在数据集成场景中,作业中断是常见的风险点------系统故障、网络波动、资源耗尽或人为暂停等情况,都可能导致正在执行的数据同步任务中断。若缺乏有效的容错机制,任务中断后需从头重新执行,不仅会造成大量的计算资源浪费,还可能引发数据重复处理、数据不一致等问题,尤其对于TB级甚至PB级的大规模数据处理场景,这种代价更为显著。
SeaTunnel 作为开源的分布式数据集成平台,其内置的断点续传(Checkpoint & Resume)机制为解决这一痛点提供了可靠方案。该机制通过定期持久化作业状态、故障后精准恢复执行位置,确保作业能够从中断处无缝续跑,大幅提升数据处理效率、降低资源损耗。本文将从架构设计、核心组件、实现流程、实操配置到最佳实践,全面拆解 SeaTunnel 断点续传机制的工作原理。
一、整体架构概览:基于分布式检查点的容错体系
SeaTunnel 断点续传机制的核心基石是分布式检查点(Checkpoint)技术 ,其整体架构围绕"状态持久化-状态恢复"的核心逻辑展开,包含四个核心组成部分,各部分协同实现断点续传的全流程: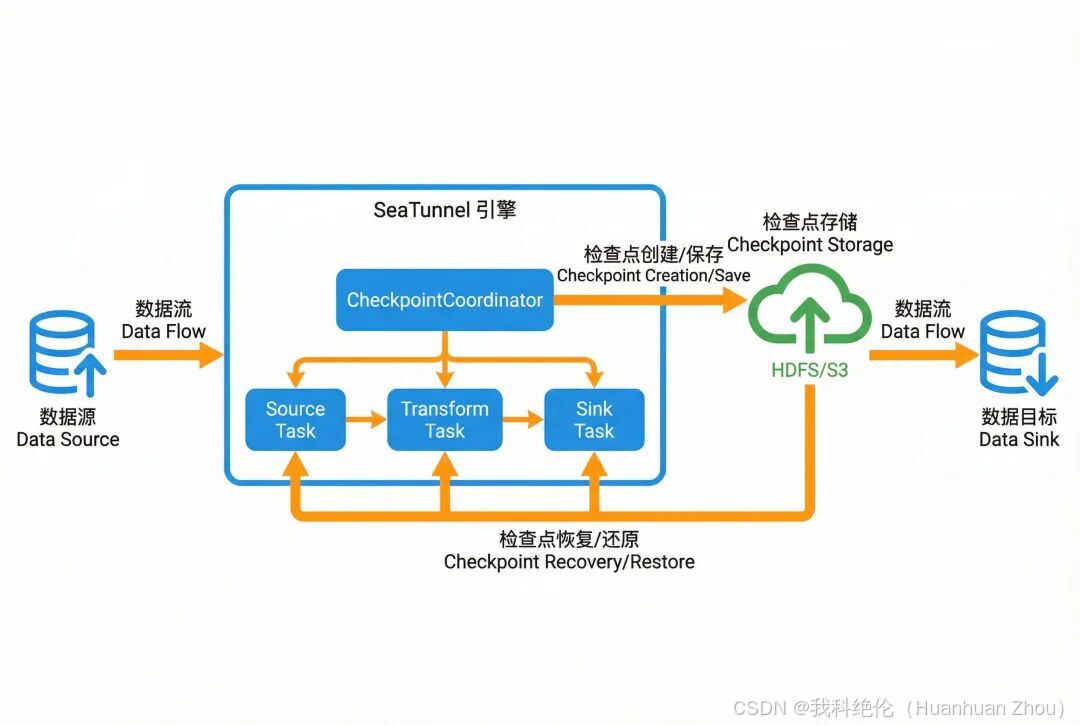
- 数据源(Source):提供待处理的原始数据,如 Kafka、MySQL、HDFS 等,需支持记录读取位置(如 Kafka Offset、文件行号、数据库 Binlog 位点),为恢复时精准定位未处理数据提供基础。
- SeaTunnel 引擎:核心协调层,包含 JobMaster、CheckpointManager、CheckpointCoordinator 等关键组件,负责触发检查点创建、协调任务状态保存与恢复、监控作业运行状态。
- 检查点存储(Checkpoint Storage):用于持久化存储检查点数据的外部存储系统,支持多种分布式/集中式存储后端,确保状态数据的可靠性与可访问性。
- 数据目标(Sink):接收处理后数据的终端,如数据仓库、湖仓、下游数据库等,需配合引擎保证恢复后数据的一致性(如支持幂等写入、事务提交)。
架构核心逻辑:作业运行过程中,SeaTunnel 引擎会按照预设间隔创建检查点,将作业的关键状态(如执行进度、数据读取位置、算子中间结果)持久化到检查点存储;当作业因故障或暂停中断后,重启时引擎会从检查点存储中读取最新的完整检查点数据,恢复作业状态与执行位置,仅处理未完成的数据分片,实现"断点续传"。
二、前提条件与配置:启用断点续传的基础准备
要使用 SeaTunnel 的断点续传功能,需先完成两项核心配置:启用 Checkpoint 功能、配置检查点存储。不同类型的作业(实时流处理、批处理)在启用方式上存在差异,具体配置如下:
2.1 启用 Checkpoint 功能
SeaTunnel 针对流处理和批处理作业的 Checkpoint 启用策略做了差异化设计,适配不同作业的生命周期特性:
- 实时流处理作业:流作业通常长期运行,对容错性要求高,因此 Checkpoint 默认启用,无需额外配置。引擎会按照默认间隔(可通过配置调整)自动创建检查点。
- 批处理作业 :批作业生命周期较短,默认不启用 Checkpoint,若需故障恢复能力,需在作业配置的
env段落中显式指定checkpoint.interval参数(单位:毫秒),定义检查点创建间隔:
yaml
env {
# 每 10 秒创建一次检查点,根据作业数据量调整
checkpoint.interval = 10000
}2.2 配置检查点存储
检查点数据需存储在外部可靠的存储系统中,需在 SeaTunnel 全局配置文件 seatunnel.yaml 中指定存储类型、存储路径及保留策略。核心配置项如下:
yaml
seatunnel:
engine:
checkpoint:
storage:
type: hdfs # 存储类型,支持 hdfs、s3、oss、cos、localfile
max-retained: 3 # 保留最近 3 个检查点,自动清理旧检查点
plugin-config: # 存储系统专属配置
namespace: /seatunnel/checkpoint # 检查点存储根路径
storage.type: hdfs
fs.defaultFS: hdfs://namenode:8020 # HDFS namenode 地址2.2.1 支持的存储后端及选型建议
SeaTunnel 支持多种存储后端,适配不同部署环境,选型需结合生产环境的存储架构与可靠性要求:
- HDFS:适合 Hadoop 生态环境,分布式架构支持高并发读写,可靠性高,推荐生产环境大规模作业使用。
- S3/OSS/COS:云厂商对象存储,无需维护底层存储集群,弹性扩展,适合云原生部署场景。
- LocalFile(本地文件系统):仅适用于单机测试场景,不支持分布式部署和高可靠性要求,生产环境禁止使用。
三、检查点创建机制:状态持久化的核心流程
检查点是断点续传的基础,其本质是作业状态的"快照",包含作业恢复所需的全部关键信息。SeaTunnel 采用"协调-分发-持久化-确认"的分布式协调流程创建检查点,确保状态数据的完整性与一致性。
3.1 检查点包含的核心信息
每个检查点本质是一组结构化数据,涵盖作业运行的全量关键状态,确保恢复时能"复刻"中断前的运行状态:
- 作业元数据:作业 ID、全局配置、任务拓扑结构(Source→Transform→Sink 的任务依赖关系)。
- 任务状态:每个任务节点的执行进度、已完成处理的数据分片(Split)列表、未处理分片列表。
- 数据偏移量:Source 端的具体读取位置,如 Kafka 主题的分区 Offset、文件的读取行号、数据库 Binlog 的位点。
- 算子中间状态:Transform 算子的中间计算结果,如聚合算子(Sum、Count)的累计值、窗口函数的未触发结果。
3.2 检查点创建的分布式协调流程
检查点的创建由 CheckpointCoordinator 统一调度,是一个跨任务节点的协同过程,具体步骤如下:
- 触发检查点 :CheckpointCoordinator 按照
checkpoint.interval配置的间隔,定期向作业拓扑中的所有任务节点发送"检查点屏障(Checkpoint Barrier)"------这是一个标记信号,用于分隔"已处理数据"和"未处理数据"。 - 任务状态保存:各任务节点收到屏障后,暂停处理新数据(确保状态一致性),将当前的任务状态、数据偏移量、中间结果等信息序列化。
- 状态数据上传:任务节点将序列化后的状态数据上传到配置的检查点存储系统(如 HDFS/S3),并向 CheckpointCoordinator 反馈"状态保存完成"。
- 检查点确认:当 CheckpointCoordinator 收到所有任务节点的"保存完成"反馈后,标记该检查点为"已完成(Completed)",并记录检查点的元数据(如创建时间、存储路径);若有任务节点保存失败,该检查点标记为"无效",等待下一轮间隔重新触发。
四、核心组件详解:断点续传的"协同中枢"
SeaTunnel 断点续传机制的实现依赖多个核心组件的协同工作,各组件分工明确,从作业启动、检查点管理到故障恢复,形成完整的容错闭环。关键组件包括 JobMaster、CheckpointManager、CheckpointCoordinator。
4.1 JobMaster:作业生命周期的"总控制器"
JobMaster 是单个作业的主控节点,负责作业的启动、运行监控、故障处理和生命周期管理,在断点续传中核心承担"恢复需求检测"和"恢复流程启动"的职责:
- 恢复需求检测 :作业启动时,JobMaster 会先检查作业配置参数,判断是否需要从检查点恢复。常见场景包括:用户通过
-r参数手动重启失败作业、通过-s参数恢复暂停作业、Master 节点故障后自动接管作业。 - 启动恢复流程:若检测到恢复需求,JobMaster 会初始化 CheckpointManager,触发状态加载流程。核心代码逻辑如下:
java
// 检查是否需要从保存点(检查点)启动
if (jobImmutableInformation.isStartWithSavePoint()) {
// 初始化 CheckpointManager,触发状态恢复
initCheckpointManager(jobImmutableInformation);
}4.2 CheckpointManager:检查点的"生命周期管家"
CheckpointManager 专门负责检查点的全生命周期管理,核心功能包括检查点存储初始化、历史检查点加载、旧检查点清理,是状态数据的"管理者":
- 检查点存储初始化 :根据
seatunnel.yaml的配置,连接到指定的存储系统(如 HDFS),创建检查点存储目录(如/seat<job-id>)。 - 历史检查点加载:作业恢复时,CheckpointManager 会扫描检查点存储目录,筛选出所有"已完成"的检查点,获取最新的有效检查点(按创建时间排序)。核心代码逻辑如下:
java
// 从存储系统加载当前作业的最新完整检查点
CompletedCheckpoint latestCheckpoint =
checkpointStorage.getLatestCompletedCheckpoint(jobId);- 检查点清理 :根据
max-retained参数的配置,自动清理超过保留数量的旧检查点,避免占用过多存储空间。
4.3 CheckpointCoordinator:检查点的"协同调度员"
CheckpointCoordinator 是断点续传机制的核心协调组件,负责触发检查点创建、协调状态恢复、监控任务故障,是组件间交互的"中枢":
- 触发检查点创建:按照配置的时间间隔,定期向所有任务节点发送检查点屏障,启动检查点创建流程。
- 状态恢复协调:作业恢复时,将 CheckpointManager 加载的最新检查点数据,按任务节点分发,确保每个任务拿到自己的状态数据。
- 故障检测与恢复:实时监控各任务节点的运行状态,若检测到任务故障,触发检查点恢复流程,重启任务并恢复状态。
五、作业恢复流程详解:从断点到续跑的全步骤
当作业因故障或暂停中断后,SeaTunnel 会通过一套标准化的恢复流程,确保状态精准恢复、作业无缝续跑。整个流程由 JobMaster 主导、多组件协同完成,共分为 7 个核心步骤:
步骤 1:检测恢复需求
JobMaster 初始化时,解析作业启动参数(如-r、-s)和作业元数据,判断是否需要从检查点恢复。若为首次启动的作业,则直接初始化任务拓扑;若为恢复启动,则进入恢复流程。
步骤 2:CheckpointManager 初始化与检查点加载
JobMaster 初始化 CheckpointManager,CheckpointManager 连接到检查点存储系统,扫描当前作业的检查点目录,筛选出所有"已完成"的检查点,验证每个检查点的完整性(避免状态数据损坏),最终加载最新的有效检查点。
步骤 3:检查点状态解析与准备
CheckpointCoordinator 接收 CheckpointManager 加载的检查点数据,解析出作业的全局状态、各任务的执行进度、数据分片分配情况、Source 端读取位置等信息,将状态标记为"待恢复",为后续任务状态分发做准备。
步骤 4:任务节点报告恢复就绪状态
JobMaster 启动所有任务节点(Source/Transform/Sink),各任务节点初始化完成后,向 CheckpointCoordinator 发送"WAITING_RESTORE"状态,告知协调器"已准备好接收恢复状态"。
步骤 5:分发恢复状态数据
CheckpointCoordinator 调用 restoreTaskState 方法,根据任务 ID 将对应的状态数据分发给各个任务节点。每个任务节点会收到三类核心数据:
- 该任务负责处理的数据分片列表(未完成的分片);
- 每个分片的已处理进度(避免重复处理);
- 算子的中间状态(如聚合结果、窗口数据)。
步骤 6:触发任务状态恢复
CheckpointCoordinator 通过 NotifyTaskRestoreOperation 向所有任务节点发送"恢复开始"通知,任务节点收到通知后执行三项操作:
- 将接收的状态数据反序列化,加载到内存中;
- 重新初始化算子,恢复中间计算状态;
- 调整 Source 端的读取位置到检查点保存的偏移量(如 Kafka Offset 重置、文件读取指针移动)。
步骤 7:作业从断点继续执行
所有任务节点完成状态恢复后,向 CheckpointCoordinator 反馈"恢复完成",CheckpointCoordinator 通知 JobMaster 启动作业续跑。此时作业会从检查点记录的断点位置开始,仅处理未完成的数据分片,实现"无缝续传"。
六、关键恢复场景与操作指南
SeaTunnel 断点续传机制适配多种故障/暂停场景,包括手动恢复、Master 节点故障自动恢复等,不同场景的操作方式和核心逻辑略有差异。
6.1 手动恢复作业(命令行方式)
对于运行失败或手动暂停的作业,可通过 SeaTunnel 提供的命令行工具,指定作业 ID 从检查点恢复。核心命令如下:
bash
# 从检查点恢复作业,-r 指定作业 ID,-c 指定作业配置文件
./bin/seatunnel.sh -r <job-id> -c $SEATUNNEL_HOME/config/v2.batch.config.template适用场景:
- 作业因任务节点故障、网络中断等原因运行失败;
- 通过
-s参数手动暂停的作业。
⚠️ 注意:通过 -can 参数取消的作业,其所有检查点信息会被自动删除,无法通过 -r 参数恢复。
6.2 Master 节点故障自动恢复
SeaTunnel 支持高可用(HA)部署,当 Master 节点发生故障时,集群会自动选举新的 Master 节点,接管并恢复所有运行中的作业,整个过程对用户透明,无需人工干预。核心流程如下:
- 故障检测:CoordinatorService 监控 Master 节点状态,检测到故障后触发 Master 选举流程;
- 作业信息加载:新 Master 节点启动后,从元数据存储中读取所有处于"运行中"的作业信息;
- 检查点加载与恢复:为每个作业初始化 CheckpointManager,加载最新检查点;
- 重建 JobMaster 与任务:为每个作业创建新的 JobMaster 实例,重启任务节点并恢复状态,触发作业续跑。
七、重要注意事项与最佳实践
要充分发挥 SeaTunnel 断点续传机制的作用,需结合作业类型、数据量、业务需求合理配置参数、选择存储方案,同时规避常见问题。
7.1 核心注意事项
- 批处理 vs 流处理的差异 :流处理作业默认启用 Checkpoint,适合长期运行的实时同步任务;批处理作业默认不启用,需显式配置
checkpoint.interval才支持恢复。 - 检查点保留策略 :
max-retained参数建议设置为 3-5 个------保留过多会占用大量存储空间,保留过少可能在连续故障时找不到有效检查点。 - 恢复粒度:SeaTunnel 以"数据分片(Split)"为最小恢复单位。作业暂停时,会等待当前正在处理的 Split 完成后再暂停;恢复时从下一个未处理的 Split 开始,确保数据不重复、不遗漏。
- 数据一致性保障:Sink 端需支持幂等写入或事务提交------若恢复后重复写入数据,需通过 Sink 端的机制(如主键去重、事务回滚)保证最终数据一致性。
7.2 最佳实践建议
- 合理设置 Checkpoint 间隔 :间隔过短会增加系统开销(频繁序列化、上传状态),间隔过长则故障时可能丢失较多进度。建议:
- 实时流作业:30 秒 - 5 分钟(数据量小、实时性要求高可设为 30 秒-1 分钟;数据量大、计算复杂可设为 2-5 分钟);
- 批处理作业:5-15 分钟(根据批处理数据量调整,确保两次检查点之间的处理量在可接受的重跑范围内)。
- 选择高可靠的存储系统:生产环境优先选择 HDFS 或云对象存储(S3/OSS/COS),避免使用本地文件系统;若使用云存储,需配置合理的访问权限和备份策略。
- 定期监控检查点状态:通过 SeaTunnel 的监控接口(如 Prometheus 指标)监控检查点的创建成功率、创建耗时、存储占用情况,若发现检查点创建失败(如存储连接异常、状态数据过大),需及时排查。
- 提前测试恢复流程:生产环境部署前,需模拟多种故障场景(如任务节点宕机、Master 故障、网络中断)测试恢复能力,验证恢复后数据的完整性和一致性。
- 手动清理历史检查点 :若存储容量紧张,可在作业正常完成后,手动清理该作业的所有检查点(SeaTunnel 仅自动清理超过
max-retained的旧检查点,已完成作业的检查点需手动清理)。
八、总结
SeaTunnel 的断点续传机制通过分布式检查点技术,构建了"状态持久化-状态恢复"的完整容错体系,从 JobMaster 的生命周期管理,到 CheckpointManager 的状态管控,再到 CheckpointCoordinator 的协同调度,各组件紧密配合,确保作业在故障、暂停等场景下能精准恢复、无缝续跑。