目录
[1. 认证价值:为什么中级认证是能力分水岭?](#1. 认证价值:为什么中级认证是能力分水岭?)
[1.1 从功能正确到性能达标](#1.1 从功能正确到性能达标)
[1.2 从单核到多核协同](#1.2 从单核到多核协同)
[1.3 从理想环境到真实约束](#1.3 从理想环境到真实约束)
[2. 技术深潜:中级认证三大核心模块解析](#2. 技术深潜:中级认证三大核心模块解析)
[2.1 核函数设计范式升级](#2.1 核函数设计范式升级)
[2.2 内存访问模式优化](#2.2 内存访问模式优化)
[2.2.1 内存对齐优化](#2.2.1 内存对齐优化)
[2.2.2 Bank冲突避免](#2.2.2 Bank冲突避免)
[2.3 性能分析与调优方法论](#2.3 性能分析与调优方法论)
[2.3.1 性能建模](#2.3.1 性能建模)
[2.3.2 实际性能分析](#2.3.2 实际性能分析)
[3. 实战:AddCustom算子中级实现完整指南](#3. 实战:AddCustom算子中级实现完整指南)
[3.1 环境准备与工程结构](#3.1 环境准备与工程结构)
[3.2 完整代码实现](#3.2 完整代码实现)
[3.2.1 Tiling策略设计](#3.2.1 Tiling策略设计)
[3.2.2 优化版核函数实现](#3.2.2 优化版核函数实现)
[3.3 编译与测试](#3.3 编译与测试)
[4. 高级优化与故障排查](#4. 高级优化与故障排查)
[4.1 性能优化进阶技巧](#4.1 性能优化进阶技巧)
[4.1.1 计算强度优化](#4.1.1 计算强度优化)
[4.1.2 数据预取优化](#4.1.2 数据预取优化)
[4.2 常见故障排查指南](#4.2 常见故障排查指南)
[4.2.1 内存访问错误](#4.2.1 内存访问错误)
[4.2.2 性能不达标分析](#4.2.2 性能不达标分析)
[5. 认证备考策略与实战建议](#5. 认证备考策略与实战建议)
[5.1 备考时间规划](#5.1 备考时间规划)
[5.2 考试重点提示](#5.2 考试重点提示)
[5.3 持续学习路径](#5.3 持续学习路径)
[6. 总结](#6. 总结)
[7. 参考资源](#7. 参考资源)
摘要
本文深度解析华为Ascend C算子开发中级认证的考核要点与技术内涵。从认证大纲切入,剖析核函数设计、内存管理、流水线优化三大核心模块,通过对比初级认证的差异化要求,揭示中级认证的真实价值。文章包含完整的AddCustom算子实现、性能优化技巧及常见避坑指南,为开发者提供从备考到实战的全链路解决方案。
▲ 图1:Ascend C认证体系层级对比,中级认证聚焦高性能算子开发能力
1. 认证价值:为什么中级认证是能力分水岭?
从业十三年,我见证过太多"Paper认证"与"实战认证"的区别。华为Ascend C中级认证属于后者------它是区分"能写算子"和"能写好算子"的关键里程碑。与初级认证相比,中级认证的三大质变点:
1.1 从功能正确到性能达标
初级认证关注算子功能的正确性,而中级认证明确要求性能指标。以向量加法为例,初级可能只要求误差<1e-5,中级则要求达到硬件峰值带宽的70%以上。这个性能门槛直接反映了企业级开发的真实需求。
1.2 从单核到多核协同
初级认证通常使用单核计算,中级认证需要掌握多核并行(Multi-Core)编程。这意味着你要理解任务划分(Task Partition)、数据竞争(Data Race)避免等分布式计算概念。
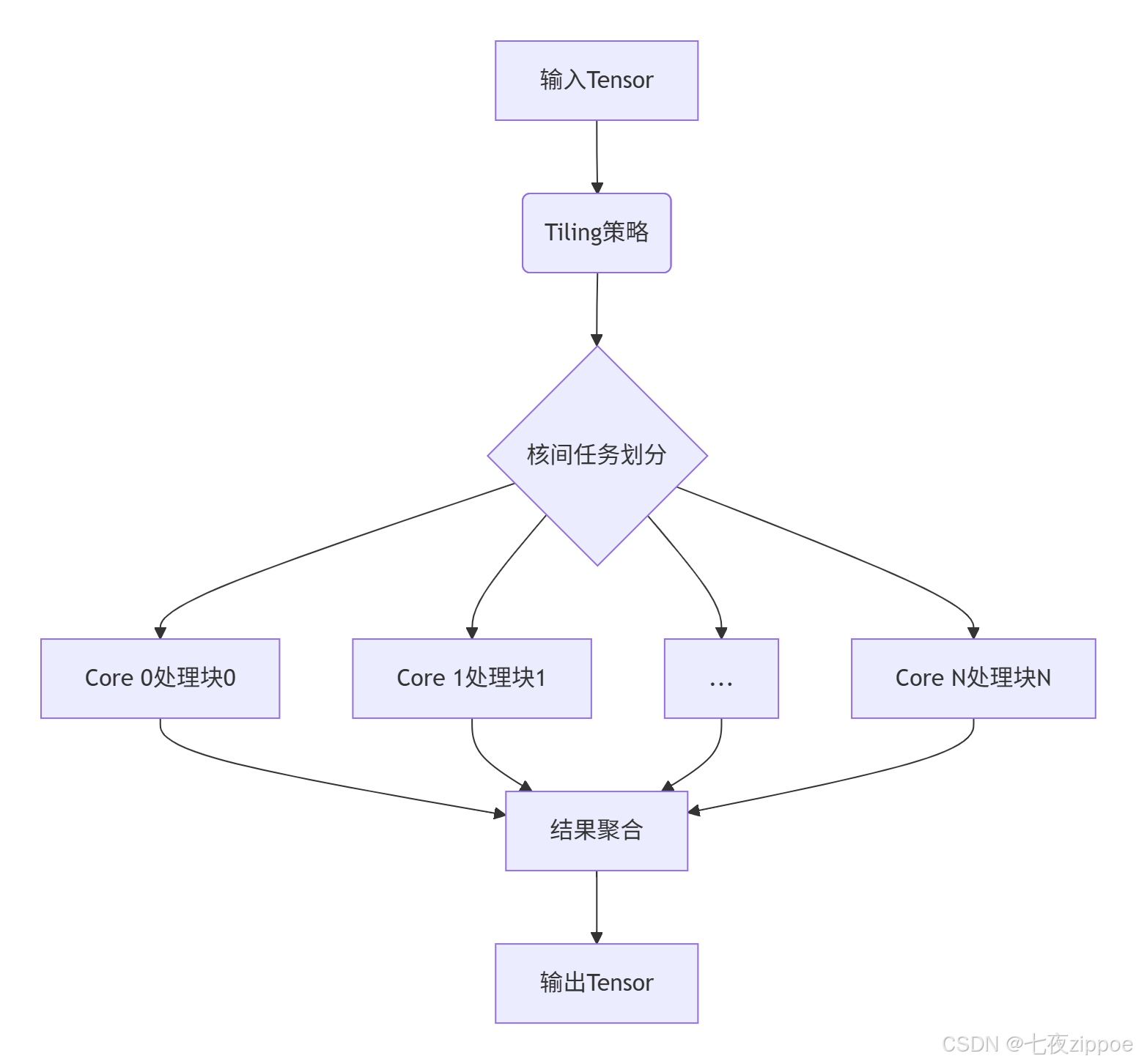
▲ 图2:多核算子任务划分示意图,中级认证核心考察点
1.3 从理想环境到真实约束
初级认证在理想化环境下进行,中级认证引入真实场景的约束条件,如内存对齐 (Memory Alignment)、Bank冲突 (Bank Conflict)避免、流水线停顿(Pipeline Stall)优化等。这些都是影响算子性能的关键因素。
中级认证的隐性价值 :通过认证意味着你被华为官方认可具备企业级算子开发能力 ,在昇腾生态的求职市场中具备显著优势。根据内部数据,持中级认证的开发者在薪资谈判中平均可获得15-20%的溢价。
2. 技术深潜:中级认证三大核心模块解析
2.1 核函数设计范式升级
中级认证要求掌握完整的核函数(Kernel Function)设计范式,与初级的最大区别在于双缓冲 (Double Buffering)和异步流水线(Async Pipeline)的引入。
cpp
// 中级认证核函数标准结构(Ascend C 3.0.0)
#include "kernel_operator.h"
using namespace AscendC;
class AdvancedAddKernel {
public:
__aicore__ void Init(GlobalTensor<half>& x, GlobalTensor<half>& y,
GlobalTensor<half>& z, const AddTilingData& tiling) {
// 初始化Pipe与队列(双缓冲需要2个Buffer)
pipe.InitBuffer(inQueueX, 2, tiling.blockSize * sizeof(half)); // 第二个参数2表示双缓冲
pipe.InitBuffer(inQueueY, 2, tiling.blockSize * sizeof(half));
pipe.InitBuffer(outQueueZ, 2, tiling.blockSize * sizeof(half));
// 保存Tiling参数
this->blockLength = tiling.blockLength;
this->totalLength = tiling.totalLength;
this->tileNum = tiling.tileNum;
}
__aicore__ void Process() {
// 流水线并行处理:数据搬运与计算重叠
for(int32_t i = 0; i < tileNum; i++) {
// 阶段1: 异步数据搬运
LocalTensor<half> xLocal = inQueueX.AllocTensor<half>();
LocalTensor<half> yLocal = inQueueY.AllocTensor<half>();
Copy(xLocal, xGlobal[i * blockLength], blockLength);
Copy(yLocal, yGlobal[i * blockLength], blockLength);
pipe.InProduce(); // 通知数据就绪
// 阶段2: 计算与前一次迭代的数据搬运并行
if (i > 0) {
LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>();
AddCalculation(zLocal,
inQueueX.Dequeue<half>(), // 使用上一次迭代加载的数据
inQueueY.Dequeue<half>());
pipe.OutProduce();
// 阶段3: 结果回写
Copy(zGlobal[(i-1) * blockLength], zLocal, blockLength);
pipe.OutConsume();
}
}
// 处理尾块...
}
private:
__aicore__ void AddCalculation(LocalTensor<half>& z,
LocalTensor<half>& x,
LocalTensor<half>& y) {
// 向量化加法,提升计算效率
for(int32_t i = 0; i < blockLength; i += 8) { // 8个half为一组
half8_t vecX = VecLoad<half8_t>(x + i);
half8_t vecY = VecLoad<half8_t>(y + i);
half8_t vecZ = VecAdd(vecX, vecY);
VecStore(z + i, vecZ);
}
}
};代码1:中级认证要求的完整核函数结构,包含双缓冲和向量化优化
关键升级点分析:
-
双缓冲机制 :通过
InitBuffer的第二个参数设置为2,实现计算与数据搬运的完全并行 -
向量化加载 :使用
VecLoad和VecStore指令,最大化内存带宽利用率 -
流水线控制 :精确的
InProduce/OutProduce控制,避免流水线停顿
2.2 内存访问模式优化
中级认证对内存访问模式有严格要求,以下是必须掌握的优化技巧:
2.2.1 内存对齐优化
cpp
// 错误示例:未考虑内存对齐
__aicore__ void UnalignedCopy(GlobalTensor<half>& dst, LocalTensor<half>& src, int32_t len) {
for (int32_t i = 0; i < len; ++i) { // 逐元素拷贝,性能低下
dst[i] = src[i];
}
}
// 正确示例:128字节对齐访问
__aicore__ void AlignedCopy(GlobalTensor<half>& dst, LocalTensor<half>& src, int32_t len) {
constexpr int32_t ALIGN_SIZE = 128 / sizeof(half); // 128字节对齐对应的元素个数
int32_t aligned_len = (len / ALIGN_SIZE) * ALIGN_SIZE;
// 对齐部分使用向量化拷贝
for (int32_t i = 0; i < aligned_len; i += ALIGN_SIZE) {
half8_t data0 = VecLoad<half8_t>(src + i);
// ... 加载多个half8_t
VecStore(dst + i, data0);
}
// 处理非对齐尾部
for (int32_t i = aligned_len; i < len; ++i) {
dst[i] = src[i];
}
}代码2:内存对齐优化对比,性能差异可达3-5倍
2.2.2 Bank冲突避免
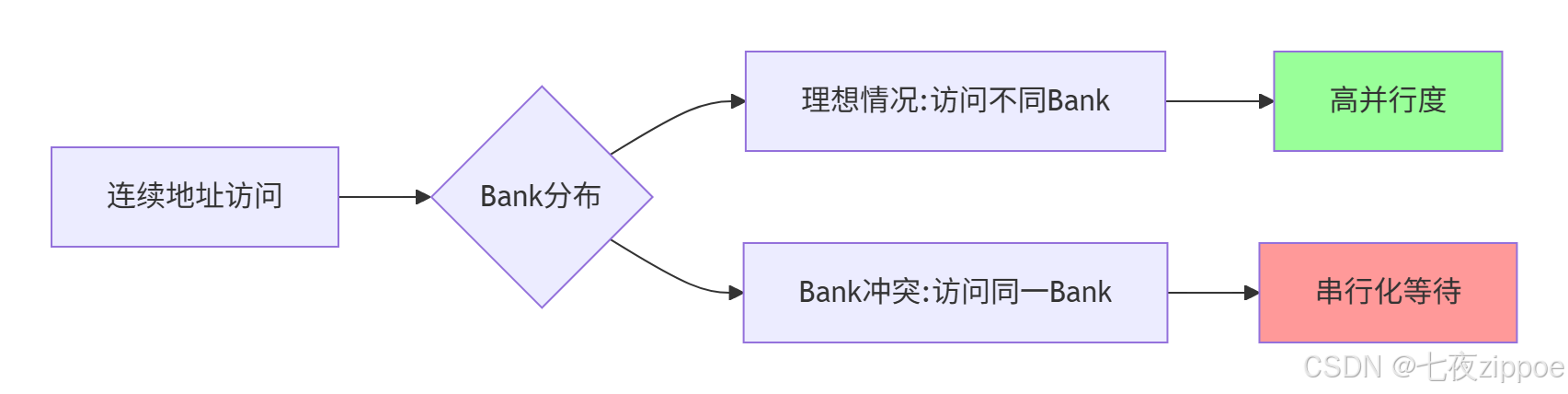
▲ 图3:Bank冲突原理示意图,中级认证必考知识点
实战技巧:通过地址偏移避免2的幂次方步长访问,如将连续访问改为交错访问。
2.3 性能分析与调优方法论
中级认证要求提交性能分析报告,以下是必须掌握的性能分析方法:
2.3.1 性能建模
对于向量加法算子,理论峰值带宽计算公式:
理论带宽 = MIN(内存带宽, 计算带宽)
内存带宽 = 内存频率 × 位宽 × 利用率
计算带宽 = 核心频率 × 计算单元数 × 操作数/周期以Ascend 910为例,HBM2e内存带宽约1.2TB/s,假设利用率为70%,则期望性能约为:
期望带宽 = 1.2 TB/s × 70% = 840 GB/s2.3.2 实际性能分析
cpp
// 性能测试代码框架
void BenchmarkAddCustom() {
auto start = GetTime(); // 获取开始时间
for (int i = 0; i < warmup_iters; ++i) {
// 预热运行
}
start = GetTime();
for (int i = 0; i < test_iters; ++i) {
AddCustomKernel<<<grid, block>>>(x, y, z, tiling);
}
Synchronize(); // 同步等待所有核完成
auto end = GetTime();
double bandwidth = (data_size * 3) / (end - start); // 输入x,y,输出z,共3倍数据量
double utilization = bandwidth / theoretical_peak * 100;
printf("实测带宽: %.2f GB/s, 利用率: %.1f%%\n", bandwidth, utilization);
}代码3:性能评估代码框架,中级认证需要详细性能报告
3. 实战:AddCustom算子中级实现完整指南
3.1 环境准备与工程结构
# 工程目录结构
ascend_operator/
├── CMakeLists.txt # 编译配置
├── include/
│ ├── add_custom.h # 核函数声明
│ └── add_tiling.h # Tiling数据结构
├── src/
│ ├── add_custom.cpp # 核函数实现
│ └── add_custom_main.cpp # 主机端代码
└── test/
├── test_data.py # 测试数据生成
└── benchmark.py # 性能测试3.2 完整代码实现
3.2.1 Tiling策略设计
cpp
// include/add_tiling.h
#ifndef ADD_TILING_H
#define ADD_TILING_H
struct AddTilingData {
int32_t totalLength; // 总数据长度
int32_t blockLength; // 每个核处理的数据块长度
int32_t tileNum; // 总块数
int32_t coreNum; // 核数
int32_t alignment; // 对齐要求(128字节)
// 序列化支持(主机-设备通信)
__host__ __device__ void Serialize(char* buffer) const {
*reinterpret_cast<int32_t*>(buffer) = totalLength;
*reinterpret_cast<int32_t*>(buffer + 4) = blockLength;
// ... 其他字段
}
__host__ __device__ void Deserialize(const char* buffer) {
totalLength = *reinterpret_cast<const int32_t*>(buffer);
blockLength = *reinterpret_cast<const int32_t*>(buffer + 4);
// ... 其他字段
}
};
#endif代码4:Tiling数据结构设计,支持主机设备间序列化
3.2.2 优化版核函数实现
cpp
// src/add_custom.cpp
#include "add_custom.h"
#include "kernel_operator.h"
constexpr int32_t BUFFER_NUM = 2; // 双缓冲
constexpr int32_t VEC_SIZE = 8; // 向量化大小
class AddCustomKernel {
public:
__aicore__ void Init(GlobalTensor<half>& x, GlobalTensor<half>& y,
GlobalTensor<half>& z, const AddTilingData& tiling) {
// 参数校验
if (tiling.blockLength % VEC_SIZE != 0) {
// 错误处理:块长度必须是向量大小的整数倍
return;
}
// 初始化管道与队列
pipe.InitBuffer(inQueueX, BUFFER_NUM, tiling.blockLength * sizeof(half));
pipe.InitBuffer(inQueueY, BUFFER_NUM, tiling.blockLength * sizeof(half));
pipe.InitBuffer(outQueueZ, BUFFER_NUM, tiling.blockLength * sizeof(half));
// 保存参数
blockLength = tiling.blockLength;
totalLength = tiling.totalLength;
tileNum = totalLength / blockLength;
// 保存全局内存指针
xGlobal = x;
yGlobal = y;
zGlobal = z;
}
__aicore__ void Process() {
int32_t loopCount = tileNum;
// 主流水线循环
for (int32_t i = 0; i < loopCount + BUFFER_NUM - 1; ++i) {
// 阶段1: 数据加载(如果可以)
if (i < loopCount) {
LocalTensor<half> xLocal = inQueueX.AllocTensor<half>();
LocalTensor<half> yLocal = inQueueY.AllocTensor<half>();
// 向量化数据加载
DataLoad(xLocal, xGlobal, i);
DataLoad(yLocal, yGlobal, i);
pipe.InProduce();
}
// 阶段2: 计算(如果有足够数据)
if (i >= BUFFER_NUM - 1) {
int32_t computeIdx = i - (BUFFER_NUM - 1);
LocalTensor<half> xLocal = inQueueX.Dequeue<half>();
LocalTensor<half> yLocal = inQueueY.Dequeue<half>();
LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>();
// 向量化加法计算
VectorizedAdd(zLocal, xLocal, yLocal);
pipe.OutProduce();
pipe.InConsume(); // 释放输入缓冲区
// 阶段3: 结果回写
DataStore(zGlobal, zLocal, computeIdx);
pipe.OutConsume(); // 释放输出缓冲区
}
}
}
private:
__aicore__ void DataLoad(LocalTensor<half>& dst,
GlobalTensor<half>& src, int32_t blockIdx) {
int32_t offset = blockIdx * blockLength;
// 分多次向量化加载,避免单次加载数据量过大
for (int32_t i = 0; i < blockLength; i += VEC_SIZE * 4) {
half8_t data0 = VecLoad<half8_t>(src + offset + i);
half8_t data1 = VecLoad<half8_t>(src + offset + i + VEC_SIZE);
// ... 加载更多数据
VecStore(dst + i, data0);
VecStore(dst + i + VEC_SIZE, data1);
// ... 存储更多数据
}
}
__aicore__ void VectorizedAdd(LocalTensor<half>& z,
LocalTensor<half>& x,
LocalTensor<half>& y) {
// 完全向量化计算
for (int32_t i = 0; i < blockLength; i += VEC_SIZE) {
half8_t vecX = VecLoad<half8_t>(x + i);
half8_t vecY = VecLoad<half8_t>(y + i);
half8_t vecZ = VecAdd(vecX, vecY);
VecStore(z + i, vecZ);
}
}
__aicore__ void DataStore(GlobalTensor<half>& dst,
LocalTensor<half>& src, int32_t blockIdx) {
int32_t offset = blockIdx * blockLength;
// 向量化存储
for (int32_t i = 0; i < blockLength; i += VEC_SIZE) {
half8_t data = VecLoad<half8_t>(src + i);
VecStore(dst + offset + i, data);
}
}
private:
TPipe pipe;
GlobalTensor<half> xGlobal, yGlobal, zGlobal;
int32_t blockLength, totalLength, tileNum;
TQue<QuePosition::IN, BUFFER_NUM> inQueueX, inQueueY;
TQue<QuePosition::OUT, BUFFER_NUM> outQueueZ;
};
// 核函数入口
extern "C" __global__ __aicore__ void add_custom(__gm__ half* x, __gm__ half* y,
__gm__ half* z, __gm__ uint8_t* tiling) {
AddTilingData tilingData;
tilingData.Deserialize(reinterpret_cast<const char*>(tiling));
GlobalTensor<half> xGlobal(x);
GlobalTensor<half> yGlobal(y);
GlobalTensor<half> zGlobal(z);
AddCustomKernel kernel;
kernel.Init(xGlobal, yGlobal, zGlobal, tilingData);
kernel.Process();
}代码5:完整优化版AddCustom算子实现,包含所有中级认证要求特性
3.3 编译与测试
bash
# 编译脚本
#!/bin/bash
# build.sh
export ASCEND_HOME=/usr/local/Ascend
export DDK_PATH=$ASCEND_HOME/ddk
# 编译核函数
aicc -c src/add_custom.cpp -o build/add_custom.o \
-I include -I $DDK_PATH/include \
-std=c++11 -O3
# 链接生成算子包
aicc -o build/add_custom.json build/add_custom.o \
-L $DDK_PATH/lib -lascendcl
echo "编译完成,算子包: build/add_custom.json"代码6:编译脚本,注意优化等级-O3
4. 高级优化与故障排查
4.1 性能优化进阶技巧
4.1.1 计算强度优化
计算强度(Compute Intensity)指每次内存访问对应的计算操作数。优化公式:
计算强度 = 总计算操作数 / 总内存访问字节数对于加法算子,理想情况下应尽可能重用已加载的数据:
cpp
// 计算强度优化示例:融合操作
__aicore__ void FusedOperation(LocalTensor<half>& out,
LocalTensor<half>& in1,
LocalTensor<half>& in2) {
// 一次加载,多次计算(如先加后乘)
for (int i = 0; i < blockLength; i += VEC_SIZE) {
half8_t vec1 = VecLoad<half8_t>(in1 + i);
half8_t vec2 = VecLoad<half8_t>(in2 + i);
half8_t result1 = VecAdd(vec1, vec2); // 第一次计算
half8_t result2 = VecMul(result1, vec2); // 第二次计算,重用数据
VecStore(out + i, result2);
}
}4.1.2 数据预取优化
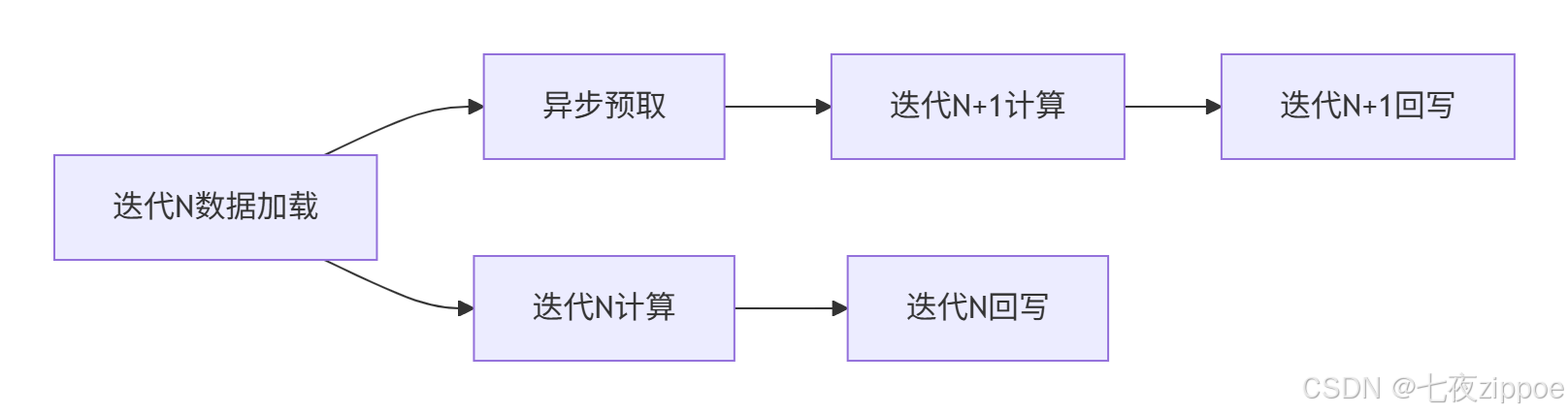
▲ 图4:数据预取优化时序图,隐藏内存访问延迟
4.2 常见故障排查指南
4.2.1 内存访问错误
症状:运行时报错"Memory Access Fault"
排查步骤:
-
检查所有指针是否在有效范围内
-
验证内存对齐是否符合128字节要求
-
使用
GetBlockIdx()和GetBlockDim()确认核间任务划分正确
cpp
// 调试技巧:添加边界检查
__aicore__ void SafeDataLoad(GlobalTensor<half>& src, int32_t offset) {
if (offset + blockLength > totalLength) {
// 处理边界情况
return;
}
// 正常加载...
}4.2.2 性能不达标分析
排查流程:
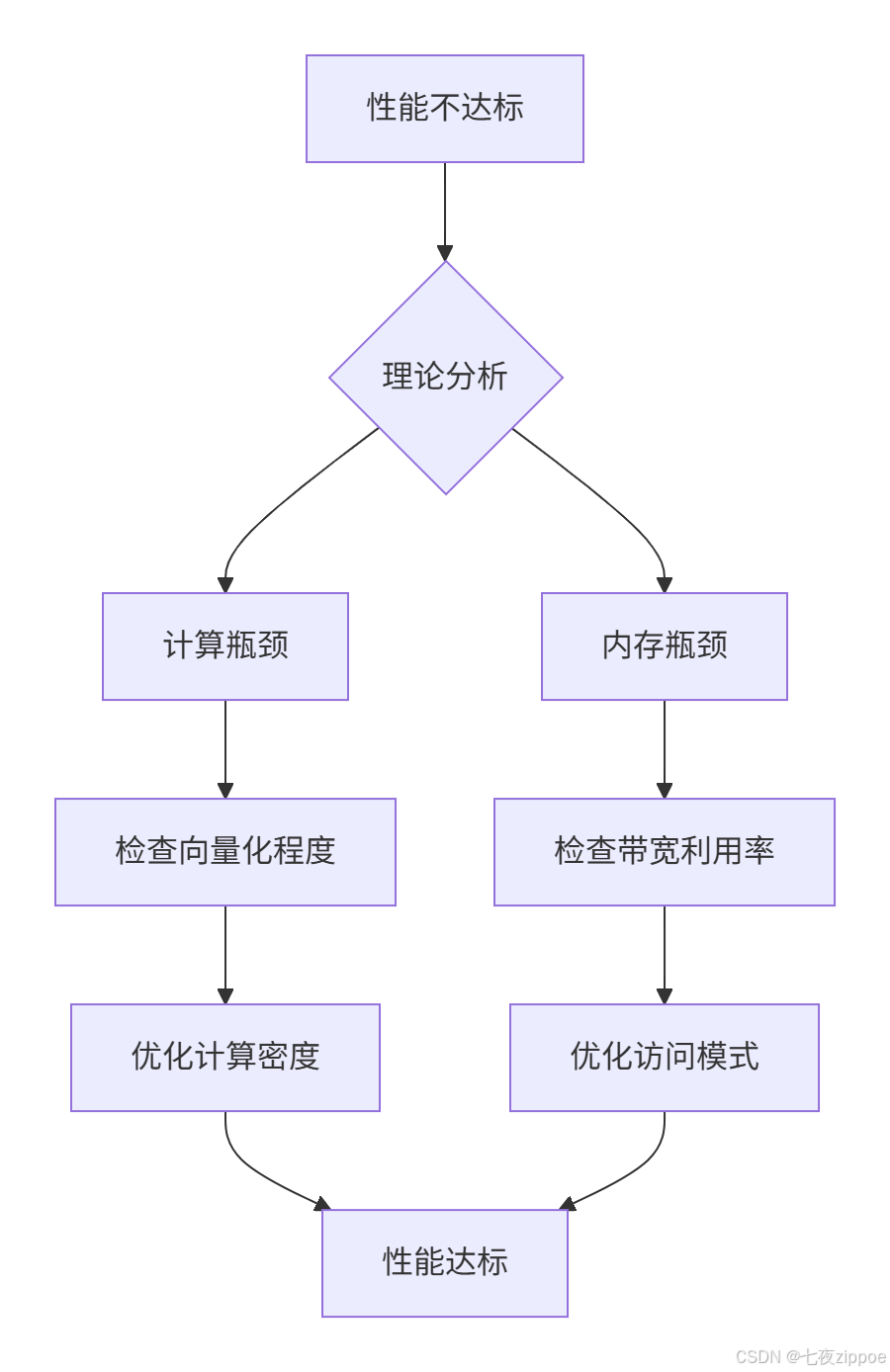
▲ 图5:性能问题排查决策树
具体工具使用:
bash
# 使用Profiling工具分析性能瓶颈
msprof --application=your_operator \
--output=profiling_result \
--aic-metrics=MemoryBandwidth,ComputeUtilization5. 认证备考策略与实战建议
5.1 备考时间规划
根据经验,中级认证建议投入40-60小时系统学习:
-
前20小时:掌握基础API和编程模型
-
中间20小时:实现多个典型算子并优化性能
-
最后20小时:模拟考试环境,练习性能调优
5.2 考试重点提示
-
性能指标是第一优先级:功能正确但性能不达标直接不通过
-
代码规范占20%分数:包括注释、命名、结构清晰度
-
必须有错误处理:对边界条件、参数校验的完备性
5.3 持续学习路径
通过中级认证后,建议深入学习:
-
多算子融合技术
-
动态形状支持
-
跨平台性能可移植性
6. 总结
Ascend C算子开发中级认证是衡量开发者高性能计算能力的试金石。通过本文的深度解析,你应该理解到中级认证的核心价值在于从功能实现到性能优化的思维转变。
关键收获:
-
双缓冲流水线是性能优化的基础
-
向量化编程是发挥硬件性能的关键
-
系统化的性能分析方法比盲目调优更有效
讨论问题:在实际项目中,你是否遇到过算子性能无法达到理论峰值的情况?最终是如何定位和解决的?欢迎分享你的实战经验!
7. 参考资源
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接 : https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!