MCP(Model Context Protocol)是一种用于将 AI 应用程序连接到外部系统的开源标准。 使用 MCP,Claude 或 ChatGPT 等 AI 应用程序可以连接到数据源(例如本地文件、数据库)、工具(例如搜索引擎、计算器)和工作流程(例如专门的提示),从而使它们能够访问关键信息并执行任务。可以将MCP视为人工智能应用的USB-C接口。正如USB-C提供了一种连接电子设备的标准化方式一样,MCP也提供了一种将人工智能应用连接到外部系统的标准化方式。
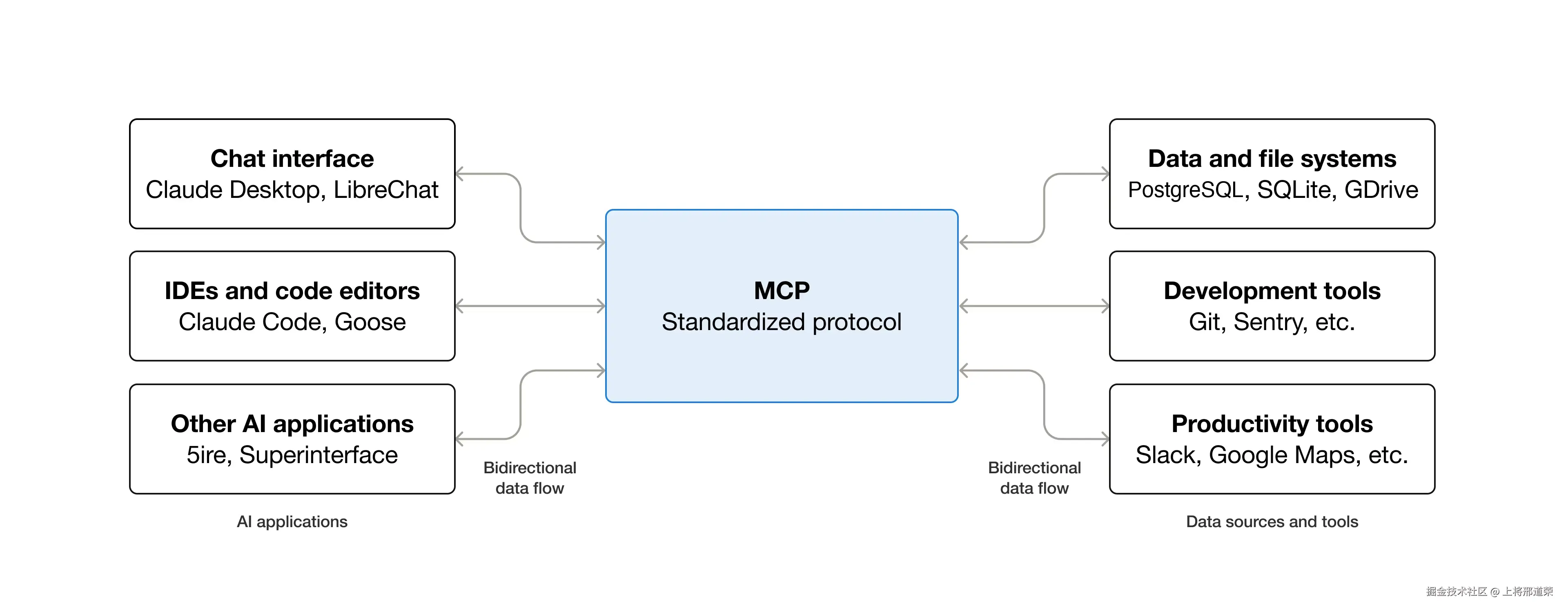
MCP的概念
参与者
MCP 采用客户端-服务器架构,其中 MCP 主机(例如Claude Code或Claude Desktop等 AI 应用)与一个或多个 MCP 服务器建立连接。MCP 主机通过为每个 MCP 服务器创建一个 MCP 客户端来实现这一点。每个 MCP 客户端与其对应的 MCP 服务器保持专用连接。使用 STDIO 传输的本地 MCP 服务器通常服务于单个 MCP 客户端,而使用 Streamable HTTP 传输的远程 MCP 服务器通常服务于多个 MCP 客户端。MCP架构的关键参与者包括:
- MCP 主机:用于协调和管理一个或多个 MCP 客户端的 AI 应用程序
- MCP 客户端:一个维护与 MCP 服务器连接并从 MCP 服务器获取上下文以供 MCP 主机使用的组件。
- MCP 服务器:一个为 MCP 客户端提供上下文信息的程序
例如 :Visual Studio Code 充当 MCP 主机。当 Visual Studio Code 与 MCP 服务器(例如Sentry MCP 服务器)建立连接时,Visual Studio Code 运行时会实例化一个 MCP 客户端对象来维护与 Sentry MCP 服务器的连接。随后,当 Visual Studio Code 连接到另一个 MCP 服务器(例如本地文件系统服务器)时,Visual Studio Code 运行时会实例化另一个 MCP 客户端对象来维护此连接。
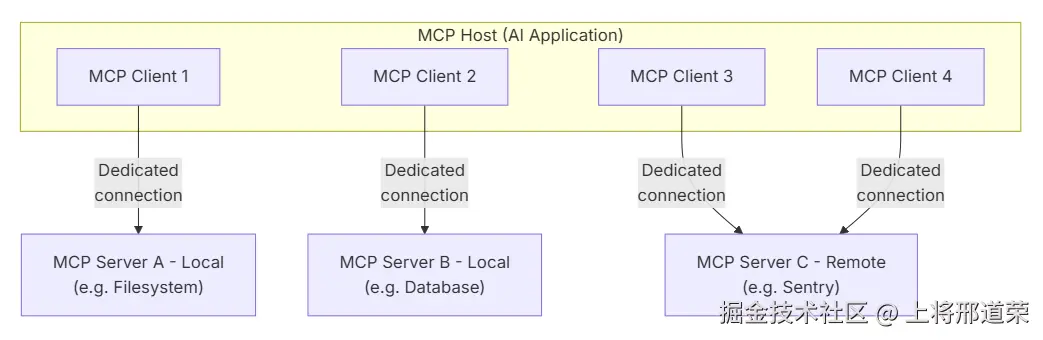 请注意,MCP 服务器 指的是提供上下文数据的程序,无论其运行位置如何。MCP 服务器可以本地运行,也可以远程运行。例如,当 Claude Desktop 启动文件系统服务器时,由于它使用 STDIO 传输,因此服务器运行在同一台机器上。这通常被称为"本地"MCP 服务器。官方的 Sentry MCP 服务器运行在 Sentry 平台上,并使用 Streamable HTTP 传输。这通常被称为"远程"MCP 服务器。
请注意,MCP 服务器 指的是提供上下文数据的程序,无论其运行位置如何。MCP 服务器可以本地运行,也可以远程运行。例如,当 Claude Desktop 启动文件系统服务器时,由于它使用 STDIO 传输,因此服务器运行在同一台机器上。这通常被称为"本地"MCP 服务器。官方的 Sentry MCP 服务器运行在 Sentry 平台上,并使用 Streamable HTTP 传输。这通常被称为"远程"MCP 服务器。
层
MCP由两层组成:
- 数据层:定义了基于 JSON-RPC 的客户端-服务器通信协议,包括生命周期管理和核心原语,如工具、资源、提示和通知。
- 传输层:定义了客户端和服务器之间进行数据交换的通信机制和通道,包括特定于传输的连接建立、消息帧和授权。
从概念上讲,数据层是内层,而传输层是外层。
数据层
数据层实现了基于JSON-RPC 2.0 的交换协议,该协议定义了消息结构和语义。该层包括:
- 生命周期管理:处理客户端和服务器之间的连接初始化、能力协商和连接终止。
- 服务器功能:使服务器能够提供核心功能,包括用于 AI 操作的工具、上下文数据资源以及来自客户端和与客户端交互的模板提示。
- 客户端功能:使服务器能够请求客户端从主机LLM进行采样、获取用户输入以及向客户端记录消息。
- 实用功能:支持实时更新通知和长时间运行操作的进度跟踪等附加功能
传输层
传输层管理客户端和服务器之间的通信通道和身份验证。它处理连接建立、消息帧构建以及MCP参与者之间的安全通信。MCP支持两种运输机制:
- Stdio 传输:使用标准输入/输出流在同一台机器上的本地进程之间进行直接进程通信,提供最佳性能,且无网络开销。
- 可流式 HTTP 传输:使用 HTTP POST 请求进行客户端到服务器的消息通信,并可选地使用服务器发送事件 (SENT) 来实现流式传输功能。此传输方式支持远程服务器通信,并支持包括持有者令牌、API 密钥和自定义标头在内的标准 HTTP 身份验证方法。MCP 建议使用 OAuth 获取身份验证令牌。
传输层将通信细节从协议层中抽象出来,从而实现所有传输机制都采用相同的 JSON-RPC 2.0 消息格式。
数据层协议
MCP 的核心部分在于定义 MCP 客户端和 MCP 服务器之间的模式和语义。开发人员可能会发现数据层(尤其是基本类型集合)是 MCP 中最有趣的部分。它定义了开发人员如何将上下文从 MCP 服务器共享到 MCP 客户端。MCP 使用JSON-RPC 2.0作为其底层 RPC 协议。客户端和服务器相互发送请求并做出相应的响应。当不需要响应时,可以使用通知机制。
生命周期管理
MCP 是一种有状态协议这就需要生命周期管理。生命周期管理的目的是协商......能力客户端和服务器都支持此功能。详细信息请参阅规范,示例展示了初始化顺序。
基本元素
MCP 原语是 MCP 中最重要的概念。它们定义了客户端和服务器之间可以相互提供哪些信息。这些原语明确规定了可以与 AI 应用共享的上下文信息类型以及可以执行的操作范围。MCP 定义了服务器可以公开的三个核心原语:
- 工具:人工智能应用程序可以调用以执行操作的可执行函数(例如,文件操作、API 调用、数据库查询)
- 资源:为人工智能应用程序提供上下文信息的数据源(例如,文件内容、数据库记录、API 响应)
- 提示:可重用的模板,有助于构建与语言模型的交互(例如,系统提示、少样本示例)
每种基本类型都有相关的发现方法(*/list)、检索方法(*/get)以及在某些情况下执行方法(tools/call)。MCP 客户端会使用这些*/list方法来发现可用的基本类型。例如,客户端可以先列出所有可用的工具(tools/list),然后再执行它们。这种设计使得列表可以动态更新。举个具体的例子,考虑一个提供数据库上下文信息的 MCP 服务器。它可以公开用于查询数据库的工具、包含数据库模式的资源,以及包含与这些工具交互的简短示例的提示。有关服务器原语的更多详细信息,请参阅服务器概念。MCP 还定义了客户端可以公开的基本功能。这些基本功能允许 MCP 服务器开发者构建更丰富的交互。
- 采样 :允许服务器向客户端的 AI 应用程序请求语言模型补全。当服务器开发者需要访问语言模型,但又希望保持模型独立性,并且不希望在其 MCP 服务器中包含语言模型 SDK 时,此功能非常有用。他们可以使用此
sampling/complete方法向客户端的 AI 应用程序请求语言模型补全。 - 请求获取 :允许服务器向用户请求额外信息。当服务器开发者想要从用户那里获取更多信息,或请求用户确认某个操作时,此功能非常有用。他们可以使用此
elicitation/request方法向用户请求额外信息。 - 日志记录:允许服务器向客户端发送日志消息,以便进行调试和监控。
有关客户端原语的更多详细信息,请参阅客户端概念。除了服务器和客户端原语之外,该协议还提供了横切实用原语,用于增强请求的执行方式:
- 任务(实验性) :持久执行包装器,可对 MCP 请求(例如,昂贵的计算、工作流自动化、批量处理、多步骤操作)进行延迟结果检索和状态跟踪。
通知
该协议支持实时通知,从而实现服务器和客户端之间的动态更新。例如,当服务器的可用工具发生变化时(例如,当新功能上线或现有工具被修改时),服务器可以发送工具更新通知,告知已连接的客户端这些变化。通知以 JSON-RPC 2.0 通知消息的形式发送(无需响应),使 MCP 服务器能够向已连接的客户端提供实时更新。
例子
数据层
本节将逐步介绍 MCP 客户端-服务器交互过程,重点关注数据层协议。我们将使用 JSON-RPC 2.0 消息演示生命周期顺序、工具操作和通知。
1
初始化(生命周期管理)
MCP 从生命周期管理开始,通过能力协商握手来实现。如生命周期管理部分所述,客户端发送initialize请求以建立连接并协商支持的功能。
初始化请求
初始化响应
json
{
"jsonrpc": "2.0",
"id": 1,
"method": "initialize",
"params": {
"protocolVersion": "2025-06-18",
"capabilities": {
"elicitation": {}
},
"clientInfo": {
"name": "example-client",
"version": "1.0.0"
}
}
}了解初始化交换
初始化过程是 MCP 生命周期管理的关键部分,具有以下几个重要用途:
- 协议版本协商 :此
protocolVersion字段(例如"2025-06-18")确保客户端和服务器使用兼容的协议版本。这可以防止不同版本尝试交互时可能发生的通信错误。如果无法协商出相互兼容的版本,则应终止连接。 - 功能发现 :该
capabilities对象允许各方声明其支持的功能,包括可以处理的基本类型(工具、资源、提示)以及是否支持通知等功能。这有助于避免执行不支持的操作,从而实现高效通信。 - 身份交换 :
clientInfo对象serverInfo提供标识和版本信息,用于调试和兼容性目的。
在这个例子中,能力协商演示了如何声明 MCP 原语:客户端功能:
"elicitation": {}- 客户端声明它可以处理用户交互请求(可以接收elicitation/create方法调用)
服务器功能:
"tools": {"listChanged": true}服务器支持工具原语,并且可以tools/list_changed在工具列表发生变化时发送通知。"resources": {}服务器还支持资源原语(可以处理resources/list和resources/read方法)
初始化成功后,客户端会发送通知表明其已准备就绪:
通知
json
{
"jsonrpc": "2.0",
"method": "notifications/initialized"
}它在人工智能应用中的工作原理
在初始化过程中,AI 应用的 MCP 客户端管理器会建立与已配置服务器的连接,并存储其功能以供后续使用。应用会利用这些信息来确定哪些服务器可以提供特定类型的功能(工具、资源、提示),以及它们是否支持实时更新。
AI应用程序初始化的伪代码
python
# Pseudo Code
async with stdio_client(server_config) as (read, write):
async with ClientSession(read, write) as session:
init_response = await session.initialize()
if init_response.capabilities.tools:
app.register_mcp_server(session, supports_tools=True)
app.set_server_ready(session)2
工具发现(原始工具)
连接建立后,客户端可以通过发送tools/list请求来发现可用的工具。此请求是 MCP 工具发现机制的基础------它允许客户端在尝试使用工具之前了解服务器上有哪些工具可用。
工具列表请求
工具列表响应
json
{
"jsonrpc": "2.0",
"id": 2,
"method": "tools/list"
}了解工具发现请求
请求tools/list很简单,不包含任何参数。
了解工具发现响应
响应包含一个tools数组,其中提供了每个可用工具的完整元数据。这种基于数组的结构允许服务器同时公开多个工具,同时保持不同功能之间的清晰界限。响应中的每个工具对象都包含几个关键字段:
name:服务器命名空间内工具的唯一标识符。它作为工具执行的主键,应遵循清晰的命名模式(例如,calculator_arithmetic而不是仅仅使用<tool>calculate``)。title:客户端可以向用户显示的、易于理解的工具显示名称description:对该工具的功能及其使用时机进行详细说明inputSchema:一个 JSON Schema,用于定义预期的输入参数,实现类型验证,并提供关于必需参数和可选参数的清晰文档。
它在人工智能应用中的工作原理
该人工智能应用程序从所有已连接的 MCP 服务器获取可用工具,并将它们整合到一个统一的工具注册表中,供语言模型访问。这使得语言学习模型 (LLM) 能够理解它可以执行哪些操作,并在对话过程中自动生成相应的工具调用。
AI应用工具发现的伪代码
ini
# Pseudo-code using MCP Python SDK patterns
available_tools = []
for session in app.mcp_server_sessions():
tools_response = await session.list_tools()
available_tools.extend(tools_response.tools)
conversation.register_available_tools(available_tools)3
工具执行(基本体)
客户端现在可以使用该方法执行工具tools/call。这演示了 MCP 原语在实践中的使用方式:在发现可用工具后,客户端可以使用适当的参数调用它们。
了解工具执行请求
该tools/call请求遵循结构化格式,确保类型安全,并保证客户端和服务器之间的清晰通信。请注意,我们使用的是发现响应中的正确工具名称(weather_current),而不是简化名称:
工具调用请求
工具调用响应
json
{
"jsonrpc": "2.0",
"id": 3,
"method": "tools/call",
"params": {
"name": "weather_current",
"arguments": {
"location": "San Francisco",
"units": "imperial"
}
}
}工具执行的关键要素
请求结构包含几个重要组成部分:
-
**
name**必须与发现响应中的工具名称完全匹配(weather_current)。这可以确保服务器能够正确识别要执行的工具。 -
**
arguments**包含工具定义的输入参数inputSchema。例如:location: "旧金山"(必填参数)units: "imperial"(可选参数,如果未指定,则默认为"metric")
-
JSON-RPC 结构 :使用标准的 JSON-RPC 2.0 格式,具有唯一的
id请求-响应关联。
了解工具执行响应
这一回应体现了MCP灵活的内容系统:
content数组:工具响应返回内容对象数组,允许返回丰富的多格式响应(文本、图像、资源等)。- 内容类型 :每个内容对象都有一个
type字段。在本例中,该字段"type": "text"表示纯文本内容,但 MCP 支持多种内容类型,以满足不同的使用场景。 - 结构化输出:响应提供可操作的信息,AI 应用程序可将其用作语言模型交互的上下文。
这种执行模式允许 AI 应用程序动态调用服务器功能并接收结构化响应,这些响应可以集成到与语言模型的对话中。
它在人工智能应用中的工作原理
当语言模型在对话过程中决定使用某个工具时,AI 应用会拦截该工具调用,将其路由到相应的 MCP 服务器,执行该工具,并将结果作为对话流程的一部分返回给语言模型。这使得语言模型能够访问实时数据并在外部世界中执行操作。
ini
# Pseudo-code for AI application tool execution
async def handle_tool_call(conversation, tool_name, arguments):
session = app.find_mcp_session_for_tool(tool_name)
result = await session.call_tool(tool_name, arguments)
conversation.add_tool_result(result.content)4
实时更新(通知)
MCP 支持实时通知,使服务器能够在客户端无需明确请求的情况下通知客户端变更。这展示了通知系统,这是保持 MCP 连接同步和响应的关键特性。
了解工具列表变更通知
当服务器的可用工具发生变化时------例如,当有新功能可用、现有工具被修改或工具暂时不可用时------服务器可以主动通知已连接的客户端:
要求
json
{
"jsonrpc": "2.0",
"method": "notifications/tools/list_changed"
}MCP通知的主要特点
- 无需响应 :请注意,通知中没有任何
id字段。这遵循 JSON-RPC 2.0 通知语义,即无需发送或接收响应。 - 基于能力 :此通知仅由在初始化期间在其工具能力中声明的服务器发送
"listChanged": true(如步骤 1 所示)。 - 事件驱动:服务器根据内部状态变化决定何时发送通知,使 MCP 连接具有动态性和响应性。
客户对通知的回应
收到此通知后,客户通常会请求更新工具列表。这样就形成了一个更新周期,使客户能够及时了解可用工具的最新信息:
要求
json
{
"jsonrpc": "2.0",
"id": 4,
"method": "tools/list"
}为什么通知很重要
该通知系统至关重要,原因有以下几点:
- 动态环境:工具可能会根据服务器状态、外部依赖项或用户权限而随时启用或禁用。
- 效率:客户端无需轮询更改;更新发生时会收到通知。
- 一致性:确保客户始终获得有关可用服务器功能的准确信息
- 实时协作:支持能够适应不断变化的环境的响应式人工智能应用
这种通知模式不仅限于工具,还扩展到其他 MCP 原语,从而实现了客户端和服务器之间的全面实时同步。
它在人工智能应用中的工作原理
当人工智能应用收到工具变更通知时,它会立即刷新工具注册表并更新语言学习模型(LLM)的可用功能。这确保了正在进行的对话始终可以使用最新的工具集,并且语言学习模型能够动态适应新功能的出现。
了解 MCP 服务器
复制页面
MCP 服务器是通过标准化协议接口向 AI 应用程序公开特定功能的程序。常见的例子包括用于文档访问的文件系统服务器、用于数据查询的数据库服务器、用于代码管理的 GitHub 服务器、用于团队沟通的 Slack 服务器以及用于日程安排的日历服务器。
核心服务器功能
服务器通过三个基本组成部分提供功能:
| 特征 | 解释 | 示例 | 谁控制它 |
|---|---|---|---|
| 工具 | LLM 可以主动调用这些函数,并根据用户请求决定何时使用这些函数。工具可以写入数据库、调用外部 API、修改文件或触发其他逻辑。 | 搜索航班 发送消息 创建日历事件 | 模型 |
| 资源 | 被动数据源,提供对上下文信息的只读访问,例如文件内容、数据库模式或 API 文档。 | 检索文档 访问知识库 查看日历 | 应用 |
| 提示 | 预先构建的指令模板,告诉模型如何使用特定的工具和资源。 | 计划假期 总结会议 内容 撰写电子邮件 | 用户 |
我们将使用一个假设的场景来演示这些功能各自的作用,并展示它们如何协同工作。
工具
工具使人工智能模型能够执行操作。每个工具都定义了一个特定的操作,并具有类型化的输入和输出。模型根据上下文请求执行工具。
工具的工作原理
工具是定义在模式中的接口,LLM(生命周期模型)可以调用这些接口。MCP 使用 JSON Schema 进行验证。每个工具都执行单一操作,并具有明确定义的输入和输出。工具可能需要在执行前获得用户许可,这有助于确保用户对模型执行的操作保持控制。协议操作:
| 方法 | 目的 | 返回 |
|---|---|---|
tools/list |
探索可用工具 | 包含模式的工具定义数组 |
tools/call |
执行特定工具 | 工具执行结果 |
工具定义示例:
css
{
name: "searchFlights",
description: "Search for available flights",
inputSchema: {
type: "object",
properties: {
origin: { type: "string", description: "Departure city" },
destination: { type: "string", description: "Arrival city" },
date: { type: "string", format: "date", description: "Travel date" }
},
required: ["origin", "destination", "date"]
}
}示例:旅行预订
工具使人工智能应用程序能够代表用户执行操作。在旅行规划场景中,人工智能应用程序可能会使用多种工具来帮助预订假期:航班搜索
less
searchFlights(origin: "NYC", destination: "Barcelona", date: "2024-06-15")查询多家航空公司并返回结构化的航班选项。日历阻塞
less
createCalendarEvent(title: "Barcelona Trip", startDate: "2024-06-15", endDate: "2024-06-22")在用户的日历中标记旅行日期。电子邮件通知
less
sendEmail(to: "team@work.com", subject: "Out of Office", body: "...")向同事发送自动外出自动回复消息。
用户交互模型
工具由模型控制,这意味着人工智能模型可以自动发现并调用它们。然而,MCP 通过多种机制强调人工监督。为了确保信任和安全,应用程序可以通过各种机制实现用户控制,例如:
- 在用户界面中显示可用工具,使用户能够定义在特定交互中是否应显示某个工具。
- 针对单个工具执行的审批对话框
- 用于预先批准某些安全操作的权限设置。
- 活动日志显示所有工具执行及其结果
资源
资源提供结构化的信息访问,人工智能应用程序可以检索这些信息并将其作为上下文提供给模型。
资源运作方式
资源可以从文件、API、数据库或人工智能理解上下文所需的任何其他来源获取数据。应用程序可以直接访问这些信息,并决定如何使用它们------无论是选择相关部分、使用嵌入进行搜索,还是将所有信息传递给模型。每个资源都有一个唯一的 URI(例如,file:///path/to/document.md),并声明其 MIME 类型以便进行适当的内容处理。资源支持两种发现模式:
-
直接资源 - 指向特定数据的固定 URI。例如:
calendar://events/2024- 返回 2024 年的日历可用性 -
资源模板------带有参数的动态 URI,可实现灵活的查询。示例:
travel://activities/{city}/{category}- 按城市和类别返回活动travel://activities/barcelona/museums- 返回巴塞罗那所有博物馆
资源模板包含标题、描述和预期 MIME 类型等元数据,使其可被发现且具有自文档性。协议操作:
| 方法 | 目的 | 返回 |
|---|---|---|
resources/list |
列出可用的直接资源 | 资源描述符数组 |
resources/templates/list |
发现资源模板 | 资源模板定义数组 |
resources/read |
获取资源内容 | 包含元数据的资源数据 |
resources/subscribe |
监控资源变化 | 订阅确认 |
示例:获取旅行计划背景信息
继续以旅行规划为例,资源为人工智能应用程序提供相关信息的访问权限:
- 日历数据 (
calendar://events/2024)- 检查用户可用性 - 旅行证件 (
file:///Documents/Travel/passport.pdf)- 获取重要文件 - 以往行程 (
trips://history/barcelona-2023) - 参考过去的旅行和偏好
AI 应用会检索这些资源并决定如何处理它们,无论是使用嵌入或关键词搜索选择数据子集,还是将原始数据直接传递给模型。在这种情况下,它向模型提供日历数据、天气信息和旅行偏好,使模型能够检查可用性、查找天气模式并参考过去的旅行偏好。资源模板示例:
json
{
"uriTemplate": "weather://forecast/{city}/{date}",
"name": "weather-forecast",
"title": "Weather Forecast",
"description": "Get weather forecast for any city and date",
"mimeType": "application/json"
}
{
"uriTemplate": "travel://flights/{origin}/{destination}",
"name": "flight-search",
"title": "Flight Search",
"description": "Search available flights between cities",
"mimeType": "application/json"
}这些模板支持灵活的查询方式。例如,用户可以查询任意城市/日期组合的天气预报。对于航班查询,用户可以搜索任意两个机场之间的航线。当用户输入"NYC"作为机场,origin并尝试输入"Bar"作为destination机场时,系统可以建议"巴塞罗那 (BCN)"或"巴巴多斯 (BGI)"。
参数补全
动态资源支持参数自动补全。例如:
- 输入"Par"
weather://forecast/{city}可能会建议"巴黎"或"帕克城"。 - 输入"JFK"
flights://search/{airport}可能会建议"JFK - 约翰·F·肯尼迪国际机场"
该系统无需了解确切的格式即可帮助发现有效值。
用户交互模型
资源由应用程序驱动,因此在检索、处理和呈现可用上下文方面具有灵活性。常见的交互模式包括:
- 树状图或列表视图,用于在类似文件夹的结构中浏览资源。
- 用于查找特定资源的搜索和筛选界面
- 基于启发式或人工智能选择的自动上下文包含或智能建议
- 手动或批量选择界面,用于选择单个或多个资源
应用程序可以自由选择任何符合自身需求的界面模式来实现资源发现功能。该协议并未强制规定特定的用户界面模式,因此支持带有预览功能的资源选择器、基于当前对话上下文的智能建议、批量选择多个资源,以及与现有文件浏览器和数据资源管理器的集成。
提示
提示符提供可重用的模板。它们允许 MCP 服务器作者为域提供参数化提示符,或展示如何最佳地使用 MCP 服务器。
提示是如何运作的
提示是结构化的模板,用于定义预期输入和交互模式。它们由用户控制,需要显式调用而非自动触发。提示可以感知上下文,引用可用资源和工具来创建全面的工作流程。与资源类似,提示支持参数补全,帮助用户发现有效的参数值。协议操作:
| 方法 | 目的 | 返回 |
|---|---|---|
prompts/list |
发现可用提示 | 提示描述符数组 |
prompts/get |
获取提示详情 | 包含参数的完整提示定义 |
例如:简化的工作流程
提示信息为常见任务提供结构化模板。在旅行计划方面: "计划一次假期"提示:
json
{
"name": "plan-vacation",
"title": "Plan a vacation",
"description": "Guide through vacation planning process",
"arguments": [
{ "name": "destination", "type": "string", "required": true },
{ "name": "duration", "type": "number", "description": "days" },
{ "name": "budget", "type": "number", "required": false },
{ "name": "interests", "type": "array", "items": { "type": "string" } }
]
}提示系统并非接受非结构化的自然语言输入,而是支持:
- 选择"计划假期"模板
- 结构化输入:巴塞罗那,7 天,3000 美元,"海滩"、"建筑"、"美食"
- 基于模板的一致工作流程执行
用户交互模型
提示由用户控制,需要显式调用。该协议赋予实现者自由,使其能够设计出与应用程序环境相协调的自然界面。其关键原则包括:
- 轻松发现可用提示
- 对每个提示的功能进行清晰描述
- 自然参数输入及验证
- 透明显示提示的底层模板
应用程序通常通过各种用户界面模式显示提示信息,例如:
- 斜杠命令(输入"/"可查看可用提示,例如 /plan-vacation)
- 用于可搜索访问的命令面板
- 常用提示的专用用户界面按钮
- 上下文菜单提供相关提示
将服务器整合在一起
MCP 的真正威力体现在多个服务器协同工作,通过统一的接口结合它们各自的专业功能。
示例:多服务器旅行计划
设想一个个性化的AI旅行规划应用程序,它有三个相互连接的服务器:
- 旅行服务专员- 负责处理航班、酒店和行程安排
- 天气服务器- 提供气候数据和预报
- 日历/邮件服务器- 管理日程安排和通信
完整流程
-
用户调用带有参数的提示符:
json{ "prompt": "plan-vacation", "arguments": { "destination": "Barcelona", "departure_date": "2024-06-15", "return_date": "2024-06-22", "budget": 3000, "travelers": 2 } } -
用户选择要包含的资源:
calendar://my-calendar/June-2024(来自日历服务器)travel://preferences/europe(来自旅行服务器)travel://past-trips/Spain-2023(来自旅行服务器)
-
AI 使用工具处理请求: 人工智能首先读取所有选定的资源以收集上下文信息------从日历中识别可用日期,从旅行偏好中学习首选航空公司和酒店类型,并从过去的旅行中发现以前喜欢的地点。基于此背景,人工智能随后执行一系列工具:
searchFlights()- 查询纽约飞往巴塞罗那的航班信息checkWeather()- 获取旅行日期的气候预报
然后,人工智能会利用这些信息创建预订并执行后续步骤,并在必要时请求用户批准:
bookHotel()- 查找符合指定预算的酒店createCalendarEvent()- 将行程添加到用户的日历中sendEmail()- 发送包含行程详情的确认信息
结果: 用户通过多个 MCP 服务器,根据自己的行程安排搜索并预订了巴塞罗那之旅。"计划假期"提示引导人工智能整合不同服务器上的资源(日历可用性和旅行历史记录)和工具(搜索航班、预订酒店、更新日历),收集相关信息并执行预订。原本可能需要数小时才能完成的任务,借助 MCP 在几分钟内就完成了。
了解 MCP 客户
复制页面
MCP 客户端由宿主应用程序实例化,用于与特定的 MCP 服务器通信。宿主应用程序(例如 Claude.ai 或 IDE)负责管理整体用户体验并协调多个客户端。每个客户端处理与一个服务器的直接通信。理解二者的区别很重要:主机 是用户与之交互的应用程序,而客户端是实现服务器连接的协议级组件。
核心客户端功能
除了利用服务器提供的上下文信息外,客户端还可以向服务器提供多种功能。这些客户端功能使服务器开发者能够构建更丰富的交互体验。
| 特征 | 解释 | 例子 |
|---|---|---|
| 诱导 | 信息获取使服务器能够在交互过程中向用户请求特定信息,为服务器按需收集信息提供了一种结构化的方法。 | 服务器在预订旅行时可能会询问用户对飞机座位、房间类型或联系电话的偏好,以完成预订。 |
| 根 | 根目录允许客户端指定服务器应该关注哪些目录,并通过协调机制传达预期范围。 | 旅行预订服务器可以被授予访问特定目录的权限,从而可以从中读取用户的日历。 |
| 采样 | 采样允许服务器通过客户端请求 LLM 完成,从而实现代理工作流。这种方法使客户端完全掌控用户权限和安全措施。 | 旅行预订服务器可以向 LLM 发送航班列表,并请求 LLM 为用户选择最佳航班。 |
诱导
获取功能使服务器能够在交互过程中向用户请求特定信息,从而创建更动态、响应更迅速的工作流程。
概述
获取方式为服务器提供了一种结构化的方法,使其能够按需收集必要信息。服务器无需预先获取所有信息,也无需在数据缺失时失败,而是可以暂停操作,向用户请求特定输入。这创造了更灵活的交互方式,服务器能够适应用户需求,而不是遵循僵化的模式。信息获取流程:
ServerClientUserServerClientUserServer initiates elicitationHuman interactionComplete requestContinue processing with new informationelicitation/createPresent elicitation UIProvide requested informationReturn user response
该流程支持动态信息收集。服务器可以根据需要请求特定数据,用户通过相应的用户界面提供信息,服务器则根据新获取的上下文继续处理数据。启发式组件示例:
css
{
method: "elicitation/requestInput",
params: {
message: "Please confirm your Barcelona vacation booking details:",
schema: {
type: "object",
properties: {
confirmBooking: {
type: "boolean",
description: "Confirm the booking (Flights + Hotel = $3,000)"
},
seatPreference: {
type: "string",
enum: ["window", "aisle", "no preference"],
description: "Preferred seat type for flights"
},
roomType: {
type: "string",
enum: ["sea view", "city view", "garden view"],
description: "Preferred room type at hotel"
},
travelInsurance: {
type: "boolean",
default: false,
description: "Add travel insurance ($150)"
}
},
required: ["confirmBooking"]
}
}
}示例:假期预订审批
旅游预订服务器通过最终预订确认流程展现了信息获取的强大功能。当用户选定理想的巴塞罗那度假套餐后,服务器需要收集最终确认信息以及任何缺失的详细信息才能继续进行。服务器通过结构化请求获取预订确认信息,其中包括行程摘要(巴塞罗那航班 6 月 15 日至 22 日,海滨酒店,总计 3,000 美元)以及任何其他偏好字段,例如座位选择、房间类型或旅行保险选项。随着预订流程的推进,服务器会收集完成预订所需的联系信息。例如,可能会询问旅客的详细航班信息、酒店的特殊要求或紧急联系人信息。
用户交互模型
启发式互动的设计应清晰、符合语境,并尊重用户自主权:请求呈现 :客户端以清晰的上下文信息展示请求,包括请求服务器、信息用途以及信息使用方式。请求消息解释了请求目的,而模式则提供了结构和验证。响应选项 :用户可以通过相应的用户界面控件(文本框、下拉菜单、复选框)提供所需信息,也可以选择不提供信息并附上解释,或者取消整个操作。客户端会在将响应返回给服务器之前,根据提供的架构对其进行验证。隐私考量:请求过程中绝不会索取密码或 API 密钥。客户端会对可疑请求发出警告,并允许用户在发送数据前进行审核。
根
根目录定义了服务器操作的文件系统边界,允许客户端指定服务器应该关注哪些目录。
概述
根目录是客户端向服务器传达文件系统访问边界的一种机制。它们由文件 URI 组成,指示服务器可以操作的目录,帮助服务器了解可用文件和文件夹的范围。虽然根目录传达了预期的边界,但它们并不强制执行安全限制。实际的安全措施必须在操作系统层面通过文件权限和/或沙箱机制来实施。根系结构:
json
{
"uri": "file:///Users/agent/travel-planning",
"name": "Travel Planning Workspace"
}根目录是文件系统路径,始终使用file://URI 方案。它们帮助服务器理解项目边界、工作区组织结构和可访问目录。根目录列表会随着用户使用不同的项目或文件夹而动态更新,服务器会在roots/list_changed边界发生变化时收到通知。
示例:旅行计划工作区
旅行社代理需要处理多个客户的行程,因此可以利用根目录来组织文件系统访问。可以考虑创建一个工作区,其中包含用于旅行计划各个方面的不同目录。客户端向旅行规划服务器提供文件系统根目录:
file:///Users/agent/travel-planning- 包含所有旅行文件的主工作区file:///Users/agent/travel-templates- 可重复使用的行程模板和资源file:///Users/agent/client-documents- 客户护照和旅行证件
当代理商创建巴塞罗那行程时,运行良好的服务器会遵守这些边界------访问模板、保存新行程以及引用指定根目录下的客户文档。服务器通常通过使用根目录的相对路径或利用遵循根目录边界的文件搜索工具来访问根目录中的文件。如果代理打开一个类似这样的归档文件夹file:///Users/agent/archive/2023-trips,客户端会通过更新根列表roots/list_changed。要完整实现尊重根目录的服务器,请参阅官方服务器存储库中的文件系统服务器。
设计理念
根目录是客户端和服务器之间的协调机制,而非安全边界。规范要求服务器"应该尊重根目录边界",而不是"必须强制执行"它们,因为服务器运行的代码是客户端无法控制的。根服务器在服务器可信或经过审核、用户了解其建议性质,且目标是预防事故而非阻止恶意行为时,效果最佳。它们擅长上下文范围界定(告知服务器关注哪些方面)、事故预防(帮助行为良好的服务器保持在规范范围内)以及工作流程组织(例如自动管理项目边界)。
用户交互模型
根目录通常由宿主应用程序根据用户操作自动管理,但有些应用程序可能提供手动根目录管理选项:自动根目录检测 :当用户打开文件夹时,客户端会自动将其暴露为根目录。打开旅行工作区时,客户端会将该目录暴露为根目录,帮助服务器了解哪些行程和文档属于当前工作范围。手动根目录配置 :高级用户可以通过配置指定根目录。例如,添加/travel-templates用于存放可重用资源的目录,同时排除包含财务记录的目录。
采样
采样允许服务器通过客户端请求语言模型补全,从而实现代理行为,同时保持安全性和用户控制。
概述
采样技术使服务器能够在不直接集成或付费购买 AI 模型的情况下执行依赖于 AI 的任务。服务器可以请求已拥有 AI 模型访问权限的客户端代表其处理这些任务。这种方法使客户端完全掌控用户权限和安全措施。由于采样请求发生在其他操作(例如数据分析工具)的上下文中,并作为独立的模型调用进行处理,因此它们能够清晰地划分不同上下文,从而更有效地利用上下文窗口。采样流程:
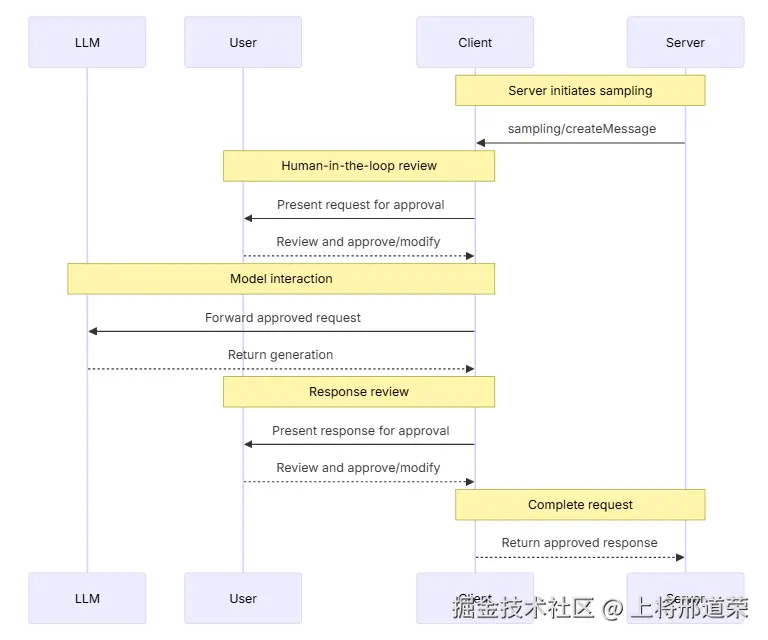 该流程通过多重人为干预检查点确保安全性。用户可以在请求返回服务器之前,查看并修改初始请求和生成的响应。请求参数示例:
该流程通过多重人为干预检查点确保安全性。用户可以在请求返回服务器之前,查看并修改初始请求和生成的响应。请求参数示例:
swift
{
messages: [
{
role: "user",
content: "Analyze these flight options and recommend the best choice:\n" +
"[47 flights with prices, times, airlines, and layovers]\n" +
"User preferences: morning departure, max 1 layover"
}
],
modelPreferences: {
hints: [{
name: "claude-sonnet-4-20250514" // Suggested model
}],
costPriority: 0.3, // Less concerned about API cost
speedPriority: 0.2, // Can wait for thorough analysis
intelligencePriority: 0.9 // Need complex trade-off evaluation
},
systemPrompt: "You are a travel expert helping users find the best flights based on their preferences",
maxTokens: 1500
}例如:飞行分析工具
假设有一个旅行预订服务器,它有一个名为"航班分析工具"的功能,该工具findBestFlight利用抽样方法分析可用航班并推荐最佳选择。当用户询问"帮我预订下个月飞往巴塞罗那的最佳航班"时,该工具需要人工智能的辅助来评估复杂的权衡取舍。该工具查询航空公司 API 并收集了 47 个航班选项。然后,它请求 AI 协助分析这些选项:"分析这些航班选项并推荐最佳选择:47 个航班,包含价格、时间、航空公司和中转次数 用户偏好:上午出发,最多 1 次中转。"客户发起抽样请求,人工智能便可评估各种方案的优缺点------例如更便宜的红眼航班与便捷的早班航班。该工具会根据分析结果给出前三项推荐。
用户交互模型
虽然并非强制要求,但抽样旨在实现人机协同控制。用户可以通过多种机制进行监督:审批控制 :采样请求可能需要用户明确同意。客户端可以说明服务器想要分析的内容及其原因。用户可以批准、拒绝或修改请求。透明功能 :客户端可以显示确切的提示、模型选择和令牌限制,允许用户在返回服务器之前查看 AI 响应。配置选项 :用户可以设置模型偏好,配置可信操作的自动审批,或要求所有操作均需审批。客户端可以提供选项来编辑敏感信息。安全注意事项:客户端和服务器在采样过程中都必须妥善处理敏感数据。客户端应实施速率限制并验证所有消息内容。人机交互设计确保服务器发起的 AI 交互不会在未经用户明确同意的情况下损害安全性或访问敏感数据。