本次主要介绍进程概念和一些进程调用接口,细节很多。
一、进程概念
什么是进程?
这里先给出一个笼统的概念:一个已经加载到内存中的程序就叫做进程,正在运行的程序也叫做进程。Windows系统下有进程管理器(任务管理器),直接搜索任务管理器或者按Shift + Esc + Ctrl都可以打开。
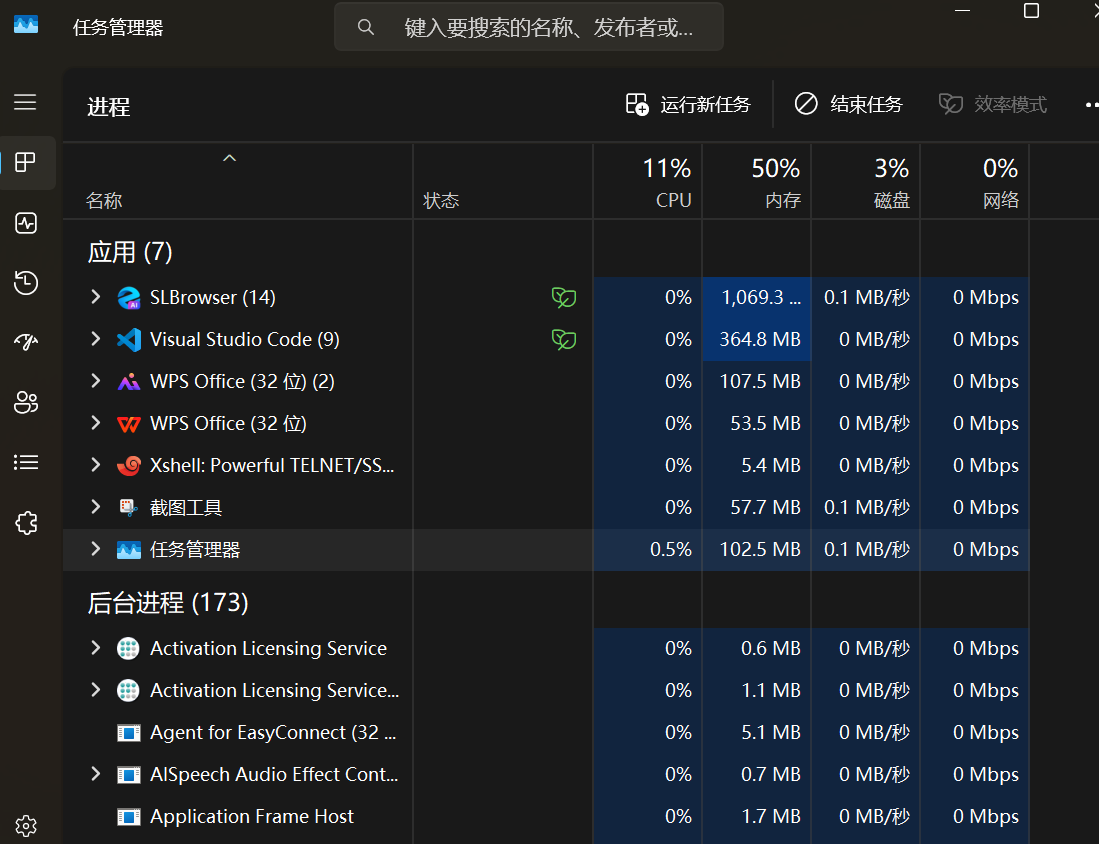
可以看到,有前台进程和后台进程之分,这个我们后面也会提到。
PCB
一个操作系统,不仅可以运行一个进程,也可以运行多个进程,Linux系统下一定存在着大量的进程!那么操作系统一定要将这些进程管理起来,怎么管理?? 先描述再组织。
任何一个可执行要加载到内存中形成一个进程的时候,要先创建描述进程的结构体对象,称之为PCB(Process Control Block) 进程控制块,他是进程属性的集合,就是个结构体,这个结构体中包含了绝大多数进程信息,如进程标识符,进程优先级,进程状态...描述过后怎么组织?? 里面在存放一个指向下一个PCB的指针就可以!!
struct PCB{
进程编号
进程的状态
进程优先级
...
struct PCB* next;
}
task_struct
Linux操作系统具体是怎么做的??
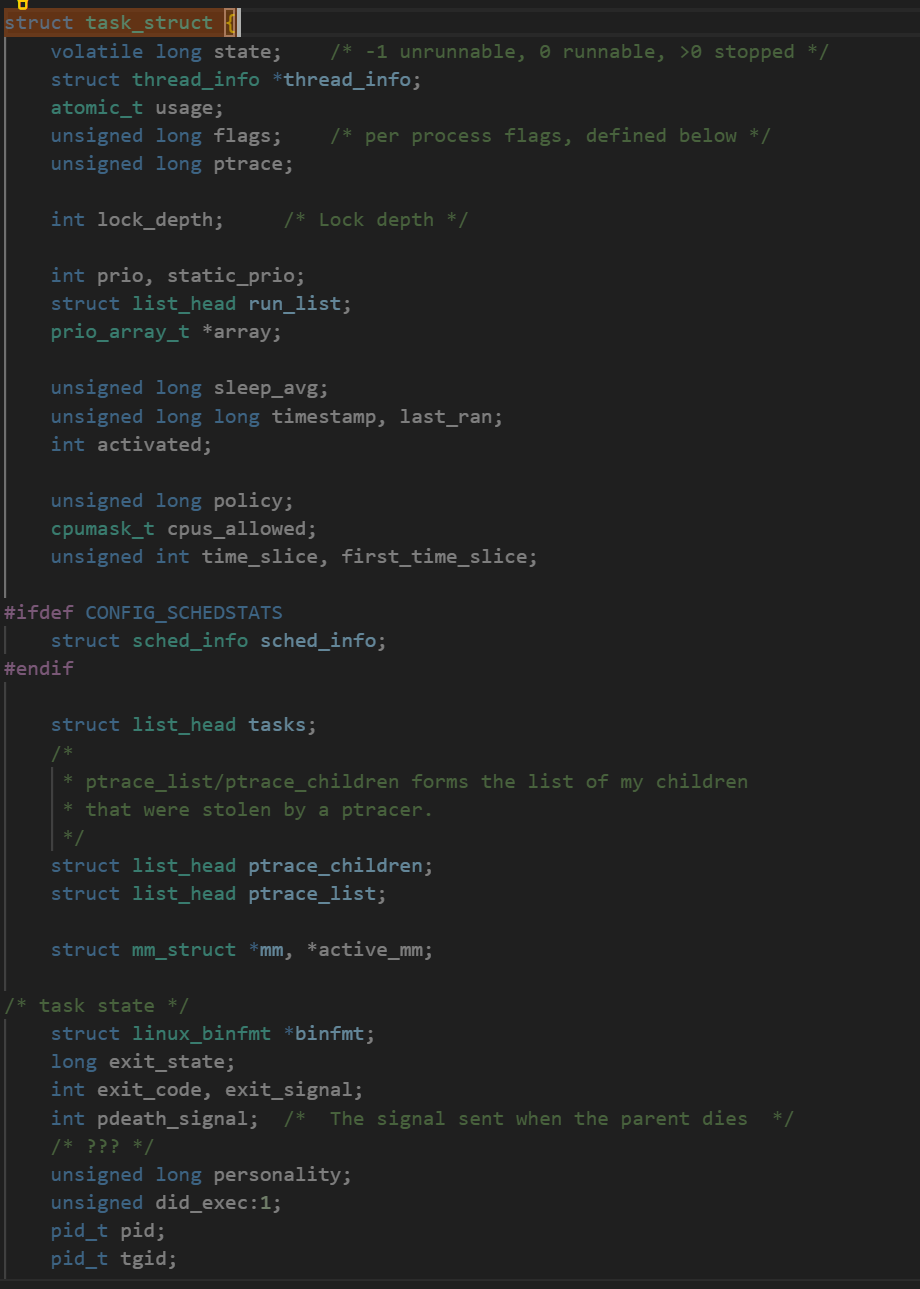
Linux下的PCB叫做task_struct,task_struct是Linux内核的一种数据结构,它会被装载到RAM(内存)里并且包含着进程的信息。如何组织?采用双向链表组织的方式!
task_struct中一定描述了进程的全部信息,比如:
标示符: 描述本进程的唯一标示符,用来区别其他进程。--pid
状态: 任务状态,退出代码,退出信号等。
优先级: 相对于其他进程的优先级。
程序计数器: 程序中即将被执行的下一条指令的地址。pc指针
内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
上下文数据: 进程执行时处理器的寄存器中的数据休学例子,要加图CPU,寄存器。
I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
其他信息等等
可以查看源代码,在include/linux/sched.h这个路径下
查看进程消息
Linux系统下如何查看进程信息呢???
第一种方法:所有的进程信息都会在/proc/pid 下,pid是什么,后面提,理解成标识不同进程的数字即可,是一个具体的数字.
第二种方法:top指令
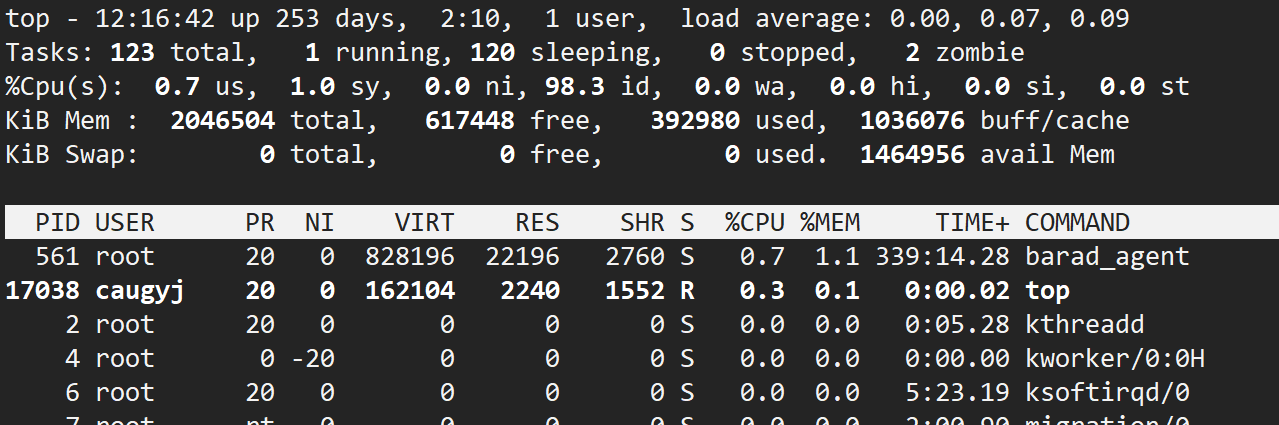
这张图里有很多信息,暂时先看一看后面分析,第二行:123total代表一共123个进程,1running代表一个在运行,120sleeping代表120个在阻塞等等,这代表进程是有状态的,不一定一直在运行。
来看PID USER那一行, 有一个PR 和 NI,这是进程优先级,进程也是有优先级的!
退出按q
第三种方法:ps指令,最常用的是ps ajx (ps aux),查看所有用户的所有进程,
a:显示所有终端关联的进程,比如bash进程
j/u:以用户为中心的格式输出,显示出一些关键信息(USER CPU等等)
x:显示所有终端无关联的进程,后台守护进程、服务进程等等,ssh就是个服务进程。
ps ajx 也常跟grep使用,ps ajx | grep xxx ,可以指定寻找某个字符串。
可以试验一下,自己写一个代码,
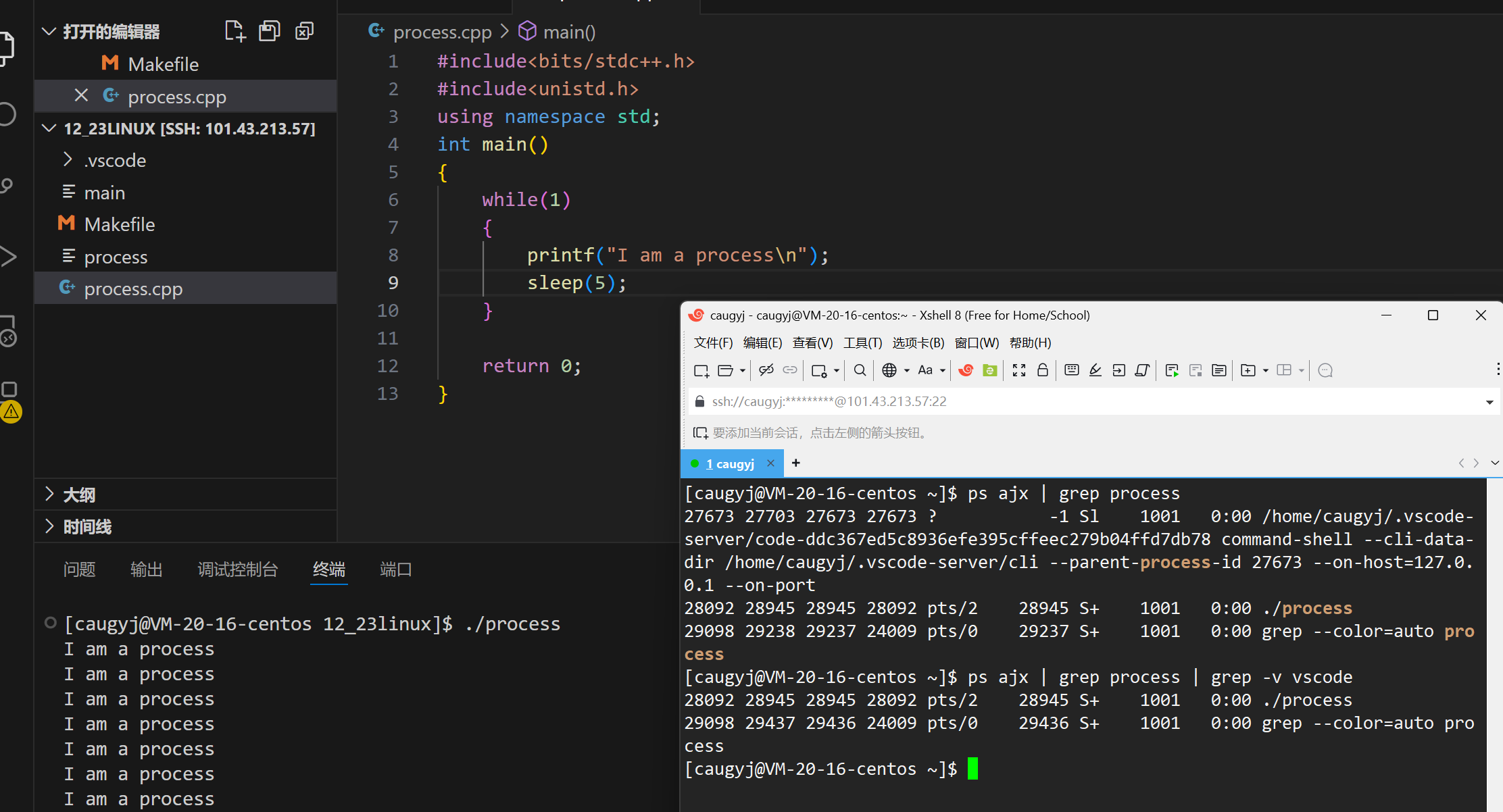
果然我们可以查到自己写的process这个进程。
那我们现在可以重新理解进程,刚才说了进程被加载到内存中运行时,要创建自己的PCB,这个进程当然也要有属于自己的代码和数据,所以,目前来看,进程 = 内核数据结构(PCB) + 自己的代码和数据!
cwd
这里介绍一个知识,比如写一个代码,这份代码就是打开一个文件,没有则创建。
果然创建出了这个文件,但是有个问题,他怎么知道在这个路径下创建的呢??先通过ps ajx | grep xx来查看pid,再通过ls /proc/pid 我们来看一眼进程信息,其中可以看到exe和cwd

这两个都是l开头的,这是个软连接,cwd指的是current work dir:当前进程的工作目录!所以,创建文件的路径实际上是cwd/p.txt!
二、关于进程的系统调用接口
这里先提一下pid和ppid过渡到系统调用接口
pid、ppid、bash
操作系统中有这么多进程,怎么区分?--pid,进程标识符,不同进程有不同的pid,一个pid就可以确定一个进程!
怎么查看?ps ajx | head -1是显示出第一行,方便查看pid,&&代表都执行,可以用; 至于grep -v xx代表搜索不存在xx的内容,主要是看起来舒服,grep时,grep也相当于一个进程!所以会查到自己。

这里看到了有个pid,还有个ppid是什么?ppid是父进程的pid,并且如果你多次运行这个程序就会发现,pid会变但是ppid不会变,那这是什么呢??
我们查一下这个数字
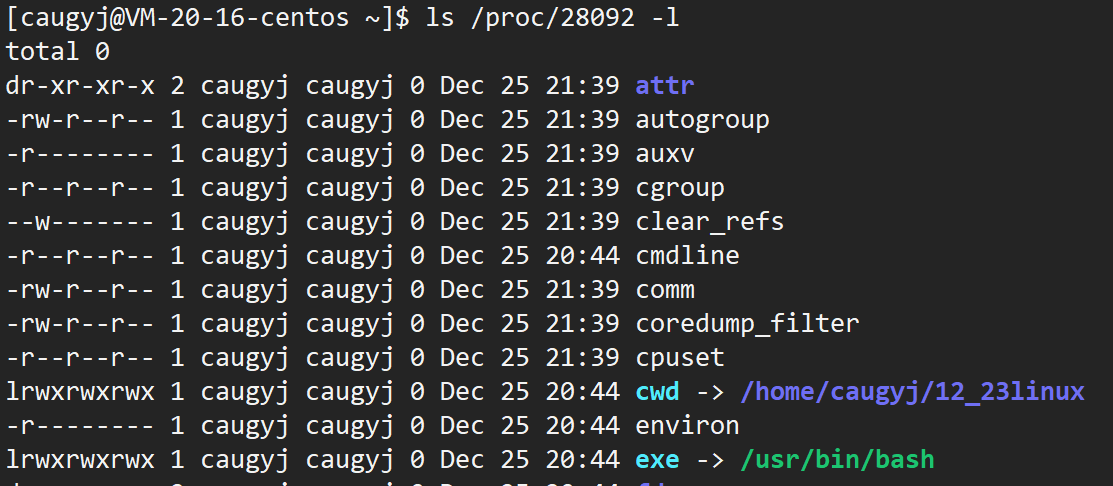
我们发现可执行的名字是bash.这里我们要引入一个知识了,bash是Unix/Linux下最常用的命令行解释器!每次打开一个新的终端,都会为我们启动一个bash进程!
这就是bash进程为你提供的交互环境!你输入命令,bash帮你解释并且执行命令!终端对应的bash进程会作为父进程!这里不是一定要创建子进程去执行命令的!也有可能就是bash自己这个进程去执行,因为命令还分为内建命令和普通命令之分!
可以通过echo $$来查看bash的pid,输入exit 或者logout就是告诉bash结束!
这里再简单谈一下ppid,父进程有什么作用?
1.可以创建子进程去完成任务,比如bash进程
2.管理子进程的资源和权限,子进程可以继承父进程的环境变量。
3.回收子进程的生命周期,防止资源泄露。
第一条比较好理解,bash就是一个很好的例子。对于第二、第三条,我们后面还会再提,这里先暂时知道即可。
getpid、getppid
刚才是用指令查看的pid,能不能从代码层面呢?可以--操作系统不相信任何用户,但是为了给用户提供服务要提供系统调用接口!可以通过man2号手册来查询--getpid()和getppid()
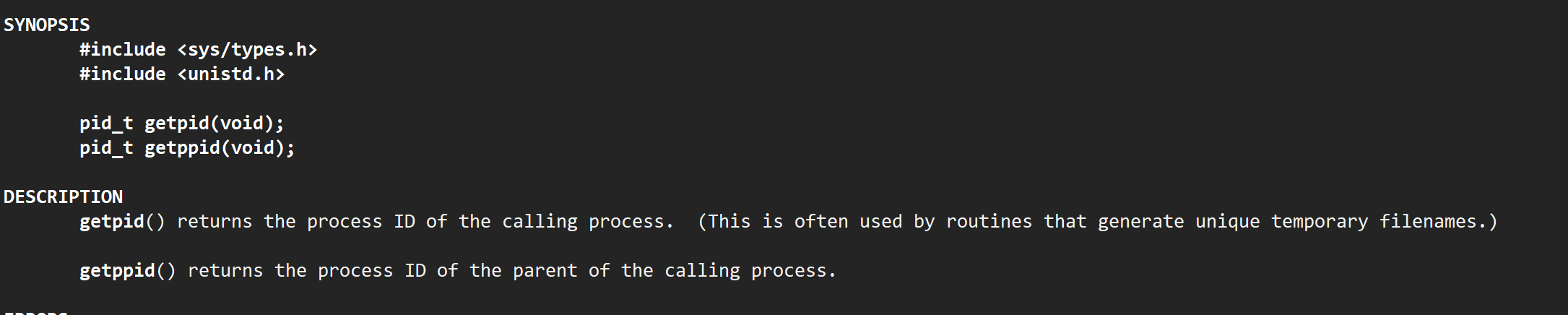
用法和含义都比较好理解,就是获得当前进程 / 当前父进程的pid,返回值是pid_t ?? 这是什么类型呢?如果你一路去查下去,它的定义,实际上就是int。
写一份代码来看看情况,顺便还可以验证一下bash。
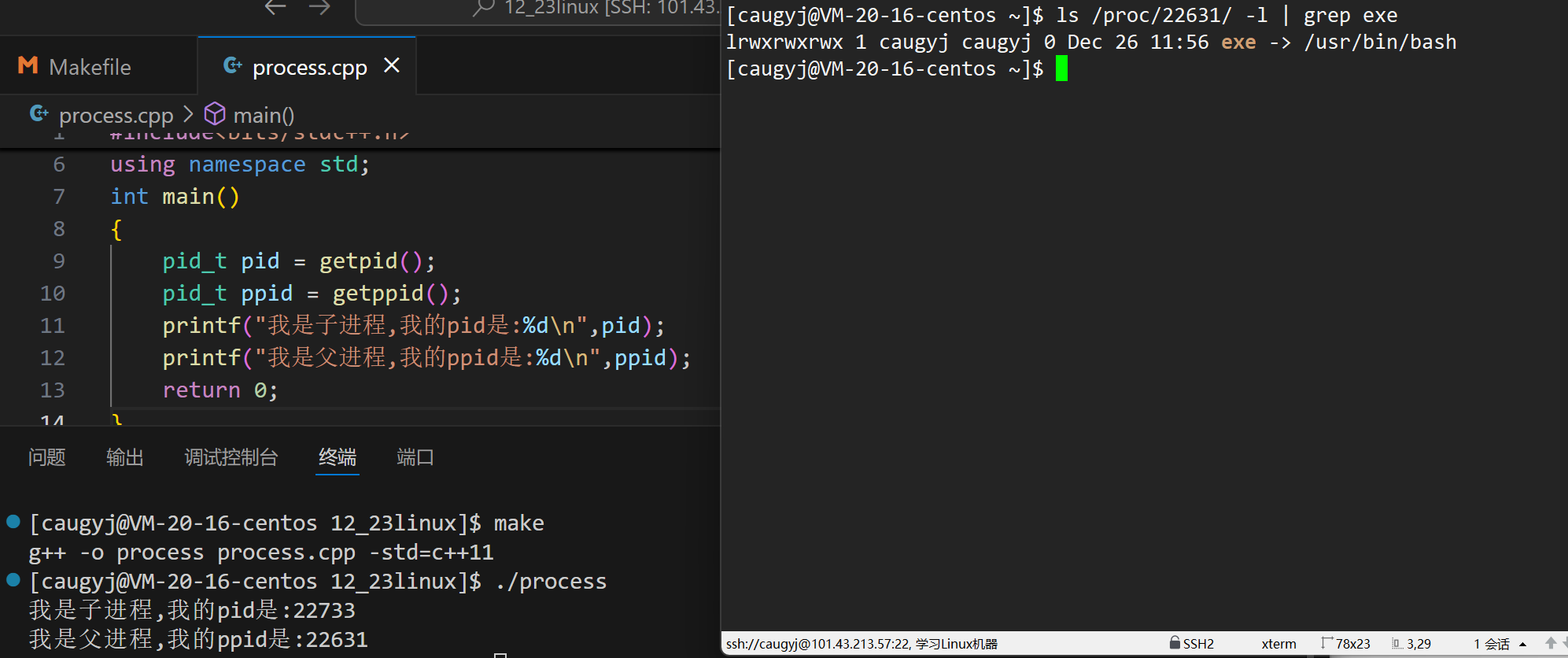
得到了22631去查果然是bash进程
fork
./process是在指令层面创建了一个进程,那我能不能从代码层面呢??可以--操作系统不相信任何用户,但是为了给用户提供服务要提供系统调用接口,这里来看一个非常重要的系统调用接口fork(), 依旧man 2 fork来查
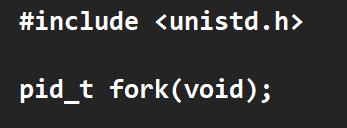
用法好像非常简单,返回值是pid_t,那它怎么能够额外创建一个进程呢?
来看返回值含义,可以/return来搜索

简单翻译一下,如果成功,子进程的PID被返回给父进程,0返回给子进程,如果失败,-1被返回给父进程,没有子进程被创建并且错误码被设置。
这一个变量返回给了两个进程?C/C++中也没见过啊,这里先写一份fork常用的代码再去分析。
cpp
#include<bits/stdc++.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
using namespace std;
int main()
{
pid_t id = fork();
if(id == 0)
{
while(1)
{
sleep(1);
printf("我是子进程,我的pid是%d\n",getpid());
}
}
else if(id > 0)
{
while(1)
{
sleep(1);
printf("我是父进程,我自己的pid是%d,我的子进程的pid是%d\n",getpid(),id);
}
}
else {
//异常情况处理
}
return 0;
}运行结果:

查一下进程:

可以发现确实确实创建了子进程!pid也对的上
这份代码竟然同时执行了if(id == 0) 和 else if(id > 0)!id难道既能大于0又能等于0??这里我们来分析一下四个问题.
1.为什么要有不同的返回值?为什么要给子进程返回0,给父进程返回子进程的pid?
2.一个函数是如何做到返回两次的?如何理解?
3.一个变量怎么会有不同的内容,如何理解?
4.fork到底干了什么?
1.有不同返回值的原因是为了让不同的执行流来执行不同的代码块。
为什么返回值具体是这样的呢?
父进程需要知道子进程的pid来进行后续的管理,子进程可以通过getpid()获取自己的pid,也没必要知道父进程的pid,用0返回更加简洁。
另外:一般而言,fork之后父子进程代码共享。
2.想知道这个就得谈谈fork干了什么,进程 = 内核数据结构(PCB) + 自己的代码和数据,每一个进程要被创建时,一定要创建自己的PCB!上面可以看到子进程确实被创建了!
所以fork大体上是这么个流程:
a.创建子进程的PCB
b.填充子进程的PCB、大部分都和父进程一样,仅有一些关键字段会自己填充
c.子进程当然要有自己的代码和数据,因为代码是不可以修改的,子进程和父进程就可以指向相同的代码!那么数据呢?数据可能被修改,那就不能让父子进程指向同一份数据,具体怎么办呢?。
第一种思路:拷贝一份父进程的数据,这样就没有影响了,但是这种思路不好,子进程被创建出来都不一定干什么,拷贝完数据有可能一点不去修改,这样很浪费资源!
第二种思路:子进程和父进程指向同一份数据,但是如果要进行数据的修改,就额外开辟块空间,这种做法比较好,没有浪费资源,这种我们称之为写时拷贝!
d.父子进程都有自己独立的PCB,可以被CPU调度运行了!
所以,fork的返回值是pid_t, 一定会有一句代码是return xx,fork之后的代码父子共享!所以父进程要return,子进程也要return,这就是为什么一个函数如何做到返回了两次
另外,父子进程被创建好之后,谁先运行是不一定的!由调度器决定!
3.暂时理解成发生了写时拷贝!至于具体是怎么样的,后面的虚拟地址空间再说.
4.fork干了什么在第二个问题的回答中已经解决完了,创建PCB,填充PCB,指向相同的代码。