**【本节概括】**个性化检索是指考虑了用户的区别,利 用用户的个性信息对检索结果进行修改或者过滤处 理,以减轻用户的检索复杂度。本节主要从个性化的角度,讨论如何更精准地提供信息服务。
目录
[3.1 基于内存(Memory-based)](#3.1 基于内存(Memory-based))
[3.2 基于模型](#3.2 基于模型)
一、前言
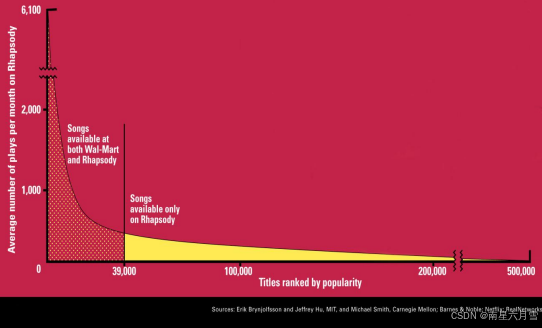
个性化服务的背景是信息从稀缺到过剩的发展趋势。简单的统计能够反映一定的趋势,但受长尾现象的影响。
【长尾现象】指 互联网、商业、数据领域中普遍存在的一种需求 / 分布规律 ,核心是:少数 "热门" 事物(头部)占据了大部分短期关注,但大量 "小众" 事物(尾部)的总价值 / 需求量,加起来能与头部相当甚至超过头部。
个性化检索问题的数学定义如下:
- 基本要素:三个集合,一个函数(效用函数)
- X,用户集合;S,项目集合;R,评分集合
- R是一个由有序元素组成的集合,例如,豆瓣的0-5星,0,1区间内的实数等
- 基于各个集合,定义效用函数如右:u: X × S → R
如果把 X 和 S 的关系用矩阵表示,那么评分集合 R 可看成一个 M * N 维的矩阵,对应 M 个用户,N 个项目。矩阵中的每个元素对应着相应 的用户对项目的评分。
其中有几个关键问题:
1. 收集"已知"的评分信息,生成效用矩阵(R):如何收集数据?没有显式评分数据的情况如何处理?
收集数据分为显示数据(可直接获得的用户评价数据,常通过用户标注的方式获得,例如众包(Crowdsourcing),如果来源可靠则效果较好,但往往难以获得)和隐式数据(基于用户行为等信息,间接地判断用户的倾向性,例如,在先前介绍的间接相关性反馈,如点击历史、浏览购买记录、停留时间等,但难以保证负样本的质量)。
2. 基于已知评分,推断未知评分:着重关注高分元素:我们更关注你喜欢什么
推断未知评分的挑战在于效用矩阵 R 的严重稀疏性,用户的行为是有限的,而且活跃用户及其稀少。与此同时,新用户没有行为历史,难以判断偏好,新项目没有评分记录,难以作为参考。
3. 推荐结果的评估:如何有效评估个性化算法的效果,并比较不同算法?
效果的评估,取决于问题的定义。基本定义方式:用户评分预测,即预测指定用户对指定项目的打分,常用均方根误差。但还有其他方式,比如说:
视作分类问题,即推荐正确/错误。一种情况为0/1效用矩阵,或基于某个阈值进行推荐,此时为完全二分类,可通过Precision/Recall/F值等评估。另一种情况为排序后返回Top N结果,此时可通过Pre@N,Rec@N等评估,注意理论上限可能不为1。
视作排序问题,即推荐项目的相关性程度。因为用户对于不同项目的接受/喜爱程度不同,所以可基于预测评分对项目进行排序,然后采用排序评估方式进行评估。如果只关注推荐的准确性,则可能受到一定的误导,在有些情况下,例如音乐的播放序列,推荐的顺序值得研究。
在现实中,我们更关注获得高分的预测内容,但推荐的多样性同样重要。
二、基于内容的推荐
这种推荐方式的基本想法是用户的偏好一般相对稳定,因此,给用户推荐他/她以前喜欢的项目准没错(偏保守的想法)。它主要包含四个步骤:
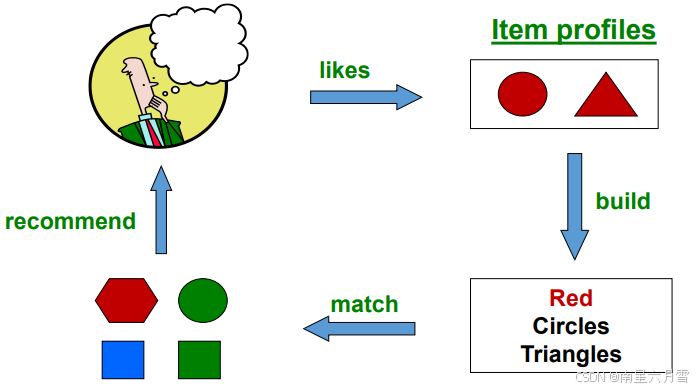
通过对用户与项目画像(也就是用向量的形式概括出特征属性),采用相似性度量进行评分,一般采用两个向量之间的余弦相似度。
这种推荐方式的好处在于每个人的推荐过程相互独立,不需要其他用户的数据。因此,可以为具有独特偏好的用户进行有效推荐,不受大众倾向性和热度的影响。可以推荐新项目或非热门项目。推荐结果也有着较好的可解释性(可列举内容特征给用户作为推荐的依据)。
坏处就是找到合适的特征是一件困难的事,对于非结构化信息,如图像、视频、音频等尤其如此,而且部分特征的提取可能存在误导性(归因错误)。同样,如何给新用户推荐项目,永远是一个困难的任务,并且会存在永远只能给用户推荐局限于其画像中的内容------信息茧房问题,用户的多方面兴趣难以体现,难以通过他人的评价对推荐结果进行评估。
三、基于协同过滤的推荐
基于内容的推荐方案只基于单一用户记录向该用户进行推荐。在实际应用中,我们发现,其他用户的浏览 行为对当前用户有借鉴作用。
如前所述,推荐系统的本质就是矩阵补全问题。相应的,协同过滤的思想在于基于矩阵的其他行,协助填补本行的空缺。大体上,可将协同过滤技术分为以下两大类:
- 基于内存(Memory-based)的协同过滤:基于现有数据与简单度量运算进行推荐
- 基于模型(Model-based)的协同过滤:基于现有数据训练模型,通过模型进行推荐
3.1 基于内存(Memory-based)
**基于用户推荐(User-based CF)**的目的在于找到这些相似用户,并基于这些用户的历史行为进行推荐。相似用户往往被称作"邻居",类似于寻找最近邻的思想。


有些时候,我们不需要考虑所有邻居的评分,而只考虑K-最近邻的情况,也就是取距离最近的 K 个邻居来计算。
从另一个角度,与用户行为相似性类似,相似的项目,往往在大众眼中的评分也比较接近。与基于内容的推荐不同,基于项目 (Item-based)的推荐,其衡量相似项目的标准,并不是项目本身的属性,而是不同项目的评分历史。同一个人给两个项目打出相似分数,说明他认为两个项目相似;越多这样的人, 两个项目越相似。

3.2 基于模型
基于内存的推荐技术,仅对数据进行简单处理,适用于各种数据。然而,数据的稀疏性、计算最近邻的高复杂度,限制了其有效性。与此同时,我们知道,从效用矩阵的视角来看,推荐系统的本质是矩阵补全,那么,矩阵的各个元素是如何生成的?
基本思路:用户对项目的评分,本质上是用户的偏好,与项目的属性之间的 相似度。相似度越高,评分越高。那么,用户的偏好与项目的属性,如何表示?
这里借鉴矩阵分解(Matrix Factorization)的思路,使用潜在因子。
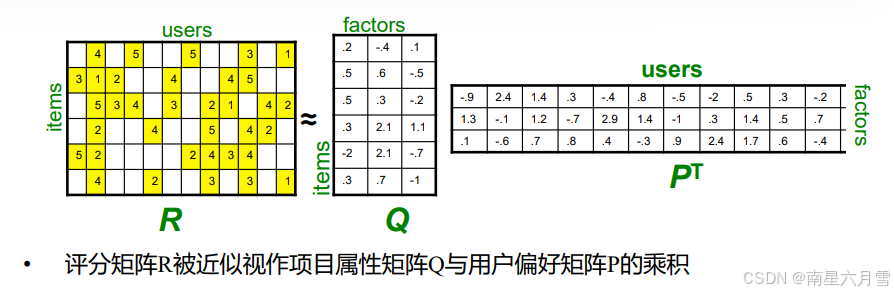
当用户与项目的潜在因子已知,则任何缺失的评分,均可以通过对应的 P、Q矩阵相应的行列运算估计得到。
什么是潜在因子?
我们没法直接用 "用户喜欢什么""项目是什么" 的直白描述(比如 "用户喜欢喜剧""电影是喜剧"),但可以用低维向量间接表示 ------ 这个向量就是 "潜在因子"。
- 比如用 K=2 个潜在因子描述 "电影":因子 1="男性向程度",因子 2="喜剧程度";
- 某电影《疯狂动物城》的潜在因子向量 Q=0.3, 0.9(低男性向,高喜剧);
- 某用户小明的潜在因子向量 P=0.2, 0.8(不太喜欢男性向,很喜欢喜剧);
- 小明对《疯狂动物城》的评分 = P 和 Q 的内积 = 0.2×0.3 + 0.8×0.9=0.78(约 4 星)。
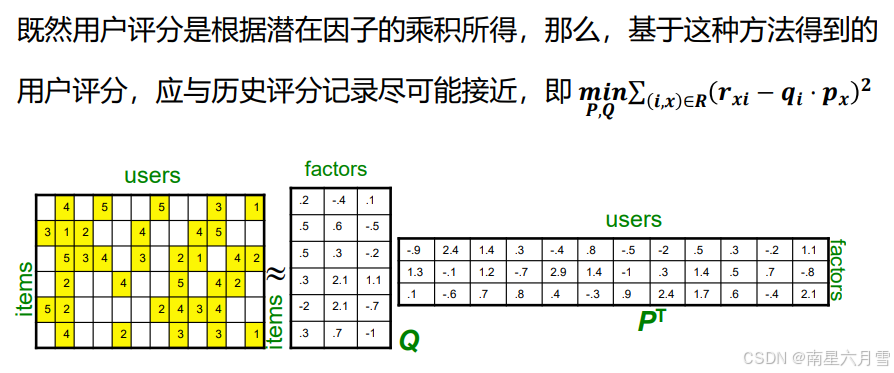
我们的目标正是通过优化这一SSE,以获得潜在因子的估计值。如果潜在因子维度 K 太大,模型会 "死记硬背" 训练数据(比如把偶然的评分误差也学进去),导致对新数据预测不准 ------ 这就是 "过拟合"。
一种思路是引入更多训练数据,但这并非易事。另一种思路则尝试通过"收缩"(Shrinkage)参数的方式来提升泛化性。过拟合问题的本质是对于训练样本的过分迁就,从而影响了模型的泛化能力。相应的,我们的目的在于通过控制参数数值,使其不那么"迁就"训练样本。
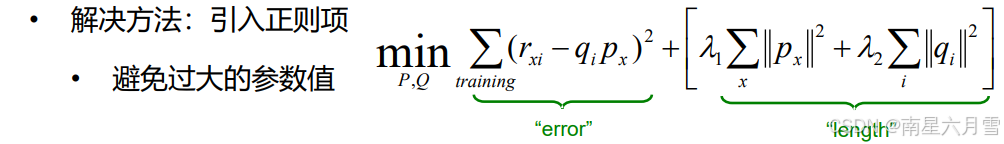
正则化的本质是:在模型训练的目标函数中,加入 "惩罚项",限制模型参数的大小,避免参数异常膨胀,从而让模型学习 "普遍规律" 而非 "偶然噪声"。