目录
[2.1 SageAttention:给注意力机制"瘦身"](#2.1 SageAttention:给注意力机制“瘦身”)
[2.2 SLA:只看重点的"稀疏眼"](#2.2 SLA:只看重点的“稀疏眼”)
[2.3 rCM:少走弯路的"捷径"](#2.3 rCM:少走弯路的“捷径”)
[2.4 W8A8量化:全面的"轻量化"](#2.4 W8A8量化:全面的“轻量化”)

🎬 攻城狮7号 :个人主页
🔥 个人专栏 :《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 清华&生数开源TurboDiffusion
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
**做过AI视频的朋友都有过这种煎熬:为了生成几秒钟的视频,你得盯着进度条看上好几分钟,甚至半小时。**如果效果不满意,调整提示词重来,又是漫长的等待。
这种"抽卡式"的创作体验,极其消磨热情。
但在2025年的尾声,清华大学TSAIL团队和生数科技联手扔出了一颗重磅炸弹------TurboDiffusion。这个开源框架号称能把视频生成速度提升200倍。以前生成一个视频要等一顿饭的功夫,现在可能只需要眨一下眼。
这不仅仅是快了一点,而是从"离线渲染"到"实时预览"的质变。

一、从"慢动作"到"闪电侠":速度提升有多离谱?
我们直接看数据,不玩虚的。
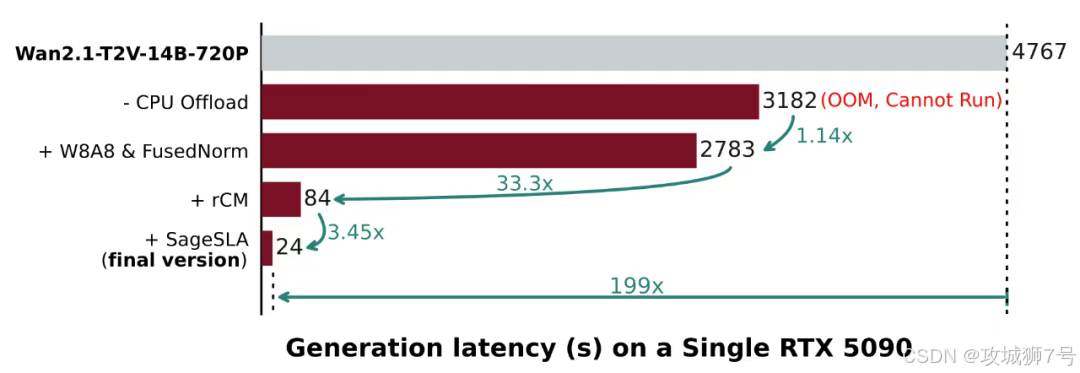
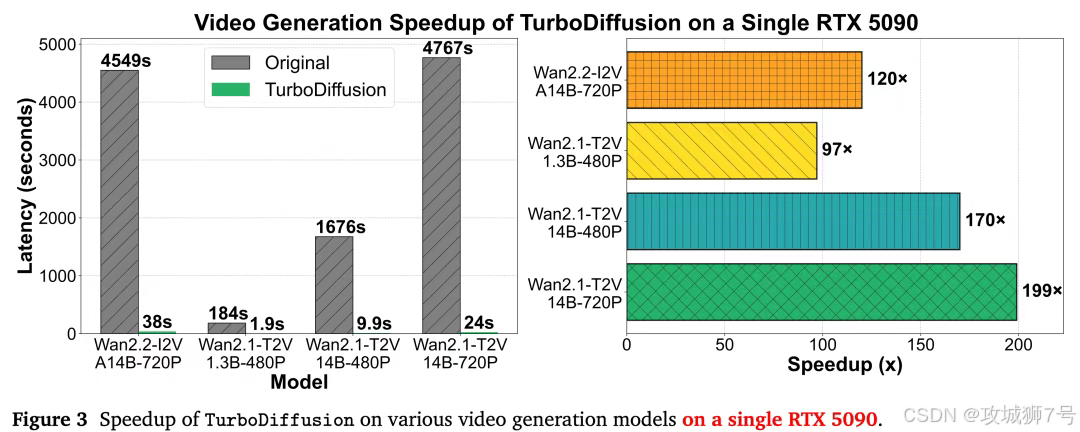
在单张RTX 5090显卡上(这是很多高端玩家和工作室能买得起的配置),对比一下使用TurboDiffusion前后的差距:

(1)文生视频(1.3B模型,480P):
* 以前:184秒(3分多钟,够泡一碗面了)。
* 现在:1.9秒(刚点完回车,视频就出来了)。
* 提升:97倍。
(2)图生视频(14B大模型,720P):
* 以前:4549秒(1个多小时,甚至可以睡一觉)。
* 现在:38秒(回几条微信的时间)。
* 提升:119倍。
在高分辨率场景下,比如1080P视频,它甚至能把原本需要15分钟(900秒)的生成时间压缩到8秒。这意味着,AI视频生成终于跟上了人类的思维速度------你有一个想法,AI立刻就能让你看到画面。
最关键的是,这种"快"不是以牺牲画质为代价的。对比视频显示,加速后的画面在光影质感、动态流畅度上,和原版几乎肉眼看不出区别。
二、扒一扒黑科技:它是怎么做到的?
TurboDiffusion之所以能跑这么快,是因为它给笨重的扩散模型(Diffusion Model)装上了"四个涡轮增压器"。
这四项技术环环相扣,专门解决视频生成中"算得慢、存不下、步数多"的老大难问题。
2.1 SageAttention:给注意力机制"瘦身"
注意力机制(Attention)是AI模型里最费算力的部分。TurboDiffusion用了一种叫SageAttention的技术,把原本精细的计算过程进行了"低比特量化"。
简单说,就是把复杂的浮点数运算变成了简单的整数运算(INT8甚至INT4),同时用巧妙的方法保证精度不丢失。这一招直接让计算速度快了3-5倍,显存占用还砍了一半。
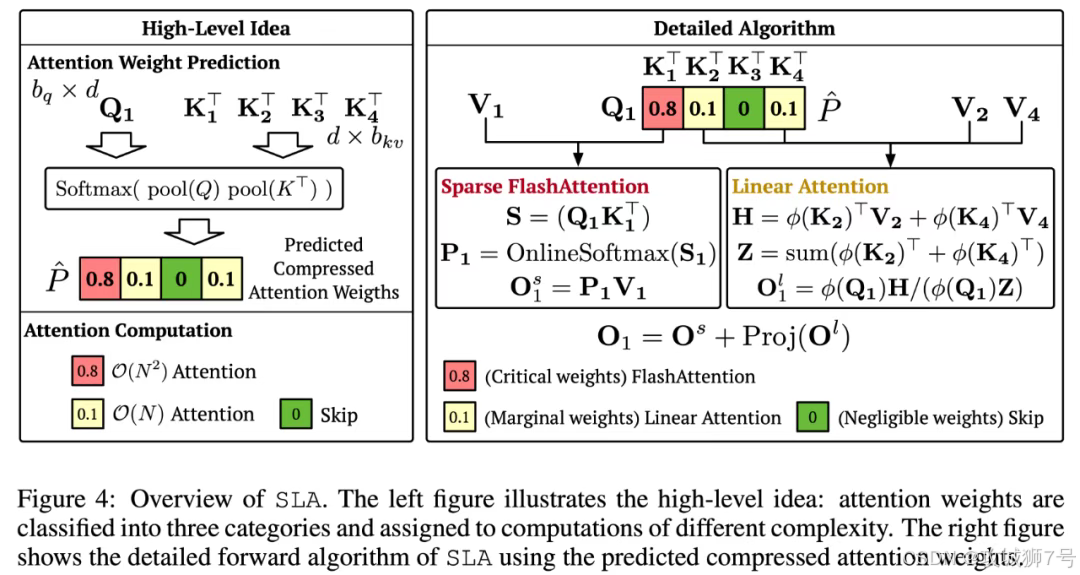
2.2 SLA:只看重点的"稀疏眼"
除了算得快,还得算得少。SLA(稀疏线性注意力)技术让模型学会了"抓重点"。在处理视频时,它不需要盯着每一个像素点死算,而是只关注那些重要的信息。
而且,SLA和上面的SageAttention是可以叠加使用的。一个负责算得快,一个负责算得少,双管齐下,速度自然起飞。
2.3 rCM:少走弯路的"捷径"
传统的扩散模型生成视频,需要一步步"去噪",通常要走50到100步。
TurboDiffusion引入了rCM蒸馏技术,教模型"走捷径"。原本需要100步才能画完的画,现在只需要3到4步就能画个八九不离十。这就好比老司机开车,不用看着导航一步步挪,直接抄近道就到了终点。
2.4 W8A8量化:全面的"轻量化"
除了核心的注意力层,模型里还有大量的线性层。TurboDiffusion对这些部分也进行了全面的8比特量化(W8A8)。这就像是把汽车上所有不必要的重零件都换成了碳纤维,整体载重轻了,跑起来自然就快了。
三、这对我们意味着什么?
技术细节可能有些枯燥,但TurboDiffusion带来的改变是实实在在的。
(1)消费级显卡也能玩大片了
以前想玩高质量的AI视频,你可能得去租昂贵的A100/H100服务器。现在,有了TurboDiffusion,一张家用高端显卡(如RTX 4090/5090)就能在本地秒级出片。这大大降低了个人创作者的门槛。
(2)实时交互成为可能
当生成时间压缩到几秒钟时,全新的玩法就出现了。
**比如"实时导演模式":**你一边说话调整剧本,屏幕上的视频就一边实时跟着变。或者在玩游戏时,NPC的剧情动画完全由AI实时生成,不再是死板的预制片段。
(3)国产算力的福音
值得一提的是,TurboDiffusion采用的低比特、稀疏化技术,对显存带宽的要求大大降低,这天然适配很多国产AI芯片。对于渴望建立自主可控AI基础设施的中国来说,这是一个极大的利好。
结语
如果说2024年是AI视频生成的"画质元年",那么2025年或许就是"速度元年"。
TurboDiffusion的开源,不仅是一次技术上的秀肌肉,更像是一把钥匙,打开了"实时AIGC"的大门。当等待被消除,想象力就成了唯一的限制。
现在,未来已来,而且只差2秒。
TurboDiffusion项目地址:
https://github.com/thu-ml/TurboDiffusion?tab=readme-ov-file
论文地址:
https://arxiv.org/pdf/2512.16093
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!