AI Agent 定义、原理
先抓住核心原理、定义和关键特征,避免被细节淹没。
发展历史
AI Agent 不是某一个人在某一刻发明的专利概念,而是几十年里随着人工智能领域的发展逐渐演变,由行业总结出来的
| 时间 | 事件/人物 | 贡献 |
|---|---|---|
| 1960s-1990s | 人工智能研究发展,产生自动推理、专家系统、智能机器人、机器学习等研究方向。具有代表性的是 ELIZA,ELIZA 通过"关键词匹配"+"模版替换"的方式,将用户陈述转化为问题,引导对话延续来模拟心理治疗师。 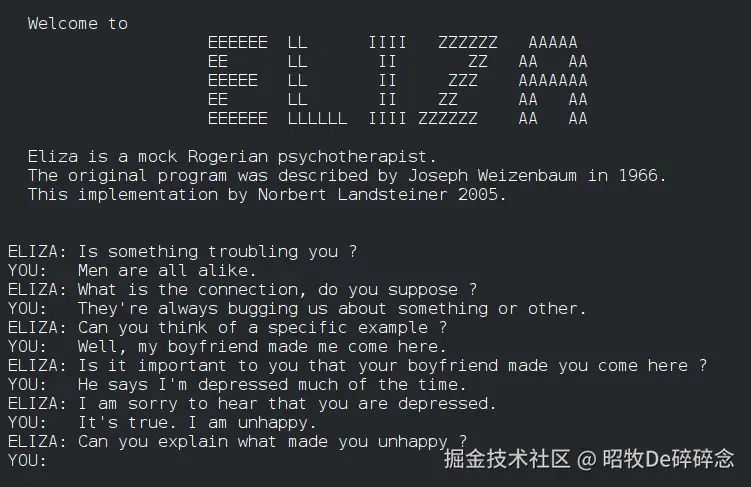 |
虽无真正的智能,却用最简单的技术对智能作出了探索 |
| 1995年 | 《 Artificial Intelligence: A Modern Approach 》出版 ,统一了 AI 研究方向,无论符号主义、连接主义还是概率方法,最终都可归为,设计理性智能体(Rational Agent)的不同实现方式。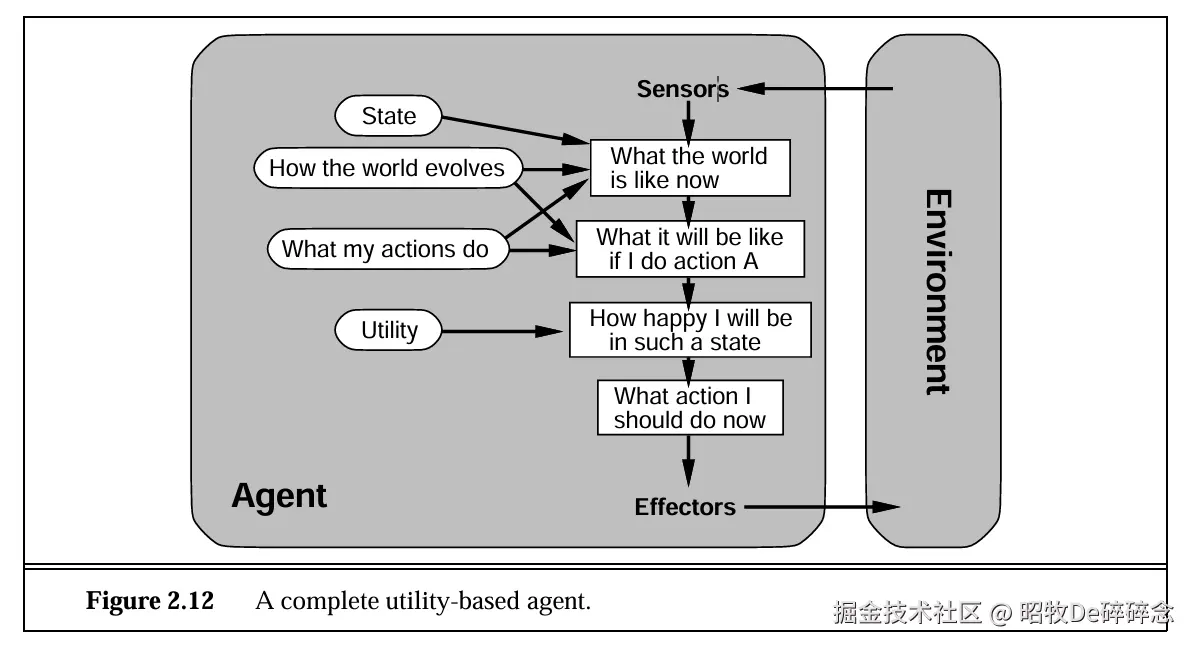 |
提出 Agent 的经典定义,通过感知环境、自主决策并执行行动以最大化目标达成的实体 |
| 2020年代 | OpenAI、Google DeepMind、Anthropic 等公司根据行业实践和研究逐步总结出来 AI Agent 的定义 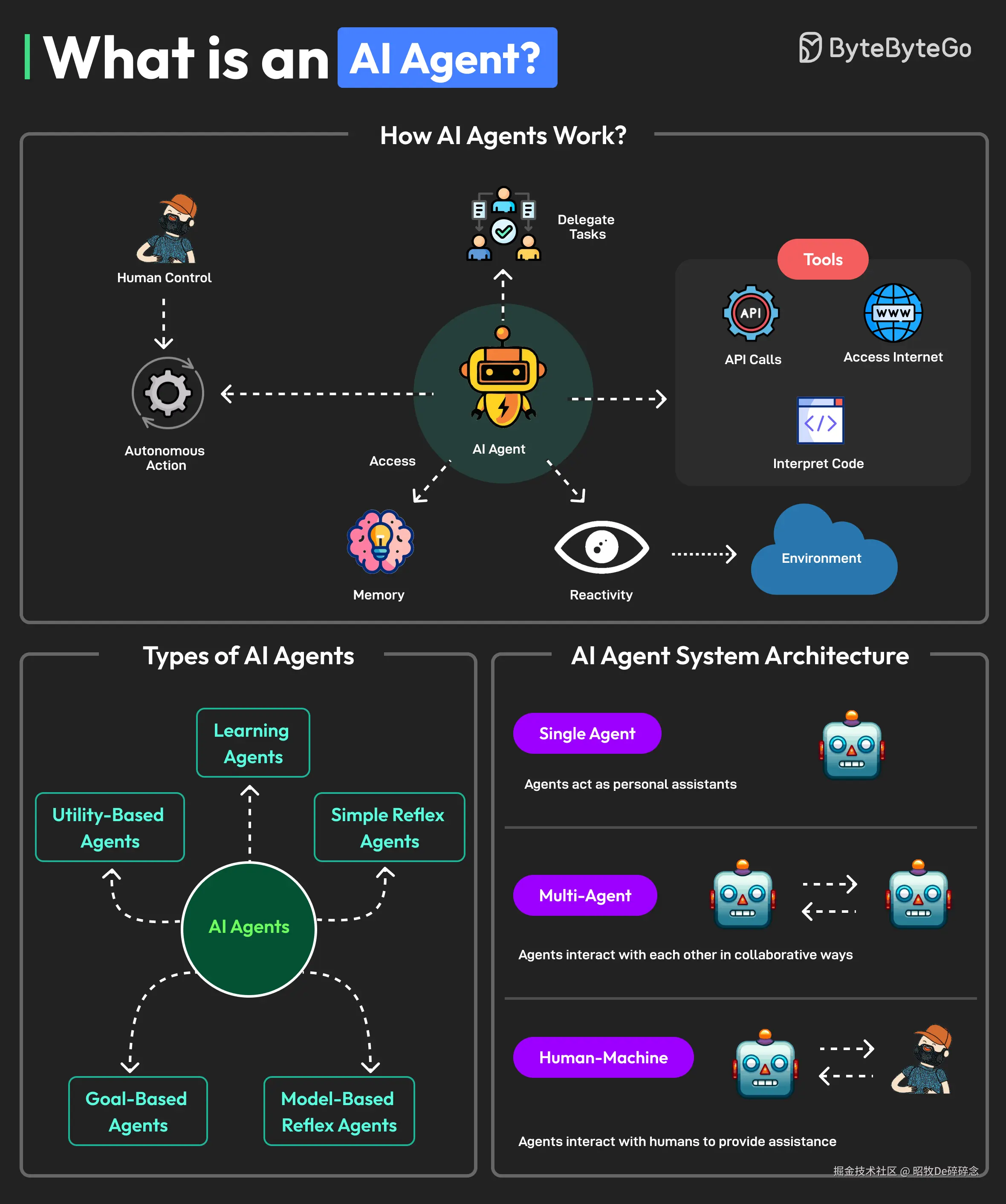 |
基于 AI 的快速发展,和已有的 Agent 概念,总结出 AI Agent |
定义
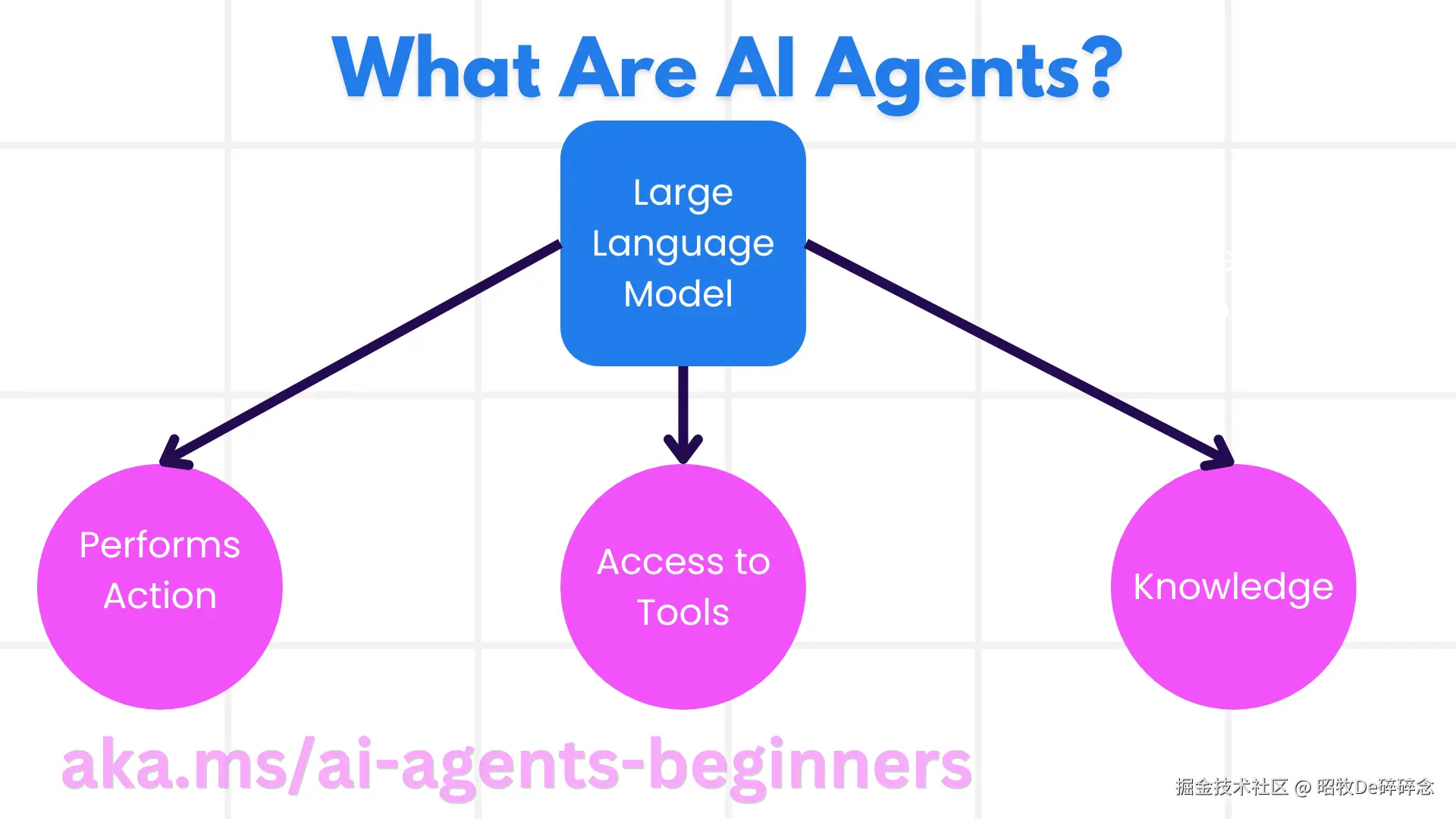
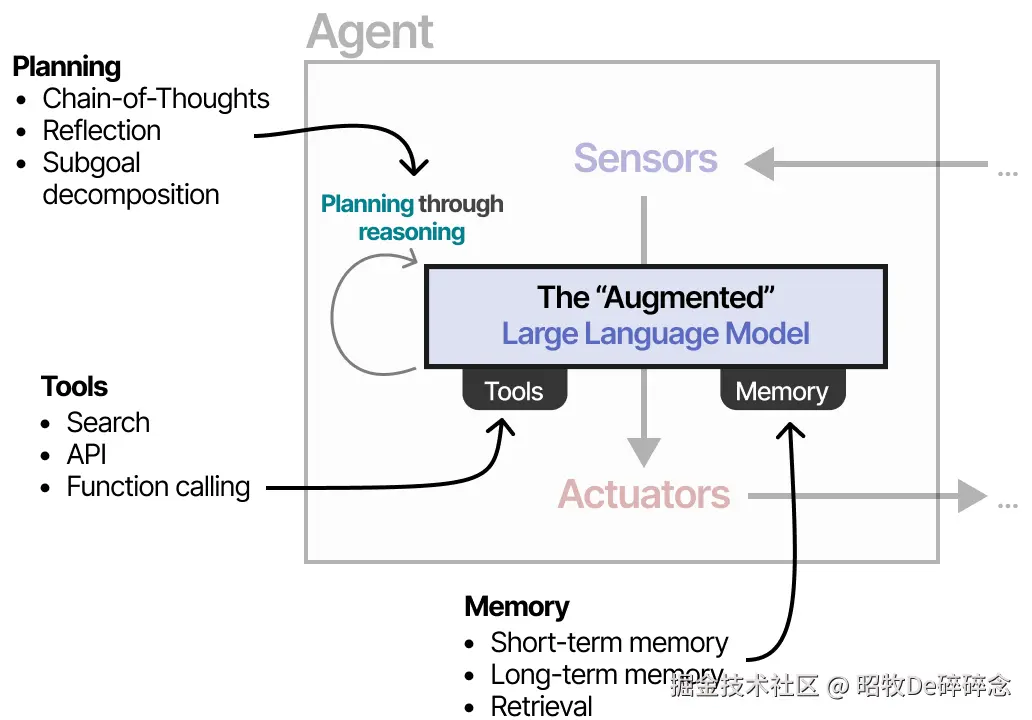
AI Agent 是一个能让 大模型(LLM) 通过 访问工具(Access To Tools) 、记忆和知识(Memory Knowledge) ,去 执行操作(Perform Actions) 的系统。
-
LLM Large Language Model,大语言模型,例如 GPT-4、Claude、Gemini。Agent 的概念在 LLM 诞生之前就已经存在,使用 LLM 去构建 AI Agent 的优势在于,LLM 能更好的理解和解释人类语言。
-
访问工具(Access To Tools) 访问工具是指 AI Agent 被授予使用外部资源或功能的能力。例如:
- 知识获取类:如浏览器、搜索引擎、数据库查询器等,用于获取信息
- 行为执行类:如 API 调用、电子邮件发送、表单填写等,用于让 Agent 对外部环境产生影响
LLM 可以访问哪些工具由 AI Agent 开发者 显示添加/定义。假设是个旅游 AI Agent,这个 AI Agent 允许在携程的预定系统中,那开发者就需要在初始化Agent时,通过声明 tools 的描述、参数结构,将访问航班信息的工具注册给LLM。LLM 根据用户输入内容与 tools 描述的匹配程度,判断是否需要生成 req 调用这个 tools。
- 执行操作(Perform Actions)。如果没有 AI Agent 这个系统,LLM 只能基于用户给的 prompt 生成内容。有了 AI Agent 后,LLM 就可以基于对用户请求的理解,去使用环节中可用的工具完成任务。
Perform Actions 指的是决策并使用工具执行具体操作的过程,在 LangChain 等框架中,对应AgentExecutor的接口定义,由 Agents 框架 结合 Tools 机制直接实现,没有单独定义模块名。
-
记忆和知识(Memory+Knowledge)
- 记忆(Memory)是 Agent 在和用户交互过程中所记住的内容,如:上下文信息,过去的经验等,偏个性化。比如,用户在旅游 AI Agent 期望的出行时间、出行地点。
- 知识(Knowledge)是用户在当前 AI Agent 环境以外能获取的信息。比如,今年夏季由于北京多雨,到北京旅游人倾向于博物馆等室内活动而不是户外活动。
类比
用类比加速理解
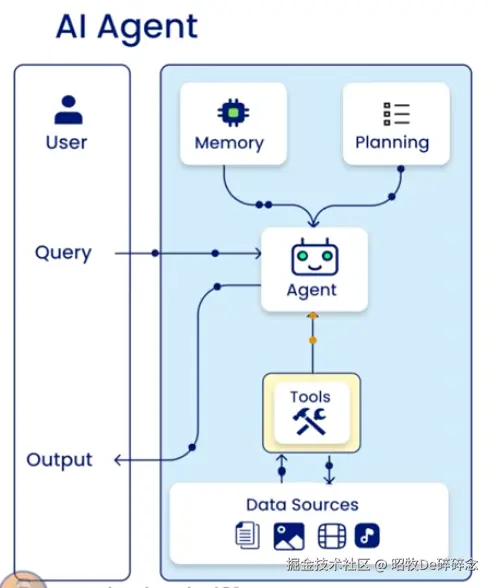
可以将 Agent 类比为 PC 电脑,一开始有了 CPU 不够,大多数人没法直接用 CPU 加法器和减法器完成任务,需要很多的外围设备+操作系统才能搭建出给人能使用的工具
可以把 Agent 类比为一台 PC。一开始只有 CPU(对应 LLM),还远远不够。大多数用户并不会直接操控 CPU 的加法器或减法器来完成任务------他们依赖操作系统进行任务调度,依靠工具接口调用外部服务,还要依赖不同层级的存储(如 RAM、硬盘)来支撑流程。类似地,AI Agent 也无法仅靠 LLM。它需要:
- 一个 规划模块(Planner) 来拆解与调度任务。类似于操作系统,调度资源、加载程序、管理内存;
- 多层次的 内存(Memory) ,包括短期记忆、工作记忆 scratchpad 和长期记忆,来管理上下文与持久知识。类似于 RAM + 硬盘存储架构,提供不同持久性和访问速度;
- 各种 工具(Tools) ,包括各类插件、外部 API、数据库等,才能完成具体操作,类似于电脑通过网线、USB访问外设或外部资源。
涉及的技术
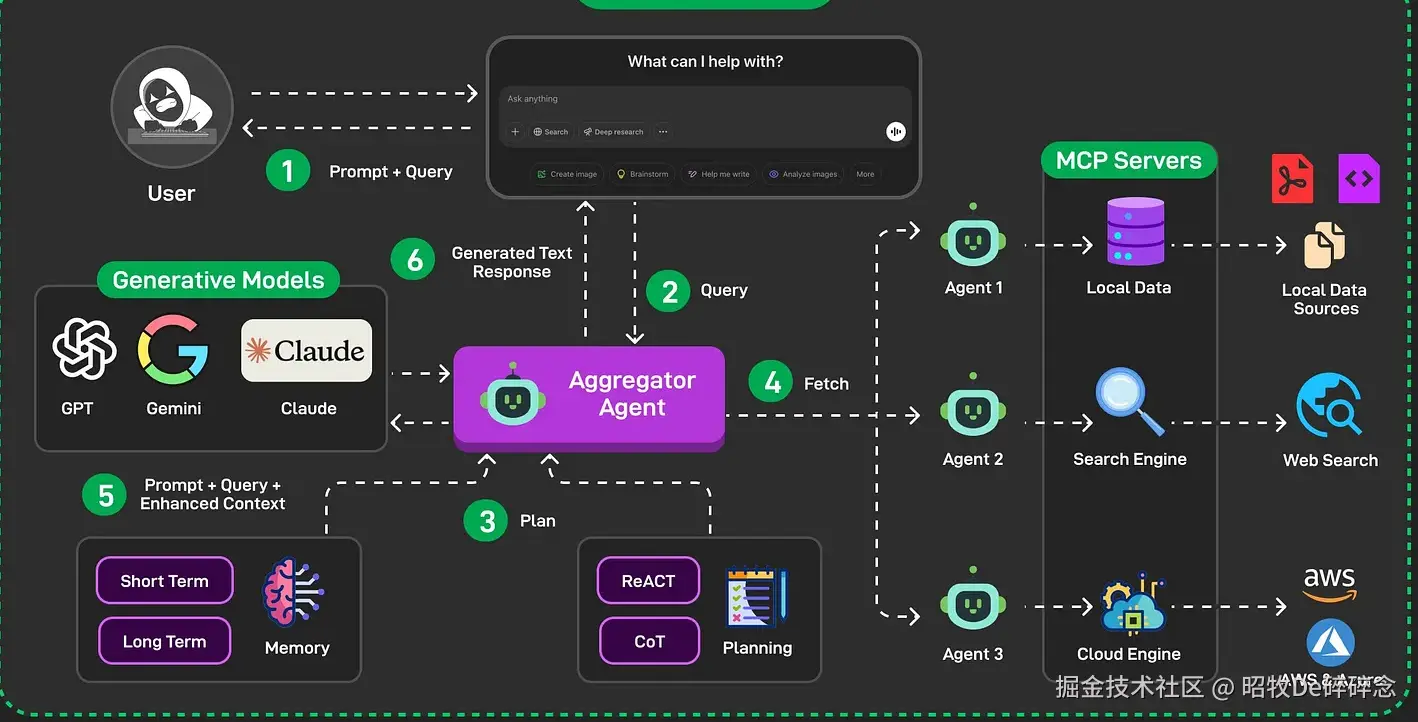
LLM 出现后,为了解决LLM几个天然的问题,诞生了 RAG、CoT、Function Calling、ReAct、Long term 等的技术,最终这些技术都被归纳到了 Tools、Plan、Memory 这几个模块。
| 问题 | 原因 | 解决办法 |
|---|---|---|
| 无实时信息 | LLM 的知识来自训练语料,是静态的、过去的。训练完成后,除非重新训练,否则它不会更新认知。新的法律、政策、新闻,用户私有文档,它都不知道 | 引入 RAG(2020年) 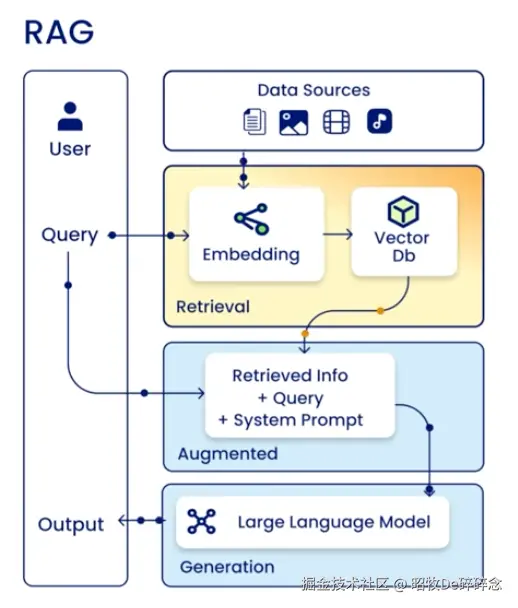 |
| 逻辑推理能力不佳 | LLM 的核心机制是基于训练集中的学习到的模式预测下一词,而不是理解问题背后的概念或结构,更不存在逻辑推理能力,不能完成需要精确计算或复杂计算/推理的任务。如: 数学题 | 引入 CoT(2022年),帮助 LLM 在多个中间步骤间维持连贯逻辑,提高准确率 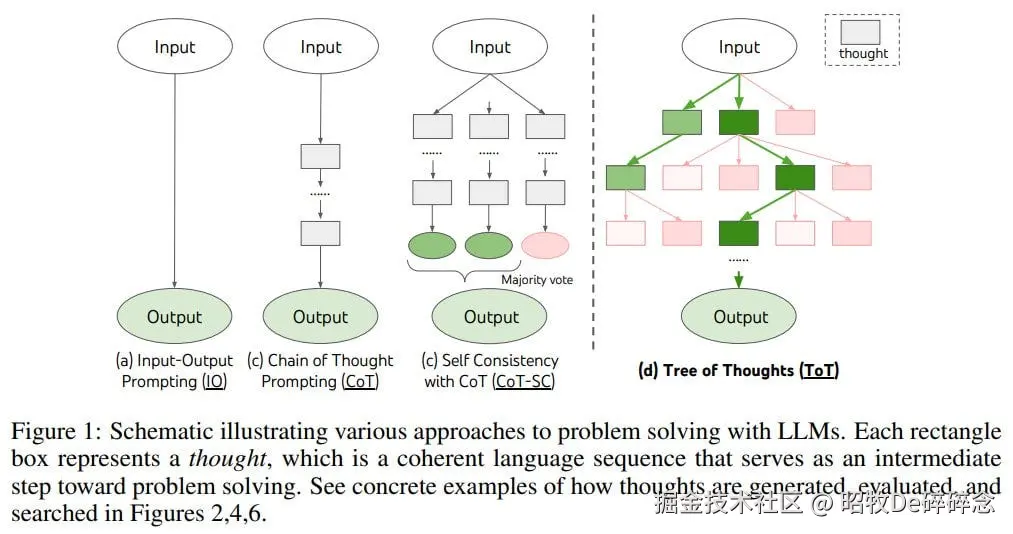 |
| 无行动能力 | 只能输出文字,不能真正去访问工具、执行操作 | 引入 Function Calling(2023年)- 2023 年 6 月 13 日,OpenAI 发布了题为 "Function calling and other API updates" 的公告,宣布推出新的 function calling 功能,允许开发者向模型描述函数,并让模型在合适的时候输出一个 JSON 格式的函数调用参数。 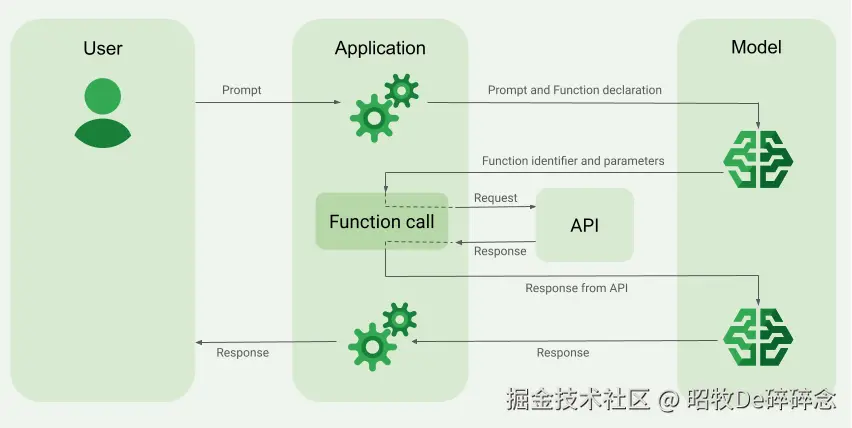 |
| 推理孤立(Reasoning Only)难以纠正 | 单纯依赖 Chain-of-Thought 推理,会随着多步推理累积错误,造成误导或最终结果出错,且难以纠正。 | 引入 ReAct(2023年),通过 Reasoning + Action 循环交替(Thought → Action → Observation → Thought...)在推理过程中更新计划,处理异常,并借助观察修正路径 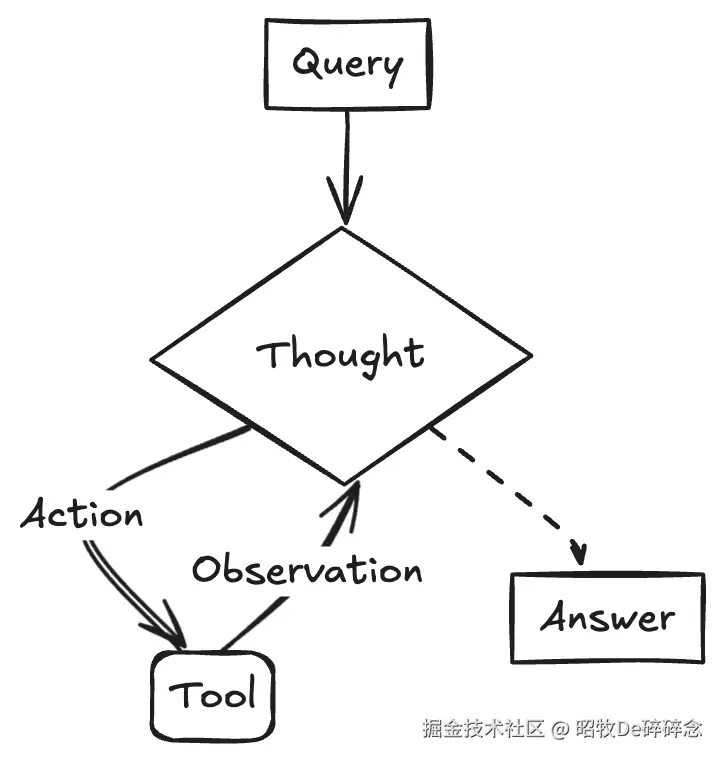 |
| 上下文只能保留有限token | LLM 的上下文窗口有严格上限,即便如今某些模型已支持到百万 token,都意味着信息量依然受到限制。在多轮对话或长任务中,老旧或不重要的信息往往被截断或遗忘,导致连贯性和整体理解能力下降 | 引入 Long-Term Memory(2023年), "Augmenting Language Models with Long-Term Memory" |
实现拆解
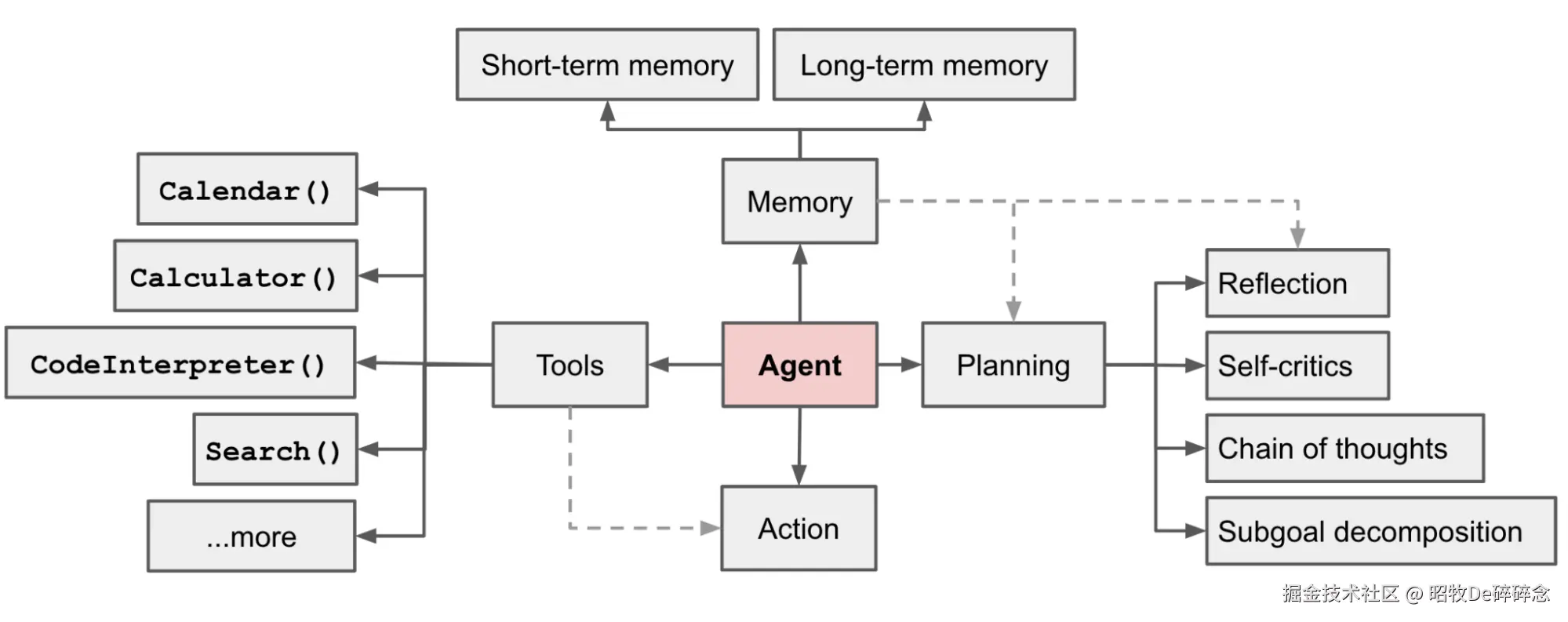
Tools
Tools的定义
Tools 是一种抽象,将一个函数(或其他实现)包装成LLM 可以调用的对象,其中包含名称、描述(用于提示模型)以及输入参数的 JSON schema 描述
Tools 在 Agent 的使用
- Agent 会根据 Tools 提供的名称、描述和参数 schema,拼进prompt 内,通过 prompt 让 LLM 知道何时可以调用哪个工具
python
Tool(
name="Calculator",
func=calculator_function,
description="Use this tool to perform calculations."
)在 LLM 生成结果时,如果 LLM 认为某个工具的调用是必要的,会在结果中包含一个 tool_calls 字段,指示需要调用的工具及其参数。这个结构化的输出使得 Agent 能够准确地解析工具调用,并执行相应的操作。
json
{
"tool_calls": [
{
"id": "call_1",
"function": {
"arguments": "{\"a\": 2, \"b\": 3}",
"name": "multiply"
},
"type": "function"
}
]
}- Agent 分析 LLM 生成的内容,如果需要使用 Tool,则调用具体的 Tool 并将结果反馈给模型,形成"模型→工具→模型"的循环结构。
当 Agent 决定需要调用某个 Tool 时,它会生成一个结构化的 ToolCall 对象。该对象包含:
json
{
"name": "multiply",
"args": {"a": 2, "b": 3},
"id": "call_1",
"type": "tool_call"
}Agent 执行 Tool 并获取结果
python
tool_output = multiply.invoke({"a": 2, "b": 3})Agent 将 Tool 结果反馈给 LLM
python
# tool_output 结果为
tool_message = ToolMessage(
content="The result is 42.",
tool_call_id="call_1"
)
# 假设 chat_history 是一个短期记忆的实例,更新对话历史, 支持LLM多轮对话时可以利用之前的 tool 结果,避免重复调用
chat_history.add_messages([tool_message])
# 假设 user_input 是用户的输入
messages = [
("human", user_input),
("tool", tool_message.content)
]
# 将 tool 的输出作为上下文信息提供给 LLM,生成最终的结果
ai_message = llm_with_tools.invoke(messages)Planning
Planning 是指让 LLM 具备分解复杂任务、规划执行步骤、动态调整策略的能力,以解决需要多步推理或多工具协作的复杂问题。模拟了人类解决问题时,拆分目标->制定步骤->执行调整的思维过程。
Planning的实现有三种
- 提示词(Prompt-based) 通过精心设计的提示词引导 LLM 自主完成任务拆解和步骤规划,适用于逻辑相对固定、无需复杂工具调用的场景。
- Chain 结构化规划 通过 链(Chain) 将多个子任务按固定流程串联,适用于步骤明确、依赖关系固定的场景,本质是硬编码规划。预先定义子任务的执行顺序(如: 数据采集->清洗->分析->输出),用 Chain 组件将每个步骤的输入输出衔接,形成流水线式规划。
- Agent 动态规划 Agent 自主拆解任务、调整步骤、执行工具以完成复杂目标。具体实现方式有 ReAct(思考Reason->行动Act->观察Observe)、Plan and Execute、Self Reflective
小思考:
- Agent如何从失败Plan中学习经验?
- CoT 和 WorkFlow 的关系是什么?
Memory
Memory 支撑 Agent 实现上下文感知、历史经验复用、长期决策连贯性。 不同类型的 Memory 对应不同的应用场景,其实现方案差异显著。最经典的分类方式是按时间跨度划分:
| 类型 | 核心场景 | 数据特点 | 存储周期 |
|---|---|---|---|
| 短期记忆(STM) | 会话内交互、实时决策 | 数据量小、时效性强、完整度高 | 单次会话 / 分钟级 |
| 长期记忆(LTM) | 跨会话复用、经验积累 | 数据量大、需提炼、长期有效 | 跨会话 / 永久级 |
短期记忆(STM)实现
用队列(deque)实现,限制最大长度(避免内存溢出)
python
from collections import deque
class ShortTermMemory:
def __init__(self, max_length=10):
self.memory = deque(maxlen=max_length) # 固定长度队列,自动FIFO
def store(self, content, source):
"""存储新的会话信息"""
entry = {
"entry_id": f"stm-{len(self.memory)}",
"content": content,
"metadata": {"source": source, "timestamp": self._get_current_time()}
}
self.memory.append(entry)
def retrieve_all(self):
"""检索所有短期记忆(用于当前会话决策)"""
return list(self.memory)
def _get_current_time(self):
import datetime
return datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")长期记忆(LTM)实现
采用 SQLite 存元数据 + FAISS 存向量 的混合方案,支持语义检索
python
import sqlite3
import faiss
import numpy as np
from sentence_transformers import SentenceTransformer
# 1. 初始化 Embedding 模型(用于生成内容向量)
emb_model = SentenceTransformer('all-MiniLM-L6-v2')
emb_dim = 384 # all-MiniLM-L6-v2 的输出维度
class LongTermMemory:
def __init__(self, db_path="ltm.db", faiss_index_path="ltm_index.faiss"):
# 初始化 SQLite 数据库(存元数据)
self.conn = sqlite3.connect(db_path)
self._create_table()
# 初始化 FAISS 索引(存向量)
self.faiss_index = self._load_faiss_index(faiss_index_path)
self.faiss_index_path = faiss_index_path
def _create_table(self):
"""创建元数据表"""
cursor = self.conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS memory_entries (
entry_id TEXT PRIMARY KEY,
content TEXT,
memory_type TEXT,
timestamp TEXT,
source TEXT,
relevance_score REAL
)
''')
self.conn.commit()
def _load_faiss_index(self, path):
"""加载或创建 FAISS 索引"""
try:
return faiss.read_index(path)
except:
index = faiss.IndexFlatL2(emb_dim) # 简单的L2距离索引(适合小数据)
faiss.write_index(index, path)
return index
def store(self, content, memory_type, source, relevance_score=0.5):
"""存储长期记忆(元数据→SQLite,向量→FAISS)"""
# 生成 Entry ID 和向量
entry_id = f"ltm-{self._get_next_id()}"
embedding = emb_model.encode([content])[0].astype(np.float32)
# 1. 存入 SQLite
cursor = self.conn.cursor()
cursor.execute(INSERT INTO memory_entries)
self.conn.commit()
# 2. 存入 FAISS(需将向量添加到索引,并用ID映射)
self.faiss_index.add(np.array([embedding]))
faiss.write_index(self.faiss_index, self.faiss_index_path)
def retrieve_semantic(self, query, top_k=3):
"""语义检索:找和 query 最相关的 top_k 条记忆"""
# 1. 生成查询向量
query_emb = emb_model.encode([query])[0].astype(np.float32)
# 2. FAISS 检索(返回距离和索引)
distances, indices = self.faiss_index.search(np.array([query_emb]), top_k)
# 3. 从 SQLite 中获取对应元数据
cursor = self.conn.cursor()
results = []
for idx, dist in zip(indices[0], distances[0]):
# 假设 FAISS 索引的 idx 与 SQLite 的 entry_id 按顺序对应(简化处理)
entry_id = f"ltm-{idx+1}" # 需根据实际ID映射调整
cursor.execute('SELECT * FROM memory_entries WHERE entry_id = ?', (entry_id,))
entry = cursor.fetchone()
if entry:
results.append({
"entry_id": entry[0],
"content": entry[1],
"similarity": 1 - dist/2 # 将L2距离转为相似度(0~1)
})
return results小思考
- AI Agent 的定义这么宽泛,是否所有的AI应用都是 AI Agent,包括对话机器人
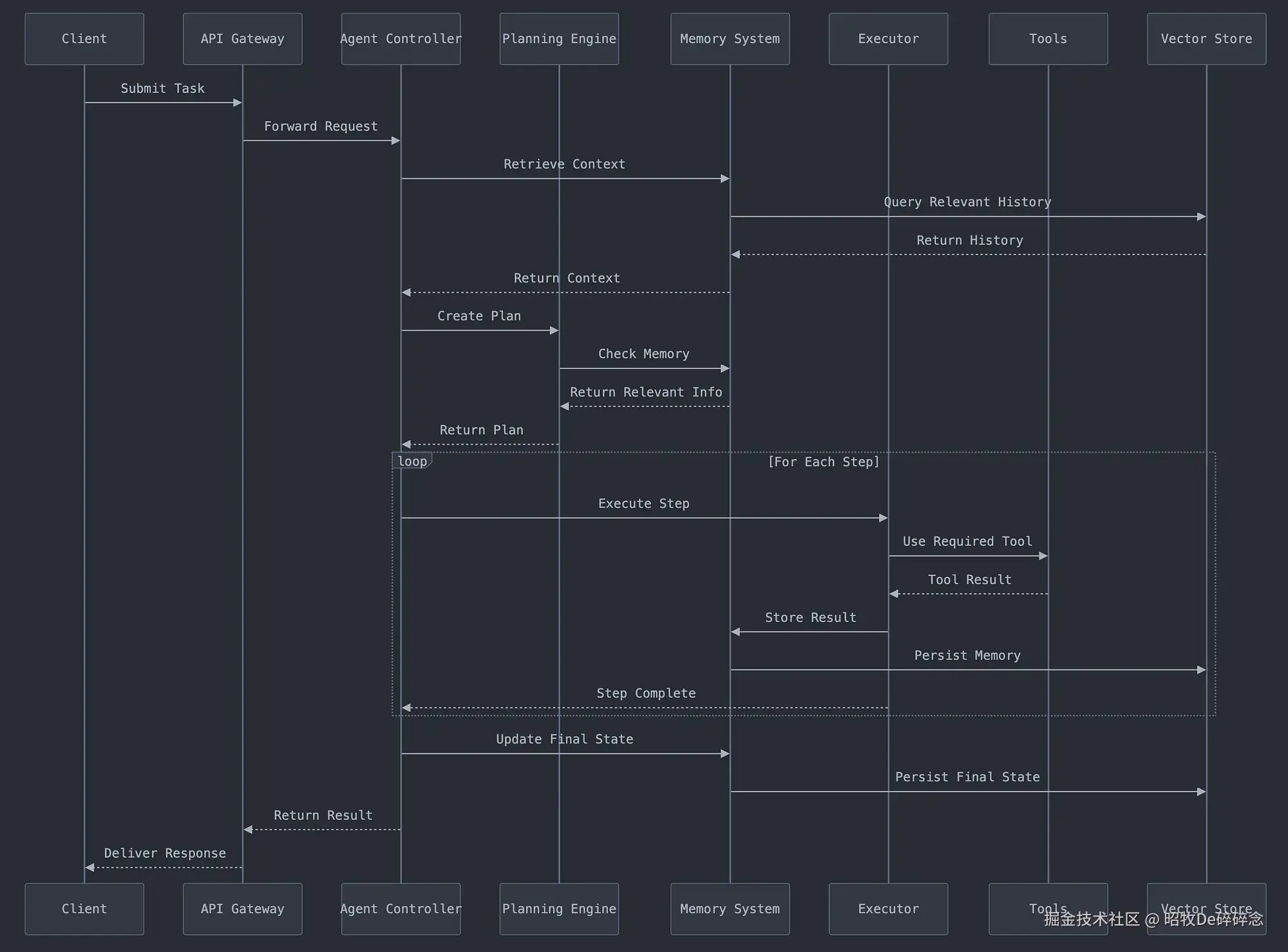
Agent 架构&&流程图
常见 Agent 架构
mp.weixin.qq.com/s/k7v4GMrut...
- 反思模式(Reflection Pattern)
- 工具模式(Tool Use Pattern)
- ReAct 推理与行动模式(Reasoning & Acting)
- 规划模式(Planning Pattern)
- 多智能体模式(Multi - agent Pattern)
AI Agent 时序图