最近在做一些大模型相关的实践时,我刻意给自己加了一个限制条件:不做"只靠通用大模型"的方案。原因很简单,在很多真实业务和专业场景里,通用模型的语言能力很强,但对"具体资料""内部文档""专业约束"的理解非常不稳定,回答往往看起来对,实际上不可用。
这次我做了一个完整的小案例,核心目标只有一个:让模型只基于我给它的专业资料来回答问题。整体方案并不复杂,但每一环都很关键:文档解析 → 知识库构建 → 智能体工作流 → 专业问答闭环。
这个过程中,我选择了TextIn负责文档解析,火山引擎的扣子负责知识库和智能体,底层模型使用的是豆包大模型。
先说为什么第一步一定要选一个"靠谱的文档解析"。
很多人一上来就做 RAG(Retrieval-Augmented Generation,检索增强生成),但实际踩坑最多的地方并不是向量库,也不是模型参数,而是原始文档被解析成了什么样。如果文本顺序是乱的、标题层级丢失、表格被拆成一堆无意义的行,那么后面切片、召回、生成再怎么调,也只是"在错误材料上做精细加工"。
我一开始也测试过传统方案,比如直接用 PDF 提取文本、OCR 后再做规则清洗。结果非常直观:结构信息几乎全部丢失,后续要靠大量人工补救,整体成本反而更高。
这也是我最终选用 TextIn 的原因,它提供了一个的接口:
https://api.textin.com/ai/service/v1/pdf_to_markdown
核心能力只有一件事,把 PDF 文档稳定地解析成结构化 Markdown。
代码我使用的是官方提供的demo,够用省事,现在谁在造轮子啊
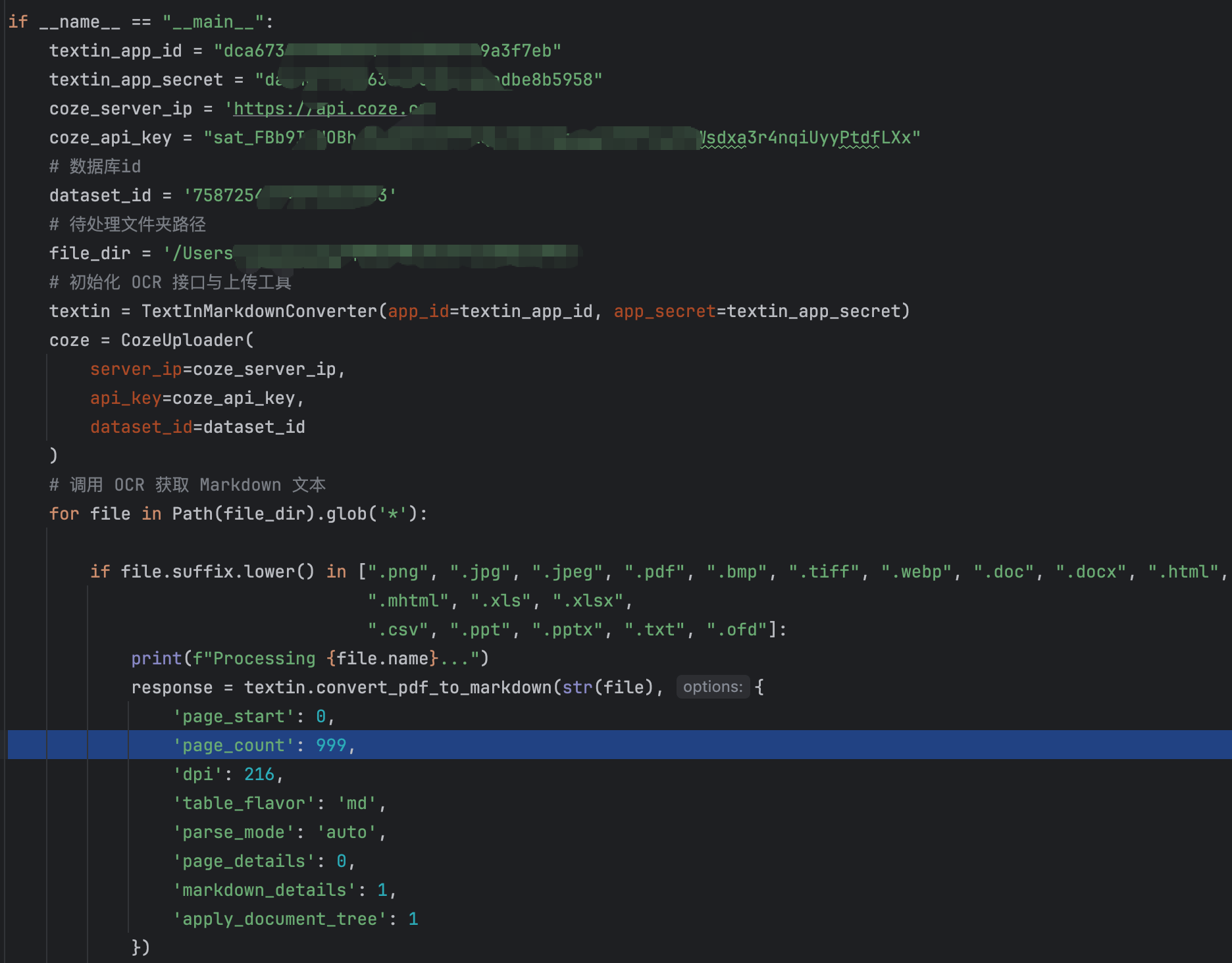
当然TextIn的作用不仅仅是这样,还有很多能实现的功能,看图

在实际使用时,有两个点需要明确强调:
-
接口请求头里必须包含 x-ti-app-id 和 x-ti-secret-code,这是鉴权的关键;
-
返回结果直接是 Markdown,而不是"看起来像文本的一坨字符串"。
我用 Python 写了一个很简单的脚本,流程非常清晰:读取 PDF → 调用 TextIn 接口 → 拿到 Markdown → 转换为Base64 编码 →作为文件或文本上传到扣子的知识库。整个过程不需要复杂逻辑,更不需要人工介入,非常适合自动化处理。
由于我是本地上传,所以选择使用 Base64 编码后再上传,也可以用url或者直接手动上传文件再倒入知识库;
为了更直观,我还做了一个简单的时间对比测试,用同一份中等体量的 PDF 文档,测试传统解析方式和 TextIn 的整体耗时(包含清洗成本):
| 解析方式 | 单文档处理时间 | 结构完整度 | 是否适合直接入库 |
|---|---|---|---|
| 传统 PDF 文本抽取 | 20~30 秒 | 低 | 否 |
| OCR + 规则清洗 | 1~2 分钟 | 中 | 勉强 |
| TextIn PDF→Markdown | 5~8 秒 | 高 | 是 |
这里"适合直接入库"这一项非常关键,因为它决定了后面的系统是不是能规模化。
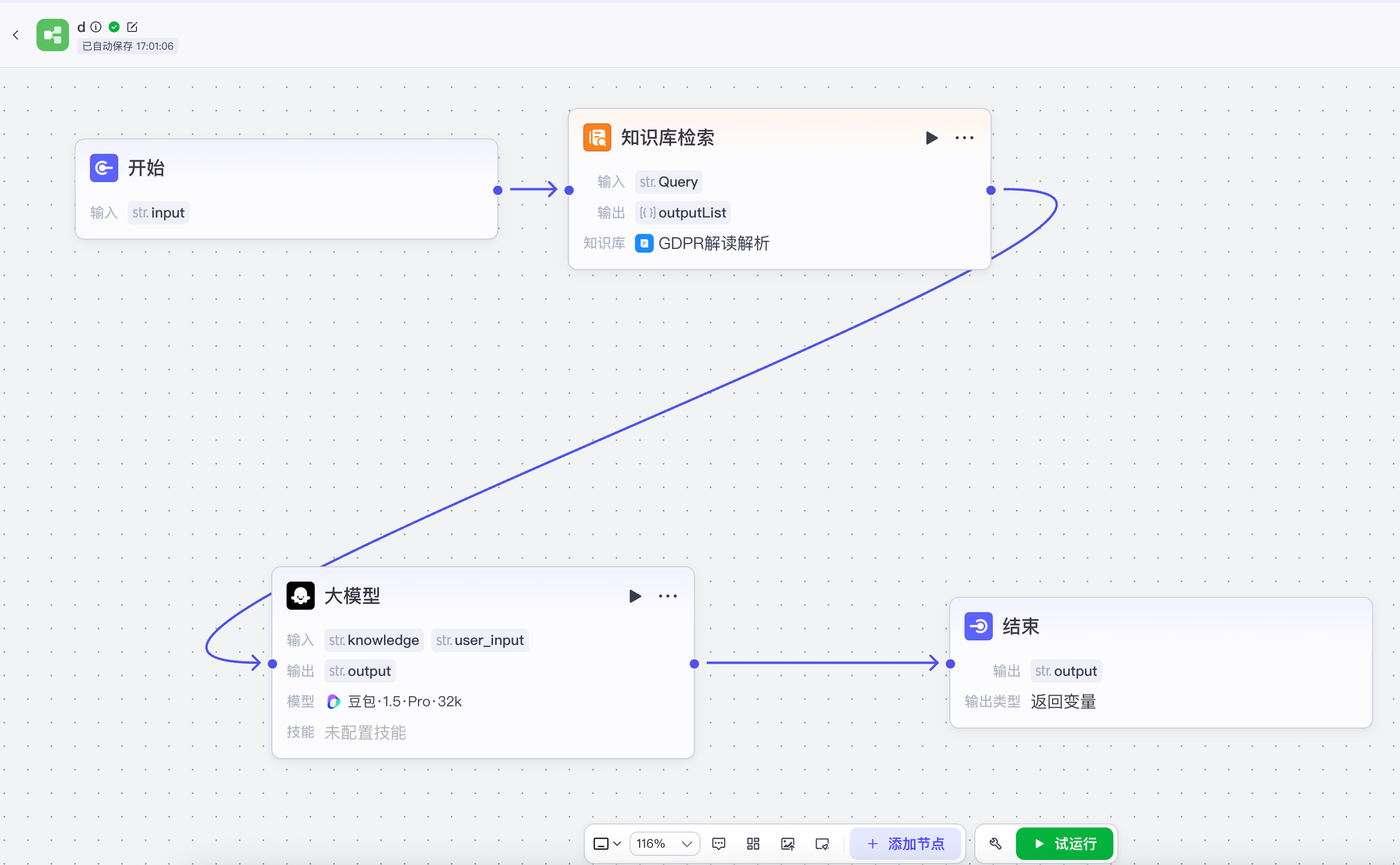
完成文档解析后,下一步就是扣子智能体。
在 扣子 里,我没有做任何花哨的配置,而是走了一条非常标准、也非常可靠的工作流:用户提问 → 检索知识库 → 召回相关片段 → 将问题和召回内容一起交给豆包大模型生成答案。这个流程看起来简单,但它和"直接问模型"的差异是本质性的。
看看对比效果,先看豆包吧

在看我的智能体
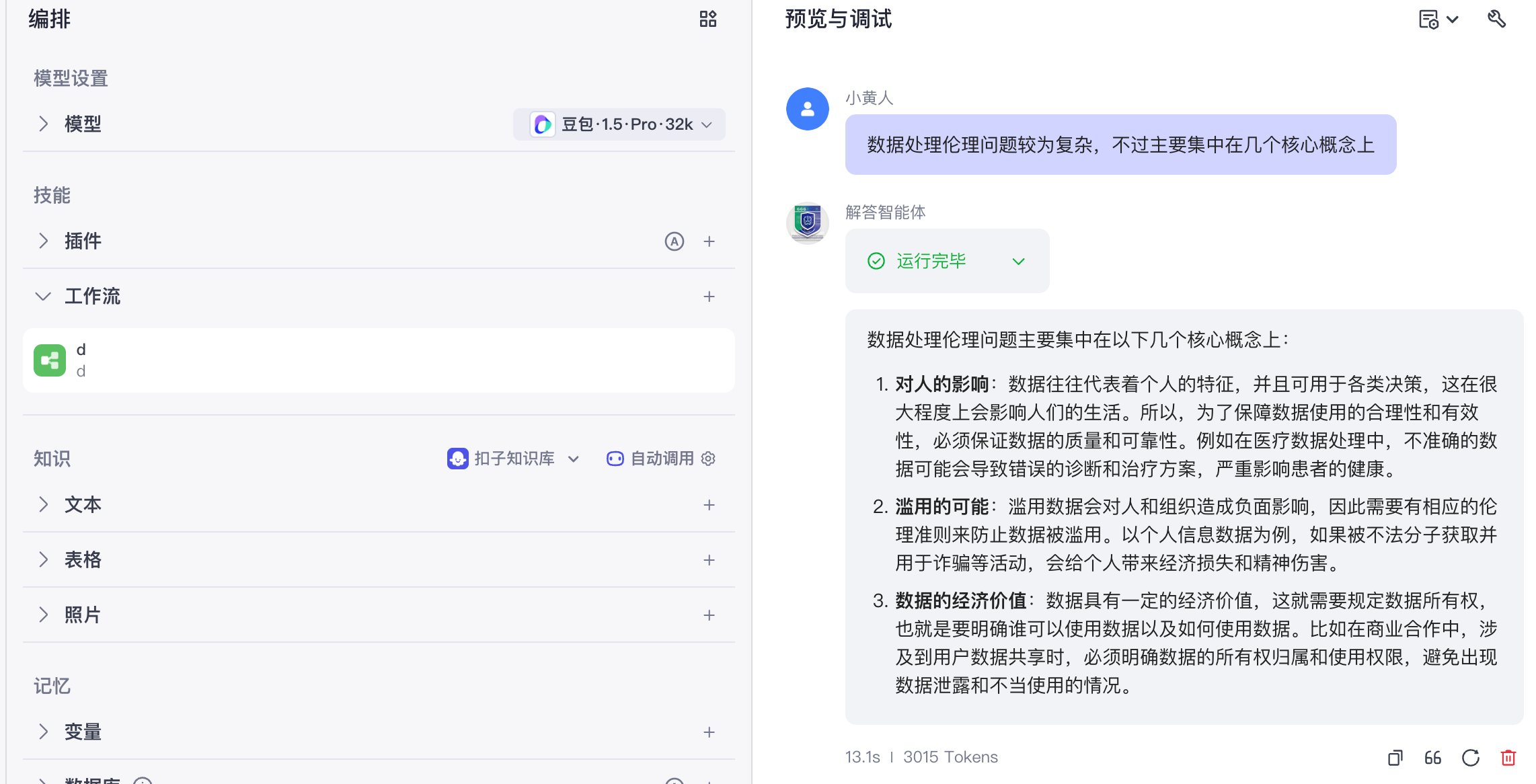
最后看标准答案

通用大模型的问题在于,它更擅长"总结已知世界",而不是"遵守你给的资料"。而一旦引入知识库,模型的角色就发生了变化,它不再是自由发挥,而是在受约束的信息空间里进行推理和表达。
在实际测试中,同样一个专业问题:
不接知识库时,模型给出的回答往往泛泛而谈,术语看似正确,但细节不对;
接入知识库后,回答明显带有"文档原文的风格和约束",可用性差异非常明显。
这个方案跑通之后,可扩展的方向就非常自然了,比如:
-
批量处理和批阅学员的答卷,把标准答案和评分规则放进知识库;
-
把智能体接入企业微信或飞书,用于自动解答学习群里的高频专业问题;
(我没时间了,再给我点时间,我一定让学习群里,多个基于textin+扣子的"助教")
-
持续增量更新文档,让智能体随资料演进,而不是频繁改 Prompt。
用了 TextIn 之后,我就一个感觉:它不是那种花里胡哨的 AI 产品,而是偏工程和系统的基础工具。现在大家都盯着大模型,但文档解析这个环节其实很容易被忽略,可这步要是做顺了,后面搞知识库、智能体、自动化流程都会轻松不少。
要是你在做 RAG、智能体,或者是那种基于专业资料的问答系统,我劝你一句:先把文档解析搞定,再去琢磨模型和智能体的设计。反正 TextIn 帮我省了超多时间,也让整个方案能稳定跑下去,挺靠谱的。