深度学习是机器学习的一个子集
机器学习分为两类:
1、监督学习
是最广泛的最常用的
监督学习指的是 x到Y的映射,或者输入到输出的映射算法,监督学习的关键特征是,给学习算法提供包含正确答案的示例,
如房价预测,对于数据是你和一条曲线还是你和一条直线,给定一个新的X输出预测的Y值,这是一个回归的例子,任务是预测一个数字
可以看做聚类,对数据进行分组,输出的种类是有限的
如通过肿块的大小去预测乳腺癌是良性还是恶性
对一个照片进行分类,判断是猫还是狗
分类算法预测类别,类别不一定是数字,也可以是数字,
分类预测的是一个小的,有限的,有限的可能输出类别集合,
监督学习将映射X输出Y 其中学习算法从正确答案中学习,监督学习的两种重要类型是回归和分类,在回归应用中,如预测房价,学习算法必须从无限多的可能输出的数字中预测数值,而分类中,学习算法必须从一个小部分可能得输出中预测一个类别,
2、无监督学习
在无监督学习中我们得到的数据没有与任何输出标签Y相关联的如图
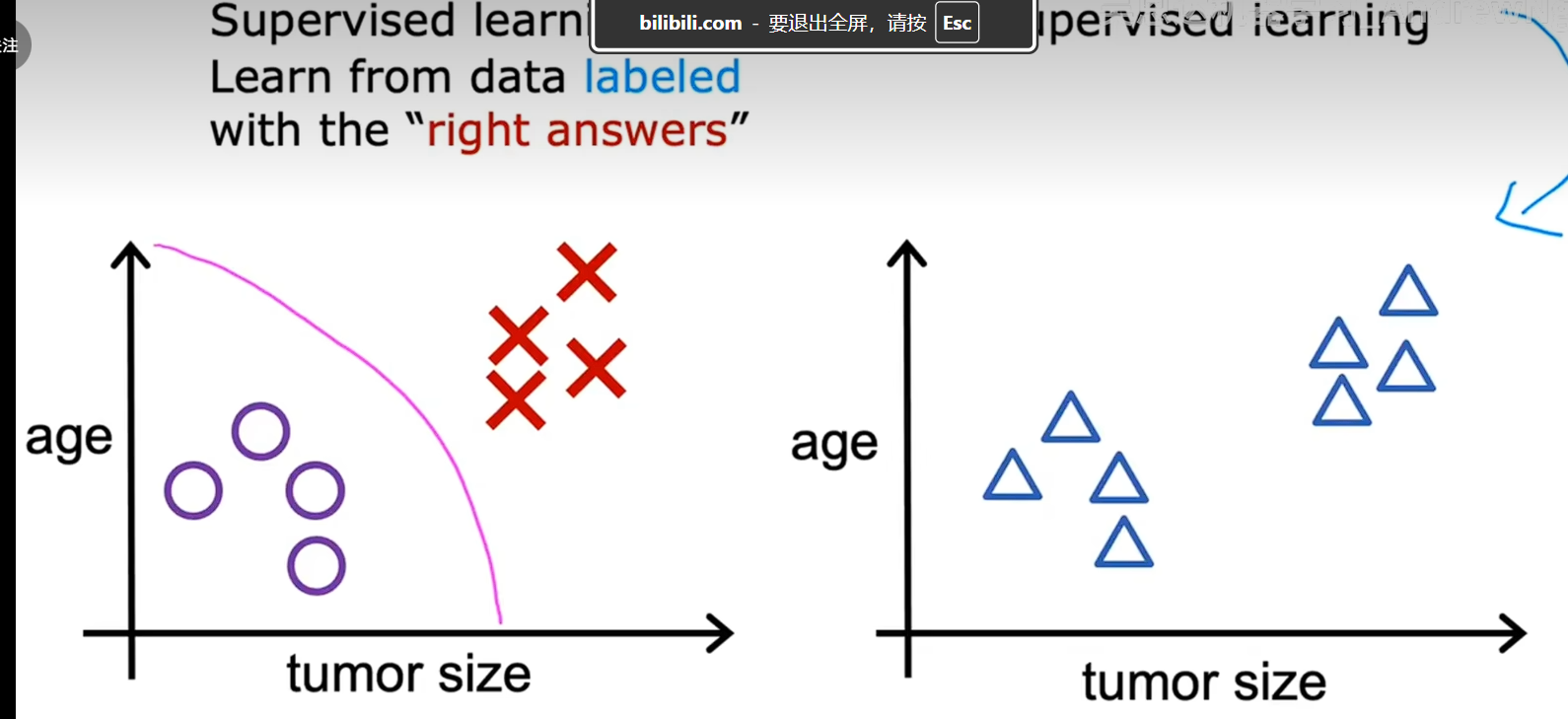
对于左图而言,我们用O表示良性,用X表示乳腺癌是恶性,横轴是肿瘤大小,纵轴是患者年龄,右边的数据没有患者肿瘤是良性还是恶性的信息,,因此呈现了右侧的数据,我们不被要求诊断是良性还是恶性,因为我们没有在数据中找到任何标签Y,相反我们的工作是找到一些结构或者是一些模式,或者只是在数据中发现一些有趣的东西,这就是无监督学习,我们称之为无监督是因为我们不是试图监督算法为每个输入提供正确的答案,相反我们要求算法自己找出数据中可能有趣或者从在的模式或者结构,对于这个特定的数据集,无监督学习算法可能会决定数据可以分配到两个组,或者两个不同的簇中 因此,他决定什么地方有一个组或者簇,这成为聚类算法的无监督学习,因为他将未标记的数据放如不同的簇中,这种证明在许多 应用中使用,例如聚类算法用于谷歌新闻,对于每天数万条新闻用人去分组是不是现实的,算法在没有监督的情况下自己找出新闻文章中的组,这就是为什么这种聚类算法称为无监督学习,
聚类算法是一种无监督学习算法,他处理无标签数据并尝试自动将他们分到簇中,
分类和回归都是属于监督学习,他们是有区别的,在分类中只有少数可能性的输出,如你的模型识别猫和狗,只有两种可能性的输出,存在一种离散的有限可能得输出,称之为分类问题
在回归中,模型会输出无限多个可能得数字,
如果存在一组离散的有限的可能输出,我们称之为分类
在机器学习中,表示输入的符号是小写的X,我们称之为变量,
总结
在监督学习中,数据同时包含输入X和输出标签Y
在无监督学习中,数据仅包含输入X没有包含输出标签Y,算法需要在数据中找到某种结构,模式或者有趣的东西,
成本函数
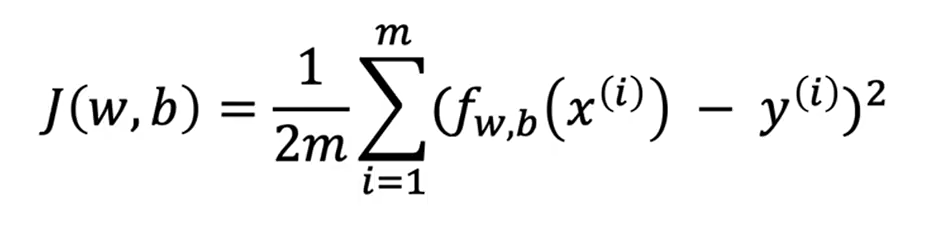
成本函数衡量的是整个训练集的样本损失
损失函数衡量的是单的训练集的数据点的样本损失
成本函数将告诉我们模型表现如何,以便我们可以尝试使其表现的更好,
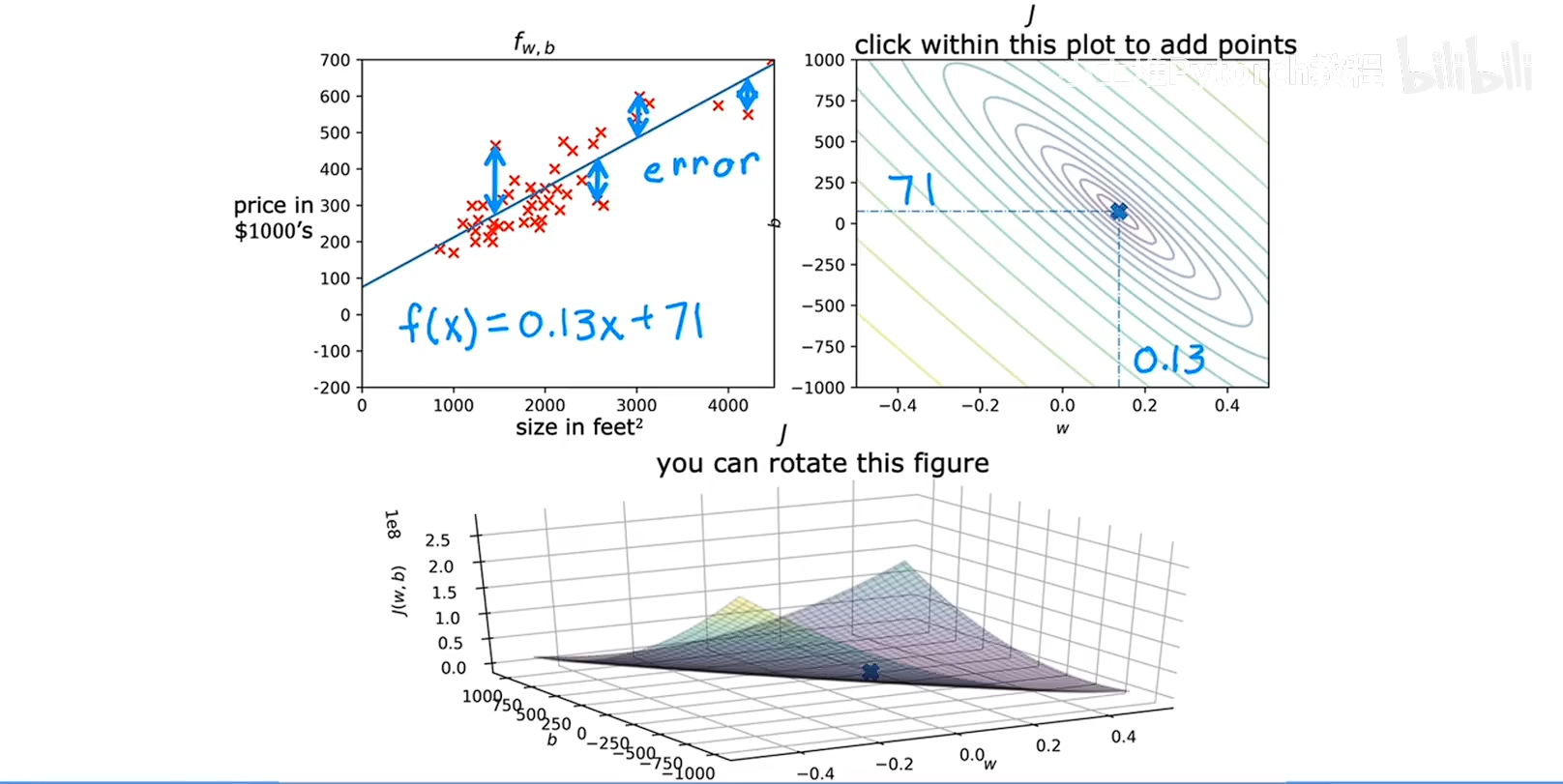
成本函数其实就是把 预测的值和真实的值进行作差然后平方最后在汇总求和,举一个例子
线性回归模型中,y=Kx, 我们的目的是找到一个参数K让模型更好的去拟合所有的数据,我们尝试不同的K值,带入模型,将预测的结果和真实的结果进行作差平方求和,就会得到K和用不同K去拟合模型的一组数据,就是把K当做变量,然后输出就是最差平方和除以2M,然后找到最小的输出,对应的K就是最适合的参数。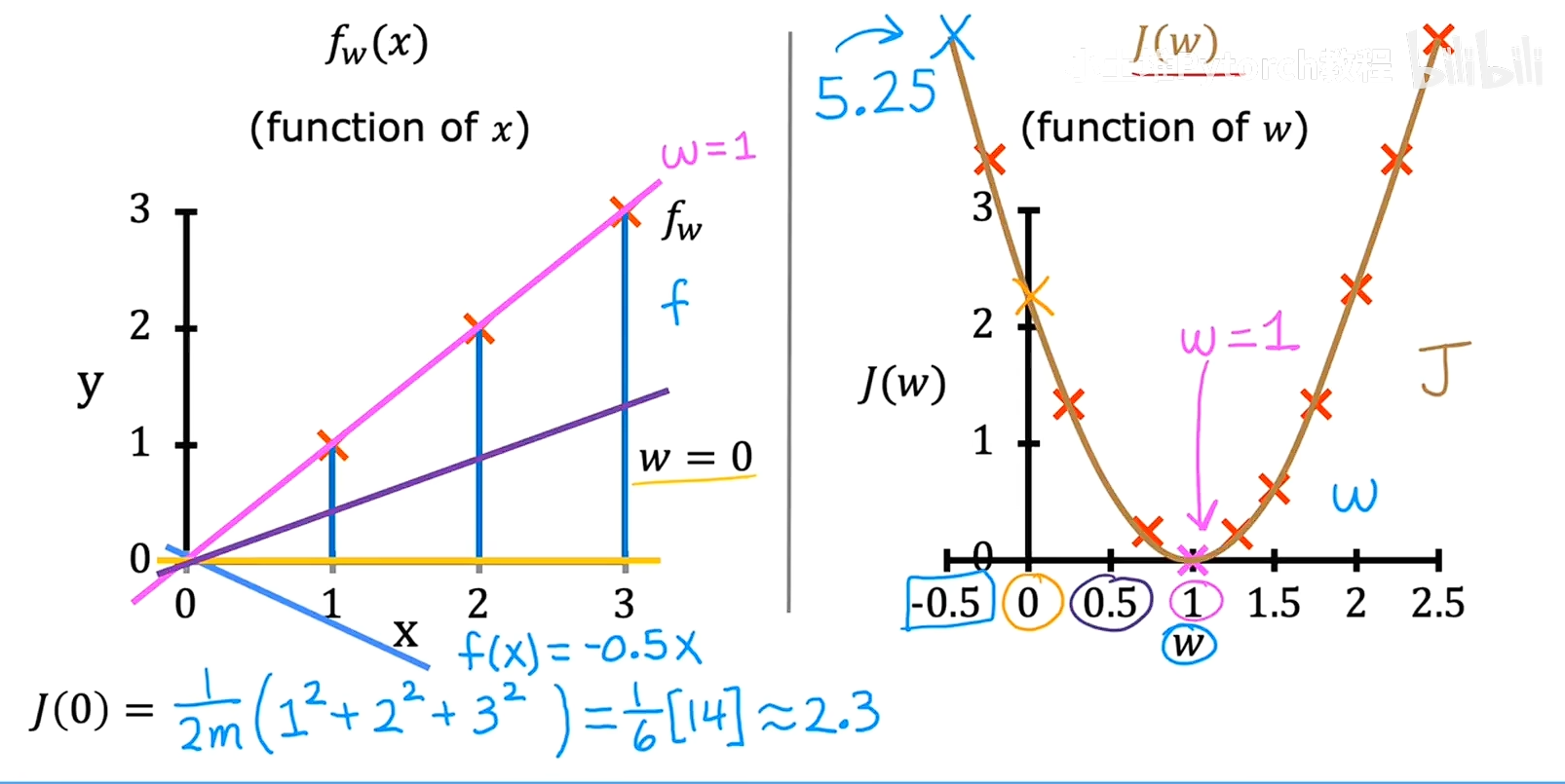
左侧的图是数据集的点,不同颜色的线代表不同程度拟合的模型,
右侧的图J(w)是不同程度拟合模型后带入数据的误差,
这两个图省去了B只考虑了X
看了f和J的图表并了解了之间的关系,y=kx+b当改变k或者B时会得到不同的直线当这条直线接近数据时,J的代价会很小
因此线性回归的目的是找到w或者k,b,使得成本函数尽可能的小,
当成本函数中的变量有两个的时候,不单单只考虑X图像是这样的,类似一个碗的一个曲面
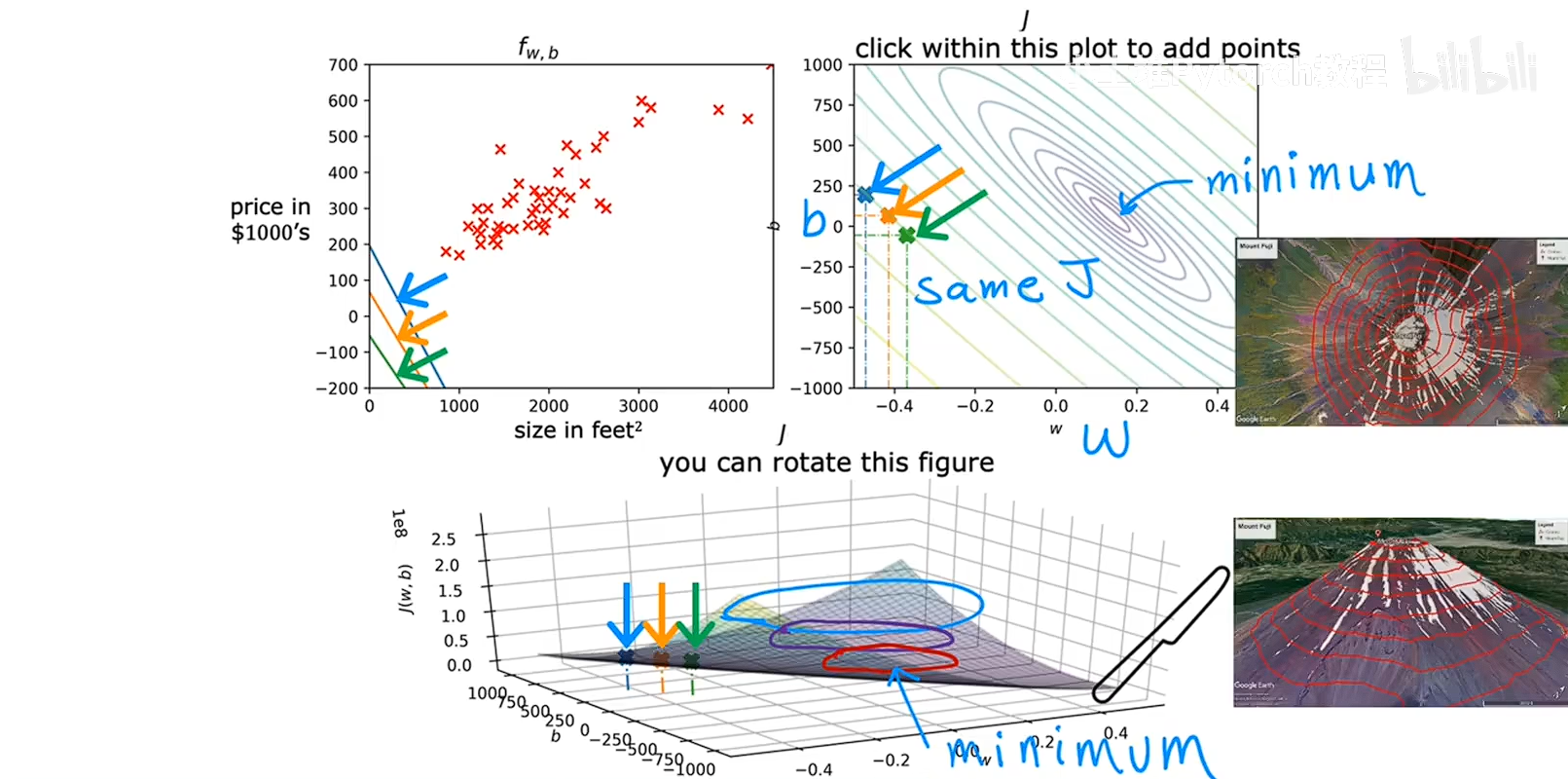
齐总右侧的图中的椭圆的线条代表的是等高线,在这条线上的函数组合他们有着想通的成本函数的数值,因为要找最低点,这个函数是一个大于0的开口向上的,所以找小的椭圆的最中心就是成本函数最小的,对应的参数就是最适合拟合的。
梯度下降
梯度下降适用于更一般的函数包括与其他两个以上参数的一起工作的其他代价函数
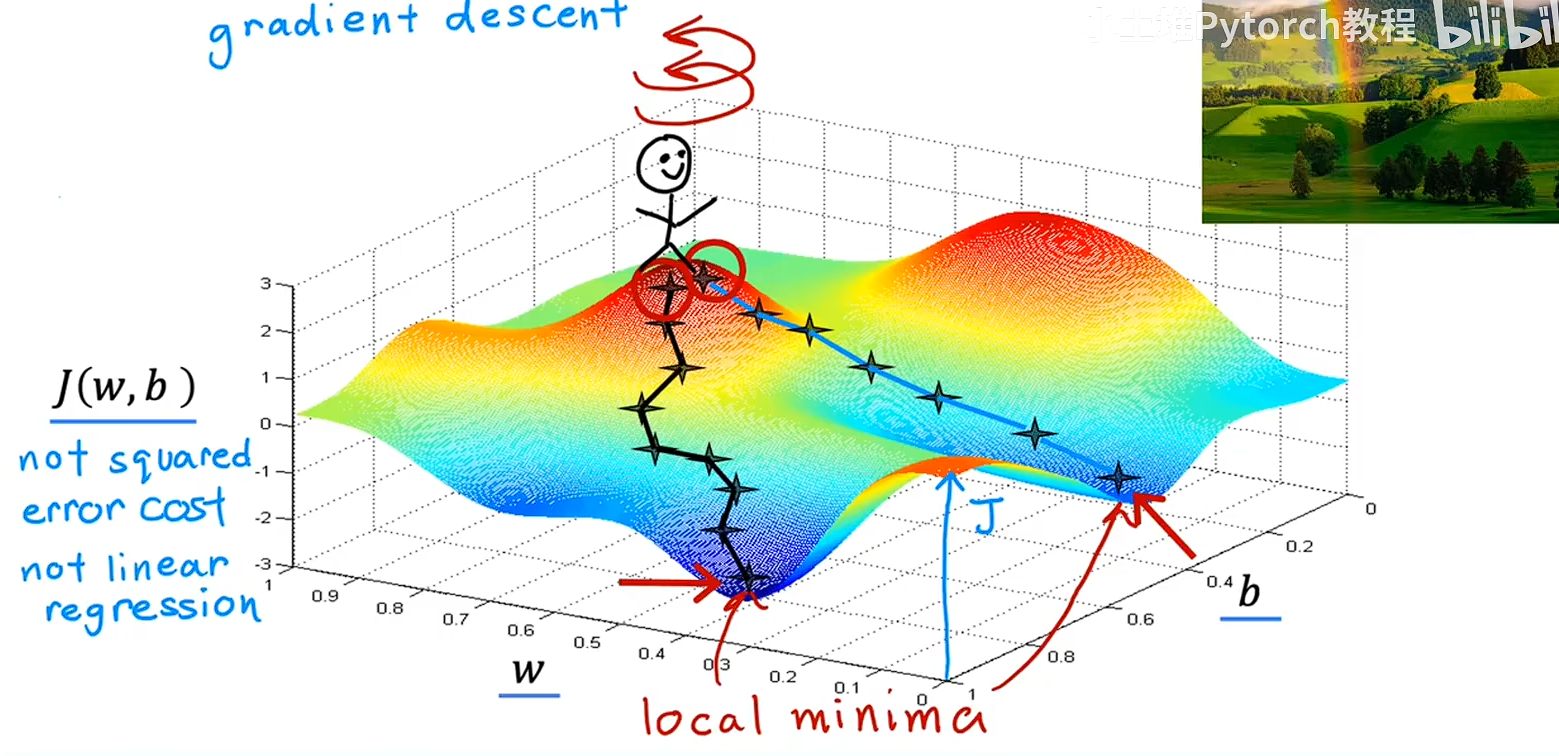
梯度下降就是一个怎么快速找到成本函数最低点的一个算法,就行一个小人下山,会先环顾四周,找到迈出一小步下山对快的那一个方向,然后就这么循环下去,
但是会有一个问题,就是梯度下降最总会到一个山谷的低处,但是这个低处是局部的最低点,不是全域的最低点,这个不知道怎么解决。
多元线性回归
之前的线性回归很简单,只有一个面积影响房屋价格,所以我们只有一个未知数X,但是现实中往往只有很多的因素,如面积,卧室数量,房屋年龄,等等,所以函数应该这样表示
y=w1*x1+w2*x2+w3*x3+w4*x4+wn*xn
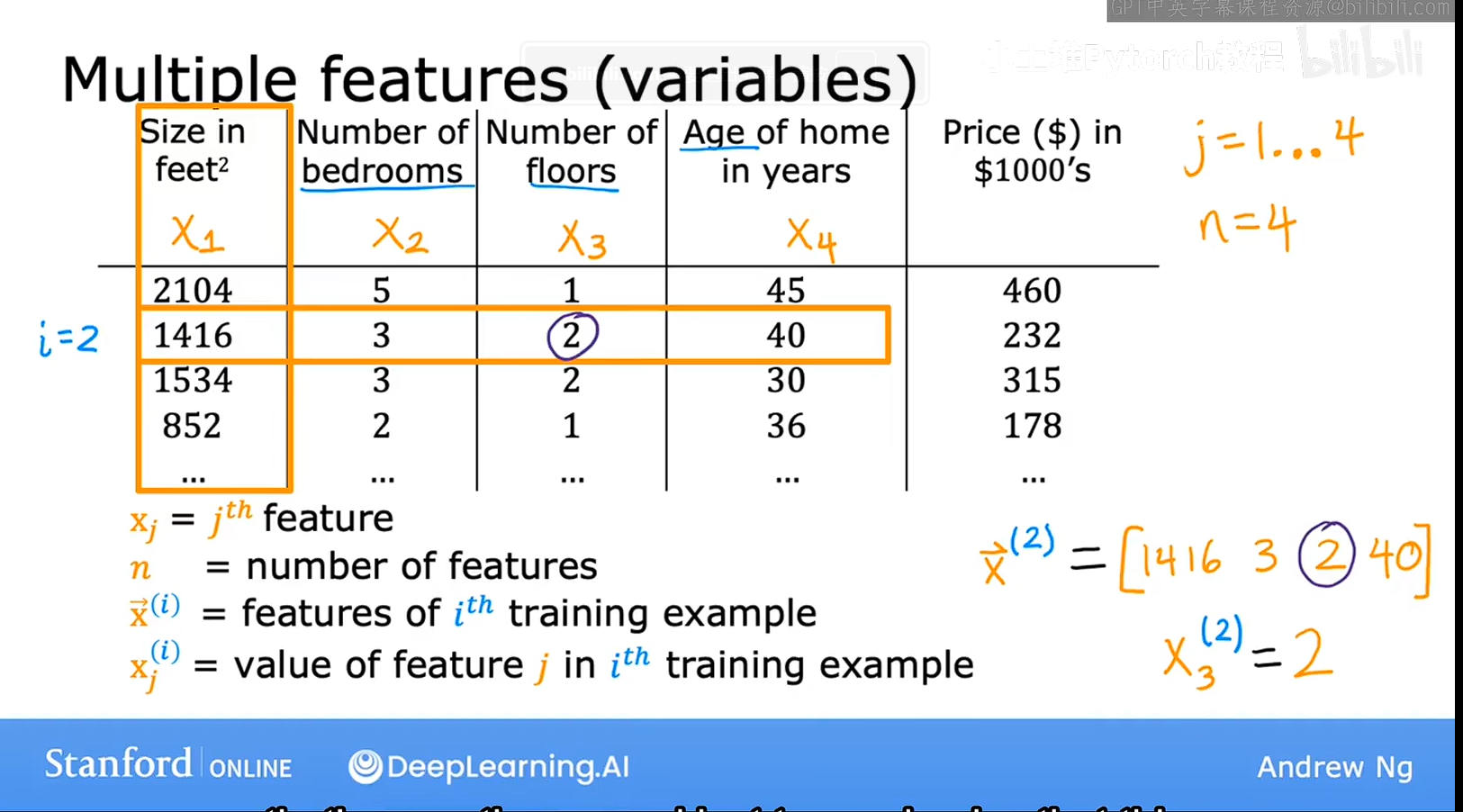 对于表示方法,我们可以看右下角那一个x x上面有一个箭头,这个箭头表示这是一个向量而不是一个数字,然后右上方有一个(2)表示是第二行数据,如何将箭头去掉,右下角加上一个数字,那么就表示是第二行的第三个数据。
对于表示方法,我们可以看右下角那一个x x上面有一个箭头,这个箭头表示这是一个向量而不是一个数字,然后右上方有一个(2)表示是第二行数据,如何将箭头去掉,右下角加上一个数字,那么就表示是第二行的第三个数据。

然后这表示的是行向量,想要简单的书写,可以这样的书写,方便观看,可以表示两个向量进行点乘,得到的就饿过就是我们想要的结果
w是权重,然后X是自变量
向量化

当我们在计算机中进行类似的多元线性规划的时候,计算就很不方便,我们可以用图片左下角的的方式进行计算,但是当数据量够大的时候就没办了,我们有用右上角的方式进行计算可能会好一些,但是这样也不是很好,Python中有专门对向量进行点乘的计算就是numpy库,如右下角,这样电脑会调动内存,cpu,gpu等等进行处理
先量化似的代码更加简洁,更容易编写,也更容易让人阅读,还会使代码运行的更快,没有向量化的代码是循环的思维,一个接着一个计算,但是想来那个还的回直接一步同时计算,计算机会为每一部分的计算分配硬件资源进行计算,所以在大数据集上进行计算,或者尝试运行大模型的时候, 向量化是非常重要的,数据量成千上万的时候,这可能是训练数据花费几分钟或者几个小时之间的差异了。
成本函数
常见的成本函数有
均方误差(MSE):用于回归问题,惩罚大误差
-
交叉熵损失:用于分类问题,衡量概率分布差异
-
绝对误差(MAE):对异常值不敏感
-
Huber损失:结合MSE和MAE的优点
对于线性回归的总结
对于线性回归,我我已经了解了,现在总结一下,线性规划的数据样本是线性的,
他的模型是Y=w1x1+w2x2+w3x3+........+wnxn+b
为了方便表示,我们可以用向量的表示表示,w箭头就是所有W的集合
x箭头就是所有x的集合,我们可以将两个向量进行点成,然后+B最后得到的结果就是原来原来的式子,然后求解,我们要用到成本函数中的军方误差,这个误差可以惩罚大误差,就是预测值和真实值的差值进行平方,然后我们对成本函数进行求导,有几个变量X就有几个偏导,偏导就是在这个点的这个这个参数,上升最快的方向,,以内有多个参数对齐结果进行影响,所以我们要把所有的偏导求出来,找到所有的方向,就像分析受力一样,最后把这些方向都合成成为最后的一个方向,就是对于这个函数的整体来说下降最快的方向,有了方向之后就要走多少了,这个就是设置学习率,就是下降的步长,步长太小运算大,时间长,步长大,容易跨过最低值,进行震荡,所以要调整合理的步长,然后就是对这个过程进行迭代,知道当调整参数的时候,均方误差数据开始趋于稳定,进行收敛,证明已经到了局部最小值,均方误差计算的是局部最小值。
正规方程
还有一种办法来求解最优的W和B 他就是正规方程
正规方程可以不用进行迭代梯度下降,可以一次算出W和B
正规方程(Normal Equation) 是求解线性回归问题的解析方法,可以直接计算出最优参数,无需迭代优化。
. 正规方程 vs 梯度下降
| 对比维度 | 正规方程 | 梯度下降 |
|---|---|---|
| 计算复杂度 | O(n³),特征多时慢 | O(kn²),特征多时快 |
| 特征数量 | n < 10000时适用 | n很大时适用 |
| 学习率 | 不需要 | 需要调参 |
| 迭代 | 一次计算 | 需要多次迭代 |
| 可解释性 | 解析解,直观 | 数值解,不直观 |
| 内存需求 | 需要存储XᵀX(n×n) | 每次迭代O(n) |
优点:
-
无需选择学习率
-
无需迭代,一次计算得到最优解
-
数学推导清晰
缺点:
-
计算逆矩阵复杂度高(O(n³))
-
当特征数n很大时(>10000),计算缓慢
-
当XᵀX不可逆时,需要特殊处理(如伪逆或正则化)
特征缩放,
当不同种类的数据之间的差异性太大的时候,代价函数的等高线会变成一个扁扁的椭圆,在同一个等高线上一个方向的W移动一点,另一个方向的W就要移动好多,这会导致梯度下降的时候变成之字形进行震荡,本质上是参数之间的贡献度差异太大了,这个参数移动一点点,另一个参数就要移动很多,这会导致梯度下降很慢,所以我们可以对数据集进行缩放,让等高线变成类似同心圆那样,梯度就会变成一个类似的直线,因为对数据进行缩放是线性的,只是在空间上进行了变换,并没有真正影响同一种数据中对W的影响,所以对模型的训练是没有影响的,数据中的缩减会在参数中补上的,不会影响最终的预测值,
原来模型 : y=w*x
缩放后 x/100
参数会自动放大 100
最终 y=100*w*k/100 最终Y=WK,
最终的目的就是 调整参数的贡献度,方便进行梯度下降, 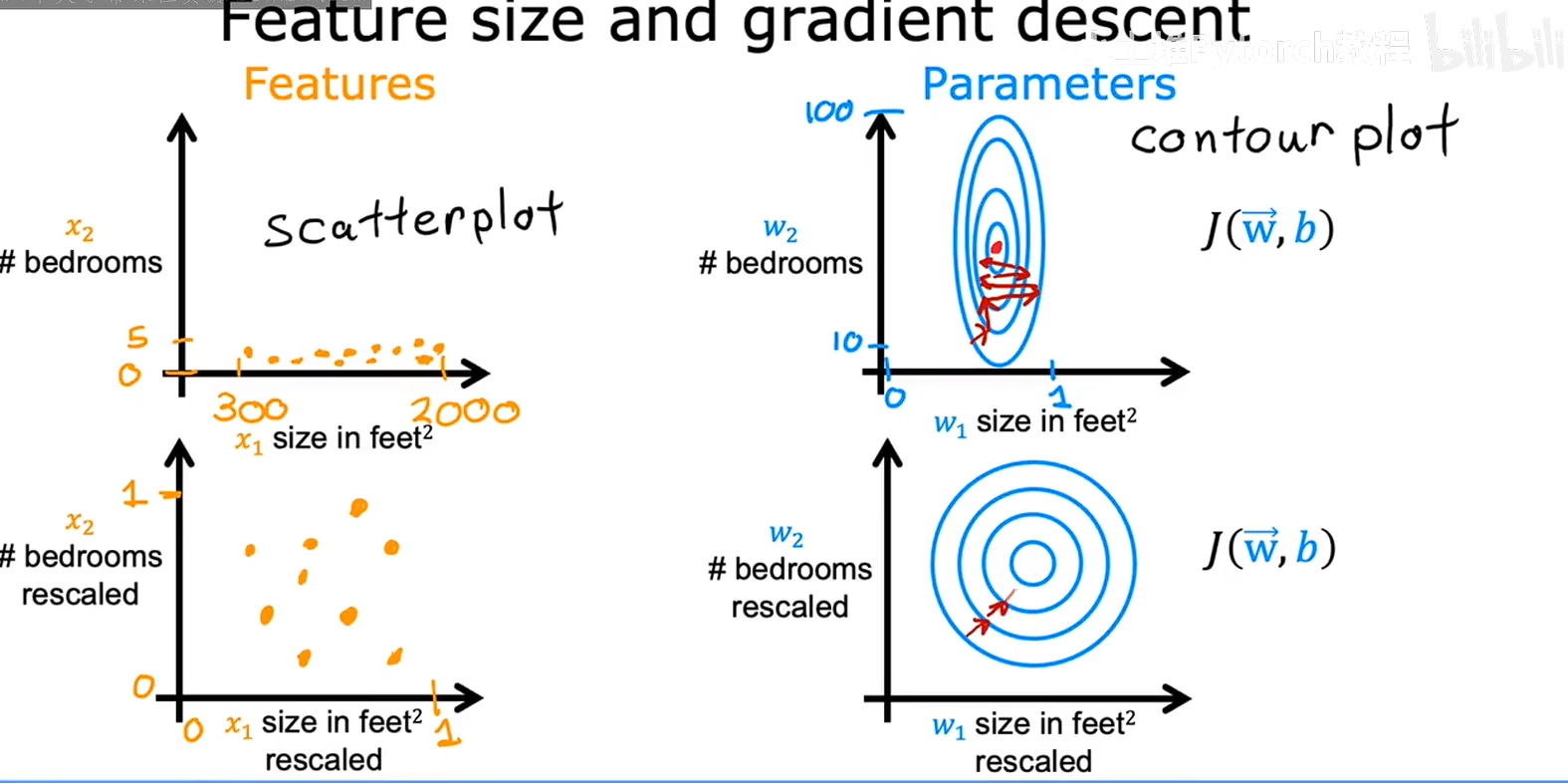
几种特征缩放的方式
特征缩放方法对比总结
| 方法名称 | 公式 | 缩放范围 | 优点 | 缺点 | 适用场景 | 异常值敏感性 |
|---|---|---|---|---|---|---|
| 标准化 Standardization | x' = (x - μ) / σ | 无固定范围 (均值为0,标准差为1) | 1. 对异常值有一定鲁棒性 2. 适合大多数算法 3. 保持原始分布形态 | 1. 不保证有界范围 2. 假设数据近似正态分布 | 线性回归、逻辑回归、神经网络、SVM、PCA | 中等 |
| 归一化 Min-Max Scaling | x' = (x - min) / (max - min) | 0, 1区间 | 1. 保留原始数据分布 2. 适合需要固定范围的算法 3. 计算简单 | 1. 对异常值非常敏感 2. 最大最小值易受极端值影响 | 图像处理、神经网络输入层、KNN、K-Means | 高 |
| 鲁棒缩放 Robust Scaling | x' = (x - median) / IQR | 无固定范围 (中位数为0,IQR为1) | 1. 对异常值非常鲁棒 2. 不受极端值影响 3. 适合偏态分布 | 1. 不保证有界范围 2. 计算稍复杂 | 数据存在异常值时、金融数据、医疗数据 | 低 |
| 最大绝对值缩放 MaxAbs Scaling | x' = x / max(x) | -1, 1区间 | 1. 保持数据稀疏性 2. 不会移动数据中心 3. 适合稀疏数据 | 1. 对异常值敏感 2. 可能放大噪声 | 稀疏数据、文本数据、推荐系统 | 高 |
| 均值归一化 Mean Normalization | x' = (x - μ) / (max - min) | 约-1, 1区间 | 1. 均值为0 2. 范围相对固定 | 1. 对异常值敏感 2. 计算量稍大 | 需要均值为0且范围固定的场景 | 高 |
事项
说明
训练/测试集处理
必须使用训练集的统计量(μ, σ, min, max等)缩放测试集,不能单独计算
树模型
决策树、随机森林、XGBoost等通常不需要特征缩放
算法敏感性
距离类算法(KNN、SVM、K-Means)和梯度下降类算法必须缩放
分类型特征
需用独热编码或标签编码,不能用数值缩放方法
顺序选择
- 处理异常值 → 2. 特征缩放 → 3. 训练模型
快速选择指南
-
默认选择:标准化(适合大多数情况)
-
有异常值:鲁棒缩放
-
需要固定范围:归一化
-
稀疏数据:最大绝对值缩放
-
树模型:不需要缩放
判断梯度下降是否收敛
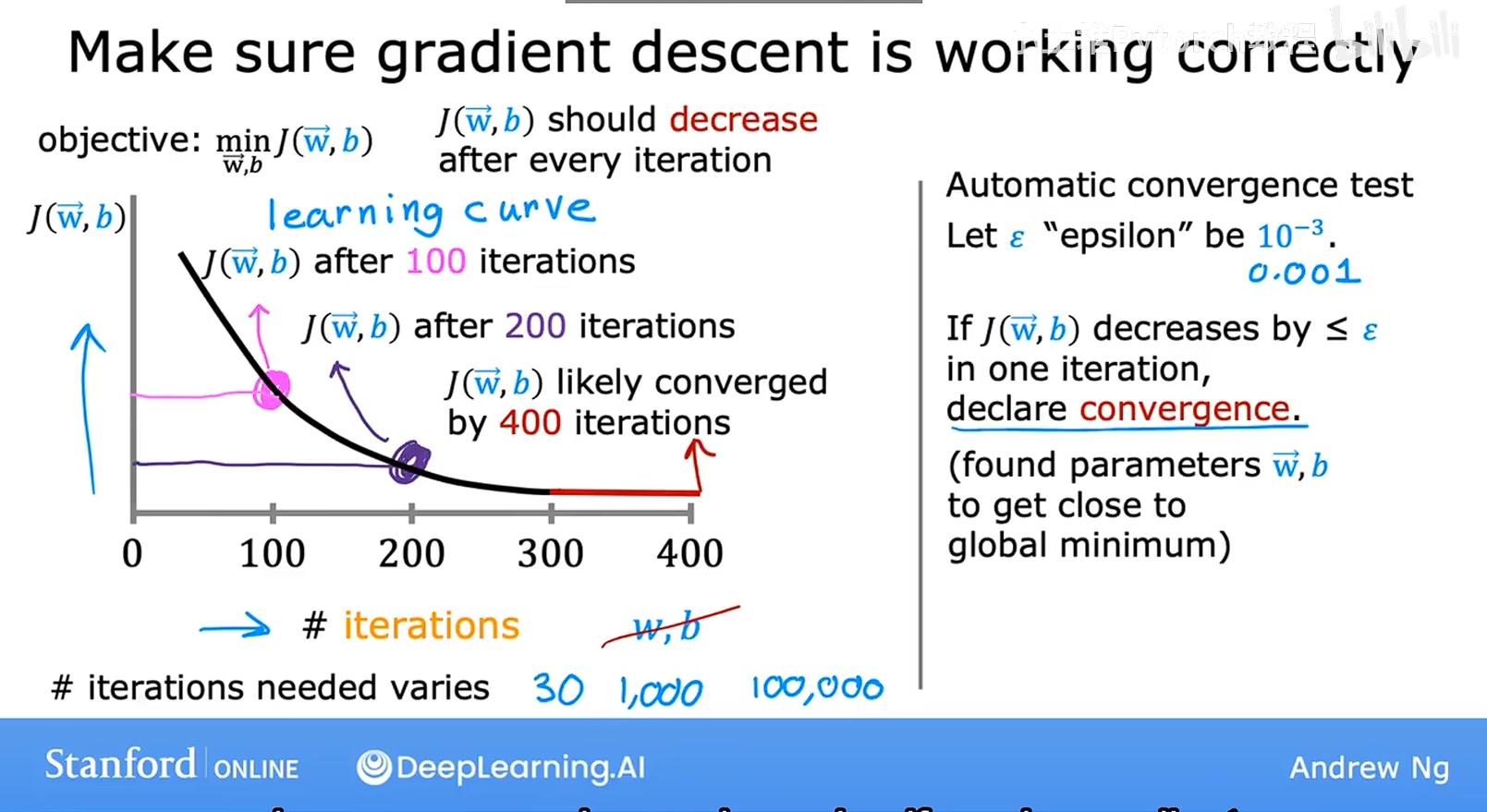
如图所示,横轴是层本函数迭代的次数,纵轴是成本,然后我们发现,在3迭代300之后,成本J趋于稳定,说明开始收敛,则梯度下降开始收敛。
选择学习率
算法选择合适的学习率的时候会运行的更好如果学习率太小,会运行的非常的慢,如果太大则可能震荡,或者出现之字形,J的结果集不会收敛,让我们看看如何为模型选择一个好的学习率,
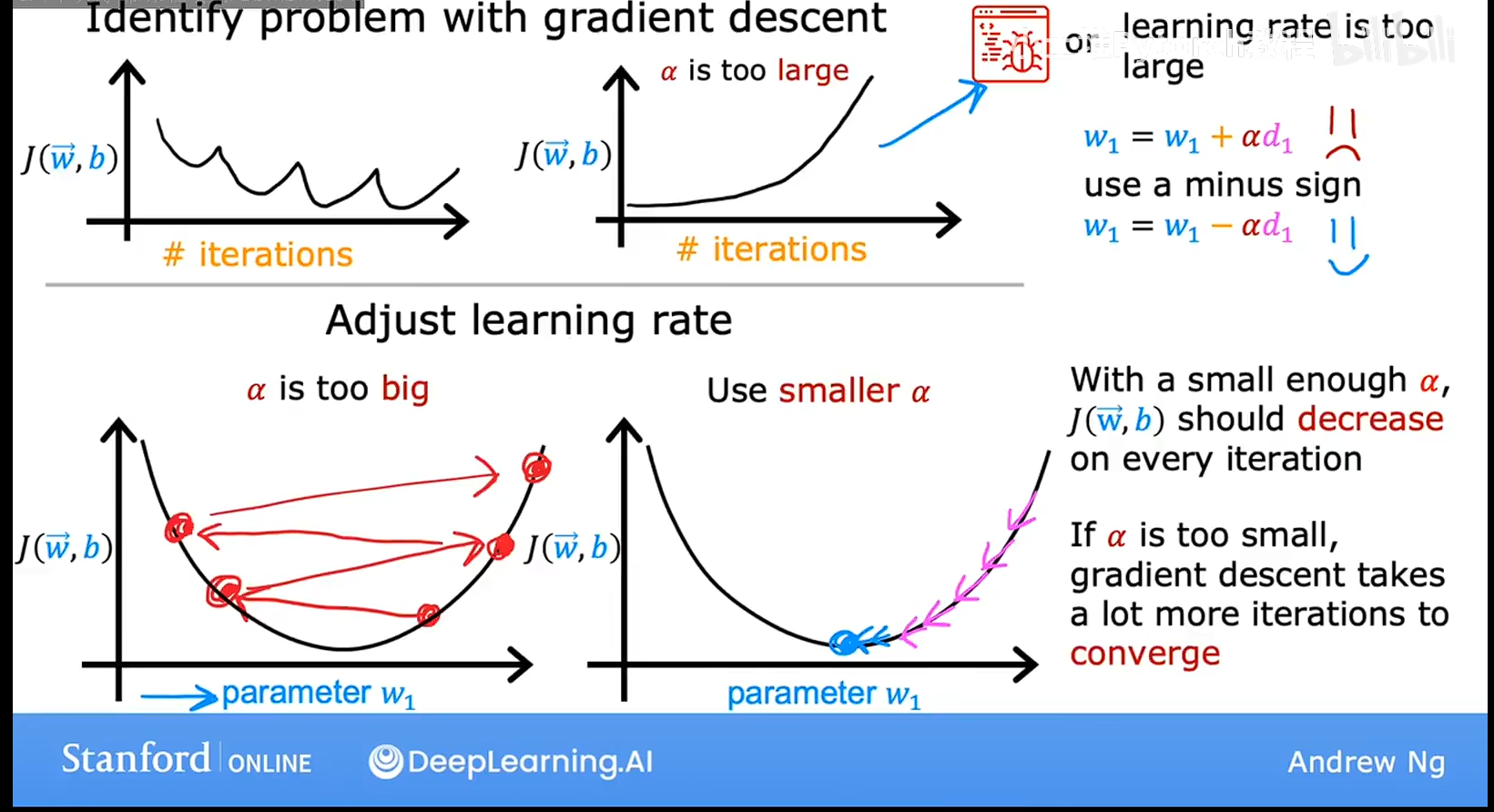
看上图,第一行的横轴是迭代次数,第二行是横轴是参数W,纵轴都是成本,看一行,有时候我们发现随着迭代次数的增加,成本不是增加的,可能出现震荡或者上升,这哦时候我们会把步长就是学习率调整的非常非常的小,如果成本还是上升的话,那么就说明是代码出现了问题,可能不是减去步长乘以倒数,而是加上,就是方向反了,
所以把学习率就是步长,调整的很小目的是为了调试步骤,但是学习率很小来训练算法通常不是很有效的,需要很多次才能收敛,
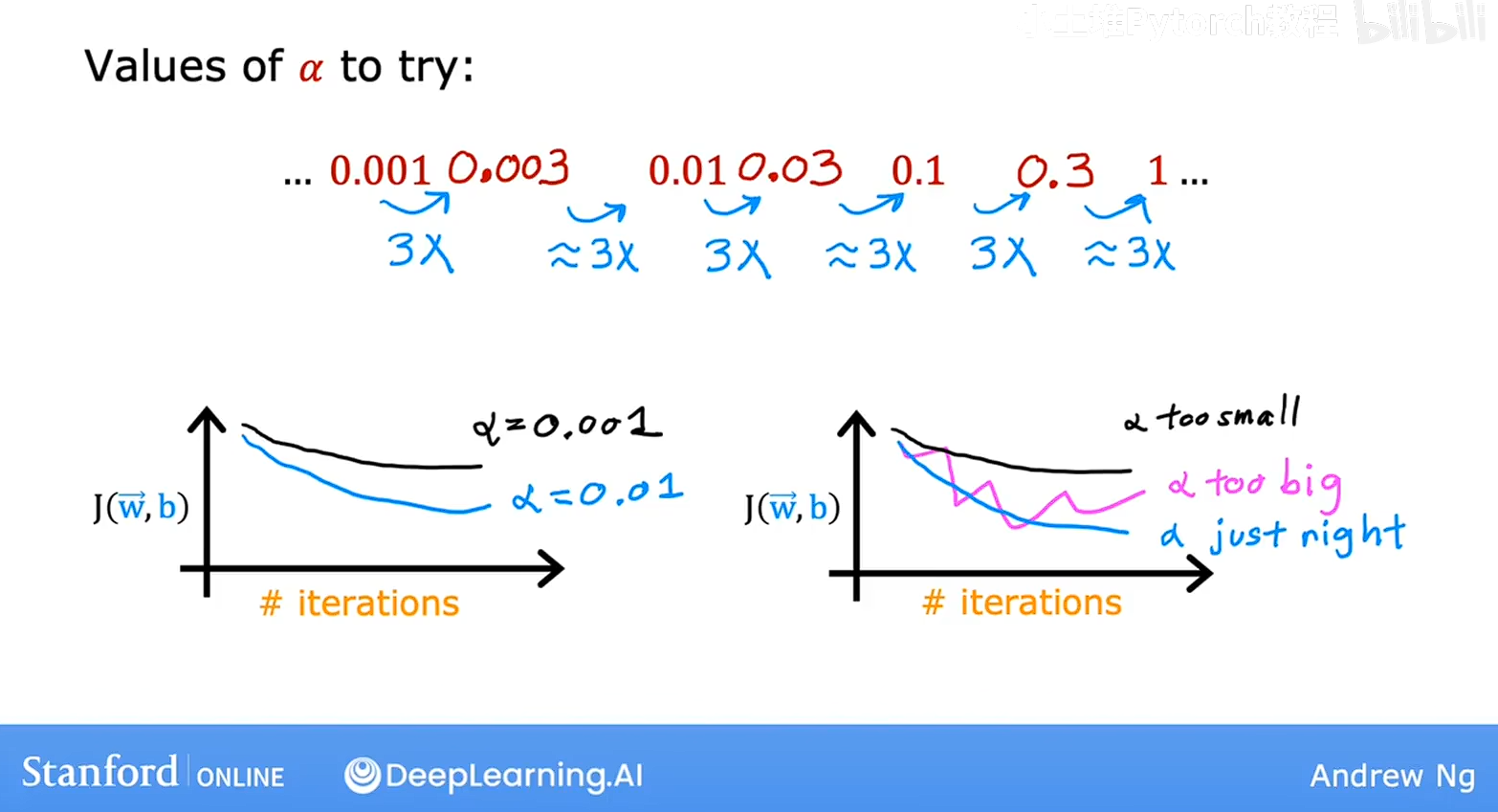
选择合适学习率的技巧
这个是开始用0.001 如果太小就增大三倍,若太大就减小三倍,可以根据图象判断学习率是否合适,然后就有一个大致的区间然后用二分法找到合适的学习率,合适的标准就是,解析率不会太大进行震荡,也不会太小运算时间太长。
特征工程
特征工程是从基础数据中,通过提取、构造、转换、筛选等手段,挖掘并整理出对模型有效的信息 的过程,最终产出高质量的特征供模型使用。
1、特征提取:
从原始、未加工的数据里,提炼出有代表性的信息,把 "原始数据" 转化为 "初步特征"。
不创造全新维度,而是对原始数据的信息提炼。
- 时序数据:从用户一周的登录日志中,提取「日均登录次数」「最长连续未登录天数」;
- 文本数据:从用户评价中,提取「关键词出现频率」「情感倾向标签(正面 / 负面)」;
- 图像数据:从一张照片中,提取「颜色直方图」「边缘轮廓的数量」
2. 特征构造
- 核心逻辑 :基于已有的特征(包括原始特征和提取后的特征),创造全新的特征维度,挖掘特征之间的隐藏关联。
- 关键特点:产生新的特征,是 "从无到有" 的过程,目的是增强特征的区分度。
- 电商数据:已有「消费总金额」和「购买次数」,构造新特征客单价 = 消费总金额 ÷ 购买次数;
- 风控数据:已有「月收入」和「月还款额」,构造新特征还款压力比 = 月还款额 ÷ 月收入;
3. 特征转换
- 核心逻辑 :调整特征的数据形式或数值范围,让特征满足模型的输入要求,消除量纲、格式等干扰因素。
- 关键特点:不新增特征维度,只是对现有特征做 "格式 / 尺度调整"。
- 常见场景与例子 :
- 标准化 / 归一化:把「身高(单位:厘米)」和「体重(单位:公斤)」缩放到同一数值区间,避免模型被量纲大的特征主导;
- 类别特征编码:把「性别:男 / 女」「城市:北京 / 上海 / 广州」这类非数值特征,转换为独热编码(1,0/0,1)、标签编码(0/1)等数值形式;
- 缺失值填充:用均值、中位数或模型预测值,填补特征中的空值。
4. 特征筛选
- 核心逻辑 :从经过提取、构造、转换后的所有特征中,剔除无用、冗余或有噪声的特征,保留对模型预测最有帮助的特征子集。
- 关键特点:是 "做减法" 的过程,目的是降低计算成本、避免维数灾难和过拟合。
- 常见场景与例子 :
- 方差筛选:剔除方差接近 0 的特征(比如一个特征的所有样本值都是 "1",没有区分度);
- 相关性筛选:剔除和目标变量相关性极低的特征(比如用 "用户姓名" 预测 "是否违约",相关性几乎为 0);
- 模型驱动筛选 :用决策树、随机森林等模型输出特征重要性,只保留重要性排名前 N 的特征。