一、引言:监控告警系统的核心价值
"在Netflix,每天处理超过2万亿个监控指标,每秒进行数百万次告警计算,确保全球1.5亿用户的流畅体验。" 监控与告警系统是现代分布式系统的"眼睛"和"耳朵",它不仅是故障检测的工具,更是系统优化、容量规划和业务决策的基础。一个优秀的监控系统能够帮助工程师在用户发现问题之前就发现并解决问题。
学习目标:
-
理解监控告警系统的核心架构和设计原则
-
掌握指标采集、存储、查询、可视化等关键技术
-
设计一个支持海量指标的分布式监控系统
-
学习智能告警、根因分析、异常检测等高级功能
-
应对面试中的深度追问和实际应用场景
先导问题(思考启动):
-
如何实时收集数千台服务器上的百万级指标?
-
如何在秒级内查询数十亿个时间序列数据点?
-
如何避免"告警疲劳"并实现智能告警?
-
如何从数百个异常指标中快速定位根因?
-
如何设计一个支持预测性告警的系统?
二、需求分析与系统特性
2.1 监控告警系统的业务场景分析
python
# 监控告警系统的业务特征分析
class MonitoringScenario:
def __init__(self):
self.scenarios = {
"INFRASTRUCTURE_MONITORING": {
"description": "基础设施监控(服务器、网络、存储)",
"challenges": ["海量指标", "实时采集", "资源消耗"]
},
"APPLICATION_MONITORING": {
"description": "应用性能监控(APM)",
"challenges": ["分布式追踪", "代码级监控", "业务指标"]
},
"BUSINESS_MONITORING": {
"description": "业务指标监控(交易量、用户活跃度)",
"challenges": ["数据一致性", "实时计算", "业务关联"]
},
"LOGS_MONITORING": {
"description": "日志监控与分析",
"challenges": ["非结构化数据", "实时搜索", "模式识别"]
},
"SYNTHETIC_MONITORING": {
"description": "合成监控(主动探测)",
"challenges": ["全球探测点", "性能基准", "可用性检查"]
}
}
def quantify_requirements(self, scale="large"):
"""量化需求规格"""
metrics = {
"small": { # 小型监控系统(千台服务器)
"servers": 1_000,
"metrics_per_second": 100_000,
"total_metrics": 10_000_000,
"data_points_per_day": 8.64e9,
"storage_needed": "10TB",
"query_latency": "<5s",
"retention_days": 30
},
"medium": { # 中型监控系统(万台服务器)
"servers": 10_000,
"metrics_per_second": 1_000_000,
"total_metrics": 100_000_000,
"data_points_per_day": 86.4e9,
"storage_needed": "100TB",
"query_latency": "<2s",
"retention_days": 90
},
"large": { # 大型监控系统(十万台服务器)
"servers": 100_000,
"metrics_per_second": 10_000_000,
"total_metrics": 1_000_000_000,
"data_points_per_day": 864e9,
"storage_needed": "1PB",
"query_latency": "<1s",
"retention_days": 365
}
}
return metrics.get(scale, metrics["medium"])2.2 功能性需求矩阵
| 功能模块 | 核心功能 | 技术挑战 | 关键技术 |
|---|---|---|---|
| 数据采集 | 指标收集、日志收集 | 低资源消耗、高吞吐 | 代理采集、Pull/Push模型 |
| 数据存储 | 时间序列存储 | 高写入吞吐、高效压缩 | TSDB、列式存储、压缩算法 |
| 数据查询 | 指标查询、聚合 | 低延迟查询、复杂聚合 | 索引优化、查询引擎 |
| 告警引擎 | 规则评估、告警触发 | 实时计算、避免抖动 | 流处理、窗口计算 |
| 可视化 | 仪表板、图表 | 实时刷新、交互查询 | Web技术、图表库 |
| 根因分析 | 异常定位、关联分析 | 多维分析、机器学习 | 相关性分析、异常检测 |
| 智能告警 | 异常检测、预测告警 | 算法准确度、低误报 | 时序预测、AI算法 |
2.3 非功能性需求(NFRS)
python
class NonFunctionalRequirements:
@staticmethod
def get_nfrs():
return {
"PERFORMANCE": {
"ingestion_latency": "<1秒(p99)",
"query_latency": {
"simple": "<100ms",
"complex": "<5秒"
},
"alert_evaluation": "<10秒",
"scalability": "支持每秒千万指标"
},
"RELIABILITY": {
"availability": "99.99%",
"data_durability": "99.999999999%",
"alert_accuracy": "误报率<1%,漏报率<0.1%"
},
"SCALABILITY": {
"horizontal": "支持无限水平扩展",
"storage": "支持PB级数据",
"queries": "支持千并发查询"
},
"MAINTAINABILITY": {
"config_management": "配置热更新",
"auto_discovery": "自动发现监控目标",
"self_healing": "组件故障自动恢复"
},
"COST_EFFECTIVENESS": {
"storage_efficiency": "压缩比>10:1",
"compute_efficiency": "CPU/指标比优化",
"operational_cost": "自动化运维"
}
}2.4 系统容量估算
假设我们要设计一个支持十万台服务器的监控系统:
图1:监控系统数据流模型

容量计算:
python
class CapacityCalculator:
def __init__(self, servers=100_000, metrics_per_server=1000, interval=10):
self.servers = servers
self.metrics_per_server = metrics_per_server
self.interval = interval # 采集间隔(秒)
def calculate_requirements(self):
# 总指标数
total_metrics = self.servers * self.metrics_per_server
# 数据点产生速率
data_points_per_second = total_metrics / self.interval
# 原始数据量(每个数据点16字节)
raw_data_per_second_mb = data_points_per_second * 16 / (1024**2)
# 每日数据量
raw_data_per_day_tb = raw_data_per_second_mb * 86400 / (1024**2)
# 压缩后数据量(假设10:1压缩比)
compressed_data_per_day_tb = raw_data_per_day_tb / 10
# 90天存储需求
storage_90_days_tb = compressed_data_per_day_tb * 90
# 内存需求(热数据缓存)
hot_data_hours = 24 # 缓存24小时热数据
hot_data_size_gb = compressed_data_per_day_tb * 1024 / 24 * hot_data_hours
# 网络带宽(考虑复制和查询)
network_bandwidth_gbps = raw_data_per_second_mb * 8 * 3 / 1000 # 3副本
return {
"total_metrics_millions": round(total_metrics / 1_000_000, 2),
"data_points_per_second_millions": round(data_points_per_second / 1_000_000, 2),
"raw_data_per_second_mb": round(raw_data_per_second_mb, 2),
"raw_data_per_day_tb": round(raw_data_per_day_tb, 2),
"compressed_data_per_day_tb": round(compressed_data_per_day_tb, 2),
"storage_90_days_tb": round(storage_90_days_tb, 2),
"hot_data_cache_gb": round(hot_data_size_gb, 2),
"network_bandwidth_gbps": round(network_bandwidth_gbps, 2)
}
calculator = CapacityCalculator()
requirements = calculator.calculate_requirements()
print("监控系统容量估算结果:")
for key, value in requirements.items():
print(f" {key}: {value}")三、系统架构设计
3.1 总体架构设计原则
图2:监控告警系统分层架构图
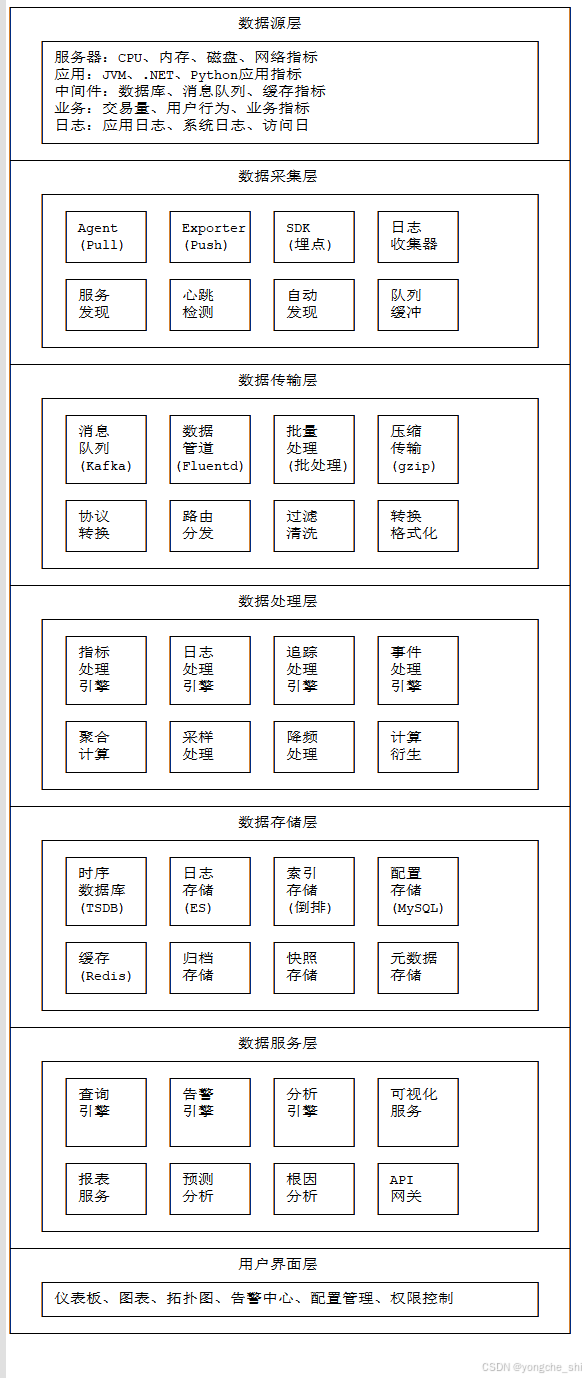
3.2 详细架构设计
3.2.1 数据采集层设计
python
class MetricsCollector:
"""指标采集器 - 支持多种采集模式"""
def __init__(self):
self.collectors = {
'pull': PullCollector(),
'push': PushCollector(),
'agent': AgentCollector(),
'sdk': SDKCollector()
}
self.discovery = ServiceDiscovery()
self.buffer = MetricsBuffer()
async def start_collection(self):
"""启动采集"""
# 1. 服务发现
targets = await self.discovery.discover_targets()
# 2. 配置采集任务
for target in targets:
collection_method = self.select_collection_method(target)
collector = self.collectors[collection_method]
# 创建采集任务
task = CollectionTask(
target=target,
collector=collector,
interval=target.get('interval', 10),
metrics=target.get('metrics', [])
)
# 启动任务
asyncio.create_task(task.run())
def select_collection_method(self, target):
"""选择采集方法"""
target_type = target.get('type', 'server')
if target_type == 'server':
# 服务器指标,使用Pull模式
return 'pull'
elif target_type == 'application':
# 应用指标,支持SDK或Exporter
if target.get('has_sdk', False):
return 'sdk'
else:
return 'push'
elif target_type == 'middleware':
# 中间件,通常有Exporter
return 'push'
elif target_type == 'custom':
# 自定义指标,使用Agent
return 'agent'
else:
return 'pull'
class PullCollector:
"""Pull模式采集器(主动拉取)"""
async def collect(self, target):
"""采集指标"""
url = f"http://{target['host']}:{target.get('port', 9100)}/metrics"
try:
async with aiohttp.ClientSession(timeout=aiohttp.ClientTimeout(total=5)) as session:
async with session.get(url) as response:
if response.status == 200:
data = await response.text()
return self.parse_metrics(data, target)
except Exception as e:
logger.error(f"Failed to collect from {target['host']}: {e}")
return []
def parse_metrics(self, data, target):
"""解析指标数据(Prometheus格式)"""
metrics = []
for line in data.split('\n'):
line = line.strip()
if not line or line.startswith('#'):
continue
# 解析指标行
# 格式: metric_name{label1="value1",...} value timestamp
if '}' in line:
metric_part, value_part = line.split('}', 1)
metric_name = metric_part.split('{')[0]
labels_str = metric_part.split('{')[1]
# 解析标签
labels = self.parse_labels(labels_str)
# 添加目标标签
labels.update({
'instance': target['host'],
'job': target.get('job', 'default')
})
# 解析值和时间戳
value_str = value_part.strip().split()[0]
value = float(value_str)
metrics.append({
'metric': metric_name,
'labels': labels,
'value': value,
'timestamp': int(time.time() * 1000)
})
return metrics
def parse_labels(self, labels_str):
"""解析标签字符串"""
labels = {}
# 移除花括号
labels_str = labels_str.strip('{}')
if not labels_str:
return labels
for pair in labels_str.split(','):
if '=' in pair:
key, value = pair.split('=', 1)
# 移除引号
value = value.strip('"')
labels[key.strip()] = value
return labels
class PushCollector:
"""Push模式采集器(被动接收)"""
def __init__(self, port=9091):
self.port = port
self.metric_buffer = {}
async def start_server(self):
"""启动HTTP服务器接收指标"""
from aiohttp import web
app = web.Application()
app.router.add_post('/metrics', self.handle_metrics)
app.router.add_get('/health', self.handle_health)
runner = web.AppRunner(app)
await runner.setup()
site = web.TCPSite(runner, '0.0.0.0', self.port)
await site.start()
logger.info(f"Push collector started on port {self.port}")
async def handle_metrics(self, request):
"""处理指标推送"""
try:
data = await request.json()
# 验证数据格式
if not self.validate_metrics(data):
return web.Response(status=400, text="Invalid metrics format")
# 处理指标
await self.process_metrics(data)
return web.Response(status=200, text="OK")
except Exception as e:
logger.error(f"Failed to process metrics: {e}")
return web.Response(status=500, text=str(e))
async def process_metrics(self, data):
"""处理指标数据"""
timestamp = data.get('timestamp', int(time.time() * 1000))
for metric in data.get('metrics', []):
metric_name = metric['metric']
labels = metric.get('labels', {})
value = metric['value']
# 添加元数据
metric_data = {
'metric': metric_name,
'labels': labels,
'value': value,
'timestamp': timestamp
}
# 缓冲指标(批量写入)
await self.buffer.add(metric_data)
class MetricsBuffer:
"""指标缓冲区 - 批量写入优化"""
def __init__(self, batch_size=1000, flush_interval=5):
self.batch_size = batch_size
self.flush_interval = flush_interval # 秒
self.buffer = []
self.lock = asyncio.Lock()
self.writer = MetricsWriter()
# 启动定时刷新
asyncio.create_task(self.periodic_flush())
async def add(self, metric):
"""添加指标到缓冲区"""
async with self.lock:
self.buffer.append(metric)
# 如果达到批量大小,立即刷新
if len(self.buffer) >= self.batch_size:
await self.flush()
async def periodic_flush(self):
"""定期刷新缓冲区"""
while True:
await asyncio.sleep(self.flush_interval)
await self.flush()
async def flush(self):
"""刷新缓冲区到存储"""
if not self.buffer:
return
async with self.lock:
# 复制缓冲区内容
batch = self.buffer.copy()
self.buffer.clear()
# 异步写入
asyncio.create_task(self.writer.write_batch(batch))
class MetricsWriter:
"""指标写入器"""
def __init__(self):
self.storage_backends = [
TimeSeriesStorage(),
CacheStorage(),
ArchiveStorage()
]
self.compression = MetricsCompression()
async def write_batch(self, batch):
"""批量写入指标"""
if not batch:
return
# 1. 压缩指标
compressed_batch = await self.compression.compress(batch)
# 2. 并行写入多个存储后端
write_tasks = []
for backend in self.storage_backends:
task = asyncio.create_task(backend.write(compressed_batch))
write_tasks.append(task)
# 3. 等待所有写入完成
try:
await asyncio.gather(*write_tasks)
except Exception as e:
logger.error(f"Failed to write batch: {e}")
# 重试机制
await self.retry_write(batch)
async def retry_write(self, batch, max_retries=3):
"""重试写入"""
for attempt in range(max_retries):
try:
await self.write_batch(batch)
return
except Exception as e:
logger.error(f"Write retry {attempt + 1} failed: {e}")
if attempt < max_retries - 1:
await asyncio.sleep(2 ** attempt) # 指数退避
# 所有重试失败,记录到死信队列
await self.dead_letter_queue.add(batch)3.2.2 时间序列存储设计
python
class TimeSeriesStorage:
"""时间序列存储引擎"""
def __init__(self, shard_count=1000):
self.shard_count = shard_count
self.shards = [TimeSeriesShard(i) for i in range(shard_count)]
self.index = TimeSeriesIndex()
self.compactor = CompactionEngine()
async def write(self, metrics):
"""写入指标"""
# 按分片分组
sharded_metrics = {}
for metric in metrics:
# 确定分片
shard_id = self.get_shard_id(metric)
if shard_id not in sharded_metrics:
sharded_metrics[shard_id] = []
sharded_metrics[shard_id].append(metric)
# 并行写入各分片
write_tasks = []
for shard_id, shard_metrics in sharded_metrics.items():
shard = self.shards[shard_id]
task = asyncio.create_task(shard.write(shard_metrics))
write_tasks.append(task)
await asyncio.gather(*write_tasks)
# 更新索引
await self.index.update(metrics)
# 异步执行压缩
asyncio.create_task(self.compactor.compact_if_needed())
def get_shard_id(self, metric):
"""根据指标确定分片"""
# 使用一致性哈希
metric_key = f"{metric['metric']}:{self.hash_labels(metric['labels'])}"
return consistent_hash(metric_key) % self.shard_count
def hash_labels(self, labels):
"""哈希标签"""
# 排序标签以确保一致性
sorted_items = sorted(labels.items())
label_str = ','.join(f"{k}={v}" for k, v in sorted_items)
return hashlib.md5(label_str.encode()).hexdigest()
async def query(self, query):
"""查询指标"""
# 1. 查询索引找到相关时间序列
series_list = await self.index.find_series(query)
# 2. 从各分片并行查询数据
query_tasks = []
for series in series_list:
shard_id = self.get_shard_id(series)
shard = self.shards[shard_id]
task = asyncio.create_task(
shard.query_series(series, query.start_time, query.end_time)
)
query_tasks.append(task)
# 3. 收集结果
results = await asyncio.gather(*query_tasks)
# 4. 合并和聚合
merged_results = self.merge_results(results, query.aggregation)
return merged_results
def merge_results(self, results, aggregation):
"""合并查询结果"""
if not results:
return []
if aggregation == 'none':
# 不聚合,直接返回所有数据点
merged = []
for result in results:
merged.extend(result)
return merged
else:
# 应用聚合函数
return self.apply_aggregation(results, aggregation)
def apply_aggregation(self, results, aggregation):
"""应用聚合函数"""
# 按时间戳分组
time_points = {}
for series_data in results:
for point in series_data:
timestamp = point['timestamp']
value = point['value']
if timestamp not in time_points:
time_points[timestamp] = []
time_points[timestamp].append(value)
# 应用聚合
aggregated = []
for timestamp, values in sorted(time_points.items()):
if aggregation == 'avg':
aggregated_value = sum(values) / len(values)
elif aggregation == 'sum':
aggregated_value = sum(values)
elif aggregation == 'max':
aggregated_value = max(values)
elif aggregation == 'min':
aggregated_value = min(values)
elif aggregation == 'count':
aggregated_value = len(values)
else:
aggregated_value = values[0] # 默认取第一个
aggregated.append({
'timestamp': timestamp,
'value': aggregated_value
})
return aggregated
class TimeSeriesShard:
"""时间序列分片"""
def __init__(self, shard_id):
self.shard_id = shard_id
self.memory_store = MemoryStore() # 内存存储(热数据)
self.disk_store = DiskStore() # 磁盘存储(冷数据)
self.write_buffer = WriteBuffer() # 写入缓冲区
async def write(self, metrics):
"""写入指标到分片"""
# 1. 写入缓冲区
await self.write_buffer.add(metrics)
# 2. 定期刷新到内存存储
if self.write_buffer.size() > 10000:
await self.flush_to_memory()
# 3. 定期持久化到磁盘
if self.memory_store.size() > 100000:
await self.persist_to_disk()
async def flush_to_memory(self):
"""刷新到内存存储"""
buffer_data = await self.write_buffer.flush()
if buffer_data:
await self.memory_store.write(buffer_data)
async def persist_to_disk(self):
"""持久化到磁盘"""
# 获取内存中的旧数据
old_data = await self.memory_store.get_old_data()
if old_data:
# 压缩数据
compressed_data = self.compress_data(old_data)
# 写入磁盘
await self.disk_store.write(compressed_data)
# 从内存中移除
await self.memory_store.remove(old_data)
async def query_series(self, series, start_time, end_time):
"""查询时间序列"""
# 1. 从内存查询(热数据)
memory_results = await self.memory_store.query(series, start_time, end_time)
# 2. 从磁盘查询(冷数据)
disk_results = await self.disk_store.query(series, start_time, end_time)
# 3. 合并结果
merged_results = self.merge_query_results(memory_results, disk_results)
# 4. 按时间戳排序
merged_results.sort(key=lambda x: x['timestamp'])
return merged_results
def compress_data(self, data):
"""压缩时间序列数据"""
# 使用时间序列专用压缩算法
compressed = []
if not data:
return compressed
# 按指标和时间排序
sorted_data = sorted(data, key=lambda x: (x['metric'], x['timestamp']))
current_series = None
previous_timestamp = 0
previous_value = 0
for point in sorted_data:
if current_series != point['metric']:
# 新时间序列
current_series = point['metric']
compressed.append({
'metric': point['metric'],
'labels': point['labels'],
'timestamps': [point['timestamp']],
'values': [point['value']]
})
previous_timestamp = point['timestamp']
previous_value = point['value']
else:
# 同一时间序列,使用增量编码
delta_time = point['timestamp'] - previous_timestamp
delta_value = point['value'] - previous_value
compressed[-1]['timestamps'].append(delta_time)
compressed[-1]['values'].append(delta_value)
previous_timestamp = point['timestamp']
previous_value = point['value']
return compressed
class MemoryStore:
"""内存存储(热数据)"""
def __init__(self):
self.data = {} # metric -> [(timestamp, value), ...]
self.index = {} # 时间索引
self.max_size = 100_000 # 最大数据点数
self.lock = asyncio.Lock()
async def write(self, metrics):
"""写入内存"""
async with self.lock:
for metric in metrics:
key = self.get_key(metric)
if key not in self.data:
self.data[key] = []
self.data[key].append((metric['timestamp'], metric['value']))
# 维护时间索引
if metric['timestamp'] not in self.index:
self.index[metric['timestamp']] = []
self.index[metric['timestamp']].append(key)
async def query(self, series, start_time, end_time):
"""查询数据"""
results = []
async with self.lock:
key = self.get_series_key(series)
if key in self.data:
# 二分查找时间范围内的数据点
points = self.data[key]
# 找到起始位置
start_idx = self.binary_search(points, start_time)
# 收集数据点
for i in range(start_idx, len(points)):
timestamp, value = points[i]
if timestamp > end_time:
break
if timestamp >= start_time:
results.append({
'timestamp': timestamp,
'value': value
})
return results
def binary_search(self, points, target_time):
"""二分查找"""
left, right = 0, len(points) - 1
while left <= right:
mid = (left + right) // 2
if points[mid][0] < target_time:
left = mid + 1
else:
right = mid - 1
return left
def get_key(self, metric):
"""获取存储键"""
return f"{metric['metric']}:{self.hash_labels(metric['labels'])}"
def get_series_key(self, series):
"""获取时间序列键"""
return f"{series['metric']}:{self.hash_labels(series['labels'])}"
def hash_labels(self, labels):
"""哈希标签"""
sorted_items = sorted(labels.items())
label_str = ','.join(f"{k}={v}" for k, v in sorted_items)
return hashlib.md5(label_str.encode()).hexdigest()3.2.3 告警引擎设计
python
class AlertEngine:
"""告警引擎"""
def __init__(self):
self.rules = AlertRules()
self.evaluator = RuleEvaluator()
self.notifier = AlertNotifier()
self.deduplicator = AlertDeduplicator()
self.silencer = AlertSilencer()
async def start(self):
"""启动告警引擎"""
# 1. 加载告警规则
await self.rules.load_rules()
# 2. 启动规则评估
asyncio.create_task(self.evaluation_loop())
# 3. 启动告警处理
asyncio.create_task(self.alert_processing_loop())
async def evaluation_loop(self):
"""规则评估循环"""
while True:
try:
# 获取所有活跃规则
active_rules = await self.rules.get_active_rules()
# 并行评估规则
evaluation_tasks = []
for rule in active_rules:
task = asyncio.create_task(
self.evaluator.evaluate(rule)
)
evaluation_tasks.append(task)
# 收集评估结果
results = await asyncio.gather(*evaluation_tasks, return_exceptions=True)
# 处理告警触发
for rule, result in zip(active_rules, results):
if isinstance(result, Exception):
logger.error(f"Rule evaluation failed: {result}")
continue
if result['triggered']:
# 创建告警
alert = self.create_alert(rule, result)
# 去重检查
if await self.deduplicator.is_new_alert(alert):
# 静默检查
if not await self.silencer.is_silenced(alert):
# 发送告警
await self.notifier.send_alert(alert)
# 等待下一个评估周期
await asyncio.sleep(10) # 10秒评估一次
except Exception as e:
logger.error(f"Evaluation loop error: {e}")
await asyncio.sleep(30)
def create_alert(self, rule, evaluation_result):
"""创建告警对象"""
alert_id = self.generate_alert_id(rule, evaluation_result)
alert = {
'id': alert_id,
'rule_id': rule['id'],
'rule_name': rule['name'],
'severity': rule['severity'],
'summary': rule.get('summary', ''),
'description': rule.get('description', ''),
'labels': self.build_alert_labels(rule, evaluation_result),
'annotations': self.build_alert_annotations(rule, evaluation_result),
'starts_at': datetime.now().isoformat(),
'generator_url': f"/rules/{rule['id']}",
'fingerprint': self.calculate_fingerprint(rule, evaluation_result),
'status': 'firing',
'value': evaluation_result.get('value'),
'threshold': evaluation_result.get('threshold')
}
return alert
def generate_alert_id(self, rule, evaluation_result):
"""生成告警ID"""
timestamp = int(time.time())
rule_hash = hashlib.md5(rule['id'].encode()).hexdigest()[:8]
return f"alert_{timestamp}_{rule_hash}"
def build_alert_labels(self, rule, evaluation_result):
"""构建告警标签"""
labels = {
'alertname': rule['name'],
'severity': rule['severity'],
'rule_id': rule['id']
}
# 添加规则标签
if 'labels' in rule:
labels.update(rule['labels'])
# 添加评估结果标签
if 'labels' in evaluation_result:
labels.update(evaluation_result['labels'])
return labels
def calculate_fingerprint(self, rule, evaluation_result):
"""计算告警指纹(用于去重)"""
# 基于规则ID和标签计算指纹
fingerprint_parts = [
rule['id'],
json.dumps(self.build_alert_labels(rule, evaluation_result), sort_keys=True)
]
fingerprint_str = '|'.join(fingerprint_parts)
return hashlib.md5(fingerprint_str.encode()).hexdigest()
class RuleEvaluator:
"""规则评估器"""
def __init__(self):
self.query_engine = QueryEngine()
self.window_manager = WindowManager()
async def evaluate(self, rule):
"""评估告警规则"""
try:
# 1. 解析规则表达式
expression = rule['expression']
# 2. 执行查询
query_result = await self.query_engine.query(expression, rule.get('for', '5m'))
# 3. 应用窗口函数
windowed_result = await self.window_manager.apply_window(
query_result, rule.get('window', '5m')
)
# 4. 检查阈值
threshold = rule.get('threshold')
comparator = rule.get('comparator', '>')
triggered = self.check_threshold(windowed_result, threshold, comparator)
return {
'triggered': triggered,
'value': windowed_result.get('value'),
'threshold': threshold,
'labels': windowed_result.get('labels', {}),
'samples': windowed_result.get('samples', [])
}
except Exception as e:
logger.error(f"Rule evaluation error: {e}")
return {'triggered': False, 'error': str(e)}
def check_threshold(self, result, threshold, comparator):
"""检查阈值"""
if threshold is None:
# 无阈值,基于存在性触发
return bool(result.get('value'))
value = result.get('value')
if value is None:
return False
if comparator == '>':
return value > threshold
elif comparator == '>=':
return value >= threshold
elif comparator == '<':
return value < threshold
elif comparator == '<=':
return value <= threshold
elif comparator == '==':
return value == threshold
elif comparator == '!=':
return value != threshold
else:
return False
class WindowManager:
"""窗口管理器"""
async def apply_window(self, data, window):
"""应用时间窗口"""
if not data or not data.get('samples'):
return {'value': None, 'samples': []}
samples = data['samples']
# 解析窗口大小
window_seconds = self.parse_duration(window)
# 获取当前时间
now = time.time()
window_start = now - window_seconds
# 过滤窗口内的样本
window_samples = [
s for s in samples
if s['timestamp'] >= window_start * 1000 # 转为毫秒
]
if not window_samples:
return {'value': None, 'samples': []}
# 应用聚合函数
aggregation = data.get('aggregation', 'avg')
values = [s['value'] for s in window_samples]
if aggregation == 'avg':
value = sum(values) / len(values)
elif aggregation == 'sum':
value = sum(values)
elif aggregation == 'max':
value = max(values)
elif aggregation == 'min':
value = min(values)
elif aggregation == 'count':
value = len(values)
elif aggregation == 'last':
value = window_samples[-1]['value']
else:
value = values[0]
return {
'value': value,
'samples': window_samples,
'labels': data.get('labels', {})
}
def parse_duration(self, duration_str):
"""解析持续时间"""
# 解析如 "5m", "1h", "30s" 等格式
import re
pattern = r'^(\d+)([smhd])$'
match = re.match(pattern, duration_str)
if not match:
return 300 # 默认5分钟
value, unit = int(match.group(1)), match.group(2)
if unit == 's':
return value
elif unit == 'm':
return value * 60
elif unit == 'h':
return value * 3600
elif unit == 'd':
return value * 86400
else:
return 300
class AlertDeduplicator:
"""告警去重器"""
def __init__(self, dedupe_window=300): # 5分钟
self.dedupe_window = dedupe_window
self.recent_alerts = {} # fingerprint -> timestamp
async def is_new_alert(self, alert):
"""检查是否是新的告警"""
fingerprint = alert['fingerprint']
current_time = time.time()
# 清理过期记录
self.cleanup_expired(current_time)
# 检查是否在去重窗口内
if fingerprint in self.recent_alerts:
last_time = self.recent_alerts[fingerprint]
if current_time - last_time < self.dedupe_window:
# 重复告警
return False
# 记录新告警
self.recent_alerts[fingerprint] = current_time
return True
def cleanup_expired(self, current_time):
"""清理过期记录"""
expired = []
for fingerprint, timestamp in self.recent_alerts.items():
if current_time - timestamp > self.dedupe_window:
expired.append(fingerprint)
for fingerprint in expired:
del self.recent_alerts[fingerprint]
class AlertSilencer:
"""告警静默器"""
def __init__(self):
self.silences = {}
async def is_silenced(self, alert):
"""检查告警是否被静默"""
for silence_id, silence in self.silences.items():
if self.matches_silence(alert, silence):
return True
return False
def matches_silence(self, alert, silence):
"""检查告警是否匹配静默规则"""
# 检查时间范围
now = datetime.now()
if now < silence['starts_at'] or now > silence['ends_at']:
return False
# 检查标签匹配
for key, value in silence['matchers'].items():
if key not in alert['labels']:
return False
if alert['labels'][key] != value:
return False
return True
class AlertNotifier:
"""告警通知器"""
def __init__(self):
self.notification_channels = {
'email': EmailNotifier(),
'slack': SlackNotifier(),
'webhook': WebhookNotifier(),
'sms': SMSNotifier(),
'pagerduty': PagerDutyNotifier()
}
self.routing_rules = NotificationRouting()
async def send_alert(self, alert):
"""发送告警通知"""
# 1. 确定通知渠道
channels = await self.routing_rules.get_channels(alert)
# 2. 并行发送通知
send_tasks = []
for channel_name in channels:
if channel_name in self.notification_channels:
channel = self.notification_channels[channel_name]
task = asyncio.create_task(channel.send(alert))
send_tasks.append(task)
# 3. 记录发送结果
results = await asyncio.gather(*send_tasks, return_exceptions=True)
# 4. 更新告警状态
await self.update_alert_status(alert, results)
class NotificationRouting:
"""通知路由"""
def __init__(self):
self.routing_rules = []
async def get_channels(self, alert):
"""获取通知渠道"""
channels = set()
# 默认基于严重程度的路由
severity = alert['severity']
if severity == 'critical':
channels.update(['pagerduty', 'sms', 'slack'])
elif severity == 'warning':
channels.update(['slack', 'email'])
elif severity == 'info':
channels.update(['email'])
# 应用自定义路由规则
for rule in self.routing_rules:
if self.matches_rule(alert, rule):
channels.update(rule['channels'])
return list(channels)
def matches_rule(self, alert, rule):
"""检查告警是否匹配路由规则"""
for matcher in rule.get('matchers', []):
key = matcher['key']
value = matcher['value']
if key not in alert['labels']:
return False
if alert['labels'][key] != value:
return False
return True四、关键技术深度解析
4.1 时间序列数据压缩
图3:时间序列压缩算法对比
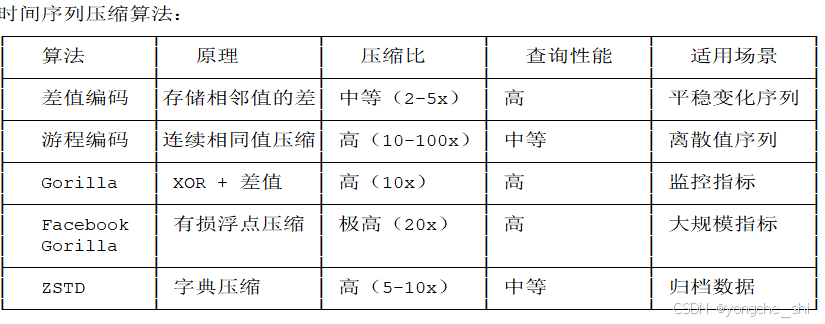
Gorilla压缩算法实现:
python
class GorillaCompressor:
"""Gorilla时间序列压缩算法"""
def __init__(self):
self.reset()
def reset(self):
"""重置压缩状态"""
self.prev_timestamp = 0
self.prev_value = 0
self.buffer = bytearray()
self.bit_offset = 0
def compress_timestamp(self, timestamp):
"""压缩时间戳"""
delta = timestamp - self.prev_timestamp
if self.prev_timestamp == 0:
# 第一个时间戳,存储原始值
self.write_bits(timestamp, 64)
else:
# 计算差值
delta_of_delta = delta - self.prev_delta
if delta_of_delta == 0:
# 存储'0'位
self.write_bit(0)
else:
# 存储'1'位
self.write_bit(1)
if -63 <= delta_of_delta <= 64:
# 存储2位长度 + 7位值
self.write_bit(0)
self.write_bits(delta_of_delta & 0x7F, 7)
elif -255 <= delta_of_delta <= 256:
# 存储2位长度 + 9位值
self.write_bit(1)
self.write_bit(0)
self.write_bits(delta_of_delta & 0x1FF, 9)
elif -2047 <= delta_of_delta <= 2048:
# 存储2位长度 + 12位值
self.write_bit(1)
self.write_bit(1)
self.write_bit(0)
self.write_bits(delta_of_delta & 0xFFF, 12)
else:
# 存储2位长度 + 32位值
self.write_bit(1)
self.write_bit(1)
self.write_bit(1)
self.write_bits(delta_of_delta & 0xFFFFFFFF, 32)
self.prev_delta = delta
self.prev_timestamp = timestamp
def compress_value(self, value):
"""压缩数值(双精度浮点)"""
import struct
# 将浮点数转为64位整数
value_bits = struct.unpack('!Q', struct.pack('!d', value))[0]
# 与前一个值进行XOR
xor = value_bits ^ self.prev_value_bits
if xor == 0:
# 存储'0'位
self.write_bit(0)
else:
# 存储'1'位
self.write_bit(1)
# 计算前导零和尾随零
leading_zeros = xor.bit_length() - 1
trailing_zeros = (xor & -xor).bit_length() - 1
# 有效位数
significant_bits = 64 - leading_zeros - trailing_zeros
if self.prev_leading_zeros != 0 and leading_zeros >= self.prev_leading_zeros and trailing_zeros >= self.prev_trailing_zeros:
# 存储'0'位 + 有效位
self.write_bit(0)
self.write_bits(xor >> self.prev_trailing_zeros, significant_bits)
else:
# 存储'1'位 + 前导零位数 + 有效位数 + 有效位
self.write_bit(1)
self.write_bits(leading_zeros, 6) # 0-63
self.write_bits(significant_bits - 1, 6) # 1-64
self.write_bits(xor >> trailing_zeros, significant_bits)
self.prev_leading_zeros = leading_zeros
self.prev_trailing_zeros = trailing_zeros
self.prev_value = value
self.prev_value_bits = value_bits
def write_bit(self, bit):
"""写入单个位"""
if self.bit_offset == 0:
self.buffer.append(0)
if bit:
self.buffer[-1] |= 1 << (7 - self.bit_offset)
self.bit_offset = (self.bit_offset + 1) % 8
def write_bits(self, value, num_bits):
"""写入多个位"""
for i in range(num_bits - 1, -1, -1):
bit = (value >> i) & 1
self.write_bit(bit)
def get_compressed_data(self):
"""获取压缩后的数据"""
return bytes(self.buffer)
class TimeSeriesBlock:
"""时间序列数据块(Gorilla格式)"""
def __init__(self, series_id, start_time, end_time):
self.series_id = series_id
self.start_time = start_time
self.end_time = end_time
self.compressor = GorillaCompressor()
self.points = []
self.compressed_data = None
def add_point(self, timestamp, value):
"""添加数据点"""
if not self.points:
# 第一个点,初始化压缩器
self.compressor.prev_timestamp = timestamp
self.compressor.prev_value = value
self.compressor.prev_value_bits = struct.unpack('!Q', struct.pack('!d', value))[0]
self.start_time = timestamp
self.points.append((timestamp, value))
self.end_time = timestamp
# 压缩数据
self.compressor.compress_timestamp(timestamp)
self.compressor.compress_value(value)
def finalize(self):
"""完成压缩"""
self.compressed_data = self.compressor.get_compressed_data()
# 计算压缩比
original_size = len(self.points) * 16 # 时间戳8字节 + 值8字节
compressed_size = len(self.compressed_data)
return {
'series_id': self.series_id,
'start_time': self.start_time,
'end_time': self.end_time,
'point_count': len(self.points),
'original_size': original_size,
'compressed_size': compressed_size,
'compression_ratio': original_size / compressed_size if compressed_size > 0 else 0,
'data': self.compressed_data
}4.2 智能告警与异常检测
图4:智能告警系统架构
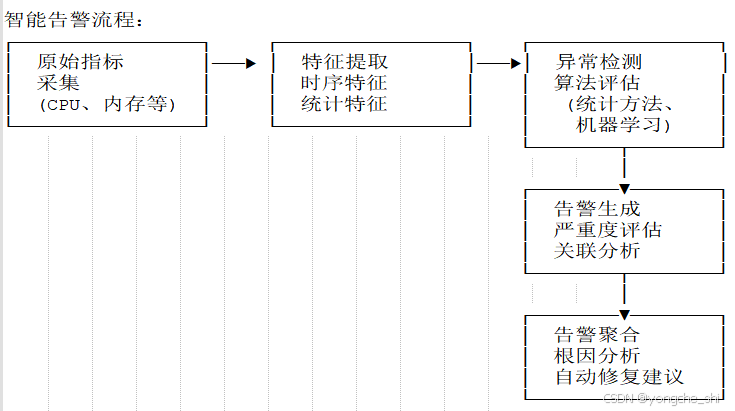
异常检测算法实现:
python
class AnomalyDetector:
"""异常检测器"""
def __init__(self):
self.detectors = {
'statistical': StatisticalDetector(),
'machine_learning': MLDetector(),
'deep_learning': DLDetector(),
'ensemble': EnsembleDetector()
}
self.feature_extractor = FeatureExtractor()
async def detect(self, time_series, method='auto'):
"""检测时间序列异常"""
# 1. 提取特征
features = await self.feature_extractor.extract(time_series)
# 2. 选择检测方法
if method == 'auto':
detector = self.select_best_detector(features)
else:
detector = self.detectors.get(method, self.detectors['statistical'])
# 3. 执行检测
anomalies = await detector.detect(features, time_series)
# 4. 后处理
processed_anomalies = self.post_process(anomalies, time_series)
return processed_anomalies
def select_best_detector(self, features):
"""选择最佳检测器"""
# 基于特征选择检测算法
if features.get('seasonality', False):
# 有季节性,使用统计方法
return self.detectors['statistical']
elif features.get('complexity', 0) > 0.8:
# 复杂模式,使用机器学习
return self.detectors['machine_learning']
else:
# 默认使用集成方法
return self.detectors['ensemble']
class StatisticalDetector:
"""统计异常检测"""
async def detect(self, features, time_series):
"""使用统计方法检测异常"""
anomalies = []
# 1. 计算统计指标
values = [point['value'] for point in time_series['points']]
timestamps = [point['timestamp'] for point in time_series['points']]
mean = np.mean(values)
std = np.std(values)
# 2. 3σ原则检测异常
threshold = 3 * std
for i, value in enumerate(values):
if abs(value - mean) > threshold:
anomalies.append({
'timestamp': timestamps[i],
'value': value,
'expected': mean,
'deviation': abs(value - mean),
'method': '3sigma',
'confidence': self.calculate_confidence(value, mean, std)
})
# 3. 滑动窗口检测
window_anomalies = await self.sliding_window_detection(values, timestamps)
anomalies.extend(window_anomalies)
return anomalies
async def sliding_window_detection(self, values, timestamps, window_size=10):
"""滑动窗口异常检测"""
anomalies = []
for i in range(len(values) - window_size + 1):
window = values[i:i + window_size]
window_mean = np.mean(window)
window_std = np.std(window)
# 检查窗口内每个点
for j in range(window_size):
value = window[j]
if window_std > 0 and abs(value - window_mean) > 3 * window_std:
anomalies.append({
'timestamp': timestamps[i + j],
'value': value,
'expected': window_mean,
'deviation': abs(value - window_mean),
'method': 'sliding_window',
'confidence': self.calculate_confidence(value, window_mean, window_std)
})
return anomalies
def calculate_confidence(self, value, mean, std):
"""计算异常置信度"""
if std == 0:
return 1.0 if value != mean else 0.0
deviation = abs(value - mean)
z_score = deviation / std
# 使用正态分布计算置信度
import scipy.stats as stats
confidence = 2 * (1 - stats.norm.cdf(z_score))
return min(confidence, 1.0)
class MLDetector:
"""机器学习异常检测"""
def __init__(self):
self.model = self.load_model()
self.scaler = StandardScaler()
async def detect(self, features, time_series):
"""使用机器学习检测异常"""
# 1. 准备数据
X = self.prepare_features(time_series)
# 2. 标准化
X_scaled = self.scaler.fit_transform(X)
# 3. 预测
predictions = self.model.predict(X_scaled)
anomaly_scores = self.model.decision_function(X_scaled)
# 4. 提取异常点
anomalies = []
for i, (pred, score) in enumerate(zip(predictions, anomaly_scores)):
if pred == -1: # -1表示异常
anomalies.append({
'timestamp': time_series['points'][i]['timestamp'],
'value': time_series['points'][i]['value'],
'score': score,
'method': 'isolation_forest',
'confidence': self.score_to_confidence(score)
})
return anomalies
def prepare_features(self, time_series):
"""准备特征矩阵"""
points = time_series['points']
features = []
for i in range(len(points)):
# 基础特征
feature_vector = [
points[i]['value'], # 当前值
]
# 统计特征
if i > 0:
feature_vector.append(points[i]['value'] - points[i-1]['value']) # 差值
else:
feature_vector.append(0)
# 滑动窗口特征
if i >= 4:
window = points[i-4:i+1]
window_values = [p['value'] for p in window]
feature_vector.extend([
np.mean(window_values), # 均值
np.std(window_values), # 标准差
np.max(window_values), # 最大值
np.min(window_values) # 最小值
])
else:
feature_vector.extend([0, 0, 0, 0])
features.append(feature_vector)
return np.array(features)
def score_to_confidence(self, score):
"""将异常分数转换为置信度"""
# 假设分数范围在[-1, 1],负数表示异常
confidence = (1 - score) / 2 # 映射到[0, 1]
return max(0, min(1, confidence))
class FeatureExtractor:
"""特征提取器"""
async def extract(self, time_series):
"""提取时间序列特征"""
points = time_series['points']
values = [p['value'] for p in points]
timestamps = [p['timestamp'] for p in points]
features = {}
# 1. 统计特征
features['mean'] = np.mean(values)
features['std'] = np.std(values)
features['min'] = np.min(values)
features['max'] = np.max(values)
features['range'] = features['max'] - features['min']
# 2. 时序特征
if len(values) > 1:
diffs = np.diff(values)
features['avg_diff'] = np.mean(diffs)
features['diff_std'] = np.std(diffs)
# 自相关性
if len(values) > 10:
autocorr = self.calculate_autocorrelation(values, lag=1)
features['autocorrelation'] = autocorr
# 3. 周期性检测
features['seasonality'] = self.detect_seasonality(values)
# 4. 趋势检测
features['trend'] = self.detect_trend(values)
# 5. 复杂性度量
features['complexity'] = self.calculate_complexity(values)
return features
def calculate_autocorrelation(self, values, lag=1):
"""计算自相关性"""
if len(values) <= lag:
return 0
mean = np.mean(values)
numerator = sum((values[i] - mean) * (values[i+lag] - mean)
for i in range(len(values)-lag))
denominator = sum((v - mean) ** 2 for v in values)
return numerator / denominator if denominator != 0 else 0
def detect_seasonality(self, values, max_lag=100):
"""检测季节性"""
if len(values) < max_lag * 2:
return False
# 计算不同滞后的自相关性
autocorrs = []
for lag in range(1, min(max_lag, len(values)//2)):
autocorr = self.calculate_autocorrelation(values, lag)
autocorrs.append(autocorr)
# 检查是否有明显的周期性峰值
if len(autocorrs) < 3:
return False
# 寻找局部最大值
peaks = []
for i in range(1, len(autocorrs)-1):
if autocorrs[i] > autocorrs[i-1] and autocorrs[i] > autocorrs[i+1]:
peaks.append((i, autocorrs[i]))
# 检查峰值是否显著
if peaks:
strongest_peak = max(peaks, key=lambda x: x[1])
return strongest_peak[1] > 0.5 # 阈值
return False
def detect_trend(self, values):
"""检测趋势"""
if len(values) < 2:
return 0
# 线性回归斜率
x = np.arange(len(values))
slope, _ = np.polyfit(x, values, 1)
return slope
def calculate_complexity(self, values):
"""计算复杂度(近似熵)"""
if len(values) < 3:
return 0
# 简化复杂度计算
diffs = np.diff(values)
sign_changes = sum(1 for i in range(1, len(diffs)) if diffs[i] * diffs[i-1] < 0)
return sign_changes / len(values)4.3 根因分析系统
4.3.1 拓扑感知的根因分析
python
class RootCauseAnalyzer:
"""根因分析器"""
def __init__(self):
self.topology = ServiceTopology()
self.metrics_correlator = MetricsCorrelator()
self.change_detector = ChangeDetector()
async def analyze(self, alert, metrics_data):
"""分析告警根因"""
analysis_results = []
# 1. 拓扑分析
topology_analysis = await self.topology_analysis(alert, metrics_data)
analysis_results.extend(topology_analysis)
# 2. 指标相关性分析
correlation_analysis = await self.correlation_analysis(alert, metrics_data)
analysis_results.extend(correlation_analysis)
# 3. 变更分析
change_analysis = await self.change_analysis(alert)
analysis_results.extend(change_analysis)
# 4. 综合评分和排序
ranked_causes = self.rank_causes(analysis_results)
return ranked_causes
async def topology_analysis(self, alert, metrics_data):
"""拓扑分析"""
causes = []
# 获取受影响的服务
affected_service = alert['labels'].get('service')
if affected_service:
# 获取服务依赖关系
dependencies = await self.topology.get_dependencies(affected_service)
# 检查依赖服务的健康状况
for dep_service in dependencies:
dep_health = await self.check_service_health(dep_service)
if not dep_health['healthy']:
causes.append({
'type': 'dependency_failure',
'service': dep_service,
'health_status': dep_health['status'],
'confidence': dep_health['confidence'],
'evidence': dep_health['metrics']
})
# 检查服务实例分布
instances = await self.topology.get_service_instances(affected_service)
unhealthy_instances = [inst for inst in instances if not inst['healthy']]
if unhealthy_instances:
causes.append({
'type': 'instance_failure',
'service': affected_service,
'unhealthy_count': len(unhealthy_instances),
'total_count': len(instances),
'unhealthy_ratio': len(unhealthy_instances) / len(instances),
'confidence': min(1.0, len(unhealthy_instances) / len(instances) * 2),
'evidence': unhealthy_instances
})
return causes
async def correlation_analysis(self, alert, metrics_data):
"""指标相关性分析"""
causes = []
# 获取告警相关指标
alert_metric = alert['labels'].get('metric')
alert_value = alert.get('value')
if alert_metric and metrics_data:
# 查找相关指标
related_metrics = await self.metrics_correlator.find_related_metrics(
alert_metric, metrics_data
)
for related_metric, correlation in related_metrics:
if abs(correlation) > 0.7: # 强相关性
# 检查相关指标是否也异常
metric_anomalies = await self.check_metric_anomalies(related_metric)
if metric_anomalies:
causes.append({
'type': 'correlated_metric',
'metric': related_metric,
'correlation': correlation,
'anomalies': metric_anomalies,
'confidence': abs(correlation) * 0.8
})
return causes
async def change_analysis(self, alert):
"""变更分析"""
causes = []
# 获取近期变更
recent_changes = await self.change_detector.get_recent_changes(
alert['labels'].get('service'),
alert['starts_at']
)
for change in recent_changes:
# 计算变更时间与告警时间的接近程度
time_diff = abs((datetime.fromisoformat(alert['starts_at']) -
change['time']).total_seconds())
if time_diff < 3600: # 1小时内
causes.append({
'type': 'recent_change',
'change_type': change['type'],
'change_id': change['id'],
'time_diff_seconds': time_diff,
'description': change['description'],
'confidence': max(0.7, 1.0 - time_diff / 3600)
})
return causes
def rank_causes(self, causes):
"""对根因进行排序"""
if not causes:
return []
# 计算综合评分
for cause in causes:
# 基础置信度
score = cause.get('confidence', 0.5)
# 类型权重
type_weights = {
'dependency_failure': 1.2,
'instance_failure': 1.1,
'correlated_metric': 1.0,
'recent_change': 0.9
}
score *= type_weights.get(cause['type'], 1.0)
# 证据强度
if 'evidence' in cause and cause['evidence']:
score *= 1.1
cause['score'] = score
# 按评分排序
return sorted(causes, key=lambda x: x['score'], reverse=True)五、实战:典型场景与面试问题
5.1 场景一:处理海量指标存储与查询
问题:如何设计一个支持每秒千万级指标写入和秒级查询的系统?
解决方案:
python
class HighScaleTimeSeriesDB:
"""高规模时间序列数据库设计"""
def design_architecture(self):
return {
"DATA_MODEL": {
"metric": "指标名称",
"labels": "标签键值对",
"timestamp": "时间戳(毫秒)",
"value": "数值(浮点)"
},
"STORAGE_LAYERS": {
"memory": "最近数据(内存,毫秒级访问)",
"ssd": "近期数据(SSD,秒级访问)",
"hdd": "历史数据(HDD,分钟级访问)",
"archive": "归档数据(对象存储,小时级访问)"
},
"PARTITIONING": {
"time": "按时间分片(每小时/每天)",
"metric": "按指标哈希分片",
"tenant": "按租户分片"
},
"INDEXING": {
"inverted_index": "标签倒排索引",
"bloom_filter": "布隆过滤器快速过滤",
"time_index": "时间范围索引"
},
"COMPRESSION": {
"gorilla": "时序专用压缩(10x)",
"zstd": "通用压缩(3-5x)",
"delta_encoding": "差值编码"
}
}
class QueryOptimizer:
"""查询优化器"""
async def optimize_query(self, query):
"""优化查询计划"""
optimization_steps = []
# 1. 重写查询
rewritten = self.rewrite_query(query)
optimization_steps.append(("rewrite", rewritten))
# 2. 选择最佳索引
index_plan = self.choose_index(rewritten)
optimization_steps.append(("index", index_plan))
# 3. 数据分布分析
distribution = await self.analyze_distribution(rewritten)
optimization_steps.append(("distribution", distribution))
# 4. 并行化策略
parallel_plan = self.parallelization_plan(rewritten, distribution)
optimization_steps.append(("parallel", parallel_plan))
# 5. 缓存策略
cache_plan = self.cache_plan(rewritten)
optimization_steps.append(("cache", cache_plan))
return {
"optimized_query": rewritten,
"execution_plan": parallel_plan,
"optimization_steps": optimization_steps
}
def rewrite_query(self, query):
"""重写查询以提高效率"""
# 下推过滤条件
if 'filters' in query:
# 将过滤条件下推到存储层
pass
# 合并相似查询
if 'similar_queries' in query:
# 合并多个相似查询
pass
# 优化聚合顺序
if 'aggregations' in query:
# 重新排序聚合操作
pass
return query
def parallelization_plan(self, query, distribution):
"""并行化执行计划"""
plan = {
"parallel_workers": 0,
"shard_assignments": [],
"merge_strategy": "sorted_merge"
}
# 根据数据分布决定并行度
shard_count = len(distribution.get('shards', []))
plan["parallel_workers"] = min(shard_count, 16) # 最大16个并行
# 分配分片给工作线程
for i in range(plan["parallel_workers"]):
assigned_shards = []
for j in range(i, shard_count, plan["parallel_workers"]):
assigned_shards.append(j)
plan["shard_assignments"].append(assigned_shards)
return plan
class TieredStorageManager:
"""分层存储管理器"""
def __init__(self):
self.tiers = {
'hot': { # 热数据:内存
'max_age': 3600, # 1小时
'max_size': '100GB',
'storage': InMemoryStore()
},
'warm': { # 温数据:SSD
'max_age': 86400 * 7, # 7天
'max_size': '1TB',
'storage': SSDStore()
},
'cold': { # 冷数据:HDD
'max_age': 86400 * 30, # 30天
'max_size': '10TB',
'storage': HDDStore()
},
'archive': { # 归档数据:对象存储
'max_age': 86400 * 365, # 1年
'max_size': '100TB',
'storage': ObjectStorage()
}
}
async def write(self, data_point):
"""写入数据点"""
# 同时写入所有层级(写放大优化)
write_tasks = []
for tier_name, tier_config in self.tiers.items():
if tier_name == 'hot':
# 热层立即写入
task = asyncio.create_task(
tier_config['storage'].write(data_point)
)
write_tasks.append(task)
else:
# 其他层级异步写入
asyncio.create_task(
self.async_write_to_tier(tier_name, data_point)
)
await asyncio.gather(*write_tasks)
async def query(self, query):
"""查询数据"""
# 确定需要查询的层级
time_range = query.get('time_range', {})
start_time = time_range.get('start')
end_time = time_range.get('end')
# 计算查询范围覆盖的层级
tiers_to_query = []
current_time = time.time()
for tier_name, tier_config in self.tiers.items():
tier_max_age = tier_config['max_age']
tier_min_time = current_time - tier_max_age
# 检查查询范围是否与该层级有时间重叠
if end_time > tier_min_time and start_time < current_time:
tiers_to_query.append(tier_name)
# 并行查询所有相关层级
query_tasks = []
for tier_name in tiers_to_query:
tier_config = self.tiers[tier_name]
task = asyncio.create_task(
tier_config['storage'].query(query)
)
query_tasks.append(task)
# 收集和合并结果
results = await asyncio.gather(*query_tasks)
merged_results = self.merge_results(results)
return merged_results
def merge_results(self, results):
"""合并来自不同层级的结果"""
# 按时间戳排序
all_points = []
for result in results:
all_points.extend(result.get('points', []))
all_points.sort(key=lambda x: x['timestamp'])
# 去重(同一时间戳可能存在于多个层级)
deduplicated = []
last_timestamp = None
for point in all_points:
if point['timestamp'] != last_timestamp:
deduplicated.append(point)
last_timestamp = point['timestamp']
return {'points': deduplicated}5.2 场景二:避免告警疲劳与智能降噪
问题:如何减少误报和重复告警,避免工程师的告警疲劳?
解决方案:
python
class AlertNoiseReduction:
"""告警降噪系统"""
def __init__(self):
self.deduplicator = AlertDeduplicator()
self.correlator = AlertCorrelator()
self.escalation = EscalationManager()
self.learning = LearningEngine()
async def process_alert(self, alert):
"""处理告警(降噪)"""
processed_alerts = []
# 1. 去重检查
if await self.deduplicator.is_duplicate(alert):
# 更新现有告警,不创建新告警
await self.deduplicator.update_existing(alert)
return []
# 2. 相关性检查
correlated = await self.correlator.find_correlated(alert)
if correlated:
# 存在相关告警,创建聚合告警
aggregated = await self.create_aggregated_alert(alert, correlated)
processed_alerts.append(aggregated)
# 抑制原始告警(可选)
if self.should_suppress_original(alert, correlated):
return processed_alerts
else:
# 独立告警
processed_alerts.append(alert)
# 3. 智能过滤
filtered = await self.intelligent_filtering(processed_alerts)
# 4. 学习模式更新
await self.learning.update_from_alert(alert)
return filtered
async def create_aggregated_alert(self, new_alert, correlated_alerts):
"""创建聚合告警"""
# 基于相关性创建聚合告警
aggregation_key = self.get_aggregation_key(new_alert, correlated_alerts)
aggregated_alert = {
'id': f"aggregated_{hash(aggregation_key)}",
'type': 'aggregated',
'severity': self.calculate_aggregated_severity(new_alert, correlated_alerts),
'summary': f"Aggregated alert: {len(correlated_alerts) + 1} related issues",
'description': self.build_aggregated_description(new_alert, correlated_alerts),
'alerts': correlated_alerts + [new_alert],
'count': len(correlated_alerts) + 1,
'first_seen': min(a['timestamp'] for a in correlated_alerts + [new_alert]),
'last_seen': max(a['timestamp'] for a in correlated_alerts + [new_alert]),
'fingerprint': aggregation_key
}
return aggregated_alert
def get_aggregation_key(self, alert, correlated_alerts):
"""获取聚合键"""
# 基于服务、组件、错误类型等聚合
aggregation_parts = []
# 服务名
service = alert['labels'].get('service')
if service:
aggregation_parts.append(f"service:{service}")
# 错误类型
error_type = alert['labels'].get('error_type')
if error_type:
aggregation_parts.append(f"error:{error_type}")
# 组件
component = alert['labels'].get('component')
if component:
aggregation_parts.append(f"component:{component}")
return '|'.join(aggregation_parts)
async def intelligent_filtering(self, alerts):
"""智能过滤"""
filtered = []
for alert in alerts:
# 1. 检查是否在维护窗口
if await self.is_in_maintenance(alert):
logger.info(f"Alert {alert['id']} suppressed due to maintenance")
continue
# 2. 检查历史模式
if await self.is_expected_pattern(alert):
logger.info(f"Alert {alert['id']} suppressed as expected pattern")
continue
# 3. 检查业务影响
if not await self.has_business_impact(alert):
logger.info(f"Alert {alert['id']} suppressed due to low business impact")
continue
# 4. 检查时间模式(如夜间低流量)
if await self.is_low_impact_period(alert):
# 降低严重程度而不是完全抑制
alert['severity'] = self.downgrade_severity(alert['severity'])
filtered.append(alert)
return filtered
class LearningEngine:
"""学习引擎(基于历史告警学习)"""
def __init__(self):
self.patterns = {}
self.feedback_history = []
async def update_from_alert(self, alert):
"""从告警中学习"""
alert_key = self.get_alert_key(alert)
# 记录告警
if alert_key not in self.patterns:
self.patterns[alert_key] = {
'count': 0,
'first_seen': time.time(),
'last_seen': time.time(),
'suppressed_count': 0,
'action_taken': []
}
pattern = self.patterns[alert_key]
pattern['count'] += 1
pattern['last_seen'] = time.time()
# 分析告警模式
await self.analyze_pattern(pattern, alert)
# 自动调整阈值
if pattern['count'] > 100:
await self.adjust_thresholds(pattern)
async def analyze_pattern(self, pattern, alert):
"""分析告警模式"""
# 时间模式分析
hour = datetime.now().hour
pattern.setdefault('hourly_distribution', [0]*24)
pattern['hourly_distribution'][hour] += 1
# 频率分析
if pattern['count'] > 10:
interval = time.time() - pattern['first_seen']
frequency = pattern['count'] / (interval / 3600) # 每小时频率
pattern['frequency'] = frequency
# 如果频率过高,可能是误报或需要调整阈值
if frequency > 10: # 每小时超过10次
await self.flag_for_review(pattern, alert)
async def adjust_thresholds(self, pattern):
"""自动调整阈值"""
# 基于历史数据动态调整告警阈值
if pattern.get('frequency', 0) > 20:
# 频率过高,提高阈值
await self.increase_threshold(pattern, factor=1.2)
elif pattern.get('suppressed_ratio', 0) > 0.8:
# 大部分告警被抑制,提高阈值
await self.increase_threshold(pattern, factor=1.1)5.3 面试问题深度解析
Q1:监控系统如何保证数据的一致性和完整性?
回答要点:
-
数据验证:写入前验证数据格式和范围
-
事务性写入:使用WAL(Write-Ahead Logging)保证原子性
-
数据复制:多副本机制,使用Raft/Paxos保证一致性
-
校验和:每个数据块都有校验和,定期验证
-
数据修复:自动检测和修复损坏的数据
示例架构:
python
class DataIntegrityManager:
async def ensure_integrity(self, data_point):
# 1. 验证数据格式
if not self.validate_format(data_point):
raise ValidationError("Invalid data format")
# 2. 写入WAL
wal_entry = await self.write_ahead_log.append(data_point)
# 3. 写入存储(多副本)
replica_results = await self.write_with_replication(data_point)
# 4. 验证写入成功
if self.check_write_success(replica_results):
# 提交WAL
await self.write_ahead_log.commit(wal_entry)
return True
else:
# 回滚
await self.write_ahead_log.rollback(wal_entry)
return FalseQ2:如何设计一个支持多租户的监控系统?
python
class MultiTenantMonitoring:
"""多租户监控系统设计"""
def design_principles(self):
return {
"ISOLATION": {
"data": "每个租户数据物理/逻辑隔离",
"performance": "租户间性能隔离",
"config": "独立配置管理"
},
"RESOURCE_MANAGEMENT": {
"quotas": "指标数量、存储空间、查询频率限制",
"billing": "基于使用量的计费",
"tiers": "不同服务级别(免费、基础、企业)"
},
"SECURITY": {
"authentication": "租户独立认证",
"authorization": "细粒度权限控制",
"encryption": "租户数据加密"
},
"OPERATIONS": {
"onboarding": "自动化租户接入",
"monitoring": "租户级别监控",
"support": "租户支持工具"
}
}
class TenantAwareStorage:
"""租户感知的存储"""
def __init__(self):
self.storage_strategies = {
'shared': SharedStorage(), # 共享存储,逻辑隔离
'dedicated': DedicatedStorage(), # 专用存储,物理隔离
'hybrid': HybridStorage() # 混合模式
}
async def write(self, tenant_id, data_point):
"""租户感知的写入"""
# 1. 检查租户配额
if not await self.check_quota(tenant_id, data_point):
raise QuotaExceededError(f"Tenant {tenant_id} quota exceeded")
# 2. 选择存储策略
strategy = self.get_storage_strategy(tenant_id)
# 3. 添加租户标签
data_point['labels']['tenant'] = tenant_id
# 4. 写入租户特定存储
await strategy.write(tenant_id, data_point)
# 5. 更新使用量
await self.update_usage(tenant_id, data_point)
def get_storage_strategy(self, tenant_id):
"""获取存储策略"""
tenant_tier = self.get_tenant_tier(tenant_id)
if tenant_tier == 'enterprise':
return self.storage_strategies['dedicated']
elif tenant_tier == 'business':
return self.storage_strategies['hybrid']
else:
return self.storage_strategies['shared']六、总结与面试准备
6.1 核心架构要点回顾
-
数据采集:多种采集模式(Pull/Push/Agent/SDK),支持自动发现
-
数据存储:分层存储架构,高效压缩算法,时间序列优化
-
数据查询:分布式查询引擎,智能查询优化,多级缓存
-
告警引擎:规则评估,智能降噪,告警聚合,多渠道通知
-
智能分析:异常检测,根因分析,预测性告警
6.2 系统演进路线图
text
阶段1:基础监控
├── 基本指标采集
├── 简单阈值告警
├── 基础仪表板
└── 日志收集
阶段2:集中监控
├── 统一数据平台
├── 复杂告警规则
├── 分布式存储
└── API集成
阶段3:智能监控
├── 机器学习异常检测
├── 自动根因分析
├── 预测性告警
└── 自愈能力
阶段4:全景监控
├── 业务监控集成
├── 用户体验监控
├── 安全监控
└── 成本监控6.3 面试checklist
-
能否清晰阐述监控告警系统的整体架构?
-
能否设计支持海量指标采集和存储的系统?
-
能否实现高效的时间序列查询和聚合?
-
能否设计智能告警和降噪系统?
-
能否实现异常检测和根因分析?
-
能否保证系统的高可用和数据一致性?
-
能否设计支持多租户的监控系统?
6.4 常见面试问题集锦
-
基础问题:
-
监控系统的主要组件有哪些?
-
如何设计时间序列数据库?
-
告警规则如何评估和执行?
-
-
进阶问题:
-
如何实现监控系统的水平扩展?
-
如何避免告警疲劳和误报?
-
如何设计智能异常检测系统?
-
-
深度问题:
-
监控系统如何支持根因分析?
-
如何设计支持预测性告警的系统?
-
监控系统如何与CI/CD流水线集成?
-
6.5 扩展思考题
-
监控系统如何与AIOps结合?
-
如何设计跨云平台的统一监控?
-
监控系统如何支持SLA/SLO管理?
-
如何实现监控数据的合规性和隐私保护?
-
监控系统如何支持边缘计算场景?
附录:生产环境部署配置
yaml
# 监控系统Kubernetes部署配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: monitoring-system
namespace: monitoring
spec:
replicas: 3
selector:
matchLabels:
app: monitoring
component: coordinator
template:
metadata:
labels:
app: monitoring
component: coordinator
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9090"
spec:
serviceAccountName: monitoring
containers:
- name: coordinator
image: monitoring-coordinator:2.1.0
env:
- name: ENVIRONMENT
value: "production"
- name: STORAGE_BACKEND
value: "cassandra"
- name: CASSANDRA_HOSTS
value: "cassandra-0.cassandra,cassandra-1.cassandra,cassandra-2.cassandra"
- name: KAFKA_BROKERS
value: "kafka-0:9092,kafka-1:9092,kafka-2:9092"
ports:
- containerPort: 9090
name: http
- containerPort: 9093
name: alertmanager
resources:
limits:
cpu: "2"
memory: "4Gi"
requests:
cpu: "500m"
memory: "2Gi"
readinessProbe:
httpGet:
path: /ready
port: 9090
initialDelaySeconds: 30
periodSeconds: 10
livenessProbe:
httpGet:
path: /health
port: 9090
initialDelaySeconds: 30
periodSeconds: 30
volumeMounts:
- name: config-volume
mountPath: /etc/monitoring
volumes:
- name: config-volume
configMap:
name: monitoring-config
---
# 数据采集器DaemonSet
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitoring
labels:
app: node-exporter
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9100"
spec:
containers:
- name: node-exporter
image: prom/node-exporter:v1.3.1
ports:
- containerPort: 9100
name: http
resources:
limits:
cpu: "200m"
memory: "100Mi"
requests:
cpu: "100m"
memory: "50Mi"
securityContext:
runAsNonRoot: true
runAsUser: 65534
args:
- "--path.rootfs=/host"
- "--path.procfs=/host/proc"
- "--path.sysfs=/host/sys"
volumeMounts:
- name: proc
mountPath: /host/proc
readOnly: true
- name: sys
mountPath: /host/sys
readOnly: true
- name: root
mountPath: /host/root
readOnly: true
volumes:
- name: proc
hostPath:
path: /proc
- name: sys
hostPath:
path: /sys
- name: root
hostPath:
path: /
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
---
# 时序数据库StatefulSet
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: tsdb-cluster
namespace: monitoring
spec:
serviceName: tsdb
replicas: 3
selector:
matchLabels:
app: tsdb
template:
metadata:
labels:
app: tsdb
spec:
serviceAccountName: monitoring
containers:
- name: tsdb
image: victoriametrics/victoria-metrics:v1.82.0
args:
- "--storageDataPath=/data"
- "--retentionPeriod=12"
- "--search.maxQueryDuration=30s"
- "--search.maxUniqueTimeseries=1000000"
ports:
- containerPort: 8428
name: http
resources:
limits:
cpu: "4"
memory: "8Gi"
requests:
cpu: "2"
memory: "4Gi"
volumeMounts:
- name: data
mountPath: /data
livenessProbe:
httpGet:
path: /health
port: 8428
initialDelaySeconds: 60
periodSeconds: 30
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: fast-ssd
resources:
requests:
storage: 500Gi
---
# 水平自动扩缩容
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: tsdb-hpa
namespace: monitoring
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: StatefulSet
name: tsdb-cluster
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 10
periodSeconds: 60
scaleUp:
stabilizationWindowSeconds: 60
policies:
- type: Percent
value: 100
periodSeconds: 10特别提示:
在实际面试中,除了技术方案,还需要关注:
-
业务价值:监控如何支持业务目标和SLA
-
运维复杂度:系统部署、配置、升级的复杂度
-
成本控制:存储成本、计算成本、网络成本优化
-
用户体验:告警的准确性和及时性,仪表板的易用性
记住:监控告警系统设计需要在数据完整性、查询性能、告警准确性和系统成本之间找到平衡。不同的业务场景(基础设施监控、应用性能监控、业务监控)需要不同的设计侧重点。