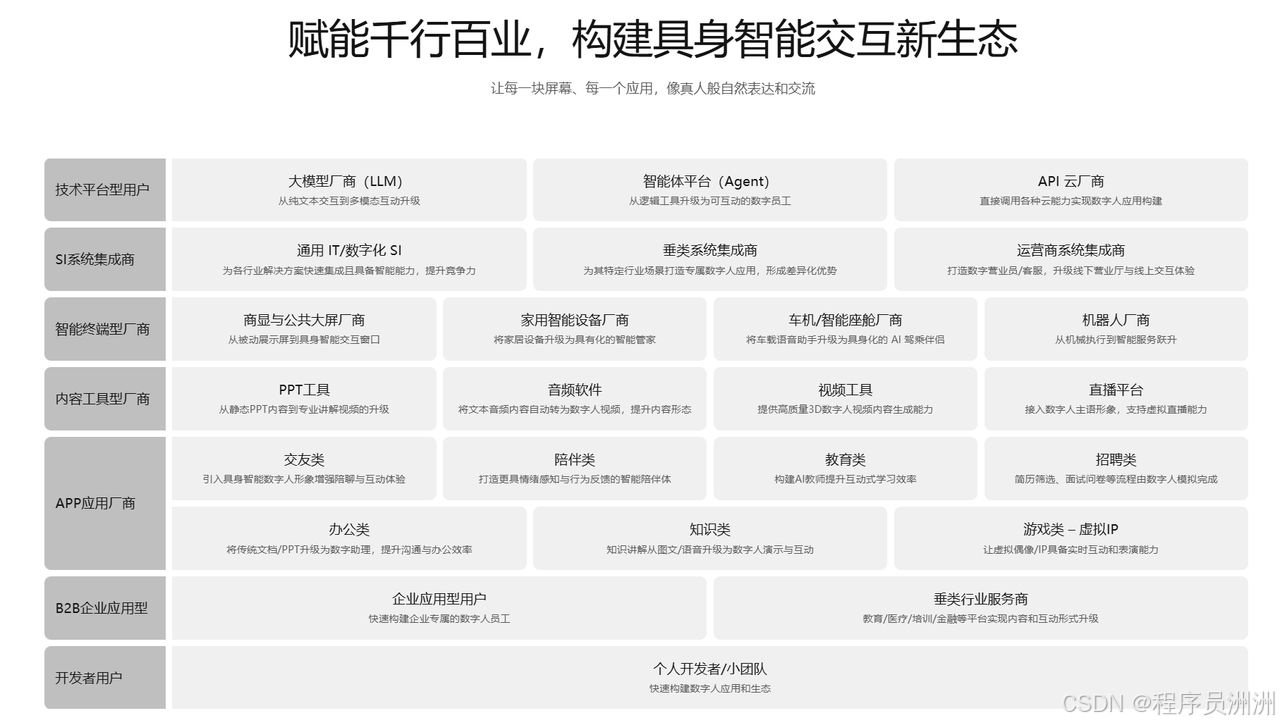
本文目录
- [一、行业破局:数字人从 "形似" 到 "神似" 的必然升级](#一、行业破局:数字人从 “形似” 到 “神似” 的必然升级)
- 二、魔珐星云:具身智能,从技术到应用的全维度领先
-
- [(1)具身驱动引擎:给数字人装上 "会思考的智能躯体"](#(1)具身驱动引擎:给数字人装上 “会思考的智能躯体”)
- [(2)魔珐星云的 6 大核心能力](#(2)魔珐星云的 6 大核心能力)
- [(3)打破 "不可能三角":技术突破支撑具身智能规模化落地](#(3)打破 “不可能三角”:技术突破支撑具身智能规模化落地)
- 三、平台实战:构建属于你自己的具身智能AI智能体
- 四、行业展望:具身智能数字人成新基建
- 五、体验指引:即刻解锁具身智能新体验
一、行业破局:数字人从 "形似" 到 "神似" 的必然升级
随着AGI技术的爆火,企业级数字人的价值正在从 "展示工具" 转向 "生产力核心"。据相关数据显示,2025年全球企业级数字人市场需求越来越大 ------ 从电商直播的虚拟主播,到企业培训的AI讲师,再到政务服务的数字客服,越来越多行业开始用数字人替代重复性人力,但其爆发背后,行业痛点却始终制约着体验与效率。
当前多数数字人仍停留在 "形似" 阶段:交互上,机械的动作、僵硬的表情与话术,让用户难以产生真实沟通感;成本端,传统方案依赖高算力GPU与专业团队,中小微企业难以负担;场景适配性更弱,多数数字人仅能适配单一终端或固定场景,跨平台、跨设备的灵活调用几乎是行业盲区。这些短板,让数字人始终难以真正融入企业的日常运营链路。
而具身智能的崛起,正在打破这一困局 ------ 魔珐星云以 "有身体 + 强智能" 的核心逻辑,为数字人装上了 "能听会动的智能躯体":不仅能通过文本驱动实时生成自然的语音、表情与肢体动作,更以低成本、跨终端的特性,让数字人真正从 "展厅展品" 落地为企业可随时调用的 "数字员工",由此打开了数字人从 "形似" 到 "神似" 的行业新赛道。
二、魔珐星云:具身智能,从技术到应用的全维度领先
(1)具身驱动引擎:给数字人装上 "会思考的智能躯体"
魔珐星云的核心技术底座,首先落地于具身驱动引擎------ 这是让数字人从 "静态形象" 变为 "可交互主体" 的关键。其核心逻辑是 "文本即指令":仅需一段文字输入,引擎就能同步完成语义与情绪解析,实时生成3D数字人的语音、表情、眼神、手势乃至连贯的身体动作,让数字人在任何屏幕、应用或终端上,都能像真人一样自然表达与互动。

这套引擎的实现了多模态协同,语音、表情、肢体动作并非独立拼接,而是基于文本情绪(如愉悦、严肃)实现同步适配,让数字人的表达更具真实感;同时以AI端侧渲染与解算技术实现低成本落地,无需依赖昂贵的 GPU算力,百元级芯片即可流畅运行,大幅降低企业部署门槛;更具备虚实兼容特性,既能驱动3D数字人完成线上交互,也能直接对接实体人形机器人,实现 "数字形象 - 物理实体" 的跨维度联动;还支持Web、App 等多端低延迟部署,同时 100% 兼容国产信创体系,覆盖政企、企业等不同场景的合规需求,让数字人的应用场景不再受限。
(2)魔珐星云的 6 大核心能力
- 高质量表现:呈现电影级 3D 视觉效果,数字人微表情丰富、口型同步精准,实现类真人的交互质感
- 低延时交互:支持全双工对话,用户可随时插话、打断,数字人即时响应,消除机械等待感
- 高并发承载:云端架构优化,可稳定支撑大规模用户同时在线,适配高流量场景
- 低成本部署:免显卡端渲染技术,无需昂贵算力服务器,大幅压缩运营成本
- 多终端覆盖:适配 iOS、Android、Web、Windows、Linux 全平台,可在 RK3566 嵌入式芯片等低配置硬件上 "无 GPU 运行"
- 信创生态适配:深度兼容国产化软硬件环境,满足政企关键领域的安全合规要求
(3)打破 "不可能三角":技术突破支撑具身智能规模化落地
在数字人开发领域,"高质量、低延时、低成本" 长期是难以兼顾的 "不可能三角":
- "不可能三角" 的行业困境:
- 追求高质量(如虚幻引擎渲染),需昂贵 GPU 算力,难在移动端运行
- 追求低成本、低延时,仅能得到动作僵硬、画质粗糙的 "纸片人"
而魔珐星云通过两大核心技术实现了这一突破:
- 魔珐星云的技术破局:
- 文生 3D 多模态动作大模型:让数字人理解语义,自动生成自然表情、动作,无需人工 K 帧即可实现高质量表现
- AI 端渲与解算技术:将渲染负载转移至终端,大幅降低硬件要求,让高质量数字人在普通设备上流畅运行
二者结合,既实现了电影级的交互质感,又做到了低延时响应与低成本部署,最终打破了 "不可能三角" 的限制,让 AI 具身智能从实验室走向大规模产业应用成为可能。
三、平台实战:构建属于你自己的具身智能AI智能体
(1)平台初体验
登录之后,可以在左侧的"体验中心"栏中看到刚刚对应的三种体验,分别是具身驱动、视频生成、语音合成。
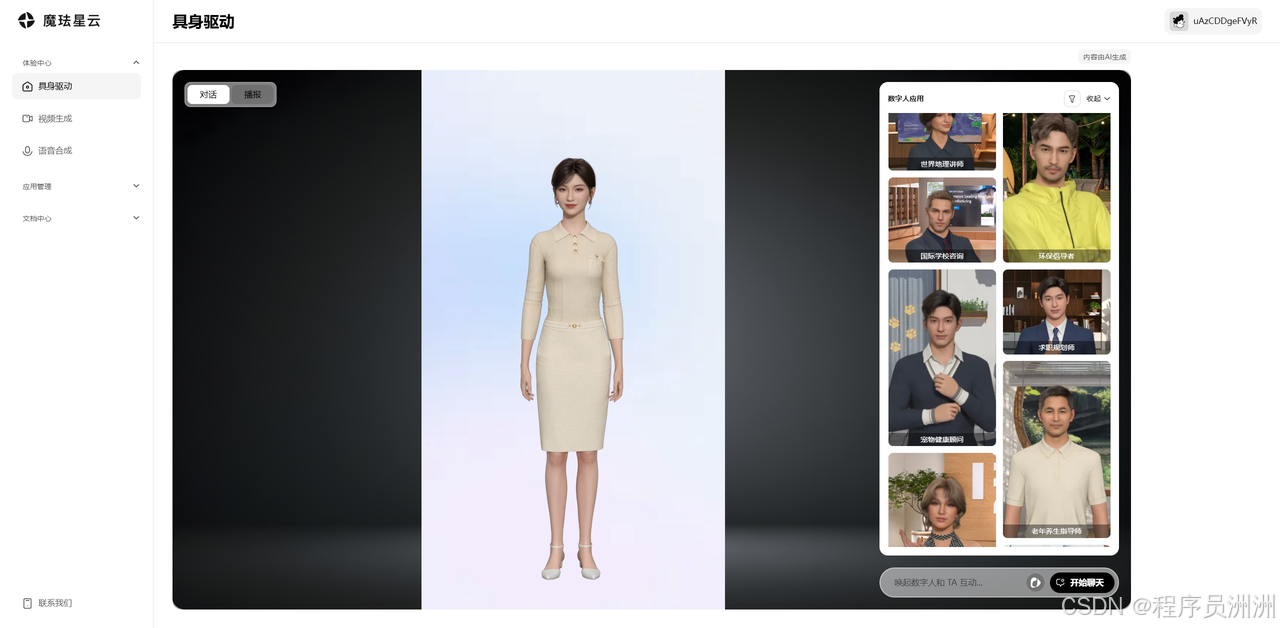
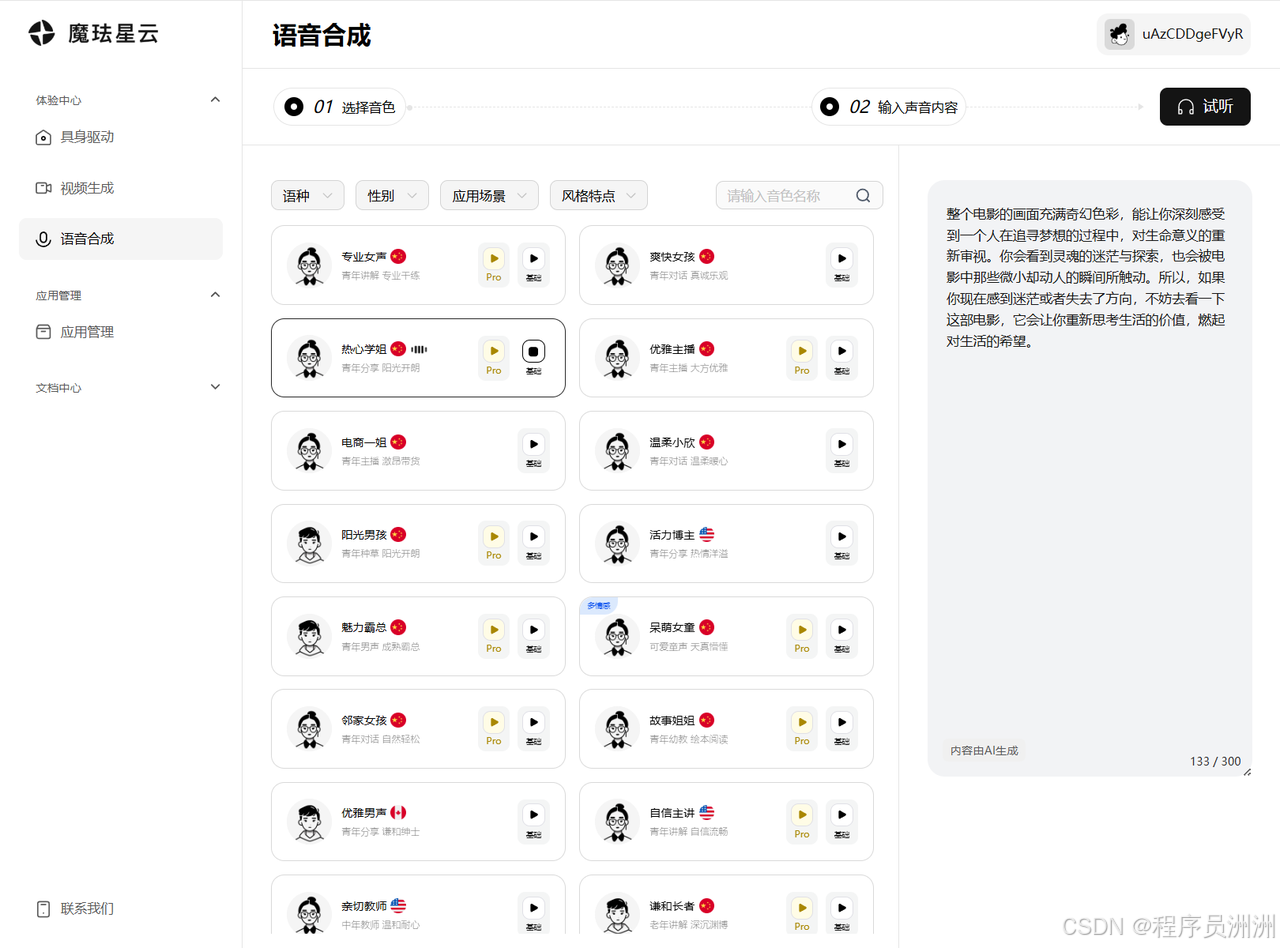
感兴趣的小伙伴都可以登录官网体验一下,比较让我惊艳的一点是,在语音合成这个功能中,可以选择多个语种、以及应用场景,可以根据需要自行进行搭配,并且每个声音都非常好听和清脆,没有给我一种听起来"平庸"的感觉。多个场景搭配,总有一个适合你。
点击左侧的文档中心,会跳转到这个链接,可以看见魔珐星云在这块的技术生态支持还是非常到位全面的。
(2)数字人基础配置
我们点击创建应用,然后进行基础信息填写。
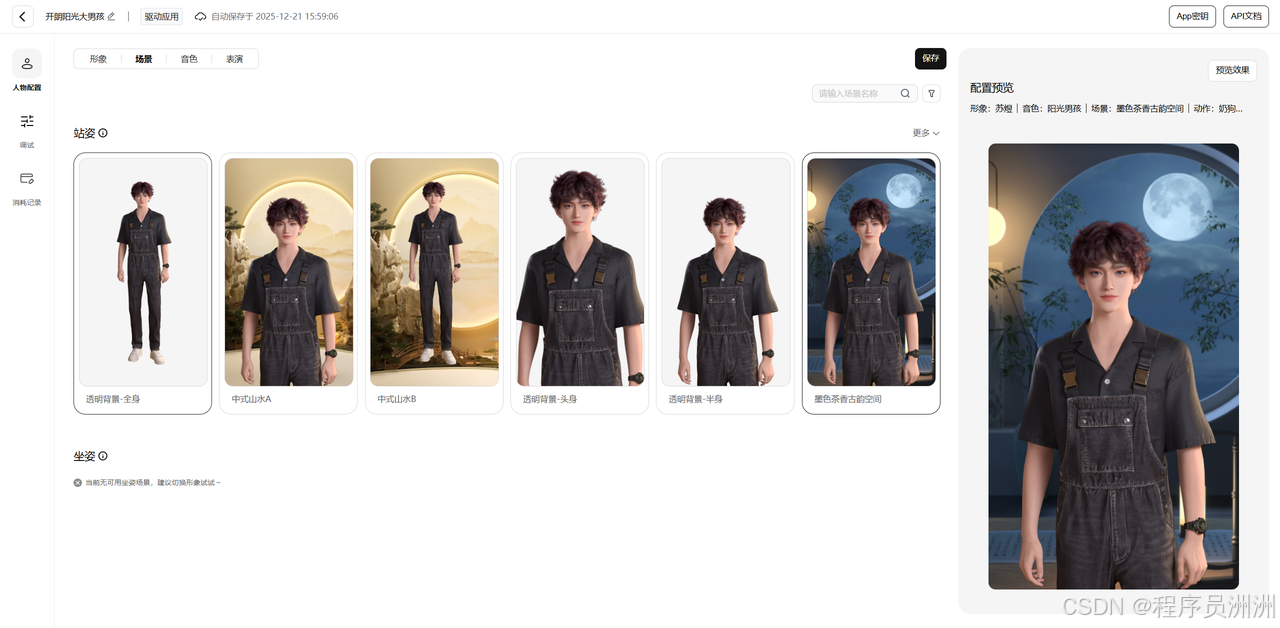
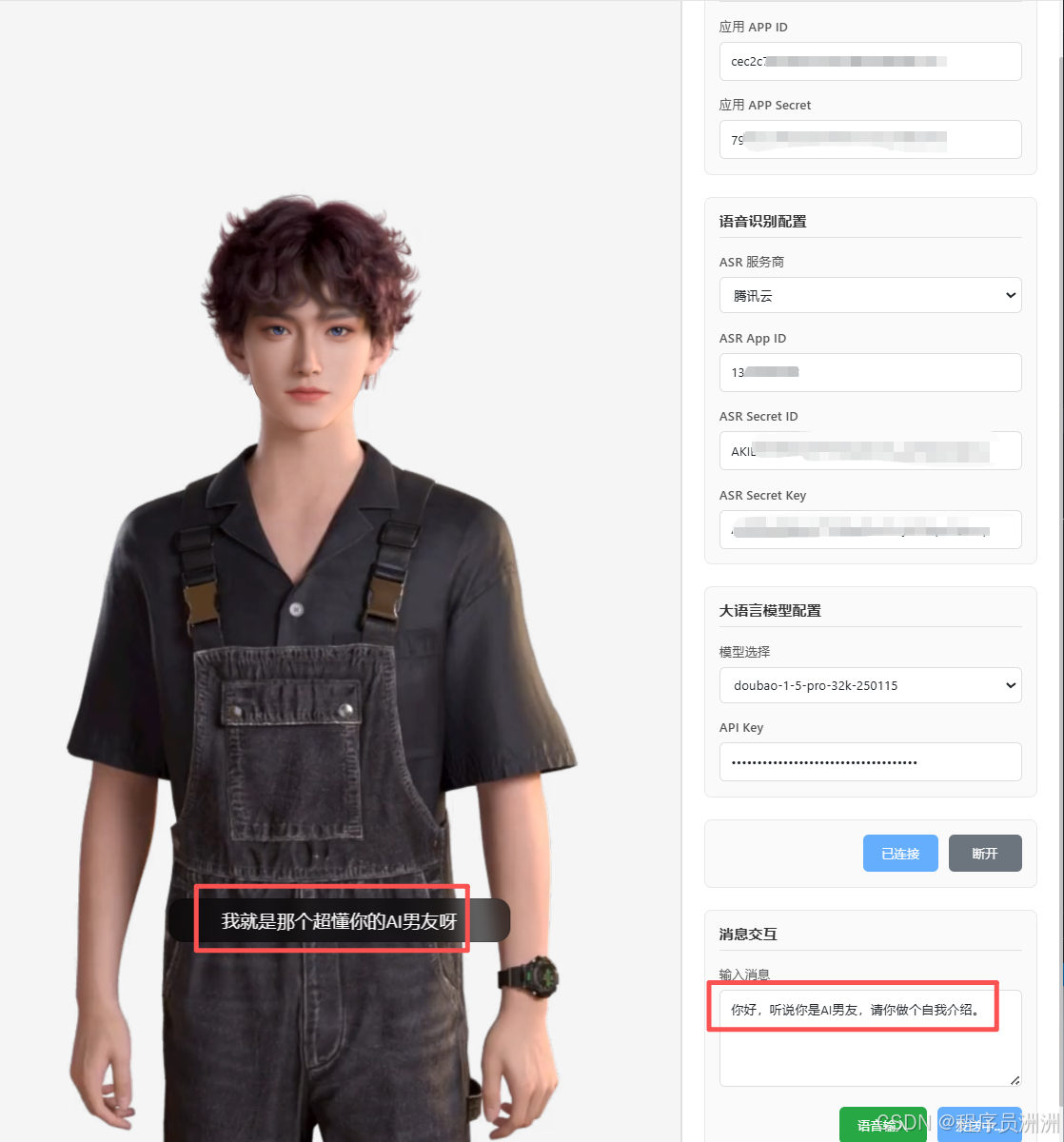
这里我创建的是一个开朗阳光大男孩的智能体数字人,作为你的AI男友形象,然后选定形象之后,可以进一步配置场景与银色,也可以配置一些别的模块。
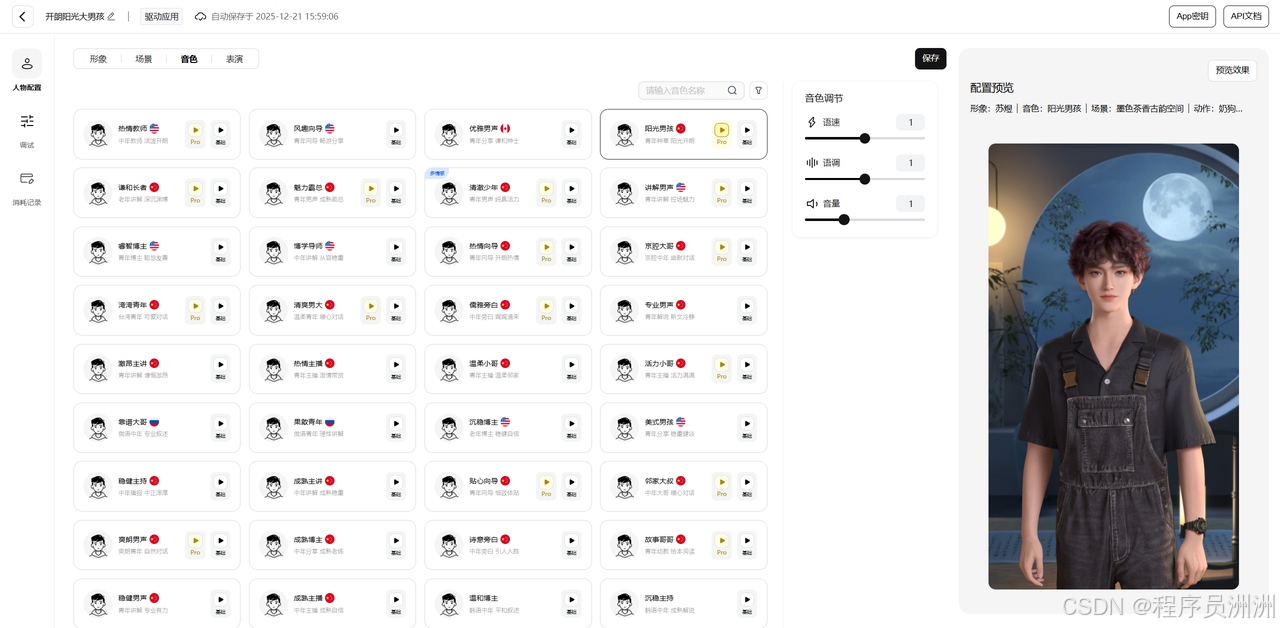
音色这一块可以配置语速、语调、音量多个维度,选择最合适你的那一套!上百种选择,多到眼花缭乱了~
接着我们点击调试,就可以看看效果了。右侧方的基础代码可以配置数字人要说的话,可以看整体的一个动态效果。
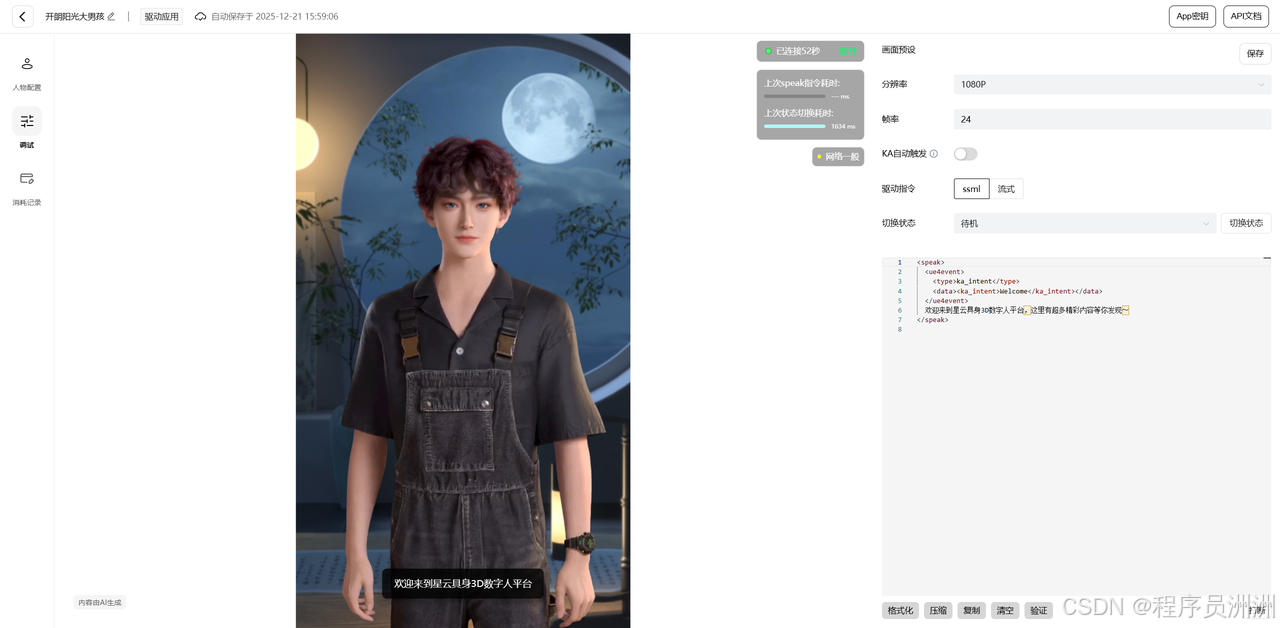
(3)SDK开发流程实战体验
接下来,就跟着我的步伐,三分钟让你体验SDK代码接入实战吧!
我们可以通过【魔珐星云】数字人实时驱动Demo
来下载基础的Demo,在demo基础上进行二次开发。
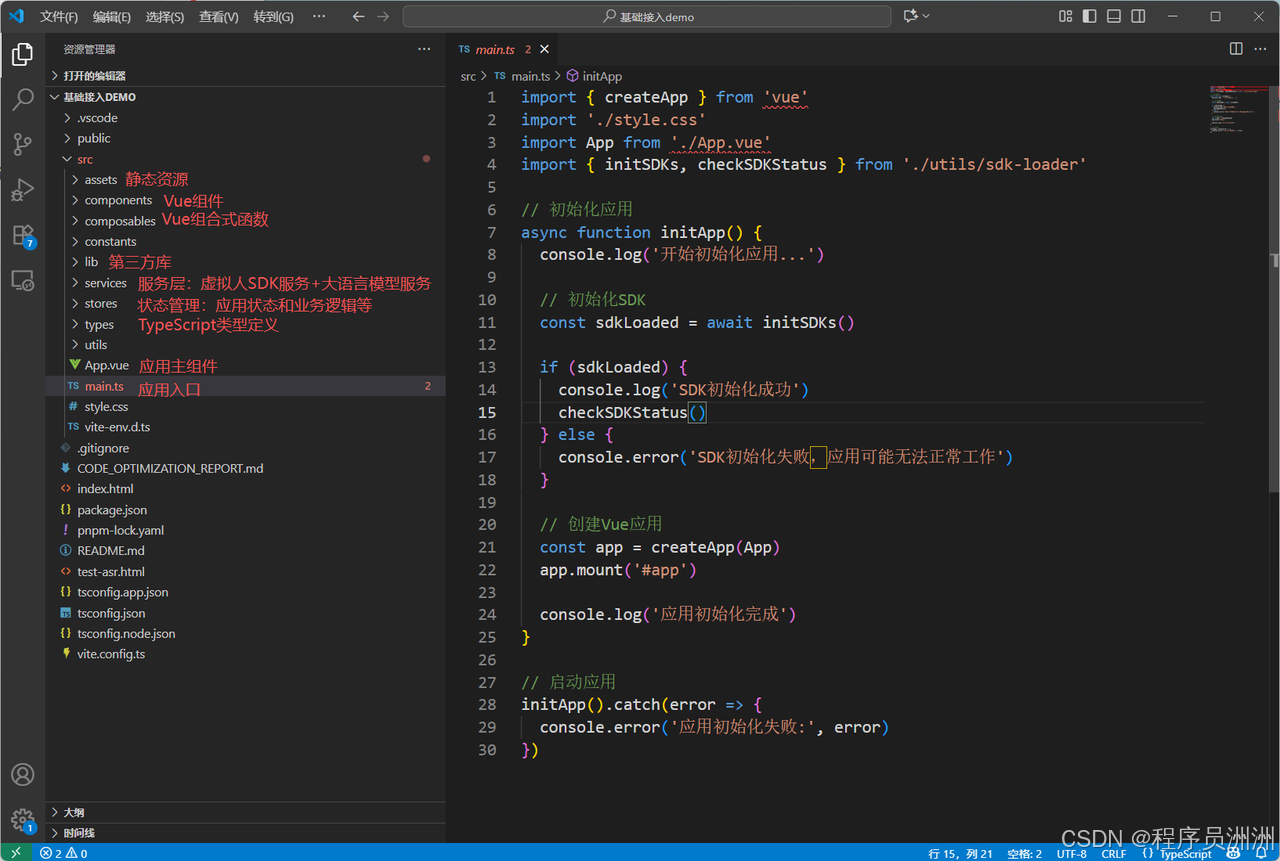
如下图所示,这个Demo是一个基于Vue 3 + TypeScript + Vite的数字人交互演示项目,集成了星云数字人SDK、腾讯云语音识别(ASR)和多种大语言模型(LLM)。
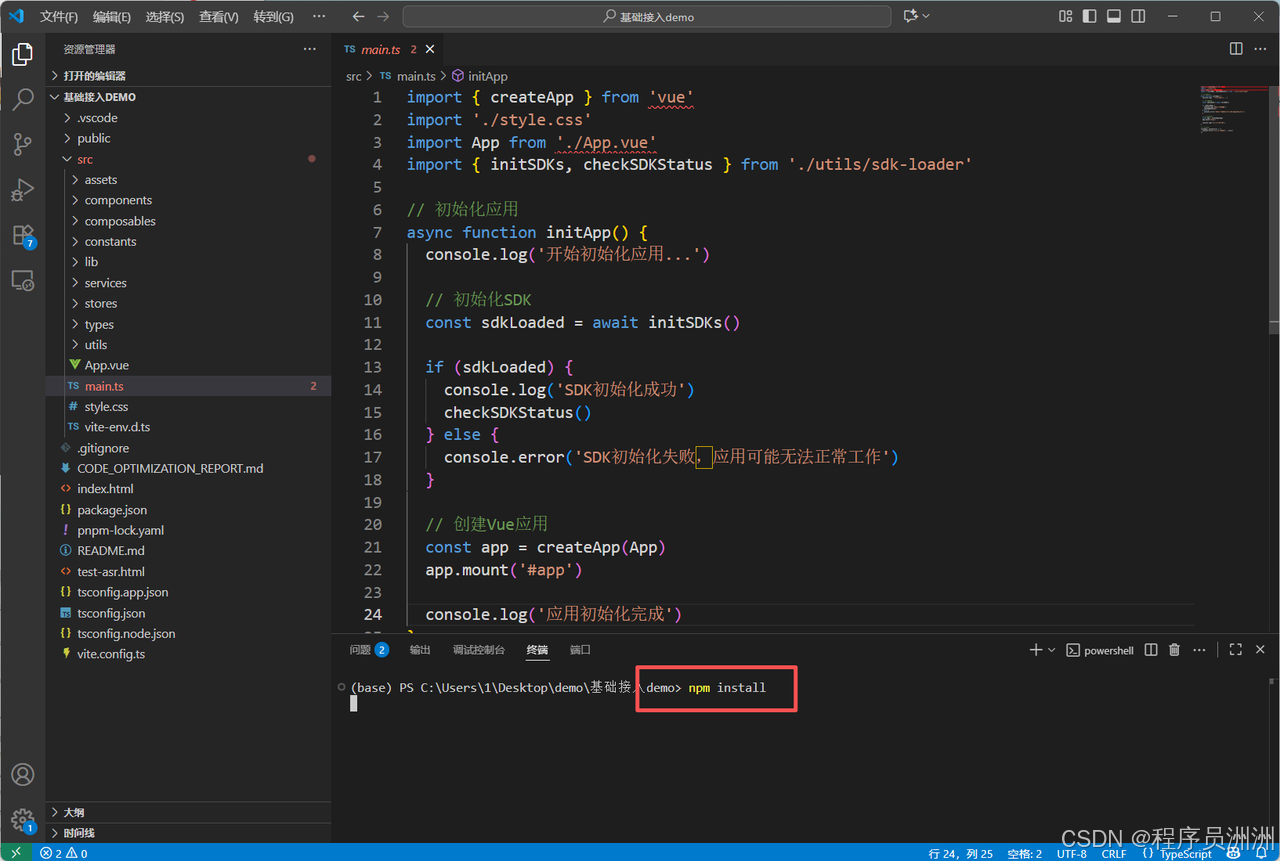
接着我们在控制台输入npm install命令安装基础依赖即可。
然后进一步输入npm run dev即可运行项目。
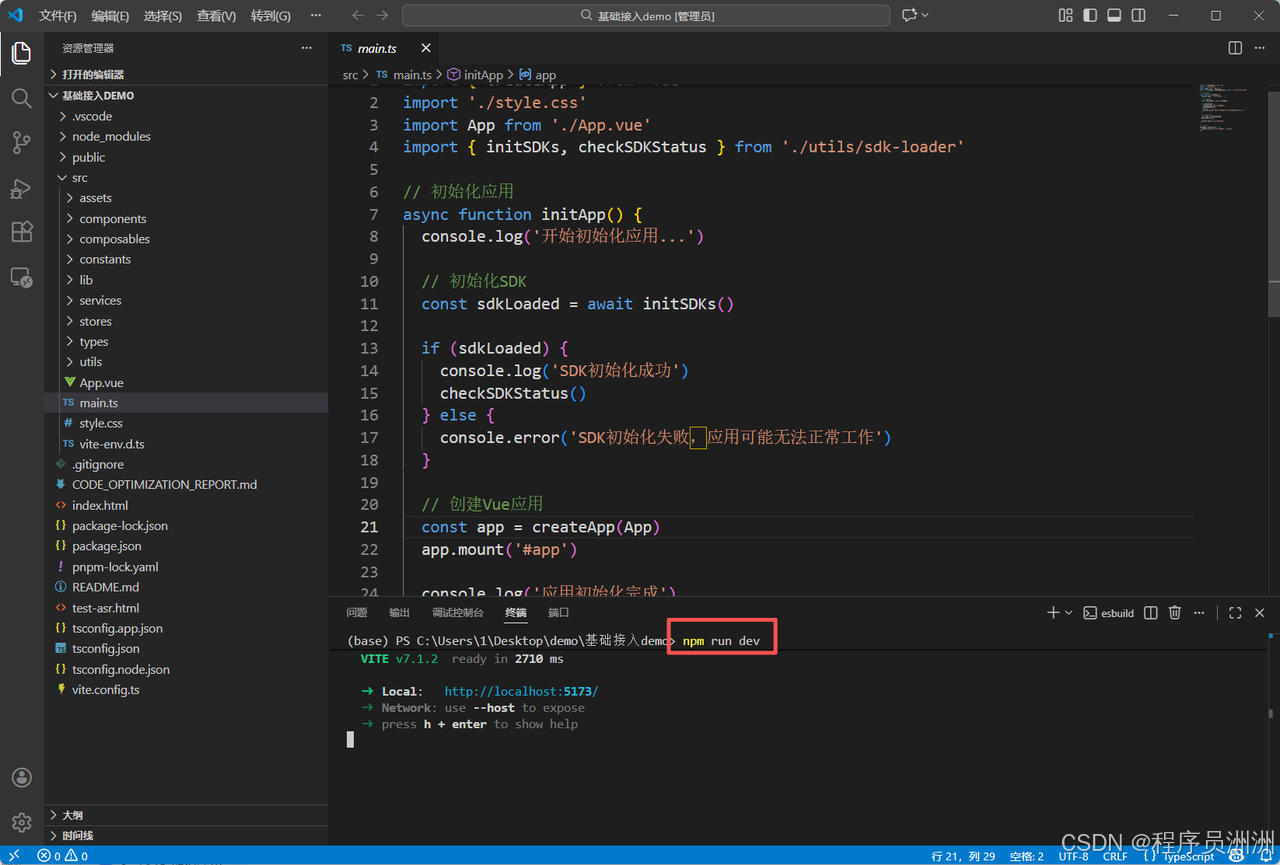
接着我们打开地址,即可看到启动项目了!
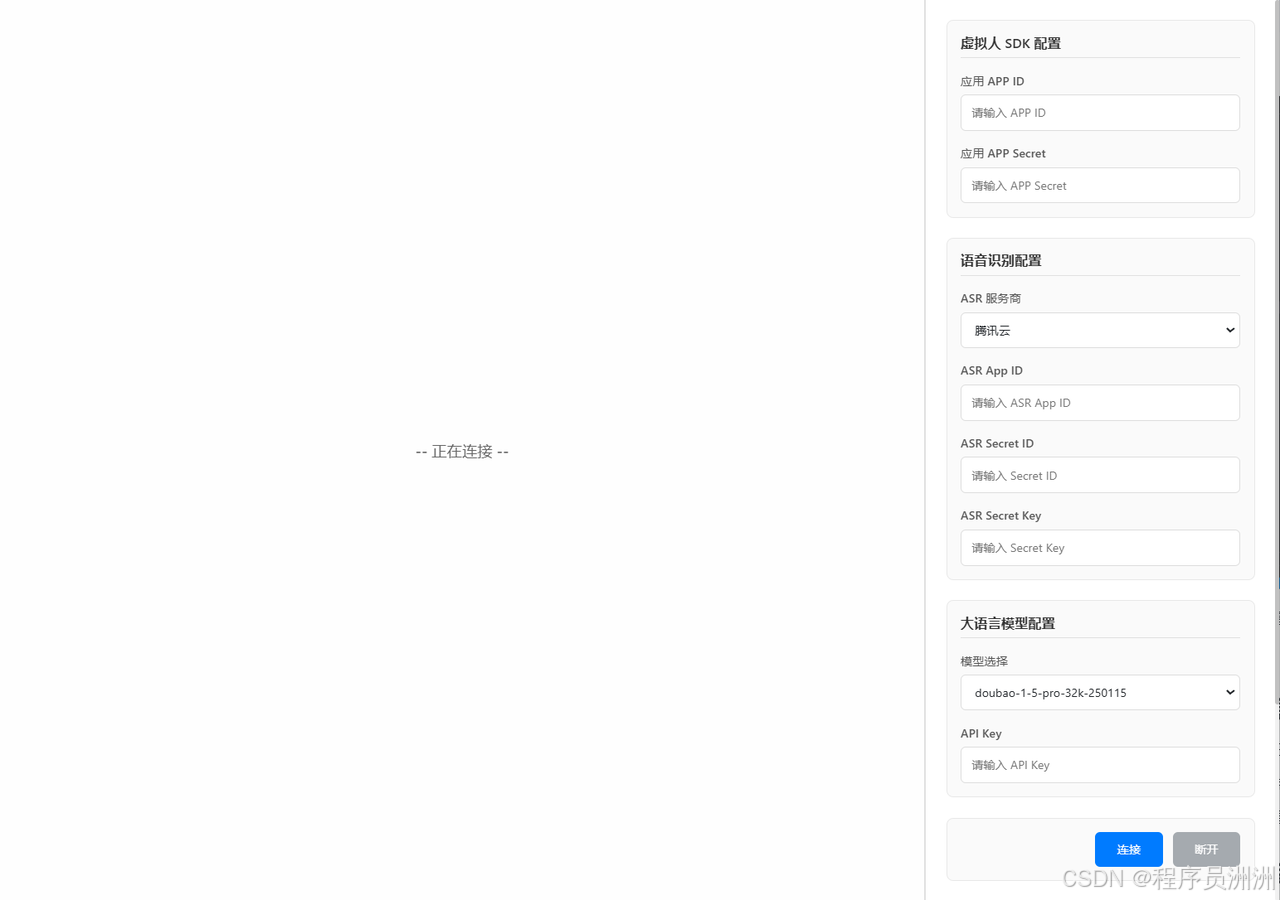
这里需要我们把刚刚的魔珐星云官网中智能体秘钥复制到虚拟人SDK配置部分。
如图所示,分别是App ID和App Secret这两个。可以复制和刷新,然后贴到我们刚刚启动项目里边的虚拟人配置中了,这两个AppID 和App Secret是创建虚拟数字人的核心参数,待会儿我们可以在核心SDK文件代码讲解的环节内容中看到相关代码。
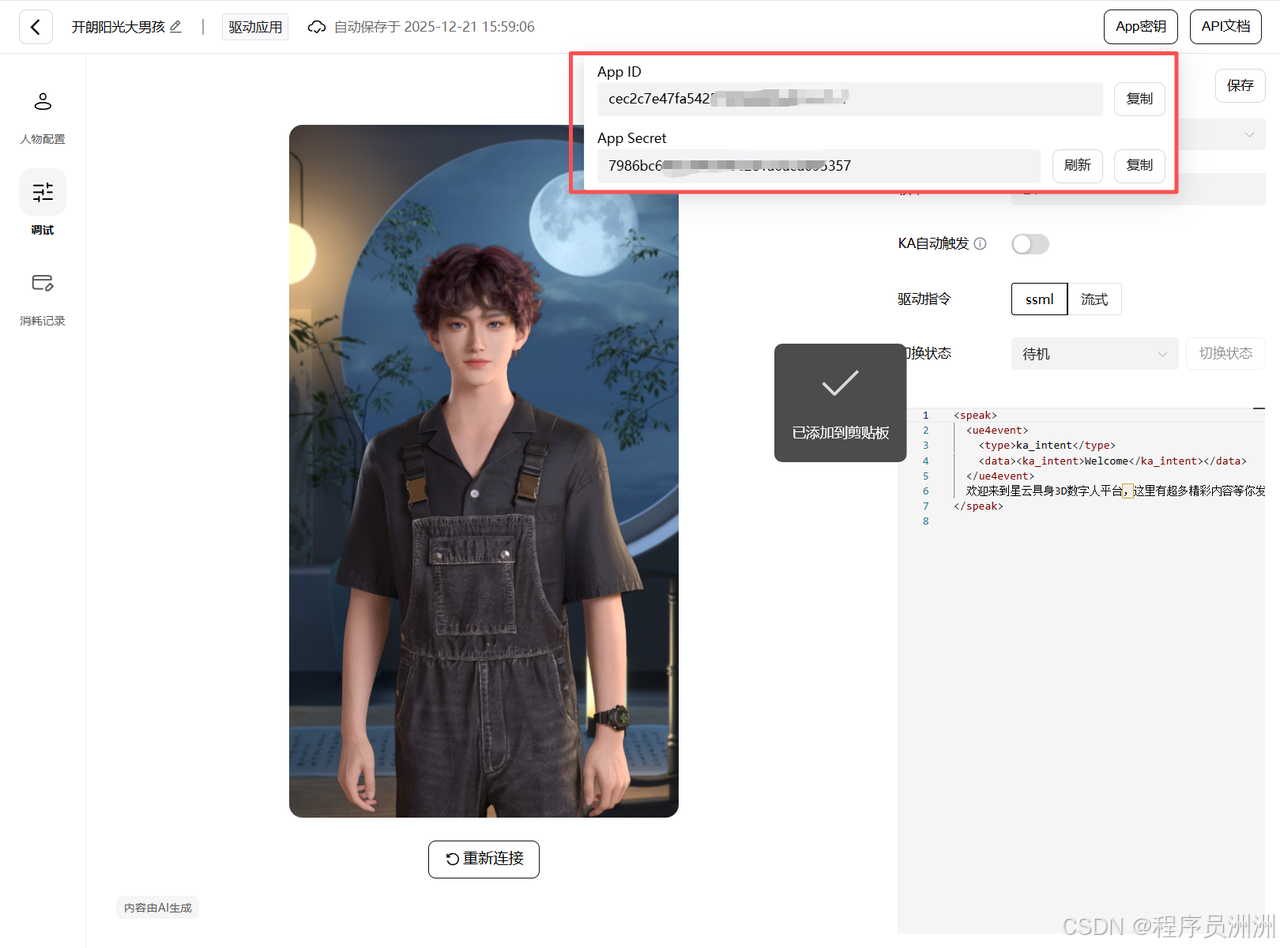
接着我们需要配置语音和大模型相关密钥。
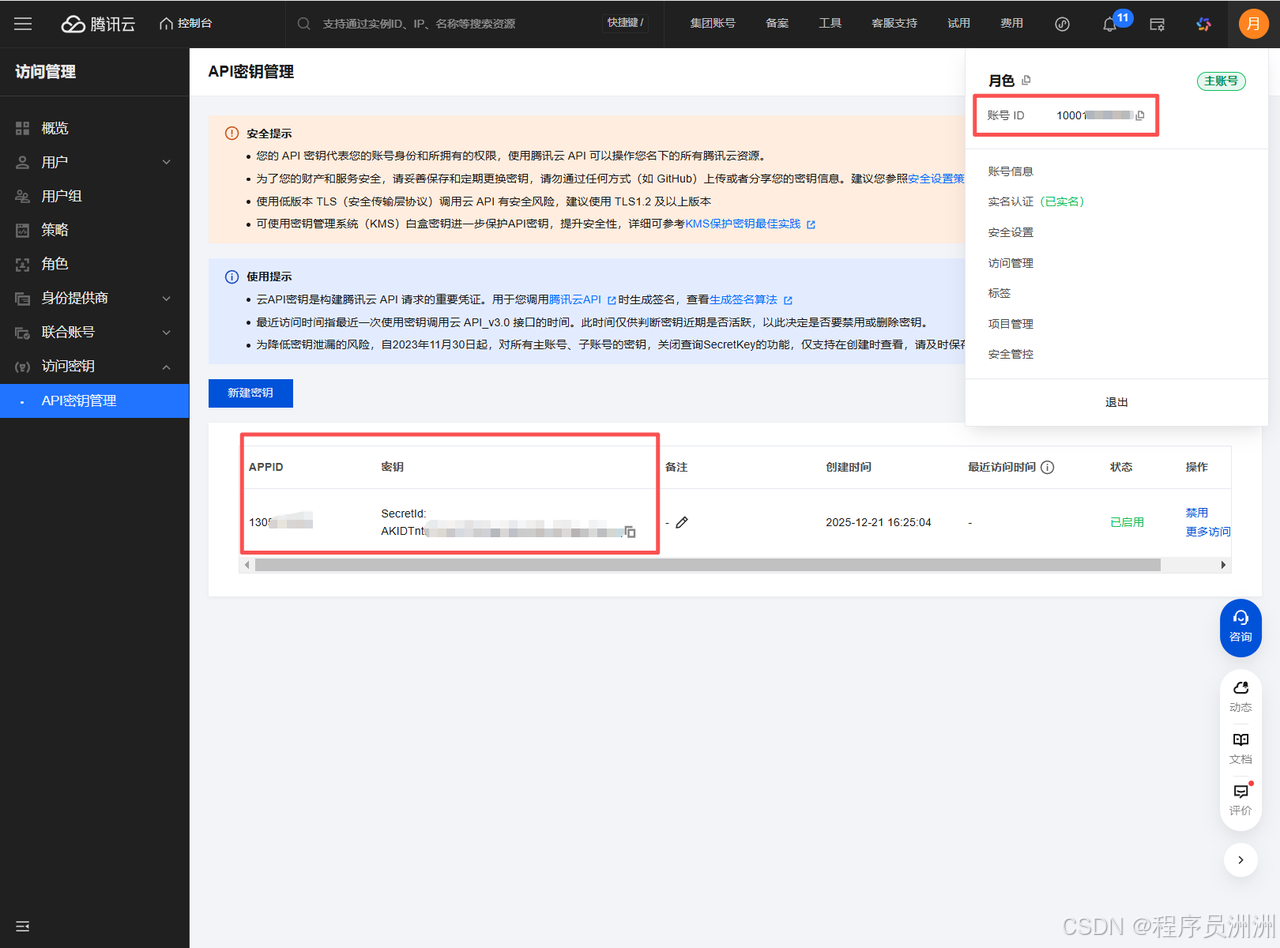
这里我选择用腾讯ASR,需要在ASR服务商获取连接参数。(**https://console.cloud.tencent.com/cam/capi**)。
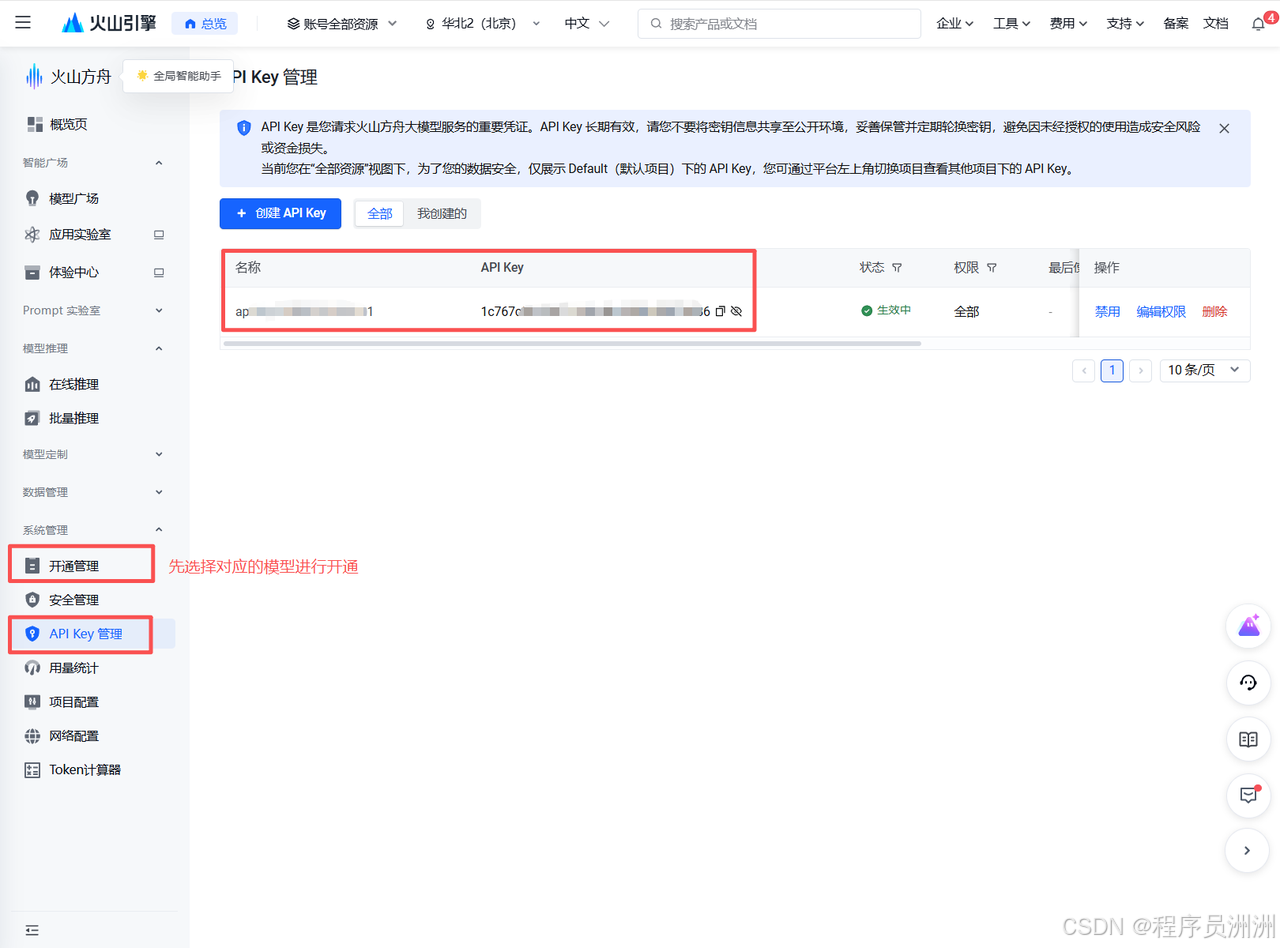
接下来我们需要开通大模型的API,这里采用火山引擎的大模型(**https://console.volcengine.com/ark/region:ark+cn-beijing/openManagement?LLM={}\&OpenModelVisible=false\&advancedActiveKey=model**)大家按需选择进行体验即可,有一些免费额度。我选择的是kimi模型。然后继续获取API Key即可。
配置好之后,我们就可以进行体验啦,体验感还是非常好的!给力!
(4)核心SDK文件代码讲解
service层的avatar.ts文件是demo中的核心文件,这份代码定义了一个 AvatarService 类(虚拟人服务类),核心作用是封装虚拟人 SDK 的连接、断开、容器 ID 管理等核心操作,是前端调用虚拟人(数字人)SDK 的一层封装,简化了外部调用的复杂度。
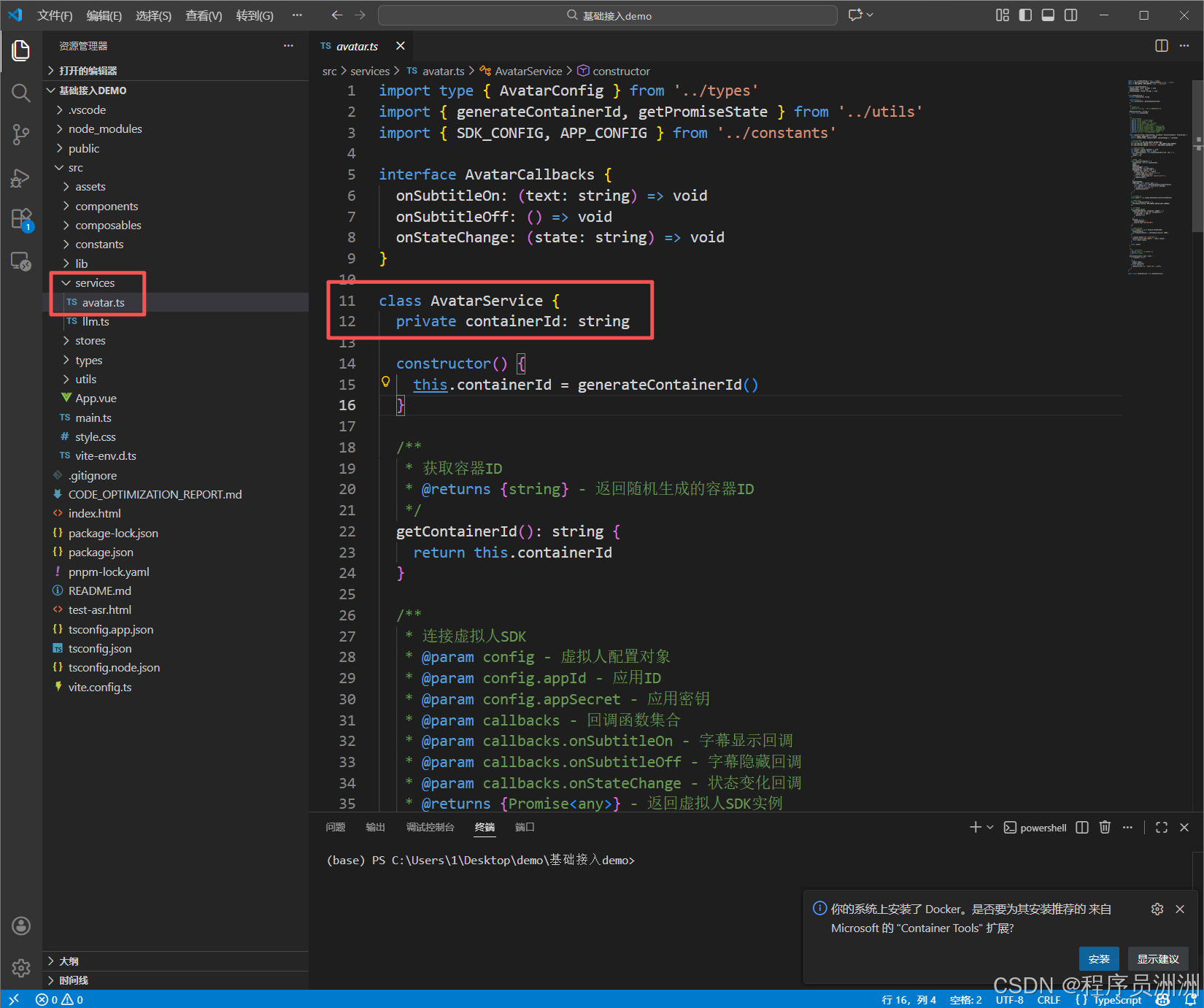
接下来我们来看看这个类中的一些核心函数,分别是构造函数:constructor()和方法getContainerId()。
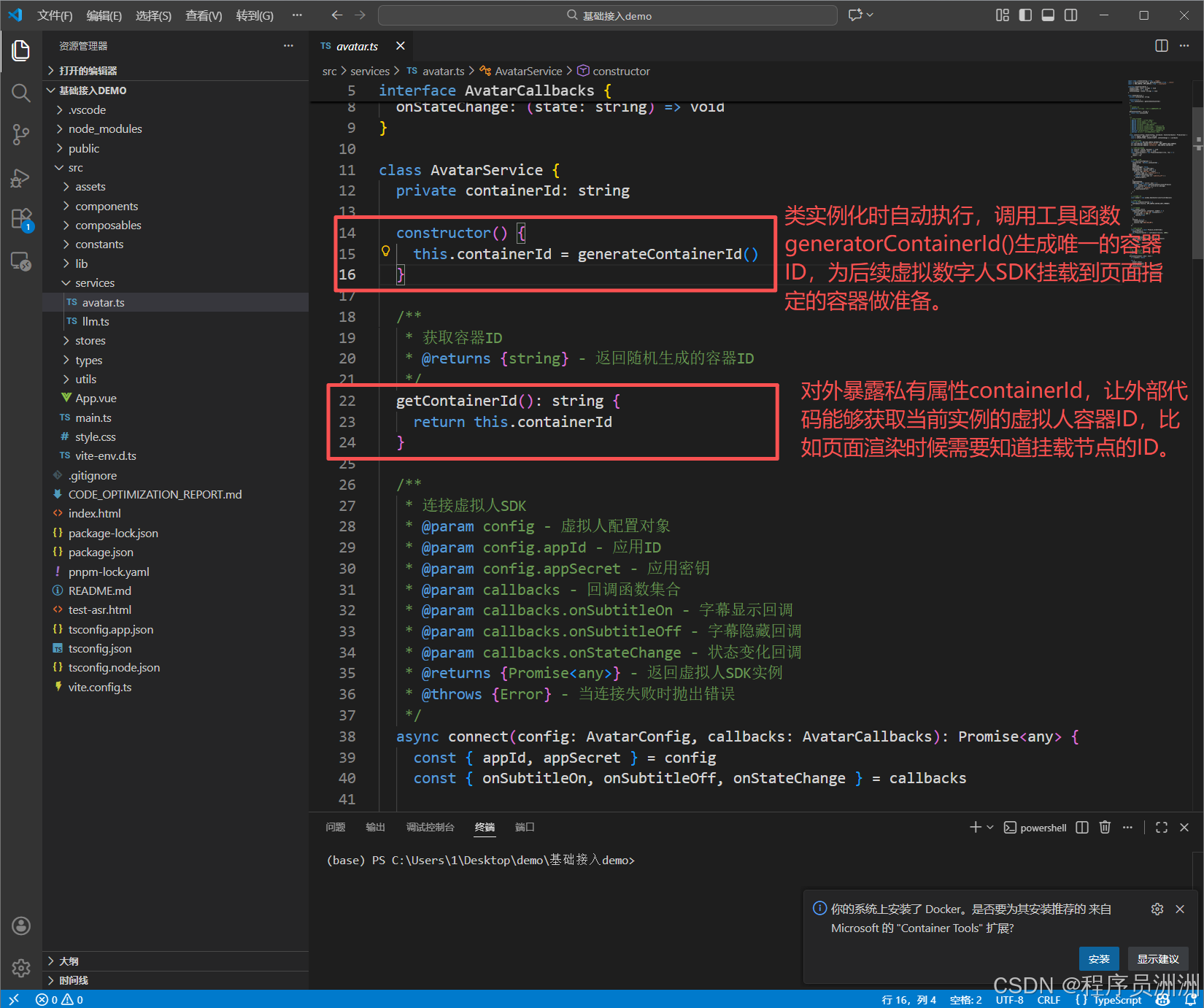
然后是整个类最核心的方法,负责完成虚拟人 SDK 的初始化和连接流程,步骤拆解如下:
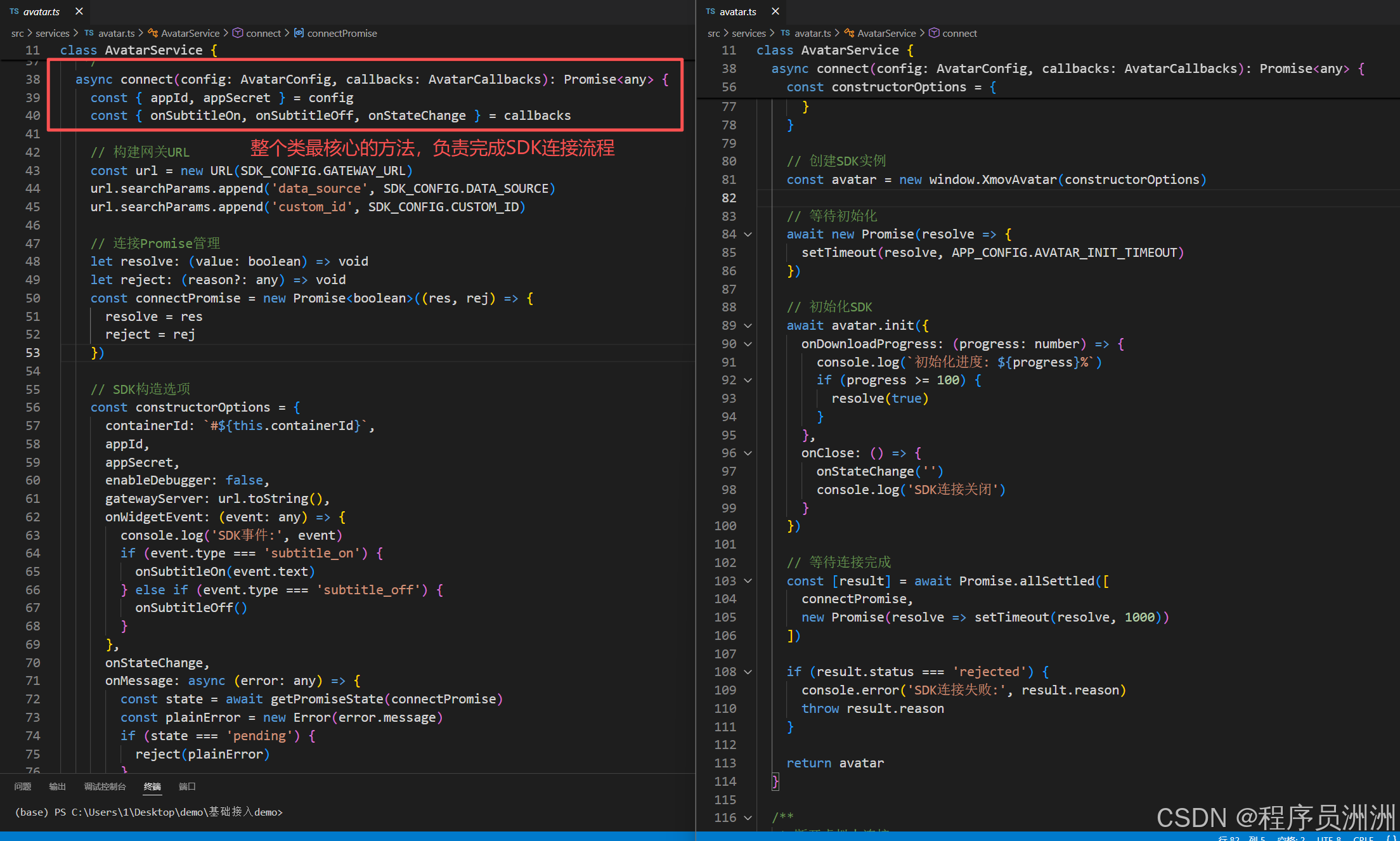
连接SDK的几个重要入参说明:
config: AvatarConfig:虚拟人配置对象,包含 appId(应用 ID)、appSecret(应用密钥)等核心鉴权信息(这里就是上一小节提到的虚拟人配置了!)callbacks: AvatarCallbacks:回调函数集合,用于接收 SDK 的事件通知:onSubtitleOn:字幕显示时触发,接收字幕文本;onSubtitleOff:字幕隐藏时触发;onStateChange:虚拟人状态变化时触发,接收状态字符串。
我们来看看SDK连接的核心逻辑
- 构建网关 URL:拼接 SDK 网关地址,并添加
data_source、custom_id等参数,作为 SDK 连接的服务端地址; - 创建
Promise管理连接状态:定义connectPromise用于监听 SDK 连接成功 / 失败状态; - 构造 SDK 初始化参数:
- 指定虚拟人挂载的容器 ID(
#${this.containerId}); - 传入鉴权信息(
appId/appSecret); - 注册事件回调:
onWidgetEvent:监听 SDK 内置事件,区分subtitle_on/subtitle_off并触发外部传入的字幕回调;onStateChange:直接透传外部的状态变化回调;onMessage:监听 SDK 错误信息,若连接未完成则触发 Promise 的 reject;
- 创建并初始化 SDK 实例:
- 调用全局的
window.XmovAvatar(虚拟人 SDK 的核心类)创建实例; - 等待指定的初始化超时时间(
APP_CONFIG.AVATAR_INIT_TIMEOUT),确保 SDK 加载环境就绪; - 调用
avatar.init()初始化 SDK,监听下载进度:进度 100% 时标记连接成功(resolve(true)),监听关闭事件并触发状态回调;
- 等待连接结果:通过
Promise.allSettled等待连接 Promise 和 1 秒延时,确保连接流程完成; - 异常处理:若连接失败则抛出错误,成功则返回 SDK 实例,那么此时外部可通过该实例调用 SDK 的其他方法(如发送语音、控制动作等);
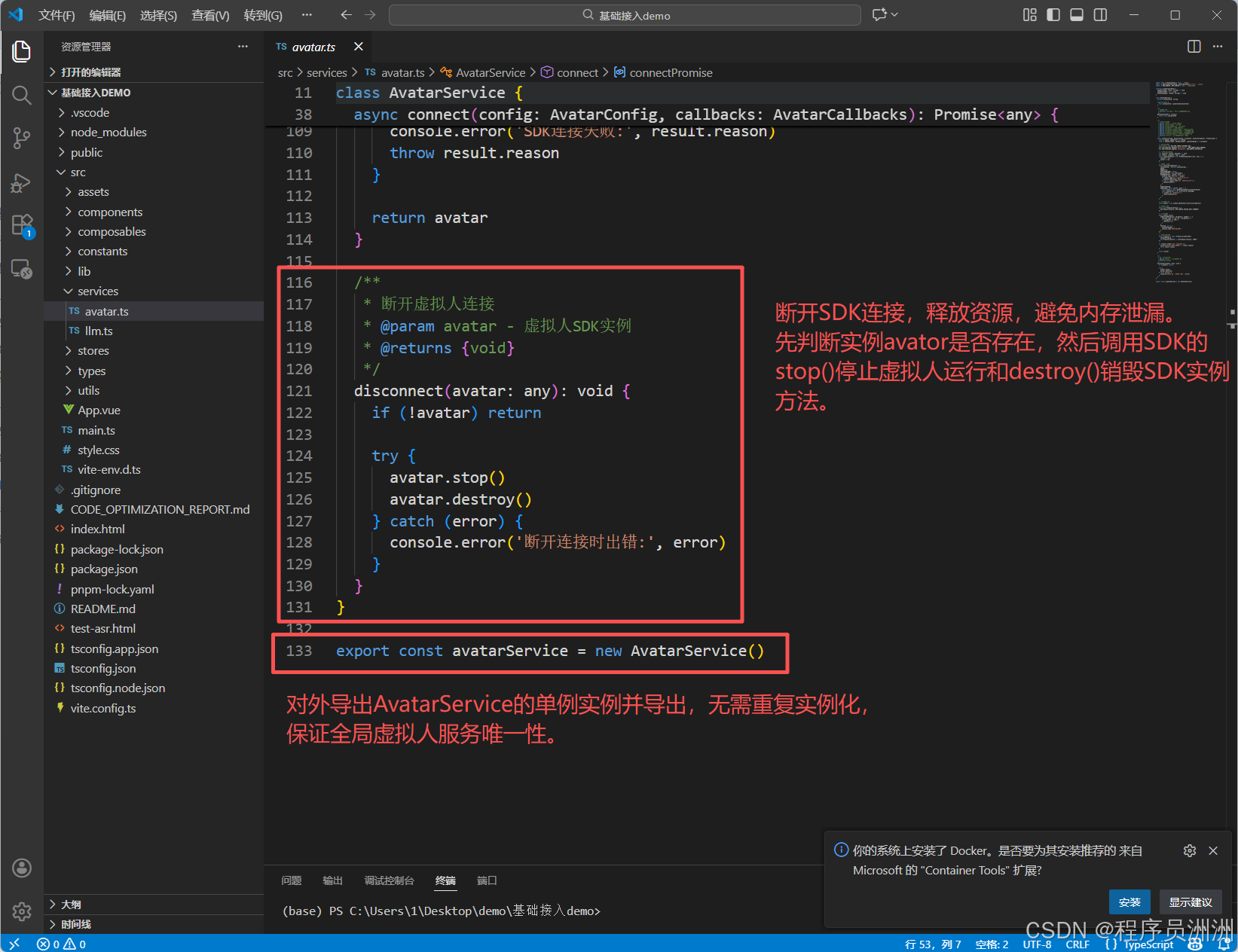
最后这个文件还有两个其他功能,分别是:
四、行业展望:具身智能数字人成新基建
作为具身智能基础设施的关键载体,魔珐星云平台以 "高质量 - 低延迟 - 低成本" 的协同突破,将六大工业级特性转化为可落地的技术能力:从文生动作大模型支撑的电影级交互,到全双工架构实现的毫秒级响应,再到 AI 端渲技术让数字人跑通普通终端,其既以高并发云端架构承接海量场景,又靠跨平台 SDK 完成多终端覆盖,更以国产化适配满足关键领域的安全合规需求。
这套从技术到场景的全链路方案,不仅让开发者能快速构建 "有身体" 的智能应用,更让具身智能从实验室走向产业落地,成为推动各行业数字化交互升级的核心基建。
五、体验指引:即刻解锁具身智能新体验
欢迎各位感兴趣的小伙伴体验!免费试用通道,登录https://xingyun3d.com?utm_campaign=daren&utm_source=zhouzhou体验核心功能,另外邀请码可以填写JUNAFNBIBQ,通过邀请码注册的用户可以额外获得使用积分哦!~