第一章:从 CUDA 到 CANN 的范式转移
在人工智能的浩瀚星河中,算力是驱动一切的引擎。长久以来,NVIDIA GPU 凭借其强大的通用并行计算能力和成熟的 CUDA 生态,几乎垄断了深度学习训练与推理的市场。然而,随着 AI 模型参数量的爆炸式增长(从 ResNet 的千万级到 GPT-4 的万亿级),通用 GPU 在能效比和特定算子优化上逐渐显露出瓶颈。
1.1 异构计算的崛起与 NPU 的定位
在传统的计算架构中,CPU(中央处理器)如同各种全能的"老教授",擅长复杂的逻辑控制、分支预测和串行任务,但在处理大规模并行矩阵运算时,效率显得捉襟见肘。GPU(图形处理器)则像成千上万个"小学生",虽然单个核心能力有限,但胜在人多势众,适合图像渲染和并行计算。
而 NPU(Neural Processing Unit,嵌入式神经网络处理器) ,则是华为为 AI 时代量身定制的"特种兵"。它抛弃了传统 CPU/GPU 中为了兼容图形渲染或通用计算而保留的冗余逻辑,专注于深度学习中最核心的数学运算------矩阵乘法(Matrix Multiplication)与卷积(Convolution)。
在异构计算(Heterogeneous Computing)的架构下,大模型的运行不再是单一芯片的独角戏,而是一场接力赛:
-
CPU:负责数据预处理、模型加载、逻辑调度。
-
NPU:负责繁重的 Tensor(张量)计算与反向传播。
1.2 深入达芬奇架构:Atlas 800T 的硬件秘密
我们本次实战使用的 Atlas 800T ,是华为昇腾系列的旗舰级训练/推理芯片。其强大的性能源于底层的达芬奇(Da Vinci)架构。达芬奇架构的核心在于三种计算单元的协同:
-
Cube Unit(矩阵运算单元) :这是 NPU 的"核动力引擎"。它能够在一个时钟周期内完成 16 X 16 X 16的矩阵乘法运算(MACs)。对于大模型中无处不在的
Linear层和Attention计算,Cube 单元提供了比 GPU CUDA Core 更高的能效比。 -
Vector Unit(向量运算单元):处理各种非矩阵类的向量计算,如激活函数(ReLU, Gelu)、归一化(LayerNorm)等。
-
Scalar Unit(标量运算单元):负责标量运算和程序流程控制。
1.3 软件栈解析:CANN 与 PyTorch Adapter 的桥梁作用
硬件虽强,若无软件支持,便是一堆废铁。NVIDIA 有 CUDA,华为则推出了 CANN (Compute Architecture for Neural Networks)。
CANN 是连接上层深度学习框架(MindSpore, PyTorch, TensorFlow)与底层 NPU 硬件的桥梁。它包含了一系列核心组件:
-
ACL (Ascend Computing Language):提供给开发者的统一编程接口。
-
AOE (Automated Operator Optimizer):算子自动调优工具。
-
HCCL (Huawei Collective Communication Library):华为集合通信库,用于多卡/多机分布式训练。
对于习惯了 PyTorch 的开发者,华为提供了 torch_npu 插件(即 PyTorch Adapter)。它的作用是将 PyTorch 的算子通过 Dispatch 机制分发到 CANN 层的算子库中执行。
-
CUDA 代码 :
model.to("cuda") -
NPU 代码 :
model.to("npu")
这一行代码的改变,背后是整个 咱们 AI 软件栈数年的努力,实现了从"可用"到"好用"的跨越。
第二章:工欲善其事 ------ 云端 NPU 环境的构建与解析
理论储备完毕,让我们进入实战战场。本次我们选择 GitCode Notebook 平台,它为开发者提供了开箱即用的昇腾算力环境,避免了繁琐的物理机驱动安装过程。
2.1 GitCode 算力平台架构深度剖析
首先,我们需要访问 CANN 的官方代码仓:https://gitcode.com/CANN。
GitCode 平台 CANN 仓库入口,点击"我的 Notebook"即可开启算力之旅
GitCode Notebook 的底层通常基于 Kubernetes 容器化技术。当我们请求一个 Notebook 实例时,系统会在后台调度一个 Pod,挂载相应的 NPU 设备(通过 Device Plugin),并加载预制的 Docker 镜像。
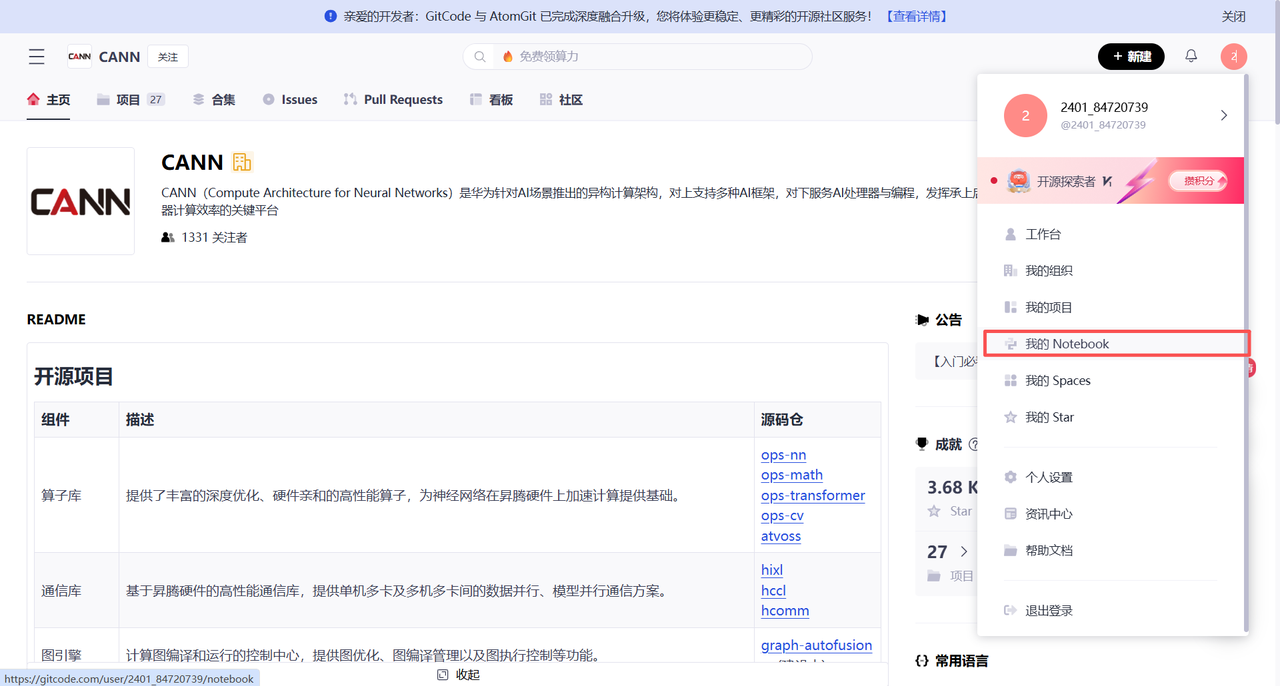
深度挖掘: 在 CANN 的仓库中,你还可以看到诸如 ops-math 等子项目。
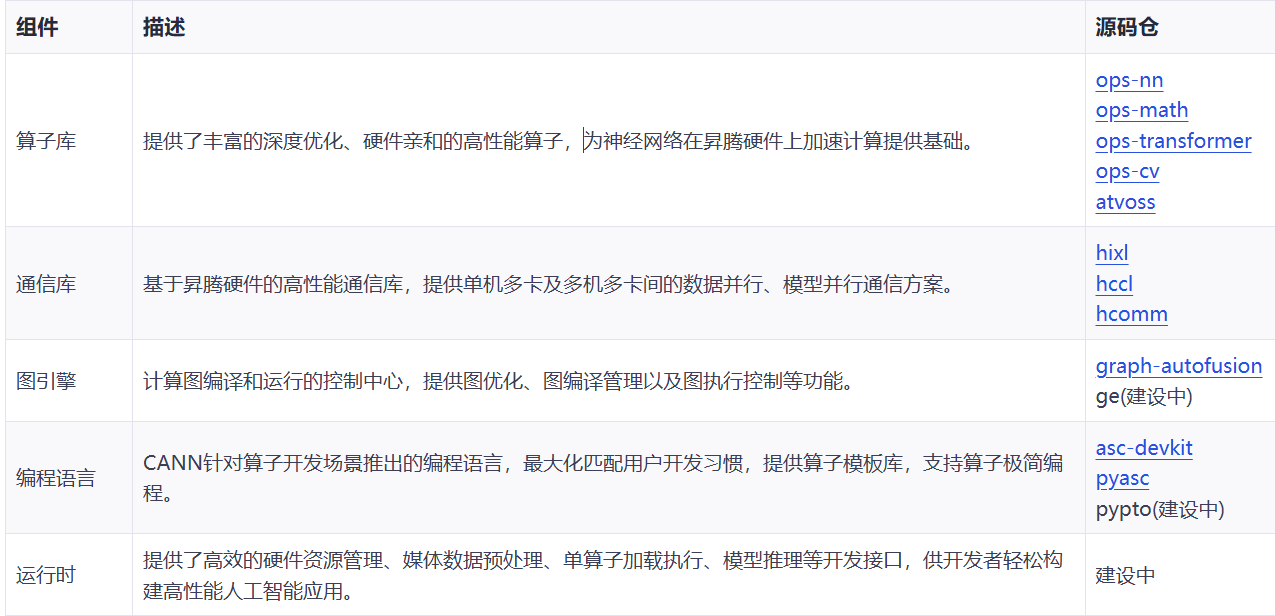
CANN 仓库中的丰富资源,ops-math 包含了大量高性能数学算子的实现源码,适合进阶开发者研究
这不仅是一个代码托管地,更是昇腾开发者的知识库。对于希望深入了解 NPU 如何实现 Sin, Cos, MatMul 等算子的同学,ops-math 是绝佳的学习材料。
2.2 镜像选择的方法论:为何 EulerOS 是首选?
在创建实例时,选择正确的**镜像(Image)**至关重要。
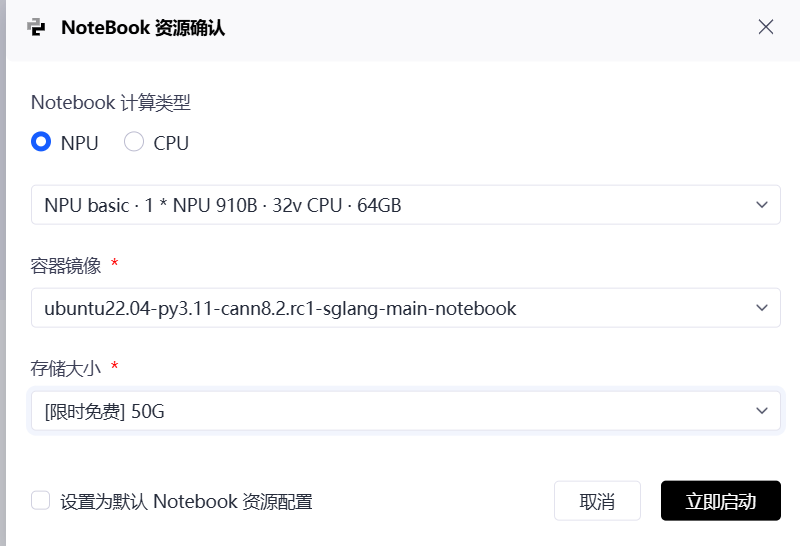
为了让 Llama-2-7b 能够顺利运行,请务必按照以下标准进行配置:
-
计算类型 :NPU
- 理由:大模型推理涉及海量的矩阵运算,CPU 根本跑不动,必须上 NPU 加速卡。
-
资源规格 :NPU basic (1 * Atlas 800T, 32vCPU, 64GB)
- 理由:Atlas 800T 是目前昇腾的主力旗舰芯片。相比上一代 910A,它拥有更大的 HBM(高带宽内存)和更强的算力。Llama-2-7b 在 FP16 精度下模型权重约占 14GB,加上推理时的 KV Cache,64GB 显存绰绰有余,甚至可以尝试 13B 模型。
-
容器镜像(🚨 核心关键点) :ubuntu22.04-py3.11-cann8.2.rc1-sglang-main-notebook
- 推荐镜像:
第三章:环境自检与 Hello World
启动 Notebook 并进入 JupyterLab 后,我们处于一个容器化的 Linux 环境中。
3.1 npu-smi 指令详解:读懂 NPU 的"体检报告"
JupyterLab 终端界面,这是我们与服务器交互的控制台
如同使用 NVIDIA GPU 时必敲 nvidia-smi,在昇腾环境,我们的第一条命令是:
Bash
npu-smi info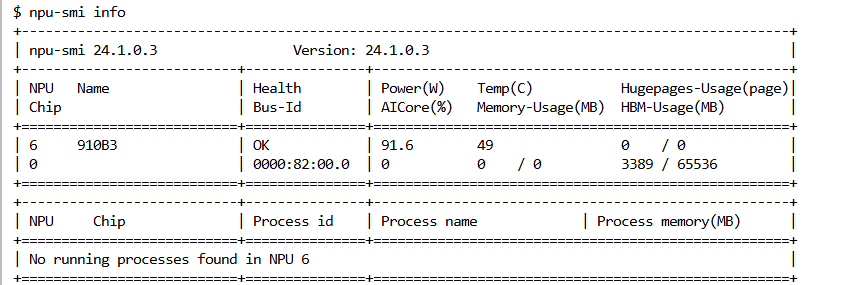
输出的表格包含了关键信息(模拟输出):
-
NPU ID:设备编号,通常为 0。
-
Chip Name:Atlas 800T。
-
Health :OK(这是最重要的,必须为 OK)。
-
Memory-Usage:显存占用情况。Atlas 800T 通常配备 64GB 或 32GB HBM(高带宽内存)。
-
Power:功耗。
3.2 兼容性验证:Python、PyTorch 与 torch_npu 的三角关系
硬件就绪后,需验证软件栈的连通性。PyTorch 必须能够通过 torch_npu 识别到底层硬件。
在终端执行:
Bash
python3 -c "import torch; import torch_npu; print(f'PyTorch: {torch.__version__}, NPU Available: {torch_npu.npu.is_available()}, Device: {torch.npu.get_device_name(0)}')"-
预期输出 :
NPU Available: True。 -
原理解析 :
import torch_npu这行代码会向 PyTorch 注册一个新的 Backend(后端)。当用户调用.to("npu")时,PyTorch 的 Dispatcher 会将操作路由给torch_npu库,进而调用 ACL 接口控制硬件。

3.3 第一次推理:GPT-2 模型的 NPU 迁移实战
为了快速验证全流程,我们先跑一个轻量级的 GPT-2 模型。
- 安装依赖:
Bash
pip install transformers accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple
- 编写测试代码 (创建
test_npu.py或在 Cell 中运行):
Python
import os
import torch
import torch_npu # 【核心知识点】必须显式导入
from transformers import AutoTokenizer, AutoModelForCausalLM
# 解决容器线程冲突问题
os.environ["OMP_NUM_THREADS"] = "1"
device = torch.device("npu:0")
print(f"🚀 Activating Device: {device}")
# 加载小模型
model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
input_text = "The future of AI is"
inputs = tokenizer(input_text, return_tensors="pt").to(device)
print("⏳ Running inference on NPU...")
# --- 注意下面这行的缩进 ---
with torch.no_grad():
# 前面加了4个空格
outputs = model.generate(**inputs, max_new_tokens=20)
print("✨ Result:", tokenizer.decode(outputs[0], skip_special_tokens=True))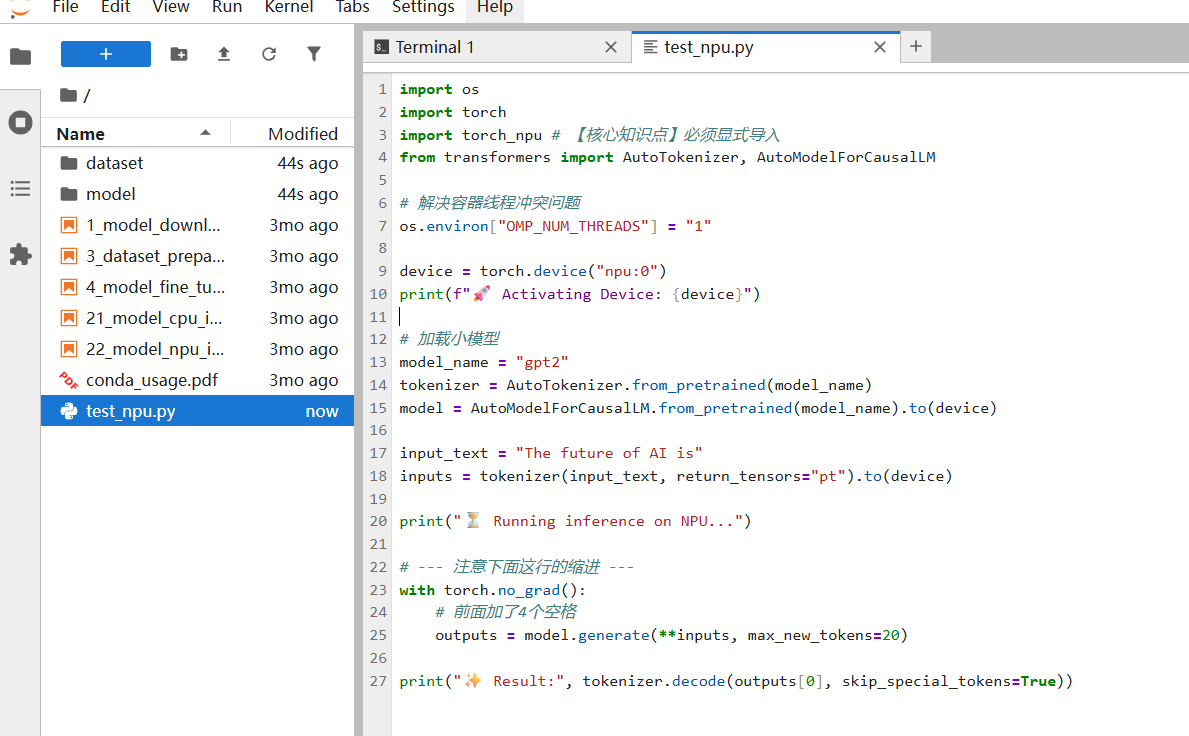
如果这段代码输出了补全后的句子,说明:网络通畅、PyTorch 适配层工作正常、CANN 算子库调用成功。
第四章: Llama-2-7b 的企业级部署方案
GPT-2 只是玩具,现在我们挑战真正的工业级大模型 ------ Meta Llama-2-7b。
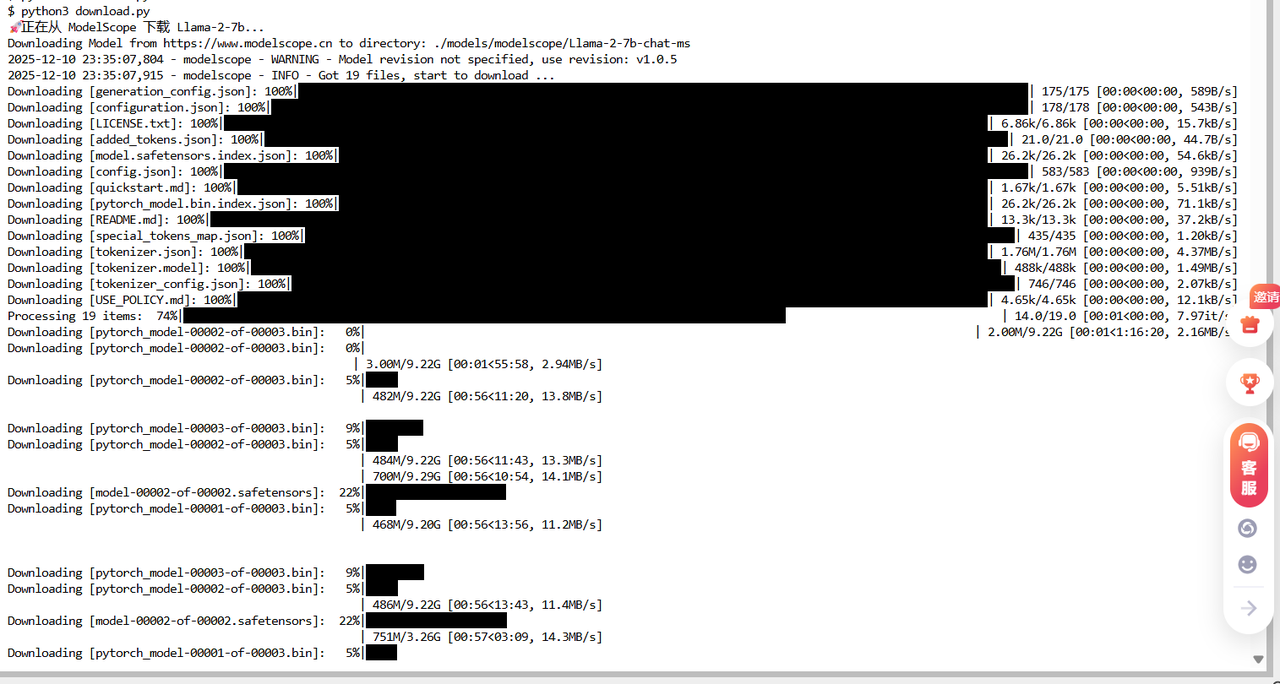
4.1 模型下载的艺术:HuggingFace 断连的替代方案
Llama-2-7b 权重文件约为 13GB+。在云端环境中,直接连接 HuggingFace Hub 经常会遇到 Connection Reset 或速度极慢的问题。
解决方案:ModelScope(魔搭社区) ModelScope 是国内领先的模型托管平台,提供了极速的内网下载体验。
将下面部分代码,写入到py文件中,然后再终端进行运行
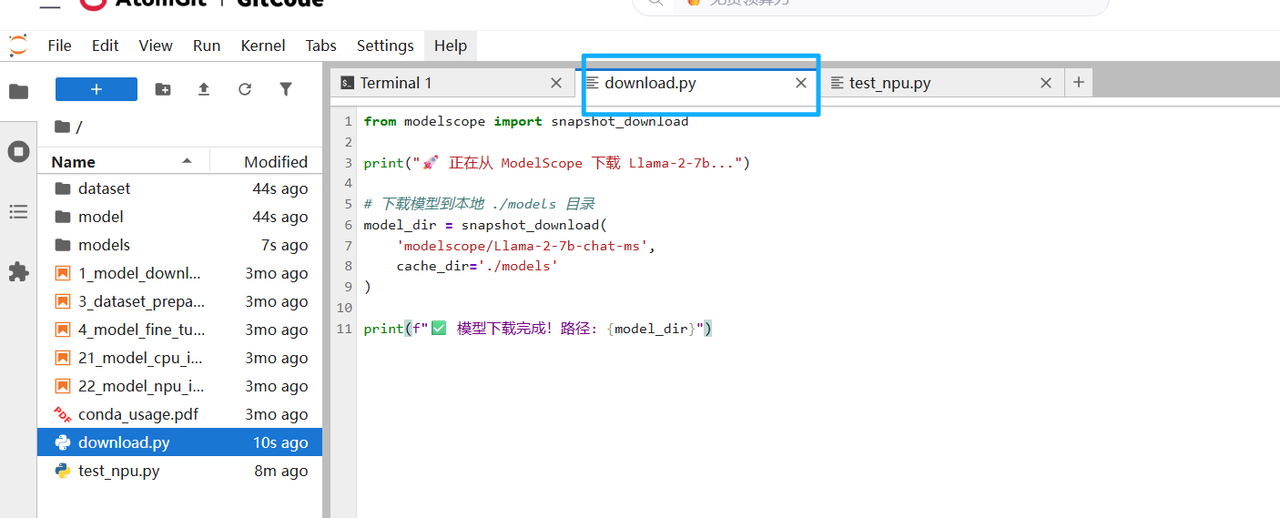
Python
# 安装 modelscope SDK
pip install modelscope
# Python 下载脚本
from modelscope import snapshot_download
# 下载模型到本地 ./models 目录
print("📥 正在从 ModelScope 下载 Llama-2-7b...")
model_dir = snapshot_download('modelscope/Llama-2-7b-chat-ms', cache_dir='./models')
print(f"✅ 模型已下载至: {model_dir}")4.2 精度与显存的博弈:FP16、BF16 与 FP32 的 NPU 适配策略
在加载模型时,有一个极其关键的参数:torch_dtype。
-
FP32 (Float32):标准单精度。7B 模型加载需要约 28GB 显存。
-
FP16 (Float16):半精度。7B 模型仅需约 14GB 显存。
-
BF16 (BFloat16):Google 提出的格式,牺牲精度换取范围,对训练更友好。
NPU 最佳实践 : 昇腾 Atlas 800T 的 Cube 单元对 FP16 的优化最为极致。使用 FP16 不仅能节省一半显存(留给 KV Cache 以支持更长的上下文),还能成倍提升计算吞吐量(TFLOPS)。
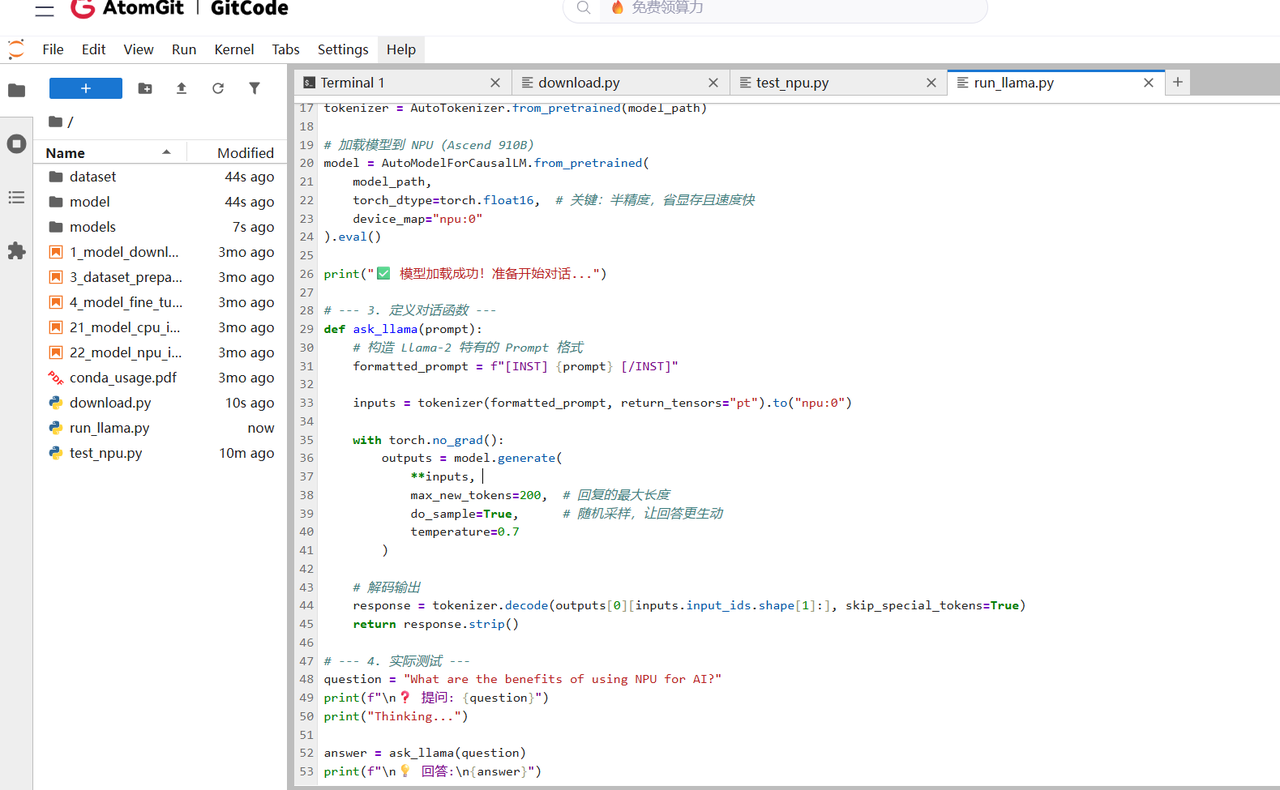

加载代码:
Python
import torch
import torch_npu
from transformers import AutoTokenizer, AutoModelForCausalLM
# 定义路径
model_path = "./models/modelscope/Llama-2-7b-chat-ms"
# 加载 Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 加载模型
# 【核心优化】使用 float16,且 device_map 这里设为自动或手动指定
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="npu:0"
).eval()4.3 核心避坑指南:容器化环境下的线程冲突与 OMP 机制
在实际部署中,90% 的新手会遇到程序莫名卡死、报错 Segmentation fault 或者 RuntimeError: Resource temporarily unavailable。
病灶分析 : PyTorch 依赖底层的 OpenMP 进行多线程并行计算。在 Docker 容器中,Python 获取到的 CPU 核数可能是宿主机的物理核数(例如 96 核),但容器实际被限制只能使用部分资源(例如 32 vCPU)。 当 OpenMP 试图创建 96 个线程时,会触发 Linux 的 cgroup 资源限制或 Pthread 创建失败,导致进程崩溃。
药方: 在导入 torch 之前,强制限制 OpenMP 的线程数。
Python
import os
# 【必背代码】在 import torch 之前设置
os.environ["OMP_NUM_THREADS"] = "1"
os.environ["MKL_NUM_THREADS"] = "1"这行代码看似简单,却是大模型容器化部署的"救命稻草"。
第五章:点石成金 ------ Prompt Engineering 与多场景应用实战
模型加载成功只是第一步。要让 Llama-2 发挥价值,我们需要掌握 Prompt Engineering(提示词工程)。Llama-2-chat 版本经过了 RLHF(人类反馈强化学习)微调,对特定的 Prompt 格式非常敏感。
我们定义一个通用的推理函数:
Python
def ask_llama(prompt, max_length=512):
"""
封装推理过程,处理 device 传输和 decode
"""
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_length,
do_sample=True, # 开启采样,增加创造性
temperature=0.7, # 控制随机度
top_p=0.9
)
# 截取生成的回答部分
response = tokenizer.decode(outputs[0][inputs.input_ids.shape[1]:], skip_special_tokens=True)
return response.strip()5.1 大模型交互的底层逻辑:Context 与 Instruction
Llama-2 官方推荐的 Prompt 模板格式如下:
LaTeX
[INST] <<SYS>>
{系统提示词 System Prompt}
<</SYS>>
{用户输入 User Input} [/INST]-
[INST]和[/INST]标记了指令的开始和结束。 -
<<SYS>>定义了模型的"人设"或"行为准则"。
5.2 场景一:构建私人英汉翻译专家
我们不希望模型啰嗦,只希望它充当一个精准的翻译工具。
Prompt 设计:
Python
text = "Artificial Intelligence is transforming the world rapidly, driven by heterogeneous computing power."
prompt_translation = f"""
[INST] <<SYS>>
You are a professional translator.
Translate the following English text into Chinese.
Do not output any explanation, just the translation.
<</SYS>>
{text} [/INST]
"""
print(ask_llama(prompt_translation))- 效果:模型会精准输出中文,而不会回复"好的,这是翻译结果..."。
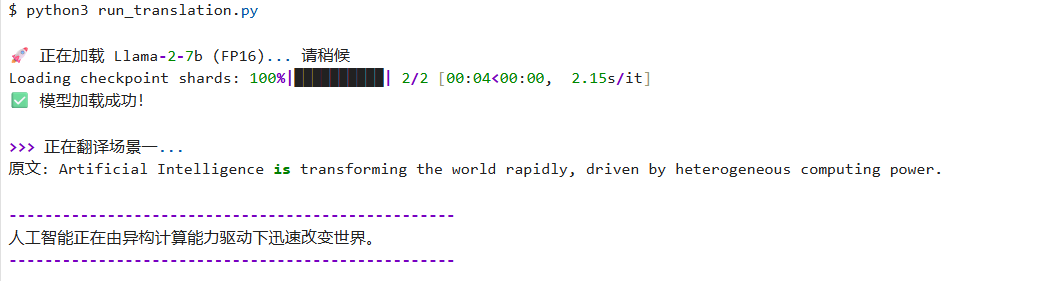
5.3 场景二:沉浸式角色扮演面试官
利用大模型的 Context 理解能力,模拟高压面试环境。
Prompt 设计:
Python
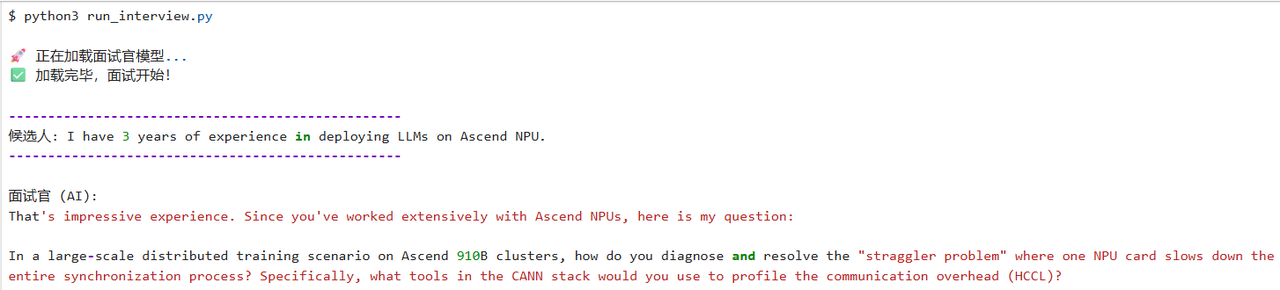
user_input = "I have 3 years of experience in deploying LLMs on Ascend NPU."
prompt_roleplay = f"""
[INST] <<SYS>>
You are a strict technical interviewer at a top AI company.
I am a candidate. Based on my introduction, ask me a challenging technical question about NPU optimization.
<</SYS>>
Candidate says: {user_input} [/INST]
"""
print(ask_llama(prompt_roleplay))- 模型反馈预期:模型可能会问"Can you explain how FlashAttention works on Ascend Atlas 800T?" 或 "How do you handle OOM issues when inference batch size increases?"。这非常适合用来做模拟面试训练。
第六章:总结与展望 ------ 算力生态的未来
通过本文的万字长征,我们从了解昇腾 NPU 的硬件架构开始,一步步完成了 GitCode 环境的搭建、PyTorch 适配层的验证、Llama-2 大模型的 FP16 部署,以及基于 Prompt Engineering 的多场景应用开发。
我们看到,算力生态已经不再是"荒漠"。
-
硬件层面:Atlas 800T 展现出了与国际主流竞品一较长短的实力,特别是在 FP16 矩阵运算的能效比上。
-
软件层面 :CANN 软件栈和 GitCode 平台的结合,极大地降低了开发者的入门门槛。
torch_npu让代码迁移变得不再痛苦。 -
应用层面:从翻译到编程再到垂直领域的微调,NPU 已经能够承载复杂的业务逻辑。
未来,随着 MindSpore 框架的成熟和算子库的进一步丰富,我们有理由相信,在 AI 大模型这波浪潮中,昇腾 NPU 将成为支撑咱们 AI 发展的坚实底座。
现在,轮到你了。打开 GitCode Notebook,点亮那颗 Atlas 800T 芯片,开始你的大模型之旅吧!