作者:无哲、言合
一、前言:Dify 的规模化挑战

Dify 是当前最受欢迎的低代码 LLM 应用开发平台之一,在 Github 上已斩获 120k+ 的星标数。国内外有众多企业基于 Dify 构建自己的智能体应用。阿里云可观测团队既是 Dify 的深度用户,也是社区的活跃贡献者。
在大规模生产实践中,我们发现 Dify 在高负载场景下面临显著的数据库性能瓶颈:其执行引擎高度依赖 PostgreSQL,单次 Chat 请求可能触发数百甚至上千次数据库访问;与此同时,Worker 进程在知识库索引构建、Trace 追踪等任务中也会持续写入大量数据。这频繁导致 DB 连接池打满、慢查询频发 等问题,已成为制约 Dify 集群横向扩展与并发能力的关键瓶颈。
二、现状与挑战:Dify 存储机制痛点分析
数据分布现状
Dify 的数据主要分为三类:
- Meta类 数据:租户、应用、工作流、工具等配置信息;
- 运行时日志:工作流执行明细、会话历史、消息记录等;
- 文件类数据:用户上传文件、知识库文档、多模态输出等(通常存于对象存储)。
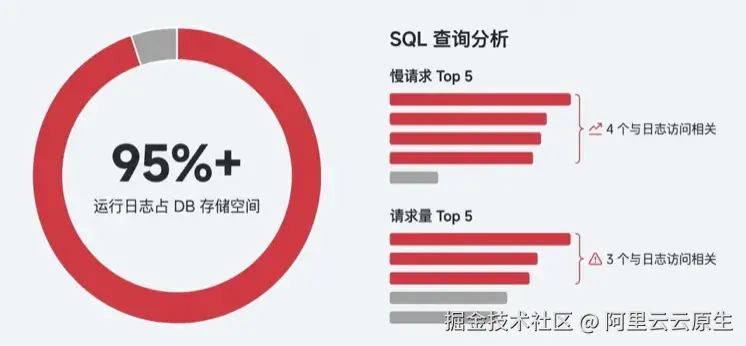
其中Meta 与运行日志均存储在 PostgreSQL 中,运行时日志占据了数据库的绝大部分资源。以我们的生产环境为例,运行日志占 DB 存储空间的 95%以上。在访问频率最高和慢查询最多的 SQL 模式中,绝大多数都与运行日志的读写相关。
Dify 的运行日志包含工作流的执行明细记录和会话消息数据,执行记录中有工具输出、模型上下文等大量长文本信息,并且运行日志数量也会随着用户请求快速增长。
核心痛点
将这类海量、高吞吐的日志数据全量存储在 PostgreSQL 中,带来了多重挑战:
- 负载压力大: Workflow 节点的每次执行都会产生明细日志(节点执行明细数据,记录节点的输入输出和运行状态等数据),高并发下
workflow_node_executions表的读写极易成为热点。 - 连接占用: 尽管 Dify 1.x 的几个版本对数据库长连接问题做了很多优化(如 issue #223071),但日志密集访问仍加剧连接池压力,影响核心业务的连接获取。
- 扩展性不足: 运行日志随着业务量呈爆发式增长,而 PG 扩容依赖垂直升配,升级规格往往伴随主备切换导致的连接闪断或维护窗口,难以实现完全的无感扩容。社区已有多个反馈(如 issue #18800 2因会话数据堆积导致首 Token 延迟增加 3 秒; issue #22796 3呼吁将日志迁出 PG)
- 分析加工能力缺失: 控制台仅支持有限关键词检索,难以满足业务对历史会话进行多维分析、二次加工及精细化运营的需求。
社区的积极探索与演进
运行日志存储一直是影响 Dify 系统性能与稳定性的痛点。针对这一问题,社区一直在积极寻求解决方案,并已落地了多项优化措施:
- 内存数据库(issue #201474):适用于无需持久化的轻量场景,同时新版执行引擎已完成日志存储抽象,为后续异构存储改造奠定了基础。
- 后台异步执行( issue #200505):通过 Celery Worker 异步写入日志,有效降低了核心链路的延迟,减轻了 API 引擎对 DB 的同步依赖。
- 周期性清理( issue #233996):引入自动清理机制,定期移除陈旧的会话与执行记录,有效缓解了数据库存储膨胀问题。
- 大字段分离存储: 针对 LLM 长上下文导致的大字段问题,支持将超长字段截断并转存至对象存储,减轻了 DB 的 I/O 压力。
根因分析:数据特征与存储引擎的错配
上述优化在特定阶段非常有效,缓解了 Dify 的燃眉之急,但在大规模生产场景下,应用层的逻辑优化(异步、清理等)已触及天花板。要彻底解决扩展性问题,必须消除数据特征与存储引擎的错配------即我们一直在试图用"关系型数据库"去承载本该由"日志系统"处理的数据。
Dify 工作流记录虽然并非完全是Append-Only写,但具有鲜明的日志特征,与典型的业务数据(如用户信息、应用配置)截然不同:
- 终态不可变: 记录仅在执行期短暂流转,结束后即成为"只读"档案。在 PG 中长期留存海量只读数据,不仅挤占昂贵的 SSD 资源,庞大的表数据更会显著降低索引效率与查询性能。
- 泛结构化与 Schema 易变: 核心负载为巨大的 JSON 对象(每个工作流节点的Inputs/Outputs),且结构随版本迭代。PG 难以高效处理深层 JSON 检索,且亿级大表的 DDL 变更会引发长时间锁表风险。
- 高吞吐时序写入: 日志随时间源源不断地产生,持续消耗 IOPS 与数据库连接。请求高峰期极易导致连接池耗尽,导致创建应用等核心业务因资源争抢而失败。
因此,我们需要一种支持存算分离、弹性伸缩、低成本且具备原生 OLAP 能力的存储架构。阿里云日志服务(SLS) 凭借其云原生特性,成为解决这一瓶颈的最佳选择。
三、方案选型:为什么 SLS 更适合 Dify 日志场景
SLS 并不是"另一个数据库替代",它是为日志场景量身定制的基础设施。在Dify工作流日志场景下,相比于 PG,SLS 在以下四个维度实现了架构上的优化升级:
极致弹性,应对流量波动
Dify 业务常有突发流量(如 AI 推理高峰)。PostgreSQL 需按峰值预置硬件资源,低谷期的资源浪费,一旦流量突增超过预设上限,数据库稳定性会有问题。
而SLS 作为 SaaS 化云服务,天然支持秒级弹性伸缩,无须关心分片或容量上限,且默认支持 3AZ 同城冗余。
高写入吞吐 + 架构解耦,保障核心稳定
- 高并发写入: SLS 针对日志场景优化,数据以追加方式顺序写入,避免了数据库中常见的随机 I/O 和锁竞争,能以极低成本支撑数万 TPS 的写入吞吐,轻松应对 AI 业务的写入洪峰。
- 资源隔离: 将日志负载剥离至 SLS 云端,实现日志数据流与 Dify 核心业务事务的物理隔离,有效保障主业务系统的稳定性与性能。
海量日志,低成本长期留存
SLS 数据采用高压缩比技术,支持自动化分层存储,可将历史数据自动沉降至低频和归档存储,无需维护清理脚本,成本远低于数据库 SSD。这使得 Dify 能以极低的成本满足长周期的分析和审计需求。
开箱即用的数据价值释放能力
- Schema-on-Read: SLS 写入时不强制校验 Schema,完美适配 Dify 快速迭代带来的字段变更,无需对历史数据重新变更。
- 秒级分析: SLS 内置了针对日志优化的分析引擎(倒排索引+列存)。开发者可以使用关键词从海量日志中检索,也可以利用 SQL 对亿级日志进行实时聚合分析,将日志数据转化为业务洞察。
- 丰富数据生态: 日志在SLS中,可以进一步进行更完善的处理和分析,比如数据加工清洗、联合分析、可视化、告警、消费和投递等等。
四、技术实现:核心架构改造与插件化
为了将 SLS 引入 Dify,整个工程实施分为两个部分:一是对 Dify 核心的插件化改造,二是基于 SLS 读写日志的插件实现。
1.Dify 核心插件化改造
Dify 早期架构中,工作流记录的读写逻辑深度耦合了 SQLAlchemy(PG ORM),扩展性受限。从 v1.4.1 以后社区引入了 WorkflowExecution 的领域模型(#200677)并开始逐步对工作流执行核心流程进行重构,定义了一套标准的 Repository 接口,涵盖日志的写入、更新、读取以及统计等标准行为。在 v1.8.0 社区引入了 Repository 的异步实现,通过推迟日志记录保存提升了工作流执行速度。
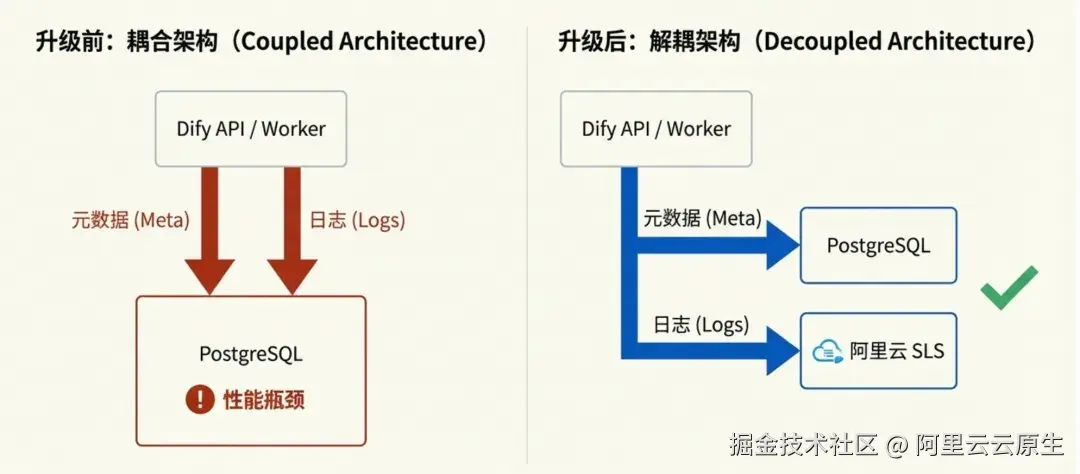
虽然 Repository 接口为多存储驱动提供了可能,但早期的抽象并不彻底:它主要解决了"写"的抽象,但大量"读"操作仍绕过 Repository 直接依赖 SQLAlchemy,且复杂的跨表 Join 查询使得存储层难以真正剥离。
为此,我们和 Dify 研发团队多次交流,确定了 Repository 抽象层的完整实现方案。我们通过剥离跨表关联查询、标准化读取与统计接口,真正实现了存储层的完全解耦与插件化加载。
2.SLS 日志插件实现
在插件实现过程中,核心挑战在于抹平关系型数据库(PG)与日志系统(SLS)在数据模型上的差异。为此,我们采用了以下技术策略:
基于多版本的状态管理
SLS 的 LogStore 是 Append-Only 追加写入,而Dify 的工作流执行过程存在状态流转,从 RUNNING 变为 SUCCEEDED/FAIL。因此我们采用了多版本控制的思路:
- 写入策略:每次状态更新,不覆盖旧日志,而是新写入一条包含完整状态的日志记录。我们在日志模型中引入了一个纳秒级的时间戳字段
log_version来区分版本。 - 读取策略:在查询或统计时,插件内部会生成聚合 SQL,对于同一个
workflow_run_id,始终选取log_version最大的那条记录作为最终状态。
Schema 自动同步
Dify 的迭代速度非常快,数据库模型经常发生变更。如果每次升级 Dify 都需要用户手动维护索引配置,将极大地增加运维负担。SLS 插件启动时会自动扫描 SQLAlchemy 模型定义,并与 SLS 索引配置进行 Diff。一旦发现新字段,自动调用 API 更新索引。用户无需手动维护索引,开发者也无须为 SLS 单独编写升级脚本。
原生 PG 协议兼容
值得一提的是,SLS 新增原生支持 PostgreSQL 协议。绝大部分原有的统计与分析 SQL,均可通过 PG 兼容模式直接发送到 SLS 上执行,极大地降低了插件的开发适配成本。
五、实践指南:配置与平滑迁移
该功能已正式合并至 Dify 社区主分支。基于Dify最新代码,只需进行简单配置,就可以将工作流执行记录切换到SLS存储。
第一步:准备工作
(1)创建 Project:在阿里云日志服务控制台创建 Project(建议与业务同地域)
无需手动创建 Logstore 和索引,Dify 启动后插件会自动检测并创建。
(2)获取访问凭证:获取具备 SLS 读写权限的 AccessKey ID 和 Secret。
可以授予
AliyunLogFullAccess,或按需配置最小权限(创建/查看Project、创建/查看logstore、创建/更新/查看索引、写日志、查日志等)
第二步:配置Dify
在 .env 或 docker-compose.yaml 中修改以下配置项,将工作流存储驱动指向 SLS 插件,并补充连接信息:
ini
# 1. 修改 Repository 驱动指向 SLS 插件
CORE_WORKFLOW_EXECUTION_REPOSITORY=extensions.logstore.repositories.logstore_workflow_execution_repository.LogstoreWorkflowExecutionRepository
CORE_WORKFLOW_NODE_EXECUTION_REPOSITORY=extensions.logstore.repositories.logstore_workflow_node_execution_repository.LogstoreWorkflowNodeExecutionRepository
API_WORKFLOW_NODE_EXECUTION_REPOSITORY=extensions.logstore.repositories.logstore_api_workflow_node_execution_repository.LogstoreAPIWorkflowNodeExecutionRepository
API_WORKFLOW_RUN_REPOSITORY=extensions.logstore.repositories.logstore_api_workflow_run_repository.LogstoreAPIWorkflowRunRepository
# 2. 新增 SLS 连接配置
ALIYUN_SLS_ACCESS_KEY_ID=your_access_key_id
ALIYUN_SLS_ACCESS_KEY_SECRET=your_access_key_secret
ALIYUN_SLS_ENDPOINT=cn-hangzhou.log.aliyuncs.com
ALIYUN_SLS_REGION=cn-hangzhou
ALIYUN_SLS_PROJECT_NAME=your_project_name
ALIYUN_SLS_LOGSTORE_TTL=365 # 日志存储天数
# 3. 迁移开关配置
LOGSTORE_DUAL_WRITE_ENABLED=false
LOGSTORE_DUAL_READ_ENABLED=true为了保证存量 PG 用户能平滑升级到 SLS 版本,我们在插件中提供了两个开关:
(1)双写机制:通过配置 LOGSTORE_DUAL_WRITE_ENABLED=True(默认关闭),系统会将日志同时写入 PG 和 SLS。这适用于存量用户迁移初期的灰度验证,确保在不改变原有数据流的情况下,验证 SLS 的配置正确性和 Dify 版本升级本身的兼容性。
(2)双读降级机制:通过配置 LOGSTORE_DUAL_READ_ENABLED=True(默认开启),系统优先从 SLS 读取日志。如果 SLS 中未找到该记录(例如迁移前的老历史数据),插件会自动降级回 PG 再次尝试读取。
六、成效对比:迁移到SLS的三大收益
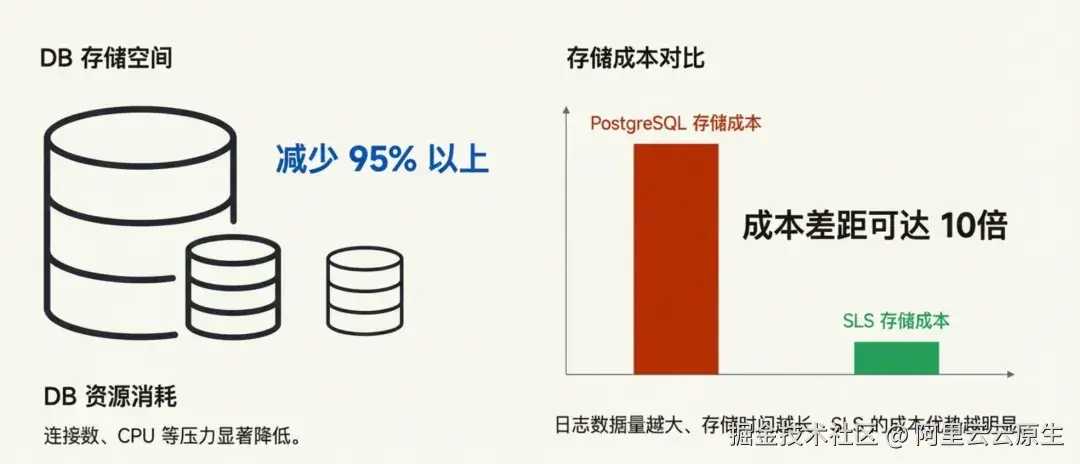
收益一:DB压力显著下降
切换到SLS,相当于把现有PG中数据量最大的两张表的数据迁移走了。根据我们线上业务的数据,DB减少了95%以上的存储空间(运行时间越长,这个比例越高),并且读写过程中的DB的连接数、CPU等压力也有显著降低。
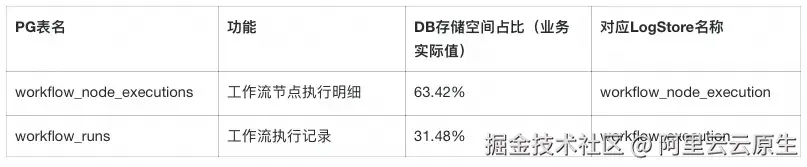
收益二:存储成本大幅降低
为了直观量化迁移后的成本收益,我们以一个典型的生产级场景进行估算:假设 Dify 应用日增日志 10GB,为了满足模型评估与回溯需求,需留存最近 300 天(约 3TB)的数据。
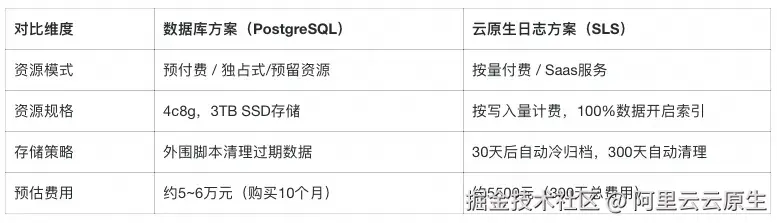
注:这里估算SLS成本的时候,已经将存多条状态记录会占用存储空间的因素考虑进去。 此外对于PG实际生产中还需额外考虑高可用多副本、预留存储空间、连接池扩容等隐性成本。
这里造成近 10 倍成本差距 的根本原因在于存储机制的不同。
Dify的工作流记录包含了用户提问、知识召回、工具调用和模型响应等数据,是评估和回归等任务需要的数据资产,长期留存价值高。
- 对于 PG: 存储时间越长,数据量越大,对昂贵的 SSD 存储空间占用就越多,成本会大幅增长。pg实例需要提前预估存储空间,存储空间不可能完全利用起来,必然闲置一部分空间。
- 对于 SLS: 专为日志设计的高压缩比与分层存储技术,使得存储数据量越大、时间越长,其边际成本优势越明显。
收益三:数据价值释放,从"运维监控"到"业务洞察"
这里我们以一个真实的 Dify 应用场景------"电商智能客服助手"为例,展示日志数据接入 SLS 后,如何挖掘其背后更大的业务价值。

(1)无缝集成,原生体验
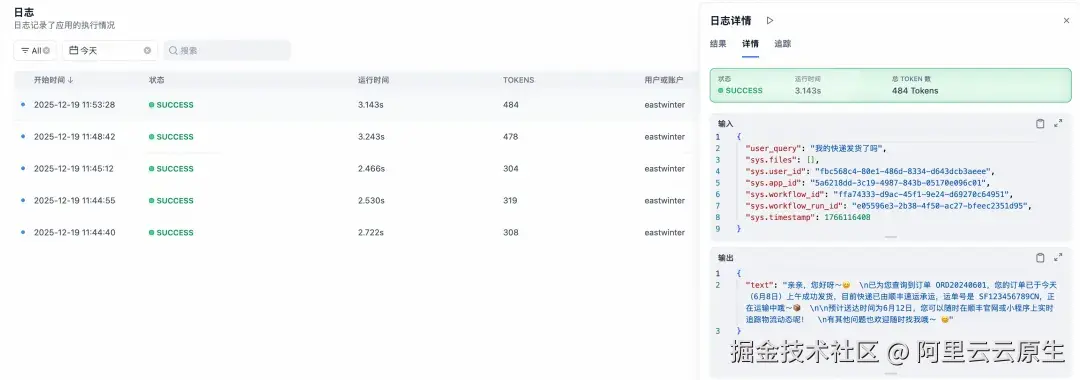
接入 SLS 后,Dify 界面上的日志查询与回溯体验保持不变,但底层存储已完全切换。
- 日志回溯:Dify 控制台的日志详情页直接从 SLS 读取数据,响应更迅速。
- 监控图表:Dify 内置的监控统计图表,也是通过执行 SLS SQL 实时生成的。
(2)超越基础,SLS 进阶分析
虽然 Dify 内置了基础查询和统计功能,但面对复杂的业务分析需求,我们可以直接转至 SLS 控制台,解锁更强大的能力。
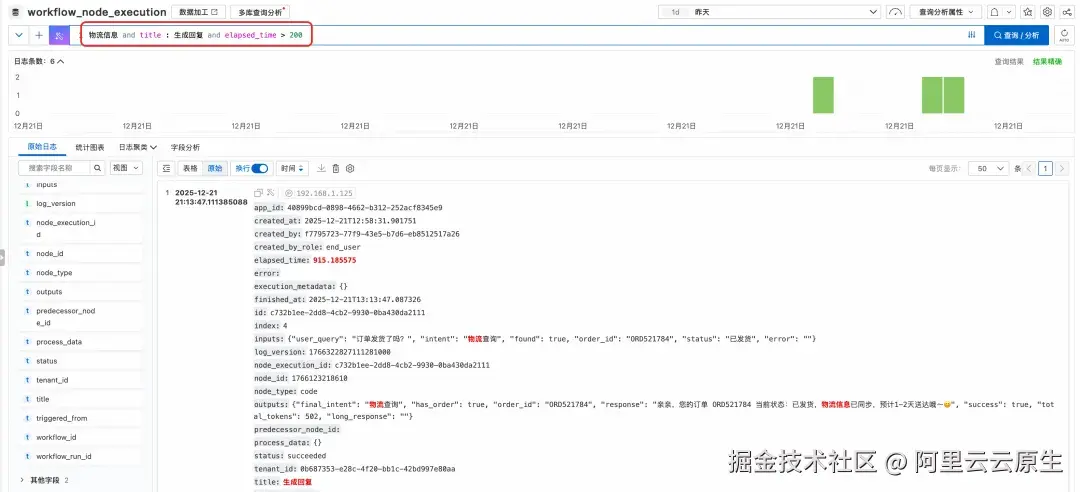
- 任意字段的高速检索
SLS 支持全文索引和任意键值对条件的组合查询,快速精准检索出符合某种特定特征的日志。
- 业务趋势分析(可视化)场景
比如这里我们分析"用户意图识别"这个工作流节点里,按识别出的用户意图的分类统计随时间变化的PV情,便于通过观察不同分类的趋势变化,做出相应的运营决策。
sql
* and title: 用户意图识别 and intent | select json_extract(outputs, '$.intent') as "用户意图", date_trunc('minute', __time__) t, count(1) as pv group by "用户意图",t order by t limit all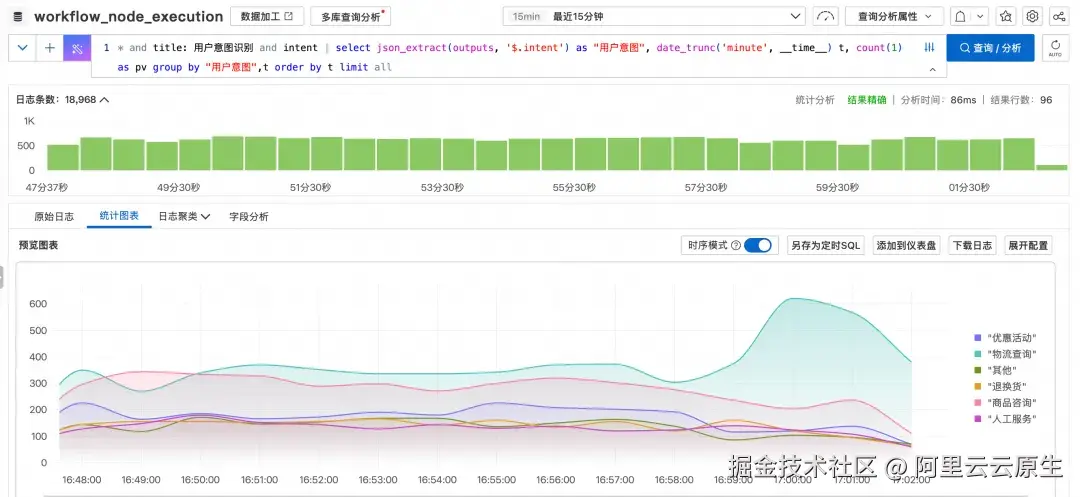
- 异常诊断(漏斗分析)场景
可以通过漏斗图,分析观察工作流哪些中间节点出现异常失败的比率较高。
vbnet
status:succeeded | select title, count(distinct workflow_run_id) cnt group by title order by cnt desc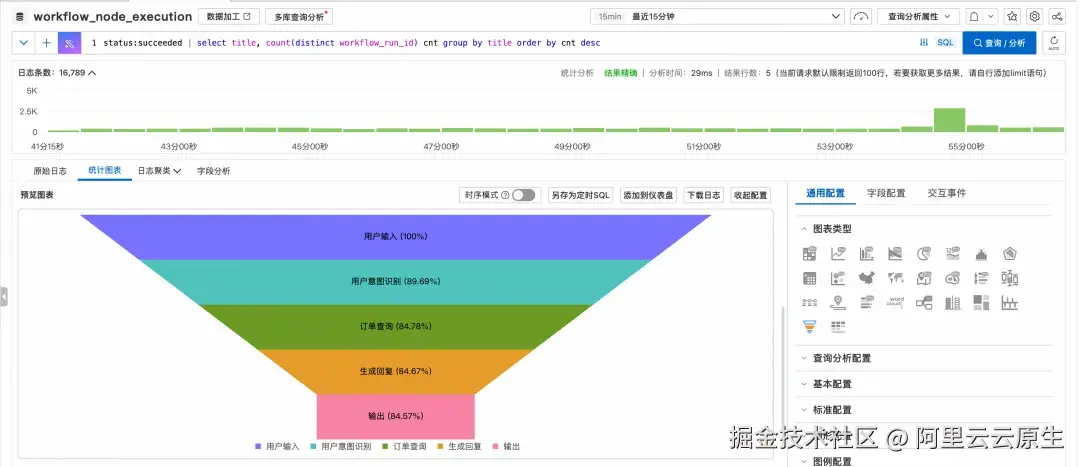
- 成本与风险风控(实时告警)场景
配置告警规则,统计 LLM 节点的 Token 消耗,一旦超过预设阈值,立即触发钉钉/电话告警。

- 数据闭环(ETL 与加工)场景
利用数据加工和定时 SQL,对工作流的输入输出进行清洗、脱敏与标准化,构建持续更新的评估与训练数据集。
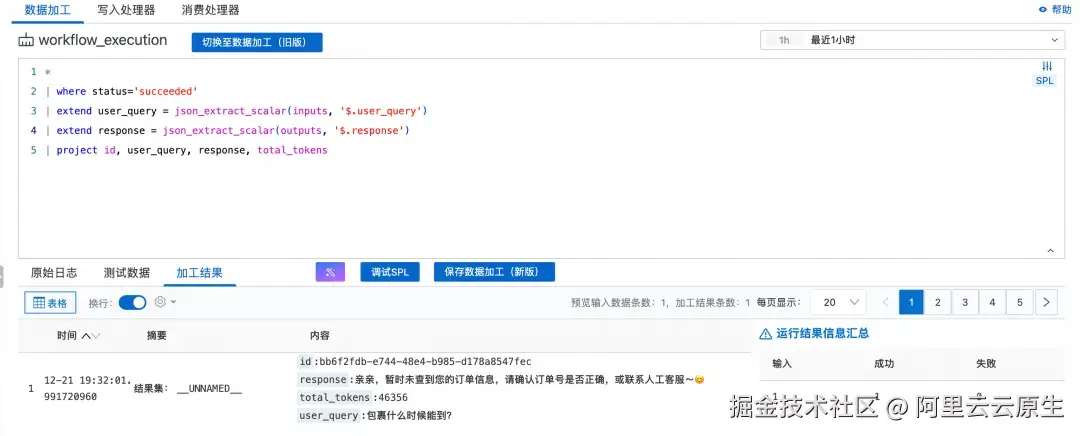
总之,将 Dify 工作流日志接入 SLS,不仅能高效查询日志,更能通过分析、可视化、告警和数据加工,将日志转化为业务洞察,真正实现从"看日志"到"懂业务"的跃升。
七、总结:迈向生产级 AI 架构
将 Dify 运行日志迁移至阿里云 SLS,并非一次简单的"存储替换",而是 Dify 向生产级高可用架构演进的关键一跃。
我们通过业务数据与日志数据解耦的架构改造,成功将高吞吐、泛结构化的日志流从事务型数据库中剥离。让 PostgreSQL 专注核心业务事务处理,让 SLS 充分发挥其在海量数据存储与分析上的原生优势。
这一特性带来的价值是全方位的:
- 解决DB性能瓶颈: 将日志与核心事务解耦,从根本上解决数据库瓶颈,保证核心业务稳定性。
- 大幅降低日志成本: 利用SLS的弹性伸缩、高压缩比、分层存储,低成本存储海量日志。
- 充分释放数据价值: 从简单的日志查看升级为强大的实时分析、监控告警、加工处理,将运维数据转换为业务洞察。
如果您正在构建大规模的 AI 应用,或者正被 Dify 数据库的性能瓶颈所困扰,现在就是升级的最佳时机。拥抱云原生日志架构,让您的 Dify 跑得更快、更稳、更智能。
参考链接: