文章目录
- 前言
- [一、前置基础:JVM 核心认知(懂概念,能对应线上问题)](#一、前置基础:JVM 核心认知(懂概念,能对应线上问题))
-
- [JVM 运行时数据区(核心关注异常高发区域)](#JVM 运行时数据区(核心关注异常高发区域))
-
- 堆
-
- [一、 堆(Heap)是什么?](#一、 堆(Heap)是什么?)
- [二、 堆(Heap)的具体作用](#二、 堆(Heap)的具体作用)
- [三、 为什么堆最容易出问题?](#三、 为什么堆最容易出问题?)
- 元空间(metaspace,替代永久代,对应图中的方法区)
-
- [一、 元空间是什么?](#一、 元空间是什么?)
- [二、 元空间的具体作用](#二、 元空间的具体作用)
- [三、 为什么元空间容易出问题?](#三、 为什么元空间容易出问题?)
- 虚拟机栈
-
- [一、 虚拟机栈是什么?](#一、 虚拟机栈是什么?)
- [二、 虚拟机栈的具体作用](#二、 虚拟机栈的具体作用)
- [三、 为什么虚拟机栈容易出问题?](#三、 为什么虚拟机栈容易出问题?)
- [GC 基础(懂类型、分代、核心流程)](#GC 基础(懂类型、分代、核心流程))
-
- [一、 GC 分代模型:核心是 "按对象存活时间划分内存,提升回收效率"](#一、 GC 分代模型:核心是 “按对象存活时间划分内存,提升回收效率”)
- [二、 常见垃圾收集器:核心是 "选对场景,无需深究实现"](#二、 常见垃圾收集器:核心是 “选对场景,无需深究实现”)
- [三、 核心认知(运维实操关键)](#三、 核心认知(运维实操关键))
- [二、 核心技能 1:JDK 自带命令行工具(运维必备,实操核心)](#二、 核心技能 1:JDK 自带命令行工具(运维必备,实操核心))
-
- [一、 JDK 核心运维命令详解](#一、 JDK 核心运维命令详解)
-
- [1. `jps`:Java 进程快速查询工具](#1.
jps:Java 进程快速查询工具) - [2. `jstat`:Java 运行状态监控工具](#2.
jstat:Java 运行状态监控工具) - [3. `jstack`:Java 线程堆栈分析工具](#3.
jstack:Java 线程堆栈分析工具) - [4. `jmap`:Java 堆内存分析工具](#4.
jmap:Java 堆内存分析工具) - [5. `jcmd`:Java 多功能综合命令](#5.
jcmd:Java 多功能综合命令)
- [1. `jps`:Java 进程快速查询工具](#1.
- [二、 运维实操实验(掌握 Java 应用问题排查全流程)](#二、 运维实操实验(掌握 Java 应用问题排查全流程))
-
- 实验目标
- 实验环境准备
- 实验步骤(有两个场景)
-
- [场景 1:线程死锁排查(核心命令:jps + jstack + jcmd)](#场景 1:线程死锁排查(核心命令:jps + jstack + jcmd))
- [场景 2:内存泄漏前兆排查(核心命令:jps + jstat + jmap)](#场景 2:内存泄漏前兆排查(核心命令:jps + jstat + jmap))
前言
作为运维工程师,JVM 学习无需深入底层开发实现,核心围绕 "监控异常、定位问题、应急处置、配置优化、日常运维" 展开,重点解决线上 Java 应用的可用性和性能问题
一、前置基础:JVM 核心认知(懂概念,能对应线上问题)
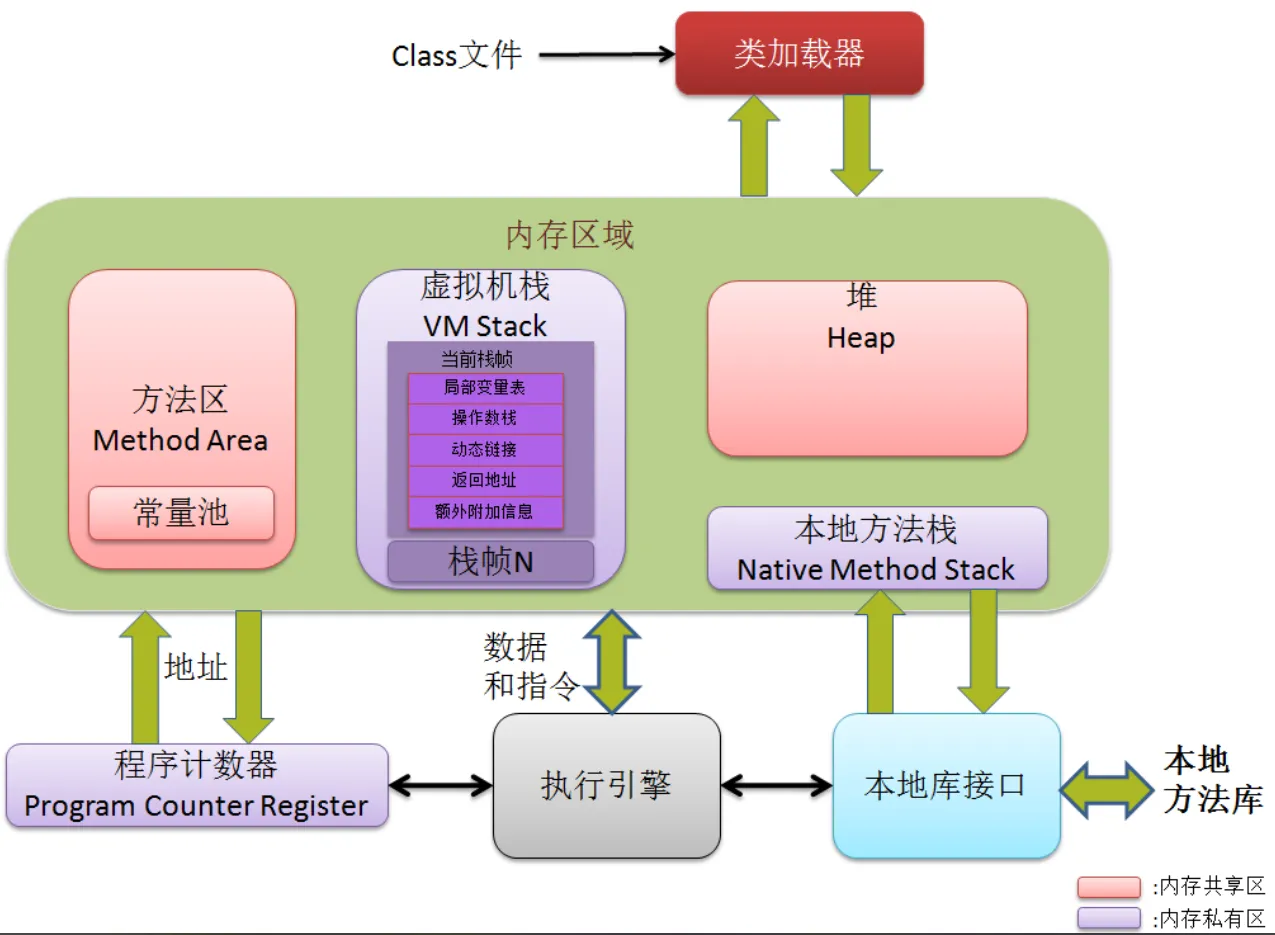
JVM 运行时数据区(核心关注异常高发区域)
- 重点掌握:堆(Heap)、元空间(Metaspace,替代永久代,对应图中的方法区)、虚拟机栈
- 核心对应:
- 堆:OOM 异常(内存溢出 / 泄漏)的核心发生区域,线上最高频问题
- 元空间:动态类加载导致的 OOM 异常(如 Spring Boot 热部署、反射框架)
- 虚拟机栈:StackOverflowError(无限递归)、栈内存不足(业务调用链过长)
- 非重点:程序计数器、本地方法栈(几乎无运维相关异常)
堆
一、 堆(Heap)是什么?
- JVM 运行时最大、全局共享的内存区域(所有 Java 线程共用);
- 启动时由 -Xms 初始化,上限由 -Xmx 控制,逻辑上分为年轻代(Eden+S0+S1)和老年代;
- 专门存储 Java 对象实例(如 new 创建的对象、数组),由 GC 自动回收无用对象,无需手动管理。
二、 堆(Heap)的具体作用
- 核心容器:承载 Java 应用运行时的所有对象实例(业务对象、框架对象等),是应用运行的内存基石;
- 生命周期管理:通过分代模型 + GC,自动完成对象的存活判断、转移(年轻代→老年代)和无用对象回收;
- 保障可用性:堆内存充足与否直接决定应用能否正常运行,内存不足会直接导致应用闪退。
三、 为什么堆最容易出问题?
- 承载压力最大:内存占比最高(占 JVM 总内存 80% 以上),又是全局共享资源,对象创建压力全部集中在此;
- 对象管理复杂:
- 高并发场景下对象创建频繁,若创建速度超过 GC 回收速度,会快速耗尽内存;
- 内存泄漏(无用对象被长期引用)导致 "僵尸对象" 堆积,逐渐耗尽堆内存;
- 大对象直接进入老年代,易快速占满老年代触发 Full GC 甚至 OOM;
- GC 机制存在天然瓶颈:
- 年轻代过小导致 Minor GC 频繁,占用大量 CPU;
- 老年代不足触发 Full GC(STW 停顿),导致应用卡顿;
- 非 G1/ZGC 收集器易产生内存碎片,导致 "内存充足但无法分配大对象" 的 OOM;
- 配置失误高发:-Xms/-Xmx 配置不合理、收集器选型错误等,会放大堆内存问题,加速异常发生。
元空间(metaspace,替代永久代,对应图中的方法区)
一、 元空间是什么?
- JVM 中用于替代永久代的内存区域,本质是本地内存(直接占用服务器物理内存,非 JVM 堆内存);
- 由 XX:MetaspaceSize(初始阈值)和 XX:MaxMetaspaceSize(最大上限)控制,默认无最大上限(可能耗尽系统内存);
- 线程私有(非全局共享),专门存储类的元数据信息,无需手动管理,由 GC 自动回收无用类元数据。
二、 元空间的具体作用
- 存储类元数据:核心承载 Java 类的结构信息(类名、方法定义、字段信息、常量池、注解等);
- 支撑类加载机制:Java 程序运行时(类加载阶段),将类的.class 文件解析后,元数据存入元空间,保障类的正常加载和使用;
- 避免永久代缺陷:突破永久代内存上限限制,减少因类元数据堆积导致的早期 OOM 问题。
三、 为什么元空间容易出问题?
- 配置缺失高发:默认无最大内存上限,若未配置 XX:MaxMetaspaceSize,元空间会持续占用服务器物理内存,最终耗尽系统内存导致应用 / 服务器宕机;
- 类加载异常场景多:
- 动态类加载频繁(如 Spring 热部署、反射框架、ASM 字节码生成、微服务频繁重启),导致类元数据急剧飙升,快速占满元空间;
- 类加载后未正常卸载(如类加载器内存泄漏),无用类元数据无法回收,形成 "僵尸元数据" 堆积;
- 初始阈值配置不合理:XX:MetaspaceSize 过小,导致元空间频繁扩容,每次扩容都会触发 Full GC,造成应用卡顿;
- 监控缺失:运维常聚焦堆内存监控,忽略元空间监控,异常发生前无预警,出现问题时已导致应用闪退。
虚拟机栈
一、 虚拟机栈是什么?
- 线程私有内存区域(每个 Java 线程对应一个独立虚拟机栈,互不干扰);
- 由 -Xss 参数控制单个栈的内存大小(默认 1M),无全局上限;
- 以 "栈帧" 为基本单位,方法调用时创建栈帧、方法执行完销毁栈帧。
二、 虚拟机栈的具体作用
- 支撑方法调用:承载 Java 方法的执行流程,方法调用对应栈帧入栈,方法返回对应栈帧出栈;
- 存储局部数据:每个栈帧中存储方法的局部变量、方法执行状态(如指令指针、操作数栈),保障方法正常执行;
- 隔离线程数据:线程私有特性避免了方法执行过程中的数据干扰,保障多线程运行安全。
三、 为什么虚拟机栈容易出问题?
- 方法调用深度超限:无限递归、超长业务调用链(如多层微服务嵌套调用),导致栈帧不断入栈,耗尽栈内存,触发 StackOverflowError;
- 栈内存配置过小:-Xss 参数配置过低(如小于 1M),对于方法调用层级深、局部变量多的场景,易触发栈内存不足异常;
- 阻塞场景堆积:线程长期处于阻塞状态(如锁等待、IO 阻塞),对应的虚拟机栈长期占用内存,若线程数量过多,会间接耗尽服务器物理内存;
- 排查难度较高:栈异常多与业务代码逻辑(递归、调用链)强相关,运维无法直接通过配置优化解决,需结合线程快照(jstack)定位问题。
GC 基础(懂类型、分代、核心流程)
GC:garbage collection,垃圾回收,是JVM自动内存管理的重要机制之一
一、 GC 分代模型:核心是 "按对象存活时间划分内存,提升回收效率"
JVM 堆内存并非整体管理,而是按对象存活时间逻辑划分为年轻代和老年代,对应两种核心 GC 类型,这是 GC 操作的基础:
- 内存划分
- 年轻代:分为 Eden 区(占 80%)、Survivor 0(S0,10%)、Survivor 1(S1,10%),专门存储新创建的对象(生命周期短,大部分对象创建后很快无用);
- 老年代(Tenured):存储从年轻代 "存活下来" 的对象(生命周期长,如缓存对象、全局对象)。
- 两种核心 GC 的区别(运维重点关注)
| 类型 | 回收区域 | 特点(运维视角) | 异常信号 |
|---|---|---|---|
| Minor GC | 仅年轻代 | 执行快、停顿短(毫秒级)、频率高 | 每秒多次执行 → 年轻代过小 |
| Full GC | 整堆(年轻代 + 老年代 + 元空间) | 执行慢、停顿长(秒级)、频率低 | 1 小时超过 3 次 → 内存瓶颈 |
- 执行快:指回收时只需要扫描一小块内存,且存货对象少、处理逻辑简单
- 停顿短:指触发的STW(停止所有 Java 线程,GC 执行时会暂停所有业务线程)时间极短,单位是毫秒级
- 频率高:GC 发生的次数多
- 核心流程(辅助理解):新对象入 Eden 区 → Eden 满触发 Minor GC → 存活对象移至 S0/S1 → 对象多次 Minor GC 后存活 → 晋升到老年代 → 老年代满触发 Full GC。
举例:
- 一个新创建的对象会优先放到 堆内存的新生代区
- 当新生代区的内存满了后 则会触发一次 Minor GC,来尝试回收那些能被回收/删除的对象(如被创建的临时对象(仅方法内局部变量,无长期引用,会被Minor GC回收)等)
- 当新生代区中对象多次无法被Minor GC回收则会被放入 老年代
- 同样,当 堆内存中的老年代区 满了后,则会触发 Full GC,尝试对这些对象进行回收,因为 Full GC 触发会对程序性能造成影响,其触发的次数需要尽可能地少
- 最后,当新生代与老年代的内存都满了后,就会触发堆内存溢出错误
下面这个简单的代码 GcGrokExperiment.java 可以帮助理解。运行该代码,然后用 jstat 命令(后半部分会提到常用命令的用法)去查看JVM的状态。
java
import java.util.ArrayList;
import java.util.List;
/**
* GC机制观察实验:
* 1. 持续创建对象,部分存活(晋升老年代),部分临时(新生代Minor GC回收)
* 2. 程序无限稳定运行,不快速OOM,支持jstat长期监控
* 3. 清晰呈现:Eden区耗尽→Minor GC→存活对象晋升老年代→老年代耗尽→Full GC
*/
public class GcGrokExperiment {
// 静态集合:持有对象引用,使其存活并最终晋升老年代(老年代内存占用的核心来源)
private static List<byte[]> oldGenAliveObjects = new ArrayList<>();
// 控制参数:避免内存快速耗尽,平衡GC触发频率(便于jstat观察)
private static final int TEMP_OBJ_SIZE_KB = 50; // 临时对象大小:50KB(新生代回收)
private static final int ALIVE_OBJ_SIZE_KB = 100; // 存活对象大小:100KB(晋升老年代)
private static final int ALIVE_OBJ_INTERVAL = 20; // 每创建20个临时对象,创建1个存活对象
private static final int CLEAR_ALIVE_RATIO = 100; // 每创建100个存活对象,移除20个(延缓OOM,长期运行)
private static long aliveObjCount = 0; // 存活对象计数器
public static void main(String[] args) throws InterruptedException {
System.out.println("GC机制观察实验启动!");
System.out.println("可使用jstat命令监控:jstat -gc <PID> 1000(每秒刷新一次)");
System.out.println("程序将持续运行,按Ctrl+C终止");
// 无限循环:持续创建对象,稳定触发GC流程
int tempObjCounter = 0;
while (true) {
// 1. 创建临时对象(仅方法内局部变量,无长期引用,会被Minor GC回收)
// 频繁创建临时对象,快速耗尽Eden区,触发Minor GC
byte[] tempObject = new byte[1024 * TEMP_OBJ_SIZE_KB];
tempObjCounter++;
// 2. 定期创建存活对象(存入静态集合,长期持有,最终晋升老年代)
if (tempObjCounter % ALIVE_OBJ_INTERVAL == 0) {
byte[] aliveObject = new byte[1024 * ALIVE_OBJ_SIZE_KB];
oldGenAliveObjects.add(aliveObject);
aliveObjCount++;
System.out.printf("创建存活对象%d,当前老年代存活对象总数:%d%n", aliveObjCount, oldGenAliveObjects.size());
// 3. 定期移除部分存活对象引用(释放老年代内存,避免快速OOM,实现程序长期运行)
if (aliveObjCount % CLEAR_ALIVE_RATIO == 0 && oldGenAliveObjects.size() > 30) {
// 移除前20个存活对象引用,让其可被Full GC回收
oldGenAliveObjects.subList(0, 20).clear();
System.out.printf("移除20个存活对象,当前老年代存活对象总数:%d(触发Full GC后回收)%n", oldGenAliveObjects.size());
}
}
// 控制对象创建速度:每10ms创建一个对象,避免内存瞬间耗尽,便于jstat观察
Thread.sleep(10);
// 重置临时对象计数器,避免数值过大
if (tempObjCounter >= Integer.MAX_VALUE - 1000) {
tempObjCounter = 0;
}
}
}
}二、 常见垃圾收集器:核心是 "选对场景,无需深究实现"
- Parallel GC(并行收集器)
- 地位:JDK 默认收集器,无需额外配置即可使用;
- 核心优势:吞吐量优先(GC 耗时占比低,能处理更多业务请求);
- 适用场景:普通业务系统(如内部管理系统、低并发服务),对应用卡顿不敏感的场景。
- G1 GC(区域化收集器)
- 地位:高可用场景首选,目前微服务、中间件(Kafka/Elasticsearch/Spring Boot)的主流选型;
- 核心优势:低停顿优先(可通过参数控制最大停顿时间),兼顾吞吐量;
- 适用场景:线上核心业务、微服务、中间件,对应用响应速度要求高的场景。
- ZGC/Shenandoah GC(低延迟收集器)
- 核心优势:极致低停顿(毫秒级以内),支持超大堆内存(百 G 级,如 128G/256G 堆内存);
- 适用场景:超大内存应用、对延迟要求极高的核心业务(如金融交易、实时风控)
三、 核心认知(运维实操关键)
"GC 不是越多越好",这是线上排查性能问题的核心原则:
- GC 本身会消耗服务器 CPU 资源,且 Full GC 执行时会触发 STW(停止所有 Java 线程);
- 线上性能瓶颈的核心诱因:
- Full GC 频繁(1 小时超 3 次):导致应用频繁卡顿,用户请求超时;
- GC 停顿时间过长(Full GC 超 2 秒):应用直接出现明显卡顿,甚至被监控系统判定为服务不可用;
- Minor GC 过于频繁(每秒超 1 次):占用大量 CPU 资源,导致应用处理业务请求的能力下降。
- 运维关注点:无需优化 GC 底层逻辑,只需通过 jstat 监控 GC 频率和停顿时间,发现异常后通过调整 JVM 配置(堆内存、收集器类型)缓解问题,优先保障应用可用性。
二、 核心技能 1:JDK 自带命令行工具(运维必备,实操核心)
作为运维工程师,jps / jstat / jstack / jmap / jcmd 是排查 Java 应用问题(内存泄漏、线程死锁、GC 异常等)的核心工具,下面先逐一详解命令,再设计可落地的实操实验,帮助你快速掌握使用方法。
一、 JDK 核心运维命令详解
1. jps:Java 进程快速查询工具
-
核心作用 :快速查找本地运行的 Java 进程 PID 和主类 / Jar 包信息(比
ps -ef | grep java更简洁、精准,无冗余输出)。 -
常用参数:
参数 含义 示例 无参数 仅显示 Java 进程 PID 和主类名 jps-l显示 PID + 主类全路径 / Jar 包完整路径(运维首选) jps -l-v显示 PID + 主类名 + JVM 启动参数 jps -v -
运维场景 :排查 Java 应用时,第一步用
jps -l获取目标进程 PID,为后续jstat/jstack等命令提供参数。
2. jstat:Java 运行状态监控工具
-
核心作用:实时监控 Java 进程的 GC 状态、内存分区使用情况、类加载统计等,是排查 GC 频繁、内存溢出前兆的核心工具。
-
常用参数:
命令格式 含义 运维场景 jstat -gc <PID> <间隔毫秒> <采样次数>监控堆内存(Eden/S0/S1 / 老年代)使用量 + GC 次数 / 耗时 排查内存增长异常、GC 频繁问题 jstat -gcutil <PID> <间隔毫秒> <采样次数>以百分比显示堆内存使用 + GC 统计(运维首选,更直观) 快速判断老年代是否满额、Minor GC/Full GC 频率 jstat -class <PID>监控类加载 / 卸载数量、总大小 排查类加载泄漏(如频繁热加载导致元空间溢出) -
核心特性:无侵入式监控,不影响 Java 应用运行,支持持续采样,可输出日志用于后续分析。
3. jstack:Java 线程堆栈分析工具
-
核心作用 :导出 Java 进程的线程堆栈信息,用于排查线程死锁、线程阻塞(BLOCKED/WAITING)、CPU 100%、线程泄漏等问题。
-
常用参数:
命令格式 含义 运维场景 jstack <PID>导出完整线程堆栈 常规线程问题排查 jstack -F <PID>强制导出堆栈(当 Java 进程卡死、无响应时使用) 进程挂起时的应急排查 jstack -l <PID>导出堆栈 + 锁详细信息(运维首选,排查死锁必备) 精准定位死锁持有者、锁竞争场景 -
核心特性 :能识别线程状态(BLOCKED/WAITING/RUNNABLE)、线程名称、所属线程池、锁信息,
jstack会自动检测死锁并给出明确提示。
4. jmap:Java 堆内存分析工具
-
核心作用:导出 Java 进程的堆内存快照(hprof 文件)、查看堆内存分布、大对象统计,是排查 ** 内存泄漏、堆内存溢出(OOM)** 的核心工具。
-
常用参数:
命令格式 含义 运维场景 jmap -histo <PID>按内存占用排序显示堆中对象(类名、数量、大小) 快速定位大对象(如超大 List/Map 导致内存溢出) jmap -dump:format=b,file=<文件名.hprof> <PID>导出堆快照(二进制格式),用于 MAT/JProfiler 分析 深度排查内存泄漏(运维核心用法) -
注意事项 :导出堆快照时(
-dump参数),Java 进程会短暂停顿(STW),建议在低峰期执行;快照文件可能较大,确保磁盘有足够空间。
5. jcmd:Java 多功能综合命令
-
核心作用 :一站式替代
jps/jstack/jmap的部分功能,支持 GC 手动触发、堆快照导出、线程堆栈导出、JVM 参数查询等,是 JDK 9 + 推荐的运维工具。 -
常用参数:
命令格式 含义 对应旧命令 jcmd列出所有 Java 进程(等效 jps)jpsjcmd <PID> VM.flags查看 JVM 启动参数(等效 jps -v)jps -vjcmd <PID> Thread.print导出线程堆栈(等效 jstack -l <PID>)jstack -l <PID>jcmd <PID> GC.heap_dump <文件名.hprof>导出堆快照(等效 jmap -dump)jmap -dump:format=b,file=xxx.hprof <PID>jcmd <PID> GC.run手动触发 Full GC(仅用于测试,生产环境禁止随意执行) 无对应旧命令 -
运维场景 :生产环境中可优先使用
jcmd,减少命令记忆成本,功能更全面、兼容性更好。
二、 运维实操实验(掌握 Java 应用问题排查全流程)
实验目标
- 掌握 5 个核心命令的基本用法和联动使用流程
- 模拟「线程死锁」和「内存泄漏前兆」场景,用对应命令排查定位
- 形成 Java 应用运维排查的标准化流程(适用于生产环境)
实验环境准备
- 系统环境:Ubuntu 20.04
- JDK 版本:JDK 11
- 实验代码 :编写两个 Java 程序,分别模拟线程死锁和内存泄漏前兆
- 程序 1:
DeadLockDemo.java(模拟线程死锁) - 程序 2:
MemoryLeakDemo.java(模拟内存泄漏,静态集合持续存放对象)
- 程序 1:
- 工具准备 :确保 JDK 的
bin目录加入系统环境变量(echo $PATH验证,能直接执行jps等命令)
实验步骤(有两个场景)
场景 1:线程死锁排查(核心命令:jps + jstack + jcmd)
步骤 1:编译并运行死锁程序
- 创建
DeadLockDemo.java:
java
/**
* 模拟线程死锁场景(运维排查常用测试用例)
*/
public class DeadLockDemo {
// 定义两个锁对象
private static final Object LOCK_A = new Object();
private static final Object LOCK_B = new Object();
public static void main(String[] args) {
// 线程1:先获取LOCK_A,再尝试获取LOCK_B
new Thread(() -> {
synchronized (LOCK_A) {
System.out.println(Thread.currentThread().getName() + " 获取到LOCK_A,等待LOCK_B");
try {
Thread.sleep(1000); // 确保线程2先获取LOCK_B
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (LOCK_B) {
System.out.println(Thread.currentThread().getName() + " 获取到LOCK_B");
}
}
}, "Thread-DeadLock-1").start();
// 线程2:先获取LOCK_B,再尝试获取LOCK_A
new Thread(() -> {
synchronized (LOCK_B) {
System.out.println(Thread.currentThread().getName() + " 获取到LOCK_B,等待LOCK_A");
try {
Thread.sleep(1000); // 确保线程1先获取LOCK_A
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (LOCK_A) {
System.out.println(Thread.currentThread().getName() + " 获取到LOCK_A");
}
}
}, "Thread-DeadLock-2").start();
// 让程序持续运行,便于排查
while (true) {
try {
Thread.sleep(3600000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}- 编译运行:
bash
# 编译
javac DeadLockDemo.java
# 后台运行(避免控制台阻塞,运维常用方式)
nohup java DeadLockDemo > deadlock.log 2>&1 &步骤 2:用 jps 获取进程 PID
bash
# 运维首选命令,精准获取PID和主类
jps -l
# 输出示例:76000 DeadLockDemo(76000即为PID,记录该值)步骤 3:用 jstack 排查死锁
bash
# 导出线程堆栈+锁信息,并重定向到文件(便于分析)
jstack -l 76000 > deadlock_thread.log
# 查看日志,筛选死锁信息
grep -A 30 "Deadlock" deadlock_thread.log预期结果:
jstack会明确提示「Found one Java-level deadlock」- 显示死锁线程(Thread-DeadLock-1、Thread-DeadLock-2)
- 显示每个线程持有的锁和等待的锁,精准定位死锁原因
步骤 4:用 jcmd 重复排查(替代 jstack)
bash
# 导出线程堆栈,等效jstack -l
jcmd 76000 Thread.print > deadlock_thread_jcmd.log
# 查看死锁信息
grep -A 30 "Deadlock" deadlock_thread_jcmd.log运维总结 :生产环境中,jcmd <PID> Thread.print 可替代jstack -l <PID>,功能一致。
场景 2:内存泄漏前兆排查(核心命令:jps + jstat + jmap)
步骤 1:编译并运行内存泄漏程序
- 创建
MemoryLeakDemo.java:
java
/**
* 模拟内存泄漏前兆(静态List持续添加对象,不释放)
*/
import java.util.ArrayList;
import java.util.List;
public class MemoryLeakDemo {
// 静态集合(生命周期与JVM一致,不会被GC回收,导致内存持续增长)
private static List<byte[]> leakList = new ArrayList<>();
public static void main(String[] args) throws InterruptedException {
System.out.println("内存泄漏模拟程序启动...");
// 循环添加大对象(每个对象100KB),模拟内存持续增长
int count = 0;
while (true) {
leakList.add(new byte[1024 * 100]); // 100KB
count++;
if (count % 100 == 0) {
System.out.println("已添加" + count + "个对象,当前集合大小:" + leakList.size() * 100 + "KB");
Thread.sleep(500); // 控制增长速度,便于监控
}
}
}
}- 编译运行:
bash
# 编译
javac MemoryLeakDemo.java
# 后台运行,指定堆内存大小(便于快速观察内存增长)
nohup java -Xms50m -Xmx50m MemoryLeakDemo > memory_leak.log 2>&1 &步骤 2:用 jps 获取进程 PID
bash
jps -l
# 输出示例:76100 MemoryLeakDemo(76100即为PID,记录该值)步骤 3:用 jstat 监控 GC 和内存增长
bash
# 以百分比监控GC状态,每秒采样1次,共采样100次(运维常用监控命令)
jstat -gcutil 76100 1000 100
S0 S1 E O M CCS YGC YGCT FGC FGCT CGC CGCT GCT
0.00 100.00 0.00 47.29 10.20 7.48 2 0.011 0 0.000 0 0.000 0.011
0.00 100.00 0.00 47.29 10.20 7.48 2 0.011 0 0.000 0 0.000 0.011
0.00 100.00 28.57 47.29 10.20 7.48 2 0.011 0 0.000 0 0.000 0.011
0.00 100.00 42.86 47.29 10.20 7.48 2 0.011 0 0.000 0 0.000 0.011
0.00 100.00 57.14 47.29 10.20 7.48 2 0.011 0 0.000 0 0.000 0.011关键指标观察(对应内存泄漏前兆):
E(Eden 区百分比):快速增长→归零(Minor GC),反复循环O(老年代百分比):持续缓慢增长(最终接近 100%)YGC(Minor GC 次数):快速递增(Eden 区频繁耗尽)FGC(Full GC 次数):随着老年代增长,逐步递增(Full GC 无法释放内存,因为静态集合持有对象引用)
步骤 4:用 jmap 查看堆内存分布
bash
# 导出堆快照(用于深度分析,运维核心操作)
jmap -dump:format=b,file=memory_leak.hprof 76100后续分析 :可将memory_leak.hprof下载到本地,用 MAT(Eclipse Memory Analyzer Tool)/ visualvm 工具打开,能精准定位到leakList静态集合导致的内存泄漏。