Android 12 作为安卓图形渲染架构的重要迭代版本,核心推出了 BLASTBufferQueue(简称 BLAST)------ 全称为 Buffer Queue Launched At SurfaceFlinger,其本质是对 Android 传统 BufferQueue 架构的重构,核心目标是解决多窗口、高刷新率场景下 SurfaceFlinger(SF)负载过高、IPC 通信开销大的问题。
一、BLASTBufferQueue 的诞生背景:传统 BufferQueue 的核心痛点
在 Android 12 之前,BufferQueue(安卓图形渲染的核心缓冲区队列)的所有权和管理权完全归属 SurfaceFlinger(SF)进程 ------SF 作为系统级合成器,集中管理所有 App 窗口的 BufferQueue,这一设计在早期单窗口、低刷新率场景下可满足需求,但在多窗口、120Hz+ 高刷、折叠屏等复杂场景下暴露了三大核心问题:
1. 频繁 IPC 通信带来的性能损耗
App 进程每次申请、释放、提交 HardwareBuffer,都需要向 SF 发起跨进程 IPC 请求(如 ANativeWindow_lock/unlockAndPost)。以 120Hz 高刷场景为例,单 App 每秒需发起 240 次以上 IPC 调用,大量时间消耗在进程间通信和数据拷贝上,直接导致渲染延迟增加。
2. SF 成为性能瓶颈
所有 App 的 BufferQueue 均由 SF 集中管理,SF 不仅要处理图层合成,还要响应所有 App 的缓冲区分配请求、维护缓冲区生命周期。在多窗口场景下,SF 负载急剧升高,易出现 "合成卡顿""掉帧" 等问题。
3. 多窗口适配灵活性差
传统 BufferQueue 由 SF 主导分配策略,App 无法根据自身渲染需求(如游戏高帧率、视频播放低延迟)灵活调整缓冲区数量、规格,只能被动接收 SF 分配的 HardwareBuffer,适配复杂场景时效率低下。
为解决上述问题,Android 12 重构了 BufferQueue 架构,推出 BLASTBufferQueue,核心是将 BufferQueue 的 "管理权" 从 SF 下移到 App 进程,让 App 自主管理缓冲区,SF 仅作为 "消费者" 接收缓冲区并完成合成。
二、BLASTBufferQueue 核心设计理念
1. 核心定义
BLASTBufferQueue 是 Android 12 为 Surface 新增的 BufferQueue 实现,本质是 "App 进程内的 BufferQueue 代理 + SF 进程的轻量级消费者",核心目标是:
- 将 BufferQueue 所有权从 SF 迁移至 App 进程;
- 消除 App 与 SF 之间频繁的缓冲区管理 IPC;
- 让 App 主导 HardwareBuffer 的分配决策,适配自身渲染需求。
2. 核心架构:分层解耦
BLASTBufferQueue 架构分为两层,彻底解耦 App 与 SF 的缓冲区管理依赖:
- App 进程侧:创建并管理 BLASTBufferQueue 实例,自主决策 HardwareBuffer 的分配规格、数量、时机;
- SF 进程侧:仅保留 "BLASTConsumer" 轻量级组件,不参与缓冲区管理,仅接收 App 提交的 HardwareBuffer 句柄并完成合成。
三、BLASTBufferQueue 底层工作原理
1. BufferQueue 归属权迁移:从 SF 到 App 进程
BLASTBufferQueue 最核心的变化是:App 进程在创建 Surface 时,直接在自身进程内创建 BLASTBufferQueue 实例,而非向 SF 请求创建 BufferQueue。App 进程成为 BufferQueue 的直接管理者,SF 不再持有 App 侧 BufferQueue 的引用。
2. HardwareBuffer 分配流程(Android 12+ BLAST 模式)
BLASTBufferQueue 并未改变 HardwareBuffer 的 "实际分配者"(仍为系统 Gralloc 模块),但彻底改变了 "分配决策者":
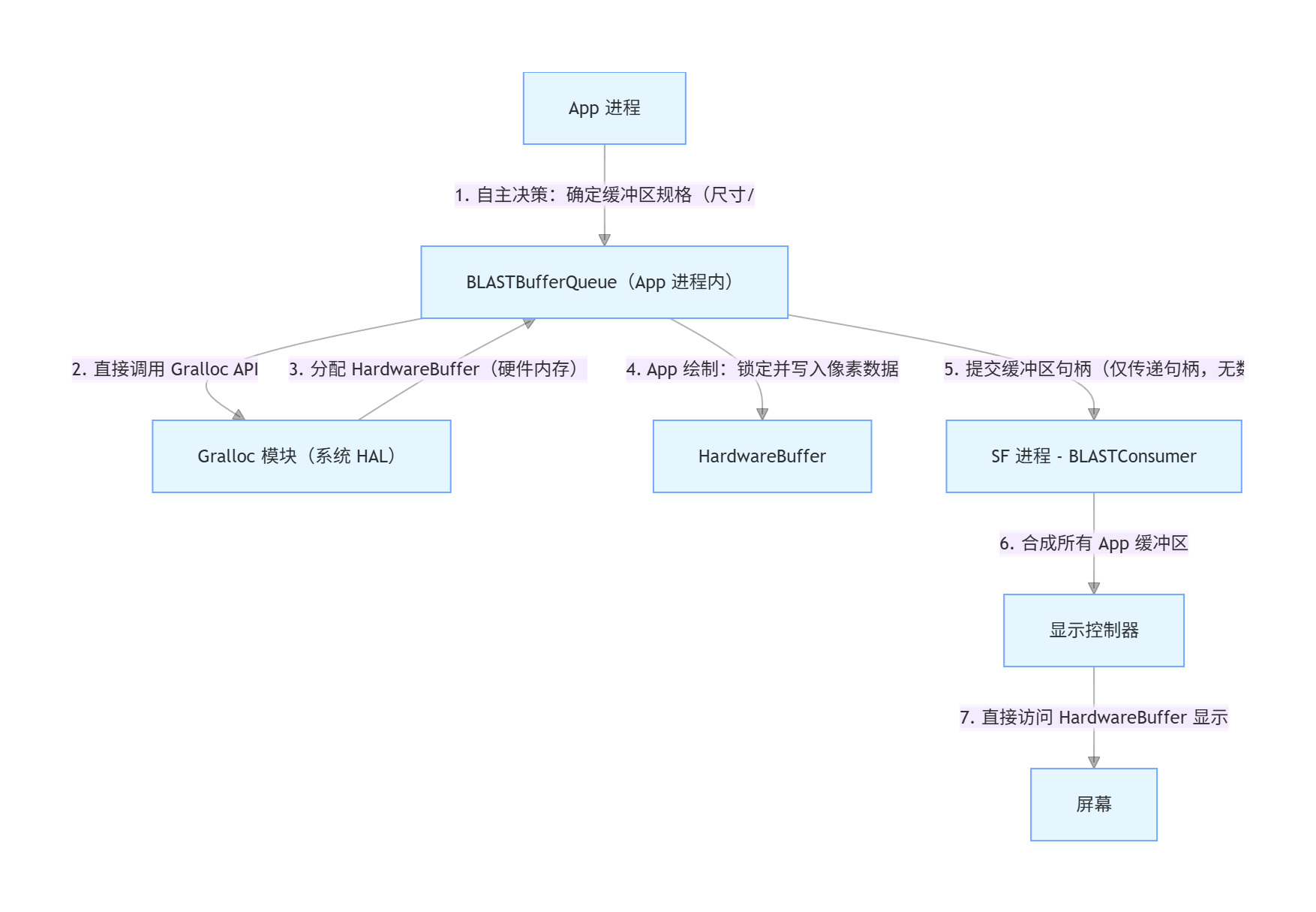
关键步骤解析:
- 分配决策自主化:App 进程的 BLASTBufferQueue 根据自身渲染需求(如游戏分配 3 个缓冲区做三缓冲、普通 UI 分配 2 个做双缓冲),自主决定 HardwareBuffer 的规格(宽度 / 高度 / 像素格式)、数量;
- 跳过 SF 直接调用 Gralloc:App 进程通过 BLASTBufferQueue 直接向系统 Gralloc 模块发起 HardwareBuffer 分配请求,无需向 SF 发起 IPC;
- 仅传递句柄,无数据拷贝:App 绘制完成后,仅将 HardwareBuffer 的 "原生句柄(Handle)" 传递给 SF 的 BLASTConsumer,而非拷贝缓冲区数据;
- SF 仅做合成:SF 接收句柄后,直接访问 Gralloc 分配的 HardwareBuffer 完成图层合成(合成也大多是硬件合成--hwc 合成),不参与任何缓冲区管理操作。
3. 与 SF 的交互逻辑:极简 IPC
BLASTBufferQueue 大幅简化了 App 与 SF 的 IPC 通信:
- 传统模式:App 每帧需发起 "申请缓冲区 + 提交缓冲区" 两次 IPC;
- BLAST 模式:仅在 "首次创建 Surface""窗口尺寸变化" 时发起少量 IPC,每帧仅需传递 HardwareBuffer 句柄(轻量级数据),IPC 开销降低 90% 以上。
四、传统 BufferQueue vs BLASTBufferQueue 核心差异
| 维度 | 传统 BufferQueue(Android 12 前) | BLASTBufferQueue(Android 12+) |
|---|---|---|
| BufferQueue 归属 | SF 进程 | App 进程 |
| HardwareBuffer 分配决策者 | SF 进程 | App 进程(BLASTBufferQueue) |
| HardwareBuffer 实际分配者 | Gralloc 模块 | Gralloc 模块(不变) |
| IPC 通信频率 | 每帧 2 次以上 | 仅窗口创建 / 尺寸变化时少量调用 |
| SF 角色 | 缓冲区管理者 + 消费者 | 仅轻量级消费者 |
| 缓冲区策略灵活性 | 低(SF 主导) | 高(App 自主调整) |
关键澄清:"App 直接分配 HardwareBuffer" 是误区
很多开发者误以为 BLASTBufferQueue 让 App "直接分配" HardwareBuffer,实则不然:
- App 仅主导 "分配决策":App 决定分配多少个、什么规格的 HardwareBuffer,但不直接操作硬件内存;
- 实际分配者仍是 Gralloc:HardwareBuffer 是硬件内存(ION 内存),必须由系统级 Gralloc 模块(HAL 层)分配,App 无法绕过 Gralloc 直接分配硬件内存;
- SF 彻底退出管理:SF 不再参与 App 侧缓冲区的分配、释放,仅接收句柄并合成。
五、BLASTBufferQueue 带来的核心收益
1. 显著降低渲染延迟
消除了 App 与 SF 之间频繁的缓冲区管理 IPC,高刷场景下(120Hz)单帧渲染延迟可降低 1~3ms,整体触控到显示的延迟(TTI)降低 10%~20%,游戏、视频等低延迟场景体验提升明显。
2. 减轻 SF 负载
SF 不再管理所有 App 的 BufferQueue,仅专注于图层合成,多窗口、折叠屏场景下 SF 负载降低 30% 以上,系统整体流畅度提升。
3. 提升 App 适配灵活性
App 可根据自身场景灵活调整缓冲区策略:
- 游戏 App:分配 3 个 HardwareBuffer 实现三缓冲,提升高帧率稳定性;
- 视频 App:减少缓冲区数量,降低内存占用,提升帧同步效率;
- 普通 UI App:按需分配缓冲区,平衡性能与功耗。
4. 优化内存管理
BLASTBufferQueue 支持 App 进程内的 HardwareBuffer 复用,避免重复分配 / 释放硬件内存;同时,系统可根据 App 前台 / 后台状态,更精准地回收闲置缓冲区,降低整体内存占用。
六、对开发者的实际影响
1. 应用层几乎无感知
对于普通 App(基于 View/Compose 开发),BLASTBufferQueue 是系统底层的透明优化,开发者无需修改代码即可享受性能提升。
2. NDK / 原生开发需注意的调整
对于基于 NDK 操作 Surface/ANativeWindow 的开发者(如音视频、游戏、跨平台渲染),需注意两点:
- 无需修改核心 API(
ANativeWindow_lock/unlockAndPost仍可用),系统会自动将传统 BufferQueue 替换为 BLASTBufferQueue; - 可通过
ANativeWindow_setBuffersCount自主调整缓冲区数量,充分利用 BLAST 的灵活性(传统模式下该接口效果受限)。
3. 兼容性注意事项
- Android 12 及以上默认启用 BLASTBufferQueue,Android 11 及以下仍使用传统 BufferQueue;
- 若 App 需兼容低版本,无需针对 BLAST 做特殊适配,系统会自动降级为传统模式。
七、总结与未来演进
BLASTBufferQueue 是 Android 图形渲染架构的一次核心重构,其本质是 "将 BufferQueue 管理权从 SF 下移到 App 进程",核心价值在于:
- 解耦:App 与 SF 不再强绑定缓冲区管理,消除频繁 IPC 开销;
- 自主化:App 主导 HardwareBuffer 分配决策,适配复杂场景更灵活;
- 高性能:降低渲染延迟,减轻 SF 负载,提升系统整体流畅度。
从未来演进来看,Android 13/14 进一步强化了 BLASTBufferQueue 的能力(如支持折叠屏动态分辨率、硬件叠加层优化),而 BLAST 的设计思路也印证了安卓图形架构的核心趋势:让 App 更自主地管理渲染资源,SF 聚焦于核心合成能力,分层解耦提升整体性能。