scrapy 爬虫框架
Scrapy 是一个用于抓取网站和提取结构化数据的应用程序框架,有着广泛的应用如数据挖掘,信息处理或历史存档等。尽管 Scrapy 最初是为网页抓取而设计的,但它也可以使用接口 API(如 Amazon Associates web Services)提取数据,或者作为通用的网络爬虫。
环境依赖
Scrapy 爬虫框架需要 Python3.9 及其以上版本,要么是 CPython实现,要么是 PyPy 实现。同时,它还依赖以下组件:
lxml:一个优秀的XML和HTML解析器;parsel: 在lxml之上的HTML/XML格式内容提取库;w3lib: 用于处理URL和网页编码的工具库;twisted:一个异步的网络处理框架;cryptography和pyOpenSSL:处理网络安全所需的库。
安装库
conda安装:
conda install -c conda-forege scrapyuv 安装:
uv add scrapy如果要 Scrapy 正常工作,别忘了安装它的依赖库。
框架结构
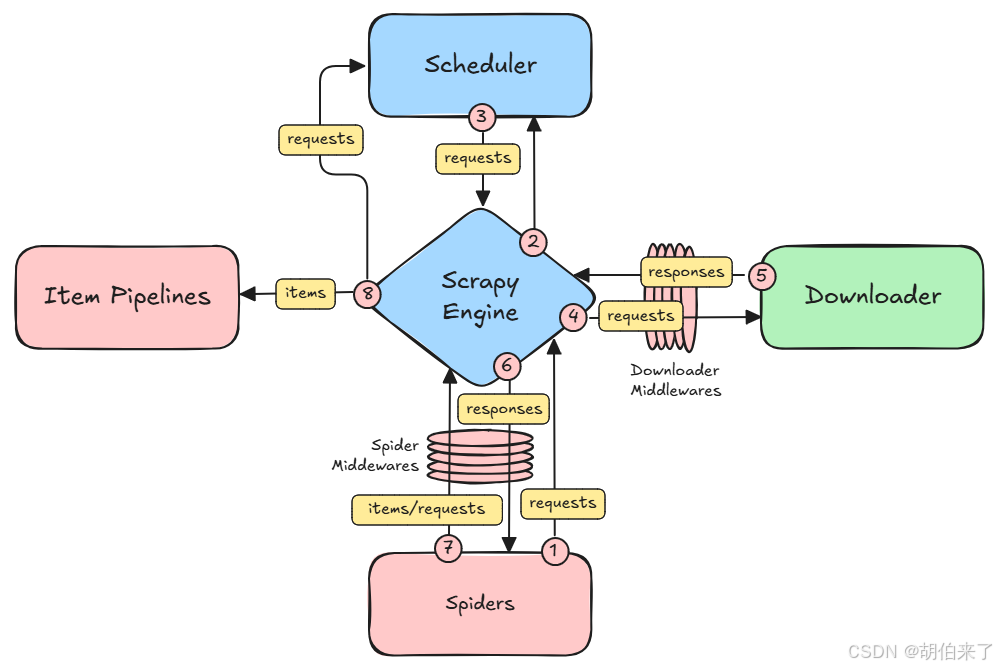
如上图,Scrapy 框架包含以下组件:
- 【引擎】(
Scrapy Engine):负责控制系统所有组件之间的数据流,并在某些操作发生时触发事件。 - 【提取项】(
Items):从非结构化资源中提取出来的结构化数据,提取项可以是一个数据字典,可以是Scrapy.Item的类或子类,可以是Scrapy.datalass类或子类,也可以是scrapy.attrs类或子类。 - 【调度器】(
Scheduler):接收来自【引擎】的请求,并对它们进行排队,以便在【引擎】请求它们时稍后将它们馈送(也馈送给【引擎】)。 - 【下载器】(
Downloader):负责抓取网页并将其提供给【引擎】,而【引擎】又将其提供给【爬虫】 。 - 【爬虫】(
Spiders):是由Scrapy用户编写的自定义类,用于解析响应并从中提取【提取项】或其他要关注的请求。 - 【提取项管道】(
Item Pipeline):处理项管道。负责在【爬虫】提取(或抓取)【提取项】后对其进行处理。典型的任务包括清理、验证和持久化(比如将【提取项】存储在数据库中)。 - 【下载器中间件】(
Downloader MiddleWare):下载器中间件。位于【引擎】和【下载器】之间的特定钩子,处理从【引擎】传递到【下载器】的请求,以及从【下载器】传递到【引擎】的响应。 - 【爬虫中间件】(
Spider MiddeleWare):位于【引擎】和【爬虫】之间的特定钩子,能够处理【爬虫】的输入(响应)和输出(处理项和请求)。
Scrapy 中的数据流由执行引擎控制:
- 【引擎】从【爬虫】那里获得抓取的初始请求。
- 【引擎】通过【调度器】调度请求,并请求抓取下一个请求。
- 【调度器】将下一个请求返回给【引擎】 。
- 【引擎】将请求通过【下载器中间件】(参见
process_request)发送给【下载器】。 - 一旦页面完成下载,【下载器】生成一个响应(与该页一起)并将其通过【下载器中间件】(参见
process_response)发送到【引擎】。 - 【引擎】接收来自【下载器】的响应,并将其通过【爬虫中间件】(参见
process_spider_input)发送给【爬虫】进行处理。 - 【爬虫】处理响应,并通过【爬虫中间件】(参见
process_spider_output)向【引擎】返回抓取的【提取项】和新的请求。 - 【引擎】将处理过的【提取项】发送到【提取项管道】,然后将处理过的请求发送到【调度器】,并请求可能的下一个请求进行抓取。
- 该过程重复(从步骤3开始),直到不再有来自【调度器】的请求。
【爬虫】和【提取项】是需要用户根据响应的需求进行编写的。除此之外,还有【下载器中间件】和【爬虫中间件】,这两个中间件为用户提供方便,通过插入自定义代码扩展 Scrapy 的功能,例如去重等。
引擎 - Scrapy Engine
【引擎】负责控制系统所有组件之间的数据流,并在某些操作发生时触发事件。
调度器 - Scheduler
【调度器】组件接收来自【引擎】的请求,并将它们存储到持久和(或)非持久数据结构中。它还获取这些请求,并在请求下载下一个请求时将它们反馈给【引擎】。
上述请求的原始来源是:
- 【爬虫】:
start()方法,为start_urls属性中的url创建请求和回调 - 【爬虫中间件】:
process_spider_output和process_spider_exception方法 - 【下载中间件】:
process_request、process_response和process_exception方法
【调度器】返回其存储请求的顺序(通过 next_request 方法)在确定下载这些请求的顺序方面起着重要作用。
Scrapy 框架中提供了 scrapy.core.scheduler.BaseScheduler 和 scrapy.core.scheduler.Scheduler 两个调度类。您可以通过在 SCHEDULER 设置中提供其完整的Python路径来使用自己的自定义调度程序类。
最小化的调度器
| 属性/方法 | 说明 |
|---|---|
| `close(reason: str)→ DeferredNone | None ` |
abstract enqueue_request(request: Request)→ bool |
处理【引擎】接收到的请求。 如果请求被正确存储则返回 True,否则返回 False。 如果为 False,【引擎】将触发 request_dropped 信号,并且往后不会进一步尝试调度请求。 |
from_crawler(crawler: Crawler)→ Self |
为调度器设置 Crawler 。 |
abstract has_pending_requests()→ bool |
如果调度程序有排队请求,则为True,否则为False |
| `abstract next_request()→ Request | None ` |
| `open(spider: Spider)→ DeferredNone | None ` |
默认的调度器
请求存储在优先级队列(SCHEDULER_PRIORITY_QUEUE)中,该队列按priority对请求进行排序。
默认情况下,对所有请求使用一个基于内存的优先级队列。在使用 JOBDIR 时,还会创建一个基于磁盘的优先级队列,并且仅将不可序列化的请求存储在基于内存的优先级队列中。对于给定的优先级值,内存中的请求优先于磁盘中的请求。
每个优先级队列将请求存储在单独的内部队列中,每个优先级值一个。内存优先级队列使用 SCHEDULER_MEMORY_QUEUE 队列,而磁盘优先级队列使用 SCHEDULER_DISK_QUEUE 队列。当请求具有相同的优先级时,内部队列决定请求顺序。默认情况下,启动请求存储在单独的内部队列中,并且排序不同。
使用 DUPEFILTER_CLASS 实例过滤掉重复的请求。
下面,我们来看看 scrapy 框架抓取调度的几种策略。
-
请求的顺序
在默认设置下,待处理请求存储在
LIFO队列中(启动请求除外)。因此,提取请求以DFO顺序进行,这通常是最方便的顺序。但是,您可以强制执行BFO或自定义顺序(除了最初的几个请求)。 -
按
start执行顺序启动请求按照
Start()产生的顺序发送,并且在priority参数上设置的优先级相同,其他请求优先于启动请求。您可以将
SCHEDULER_START_MEMORY_QUEUE和SCHEDULER_START_DISK_QUEUE设置为None,以便在顺序和优先级方面处理与其他请求相同的启动请求。 -
按
BFO顺序抓取如果你想按
BFO顺序抓取,你可以设置以下设置:Depth_priority = 1 SCHEDULER_DISK_QUEUE = "scrapy. queues. picklefifodiskqueue " SCHEDULER_MEMORY_QUEUE = "scrapy. queues. fifommemoryqueue " -
自定义顺序
您可以通过
priority参数手动设置请求的优先级,以强制执行特定的请求顺序。 -
并发影响的顺序
当挂起的请求低于
CONCURRENT_REQUESTS、CONCURRENT_REQUESTS_PER_DOMAIN或CONCURRENT_REQUESTS_PER_IP的配置值时,这些请求将并发发送。因此,抓取的前几个请求可能不遵循期望的顺序。将这些设置降低到 1 1 1 会强制执行除第一个请求之外的所需顺序,但它会显著降低整个抓取速度。
| 属性/方法 | 说明 |
|---|---|
__init__(dupefilter: BaseDupeFilter, jobdir= None, dqclass= None, mqclass = None, logunser: bool = False, stats = None, pqclass = None, crawler = None) |
参数 dupefilter:scrapy.dupefilters.BaseDupeFilter实例或BaseDupeFilter 的子类)。负责检查和过滤重复请求的对象。默认情况下使用 DUPEFILTER_CLASS 设置的值。 jobdir: str类型,默认为None。用于持久化抓取状态的目录路径。默认情况下使用 JOBDIR设置的值。参见乔布斯:暂停和恢复爬行。 dqclass: class 类型。用作持久请求队列的类。默认情况下使用SCHEDULER_DISK_QUEUE设置的值。 mqclass: class 类型。用作非持久性请求队列的类。默认情况下使用 SCHEDULER_MEMORY_QUEUE 设置的值。 logunser: bool。指示是否应该记录不可序列化的请求。默认情况下使用 SCHEDULER_DEBUG 设置的值。 state:scrapy.statscollectors.StatsCollector实例或任何实现 StatsCollector接口的类)。一个统计收集器对象,用于记录有关请求调度过程的统计信息。默认使用 STATS_CLASS 设置的值。 pqclass:class 类型。作为请求优先队列使用的类。默认情况下使用 SCHEDULER_PRIORITY_QUEUE 设置的值。 crawler: scrapy.crawler.Crawler 类型。与当前抓取对应的抓取对象。 |
__len__()→ int |
返回排队请求的总数 |
| `close(reason: str)→ DeferredNone | None ` |
enqueue_request(request: Request)→ bool |
处理【引擎】接收到的请求。 如果请求被正确存储则返回 True,否则返回 False。 如果为 False,【引擎】将触发 request_dropped 信号,并且往后不会进一步尝试调度请求。 |
from_crawler(crawler: Crawler)→ Self |
为调度器设置 Crawler 。 |
has_pending_requests()→ bool |
如果调度程序有排队请求,则为True,否则为False |
| `next_request()→ Request | None ` |
| `open(spider: Spider)→ DeferredNone | None ` |
下载器 - Downloader
【下载器】负责抓取网页并将其提供给【引擎】,而【引擎】又将其提供给【爬虫器】。
爬虫 - Spider
【爬虫】是定义如何抓取某个网站(或一组网站)的类,包括如何执行抓取(即跟踪链接)以及如何从页面中提取结构化数据(即抓取【提取项】)。换句话说【爬虫】中自定义行为,以便为特定站点(或者在某些情况下为一组站点)抓取和解析页面。
对于【爬虫】来说,处理的过程一般是:
- 首先生成用于抓取第一个
URL的初始请求,并指定要调用的回调函数来处理这些请求返回的响应。要执行的第一个请求是通过迭代start()方法获得的,默认情况下,该方法为【爬虫】的start_urls属性中的每个URL生成一个Request对象,并将解析方法设置为处理每个响应的回调函数。 - 在回调函数中,解析响应(网页)并返回【提取项】对象、Request对象或这些对象的可迭代对象。这些请求还将包含一个回调(可能是相同的),然后由
Scrapy下载,然后由指定的回调处理它们的响应。 - 在回调函数中,解析页面内容,通常使用
Selectors(但也可以使用BeautifulSoup、lxml或您喜欢的任何机制),并使用解析后的数据生成项。 - 【爬虫】 返回的【提取项】通常会被持久化到数据库中(在某些【提取项管道】中),或者使用
Feed导出写入文件。
尽管这个循环可看作是适用于任何类型的爬虫,但是由于不同的目的,在 Scrapy 中绑定了不同类型的默认爬虫。我们将在这里讨论这些类型。
Scrapy 提供了 Scrapy.Spider 爬虫基类;所有的爬虫类必须继承该基类。
他提供了 start() 和 parse() 两个方法:start() 发送 start_urls 参数提供的请求地址并获取响应;然后调用parse() 方法从获取的响应中抽取所需的数据。
属性
| 属性名 | 类型 | 说明 |
|---|---|---|
name |
str |
爬虫名称字符串。爬虫名称是 Scrapy 定位(和实例化)爬虫的方式,所以它必须是唯一的。如果爬虫抓取的是单个域,通常的做法是用域来命名爬虫,无论是否带有 TLD 。如抓取的站点是 mywebsite.com,则爬虫通常被称为mywebsite。 |
allowed_domains |
list[str] |
一个可选的字符串列表,爬虫抓取的域的列表。如果启用了 OffsiteMiddleware,则不属于此列表中指定的域名(或其子域)的 URL 请求将会丢弃。 假设您的目标 url 是 https://www.example.com/1.html,然后将 example.com 添加到列表中。 |
start_urls |
list[str] |
待处理的请求地址列表 |
custom_settings |
dict |
运行此爬虫时将覆盖掉项目上的同名通用配置。它必须定义为类属性,因为在实例化之前会更新设置。 |
crawler |
Crawler |
该属性在初始化类之后由 from_crawler()类方法设置,并绑定到此爬虫实例的 Crawler对象。 |
settings |
Settings |
运行此爬虫的配置。这是一个 Settings 实例。 |
logger |
Logging |
用爬虫的 name 创建的Python日志记录器。您可以使用它发送日志消息。 |
state |
dict |
可用于在批之间持久化某些爬虫状态的字典。 |
方法
| 方法名 | 说明 |
|---|---|
from_crawler(crawler, *args, **kwargs) |
这是 Scrapy 用来创建爬虫的类方法。 你可能不需要直接覆盖它,因为默认实现充当 __init__() 方法的代理,使用给定的参数 args 和命名参数 kwargs 调用它。 尽管如此,该方法在新实例中设置爬虫和设置属性,以便以后可以在爬虫代码中访问它们。 crawler:Crawler 对象类型。绑定到爬虫的 Crawler 实例; 参数 : args:list 类型。传递给 __init__()方法的参数 kwargs:dict 类型。传递给 __init__()方法的关键字参数 |
update_settings(setting) |
用于修改爬虫的设置,并在爬虫实例初始化期间调用。 它接受一个 Settings 对象作为参数,可以添加或更新爬虫的配置值。此方法是一个类方法,这意味着它在 Spider 类上调用,并允许该 Spider 的所有实例共享相同的配置。 虽然每个爬虫的设置可以在 custom_settings 中设置,但使用 update_settings()允许您根据其他设置,爬虫属性或其他因素动态添加,删除或更改设置,并使用设置优先级而不是 spider。此外,在子类中扩展 update_settings()很容易通过重写它,而对 custom_settings 做同样的事情可能很难。 |
async start() → AsyncIterator[Any] |
发送请求。默认实现从 start_urls 读取 url ,并在启用了 dont_filter 的情况下为每个 url 生成一个请求。 |
parse(response) |
这是 Scrapy 用来处理下载响应的默认回调,当它们的请求没有指定回调时。 parse 方法负责处理响应并返回抓取的数据和/或更多要跟踪的 url。其他请求回调函数具有与Spider 类相同的要求。 这个方法,以及任何其他的 Request 回调,必须返回一个 Request 对象,一个 item 对象,一个 Request 对象和(或)item 对象的可迭代对象,或者None 。 参数 : response: 需要解析的响应实例。 |
log(message[,level,component]) |
通过 Spider 的日志记录器发送日志消息的包装器,保持向后兼容性。 |
closed(reason) |
当爬虫关闭时调用。这个方法为 spider_closed 信号的 signals.connect()提供了一个快捷方式。 |
通用爬虫类
Scrapy 附带了一些有用的通用【爬虫】,您可以使用它们来子类化您的【爬虫】。他们的目标是为一些常见的抓取情况提供方便的功能,比如基于某些规则跟踪站点上的所有链接,从 Sitemaps 中抓取,或者解析 XML / CSV 提要等。
| 类名 | 说明 |
|---|---|
scrapy.spiders.CrawlSpider |
这是从常规网站抓取时最常用的【爬虫】,因为它通过定义一组规则为跟踪链接提供了一种方便的机制。它可能不是最适合您的特定网站或项目,但在某些情况下它是通用的,因此您可以从它开始,并根据需要覆盖它以实现更多自定义功能,或者只是实现您自己的【爬虫】。 rules:它是一个(或多个)Rule 对象的列表。每个规则定义了站点抓取的特定行为。如果多个规则匹配相同的链接,则将根据在此属性中定义的顺序使用第一个规则。 parse_start_url(response, **kwargs):对于为【爬虫】的 start_urls 属性中的 url 生成的每个响应,都会调用此方法。它允许解析初始响应,并且必须返回一个【提取项】对象、一个 Request 对象或包含其中任何一个的可迭代对象。 |
scrapy.spiders.XMLFeedSpider |
XMLFeedSpider 设计用于通过按特定节点名称遍历XML提要来解析 XML 提要。迭代器可以从iternodes、xml 和 html 中选择。出于性能考虑,建议使用 iternodes 迭代器,因为 xml 和 html 迭代器一次生成整个DOM 以便解析它。但是,在解析带有错误标记的 XML 时,使用 html 作为迭代器可能很有用。 |
scrapy.spiders.CSVFeedSpider |
这个【爬虫】与 XMLFeedSpider 非常相似,不同之处在于它遍历行,而不是遍历节点。在每次迭代中调用的方法是 parse_row()。 |
scrapy.spiders.SitemapSpider |
SitemapSpider 允许您通过使用 Sitemaps 发现 url 来抓取站点。 它支持嵌套的站点地图和从 robots.txt 中发现站点地图 url。 |
提取项管道 - Item Pipeline
【提取项管道】负责在【爬虫】提取(或抓取)【提取项】后对其进行处理。典型的任务包括清理、验证和持久化(比如将项存储在数据库中)。
【爬虫】抓取【提取项】后,将其发送到【提取项管道】,【提取项管道】通过顺序执行的几个组件处理【提取项】。
每个【提取项管道】组件是一个Python类,实现一个简单的方法。它们接收一个项目并对其执行操作,同时决定该【提取项】是应该继续通过管道,还是应该被丢弃并不再处理。
【提取项管道】的典型用途有:
- 清理
HTML数据 - 验证抓取的数据(检查【提取项】是否包含某些字段)
- 检查重复(并删除它们)
- 将抓取的【提取项】存储在数据库中
编写自己的【提取项管道】组件
每个【提取项管道】都是一个组件,必须实现下表的方法:
| 方法名 | 说明 |
|---|---|
process_item(self,item,spider) |
此方法将为每个【提取项管道】组件调用。 参数: Item: Item对象类型。被抓取的【提取项】 spider:Spider对象类型。 |
open_spider(self,spider) |
该方法将在打开【爬虫】时调用。 参数: spider:Spider对象类。被打开的【爬虫】 |
close_spider(self,spider) |
该方法将在【爬虫】关闭时调用。 参数: spider:Spider对象。关闭的【爬虫】 |
激活编写的组件
要激活一个【提取项管道】组件,你必须将它的类添加到 ITEM_PIPELINES 设置中,如下例所示:
ITEM_PIPELINES = {
"myproject.pipelines.PricePipeline": 300,
"myproject.pipelines.JsonWriterPipeline": 800,
}在此设置中,为类分配的整数值决定了它们运行的顺序为从低到高。通常将这些数字定义在 0 ~1000 范围内。
下载中间件 - Downloader Middleware
【下载中间件】是位于【引擎】和【下载器】之间的特定钩子,处理从【引擎】传入到【下载器】的请求,以及从【下载器】传递到【引擎】的响应。
如果有以下需要,使用【下载中间件】:
- 在发送到【下载器】之前预处理请求信息(即在
Scrapy将请求发送到网站之前); - 在接收到的响应传给 【爬虫】之前处理接收到的响应;
- 发送一个新的请求,而不是将收到的响应传送给 【爬虫】;
- 在没有获取网页时传送响应给【爬虫】;
- 静默删除一些请求。
通用的下载中间件
Scrapy 提供了一些【下载中间件】组件。如下表:
| 类名 | 说明 |
|---|---|
CookiesMiddleware |
这个中间件支持处理需要 cookie 的站点,比如那些使用会话的站点。它跟踪 web 服务器发送的 cookie ,并在后续请求(来自该【爬虫】)时将它们发送回来,就像 web 浏览器一样。 可以使用以下设置来配置 cookie中间件: COOKIES_ENABLED:是否启用 cookie 中间件。如果禁用,则不会向 web 服务器发送任何 cookie。默认为 True 。 COOKIES_DEBUG:如果启用,Scrapy 将记录在请求中发送的所有 Cookie(即 Cookie 头)和在响应中接收的所有Cookie(即 Set-Cookie 头)。 |
DefaultHeadersMiddleware |
该中间件设置DEFAULT_REQUEST_HEADERS 设置中指定的所有默认请求头。 |
DownloadTimeoutMiddleware |
该中间件为 DOWNLOAD_TIMEOUT 设置或【爬虫】的download_timeout 属性中指定的请求设置下载超时。 |
HttpAuthMiddleware |
此中间件使用基本访问身份验证(也称为。HTTP 身份验证)。 要为【爬虫】启用 HTTP 身份验证,将http_user 和 http_pass 爬行器属性设置为身份验证数据,并将 http_auth_domain 爬行器属性设置为需要此身份验证的域(其子域也将以相同的方式处理)。您可以将 http_auth_domain 设置为 None 以对所有请求启用身份验证,但您可能会将身份验证凭据泄露到不相关的域。 |
HttpCacheMiddleware |
该中间件为所有 HTTP 请求和响应提供低级缓存。它必须与缓存存储后端以及缓存策略相结合。 |
DummyPolicy |
该策略不知道任何 HTTP 缓存控制指令。每个请求及其相应的响应都被缓存。当再次看到相同的请求时,将返回响应,而无需从 Internet 传输任何内容。 Dummy 策略对于更快地测试【爬虫】(而不必每次都等待下载)以及在没有Internet 连接时离线尝试【爬虫】非常有用。目标是能够"重播"【爬虫】的运行,就像它之前运行的那样。 |
RFC2616Policy |
该策略提供了一个 RFC2616 兼容的 HTTP 缓存,即 HTTP 缓存控制意识,针对生产和连续运行,以避免下载未修改的数据(以节省带宽和加快爬行速度)。 |
| FilesystemCacheStorage` | 文件系统存储后端可用于 HTTP 缓存中间件。 目录名来自请求指纹,并且使用一个子目录级别来避免在同一目录中创建太多文件(这在许多文件系统中是低效的)。 |
DbmCacheStorage |
DBM 存储后端也可用于HTTP缓存中间件。 默认情况下,它使用 dbm,但您可以使用 HTTPCACHE_DBM_MODULE 设置更改它。 |
HttpCompressionMiddleware |
这个中间件允许从网站发送/接收压缩(gzip, deflate)的流量。 该中间件还支持解码 brotli-compressed 和 zstd-compressed 响应,前提是分别安装了 brotli 或 zstandard。 |
OffsiteMiddleware |
在 2.11.2 版添加。 过滤掉【爬虫】覆盖的域之外的 url 请求。 这个中间件过滤掉主机名不在【爬虫】的allowed_domains属性中的每个请求。也允许列表中任何域的所有子域。例如,规则 www.example.org 也将允许 bob.www.example.org,但不允许www2.example.com 和 example.com。 |
RedirectMiddleware |
该中间件根据响应状态处理请求的重定向。 请求经过的 url(当被重定向时)可以在 Request.meta的redirect_urls 中获取。 redirect_urls 中每个重定向背后的原因可以在Request.meta中的 redirect_reasons 中找到。例如:[301,302,307,'meta refresh']。 原因的格式取决于处理相应重定向的中间件。例如,RedirectMiddleware 将触发响应状态码表示为整数,而MetaRefreshMiddleware 总是使用 meta refresh 字符串作为原因。 RedirectMiddleware 可以通过以下设置进行配置(更多信息请参阅设置文档): REDIRECT_ENABLED REDIRECT_MAX_TIMES 如果 Request.meta 将 dont_redirect key设置为 True,则该中间件将忽略该请求。 如果希望在【爬虫】中处理一些重定向状态码,可以在 handle_httpstatus_list【爬虫】属性中指定它们。 |
MetaRefreshMiddleware |
这个中间件处理基于html 标签 meta-refresh 的请求重定向。 MetaRefreshMiddleware 可以通过以下设置进行配置(更多信息请参见设置文档): METAREFRESH_ENABLED METAREFRESH_IGNORE_TAGS METAREFRESH_MAXDELAY 这个中间件遵循 REDIRECT_MAX_TIMES设置,Request.meta 中的 dont_redirect, redirect_urls 和 redirect_reasons 参数在RedirectMiddleware 中描述 |
RetryMiddleware |
用于重试可能由连接超时或HTTP 500错误等临时问题引起的失败请求的中间件。 在抓取过程中收集失败的页面,并在【爬虫】完成所有常规(非失败)页面的爬行后重新调度。 RetryMiddleware 可以通过以下设置进行配置(更多信息请参见设置文档): RETRY_ENABLED RETRY_TIMES RETRY_HTTP_CODES RETRY_EXCEPTIONS 如果 Request.meta 将 dont_retry 参数设置为 True,此中间件将忽略该请求。 |
RobotsTxtMiddleware |
这个中间件过滤掉 robots.txt 中排除标准禁止的请求。 为了确保 Scrapy 遵循 robots.txt,请确保启用了中间件并启用了ROBOTSTXT_OBEY设置。 ROBOTSTXT_USER_AGENT设置可用于指定用于在 robots.txt 文件中进行匹配的用户代理字符串。如果为 None,则您发送请求的 User-Agent 头或USER_AGENT 设置(按此顺序)将用于确定 robots.txt文件中要使用的用户代理。 这个中间件必须与 robots.txt 解析器结合使用。 |
UserAgentMiddleware |
允许【爬虫】覆盖默认用户代理的中间件。 为了使【爬虫】覆盖默认用户代理,必须设置其 user_agent属性。 |
编写自己的下载中间件
每个【下载中间件】都是一个定义了以下表中的一个或多个方法组件:
| 方法名 | 说明 |
|---|---|
process_request(request,spider) |
对于通过【下载中间件】的每个请求,都会调用此方法。 process_request() 可能返回 None,或者 Response对象,获取Request对象,或者引发IgnoreRequest。 如果它返回None,则 Scrapy 将继续处理此请求,执行所有其他中间件,直到最后调用适当的【下载器】处理程序执行请求(并下载其响应)。 如果它返回一个 Response 对象,Scrapy 就不会调用任何其他的process_request() 或 process_exception() 方法,或者相应的下载函数;它会返回那个响应。已安装中间件的 process_response() 方法总是在每次响应时调用。 如果它返回一个 Request 对象,Scrapy 将停止调用 process_request() 方法,并重新安排返回的请求。一旦执行了新返回的请求,就会在下载的响应上调用相应的中间件链。 如果它引发一个 IgnoreRequest 异常,则将调用已安装的下载器中间件的process_exception() 方法。如果它们都没有处理异常,则调用请求的errback 函数(request .errback)。如果没有代码处理引发的异常,它将被忽略且不记录(与其他异常不同)。 参数: request:Request对象。正在处理的请求 spider:Spider对象。此请求所针对的【爬虫】 |
process_response(request,response,spider) |
process_response() 返回一个 Response 对象,或一个 Request 对象,或者引发一个 IgnoreRequest 异常。 如果它返回一个Response(它可以是相同的给定响应,也可以是全新的响应),则该响应将继续由链中下一个中间件的 process_response()处理。 如果它返回一个 Request 对象,中间件链将停止,返回的请求将被重新调度,以便将来下载。这与从 process_request()返回请求的行为相同。 如果它引发一个 IgnoreRequest 异常,则调用请求的 errback 函数(request .errback)。如果没有代码处理引发的异常,它将被忽略且不记录(与其他异常不同)。 参数: request:Request对象。发起响应的请求 response:Response对象。正在处理的响应 spider:Spider对象。此响应所针对的蜘蛛 |
process_exception(request,exception,spider) |
当【爬虫】或 process_request()(来自下载中间件)引发异常(包括 IgnoreRequest 异常)时,Scrapy 调用 process_exception()。 process_exception() 返回 None、或Response对象或 Request对象。 如果它返回 None, Scrapy 将继续处理此异常,执行已安装中间件的任何其他 process_exception() 方法,直到没有中间件剩余并启动默认异常处理。 如果它返回一个 Response 对象,则启动已安装中间件的process_response() 方法链,并且 Scrapy 不会调用中间件的任何其他process_exception() 方法。 如果它返回一个 Request 对象,返回的请求将被重新调度,以便将来下载。这将停止中间件的 process_exception() 方法的执行,就像返回响应一样。 参数: request:Request对象。生成异常的请求 exception:Exception对象。引发的异常 spider:Spider 对象。此请求所针对的【爬虫】 |
激活自己的下载中间件
要激活下载中间件组件,请将其添加到 DOWNLOADER_MIDDLEWARES 设置中,该设置是一个字典,其键是中间件类路径,其值是中间顺序。这里有一个例子:
DOWNLOADER_MIDDLEWARES = {
"myproject.middlewares.CustomDownloaderMiddleware": 543,
}DOWNLOADER_MIDDLEWARES设置与 Scrapy 中定义的 DOWNLOADER_MIDDLEWARES_BASE 设置合并(并不一定是覆盖),然后按顺序排序以获得启用中间件的最终排序列表:第一个中间件是靠近【引擎】的中间件,最后一个是靠近【下载器】的中间件。换句话说,每个中间件的 process_request()方法将按递增的中间件顺序调用(100,200,300,...),每个中间件的 process_response()方法将按递减的顺序调用。
要决定将哪个顺序分配给中间件,请参阅 DOWNLOADER_MIDDLEWARES_BASE 设置,并根据要插入中间件的位置选择一个值。顺序很重要,因为每个中间件执行不同的操作,您的中间件可能依赖于应用的某个先前(或后续)中间件。
如果你想禁用一个内置中间件(在 DOWNLOADER_MIDDLEWARES_BASE中定义的,默认情况下是启用的),你必须在项目的DOWNLOADER_MIDDLEWARES 设置中定义它,并将其值指定为 None。例如,如果您想禁用 user-agent 中间件:
DOWNLOADER_MIDDLEWARES = {
"myproject.middlewares.CustomDownloaderMiddleware": 543,
"scrapy.downloadermiddlewares.useragent.UserAgentMiddleware": None,
}爬虫中间件 - Spider middlewares
【爬虫中间件】是位于【引擎】和【爬虫】之间的特定钩子,能够处理【爬虫】的输入(响应信息)和输出(【提取项】和请求信息)。如果有以下需要,使用【爬虫中间件】:
- 【爬虫】回调的后处理输出:更改、添加或删除请求或【提取项】;
- 后处理启动请求或【提取项】;
- 处理【爬虫】异常;
- 根据响应内容调用错误回调而不是回调。
中间件基类
Scrapy为定制【爬虫中间件】提供了一个基类BaseSpiderMiddleware。它不是必须使用的,但它可以帮助简化中间件实现并减少通用中间件中的样板代码数量。
| 属性/方法 | 说明 |
|---|---|
get_processed_item(item: Any, response=None)→ Any |
返回从【爬虫】输出中已处理过的项。此方法使用起始种子或【爬虫】输出中的单个【提取项】来调用。它应该返回相同或不同的【提取项】,或者返回 None 来忽略它。 参数: Item :Item对象。输入项 response:Response 对象,默认为 None:正在处理的响应 **返回:**处理项或None |
get_processed_request(request: Request, response=None)→ Request=None |
返回从【爬虫】输出中已处理过的请求。此方法通过从启动种子或【爬虫】输出的单个请求调用。它应该返回相同或不同的请求,或者返回 None 以忽略它。 参数: request:Request对象。输入请求 response:Response 对象,默认为 None。-正在处理的响应 **返回:**处理后的请求或 None |
通用中间件
| 类名 | 说明 |
|---|---|
DepthMiddleware |
|
HttpErrorMiddleware |
过滤掉不成功的(错误的)HTTP 响应,使【爬虫】不必处理它们,因为(大多数时候)处理它们会增加开销,消耗更多资源,并使【爬虫】逻辑更加复杂。 根据 HTTP标准,状态码在200-300范围内的响应是成功的响应。如果仍然希望处理超出该范围的响应代码,则可以使用【爬虫】的属性 handle_httpstatus_list spider 或 HTTPERROR_ALLOWED_CODES 设置指定【爬虫】能够处理哪些响应代码。 |
RefererMiddleware |
根据生成它的响应的 URL 填充请求 Referer 头。 |
StartSpiderMiddleware |
设置 is_start_request 参数。如果设为 True,允许您将启动请求与其他请求区分开来。 |
UrlLengthMiddleware |
过滤 url 长度超过 URLLENGTH_LIMIT 的请求 UrlLengthMiddleware 可以通过以下设置进行配置(更多信息请参见设置文档): URLLENGTH_LIMIT :允许抓取的 URL 的最大 URL 长度。 |
编写自己的爬虫中间件
每个【爬虫中间件】都是一个定义了下表中列出的一个或多个方法的组件:
| 方法 | 说明 |
|---|---|
async process_start(start: AsyncIterator[Any],/) → AsyncIterator[Any] |
迭代start()的输出或早期【爬虫】中间件的 process_start()方法的输出,重写它。 |
process_spider_input(response,spider)* |
对于经过【爬虫中间件】并进入【爬虫】进行处理的每个响应,都会调用此方法。 process_spider_input()应该返回 None 或引发异常。 如果它返回 None,则 Scrapy 将继续处理该响应,并执行所有其他中间件,直到最后将响应交给爬行器进行处理。 如果它引发了一个异常,Scrapy 就不会调用任何其他爬虫中间件的 process_spider_input(),如果有,它将调用请求 errback,否则它将启动 process_spider_exception()链。errback 的输出在另一个方向上被链接起来,以便 process_spider_output() 处理它,如果它引发异常,则process_spider_exception()。 参数: response: Response 对象。正在处理的响应 spider:Spider对象。此响应所针对的蜘蛛 |
process_spider_output(response,result,spider) |
在处理完响应后,使用从【爬虫】返回的结果调用此方法。 process_spider_output()必须返回 Request 对象和 item 对象的可迭代对象。 在 2.7 版更改:此方法可以定义为异步生成器,在这种情况下,result 是一个异步可迭代对象。 考虑将此方法定义为异步生成器,这将是 Scrapy 未来版本的需求。但是,如果您计划与其他人共享您的爬行器中间件,请考虑将 Scrapy 2.7 作为爬行器中间件的最低要求,或者使您的爬行器中间件通用,以便与早于 Scrapy 2.7 的 Scrapy 版本一起工作。 参数: response:Response对象。从爬行器生成此输出的响应 result: Request对象和 Item对象的可迭代对象。【爬虫】]返回的结果 spider:(蜘蛛对象。正在处理其结果的蜘蛛 |
async process_spider_output_async(response,result,spider) |
在 2.7 版添加。 如果定义了该方法,则该方法必须是一个异步生成器,如果 result 是一个异步可迭代对象,则调用该方法而不是调用process_spider_output()。 |
process_spider_exception(response,exception,spider) |
当【爬虫】或 process_spider_output()方法(来自以前的【爬虫中间件】)引发异常时,调用此方法。 process_spider_exception() 应该返回 None 或 Request 或 item 对象的可迭代对象。 如果它返回 None , Scrapy 将继续处理此异常,在以下中间件组件中执行任何其他 process_spider_exception(),直到没有剩下任何中间件组件并且异常到达引擎(在那里它被记录并丢弃)。 如果它返回一个可迭代对象,process_spider_output()管道就会启动,从下一个爬行器中间件开始,并且不会调用其他process_spider_exception()。 参数: response:Reponse 对象。引发异常时正在处理的响应 exception:Exception 对象。引发的异常 spider:Spider对象。引发异常的蜘蛛 |
激活中间件
要激活【爬虫中间件】组件,请将其添加到 SPIDER_MIDDLEWARES 设置中,该设置是一个字典,其键是中间件类路径,其值是中间件订单。
这里有一个例子:
SPIDER_MIDDLEWARES = {
"myproject.middlewares.CustomSpiderMiddleware": 543,
}SPIDER_MIDDLEWARES 设置与 Scrapy 中定义的 SPIDER_MIDDLEWARES_BASE设置合并(并且不打算被覆盖),然后按顺序排序以获得已启用中间件的最终排序列表:第一个中间件是靠近引擎的中间件,最后一个是靠近蜘蛛的中间件。换句话说,每个中间件的process_spider_input()方法将按递增的中间件顺序调用(100,200,300,...),每个中间件的 process_spider_output()方法将按递减的顺序调用。
要决定将哪个顺序分配给中间件,请参阅 SPIDER_MIDDLEWARES_BASE 设置,并根据要插入中间件的位置选择一个值。顺序很重要,因为每个中间件执行不同的操作,您的中间件可能依赖于应用的某个先前(或后续)中间件。
如果你想禁用一个内置中间件(在 SPIDER_MIDDLEWARES_BASE 中定义的中间件,默认情况下是启用的),你必须在你的项目中设置SPIDER_MIDDLEWARES ,并将其值指定为 None。例如,如果您想禁用离线中间件:
SPIDER_MIDDLEWARES = {
"scrapy.spidermiddlewares.referer.RefererMiddleware": None,
"myproject.middlewares.CustomRefererSpiderMiddleware": 700,
}事件驱动网络
Scrapy 是用 Twisted 编写的,Twisted 是一个流行的Python事件驱动网络框架。因此,它是使用非阻塞代码实现并发的。
使用 Scrapy 框架
创建爬虫项目
Scrapy框架提供了命令行工具,首先进入工作目录(比如 D:/template,以下称 WD),可以直接使用它来创建新的爬虫项目。如下:
scrapy startproject tutorial这样,在 WD 目录下创建了新的工程目录 tutorial,目录结构为:
├ tutorial/
├--├-- scrapy.cfg # 部署配置文件
├--├-- tutorial/ # 项目模块目录
├--├----├-- __init__.py
├--├----├-- items.py # 项目 items 定义文件
├--├----├-- middlewares.py # 中间件文件
├--├----├-- pipelines.py # 项目 pipelines 文件
├--├----├-- settings.py # 项目配置参数文件
├--├----├-- spiders/ # 放置爬虫代码的目录
└--└----└----└-- __init__.py编写爬虫代码
【爬虫】是您定义的抓取网页的类,Scrapy 使用它从一个网站(或一组网站)中抓取信息。它们必须继承自 Spider 基类并定义要发出的初始请求,如果需要,可以跟踪页面中的链接和解析下载的页面内容以提取数据。
这是我们第一个爬虫代码。将其保存在项目 tutorial/spider 目录下的 quotes_spider.py 文件中:
from pathlib import Path
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
async def start(self):
urls = [
"https://quotes.toscrape.com/page/1/",
"https://quotes.toscrape.com/page/2/",
]
// 将要抓取的URL地址放到请求队列中,并传入回调 parse 来处理抓取的响应
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = f"quotes-{page}.html"
Path(filename).write_bytes(response.body)
self.log(f"保存到 {filename}")如您所见,我们的 Spider子类 QuotesSpider 定义了一些属性和方法:
name:定义新创建爬虫的标识名称。它在一个项目中必须是唯一的,也就是说,您不能为不同的爬虫设置相同的名称。Start():必须是一个异步生成器,为爬虫开始抓取生成请求(以及可选的项)。后续请求将根据这些初始请求中依次生成。Parse(): 提交的请求响应后,调用该方法来处理响应的方法。response属性是TextResponse的一个实例,它保存页面内容,并提供一些方法来处理页面内容。parse()方法通常解析响应,将抓取的数据提取为字典;并从响应中查找新URL地址,并创建新请求。
运行爬虫程序
如果要运行爬虫项目,我们要返回到项目根目录下运行:
scrapy crawl quotes以上命令启动刚才我们新建的爬虫 quotes ,它将向 quotes.toscrape.com 域发送请求。
启动完成后,我们检查当前目录中的文件。您应该注意到已经创建了两个新文件:quotes-1.html 和 quotes-2.html,其中包含各自 URL的内容,正如我们的解析方法所指示的那样。
Scrapy 发送第一个 scrapy.Request请求给爬虫中的 start() 方法,start() 方法将要采集的 URL 提交给 scrapy.Request。在接收到每个请求的响应后,Scrapy 调用传入的回调方法 parse 来处理响应数据。
从响应中提取数据
使用 Scrapy shell 工具提取
scrapy shell "https://quotes.toscrape.com/page/1/"执行后,我们可以使用 shell 工具提供的 response.css 方法来提取元素:
response.css("title")运行 response.css('title') 得到的结果是一个 SelectorList 的类似列表的对象,它包含 XML / HTML 元素的 Selector 对象列表,并允许您运行进一步的查询来优化选择或提取数据。
从 title 节点中提取文本,可以使用:
response.css("title::text").getall()这里有两点需要注意:一是我们在 CSS 查询中添加了 ::text ,意思是我们只想直接选择 <title> 元素中的文本内容。如果不指定 ::text,我们将得到完整的 title 元素,包括它的标签:
response.css("title").getall()另一件事是调用 .getall() 的结果是一个列表:选择器可能返回多个结果,因此我们将它们全部提取出来。当你知道你只想要第一个结果时,就像在这个例子中,你可以这样做:
response.css("title::text").get()作为替代,你可以这样写:
response.css("title::text")[0].get()如果没有结果,访问 SelectorList 实例上的索引将引发 IndexError 异常:
response.css("noelement")[0].get()输出:
IndexError: list index out of range你可能想直接在 SelectorList 实例上使用 .get() ,如果没有结果则返回 None:
response.css("noelement").get()这里有一个教训:对于大多数抓取代码,您希望它能够适应由于在页面上没有找到内容而导致的错误,这样即使某些部分无法被抓取,您至少可以获得一些数据。
除了 getall() 和 get() 方法,你还可以使用 re() 方法来使用正则表达式进行提取:
response.css("title::text").re(r"Quotes.*")
response.css("title::text").re(r"Q\w+")
response.css("title::text").re(r"(\w+) to (\w+)")除了使用 response.css 方法外,还可以使用 response.xpath :
response.xpath("//title")
response.xpath("//title/text()").get()XPath 表达式非常强大,是 Scrapy 选择器的基础。实际上,CSS 选择器在底层也是被转换为 XPath。
虽然 XPath 表达式可能不如 CSS 选择器流行,但它提供了更强大的功能,因为除了导航结构之外,它还可以查看内容。使用 XPath,您可以选择以下内容:包含文本"下一页"的链接。这使得 XPath 非常适合于抓取任务,会使抓取变得容易得多。
在爬虫代码中提取数据
我们回头看看刚才些的爬虫代码,到目前为止,它还没有提取任何特定的数据,只是将整个HTML 页面保存到本地文件中。让我们将上面的提取逻辑集成到爬虫中。
Scrapy 爬虫在从响应中提取数据时,通常使用字典来保存;要做到这一点,我们在回调中使用 yield Python 关键字,如下所示:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
"https://quotes.toscrape.com/page/1/",
"https://quotes.toscrape.com/page/2/",
]
def parse(self, response):
for quote in response.css("div.quote"):
yield {
"text": quote.css("span.text::text").get(),
"author": quote.css("small.author::text").get(),
"tags": quote.css("div.tags a.tag::text").getall(),
}要运行这个爬虫,输入以下命令退出 scrapy shell:
quit()然后运行:
scrapy crawl quotes现在可以看到如下日志:
2016-09-19 18:57:19 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/page/1/>
{'tags': ['life', 'love'], 'author': 'André Gide', 'text': '"It is better to be hated for what you are than to be loved for what you are not."'}
2016-09-19 18:57:19 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/page/1/>
{'tags': ['edison', 'failure', 'inspirational', 'paraphrased'], 'author': 'Thomas A. Edison', 'text': ""I have not failed. I've just found 10,000 ways that won't work.""}存储数据
存储抓取数据的最简单方法是使用 Feed 导出,使用以下命令:
scrapy crawl quotes -O quotes.json这将生成一个包含所有抓取内容的 quotes.json 文件, json 格式。
-O 命令行参数表示将内容覆盖现有文件; -o 命令行参数表示将新内容添加到现有文件。使用追加到 JSON 文件的方式可能会使文件内容变成无效JSON 格式;因此,采用 -o 方式可以考虑使用不同的序列化方法,例如 JSON Lines:
scrapy crawl quotes -o quotes.jsonlJSON Lines 很有用,因为它类似于流,所以您可以轻松地向其添加新记录。当您运行两次时,它不会出现与 JSON 相同的问题。此外,由于每条记录都是单独的一行,因此您可以处理大文件,而不必将所有内容都放入内存中,有 JQ 等工具可以在命令行中帮助您完成此工作。
在小型项目中,这应该足够了。但是,如果您想要对抓取的项执行更复杂的操作,您可以编写一个 Item Pipeline。项目创建时,在 tutorial/ Pipelines .py 中已经为您设置了项目管道的占位符文件。不过,如果您只想存储抓取的项,则不需要实现任何项管道。
提取新的请求链接
比方说,你不只想从 https://quotes.toscrape.com 的前两页抓取内容,你想要从网站的所有页面中引用。
现在您已经知道了如何从页面中提取数据,接下来让我们看看如何从页面中跟踪并提取链接。
首先要做的是提取到我们想要关注的页面的链接。检查我们的页面,我们可以看到有一个链接到下一页与以下标记:
<ul class="pager">
<li class="next">
<a href="/page/2/">Next <span aria-hidden="true">→</span></a>
</li>
</ul>在 shell 中提取链接:
response.css('li.next a').get()这将获得 a 元素,但我们需要属性 href。为此,Scrapy 支持一个 CSS 扩展,可以让你选择属性内容,如下所示:
response.css("li.next a::attr(href)").get()还有一个可用的属性:
response.css("li.next a").attrib["href"]现在回到爬虫代码,修改为递归地跟随链接到下一页,从中提取数据:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
"https://quotes.toscrape.com/page/1/",
]
def parse(self, response):
for quote in response.css("div.quote"):
yield {
"text": quote.css("span.text::text").get(),
"author": quote.css("small.author::text").get(),
"tags": quote.css("div.tags a.tag::text").getall(),
}
next_page = response.css("li.next a::attr(href)").get()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)现在,在提取数据之后,在 parse() 方法中查找到 "下一页" 的链接,使用 urljoin() 方法构建一个完整的绝对 URL(因为链接可以是相对的),并生成一个对下一页的新请求,将自己注册为回调,以处理下一页的数据提取,并保持在所有页面上爬行。
您在这里看到的是 Scrapy 的以下链接机制:当您在回调方法中产生请求时,Scrapy 将安排发送该请求并注册一个回调方法,以便在该请求完成时执行。
使用它,您可以构建复杂的爬虫,根据您定义的规则跟踪链接,并根据所访问的页面提取不同类型的数据。
在例子中,它创建了一种循环,跟随所有到下一页的链接,直到它找不到任何的链接。
除了上面例子,还可以使用另外一种方式来构建新的请求:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
"https://quotes.toscrape.com/page/1/",
]
def parse(self, response):
for quote in response.css("div.quote"):
yield {
"text": quote.css("span.text::text").get(),
"author": quote.css("span small::text").get(),
"tags": quote.css("div.tags a.tag::text").getall(),
}
next_page = response.css("li.next a::attr(href)").get()
if next_page is not None:
yield response.follow(next_page, callback=self.parse)不像 scrapy.Request ,response.follow直接支持相对 URL,不需要调用 urljoin。注意,response.follow 只返回一个Request 实例;你还是得 yied 这个请求。
你也可以传递一个选择器给 response.follow。而不是字符串;这个选择器应该提取必要的属性:
for href in response.css("ul.pager a::attr(href)"):
yield response.follow(href, callback=self.parse)对于 <a> 元素,有一个快捷方式:response.follow 自动使用它们的 href 属性。代码可以进一步改为:
for a in response.css("ul.pager a"):
yield response.follow(a, callback=self.parse)要从一个可迭代对象创建多个请求,可以使用 response.follow_all 替代:
anchors = response.css("ul.pager a")
yield from response.follow_all(anchors, callback=self.parse)或者:
yield from response.follow_all(css="ul.pager a", callback=self.parse)