欢迎来到我的频道 【点击跳转专栏】
码云链接 【点此转跳】
文章目录
- [1. 冯诺依曼体系结构](#1. 冯诺依曼体系结构)
- [1.1 为什么要有内存?](#1.1 为什么要有内存?)
- [1.1.1 存储分级](#1.1.1 存储分级)
- [1.1.2 体系结构的效率问题](#1.1.2 体系结构的效率问题)
- [1.1.3 内存的意义(为什么要有内存!)](#1.1.3 内存的意义(为什么要有内存!))
- [1.2 程序与内存的关系](#1.2 程序与内存的关系)
- [1.3 输入输出(效率的本质)](#1.3 输入输出(效率的本质))
- [1.4 基于冯·诺依曼体系结构来解释数据流动](#1.4 基于冯·诺依曼体系结构来解释数据流动)
- [2. 操作系统](#2. 操作系统)
- [2.1 概念](#2.1 概念)
- [2.2 设计OS的⽬的](#2.2 设计OS的⽬的)
- [2.3 操作系统的管理本质](#2.3 操作系统的管理本质)
- [2.4 换个角度理解面向对象](#2.4 换个角度理解面向对象)
- [2.5 系统调⽤和库函数概念](#2.5 系统调⽤和库函数概念)
- [3 进程的基本概念与基本操作](#3 进程的基本概念与基本操作)
- [3.1 进程概念的引出](#3.1 进程概念的引出)
- [3.2 描述进程-PCB](#3.2 描述进程-PCB)
- [3.3 task_ struct](#3.3 task_ struct)
- [3.3.1 内容分类](#3.3.1 内容分类)
- [3.3.2 获取进程ID(建议配合 3.3.3 一起食用)](#3.3.2 获取进程ID(建议配合 3.3.3 一起食用))
- [3.3.3 认清楚系统调用和库函数(加餐)](#3.3.3 认清楚系统调用和库函数(加餐))
- [3.4 查看进程](#3.4 查看进程)
- [3.4.1 ps](#3.4.1 ps)
- [3.4.2 父进程](#3.4.2 父进程)
- [3.4.3 系统⽂件夹查看进程](#3.4.3 系统⽂件夹查看进程)
- [3.4.4 cwd&&chdir](#3.4.4 cwd&&chdir)
- [3.5 创建进程](#3.5 创建进程)
- [3.5.1 通过系统调⽤创建进程-fork初识](#3.5.1 通过系统调⽤创建进程-fork初识)
- [3.3.2 fork的返回值问题](#3.3.2 fork的返回值问题)
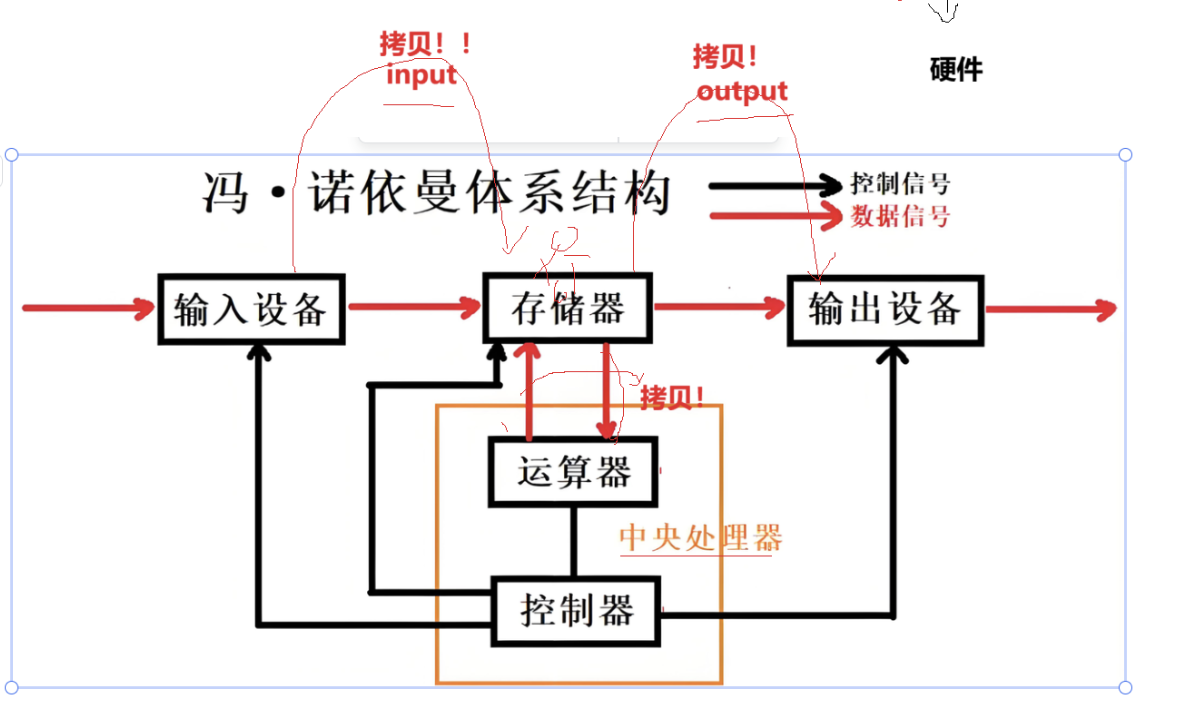
1. 冯诺依曼体系结构
我们常⻅的计算机,如笔记本。我们不常⻅的计算机,如服务器,⼤部分都遵守冯诺依曼体系。
而 输入-> 计算 -> 输出 就是一个最典型的模型!
截至目前,我们所认识的计算机,都是由一个个的硬件组件组成:
- 输入单元:包括键盘, 鼠标,扫描仪, 写板,摄像头,话筒,网卡,磁盘等
- 中央处理器(CPU):含有运算器 和控制器 等(运算器 的主要工作是 算数运算 或者逻辑运算(逻辑真假之类的))
- 输出单元:显示器,打印机,内置的喇叭,网卡,磁盘等
⚠️:我们一般将输入输出设备统称为外设
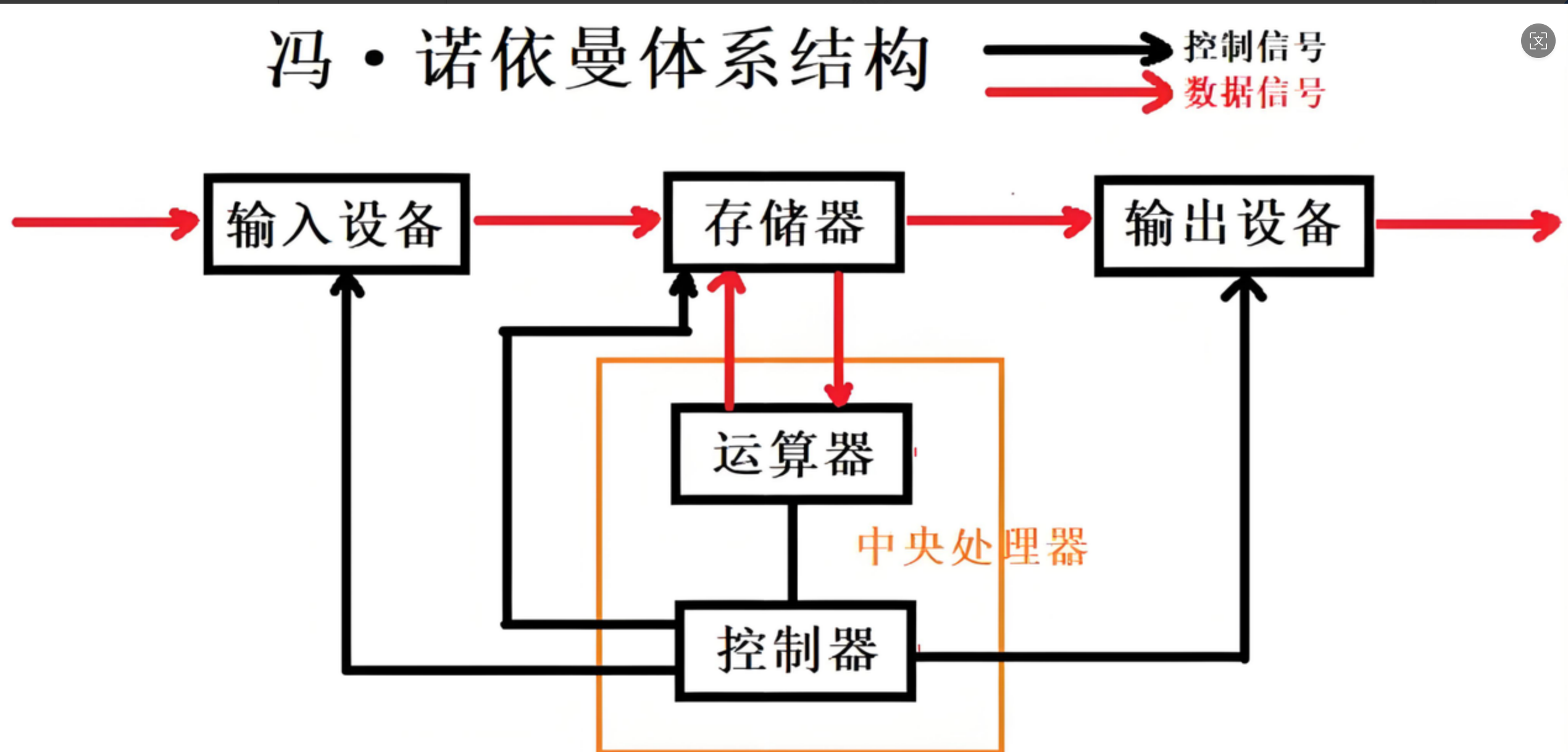
关于冯诺依曼,体系结构规定(核心定义!):
- 这里的存储器 指的是内存!
- 不考虑缓存情况,这里的CPU 能且只能对内存 进行读写,不能访问外设(输入或输出设备)(数据层面)
- 外设(输入或输出设备)要输入或者输出数据,也只能写入内存或者从内存中读取。
- 一句话,所有设备都只能直接和内存打交道。
1.1 为什么要有内存?
既然干什么都需要经过内存 那么冯诺依曼体系 为什么要有内存?为什么要这么设计?? 在回答这个问题之前 必须有两个前置概念 存储分级 和体系结构效率问题
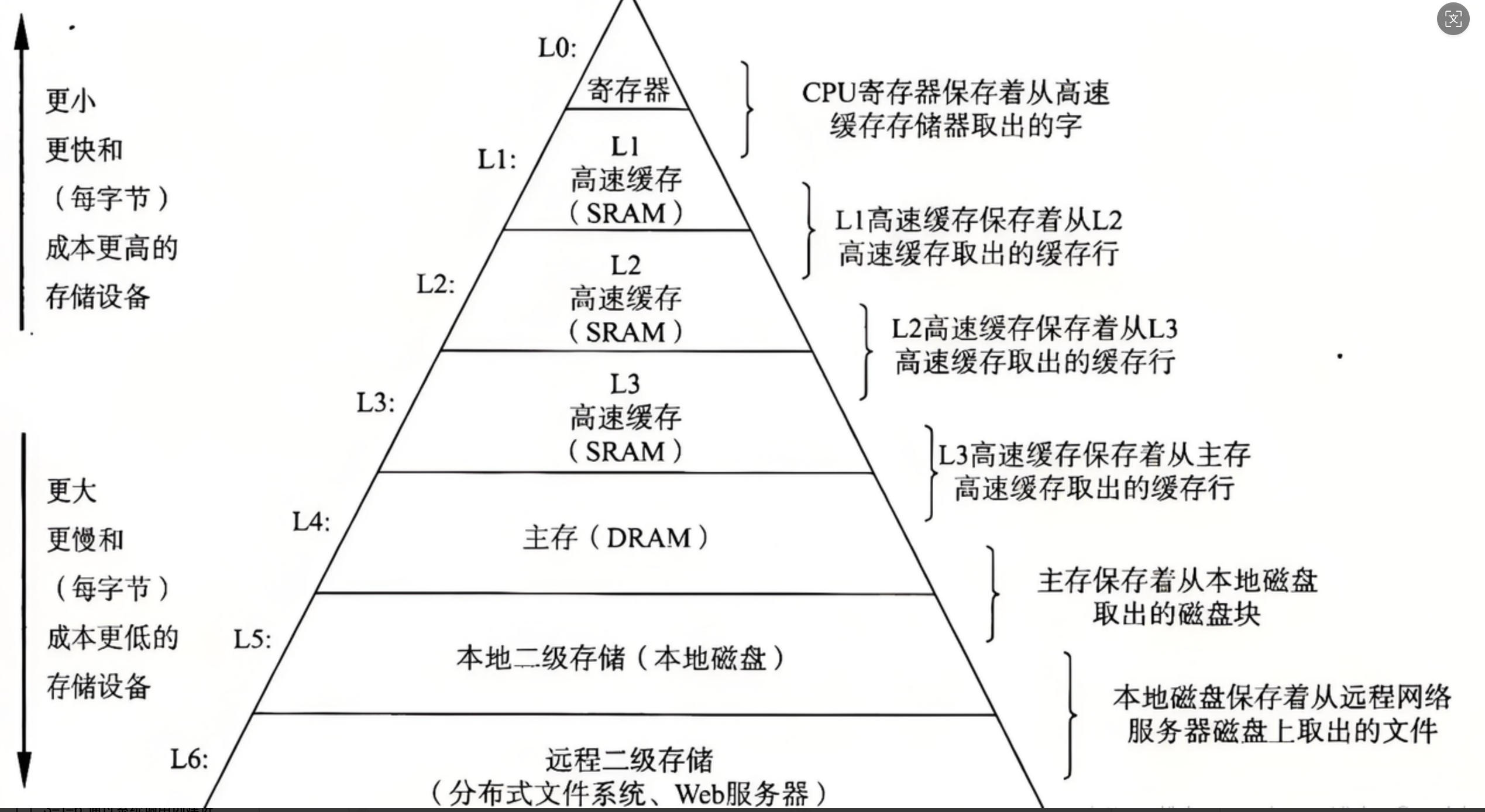
1.1.1 存储分级
具有存储能力所对应的设备 离CPU 越近 效率越高的设备 往往容量越小造价越高 反之离CPU越远的设备 效率比较低 往往容量大造价低。
而我们常说的 内存 就是图里的 主存。
1.1.2 体系结构的效率问题
如果将计算机设计成 输入设备 -> CPU -> 输出设备。但是外设(ms级)相比较于CPU(ns级),速度特别慢。
根据木桶原理 如果按照 输入设备 -> CPU -> 输出设备 这样设计的计算机 效率太慢了(完全按照外设)!所以我们在外设和CPU之间 加了个内存!
1.1.3 内存的意义(为什么要有内存!)
在数据层面,CPU 不和外设 之间打交道!只会和内存打交道。在操作系统 的控制下 会将输入设备 的数据(假设100兆)全部载入存储器 (预加载)然后 CPU 读取数据只需要在内存读取!
💡: 因为数据可以提前加载,大部分情况下,处理数据的时候,就可以转化为CPU和内存的交互,计算机的效率就以内存为主!!(根据局部性原理:当你访问一个位置的数据 大概率接下来访问的还是它周围的数据,这也是为什么值得我们把数据提前加载到内存)
但是由于寄存器造价过于昂贵!为了让普通人以较低的价格,获得效率不错的计算机,内存就有了存在的意义!!从而出现了连锁反应 冯诺依曼为电脑提供性价比 从而被人们广泛接受 所以大家都买得起计算机 才可能形成全球那么多的网民数量,从而才会孵化出互联网!
1.2 程序与内存的关系
一个C语言程序 先编译成二进制可执行文件(存储在磁盘上) 而程序要运行 必须加载到内存中!
因为程序本质由逻辑(if while等) 和 数据(变量等)组成 而这两者本身也还是数据 (无论是if指令还是变量等)而在数据层面 数据都必须要先拷贝到内存里!为什么呢? 因为这就是 冯诺依曼体系结构的规定!!
1.3 输入输出(效率的本质)
根据上述内容 我们不难得知:在数据层面,CPU是不会和外设打交道的,CPU读写数据,只会和内存打交道。
那么我们口中的输入和输出(外设),是站在谁的角度去考虑的呢?
答案:站在内存(硬件)的角度,换句话说就是站在加载到内存中的程序的角度!(
IO)
当我们重谈效率问题:计算机数据流动本质靠的是拷贝 ,那么计算机的效率问题,由设备的拷贝效率决定!而计算机效率根据冯诺依曼体系 由内存决定,所以存储设备的效率就是由它拷贝效率决定!
由于不同设备拷贝效率不同,此时由 内存中转 就将这些速度差弄的很低了。
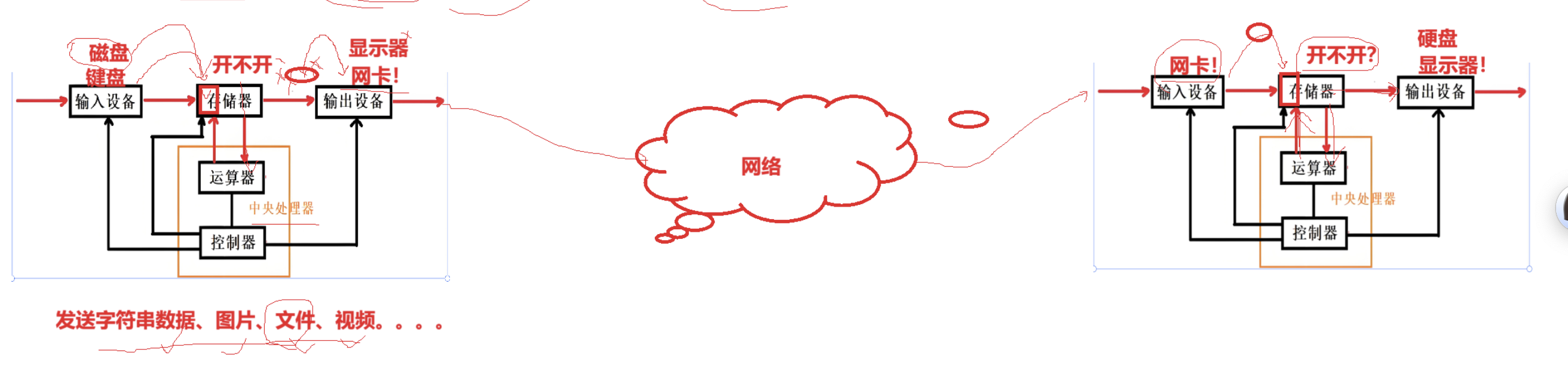
1.4 基于冯·诺依曼体系结构来解释数据流动
假设 你打算在qq上给你朋友发了个消息:
- 你打字"你好"
- 键盘输入 → 操作系统把字符写入内存中的输入缓冲区;
- QQ 程序(正在运行的指令)读取这块内存,把"你好"存到自己的变量里(内存中)。
- 点击"发送"
- QQ 执行"发送"函数的指令:
-
- 把"你好"和其他信息(如时间、ID)组合成一个数据结构(在内存)然后通过CPU读取后对信息进行加密后再次拷贝回内存;
-
- 调用系统接口(比如 send()这个调用本身也是 CPU 执行的一条指令)然后通过网卡传输到网络。
- 显示在朋友窗口
- 朋友电脑的网卡接收到该数据,把它存入内存,CPU对信息进行读取解密后再写回内存;
- QQ 执行绘图指令,把"你好"写入图形缓冲区(内存的一部分);
显卡定期读取这块内存,输出到屏幕。
2. 操作系统
2.1 概念
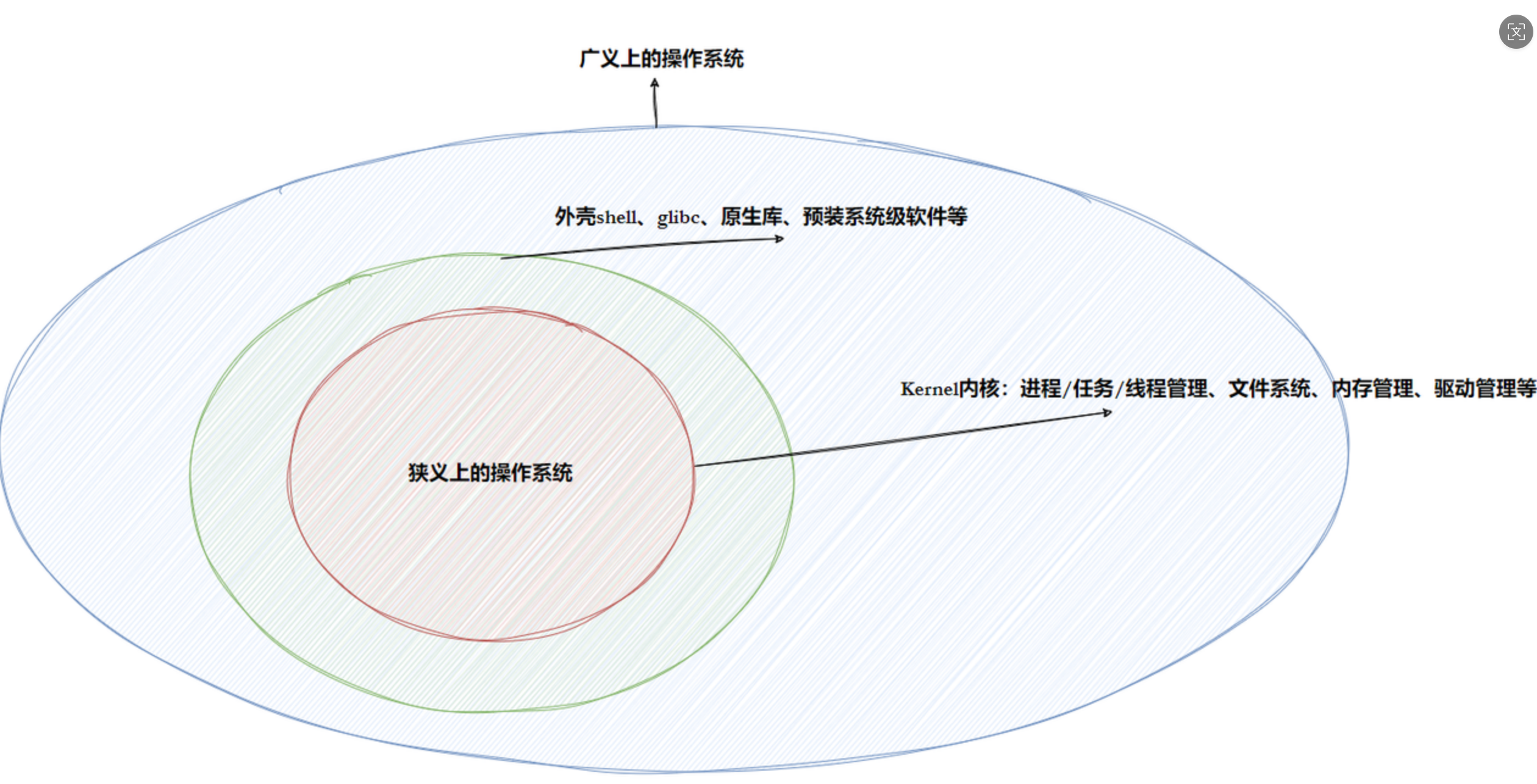
任何计算机系统都包含⼀个基本的程序集合,称为操作系统(OS)。笼统的理解,操作系统包括:
内核(内核本质就是4大功能:进程管理,内存管理,⽂件管理,驱动管理)
其他程序(例如函数库,shell程序,win上的图形化界面等等)
操作系统 分广义操作系统(外壳+内核) 和 狭义上的操作系统(内核)而我们熟知的 安卓 就是 Linux内核+安卓的外壳
安卓 的本质就是操作系统内核 的一层外壳程序 而安卓 提供可编程的图形化界面调用接口(函数库)提供给上层,人们就基于安卓 进行各种各样的开发,从此就诞生了我们熟知的 小米,vivo等 ;而华为鸿蒙 诞生初期 内核 依然大体还是 Linux内核 但是去掉了安卓 的外壳程序改用自己的,直到纯血鸿蒙 的发布 才正式替换掉了Linux内核。
2.2 设计OS的⽬的
首先我们要明确一个问题 操作系统是干什么的?
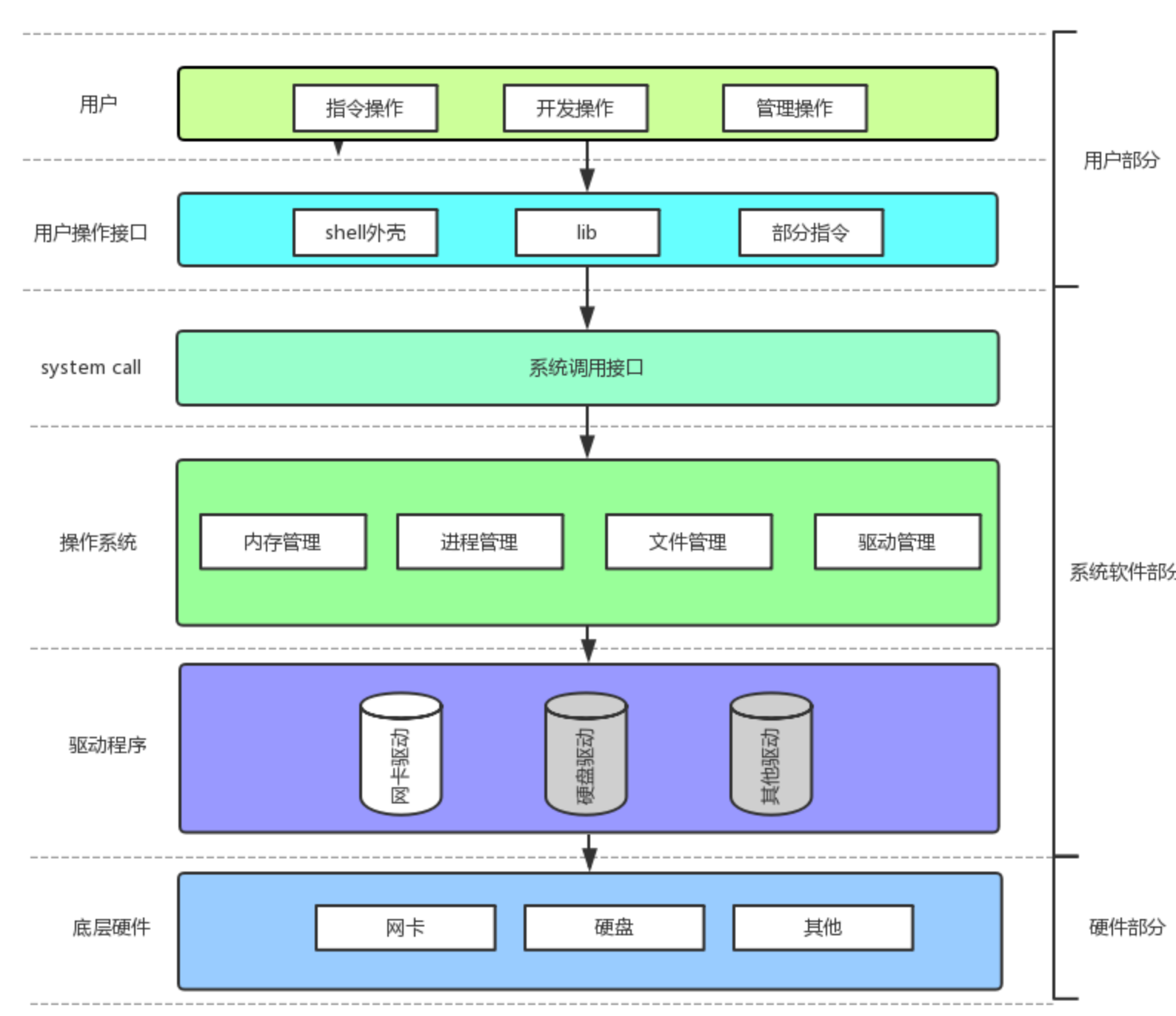
💡:答案是通过操作系统把软硬件资源管理好。
补充:每一个硬件都存在对应的驱动程序(例如网卡 需要网卡驱动程序 一般由网卡厂家写入)而操作系统就是通过这些驱动程序管理硬件
但是把软硬件管理好,这是手段 不是目的! (哪怕没有操作系统 我们依然需要各种手段去管理这些资源)
所以操作系统 存在的意义还是 给人提供一个良好的使用环境(稳定,高效,安全) 总结出一个词 就是
以人为本。
- 对下,与硬件交互,管理所有的软硬件资源
- 对上,为⽤⼾程序(应⽤程序)提供⼀个良好的执⾏环境
2.3 操作系统的管理本质
首先我们要给操作系统一个定义:操作系统是⼀款纯正的"搞管理"的软件。
那么 "管理" 二字该怎么理解呢?
我们用 「校长---辅导员---学生」的关系来理解:
| 校园角色 | 对应 OS 组件 | 说明 |
|---|---|---|
| 校长 | 操作系统内核(Kernel) | 最高管理者,掌握全局资源,制定规则,不直接管每个学生(学生校长不需要见面,只需要根据数据(成绩、学号院系信息等 )就能管理),所以校长管理学生的本质就是对学生的数据进行管理 ,而数据 是作为决策 的依据,而管理数据的核心离不开数据结构 ,最后校长根据数据 进行决策 ,通过对数据结构 的增删查改 进行管理。 |
| 辅导员 | 系统调用 / 驱动程序 / 资源调度器 | 执行校长指令,对接学生需求,分配资源,处理具体事务(是学生和校长对接的"桥梁"),所以导员本质就是 用于传达校长指令给学生同时收集学生信息反馈给校长。 |
| 学生 | 应用程序、硬件 | 学生不能直接和校长进行沟通,想使用资源,需要通过导员进行信息传递,所以学生本质就是 传递自己的诉求给导员,拜托导员传递给校长做决策,并且同时执行导员传达下来的校长的命令。 |
那么如何将现实问题转化成计算机问题?
校长将单个学生信息(C语言为例子)以
struct形式描述 (学号,成绩等),然后通过数据结构 (链表 )组织 起来,比如说我想让一位学生留级,那么把该同学结构体里面 年级-1 ;想开除一个人,把他从链表里面删除即可,所以我们就把现实问题转化成计算机问题,这个过程就叫做 建模。
建模 可以用6个字总结:先描述再组织。那么管理硬件也是一样的道理!!
硬件就是里面的学生(执行指令),导员就是里面的驱动程序(传达指令),操作系统就是里面的校长,操作系统通过结构体描述每一个的硬件信息(类型、状态、厂商、是否能被访问等),然后通过一个数据结构 串联起来这些数据,进行管理(本质就是数据的管理)。
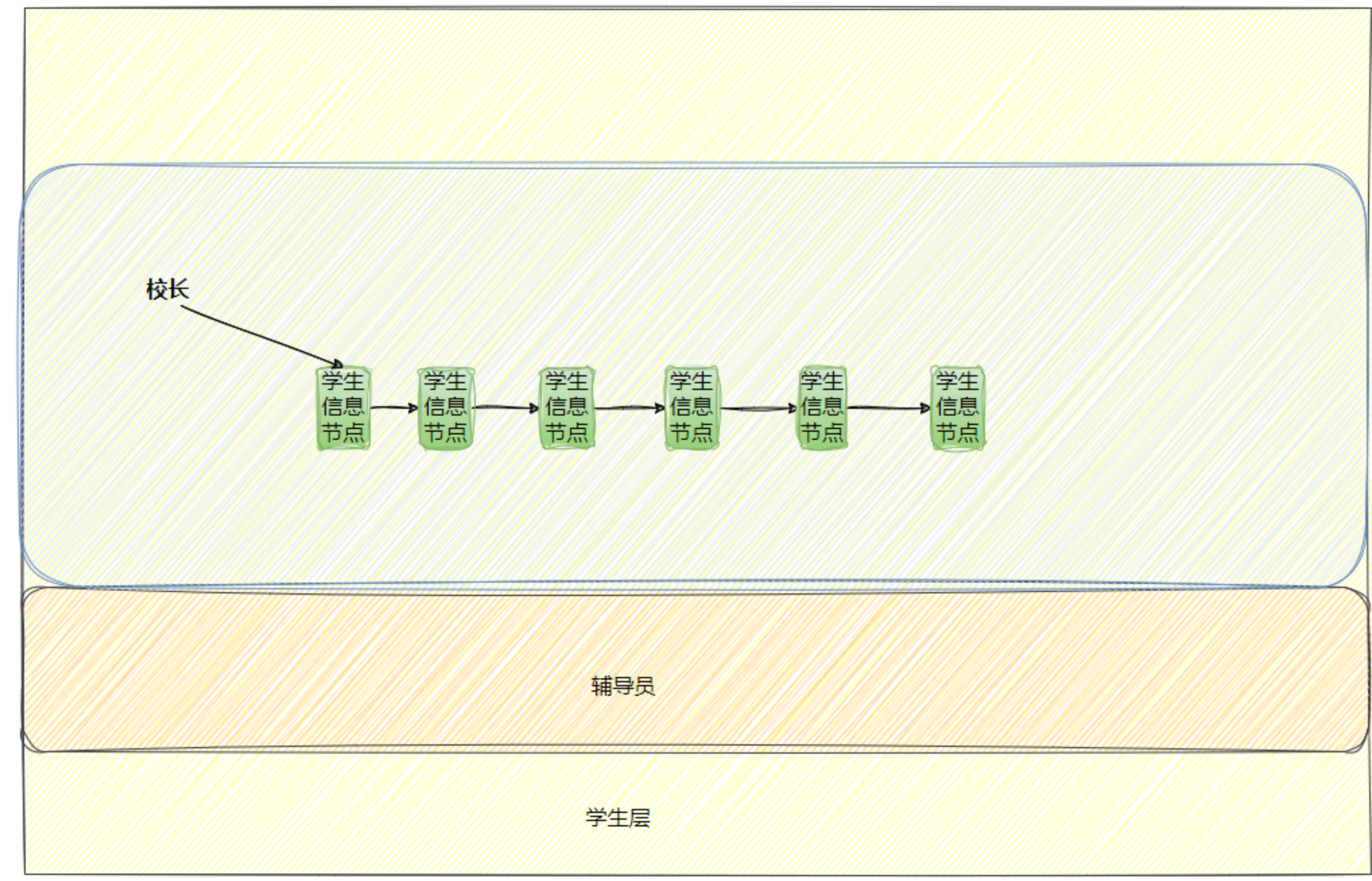
💡:综上 OS 核心就是数据结构 !将数据 用各种数据结构存储 ,而各种 所谓的管理 本质就是 转化成各种数据结构 的 增删查改! 其核心思想就是:先描述再组织。
2.4 换个角度理解面向对象
在C++中 我们定义的类 对应的就是 描述 ;而STL库对应的就是 组织 其实我们不难发现 几乎所有的编程语言都离不开 类和对象以及数据结构库 并且C++ 告诉我们一切皆对象 这是为什么呢?
这就涉及到了这个世界一个本质的 真相 我们这个世界的所有问题都是离不开 先描述再组织。
2.5 系统调⽤和库函数概念
- 操作系统对下把软硬件资源管理好,这是手段。
- 对上给人提供一个良好的使用环境才是目的。
那么操作系统如何对上提供一个安全、稳定的服务呢?
如果用户能随意访问操作系统的任意代码和数据,这种过程是非常不安全的!举个例子吧。
比如说有一个银行,张三来存钱了,存钱的时候张三想要自己在银行电脑上操作,并且进入银行金库把钱放到金库里面,这显然是不合理的 。银行要保证自己的安全,因为群众中可能有坏人 ,但是银行又必须给正常人提供服务! 这个时候银行必须要在保证自己安全的前提下,给别人提供服务。 所以现实生活中银行会在系统内开一些小窗口,通过银行的柜台小姐姐来办理你所需要的服务。

那么换成操作系统,就必须为用户提供一定的系统调用接口 (system call),就好比操作系统给自己开的小小的银行窗口,本质 就是系统提供的一个个函数 !
在开发⻆度,操作系统对外会表现为⼀个整体,但是会暴露⾃⼰的部分接⼝,供上层开发使⽤,这部分由操作系统提供的接⼝,叫做系统调⽤。
但这时 一位大爷 李四 根本不懂银行的办理流程 去了也不知道该怎么办理业务 所以在银行外部 提供了一个 大堂经理 的角色帮助大爷熟悉流程 。大爷不会写字 这个时候大堂经理 就问大爷:"大爷,您贵姓啊?身份证带来没?银行卡卡号多少啊?要存多少钱啊?" 大爷回答了大堂经理的问题 然后代替大爷在窗口办理了业务。
那么换成操作系统,大堂经理 就相当于 我们曾经学C++、Java的库(printf、scanf库)封装了系统调用 ,我们系统开发者所用的都是封装好了的库,几乎没见过系统调用 ,所以我们在座的机会每一个人,都是大爷 。
**系统调⽤**在使⽤上,功能⽐较基础,对⽤⼾的要求相对也⽐较⾼,所以,有⼼的开发者可以对部分系统调⽤进⾏适度封装,从⽽形成库,有了库,就很有利于更上层⽤⼾或者开发者进⾏⼆次开发。
比如说 你是开发者 那么操作系统给你提供
C、C++函数库(底层也是系统调用);如果你要使用操作系统 (打游戏,打开word之类的),那么给你提供图形化界面(win),外壳程序(Linux);如果你要管理操作系统 (安装卸载软件),给你提供yum、apt、控制面板。
⚠️:
- 系统调用 不是shell外壳 (外壳程序是C语言写的,是用C语言标准库 结合系统调用设计的一款软件,本质就是命令)
Linux指令也不是系统调用,指令本质是C语言编译好的可执行程序(利用C语言库 形成的二进制文件),底层也是用系统调用。
| 对比项 | 系统调用 | 库函数 |
|---|---|---|
| 目的 | 让用户程序使用内核能力(如文件、进程、网络) | 提供便捷功能(如字符串处理、数学计算、I/O封装) |
| 权限 | 需要切换到内核态(特权模式) | 纯用户态,无特权 |
| 性能开销 | 较大(涉及上下文切换、安全检查) | 很小(就是普通函数调用) |
| 可移植性 | 依赖操作系统(Linux vs Windows 不同) | 可跨平台 |
| 例子 | read, write, fork, getpid, open |
printf, malloc, strlen, sin, fopen |
举个典型例子:printf("Hello")
c
#include <stdio.h>
int main() {
printf("Hello\n");
return 0;
}printf是库函数- 定义在 C 标准库(如 glibc) 中;
- 它负责格式化字符串(把
"Hello"变成字节流); - 全程在用户空间运行。
- 但最终要输出到屏幕,必须靠内核
printf内部会调用更底层的 I/O 函数(如write());- 而
write()是一个 系统调用; - 此时程序执行
syscall指令,陷入内核; - 内核收到请求后,真正操作显卡/终端设备,把字符显示出来。
✅ 所以:库函数可能封装系统调用(如
getpid()),但二者层级不同,。
3 进程的基本概念与基本操作
3.1 进程概念的引出
- 课本概念:程序的一个执行实例,正在执行的程序等
程序和可执行文件是一回事(在磁盘上),指令本质也是程序,程序想要运行起来根据冯诺依曼体系 必须要加载到存储器 (内存)中,而在内存中的程序,运行起来的程序,就叫进程 。
无论是双击(win)启动app还是
./(linux)亦或者是命令行 执行命令,本质都是启动进程
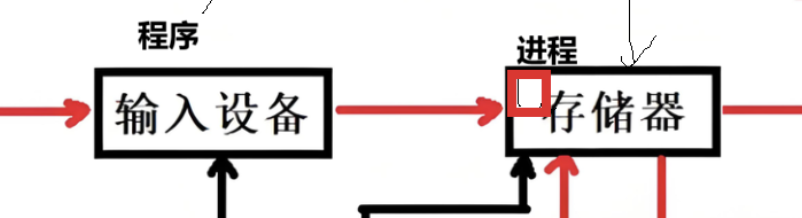

不是很好理解是吧!没事我还有通俗理解版:
在操作系统里,可以同时运行很多程序,每一个程序都要加载到内存,那么根据上面的概念,是不是就是同时有很多的进程。
那么在我们还没有启动进程前,第一款软件是什么?
答案是操作系统,也是在内存里。
内存中的这些进程,要不要被操作系统管理?
肯定是要的啊。
那怎么管理?
先描述,在组织!操作系统99%是C语言写的 那么用一个结构体描述进程属性;然后用数据结构将其串起来(链表),那么操作系统对进程的管理,是不是就简化成对链表的增删查改!
问个问题,你怎么证明你是你吗学校的学生?
- 你人得在学校上课吧
- 得有描述你属性信息的结构体吧
好再来个问题 未来你怎么找工作?
- 写简历->本质是:描述自己(不是你在找工作,是你的简历在帮你找)
- 投递公司,落在一起,排队-> 组织起来(不是你在排队,你是的简历)
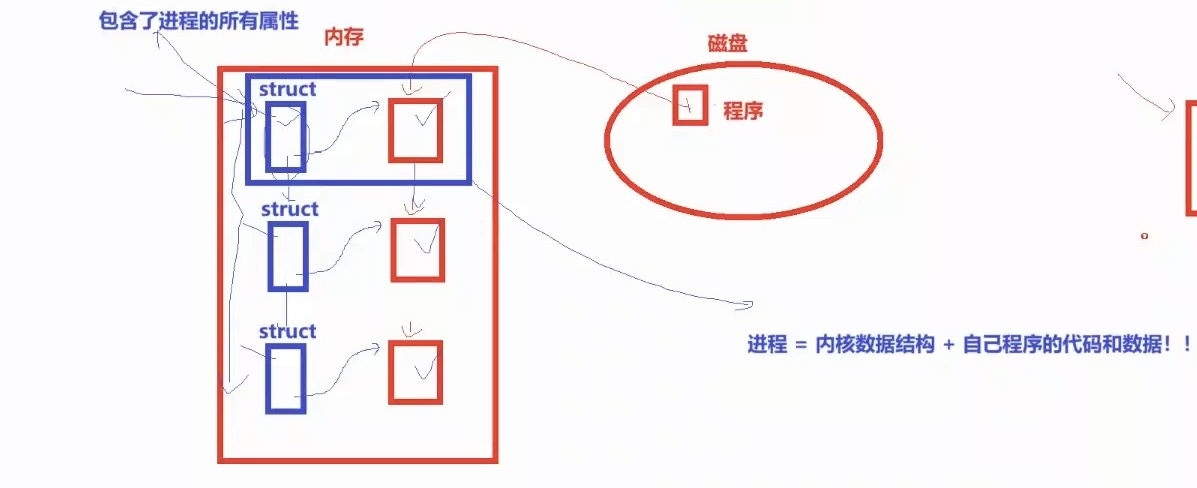
最后那么到底什么是进程?你想将磁盘中的程序运行起来,你双击了它(假设是win)!那么此时你的代码和数据 就加载到了内存中,此时操作系统为了完成对应人物,就会创建一个描述该进程的结构体 ,结构体包含了进程的所有属性,这个结构体一定能帮我在内存中找到对应的可执行程序 ,你可能会存在很多进程,真正把你进程组织 起来的 不是把程序 组织起来,而是利用数据结构(链表)把你的结构体 利用链表链接起来 。
所以面试官选择一个牛马,不是选择人(程序) ,而是遍历所有 简历(进程链表) ,挑出想要的 简历 (结构体),根据简历属性 找到对应的人 (根据结构体找到对应的程序! )
通俗说 程序 加载到内存 操作系统 为程序 在内存 创建的内核数据结构 而内核结构 里面有程序的具体信息。
💡:综上进程 = 操作系统为程序创建的内核数据结构 + 自己程序的代码和数据
3.2 描述进程-PCB
进程信息被放在⼀个叫做进程控制块的数据结构中,可以理解为进程属性的集合。在操作系统 层面我们称呼其
PCB(对应于媒婆 ),对于具体的操作系统Linux的PCB就叫:task_struct(对应于王婆 )

综上,task_struct是PCB 的⼀种,task_struct 是 Linux 内核的⼀种数据结构类型 ,它会被装载到RAM(内存)⾥并且包含着进程的信息。
3.3 task_ struct
3.3.1 内容分类
- 标示符: 描述本进程的唯一标示符,用来区别其他进程。(
也叫pid)
操作系统内操作系统太多了,为了标识进程的唯一性,就好比学校内的学号,在我看来可能就是结构体内的一个数字。
- 状态: 任务状态,退出代码,退出信号等。
比如说电脑上放音乐,它会有停止、播放、关闭等状态,可能就是结构体内的一个数字(启动时1,暂停是0之类的)。
- 优先级: 相对于其他进程的优先级。
类比排队,排队本质就是确认优先级,谁在头谁就先打饭;对于进程,就是
task_struct排队,谁先谁先得CPU资源。
- 程序计数器: 程序中即将被执行的下一条指令的地址。
补充:CPU上存在寄存器 ,用于保存执行过程的临时数据(比如
x、y、z变量,存储在寄存器 通过CPU的运算单元计算出结果,而result在内存中,return就相当于执行move直接把寄存器 中的z转移给result,就这是为什么z无法引用接受的原因)
我们执行代码不是一下子都执行完的,那么CPU怎么知道你下次代码执行的时候该执行哪一行呢?此时CPU里面有个叫
EIP(又名PC指针、程序计数器)【寄存器】,用于记录指向程序中即将被执行的下一行指令的地址。OS 会把当前进程的所有寄存器值,从寄存器复制到结构里,而程序计数器就是task_struct对应的数据的一种。
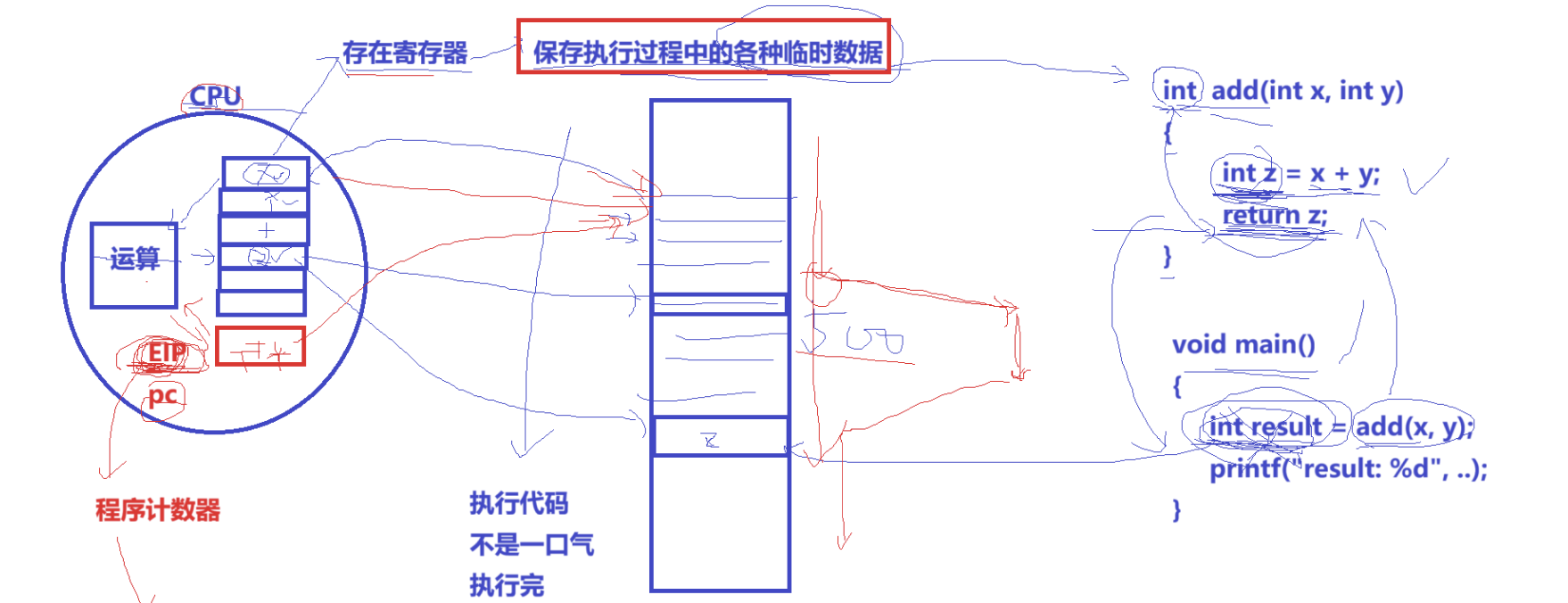
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
CPU要执行代码,不是结构体,就是通过内存指针找到内存中对应的程序
- 上下文数据: 进程执行时处理器的寄存器中的数据。
💡:一个进程在执行代码的时候,会占有
CPU,但是它不会吧你的代码执行完才放弃CPU(参考while(1),你电脑也没"爆炸"啊),这是因为当代计算机,都会给一个进程分配一个时间片,比如说你分配一个进程1s时间片,那么这个进程就只会占用CPU 1s,1s后进程就会剥离,让另一个进程执行,这个就叫基于时间片的轮转调度 。其实这么多话 我只是想说明:一个进程没有执行完,就可能把CPU让出去 ,这时寄存器 就会出现执行中的临时数据 这些就是临时数据 ,而OS 会把当前进程的所有寄存器值,从寄存器复制到结构里 ,上下文数据 就是
task_struct对应的数据的一种。⚠️:cpu内寄存器只有一份,但上下文可以有多份,分别对应不同进程(上下文数据属于进程内的数据,是寄存器产生的数据 ,不是寄存器 ,程序计数器 就属于上下文数据的一部分)
- I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
- 记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
用于衡量你进程调度的总时间
- 其他信息
⚠️:虽然上面都很抽象,但这些概念本质就是
task_struct内的一个属性(数字,bool等)!
3.3.2 获取进程ID(建议配合 3.3.3 一起食用)
它是 POSIX 标准提供的一个函数,用于获取当前进程的进程 ID(PID),属于 系统调用 。
c
#include <unistd.h>
pid_t pid = getpid();
cpp
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
while(1)
{
printf ("I am a process,pid %d\n",getpid());
sleep(1);
}
return 0;
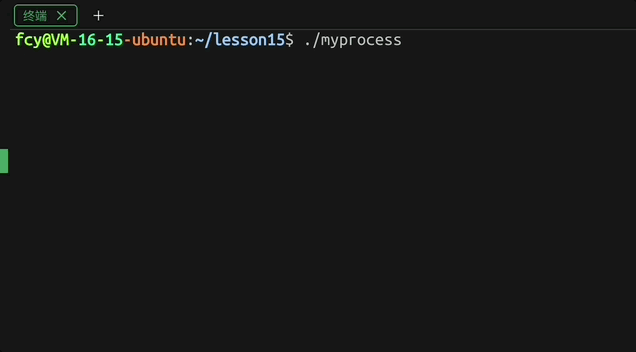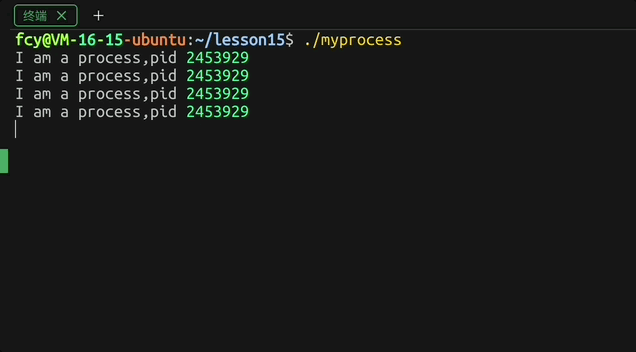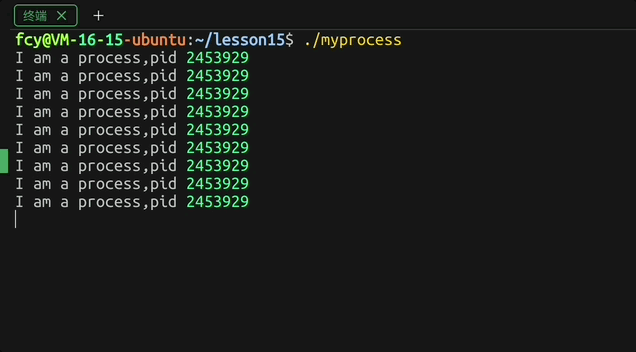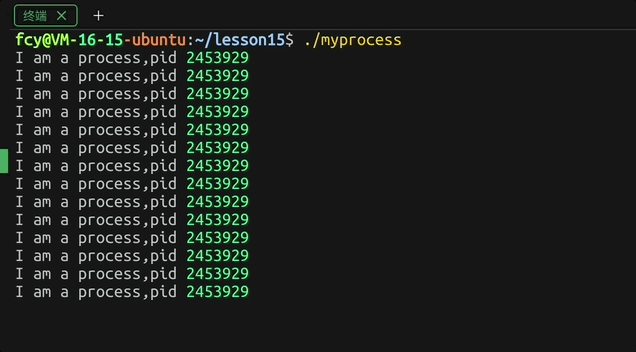
}效果:
当然每次运行程序后 它的
pid都会发生变化(这个就不展示了)
3.3.3 认清楚系统调用和库函数(加餐)
我认为写这一段是很有必要的,因为我学的时候就对库和系统调用还是有些不理解,有些陌生概念没必要懂,只是为了说明一下系统调用和库函数的区别与关系,如果你对这两个概念理解非常清楚,跳过不看也没事。
被库封装的系统调用,本质上仍然是系统调用;库只是提供了一个用户友好的"包装接口"。
- 语义上 / 功能上 :它是 系统调用(因为最终目的是请求内核服务);
- 代码形式上 :你调用的是 库函数 (比如 glibc 中的
getpid()函数);- 执行时 :它会 触发真正的系统调用机制 (如
syscall指令)。
c
#include <unistd.h>
pid_t pid = getpid(); // ← 写的是"函数调用"getpid这个符号 :由 C 标准库(如 glibc)提供,是一个函数;- 这个函数的实现 :
- 在老系统中:内部执行
syscall(__NR_getpid)→ 真正陷入内核; - 在现代 Linux 中:可能通过 VDSO 直接读取内核映射到用户空间的内存页 → 不陷入内核,但仍是系统调用的语义;
- 在老系统中:内部执行
- 无论哪种实现,它的目的始终是:获取内核为当前进程分配的 PID。
所以:库是"信使",系统调用是"国王的命令" 。
你对信使说话,但真正做事的是国王(内核)。
🧩 类比理解
| 角色 | 对应 |
|---|---|
| 你想办护照(需求) | 用户程序想获取 PID |
| 你去政务大厅窗口提交申请 | 调用 getpid()(库函数) |
| 窗口工作人员把你的材料转给公安局 | 库函数触发系统调用 |
| 公安局(内核)审核并签发护照 | 内核返回 PID |
👉 你接触的是窗口(库) ,但权力来自公安局(内核) 。
所以这件事的本质是"政府服务"(系统调用),不是"窗口自营业务"。
✅ 如何判断一个函数是不是系统调用?
看它是否最终依赖内核提供服务:
| 函数 | 是系统调用? | 说明 |
|---|---|---|
getpid() |
✅ 是 | 必须由内核提供 PID |
read() |
✅ 是 | 必须由内核读磁盘/设备 |
printf() |
❌ 否 | 是库函数,内部调用 write()(系统调用) |
malloc() |
❌ 否 | 是库函数,内部调用 brk/mmap(系统调用) |
strlen() |
❌ 否 | 纯用户态计算,无需内核 |
💡 规则 :如果函数的功能涉及硬件、进程、文件、网络、权限等系统资源,那它大概率封装了系统调用。
| 问题 | 回答 |
|---|---|
| 被库封装的系统调用属于库还是系统调用? | 属于系统调用(库只是调用入口) |
| 我调用的是库函数,为什么说是系统调用? | 因为功能由内核实现,库仅做适配和封装 |
| 能否绕过库直接调系统调用? | 可以(如用 syscall(39)),但不推荐(可移植性差) |
🎯 核心思想 :
系统调用是操作系统提供的"能力",库是程序员使用的"工具"。
工具可以换(glibc、musl、Windows CRT),但底层能力始终来自内核。⚠️:被库封装的系统调用,本质上仍然是系统调用;库只是提供了一个用户友好的"包装接口"。(这也是主播学习时当时的一个疑难点)
3.4 查看进程
3.4.1 ps
我们可以使用ps命令查看进程 选项以后章节会介绍,如果想查看详细进程可以
shell
ps axj这里可以:
shell
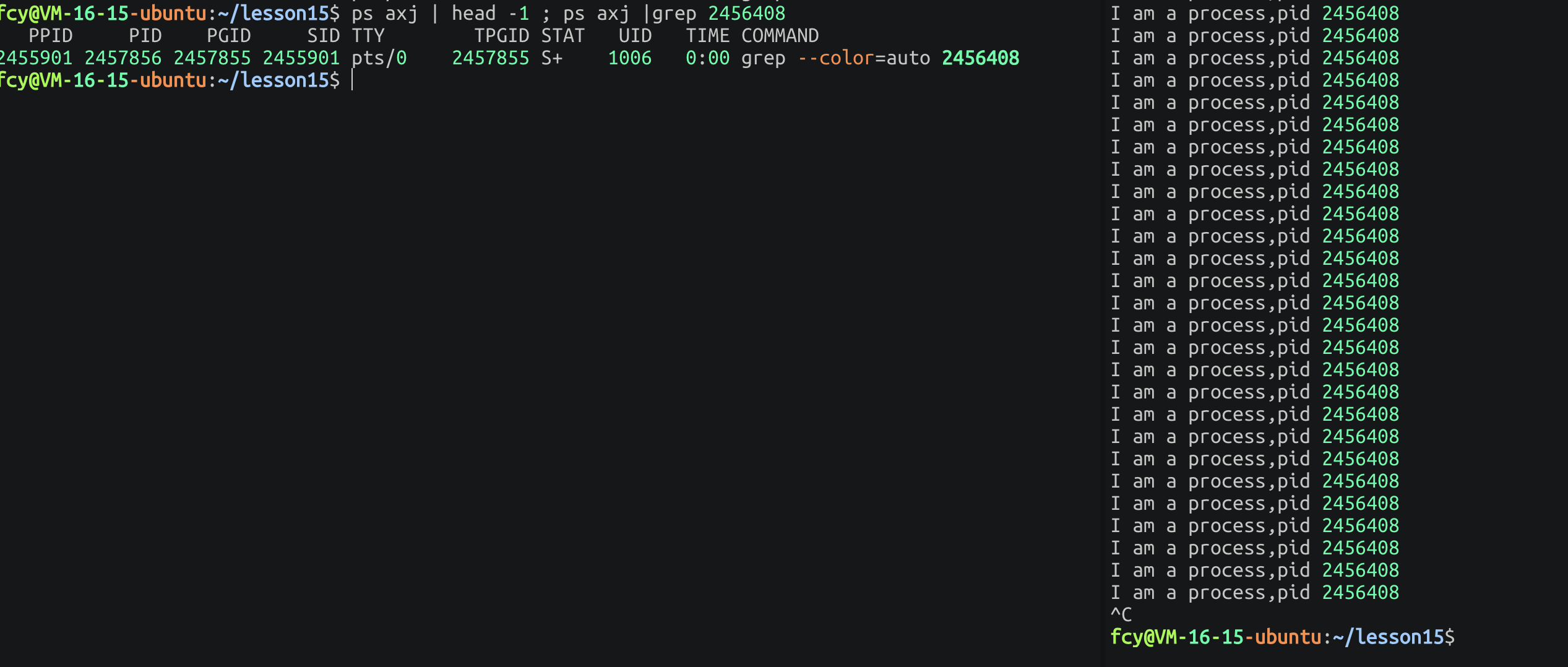
ps axj | head -1 ; ps axj |grep pid
#或者 ps axj | head -1 && ps axj |grep pid
#这里的 ; 和 && 是一样的 表示左边执行完又执行右边当我们运行代码时:可以查看到进程
这里有
grep --color=auto 2456408因为grep是命令 自身也是进程查的时候就一起过滤出来了。
当我们终止代码后,发现进程也没了

3.4.2 父进程
进程里面不光有
pid还有ppid通过getppid()查看其pid
c
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
while(1)
{
printf ("I am a process,pid %d\n,ppid %d",getpid(),getppid());
sleep(1);
}
return 0;
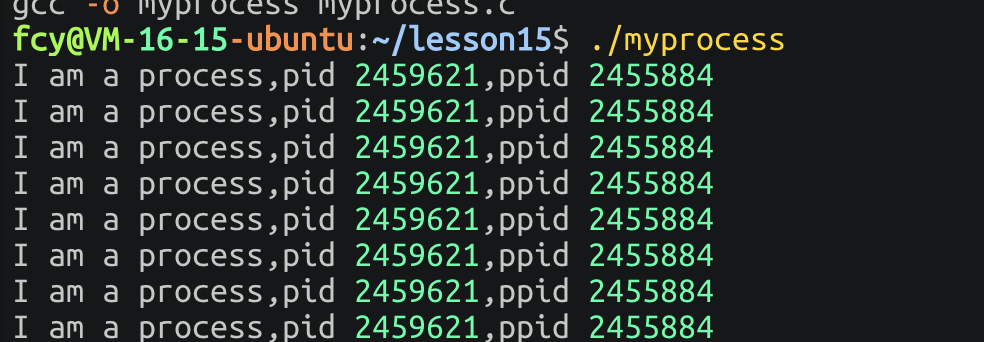
}结果:
那么什么是父进程?通俗讲,在
LInux系统中,新的进程,往往都是通过父进程的方式,创造出来的。在我们每次
./myprocess时候,本质就是创建一个新的进程,每次pid都是会变的,但是神奇的是 我们每次创建 它的ppid都没有改变
那么它的父进程 是啥啊?
通过查看发现,父进程的
pid居然是bash(命令行解释器!)这也可以得出 命令行解释器 本身也是 一个进程!
我们自己的程序一般都是通过 命令行解释器创造出来的子进程

3.4.3 系统⽂件夹查看进程
进程的信息可以通过 /proc 系统⽂件夹查看
在
Linux系统的根目录下 能让进程信息实时的以文件的方式显现
文件夹里面有很多其他文件:
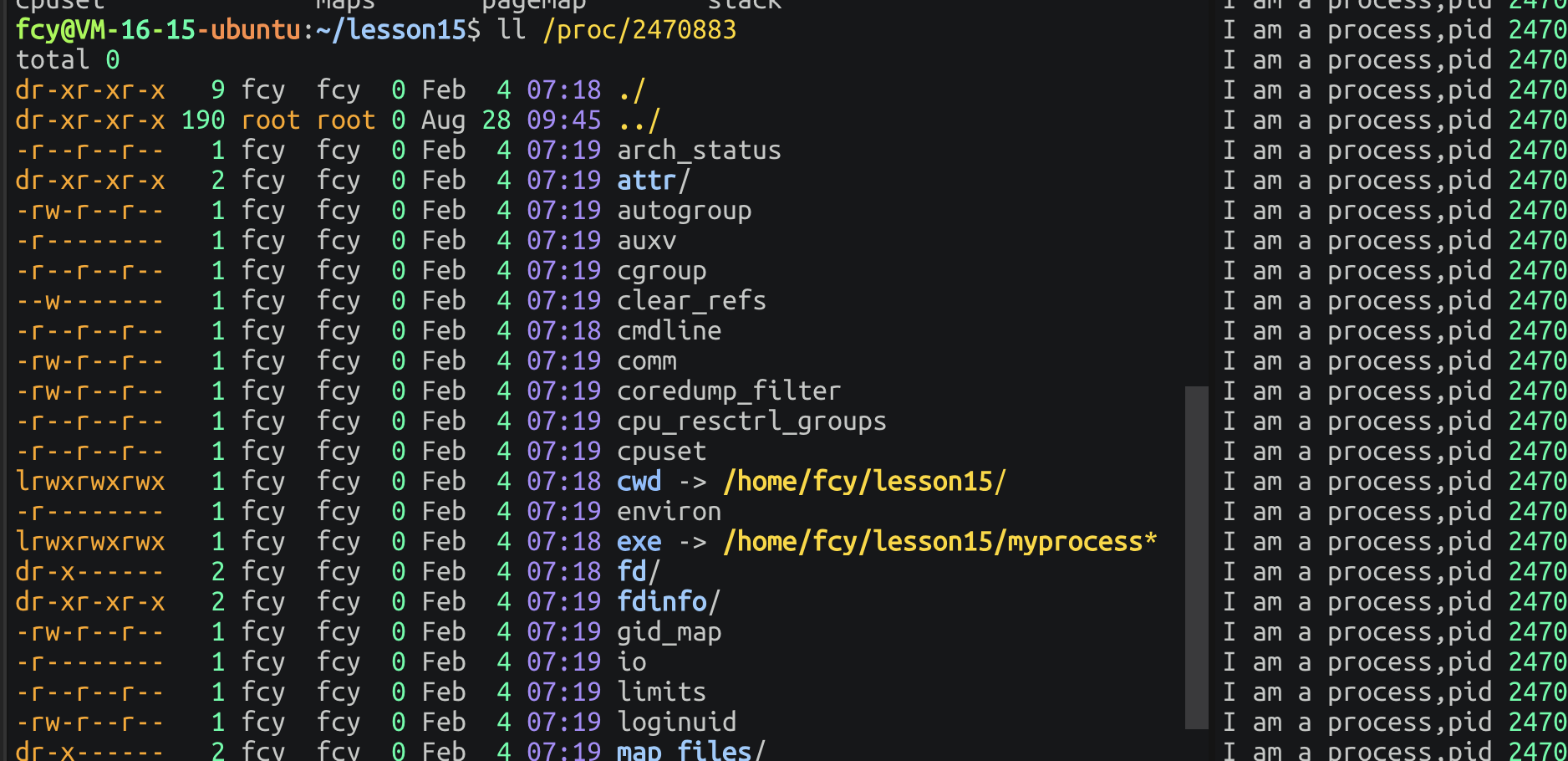
里面的exe是执行程序所在文件 这里面重点要说的是cwd
3.4.4 cwd&&chdir
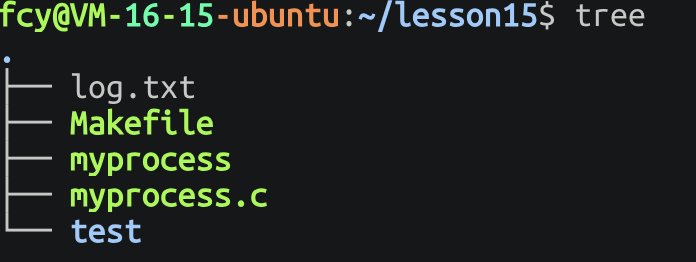
在我们C语言 fopen("log.txt","w")的时候 如果文件不存在 会默认在当前路径 下新建文件 而当前路径就是 cwd 也就是进程的工作路径
cpp
FILE *fp = fopen("log.txt", "w");
if(fp == NULL)
{
perror("fopen");
}
fclose(fp);创建后所在路径默认就是和
process在同一目录下也就是其cwd(工作路径)

而这里为了证明 我们需要用到一个系统调用
chdir,这个是用于更改进程的cwd

cpp
chdir("/home/fcy/lesson15/test");
FILE *fp = fopen("log.txt", "w");
if(fp == NULL)
{
perror("fopen");
}
fclose(fp);
while(1)
{
printf ("I am a process,pid %d,ppid %d\n",getpid(),getppid());
sleep(1);
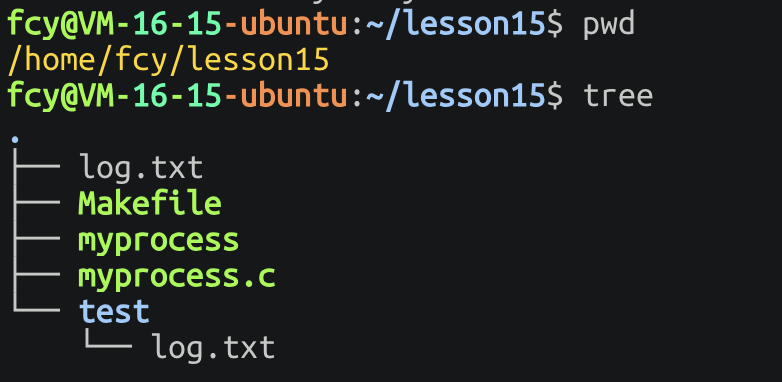
}此时随着
cwd修改 并且log.txt默认生成的地方变成了/home/fcy/lesson15/test
所以说 所谓的
当前工作路径本质上 就是你进程的工作路径!

3.5 创建进程
3.5.1 通过系统调⽤创建进程-fork初识
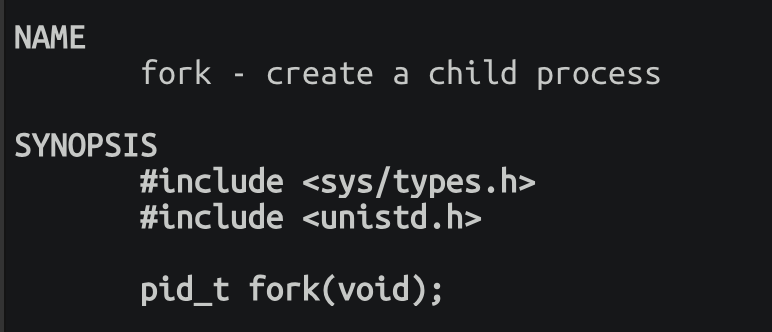
cpp
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
printf("我是一个进程,pid: %d,ppid: %d\n",getpid(),getppid());
fork();
printf("我是一个进程(fork过了),pid: %d,ppid: %d\n",getpid(),getppid());
return 0;
}运行结果:

在fork之前 只有一个执行流 2466421;但是fork之后 就有了两个执行流 多了个2466422 也就是子进程 ,其实在bash内部本质也是用fork创建的子进程。
同时我们也发现以下代码执行了两次:
cpp
printf("我是一个进程(fork过了),pid: %d,ppid: %d\n",getpid(),getppid());3.3.2 fork的返回值问题
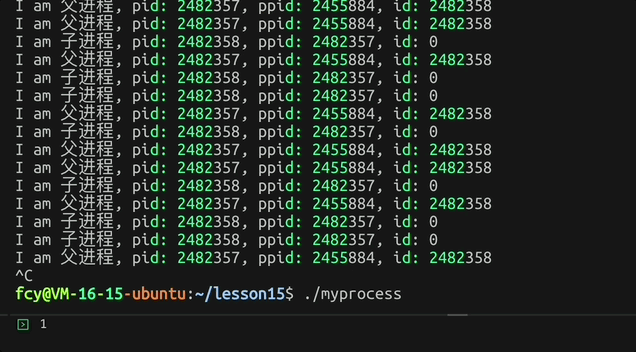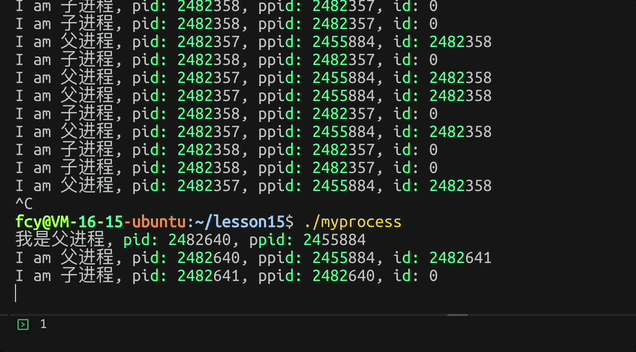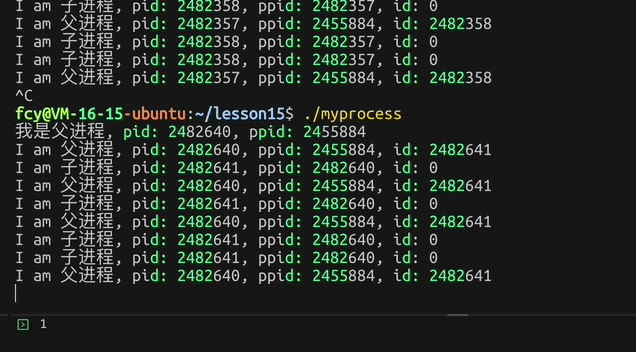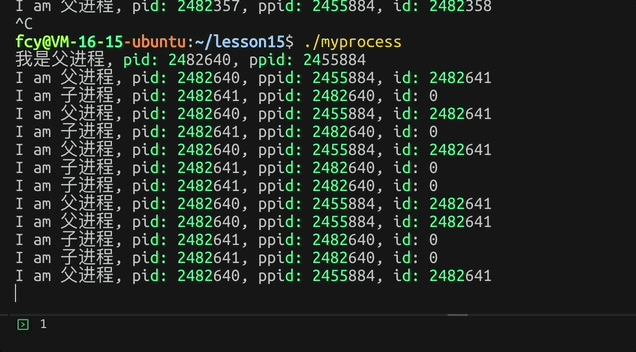
fork后 子进程返回0而父进程返回子进程的pid,而返回值 可以进行父子分流!让不同进程干不同的事
c
printf("我是父进程, pid: %d, ppid: %d\n", getpid(), getppid());
pid_t id = fork();
if(id == 0)
{
// 子进程
while(1)
{
printf("I am 子进程, pid: %d, ppid: %d, id: %d\n", getpid(), getppid(), id);
sleep(1);
}
}
else
{
// 父进程
while(1)
{
printf("I am 父进程, pid: %d, ppid: %d, id: %d\n", getpid(), getppid(), id);
sleep(1);
}
}效果:
默认情况下fork后 子进程会以父进程为模版 生成一个task_struct,但是代码和数据二者事共享的
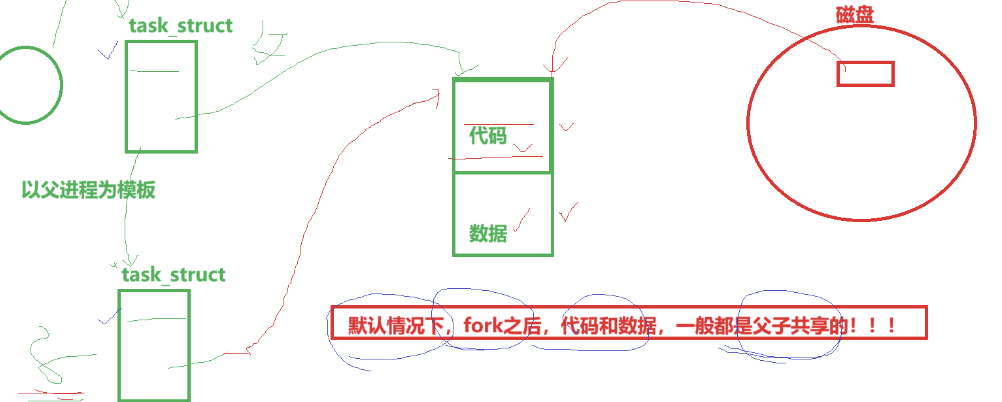
为什么fork()一个函数可以返回两次?
fork核心工作是创建子进程,一定有一个功能,就是把父进程的PCB给子进程拷贝一份,而fork最后工作一定是return id在return id执行前 该函数核心功能肯定是已经完成了 也就是说此时 父子进程都已经存在了,子进程的PCB肯定是已经创建好了,注意此时代码是父子进程共享的 你printf都能打两次,那么你return是不是也能返回两次!所以
return返回两次 本质是父子各执行两次return!!
那为什么id返回值又不同?
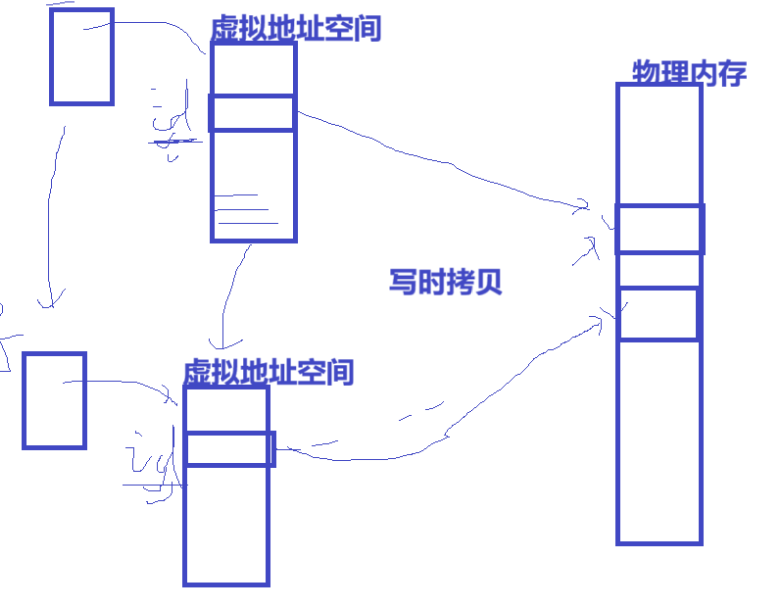
这里现有知识没发完整解释 其实这里的id所对应的空间 是在虚拟空间上开辟的 现在就说那么多 等学了虚拟地址空间就明白了。
简单来说虚拟内存 独立于物理内存 父子进程各有一个
id在虚拟内存上,当id相同的时候 此时物理内存上存储的id此时是父子进程是共用同一块物理内存的 当其中一个id在虚拟内存上修改后(return写入新的id) 此时会额外开辟新的物理内存 创建一个新的id 这个也叫 写时拷贝 ,也就是说虽然都叫id但是对应内存已经变了 父子进程的id所在物理内存是不同的(了解就行,不懂也没事)