背景
最近接到任务,要使k8s集群支持调度GPU,我对硬件资源不是很懂,大概看了看官方,简单梳理了一下思路,便开始了踩坑之路(本片文章是无坑文档,请放心使用/参考)
前提条件:
对于实验学习而言,在k8s集群中,至少保证1台node节点是有显卡的(本文是NVIDIA),其他品牌显卡请出门右转自行Google
集群环境说明:
本文是学习实验环境,所以只有
ai-gpu-flask2.novalocal支持GPU,其余的节点都是虚拟机。最终验证也是在ai-gpu-flask2.novalocal上进行。
| 系统 | 名称 | 角色 | k8s版本 |
|---|---|---|---|
| centos7.6 | ai-gpu-flask2.novalocal | worker | kubeadm v1.16.8 |
| centos7.6 | master | etcd,master | kubeadm v1.16.8 |
| centos7.6 | node1 | worker | kubeadm v1.16.8 |
| centos7.6 | node2 | worker | kubeadm v1.16.8 |
预安装
- 本步骤在支持
GPU节点上执行 - 参考链接:https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#introduction
要验证您的 GPU 是否具有 CUDA 功能,请转至与您的发行版等效的"系统属性",或者在命令行中输入:
bash
$ lspci | grep -i nvidia
00:06.0 3D controller: NVIDIA Corporation TU104GL [Tesla T4] (rev a1)要确定您正在运行的发行版和发行版号,请在命令行中键入以下内容:
bash
$ uname -m && cat /etc/*release要验证系统上安装的gcc版本,请在命令行中键入以下内容:
bash
$ gcc --version可以通过运行以下命令找到系统正在运行的内核版本:
bash
$ uname -r当前运行的内核的内核头文件和开发包可以通过以下方式安装:
bash
$ sudo yum install kernel-devel-$(uname -r) kernel-headers-$(uname -r)选择您正在使用的平台并下载 NVIDIA CUDA Toolkit
bash
$ wget http://developer.download.nvidia.com/compute/cuda/10.2/Prod/local_installers/cuda-repo-rhel7-10-2-local-10.2.89-440.33.01-1.0-1.x86_64.rpm
$ sudo rpm -i cuda-repo-rhel7-10-2-local-10.2.89-440.33.01-1.0-1.x86_64.rpm
$ sudo yum clean all
$ sudo yum -y install nvidia-driver-latest-dkms cuda
$ sudo yum -y install cuda-drivers要安装显示驱动程序,必须首先禁用 Nouveau 驱动程序:
在以下位置创建文件
bash
$ vim /etc/modprobe.d/blacklist-nouveau.conf
# 具有以下内容:
$ blacklist nouveau
$ options nouveau modeset=0重新生成内核initramfs:
bash
$ sudo dracut --force验证
bash
# 正常来说会输出已经安装过的程序
$ rpm -qa | grep nvidia
# 正常来说会输出已经安装过的程序
$ rpm -qa | grep cuda满足先决条件
- 阅读文档:https://github.com/NVIDIA/k8s-device-plugin#prerequisites
- 说明:该文章中描述了安装
k8s-device-plugin的先决条件
- 说明:该文章中描述了安装
- 条件一 NVIDIA drivers ~= 384.81 已经满足
- 条件四 Kubernetes version >= 1.10 已经满足
先决条件准备
- 满足
条件二nvidia-docker version > 2.0 - 参考链接:https://github.com/NVIDIA/nvidia-docker#centos-7-docker-ce-rhel-7475-docker-ce-amazon-linux-12
bash
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
$ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
$ sudo yum install -y nvidia-container-toolkit
$ sudo systemctl restart docker- 满足
条件三docker configured with nvidia as the default runtime. - 参考链接:https://github.com/NVIDIA/k8s-device-plugin#preparing-your-gpu-nodes
bash
$ vim /etc/docker/daemon.json
json
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}验证
bash
$ docker run --gpus all nvidia/cuda:10.0-base nvidia-smi
# 报错如下:
docker: Error response from daemon: OCI runtime create failed: unable to retrieve OCI runtime error (open /run/containerd/io.containerd.runtime.v1.linux/moby/36cd5b1383a3ca5d2196d05e3655122ea4703af69bdfedfdfc6657f/log.json: no such file or directory): fork/exec /usr/bin/nvidia-container-runtime: no such file or directory: unknown.
ERRO[0000] error waiting for container: context canceled- 解决办法
bash
$ yum search nvidia-container-runtime
$ yum -y install nvidia-container-runtime.x86_64 nvidia-container-runtime-hook.x86_64再次验证
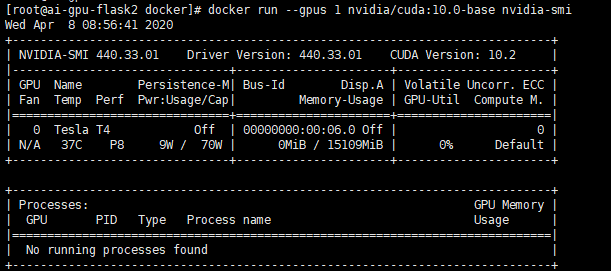
bash
$ docker run --gpus all nvidia/cuda:10.0-base nvidia-smi至此,docker环境下使用GPU已经完成,接下来部署k8s-device-plugin使k8s也支持GPU
参考链接:https://github.com/NVIDIA/k8s-device-plugin#enabling-gpu-support-in-kubernetes
bash
$ kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/1.0.0-beta5/nvidia-device-plugin.yml验证
通过命令kubectl describe node ai-gpu-flask2.novalocal可以看到node节点有ncidia.com/gpu就正常了
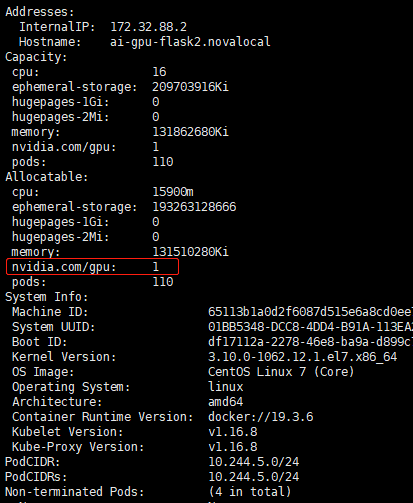
运行一个pod
yaml
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: cuda-container
image: nvidia/cuda:9.0-devel
resources:
limits:
nvidia.com/gpu: 2 # requesting 2 GPUs
- name: digits-container
image: nvidia/digits:6.0
resources:
limits:
nvidia.com/gpu: 2 # requesting 2 GPUs结束语
经过两天踩坑到填坑的魔鬼历程,才有了这篇无坑文章,大家且用且珍惜。
GPU的学习成本较高,普通的虚拟机是不可能完成这个实验操作的,如果你看到了这篇文档,不妨先收藏一下,日后如果有需求,可以第一时间拿出来参考。