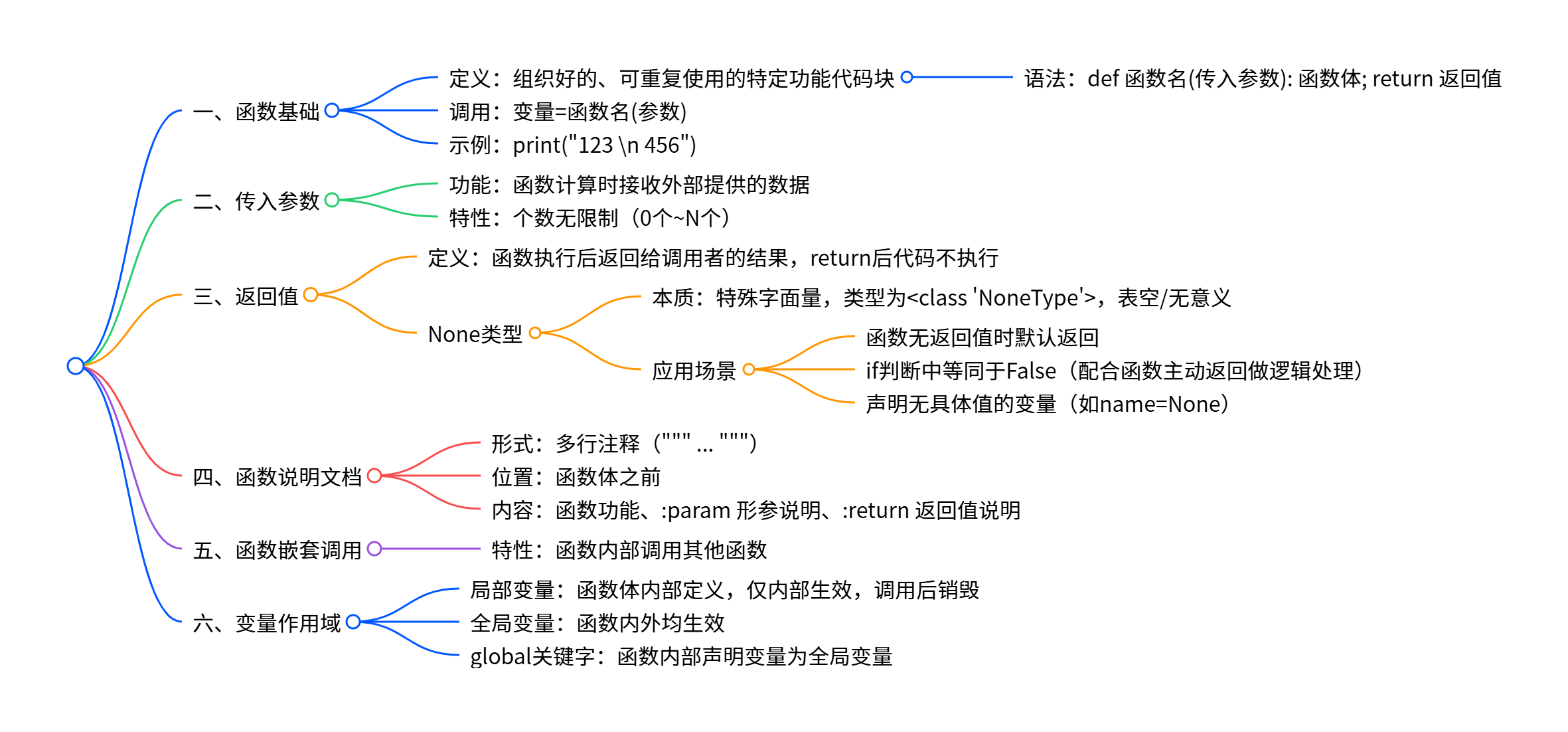
一、Pyhton函数
1.函数:是组织好的,可重复使用的,用来实现特定功能的代码块
(1)函数定义:
def 函数名(传入参数):
函数体
return 返回值
(2)函数调用:
变量=函数名(参数)
(3)print("123 \n 456")
python
# 函数定义
def fisrt_test():
print("first_test...\ntry")
# 函数调用
fisrt_test()
# 函数参数
def add_test(x,y): # 形参
sum= x + y
print(f"{x}+{y}={sum}",type(x)) # f:将变量/表达式的值以字符串的形式嵌入语句中
result=add_test(3,4) # 实参
print(result)
print(type(result))2.函数的传入参数
(1)功能:在函数进行计算时,接受外部(调用时)提供的数据
(2)传入参数的个数不受限制,可以0个可以N个
3.函数的返回值
(1)函数返回值的定义
函数在执行完成之后,返回给调用者的结果;return之后的代码不会执行
(2)None类型
当函数没有使用return语句返回数据,函数的返回值是---None
None是一个特殊的字面量,其类型是:<class 'NoneType'>
无返回值的函数,实际上是返回了None这个字面量
None:空的、无实际意义
(3)None应用场景:
用在函数无返回值上
用在if判断上:
if判断中,None等同于False
一般用于在函数中主动返回None,配合if判断做相关处理
def check(age):
if age>19:
return "SUCCESS"
return None
result=check(5)
if not result:
print("未成年")
用在声明无内容的变量上:
定义变量,但暂时不需要变量有具体值,可以用None来代替
name=None
python
# None类型的应用场景 --if判断
def check(age):
if age>19:
return "SUCCESS"
return None
result=check(5)
print(result) # none
print(bool(result)) # False
print(not result) # True
if not result:
# 进入if语句 说明result是None 即False
print("未成年")4.函数说明文档
(1)通过多行注释(""" .... """)的形式,对函数进行说明解释
def fun(x,y):
"""
函数说明
:param x:形参x的说明
:param y:形参y的说明
:return:返回值的说明
"""
函数体
return 返回值
(2)内容写在函数体之前
python
# 定义函数,并进行文档说明
def add(a,b):
"""
add函数可以接收两个参数,进行两数相加的结果
:param a:
:param b:
:return:返回两数相加的结果
"""
result=a+b
print(f"两数相加的结果是:{result}")
return result
add(5,6)5.函数的嵌套调用
6.变量的作用域
(1)变量的作用域是指变量的作用返回
(2)局部变量:定义在函数体内部的变量,即只在函数体内部生效
作用在函数内部,在函数运行时临时保存数据,调用完成之后,销毁局部变量
(3)全局变量:在函数体内、外都能生效的变量
(3)global关键字:可以在函数内部声明变量为全局变量
python
# global设置全局变量
num=200
print(num)
def test():
global num
num=500
print(num)
test()
print(num)二、Python数据容器
(1)Pyhton中数据容器:一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素;每一个元素,可以是任意类型的数据,比如字符串、数字、布尔等
(2)数据容器根据特点的不同,如:是否可以支持重复元素、是否可以修改、是否有序,分为5类,分别是:列表(list)、元组(tuple)、字符串(str)、集合(set)、字典(dict)
2.list列表
(1)基本语法
字面量
元素1,元素2,元素3,元素4,...
定义变量
变量名称=元素1,元素2,元素3,元素4,...
#定义空列表
变量名称=\[\]
变量名称=list()
(2)列表内的每一个数据,称之为元素
以\[\]作为标识
列表内每一个元素之间用逗号隔开
(3)列表可以一次存储多个数据,且可以为不同的数据类型,支持嵌套 list122
(4)列表的下标索引 :从前向后 ,从0开始,依次递增
(5)列表的下标索引--反向索引:从后往前,从-1开始,依次递减(-1,-2,-3)
3.列表的常用操作
(1)插入元素 删除元素 清空列表 修改元素 统计元素个数 --列表的方法
(2)函数式一个封装的代码单元,可以提供特定功能;在Python中,如果将函数定义为class(类)的成员,那么函数会称之为:方法
(3)def add(x,y):
return x+y ----函数
class Student:
def add(self,x,y):
return x+y
(4)方法和函数功能一样,有传入参数,有返回值,只是方法的使用格式不同:
函数的使用:num=add(1,2)
方法的使用:student=Student()
num=student.add(1,2)
(5)列表的查询功能
查找指定元素在列表的下标,没有找到,报错Value
语法:列表.index(元素)
index--是列表对象(变量)内置的方法(函数)
(6)列表的修改:列表下标=值
(7)列表的插入: 列表.insert(下标,元素),在指定的下标位置,插入指定的元素
(8)追加元素:
列表.append(元素),将指定元素,追加到列表的尾部
(9)追加多个元素
列表。extend(其它数据容器),将其它数据容器的内容取出,依次追加到列表尾部
(10)删除元素:
del 列表下标
列表.pop(下标) 可以接收到被删除元素--作为返回值
(11)删除指定元素(删除元素在列表中的第一个匹配项)
列表.remove(元素)
(12)清空列表内容
列表.clear()
(13)统计某元素在列表内的数量
列表.count(元素)
(14)统计列表内,有多少元素
len(列表)
python
# 数据容器 list
try_list1=["abc",123,[13.14,34,78]]
print(try_list1)
print(try_list1[2][2])
# 反向索引
print(try_list1[-1][-1])
# 1.list index方法
list2=["app1","app2","app3"]
index= list2.index("app1")
print(index)
# 2.列表的修改
list2[1]="opop"
# 3.列表-插入元素
list2.insert(2,"oiu")
print(list2)
# 4.列表-尾部插入
list2.append("final")
print(list2)
# 5.列表-追加多个元素
list2.extend(["add1","add2","add3"])
print(list2)
# 6.列表-删除 del pop
del list2[2]
remove_element= list2.pop(1)
print(remove_element)
print(list2)
# 7.列表删除指定元素(第一个匹配项)
list2.append("app3")
# 9.统计某元素在列表中的数量
print(list2.count("app3"))
# 10.统计列表中元素的个数
count=len(list2)
print(count)
list2.remove("app3")
print(list2)
# 8.清空列表内容
list2.clear()
print(list2)4.列表总结:
(1)列表可以容纳多个元素
(2)可以容纳不同类型的元素(混装)
(3)数据是有序存储的(有下标序号)
(4)允许重复数据出现
(5)可以修改(增加或删除元素)
5.list(列表)的遍历
(1)遍历/迭代:将容器中的元素依次取出进行处理
数据容器--tuple(元组)
数据容器--tuple(元组)--只读list
1.元组一旦定义完成,就不可修改
2.当需要再程序内封装数据,又不希望封装的数据被篡改,--使用元组
3.元组定义:使用小括号,逗号隔开各个数据,数据可以是不同的数据类型
(1)# 定义元组字面量
(元素,元素,......,元素)
(2)
定义元组变量变量名称 =(元素,元素,......元素)
(3)
定义空元组
变量名称=() # 方式1
变量名称 = tup1e() # 方式2 得到元组的类对象
(4)定义单个元素的元组
t4=("aad",) # 单独加逗号,否则是str类型
4.元组的使用:
(1)index():查找某个数据,返回下标
(2)count():统计某个元素在元组中出现的个数
(3)len(元祖):统计元祖内的元素个数
5.元组不能修改内容 如果元组中嵌套list 则根据下标定位到ist再进行修改/增加
python
# tuple 元组的定义和操作
# 1.定义
t1=(1,"aad",True)
t2=()
t3=tuple()
print(type(t1))
print(type(t2))
print(type(t3))
# 2.定义单个元素的元组 加, 否则是str类型
t4=("aad")
print(type(t4))
t5=("add",)
print(type(t5))
t2=(("1","2","3"),(2,3,4))
print(t2[-1][-1])
# 元组不能修改内容 如果元组中嵌套list 则根据下标定位到ist再进行修改
t3=(1,2,["aa","cc"])
print(t3)
t3[2][0]="bb"
print(t3)数据容器--str(字符串)
1.字符串是字符的容器,一个字符串可以存放任意数量的字符
2.字符串是一个无法修改的数据容器
3.字符串的常用操作
(1)字符串.index(字符串) 查找特定字符串的下标索引值(起始索引值)
(2)字符串的替换
字符串.replace(字符串1,字符串2)
将字符串1内的全部内容,替换为字符串2
得到一个新的字符串
(3)字符串的分割
字符串.split(分隔符字符串)
按照指定的分隔符字符串,将字符串划分为多个字符串,并存入列表对象中
字符串本身不变,而是得到了一个列表对象
(4)字符串的规整操作(去前后空格)
字符串.strip()
(5)字符串的规整操作(去前后指定字符串)
字符串.strip(字符串)
str1.strip("12") --去除1和2
(6)字符串容器的特点:只可以存储字符串;不可以修改
python
# 数据容器 str
try_str="app and add"
print(try_str)
# 1.获得指定字符串的位置
str_content=try_str.index("add")
print(str_content)
# 2.字符串替换--得到新字符串
new_str=try_str.replace("add", "hello")
print(new_str)
# 3.字符分割
str2="hi kitty 12345"
str2_list=str2.split(" ")
print(str2_list,type(str2_list))数据容器 序列的切片操作
1.序列:指内容连续、有序、可使用下标索引的一类数据容器
列表、元组、字符串,均可视为序列
2.切片:从一个序列中,取出一个子序列
(1)语法:序列起始下标:结束下标:步长
(2)表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列:
起始下标: 从何处开始,可以留空,留空视作从头开始
结束下标(不含): 何处结束,可以留空,留空视作截取到结尾
步长: 依次取元素的间隔
步长1表示,一个个取元素 (默认值)
步长2表示,每次跳过1个元素取
步长N表示,每次跳过N-1个元素取
步长为负数表示,反向取(注意,起始下标和结束下标也要反向标记)
(3)对序列的切片操作不会影响序列本身,而是会得到一个 新序列
python
# 序列[起始下标:结束下标:步长]
# 1.起始和结束不写表示从头到尾,步长为1可以省略
try_tuple=(0,1,2,3,4)
new_tuple=try_tuple[:]
print(new_tuple)
# 2.对str进行切片,从头到尾,步长为2
try_str="addcg111"
new_str=try_str[::2]
print(new_str)
# 3.将str字符串反转
new_str2=try_str[::-1]
print(new_str2)
# 3.对列表进行切片,从3开始,到一结束,步长-1
try_list=[0,1,2,3,4]
new_list=try_list[3:1:-1]
print(new_list)集合 {} set
(1)不支持重复元素【会去重】;内容无序
(2)基本语法:
定义集合字面量
{元素,元素,...,元素}
定义集合变量
变量名称 ={元素,元素,......,元素}
定义空集合
变量名称 = set()
(3)集合无序,--不支持下标索引访问;可以修改
(4)从集合中随机取一个元素 集合.pop()
会得到一个元素的结果;集合本身被修改,元素被移除
(5)集合--修改:取两个集合的差集
集合1.difference(集合2):取出集合1有而集合2没有
得到一个新集合,集合1和集合2不变
(6)消除2个集合的差集
集合1.difference_update(集合2)
在集合1内,删除和集合2相同的元素;集合1被修改,集合2不变
(7)两个集合合并 --得到新集合
集合1.union(集合2) ---会去重
功能:将集合1 和集合2组成新集合;得到新集合,集合1和集合2不变
(8)统计集合元素数量 --len() 会去重统计
(9)集合的遍历:集合不支持下标索引,不能用while循环;可以使用for循环
python
# 1.取两个集合的差集 --取出集合1有而集合2没有
set1={1, 2, 3, 4, 5}
set2={3, 4, 5, 6, 7, 8}
new_set= set1.difference(set2)
print(new_set)
print(set1)
print(set2)
print("----------------------------------------------------")
# 2.消除2个集合的差集 --集合1被修改
# 集合1.difference_update(集合2)
set1.difference_update(set2)
print(set1)
print(set2)
print("----------------------------------------------------")
# 3.两个集合合并 --得到去重的新集合
set1={1,2,3,4,5}
set2={3,4,5,6,7,8}
new_set2= set1.union(set2)
print(new_set2)
# 4.统计集合元素数量 去重统计
set3={1,2,3,4,5,5,4,3,2,1}
num=len(set3)
print(num)
# 5.集合的遍历 集合不支持下标索引,不可使用while循环可以使用for循环
for i in set2:
print(i)数据容器:dict(字典、映射)
(1)字典的基础定义
定义字典字面量
{key :value,key:value } 通过key使用value
如 通过姓名检索学生的成绩
定义空字典
dict1={} or dict1=fict()
(2)不允许key重复 如果定义两个相同的ket,最后的key会覆盖前一个key
(3)不可使用下标索引,通过key获取value
dict1"某个key"
(4)字典嵌套:
字典的key和value可以是任意数据类型(key不可以是字典)
(5)字典的操作 ---新增
字典key=value 字典被修改,新增了元素
(6)字典的操作 ---更新
字典key=value 字典被修改,元素被更新 字典key不可以重复,所以对已存在的key上执行上述操作,就是更新value
(7)删除元素
语法:字典tpop(Key)结果: 获得指定Key的Value,同时字典被修改,指定Key的数据被删除 返回值是被删除的值
(8)获取全部key --可以用于遍历字典
字典.keys() 得到字典中的全部key
python
# 1.新增
dict1={"kk1":{
"语文":66,"数学":66},
"kk2":{
"语文":88,"数学":86},
"kk3":{
"语文":99,"数学":66},
};
dict1["kk4"]=[{
"语文":90,
"数学":99
}]
print(dict1)
print("--------------------")
# 2.更新
dict1["kk3"]["语文"]=100
print(dict1)
# 3.获取全部keys --可以用于遍历字典
print("--------------------")
dict1_keys=dict1.keys();
print(f"字典的全部key是:{dict1_keys}")
print("--------------------")
# 4.遍历字典 方式一
for x in dict1_keys:
print(f"字典的key:{x}")
print(f"字典的value:{dict1[x]}")
print("--------------------")
# 4.遍历字典 方式二 直接对字典进行for循环,每一次循环直接得到key
for x in dict1:
print(f"字典的key:{x}")
print(f"字典的value:{dict1[x]}")数据容器共性操作
(1)数据容器的通用统计特性
len(容器):统计容器的元素个数
max(容器):统计容器的最大元素 --字符串按字母排序,最小是a;字典:根据key判断大小而不是value 如 "key1": 2 "key2": 1 最大是key2
min(容器):统计容器的最小元素
(2)容器的通用转换功能
list(容器):将给定容器转换为列表
字符串转列表:把每个字符当做一个元素
字典转列表:只保留key
str(容器):将给定容器转换为字符串
列表,元组 会加"",如
"\[\]" "()"
字典转列表:key value都保留
tuple(容器):将给定容器转换为元组
字符串转元组:把每个字符当做一个元素
字典转元组:只保留key
set(容器):将给定容器转换为集合
字符串转集合:把每个字符当做一个元素 变成无序并去重
字典转集合:只保留key 变成无序
(3)容器的通用排序功能
sorted(容器,reverse=True) ---结果会变成列表对象
reverse=True:反向排序
字符串比大小
(1)基于数字的码值大小进行比较
(2)按位比较,只要有一位大,整体就大
三、总结