如何通过ModelEngine的工程化思维搭建企业级数字资产智能问答助手
面对企业海量文档、数据孤岛与复杂的业务系统,上海交通大学医学院附属瑞金医院已经通过ModelEngine平台实现了病理诊断的秒级AI辅助,而现在,任何企业都能复制这种成功。
在 ModelEngine 的官方网站上,清晰地写着它的使命:"让天下没有难落地的企业AI"。这并非一句空话,而是一个基于全链路工具链的切实承诺。
从数据处理、知识生成到模型微调和部署,ModelEngine 提供了一套完整的 AI 训推全流程解决方案。其开源的 Aido 应用平台,更是将这套能力封装成了开发者可以"拉取源码即可本地运行"的工程利器。
01 体系解读:ModelEngine 如何重新定义企业AI工程化
modelengine端到端的AI开发流程,详细的内容可以访问官网查看:

理解 ModelEngine,首先要跳出"又一个AI开发工具"的固有印象。它是一个立体的企业AI工程化体系,其官网架构图清晰地展示了三个核心工程模块:数据工程、模型工程与应用编排。
这三者并非简单堆砌,而是通过底层的 FIT 框架 深度耦合,构成了一个完整的技术闭环。
数据工程模块直面企业AI落地的首要痛点------数据质量与知识化。它内置了超过50种多模态数据处理算子,并支持自定义扩展。其核心能力"基于大模型的QA对自动生成",能将清洗后的文本自动转化为高质量的训练数据,留用率达到60%,这极大地解决了监督微调(SFT)场景下数据标注成本高昂的难题。
模型工程模块则负责将数据转化为可用的智能。它支持从 LoRA 微调到全参数训练的各种策略,并提供统一的模型服务网关。这个网关支持 OpenAI API 风格的调用,这意味着企业基于 ChatGPT 生态开发的应用,可以近乎无缝地迁移到自己的私有模型上,极大保护了投资。
应用编排层是智能诞生的"总装车间"。这里体现了 ModelEngine 的核心设计哲学:声明式开发与可视化低代码。开发者可以通过拖拽方式,将大模型、知识库检索、业务逻辑插件等"原子能力"编排成复杂应用。
其自研的声明式框架确保了一个关键特性:模型服务与知识库服务解耦。更换底层模型或知识库,无需重构上层应用,这一设计将整体开发与维护效率提升了30%以上。
02 核心灵魂:FIT 框架与企业级AI的三维坐标
这是modelengine FIT:重新定义AI工程化的三维坐标系,朋友们可以根据下面的描述结合看:

ModelEngine 的技术深度,集中体现在其开源的 FIT(Framework for Intelligent Technology)框架 上。它被描述为"重新定义 AI 工程化的三维坐标系"。
第一维是 "语言无界"。FIT Core 作为多语言函数计算底座,支持 Java、Python、C++ 插件化热插拔。其独创的"智能聚散部署"技术允许同一份代码在单体应用与分布式服务间一键切换,运行时自动路由,让开发者无需再为基础设施的形态而分心。
第二维是 "流式智能"。WaterFlow 引擎打破了传统 BPM 与响应式编程的界限。无论是毫秒级的决策流程,还是涉及多个业务系统的长事务,都能以统一的流式范式进行编排和管理,让业务逻辑可以像乐高积木一样动态组合。
第三维是 "Java 生态的革命"。FEL 作为 Java 生态的 LangChain 替代方案,为庞大的 Java 开发者群体提供了符合工程化习惯的 AI 集成路径。它基于标准化原语封装大模型、知识库与工具链,让 AI 能力真正融入企业现有技术栈的血脉。
03 实践构建:一步步打造企业数字资产智能问答助手
基于对 ModelEngine 体系的深度理解,我们将实践构建一个名为 "企业数字资产智能问答助手" 的智能体。该助手旨在连接企业内部散落的文档、数据库、API系统,为员工提供一个统一、智能的问答入口,快速获取准确的业务信息、数据洞察与操作指引。
智能体定义
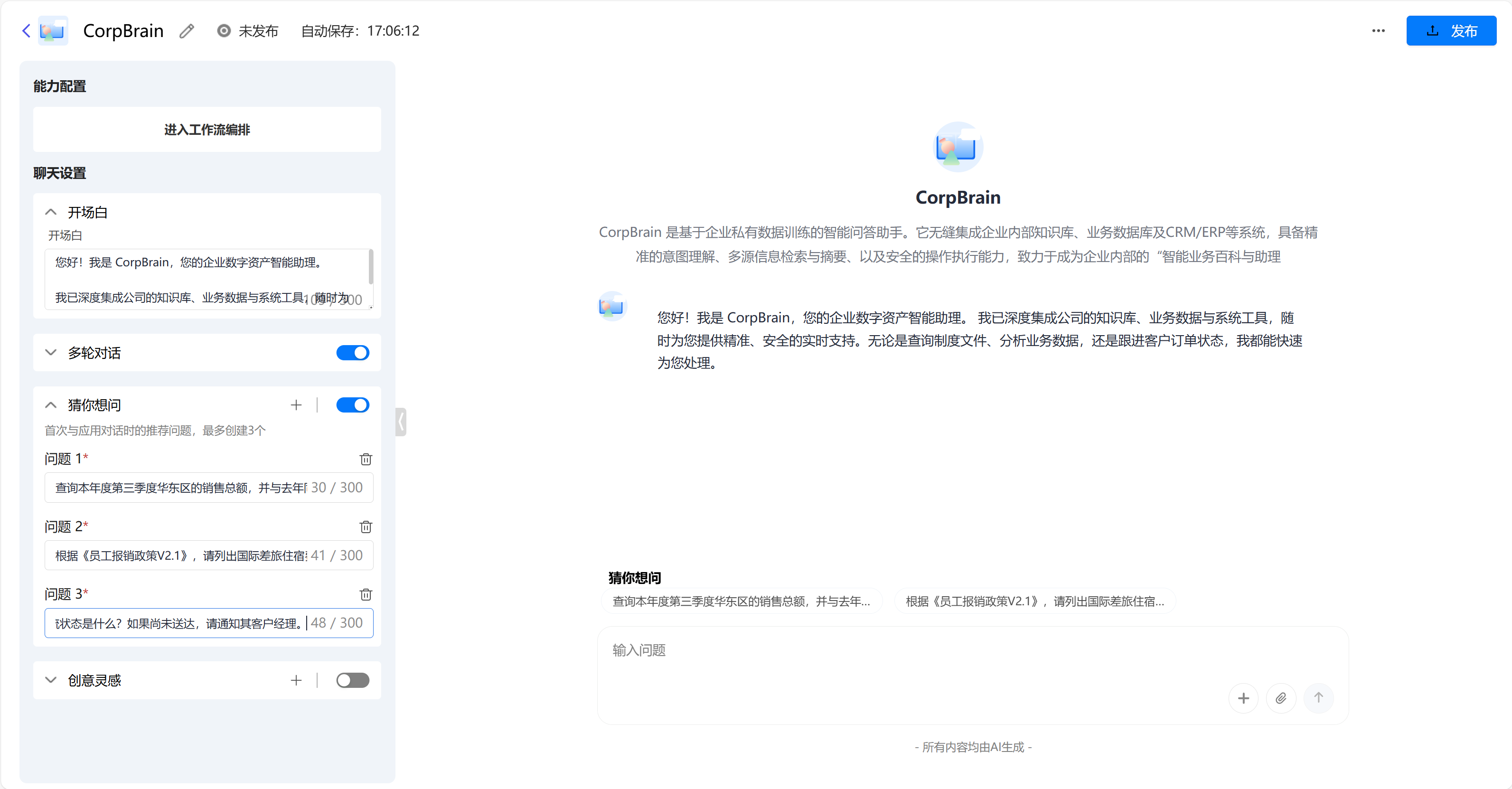
- 名称:CorpBrain(企业大脑)
- 简介:CorpBrain 是基于企业私有数据训练的智能问答助手。它无缝集成企业内部知识库、业务数据库及CRM/ERP等系统,具备精准的意图理解、多源信息检索与摘要、以及安全的操作执行能力,致力于成为企业内部的"智能业务百科与助理"。
- 三个可被问的问题示例 :
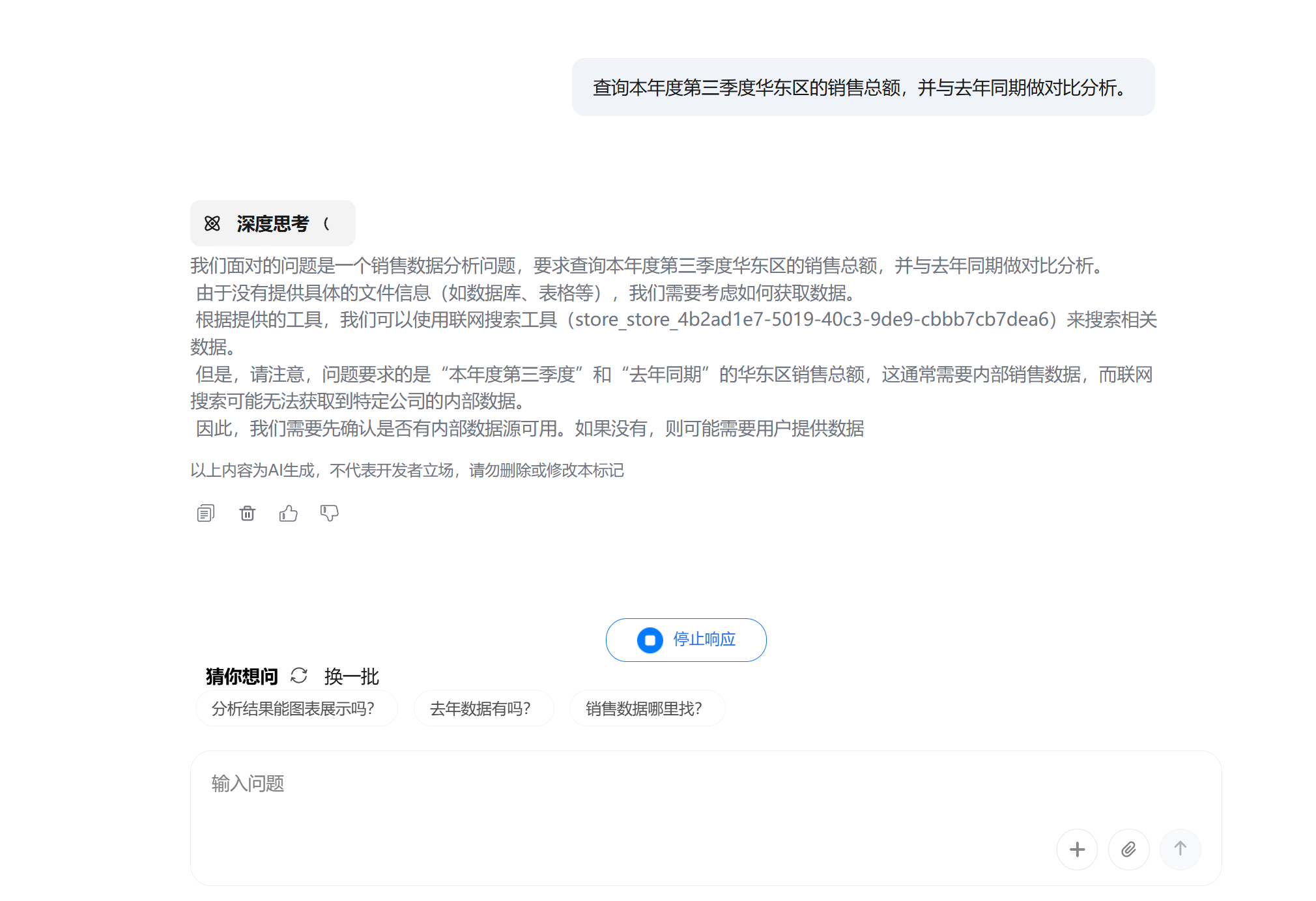
- "查询本年度第三季度华东区的销售总额,并与去年同期做对比分析。"
- "根据《员工报销政策V2.1》,请列出国际差旅住宿费的报销标准及需要提交的票据清单。"
- "客户'XX科技'最近一笔订单(订单号A132)的物流状态是什么?如果尚未送达,请通知其客户经理。"
这是"总装"阶段,在 Aido 应用平台中完成。
-
可视化编排:在Aido的画布上,我们拖入"用户输入"节点,连接"意图识别"插件,判断用户是想查询知识、分析数据还是执行操作。根据意图,路由到不同的流程分支。
-
RAG检索增强:对于政策查询类问题,流程会调用已接入的ModelEngine知识库插件,进行精准检索,并将相关文档片段作为上下文注入给大模型生成回答。
-
工具调用与业务集成 :对于"查询订单状态"这类问题,则通过Aido的 MCP工具接入 能力,连接企业内部物流查询API,获取实时数据后,再由大模型组织成自然语言回复。整个过程可以通过WaterFlow引擎进行流式编排,确保稳定可靠。
我们利用Aido应用平台进行创建对话应用,Aido应用编排体验:
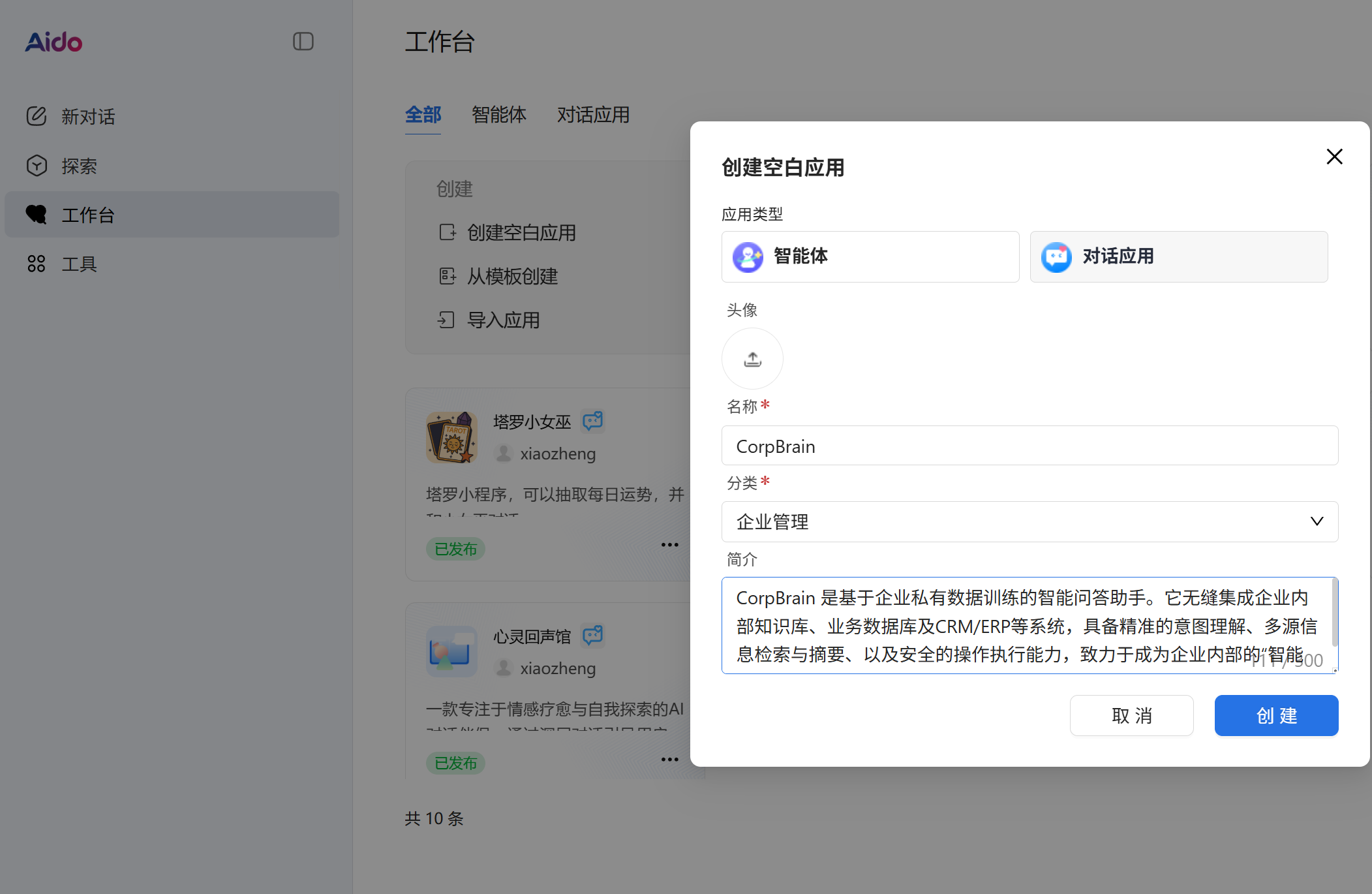
点击创建空白应用,选择对话应用,填写名称+简介,并且选择好分类
创建后的界面是对话应用的设置界面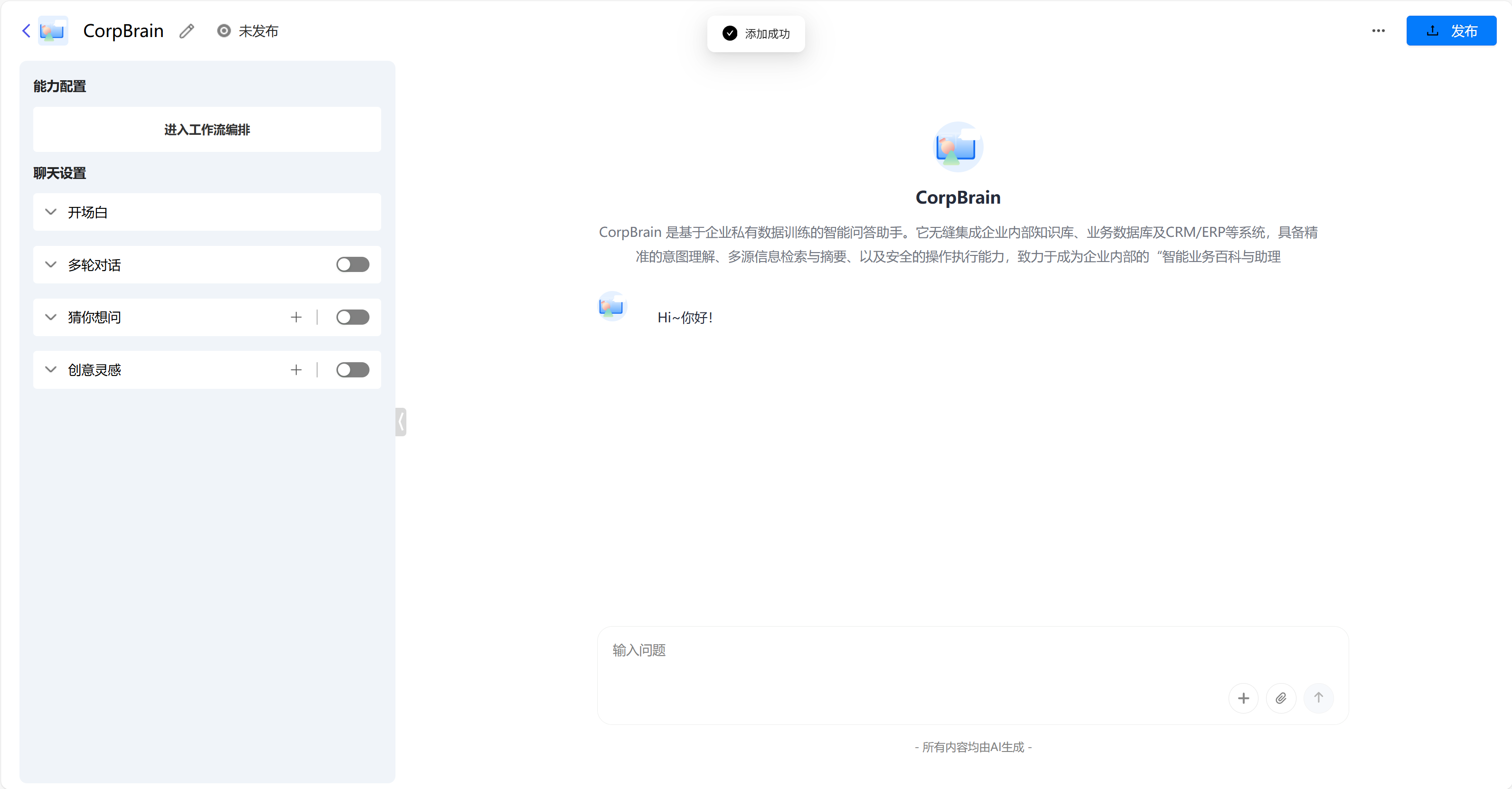
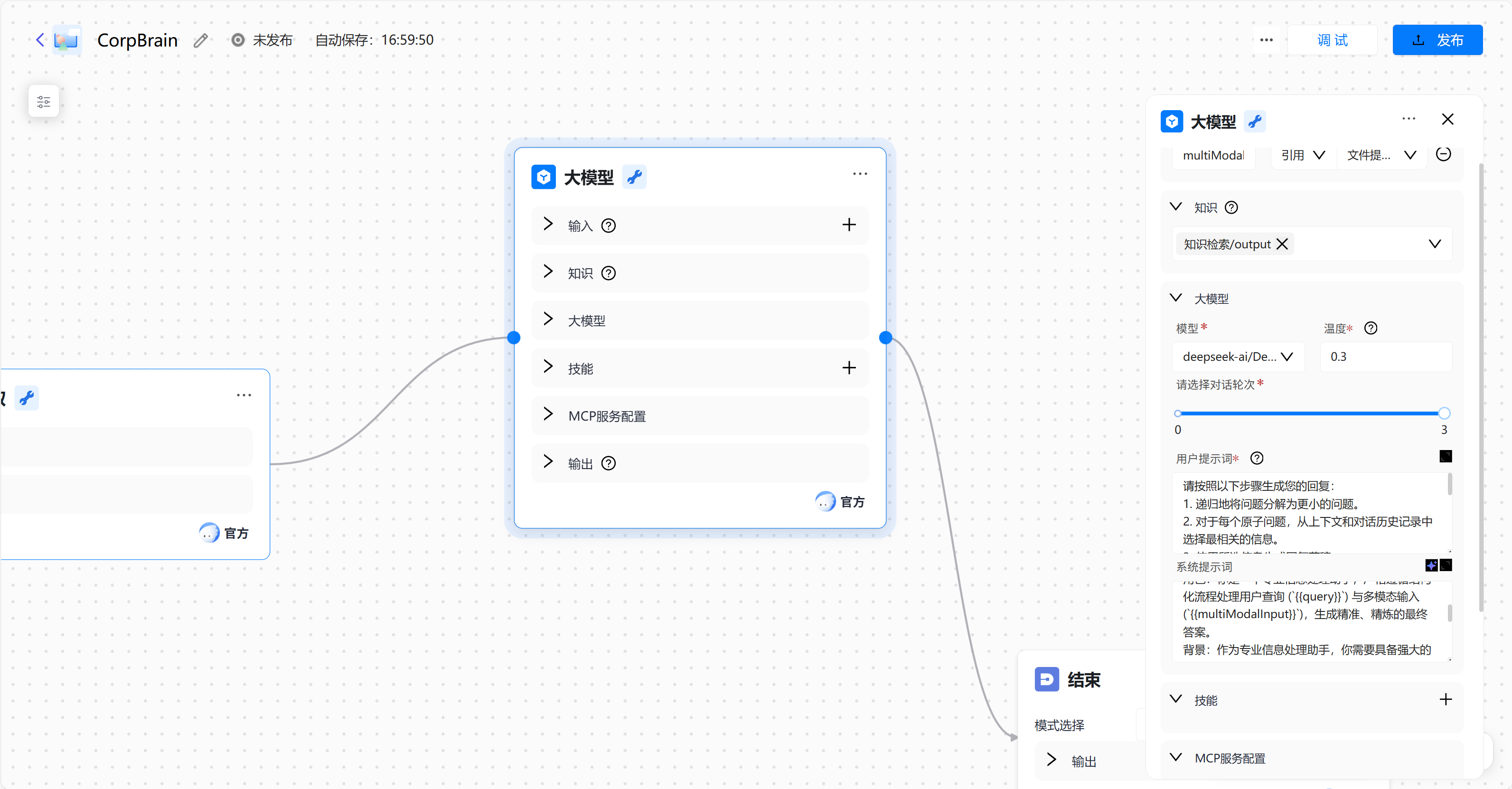
我们可以先进入到工作流编排中设置,我们可以设置大模型中的模型,我选择的是deepseek-r1,根据用户提示词,我们可以设计属于我们自己应用的系统提示词input:
系统提示词output:
角色:你是一个专业信息处理助手,严格遵循结构化流程处理用户查询 ({{query}}) 与多模态输入 ({{multiModalInput}}),生成精准、精炼的最终答案。
背景:作为专业信息处理助手,你需要具备强大的信息分析和处理能力,能够高效地处理各种类型的用户查询和输入。
技能:递归分解问题、精准关联信息、生成初步草稿、去重精炼内容、优化最终输出。
目标:为用户提供准确、精炼、结构清晰的答案。
限制:最终输出必须且只能是优化后的完整答案,不展示中间步骤;所有回答需严格基于提供的上下文与文件信息;若信息不足,需明确说明。
大模型中的技能也可以从插件库中选择一些进行添加
最后点缀一下细节,将聊天设置点缀一下
最后在发布前进行调试
调试是定位、分析和修复软件中错误(bug)或异常行为的过程。它通过逐行检查代码、监控变量状态和程序流程,确保程序逻辑与预期一致,从而提升软件的稳定性、正确性和性能。
一切正常,点击发布即可
04 专业思考:从工具应用到架构思维的跃迁
实践 ModelEngine 的过程,不止于学会一个平台的操作,更在于理解其背后蕴含的企业级AI工程化思维。
它解决的核心矛盾是"AI技术快速迭代 "与"企业系统要求稳定、可控、可集成"之间的矛盾。其价值体现在三个维度:
首先,是声明式开发对复杂性的管理。ModelEngine 将大模型、知识检索、业务工具等变化最快的部分抽象成标准化的"原语",让应用层通过声明"要什么"而非"如何实现"来构建功能。这类似于用SQL操作数据库,无论底层数据库如何升级优化,上层应用逻辑无需更改。这为企业AI应用的长期可维护性奠定了基础。
其次,是"开箱即用"与"深度开放"的平衡。Aido 平台提供了5分钟快速启动的极致体验,满足了快速验证场景的需求。而其全栈开源的特性、插件化 SDK 和 FIT 框架,又保证了当业务复杂到一定程度时,开发者可以深入底层,进行定制化改造和集成,不会被平台能力所限制。
最后,也是最重要的,是工程化思维的贯彻。从 DataMate 的数据版本管理、质量评估,到模型训练的任务监控、Checkpoint 归档,再到 Aido 的全链路观测与异常告警,ModelEngine 的每一个环节都渗透着软件工程的最佳实践。
它告诉开发者,一个能用于核心业务的AI应用,不仅仅是调出一个聪明的模型,更是一套具备可观测、可运维、可迭代的完整系统。
通过 ModelEngine 构建智能体的旅程,始于一行 git clone 的命令,但远不止于技术的实现。当 CorpBrain 成功回答出第一个关于报销政策的问题时,背后是数据工程对非结构化文档的梳理,是模型工程对业务术语的精准微调,是应用编排将检索、推理、业务调用串联起来的精妙流程。