或分割过长的块,以保证最终分块的质量和均衡性。
3 应用示例
这里通过具体例子,示例Semantic Chunkers的分块过程。
3.1 文本分块
安装senmantic-chunkers、datasets、senmantic-router模块。
由于计划使用ollama模型,所以需要安装'semantic-routerollama'模块。
!pip install -qU \
semantic-chunkers \
datasets==2.19.1
!pip install -qU 'semantic-router[ollama]'下载数据,这里从hf-mirror.com下载,所以需要设置HF_ENDPOINT
import os
os.environ['HF_ENDPOINT'] = "https://hf-mirror.com"
from datasets import load_dataset
data = load_dataset("jamescalam/ai-arxiv2", split="train")
content = data[3]["content"]
print(content[:1000])
content = content[:20_000]设置encoder,这里采用OllamaEncoder,连接ollama服务器创建encoder
import os
from getpass import getpass
from semantic_router.encoders import OllamaEncoder
encoder = OllamaEncoder(name="qllama/bce-embedding-base_v1:latest", base_url="http://localhost:11434")StatisticalChunker是senmatic_chunkers最好分块工具,通过相似度计算确定分块位置。
代码示例如下
from semantic_chunkers import StatisticalChunker
chunker = StatisticalChunker(encoder=encoder)
chunks = chunker(docs=[content])
chunker.print(chunks[0])输出如下所示
Split 1, tokens 300, triggered by: token limit
Mamba: Linear-Time Sequence Modeling with Selective State Spaces # Albert Gu*1 and Tri Dao*2 1Machine Learning Department, Carnegie Mellon University 2Department of Computer Science, Princeton University agu@cs.cmu.edu, tri@tridao.me # Abstract Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformersâ computational ineï¬ ciency on long sequences, but they have not performed as well as attention on important modalities such as language. We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements. First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token. Second, even though this change prevents the use of eï¬ cient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simpliï¬ ed end-to-end neural network architecture without attention or even MLP blocks (Mamba). Mamba enjoys fast inference (5à higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences.
Split 2, tokens 300, triggered by: token limit
As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation. # 1 Introduction Foundation models (FMs), or large models pretrained on massive data then adapted for downstream tasks, have emerged as an eï¬ ective paradigm in modern machine learning. The backbone of these FMs are often sequence models, operating on arbitrary sequences of inputs from a wide variety of domains such as language, images, speech, audio, time series, and genomics (Brown et al. 2020; Dosovitskiy et al. 2020; Ismail Fawaz et al. 2019; Oord et al. 2016; Poli et al. 2023; Sutskever, Vinyals, and Quoc V Le 2014). While this concept is agnostic to a particular choice of model architecture, modern FMs are predominantly based on a single type of sequence model: the Transformer (Vaswani et al. 2017) and its core attention layer (Bahdanau, Cho, and Bengio 2015) The eï¬ cacy of self-attention is attributed to its ability to route information densely within a context window, allowing it to model complex data.
Split 3, tokens 239, triggered by: 0.30
However, this property brings fundamental drawbacks: an inability to model anything outside of a ï¬ nite window, and quadratic scaling with respect to the window length. An enormous body of research has appeared on more eï¬ cient variants of attention to overcome these drawbacks (Tay, Dehghani, Bahri, et al. 2022), but often at the expense of the very properties that makes it eï¬ ective. As of yet, none of these variants have been shown to be empirically eï¬ ective at scale across domains. Recently, structured state space sequence models (SSMs) (Gu, Goel, and Ré 2022; Gu, Johnson, Goel, et al. 2021) have emerged as a promising class of architectures for sequence modeling. These models can be interpreted as a combination of recurrent neural networks (RNNs) and convolutional neural networks (CNNs), with inspiration from classical state space models (Kalman 1960). This class of models can be computed very eï¬ ciently as either a recurrence or convolution, with linear or near-linear scaling in sequence length. Additionally, they have principled
Split 4, tokens 216, triggered by: 0.33
Equal contribution. 1 mechanisms for modeling long-range dependencies (Gu, Dao, et al. 2020) in certain data modalities, and have dominated benchmarks such as the Long Range Arena (Tay, Dehghani, Abnar, et al. 2021). Many ï¬ avors of SSMs (Gu, Goel, and Ré 2022; Gu, Gupta, et al. 2022; Gupta, Gu, and Berant 2022; Y. Li et al. 2023; Ma et al. 2023; Orvieto et al. 2023; Smith, Warrington, and Linderman 2023) have been successful in domains involving continuous signal data such as audio and vision (Goel et al. 2022; Nguyen, Goel, et al. 2022; Saon, Gupta, and Cui 2023). However, they have been less eï¬ ective at modeling discrete and information-dense data such as text.
Split 5, tokens 129, triggered by: 0.36
We propose a new class of selective state space models, that improves on prior work on several axes to achieve the modeling power of Transformers while scaling linearly in sequence length. Selection Mechanism. First, we identify a key limitation of prior models: the ability to eï¬ ciently select data in an input-dependent manner (i.e. focus on or ignore particular inputs). Building on intuition based on important synthetic tasks such as selective copy and induction heads, we design a simple selection mechanism by parameterizing the SSM parameters based on the input. This allows the model to ï¬ lter out irrelevant information and remember relevant information indeï¬
Split 6, tokens 145, triggered by: 0.34
nitely. Hardware-aware Algorithm. This simple change poses a technical challenge for the computation of the model; in fact, all prior SSMs models must be time- and input-invariant in order to be computationally eï¬ cient. We overcome this with a hardware-aware algorithm that computes the model recurrently with a scan instead of convolution, but does not materialize the expanded state in order to avoid IO access between diï¬ erent levels of the GPU memory hierarchy. The resulting implementation is faster than previous methods both in theory (scaling linearly in sequence length, compared to pseudo-linear for all convolution-based SSMs) and on modern hardware (up to 3à faster on A100 GPUs).
Split 7, tokens 179, triggered by: 0.32
Architecture. We simplify prior deep sequence model architectures by combining the design of prior SSM architectures (Dao, Fu, Saab, et al. 2023) with the MLP block of Transformers into a single block, leading to a simple and homogenous architecture design (Mamba) incorporating selective state spaces. Selective SSMs, and by extension the Mamba architecture, are fully recurrent models with key properties that make them suitable as the backbone of general foundation models operating on sequences. (i) High quality: selectivity brings strong performance on dense modalities such as language and genomics. (ii) Fast training and inference: computation and memory scales linearly in sequence length during training, and unrolling the model autoregressively during inference requires only constant time per step since it does not require a cache of previous elements. (iii) Long context: the quality and eï¬
Split 8, tokens 100, triggered by: 0.34
ciency together yield performance improvements on real data up to sequence length 1M. We empirically validate Mambaâ s potential as a general sequence FM backbone, in both pretraining quality and domain-speciï¬ c task performance, on several types of modalities and settings: â ¢ Synthetics. On important synthetic tasks such as copying and induction heads that have been proposed as being key to large language models, Mamba not only solves them easily but can extrapolate solutions indeï¬
Split 9, tokens 261, triggered by: 0.27
nitely long (>1M tokens). â ¢ Audio and Genomics. Mamba out-performs prior state-of-the-art models such as SaShiMi, Hyena, and Transform- ers on modeling audio waveforms and DNA sequences, both in pretraining quality and downstream metrics (e.g. reducing FID on a challenging speech generation dataset by more than half). In both settings, its performance improves with longer context up to million-length sequences. â ¢ Language Modeling. Mamba is the ï¬ rst linear-time sequence model that truly achieves Transformer-quality performance, both in pretraining perplexity and downstream evaluations. With scaling laws up to 1B parameters, we show that Mamba exceeds the performance of a large range of baselines, including very strong modern Transformer training recipes based on LLaMa (Touvron et al. 2023). Our Mamba language model has 5à generation throughput compared to Transformers of similar size, and Mamba-3Bâ s quality matches that of Transformers twice its size (e.g. 4 points higher avg. on common sense reasoning compared to Pythia-3B and even exceeding Pythia-7B). Model code and pre-trained checkpoints are open-sourced at https://github.com/state-spaces/mamba.
...
另外,还可以选择ConsecutiveChunker、RegexChunker等,代码示例如下所示。
ConsecutiveChunker
from semantic_chunkers import ConsecutiveChunker
chunker = ConsecutiveChunker(encoder=encoder, score_threshold=0.3)
chunks = chunker(docs=[content])
chunker.print(chunks[0])RegexChunker
from typing import List
from semantic_chunkers import RegexChunker
from semantic_chunkers.schema import Chunk
chunker = RegexChunker()
chunks: List[List[Chunk]] = chunker(docs=[content])
chunker.print(chunks[0])示例原始参考链接如下
https://github.com/aurelio-labs/semantic-chunkers/blob/main/docs/00-chunkers-intro.ipynb
3.2 视频分块
安装模块
!export HF_ENDPOINT=https://hf-mirror.com
!pip install -qU \
"semantic-chunkers[stats]" \
"semantic-router[vision]==0.0.39" \
opencv-python下载视频
import cv2
vidcap = cv2.VideoCapture("https://www.w3schools.com/html/mov_bbb.mp4")
frames = []
success, image = vidcap.read()
while success:
frames.append(image)
success, image = vidcap.read()
len(frames)转化为PIL图片
from PIL import Image
image_frames = list(map(Image.fromarray, frames))
len(image_frames)加载编码器
VitEncoder默认采用"google/vit-base-patch16-224"编码器。
https://hf-mirror.com/google/vit-base-patch16-224/tree/main
需要先下载到本地,示例如下,否则会因为hf访问异常报错。
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download --resume-download google/vit-base-patch16-224
然后加载编码器,代码示例如下
import torch
from semantic_router.encoders import VitEncoder
device = (
"mps"
if torch.backends.mps.is_available()
else "cuda"
if torch.cuda.is_available()
else "cpu"
)
print(f"Using '{device}'")
encoder = VitEncoder(device=device)然后,就是视频分割,这里采用ConSecutiveChunker
from semantic_chunkers import ConsecutiveChunker
chunker = ConsecutiveChunker(encoder=encoder, score_threshold=0.6)
chunks = chunker(docs=[image_frames])
print(f"{len(chunks[0])} chunks identified")展示分割结果
import matplotlib.pyplot as plt
f, axarr = plt.subplots(len(chunks[0]), 3, figsize=(20, 5))
for i, chunk in enumerate(chunks[0]):
axarr[i, 0].imshow(chunk.splits[0])
num_docs = len(chunk.splits)
mid = num_docs // 2
axarr[i, 1].imshow(chunk.splits[mid])
axarr[i, 2].imshow(chunk.splits[num_docs - 1])输出示例如下所示,可见ConSecutiveChunker较好的按场景语义对视频进行分割。
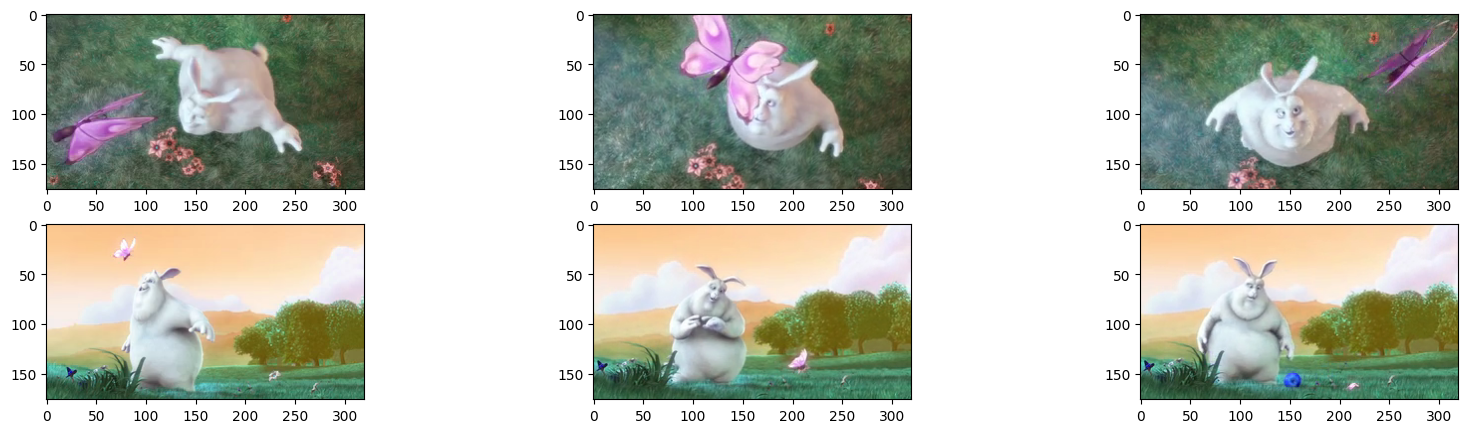
以下是一个复杂例子,需要配置score_threshold,这里设置为0.65
A lower threshold value means that the chunker is more lenient to accepting frames within a
chunk, with threshold 0 meaning all frames are just 1 chunk.Conversely, the higher the threshold value, the stricter the chunker becomes, with threshold 1 putting each frame (besides 100% identical ones) into the same chunk.
For this video, we empirically found a value of
0.65to work the best.
vidcap = cv2.VideoCapture(
"http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/WeAreGoingOnBullrun.mp4"
)
frames = []
success, image = vidcap.read()
while success:
frames.append(image)
success, image = vidcap.read()
image_frames = list(map(Image.fromarray, frames))
print(len(image_frames))
chunker = ConsecutiveChunker(encoder=encoder, score_threshold=0.65)
chunks = chunker(docs=[image_frames])然后输出chunks
import matplotlib.pyplot as plt
f, axarr = plt.subplots(len(chunks[0]), 3, figsize=(20, 60))
for i, chunk in enumerate(chunks[0]):
axarr[i, 0].imshow(chunk.splits[0])
num_docs = len(chunk.splits)
mid = num_docs // 2
axarr[i, 1].imshow(chunk.splits[mid])
axarr[i, 2].imshow(chunk.splits[num_docs - 1])输出部分截图如下所示

示例原始参考链接
https://github.com/aurelio-labs/semantic-chunkers/blob/main/docs/01-video-chunking.ipynb
reference
senmantic-router
https://github.com/aurelio-labs/semantic-router
Semantic Chunkers
https://github.com/aurelio-labs/semantic-chunkers
Semantic Chunkers: 智能文本、视频和音频分块的多模态库
https://www.dongaigc.com/a/semantic-chunkers-multimodal-library
semantic-chunkers
https://pypi.org/project/semantic-chunkers/
Public video url for your test
https://gist.github.com/SeunghoonBaek/f35e0fd3db80bf55c2707cae5d0f7184