ThreadPoolExecutor实战指南:为什么生产环境必须自定义线程池参数?
-
告别Executors工具类:ThreadPoolExecutor自定义配置全解析
-
生产环境线程池配置陷阱:为什么阿里开发手册禁止使用Executors?
-
从入门到精通:ThreadPoolExecutor的七大核心参数深度解读
-
固定大小线程池的两种创建方式对比:Executors vs 直接构造
正文
引言:线程池创建的两种路径
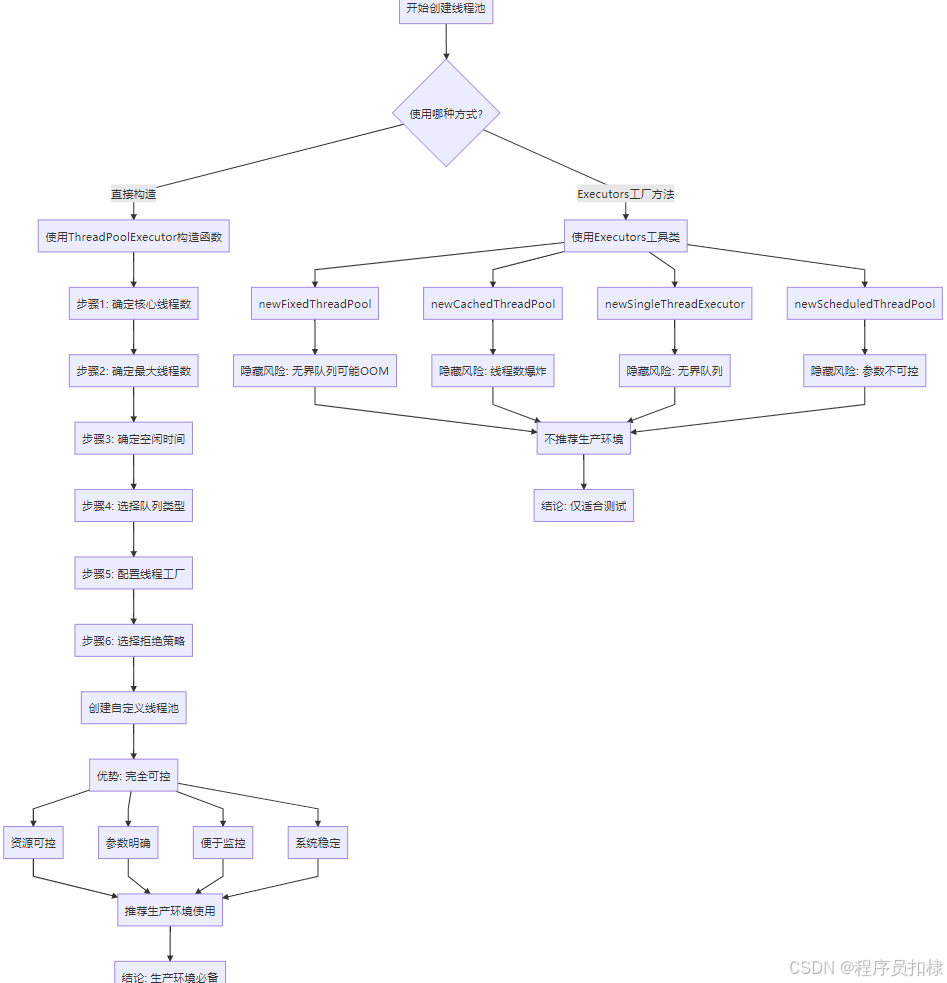
在Java并发编程中,线程池的创建有两种主流方式:一种是使用Executors工具类的工厂方法,另一种是直接调用ThreadPoolExecutor构造函数。虽然前者使用简单,但在生产环境中却暗藏风险。本文将深入探讨如何正确使用ThreadPoolExecutor创建自定义线程池,并通过对比分析两种方式的优劣,为你揭示生产环境中的最佳实践。
一、Executors工具类的便利与隐患
1.1 Executors的常见用法
大多数Java开发者最初接触线程池时,都是从Executors工具类开始的:
java
// 固定大小线程池
ExecutorService fixedPool = Executors.newFixedThreadPool(10);
// 缓存线程池
ExecutorService cachedPool = Executors.newCachedThreadPool();
// 单线程线程池
ExecutorService singlePool = Executors.newSingleThreadExecutor();
// 调度线程池
ScheduledExecutorService scheduledPool = Executors.newScheduledThreadPool(5);这些方法的优点显而易见:简单、快捷、无需关注底层参数。但正是这种"便捷性"埋下了隐患。
1.2 隐藏的风险:无界队列的OOM陷阱
让我们查看Executors.newFixedThreadPool的源码实现:
java
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}注意第5行的LinkedBlockingQueue<Runnable>(),这是无参构造函数创建的无限容量队列。这意味着:
-
当任务提交速度持续超过处理速度时
-
任务会无限制地堆积在队列中
-
最终导致内存溢出(OOM)
同样的问题也存在于Executors.newSingleThreadExecutor()中。
1.3 缓存线程池的线程数爆炸问题
再看Executors.newCachedThreadPool()的实现:
java
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}这里的最大线程数是Integer.MAX_VALUE(约21亿),这意味着:
-
在高并发场景下,可能创建海量线程
-
每个线程都需要分配栈内存(默认1MB)
-
快速耗尽系统内存和CPU资源
二、ThreadPoolExecutor构造函数的全面解析
2.1 七大核心参数详解
直接使用ThreadPoolExecutor构造函数,需要理解每个参数的含义:
java
public ThreadPoolExecutor(
int corePoolSize, // 核心线程数
int maximumPoolSize, // 最大线程数
long keepAliveTime, // 线程空闲时间
TimeUnit unit, // 时间单位
BlockingQueue<Runnable> workQueue, // 工作队列
ThreadFactory threadFactory, // 线程工厂
RejectedExecutionHandler handler // 拒绝策略
)让我们深入每个参数:
1. corePoolSize(核心线程数)
-
线程池长期保持的线程数量
-
即使线程空闲也不会被回收(除非设置allowCoreThreadTimeOut)
-
建议设置:CPU密集型任务设置为CPU核心数,IO密集型可适当增加
2. maximumPoolSize(最大线程数)
-
线程池允许创建的最大线程数量
-
当队列已满且当前线程数小于此值时,会创建新线程
-
必须大于等于corePoolSize
3. keepAliveTime(线程空闲时间)
-
非核心线程空闲时的存活时间
-
超过此时间且线程数大于corePoolSize,线程会被回收
-
可设置为0表示立即回收
4. unit(时间单位)
-
keepAliveTime的时间单位
-
常用:TimeUnit.SECONDS、TimeUnit.MILLISECONDS
5. workQueue(工作队列)
-
用于存储等待执行的任务
-
常见实现:
-
ArrayBlockingQueue:有界队列,固定大小 -
LinkedBlockingQueue:可选有界或无界 -
SynchronousQueue:不存储元素的队列 -
PriorityBlockingQueue:优先级队列
-
6. threadFactory(线程工厂)
-
用于创建新线程
-
可自定义线程名称、优先级、是否为守护线程等
-
便于问题排查和监控
7. handler(拒绝策略)
-
当线程池和队列都饱和时的处理策略
-
内置四种策略:
-
AbortPolicy:抛出RejectedExecutionException(默认) -
CallerRunsPolicy:调用者线程执行任务 -
DiscardPolicy:直接丢弃任务 -
DiscardOldestPolicy:丢弃队列中最旧的任务
-
2.2 创建自定义线程池的完整示例
下面是一个生产环境级别的线程池配置示例:
java
public class CustomThreadPoolDemo {
public static void main(String[] args) {
// 创建自定义线程池
ThreadPoolExecutor executor = new ThreadPoolExecutor(
5, // 核心线程数
20, // 最大线程数
60, // 空闲线程存活时间
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(100), // 有界队列,容量100
new CustomThreadFactory("business-pool"), // 自定义线程工厂
new CustomRejectedExecutionHandler() // 自定义拒绝策略
);
// 可选:允许核心线程超时回收
executor.allowCoreThreadTimeOut(true);
// 提交任务
for (int i = 0; i < 150; i++) {
final int taskId = i;
try {
executor.execute(() -> {
System.out.println(Thread.currentThread().getName()
+ " 执行任务 " + taskId);
try {
Thread.sleep(1000); // 模拟任务执行
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
} catch (Exception e) {
System.err.println("任务 " + taskId + " 被拒绝: " + e.getMessage());
}
}
// 监控线程池状态
monitorThreadPool(executor);
// 优雅关闭
executor.shutdown();
try {
if (!executor.awaitTermination(60, TimeUnit.SECONDS)) {
executor.shutdownNow();
}
} catch (InterruptedException e) {
executor.shutdownNow();
Thread.currentThread().interrupt();
}
}
// 自定义线程工厂
static class CustomThreadFactory implements ThreadFactory {
private final String namePrefix;
private final AtomicInteger threadNumber = new AtomicInteger(1);
CustomThreadFactory(String poolName) {
namePrefix = poolName + "-thread-";
}
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r, namePrefix + threadNumber.getAndIncrement());
t.setDaemon(false);
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
// 自定义拒绝策略
static class CustomRejectedExecutionHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 记录日志
System.err.println("任务被拒绝,线程池状态: "
+ "活跃线程=" + executor.getActiveCount()
+ ", 队列大小=" + executor.getQueue().size()
+ ", 池大小=" + executor.getPoolSize());
// 尝试重新放入队列
try {
if (!executor.isShutdown()) {
executor.getQueue().put(r);
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RejectedExecutionException("任务被中断", e);
}
}
}
// 监控方法
static void monitorThreadPool(ThreadPoolExecutor executor) {
ScheduledExecutorService monitor = Executors.newSingleThreadScheduledExecutor();
monitor.scheduleAtFixedRate(() -> {
System.out.println("=== 线程池监控 ===");
System.out.println("核心线程数: " + executor.getCorePoolSize());
System.out.println("活跃线程数: " + executor.getActiveCount());
System.out.println("最大线程数: " + executor.getMaximumPoolSize());
System.out.println("池中线程数: " + executor.getPoolSize());
System.out.println("队列大小: " + executor.getQueue().size());
System.out.println("已完成任务数: " + executor.getCompletedTaskCount());
System.out.println("================\n");
}, 0, 2, TimeUnit.SECONDS);
}
}三、两种创建方式的深度对比
3.1 代码层面的对比分析
让我们对比创建固定大小线程池的两种方式:
方式一:使用Executors(不推荐生产环境)
java
ExecutorService executor = Executors.newFixedThreadPool(10);
// 等价于:
new ThreadPoolExecutor(10, 10, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());方式二:直接构造(推荐生产环境)
java
ExecutorService executor = new ThreadPoolExecutor(
10, 20, 60L, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(1000),
new NamedThreadFactory("business-pool"),
new ThreadPoolExecutor.CallerRunsPolicy()
);3.2 关键差异对比表
| 对比维度 | Executors.newFixedThreadPool | 直接构造ThreadPoolExecutor |
|---|---|---|
| 队列类型 | LinkedBlockingQueue(无界) | 可自定义(推荐有界队列) |
| 队列容量 | Integer.MAX_VALUE(无限) | 可控制(如1000) |
| 拒绝策略 | 默认AbortPolicy | 可自定义(推荐CallerRunsPolicy) |
| 线程命名 | 默认pool-N-thread-M | 可自定义业务相关名称 |
| 核心线程超时 | 默认false | 可设置为true |
| 资源控制 | 弱(可能OOM) | 强(可控) |
| 监控友好度 | 差 | 好(自定义线程名) |
| 适用场景 | 测试、简单应用 | 生产环境、高并发系统 |
3.3 性能与稳定性影响
内存使用对比:
-
Executors方式:队列无限增长 → 内存使用不可控 → 可能OOM
-
自定义方式:有界队列 → 内存使用可控 → 系统稳定
响应时间对比:
-
Executors方式:队列过长 → 任务等待时间增加 → 响应延迟
-
自定义方式:队列适中 → 等待时间可控 → 响应及时
故障排查对比:
-
Executors方式:线程名无意义 → 问题定位困难
-
自定义方式:线程名有业务含义 → 快速定位问题
四、生产环境最佳实践
4.1 参数配置原则
-
核心线程数计算
java// CPU密集型任务 int corePoolSize = Runtime.getRuntime().availableProcessors(); // IO密集型任务(考虑IO等待时间) int corePoolSize = Runtime.getRuntime().availableProcessors() * 2; -
队列容量设置
-
根据系统内存和业务需求设定
-
一般经验值:100-10000之间
-
需要压测确定最优值
-
-
拒绝策略选择
-
CallerRunsPolicy:对可用性要求高的系统
-
自定义策略:记录日志、持久化、降级处理
-
4.2 监控与调优
建立完善的线程池监控体系:
java
@Component
public class ThreadPoolMonitor {
@Scheduled(fixedRate = 5000)
public void monitorAllPools() {
for (ThreadPoolExecutor pool : getAllBusinessPools()) {
log.info("线程池 {} 状态: 活跃={}, 队列={}, 完成={}",
pool.getThreadFactory().toString(),
pool.getActiveCount(),
pool.getQueue().size(),
pool.getCompletedTaskCount());
// 动态调优
dynamicAdjust(pool);
}
}
private void dynamicAdjust(ThreadPoolExecutor pool) {
double loadFactor = (double) pool.getQueue().size() / 1000; // 假设队列容量1000
if (loadFactor > 0.8) {
// 队列使用率超过80%,适当增加核心线程数
int newCoreSize = Math.min(
pool.getCorePoolSize() * 2,
pool.getMaximumPoolSize()
);
pool.setCorePoolSize(newCoreSize);
} else if (loadFactor < 0.2 && pool.getCorePoolSize() > 5) {
// 队列使用率低于20%,适当减少核心线程数
pool.setCorePoolSize(pool.getCorePoolSize() / 2);
}
}
}4.3 不同业务场景的配置模板
场景1:Web请求处理线程池
java
// 处理HTTP请求,IO密集型
ThreadPoolExecutor webRequestPool = new ThreadPoolExecutor(
50, // 核心线程:CPU核数×2
200, // 最大线程:应对突发流量
30L, TimeUnit.SECONDS, // 空闲线程保留30秒
new ArrayBlockingQueue<>(2000), // 有界队列
new NamedThreadFactory("web-request"),
new ThreadPoolExecutor.CallerRunsPolicy() // 降级到调用线程
);场景2:数据库操作线程池
java
// 数据库操作,受连接数限制
ThreadPoolExecutor dbOperationPool = new ThreadPoolExecutor(
10, // 与数据库连接池大小匹配
10, // 固定大小,不超过连接数
0L, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<>(100), // 较小队列
new NamedThreadFactory("db-operation"),
new CustomRejectWithRetryPolicy() // 自定义重试策略
);场景3:计算密集型任务线程池
java
// 数据处理、计算任务
ThreadPoolExecutor computePool = new ThreadPoolExecutor(
Runtime.getRuntime().availableProcessors(), // CPU核心数
Runtime.getRuntime().availableProcessors(), // 不超过CPU核心数
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(), // 无界队列(CPU不会成为瓶颈)
new NamedThreadFactory("compute"),
new ThreadPoolExecutor.AbortPolicy() // 直接拒绝,避免堆积
);五、常见问题与解决方案
5.1 如何选择合适的队列?
| 队列类型 | 特点 | 适用场景 |
|---|---|---|
| ArrayBlockingQueue | 有界,FIFO,数组实现 | 需要控制资源使用的场景 |
| LinkedBlockingQueue | 可选有界/无界,链表实现 | 吞吐量要求高的场景 |
| SynchronousQueue | 不存储元素,直接传递 | 高响应要求的场景 |
| PriorityBlockingQueue | 优先级排序 | 需要优先级调度的场景 |
5.2 线程池关闭的正确姿势
java
public void gracefulShutdown(ThreadPoolExecutor executor, long timeout) {
executor.shutdown(); // 停止接收新任务
try {
if (!executor.awaitTermination(timeout, TimeUnit.SECONDS)) {
// 超时后强制关闭
executor.shutdownNow();
// 再次等待
if (!executor.awaitTermination(timeout, TimeUnit.SECONDS)) {
log.error("线程池未能正常关闭");
}
}
} catch (InterruptedException e) {
executor.shutdownNow();
Thread.currentThread().interrupt();
}
}5.3 线程池的复用与隔离
最佳实践:不同的业务使用不同的线程池,实现资源隔离,避免相互影响。
java
public class ThreadPoolRegistry {
private static final Map<String, ThreadPoolExecutor> pools = new ConcurrentHashMap<>();
public static ThreadPoolExecutor getOrCreate(String business,
Supplier<ThreadPoolExecutor> creator) {
return pools.computeIfAbsent(business, k -> creator.get());
}
}结论:选择权在开发者手中
通过本文的深入分析,我们可以看到直接使用ThreadPoolExecutor构造函数虽然比Executors工具类更复杂,但它提供了:
-
更好的资源控制:避免无界队列导致的OOM
-
更灵活的配置:根据业务特点定制参数
-
更强的稳定性:合理的拒绝策略保护系统
-
更方便的监控:自定义线程工厂便于问题排查
生产环境的黄金法则:
永远不要在生产环境中使用Executors的默认工厂方法创建线程池。始终通过ThreadPoolExecutor构造函数,根据实际业务需求明确指定所有参数。
记住,线程池不是"配置一次就忘记"的组件。它需要根据业务发展、流量变化和性能监控数据进行持续调优。只有深入理解每个参数的含义,并建立完善的监控机制,才能构建出既高效又稳定的并发处理系统。
流程图