文章目录
- 前言
- [LLaMA Factory WebUI](#LLaMA Factory WebUI)
- [LLaMA Factory 微调通用设置](#LLaMA Factory 微调通用设置)
前言
本文不涉及 LLaMA Factory 的具体使用,而仅仅是对 LLaMA Factory 其中各种参数设定等功能进行详解。
LLaMA Factory 快速使用:使用 LLaMA Factory 微调一个 Qwen3-0.6B 猫娘
本文重点参考 code秘密花园 的教程,因其过于繁琐,故用本人阅读喜好重写笔记,用作留存。
原版教程:从零教你微调一个专属领域大模型,看完小白也能学会炼丹!(完整版)
LLaMA Factory WebUI
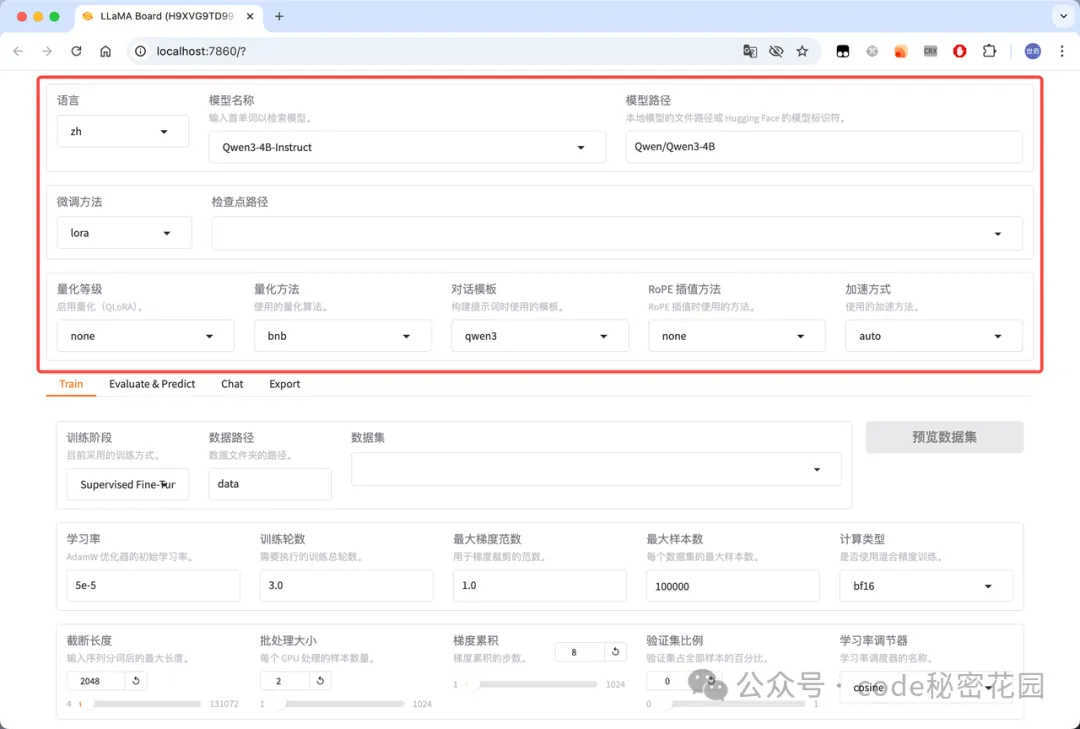
- 通用设置:可以设置 WebUI 展示的语言、需要微调的模型、微调的方法、是否量化、微调的加速方式等配置:
- 微调训练:包括以下几部分配置:
- 微调训练的阶段:预训练、指令微调、强化学习等等;
- 微调使用的数据集:数据集的格式、路径、验证集的比例等等;
- 关键微调参数:在我们之前教程中重点学习的:学习率、训练轮数、批量 大小等等;
- LoRA 参数:当使用 Lora 微调时需要配置的一些特殊参数;
- RLHF 参数:当训练阶段为强化学习时需要配置的一些特殊参数;
- 特殊优化参数:当选择使用 GaLore、APOLLO 和 BAdam 优化器时需要配置的一些参数;
- SwanLab 参数:一款开源的模型训练跟踪与可视化工具;
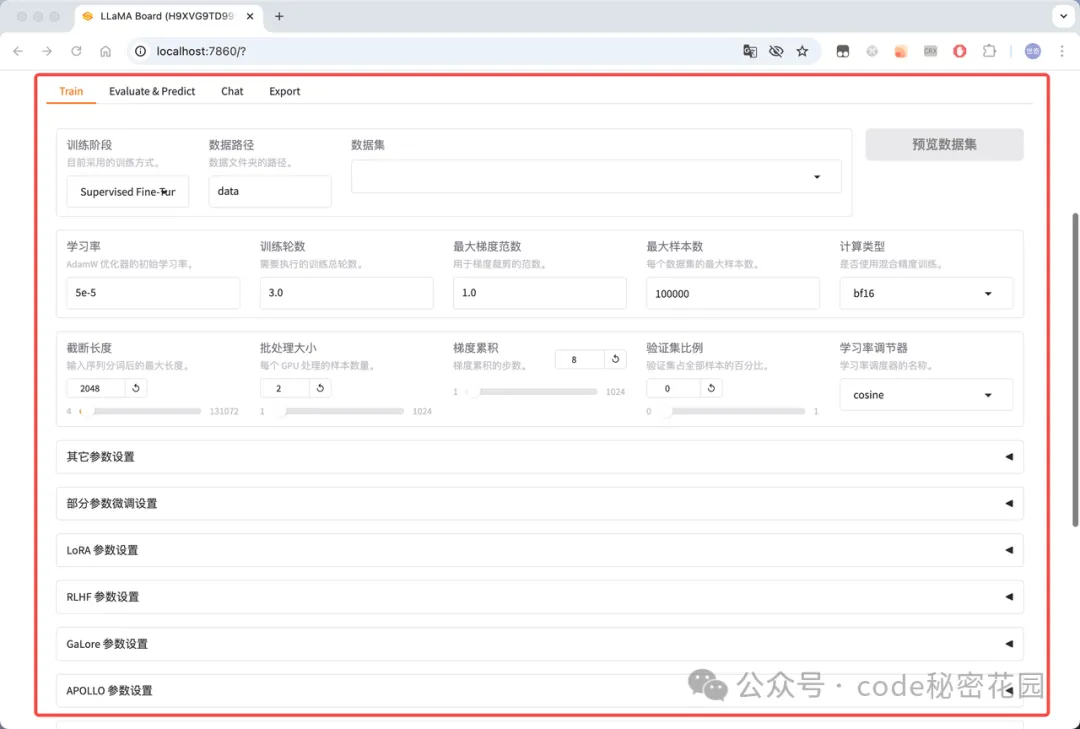
- 模型评估:在完成模型训练后,可以通过此模块来评估模型效果,这里可配置模型评估所需的数据集等:
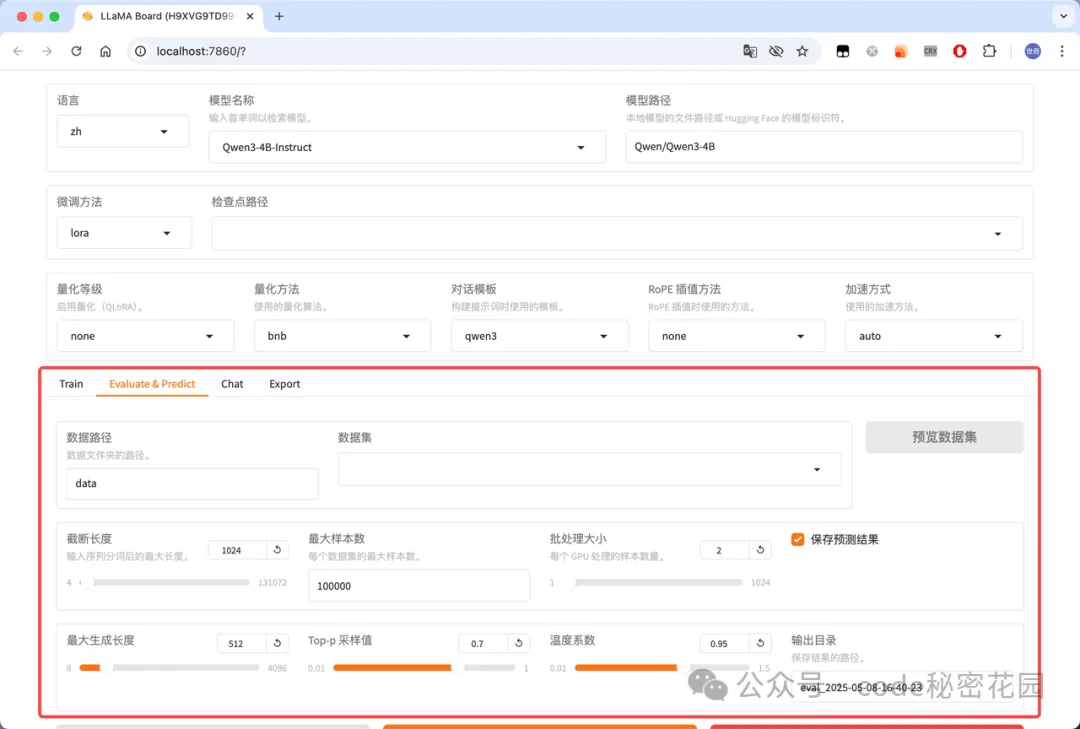
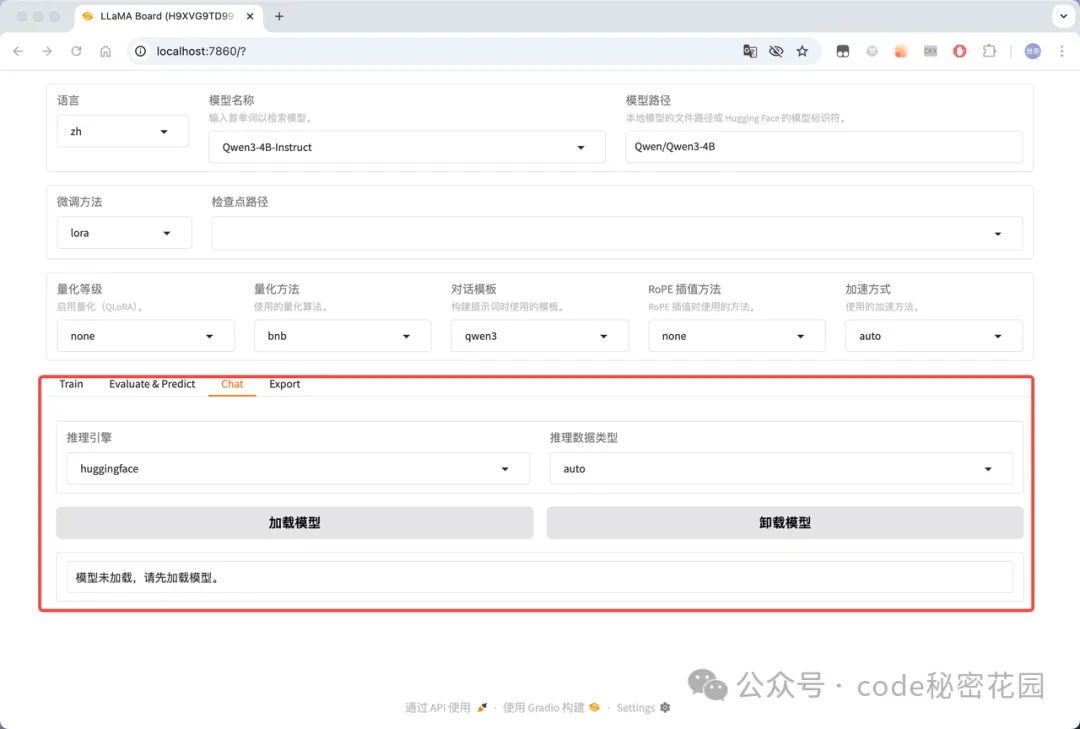
- 在线推理:可以选择使用 huggingface、vllm 等推理引擎和模型在线聊天,主要用来测试加载模型:
- 模型导出:可以指定模型、适配器、分块大小、导出量化等级及校准数据集、导出设备、导出目录等。
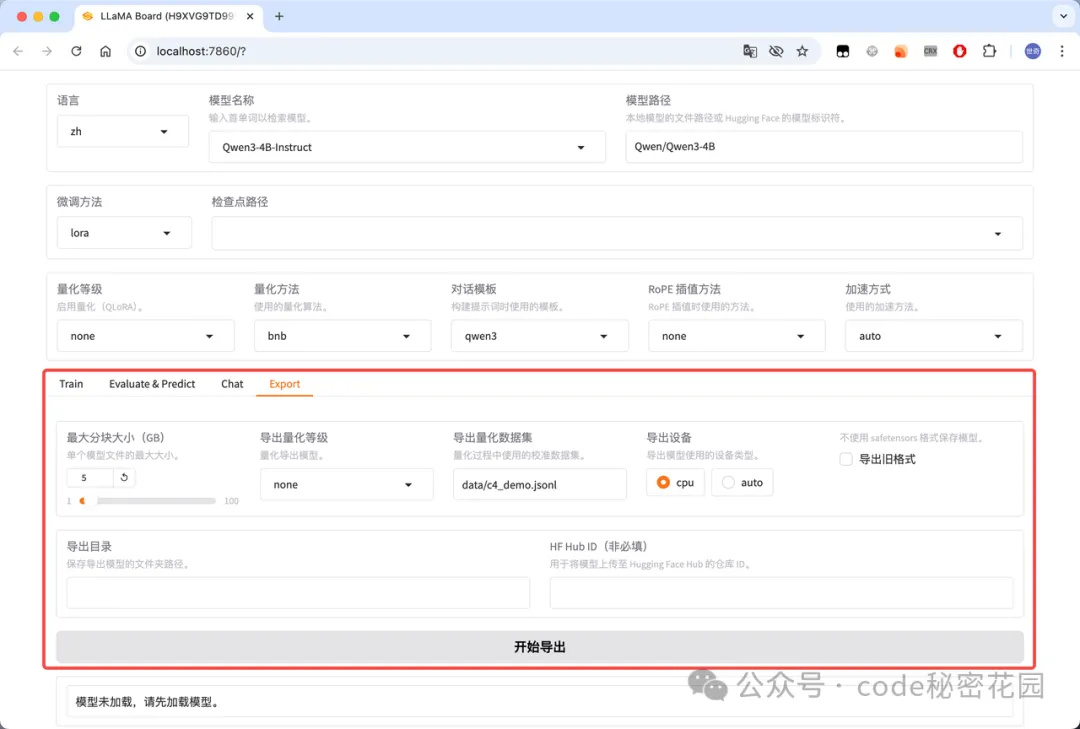
LLaMA Factory 微调通用设置
基座选择
| 分类 | 标识 | 含义 | 示例(模型名称) |
|---|---|---|---|
| 功能开发与任务类型 | -Base | 基础模型,未经过特定任务微调,提供原始能力(用于二次开发)。 | Qwen3-14B-Base |
| -Chat | 对话优化模型,支持交互式聊天、问答,不针对特定任务微调。 | DeepSeek-LLM-7B-Chat | |
| -Instruct | 指令微调模型,擅长遵循具体任务指令(推理、生成、翻译等)。 | Qwen3-0.6B-Instruct | |
| -Distill | 知识蒸馏模型,通过蒸馏技术压缩,模型更小、推理更高效。 | DeepSeek-R1-1.5B-Distill | |
| -Math | 专注数学推理任务,优化数值计算、公式推导、逻辑证明等能力。 | DeepSeek-Math-7B-Instruct | |
| -Coder | 针对代码生成、编程任务优化,支持代码补全、漏洞检测、算法实现等。 | DeepSeek-Coder-V2-16B | |
| 多模态 | -VL | 视觉-语言多模态(Vision-Language),支持图文联合输入输出。 | Kimi-VL-3B-Instruct |
| -Video | 视频多模态模型,结合视频帧与文本进行交互。 | LLaVA-NeXT-Video-7B-Chat | |
| -Audio | 支持音频输入,涉及语音识别(ASR)或语音合成(TTS)。 | Qwen2-Audio-7B | |
| 技术特性与存在优化 | -Int8/-Int4 | 权重量化模型(Int8为8位,Int4为4位),降低显存占用,提升推理速度(适合低资源设备)。 | Qwen2-VL-2B-Instruct-GPTQ-Int8 |
| -AWQ/-GPTQ | 特定量化技术(自适应权重/GPT量化),优化低精度下的模型性能。 | Qwen2.5-VL-7B-Instruct-AWQ | |
| -MoE | 混合专家模型(Mixture of Experts),包含多个专用模块处理复杂任务。 | DeepSeek-MoE-16B-Chat | |
| -RL | 使用强化学习(Reinforcement Learning)优化,提升对话质量或任务响应。 | MiMo-7B-Instruct-RL | |
| 版本与变体标识 | -v0.1/-alpha/beta | 模型版本号,标识开发阶段(alpha/beta/正式版)。 | Mistral-7B-v0.1 |
| -Pure | 纯净版模型,去除领域数据或保留原始能力,避免特定偏见。 | Index-1.9B-Base | |
| -Character | 角色对话模型,支持角色扮演或特定人设(如虚拟助手、动漫角色)。 | Index-1.9B-Character-Chat | |
| -Long-Chat | 支持长上下文对话(通常≥4k tokens),处理超长输入输出。 | Orion-14B-Long-Chat | |
| 领域与应用标识 | -RAG | 检索增强生成模型,结合外部知识库检索与生成能力。 | Orion-14B-RAG-Chat |
| -Chinese | 中文优化版本,支持中文分词、方言、拼音纠错等本土化能力。 | Llama-3-7B-Chinese-Chat | |
| -MT | 机器翻译专用模型,支持多语言翻译任务(如中英、英日互译)。 | BLOOMZ-7B1-mt |
微调方法
Full(全参)
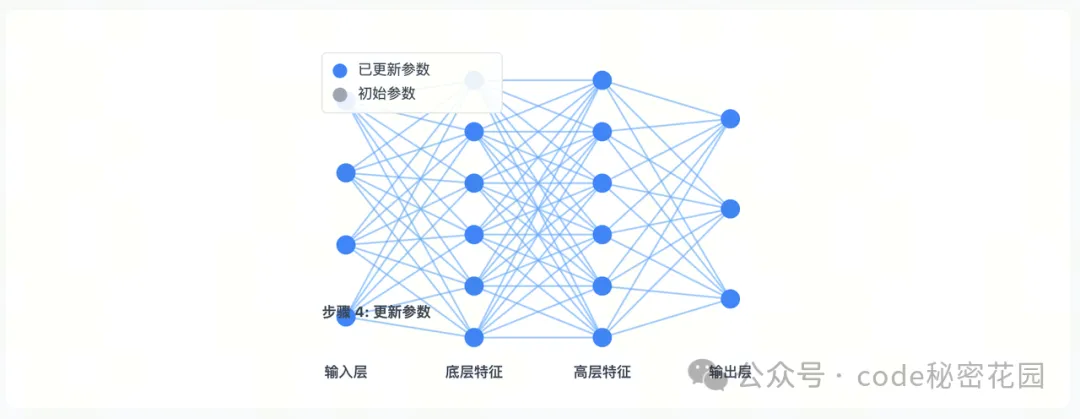
- 全参数微调是最直接的迁移学习方法,通过在目标任务数据上继续训练预训练模型的全部参数。
- 通俗理解:就好比把一栋房子彻底拆掉重建。预训练模型就像已经建好的房子,里面的每一块砖、每一根梁,在全参数微调时都要重新调整。例如,当我们想用一个原本用于识别普通图片的模型,改造为识别医学影像的模型时,就要把模型里所有参数都更新一遍。
- 优点
- 最大化性能:通常能够在目标任务上达到最佳性能
- 完全适应性:允许模型充分适应新任务的特性
- 灵活性:可以用于各种不同的下游任务
- 实现简单:概念直接,实现相对简单
- 缺点
- 计算资源需求高:需要大量GPU内存和计算能力
- 存储成本高:每个任务都需要保存一个完整模型副本
- 灾难性遗忘:可能会丢失原始预训练中获得的知识
- 过拟合风险:在小数据集上容易过拟合
- 不适合低资源场景:在资源受限设备上难以部署
全参数微调适用场景:有充足的计算资源、需要最大化模型性能、目标任务与预训练任务有显著差异、 或有足够的任务数据可以有效训练所有参数。
Freeze(冻结)
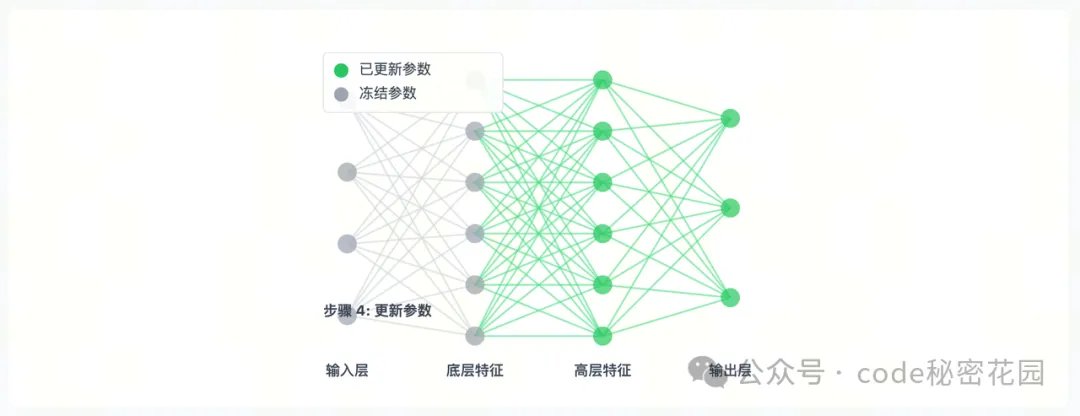
- 参数冻结微调通过选择性地冻结模型的某些部分,只更新剩余参数,从而减少计算量并防止过拟合。
- 通俗理解:像是给房子做局部装修。我们保留房子的框架结构,只对部分区域进行改造。在模型中,就是保留预训练模型的底层结构,只调整顶层的部分参数。比如在训练一个糖尿病问答模型时,我们可以把语言模型的前 24 层参数冻结起来,只训练最后 3 层专门用于医学领域问答的分类器。
- 优点
- 计算效率:减少需要计算的参数数量,加快训练速度
- 内存效率:反向传播中不需要存储冻结参数的梯度
- 防止过拟合:特别适合小型数据集训练
- 保留通用特征:防止破坏预训练模型中有价值的通用特征
- 减少灾难性遗忘:保持模型的泛化能力
- 缺点
- 性能可能次优:在某些任务上可能无法达到全参数微调的性能
- 需要专业知识:选择哪些层冻结需要对模型架构有深入了解
- 灵活性降低:在任务与预训练差异大时效果可能不佳
- 调优困难:找到最佳的冻结点可能需要多次实验
参数冻结微调适用场景:计算资源受限的环境、训练数据集较小、目标任务与预训练任务相似、模型主要需要学习任务特定的表示、需要防止过拟合。
LoRA(低秩矩阵)
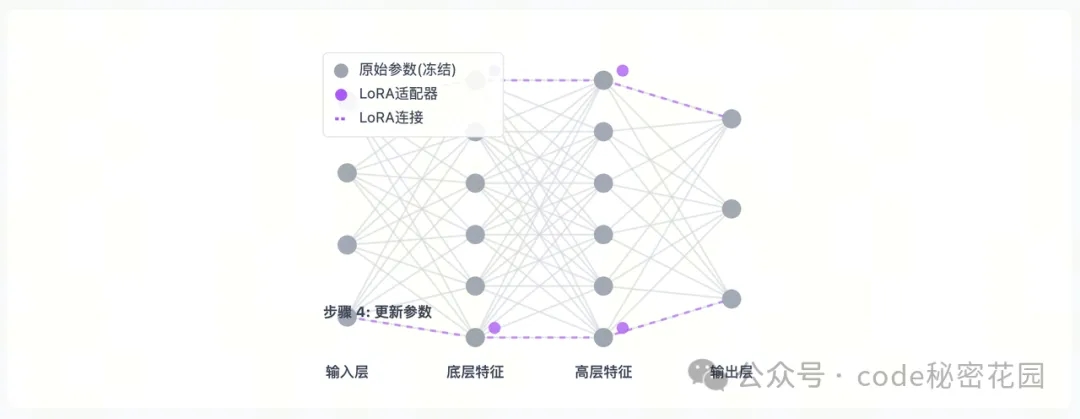
- LoRA 通过向预训练模型中注入小型、可训练的低秩矩阵,在保持原始参数不变的情况下实现高效微调。
- 通俗理解:可以想象成给房子安装智能设备,不改变房子的原有结构,却能让房子变得更智能。在模型里,它不会直接修改原有的参数,而是在关键位置插入可训练的 "小模块"。
- 优点
- 极高的参数效率:训练参数数量减少99%以上
- 内存效率:大幅降低GPU内存需求
- 训练速度快:减少计算量,加快收敛
- 存储高效:每个任务只需保存小型适配器
- 可组合性:不同任务的适配器可以组合使用
- 避免灾难性遗忘:原始参数保持不变
- 缺点
- 性能上限:在某些复杂任务上可能弱于全参数微调
- 秩超参数选择:需要为不同模型和任务调整适当的秩
- 实现复杂性:比简单的微调方法实现更复杂
- 不是所有层都适合:某些特殊层可能不适合低秩适应
- 推理稍复杂:需要额外处理原始模型和适配器的组合
Lora 微调适用场景:计算资源有限、需快速适配新任务(如多任务切换)、追求轻量化模型部署与分享、目标任务和预训练任务存在中等差异、多模态任务场景、需频繁基于新数据迭代优化的场景。
对比和总结
|-------|-----------------|------------------|-------------------|
| 比较指标 | FULL PARAMETER | FREEZE | LORA |
| 参数数量 | 100% 所有参数都参与训练 | 10-50% 仅顶层参数参与训练 | <1% 只训练低秩适配矩阵 |
| 内存消耗 | 高 需要存储所有参数的梯度 | 中 仅需存储部分参数梯度 | 低 只存储少量适配器参数梯度 |
| 训练速度 | 慢 更新所有参数,计算量大 | 中 更新部分参数,速度适中 | 快 仅更新小量参数,速度快 |
| 存储需求 | 高 每个任务需保存完整模型 | 高 仍需保存完整模型 | 低 只需保存小型适配器 |
| 性能上限 | 最高 理论上能达到最佳性能 | 中高 取决于冻结策略 | 中高 接近全参数微调但有差距 |
| 灾难性遗忘 | 高风险 可能丢失预训练知识 | 低风险 底层知识得到保留 | 极低风险 原始参数完全保留 |
| 多任务支持 | 困难 每个任务需要一个完整模型 | 中等 通常仍需一个模型一个任务 | 简单 只需切换适配器都即可切换任务 |
| 实现复杂度 | 简单 直接训练全部参数 | 中等 需要选择冻结策略 | 较复杂 需要实现低秩适配架构 |
各微调方法各有优劣势:全参数微调性能最优但计算资源需求高;参数冻结提供了性能和效率的平衡;LoRA则在极高的参数效率下提供接近全参数微调的性能。选择何种方法应基于具体任务需求,可用资源和性能要求。
模型量化
模型的量化还有蒸馏,其实都是属于模型压缩的常见方法。对于一些大参数模型,比如前段时间非常火的 DeepSeek-R1 满血版具有 6710 亿个参数、最新的 Qwen3 满血版有 2350 亿个参数,它们都是各自公司下的旗舰版模型,具备着最先进的能力。但是由于参数量巨大,普通的小公司或者个人想要在本地部署模型需要的成本是非常高的,所以我们一般会选择使用量化、蒸馏这些手段对模型进行压缩,从而在损失一定精度的情况下减小模型的部署成本。
模型量化是一种通过降低权重和激活值的精度来减小模型尺寸、加快推理速度,同时尽量保持模型准确率的技术。简单来说,就是用更少的数字位数来表示模型中的数据。
通俗理解:想象一下从无损音乐(FLAC)到压缩音乐(MP3)的转换。无损音乐就像 FP32 模型,保存了所有细节,但文件很大。MP3 就像量化后的INT8模型,牺牲了一些人耳难以察觉的细节,但大幅减小了文件体积。不同的比特率 (320kbps、128kbps等) 就像不同等级的量化 (INT8、INT4等) 。
大模型本质上是由很多参数构成的,比如 DeepSeek-R1 满血版具有 6710 亿个参数。大模型通常是基于深度学习的神经网络架构,由大量的神经元和连接组成。这些参数主要包括神经元之间的连接权重以及偏置项等。在模型的训练过程中,这些参数会通过反向传播算法等优化方法不断调整和更新,以最小化损失函数,从而使模型能够学习到数据中的规律和特征。而在计算机中,这些参数是以数字的形式存储和计算的,通常使用浮点数(如单精度浮点数 float32 或双精度浮点数 float64)来表示,以在精度和计算效率之间取得平衡。
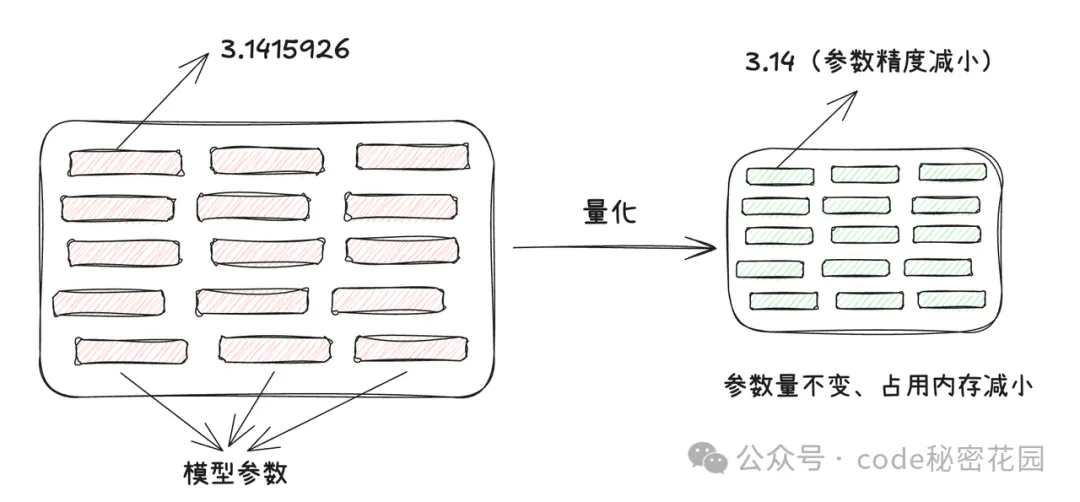 为了表示这些参数,我们需要在计算机上开辟一些内存空间,开辟多大的内存空间就取决于这些参数存储的精度。如果参数的精度越低,所需的内存空间就越小,反之参数精度越高,所需内存空间就越大。比如我们把原本存储了 7 位小数的一个参数:3.1415926,转换成一个精度更低的值:3.14 来进行存储,很明显我们丢掉的精度仅仅为 0.0015926 ,但是我们却大大节省了存储空间,模型量化的本质其实就是把模型的参数从高精度转换成低精度的过程。
为了表示这些参数,我们需要在计算机上开辟一些内存空间,开辟多大的内存空间就取决于这些参数存储的精度。如果参数的精度越低,所需的内存空间就越小,反之参数精度越高,所需内存空间就越大。比如我们把原本存储了 7 位小数的一个参数:3.1415926,转换成一个精度更低的值:3.14 来进行存储,很明显我们丢掉的精度仅仅为 0.0015926 ,但是我们却大大节省了存储空间,模型量化的本质其实就是把模型的参数从高精度转换成低精度的过程。
常用的精度单位有:
- FP:浮点(Floating Point),如 FP16、FP32,可以理解为科学计数法表示的数字,包含符号位、指数部分和尾数部分;优点:可表示范围广,精度高、缺点:占用空间较大。
计算机底层使用的是二进制存储(也就是只能存0 和 1)这里的 16、32 是二进制位数(bit),也就是计算机存储这个数时用了多少个 0 和 1。比如 FP32 就是用 32 个二进制位(4 字节,1 字节 = 8 位) 存一个浮点数。FP16 就是用 16 个二进制位(2 字节) 存一个浮点数。 - BF:脑浮点(Brain Floating Point),如 BF16,专为深度学习设计的浮点数格式,相比传统浮点数,在保持数值范围的同时减少精度,平衡了精度和范围的需求,兼顾精度与效率。
- INT:整数(Integer),如 INT8、INT4,用整数表示权重和激活值,压缩模型体积并加速推理。优点:结构简单,占用空间小、缺点:表示范围有限,精度丢失较多。
常见的模型参数的精度:
- FP32(单精度):32 位 = 1 位符号 + 8 位指数 + 23 位尾数,能够表示的精度范围是:±3.4×10³⁸ ;
- FP16(半精度):16 位 = 1 位符号 + 5 位指数 + 10 位尾数,能够表示的精度范围是: ±65,504;
- BF16(脑浮点):16 位 = 1 位符号 + 8 位指数 + 7 位尾数,范围与 FP32 相同(±3.4×10³⁸),但尾数更短;
- INT8:8 位二进制,有符号范围 - 128~127,无符号 0~255;
- INT4:4 位二进制,有符号范围 - 8~7,无符号 0~15。