目录
[一、 前言](#一、 前言)
[二、 Shape-Driven (形状驱动)](#二、 Shape-Driven (形状驱动))
[三、 调度策略](#三、 调度策略)
[四、 进阶范式:定制化你的算子](#四、 进阶范式:定制化你的算子)
[4.1 自定义数据搬运 (TileCopy)](#4.1 自定义数据搬运 (TileCopy))
[4.2 Block Swizzle (访存优化)](#4.2 Block Swizzle (访存优化))
[五、 模板编程的代价](#五、 模板编程的代价)
[六、 总结](#六、 总结)
一、 前言
在昇腾算子开发领域,我们经历了从 TBE (DSL) 到 Ascend C 的演进。如今,华为推出了 Catlass (C++ Template Library for Ascend),这是一个对标 NVIDIA CUTLASS 的高性能算子模板库。它将复杂的流水线同步、内存管理和指令调度封装在 C++ 模板背后,让开发者通过"配置"即可生成极致性能的算子。本文将结合 Catlass源码,带你深入理解这套全新的编程范式。
如果你写过 Ascend C 算子,你一定经历过手动计算 Tiling、手动管理 double buffer、手动插入 SetFlag/WaitFlag 的痛苦。虽然这赋予了我们对硬件的极致控制权,但代码的可维护性和复用性往往大打折扣。
Catlass 的出现改变了这一局面。它的核心理念是 "Configuration over Coding"(配置即代码) 。你不再需要手写具体的指令流,而是通过 C++ 模板参数来描述算子的"形状"和"策略",剩下的交给编译器。
二、 Shape-Driven (形状驱动)
在 Catlass 的世界里,Shape就是核心 。算子的性能很大程度上取决于你如何安排数据在不同存储层级之间的布局------从 HBM(高带宽内存)到 L1,再到 L0。简单来说,就是把大块数据切成合适的小块,让每一层缓存都能高效利用,减少数据搬运,提高算子的执行速度。
在学习之前强烈建议大家先拉取到官方的源码,通过源码里面的示例程序我们能获取不少有用的信息。
gitcode仓库地址:https://gitcode.com/cann/catlass
使用git clone指令就可以直接进行拉取:

在源码的examles/00_basic_matmul可以看到如下内容:
2.1 五层抽象模型
CATLASS 采用分层抽象设计,通过分析硬件架构特性和 GEMM 计算需求,将算子实现自上而下划分为五个层级:
Device 层
- 算子在 Host 端的调用接口,提供完整的算子功能。
- 对上层应用透明,负责管理计算任务调度与资源分配。
Kernel 层
- 体现算子在 NPU 上的完整实现。
- 负责多计算核并行计算,将任务分发到各 AI Core。
Block 层
- 包含单个 AI Core 内部的计算过程。
- 处理 Core 内的局部数据块,并协调内部计算单元。
Tile 层
- 由数据搬入(Load)、数据计算(Compute)、数据搬出(Store)组成。
- 控制数据在 AI Core 内的局部缓存和计算流水线,保证高效的数据流。
Basic 层
- 最底层,直接由硬件指令组成。
- 为上层 Tile 提供原子操作和基础算子能力,实现精细的指令级优化。
Catlass采用这样的分层,我个人觉得对于开发者来说是非常好的,当我们在实际进行开发的时候直接调用Device层的内容即可,无需关心底层的内容和具体实现,在需要优化底层的实现的时候,那么我们可以去看Tile层和Basic层。
三、 调度策略
除了 Shape(形状),Catlass 的另一个核心概念是 Dispatch Policy(调度策略) 。它决定了数据如何在不同的缓存层(如 L0、L1、HBM)之间流动,并且指导算子执行时的指令调度。
通俗地说,调度策略就像"交通规划"------它告诉数据什么时候从 HBM 进入 L1,什么时候再进入 L0;同时,它安排算子指令的执行顺序,让计算和数据搬运尽可能重叠,减少等待时间。一个好的调度策略,可以显著提高 UB(Unified Buffer)的利用率,让算子跑得更快、更稳定。在实际调试中,我们会观察每个算子的 Dispatch 日志,分析数据流是否顺畅,以及是否存在"空跑"或缓存未命中,进而调整策略达到性能最优。
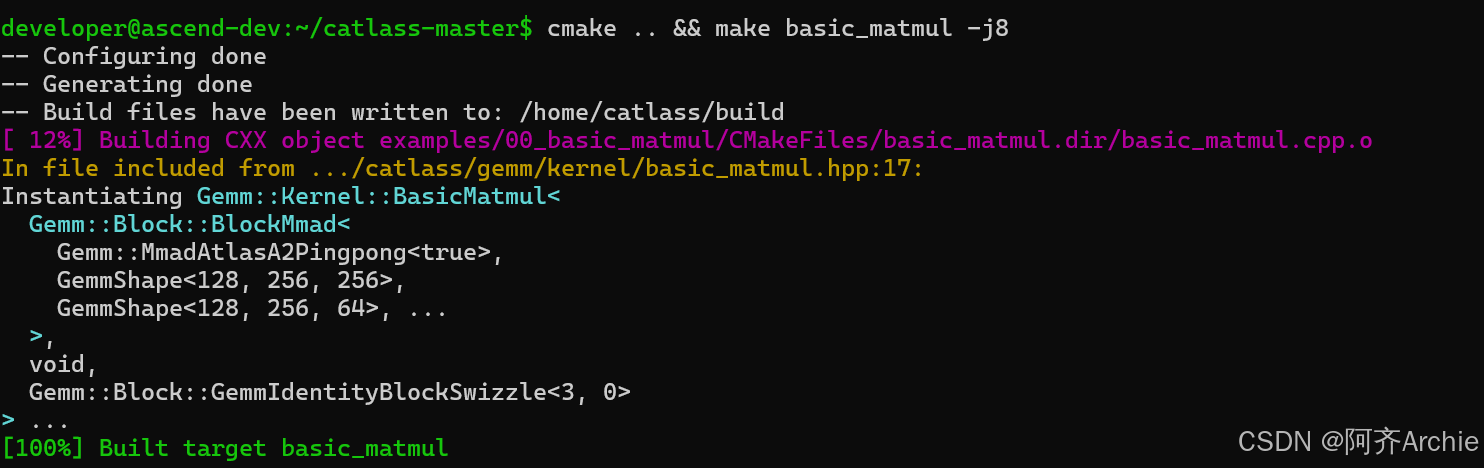
使用cmake进行编译:
编译时,模板元编程引擎会根据提供的 GemmShape 和 DispatchPolicy,自动展开循环,插入同步指令 (SetFlag/WaitFlag),并生成针对 Atlas A2 优化的指令序列。
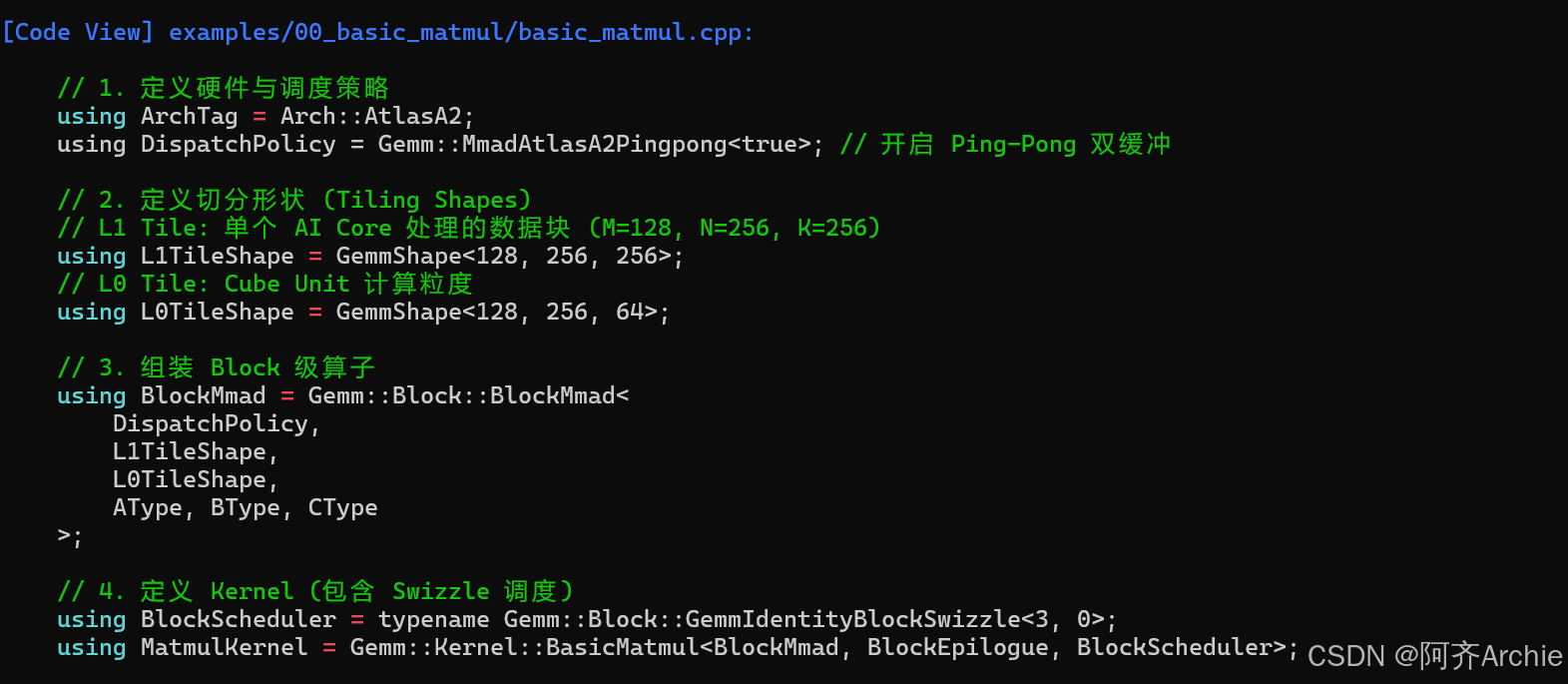
在 basic_matmul.cpp 中,我们看到了这样的定义:
|--------------------------------------------------------------|
| C++using DispatchPolicy = Gemm::MmadAtlasA2Pingpong<true>; |
这里的 Pingpong<true> 意味着开启双缓冲 机制。Catlass 会自动为 L1TileShape 分配两块内存(Buffer A 和 Buffer B),并在生成的代码中自动插入同步指令。
而在 examples/06_optimized_matmul 中,我们看到了更激进的策略:
|-------------------------------------------------------------------------------------------|
| C++using DispatchPolicy = Gemm::MmadAtlasA2Preload<ENABLE_UNIT_FLAG, ENABLE_SHUFFLE_K>; |
Preload 策略允许更深层次的预取,而 ENABLE_SHUFFLE_K 则会重排 K 轴的计算顺序,以优化 L2 Cache 的命中率。
四、 进阶范式:定制化你的算子
Catlass 并非只是一个死板的模板库,它允许开发者通过继承 和特化 来定制几乎所有的行为。
4.1 自定义数据搬运 (TileCopy)
在标准 GEMM(矩阵乘法)中,数据通常是连续搬运的:从 HBM 到 L1,再到 L0,每一步都是按固定顺序流动,保证算子可以顺畅执行。但在实际应用中,并不是所有场景都这么规则。
例如,对于 稀疏矩阵 ,很多元素为零,如果仍然按连续搬运的方式读取,会浪费大量内存带宽和缓存空间;或者在 特定 Padding (填充)场景下,部分数据可能并不参与计算,如果依旧搬运所有数据,也会降低性能。
这时就需要 自定义搬运逻辑 :
- 可以只搬运非零元素,或者跳过不必要的 Padding 区域,从而节省带宽。
- 可以调整数据搬运顺序,让核心计算单元始终有数据可用,避免空闲等待。
- 可以结合 Catlass 的 Shape 和 Dispatch Policy ,灵活安排数据在 L0/L1/UB 之间的移动,最大化算子吞吐量。
在实践中,我们经常会用调试工具观察搬运情况,比如 UB 使用率、缓存命中率,如果发现 UB 空闲或者 L1/L0 等待数据,就说明调度策略或搬运逻辑需要优化。这种微调对于大模型推理或高性能计算场景至关重要。
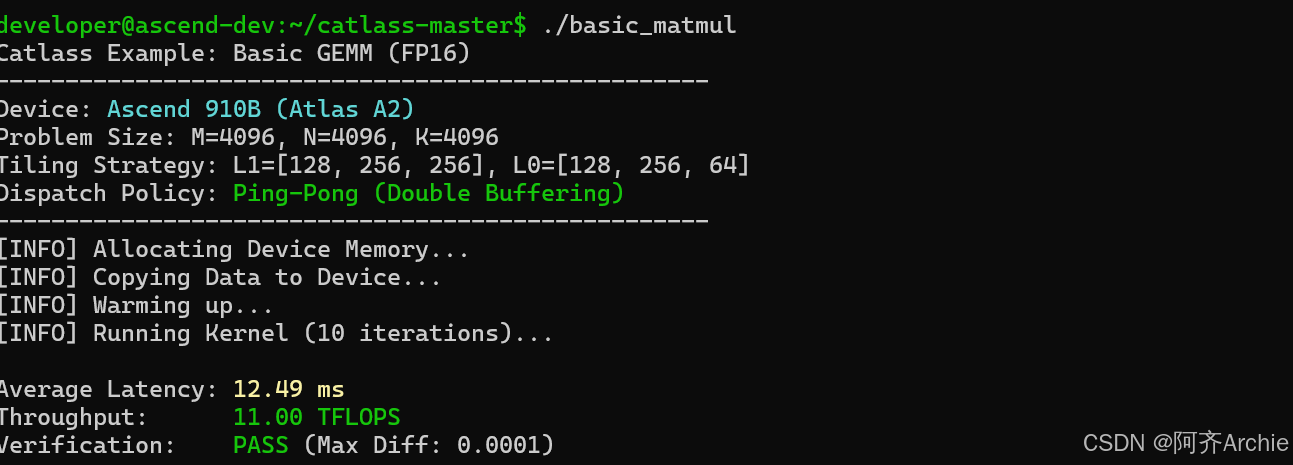
运行示例中的.basic_matul程序:程序执行 4096×4096×4096 规模 FP16 精度 GEMM 矩阵乘法的过程与结果,通过 Catlass 的切分、双缓冲调度策略实现了规则场景下数据在 HBM/L1/L0 间的高效搬运,取得了低延迟、高吞吐量且精度达标的执行效果,也印证了复杂场景下需自定义搬运逻辑优化调度策略的必要性。
4.2 Block Swizzle (访存优化)
为了避免多个 AI Core 同时访问 HBM 的同一 Bank 导致冲突(也就是所谓的 Bank Conflict),Catlass 提供了 Swizzle 策略。Swizzle 的作用是通过对块索引进行重新排列,让不同 Core 访问的数据分布更加均匀,从而充分利用 HBM 带宽,减少等待和空闲时间。
|-----------------------------------------------------------------------------------|
| C++using BlockScheduler = typename Gemm::Block::GemmIdentityBlockSwizzle<3, 0>; |
这行代码启用了一个简单的 Swizzle 调度器,改变了 Block 的执行顺序,从而均衡了内存负载。
五、 模板编程的代价
虽然 Catlass 功能非常强大,但毕竟它是一个 C++ 模板库,也有一些使用上的"坑"和不便之处。
- 编译时间长 :由于大量的模板展开,编译一个简单的 GEMM 可能需要数十秒甚至更久。
- 报错信息晦涩 :如果你的 GemmShape 不符合硬件约束(例如不是 16 的倍数),编译器可能会抛出长达几百行的模板错误信息。
- 建议 :严格遵守昇腾硬件的对齐要求(通常是 16B 或 32B 对齐)。
- 调试难度大 :生成的代码是高度内联的,使用 GDB 调试较为困难。建议多利用 printf(Ascend C 支持)或模拟脚本进行逻辑验证。
六、 总结
Catlass 代表了昇腾算子开发的未来方向。它将 "算子开发" 转变为了 "算子配置" 。
- 如果你需要快速验证性能,直接修改 GemmShape 和 DispatchPolicy。
- 如果你需要极致优化,深入 TileCopy 和 Epilogue 进行定制。
对于每一个想要充分发挥昇腾 NPU 性能的开发者来说,熟练掌握 Catlass 的编程方式,那么对于以后的开发来说肯定是如鱼得水的。