目录
干货分享,感谢您的阅读!
在高并发场景下,缓存作为前置查询机制,显著减轻了数据库的压力,提高了系统性能。然而,这也带来了缓存失效、增加回溯率等风险。常见的问题包括缓存穿透、缓存雪崩、热Key和大Key等。这些问题如果不加以处理,会影响系统的稳定性和性能。因此,采用有效的缓存策略,如缓存空结果、布隆过滤器、缓存过期时间随机化、多级缓存等,对于保障系统在高并发情况下的可靠性至关重要。本次我们将详细探讨缓存穿透及其应对策略。
一、问题描述
缓存的设计通常旨在提高系统的查询效率,通过减少对数据库的直接访问来缓解压力。然而,当大量非法请求查询数据库中不存在的数据时,既无法命中缓存,也无法从数据库中获取结果,这种情况被称为缓存穿透。缓存穿透使缓存形同虚设,缓存命中率降为零,每次请求都直接穿过缓存到达数据库。
在这种情况下,数据库承受了所有请求的压力,缓存未能发挥其应有的作用。如果有人恶意攻击系统,通过大量不存在的key请求接口,这些请求会直接穿透缓存并打到数据库上,可能导致数据库负载过重甚至宕机。
二、解决策略分析
(一)解决策略一:缓存空结果
对于查询结果为空的数据,可以将空结果缓存一段时间,防止频繁的重复查询。这有效地阻止了非法请求反复查询相同的不存在数据。建议通过将不存在的数据标识为特殊的空对象(如"##"),可以避免每次查询都回溯到数据库。同时,通过设置合理的过期时间,可以防止这种空对象占用缓存空间过久。
java
public Object getCache(final String key) {
// 从缓存中获取值
Object value = redis.get(key);
// 如果缓存中存在该值
if (value != null) {
// 如果值是空对象标识,则返回null
if ("##".equals(value)) {
return null;
}
// 否则返回缓存中的值
return value;
}
// 缓存中不存在该值,从数据库中查询
Object valueFromDb = getValueFromDb(key);
// 如果数据库中也不存在该值
if (valueFromDb == null) {
// 将空对象标识存入缓存,并设置过期时间
redis.set(key, "##", t);
return null;
}
// 将数据库查询到的值存入缓存,并设置过期时间
redis.set(key, valueFromDb, t);
return valueFromDb;
}(二)解决策略二:参数合法性校验
在应用层进行参数校验,过滤掉不合理的请求,避免无效请求穿透缓存到达数据库。例如,对于ID范围的验证,如果ID超出合理范围,则直接返回错误。
java
if (!isValid(key)) {
return null; // 非法请求
}(三)解决策略三:引入布隆过滤器
缓存穿透是指查询数据每次都要经过缓存,当查询未命中时会回溯到数据库。这种情况会对数据库造成很大的压力,尤其在高并发场景下。如果能在查询缓存之前提前过滤掉那些一定不存在的数据,就能有效避免缓存穿透的问题。这就需要一种高效的存储结构来存储所有数据,提前过滤查询数据是否存在。
通过引入布隆过滤器,可以在查询缓存之前有效过滤掉那些一定不存在的数据,避免无效查询穿透缓存并打到数据库上。这不仅提高了缓存的命中率,减轻了数据库的压力,还提升了系统的整体性能。布隆过滤器以其低内存占用和高效查询的特点,成为解决缓存穿透问题的一种有效手段。在实际应用中,可以结合具体业务需求和系统特点,灵活运用布隆过滤器与其他缓存策略,确保系统在高并发情况下的稳定性和高性能。
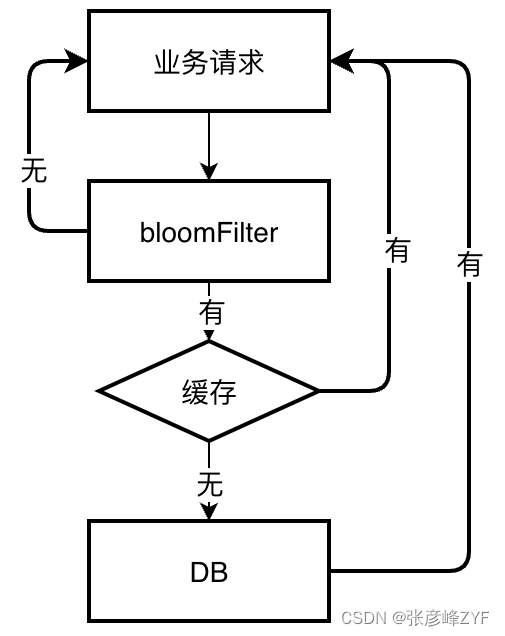
以下是布隆过滤器在防止缓存穿透中的示例代码:
java
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class CacheService {
// 布隆过滤器实例
private BloomFilter<String> bloomFilter;
public CacheService(int expectedInsertions, double falsePositiveProbability) {
// 初始化布隆过滤器
bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), expectedInsertions, falsePositiveProbability);
// 将现有的数据加载到布隆过滤器中
loadDataToBloomFilter();
}
// 加载现有的数据到布隆过滤器中
private void loadDataToBloomFilter() {
// 假设从数据库中加载所有键
List<String> allKeys = getAllKeysFromDb();
for (String key : allKeys) {
bloomFilter.put(key);
}
}
// 查询缓存方法
public Object getCache(final String key) {
// 先通过布隆过滤器判断数据是否可能存在
if (!bloomFilter.mightContain(key)) {
// 如果布隆过滤器判断数据不存在,直接返回null
return null;
}
// 从缓存中获取值
Object value = redis.get(key);
// 如果缓存中存在该值,直接返回
if (value != null) {
return value;
}
// 缓存中不存在该值,从数据库中查询
Object valueFromDb = getValueFromDb(key);
// 将查询到的值存入缓存
redis.set(key, valueFromDb, t);
return valueFromDb;
}
// 从数据库中获取所有键的方法(示例方法)
private List<String> getAllKeysFromDb() {
// 假设从数据库中获取所有键的列表
return Arrays.asList("key1", "key2", "key3", ...);
}
// 从数据库中获取值的方法(示例方法)
private Object getValueFromDb(String key) {
// 假设从数据库中获取值
return ...;
}
}三、总结
在面对高并发场景下的系统优化中,缓存作为提高性能的重要手段,却也引发了一系列挑战,如缓存穿透问题。缓存穿透指的是恶意请求或不存在的数据频繁穿透缓存直达数据库,严重影响系统的稳定性和性能。为应对这一问题,本文深入探讨了多种有效的解决策略。
首先,我们介绍了缓存空结果的策略,通过在缓存中存储空对象标识,并设置合理的过期时间,有效防止了重复查询对数据库造成的冲击。其次,参数合法性校验作为应用层的第一道防线,有效过滤掉不合理的请求,避免了无效查询穿透到数据库。最重要的是引入布隆过滤器的策略,该技术在查询前判断数据是否可能存在,显著提高了缓存命中率,有效遏制了缓存穿透问题的发生。
这些策略不仅仅是理论上的探讨,更包括了具体的实现代码和技术应用。通过结合这些策略,可以有效保障系统在高并发场景下的稳定性和性能表现。每种策略都有其独特的应用场景和优缺点,系统设计者可以根据具体业务需求和系统特点选择合适的组合方案。
有效应对缓存穿透问题不仅是技术优化的需求,更是保障系统可靠性和高效性的关键一环。随着技术的不断演进和应用场景的扩展,我们期待通过更加智能和创新的缓存策略,进一步提升系统的整体性能和用户体验。