一、整体架构图解(核心流程)
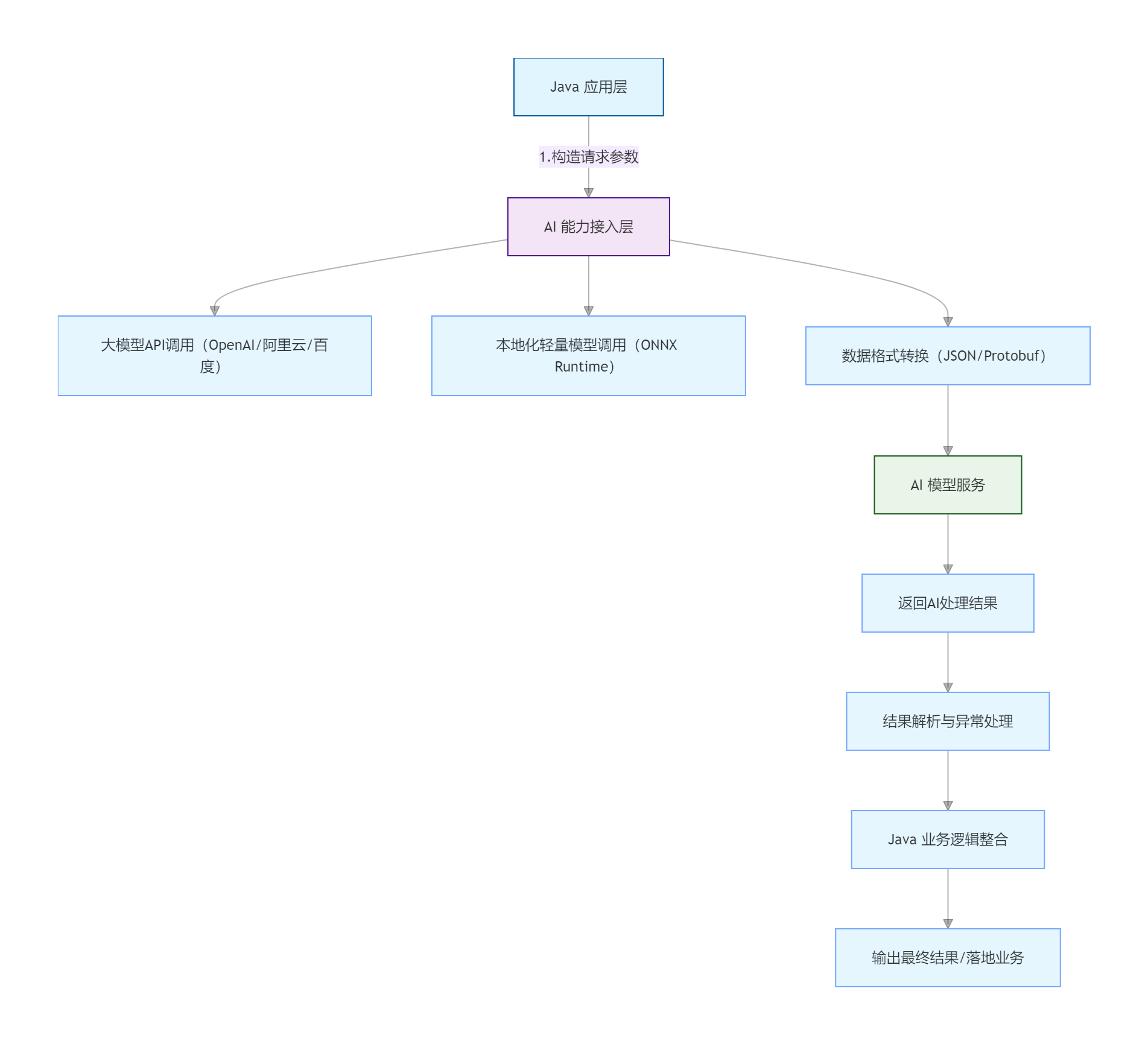
架构说明
Java 应用层:你熟悉的业务代码(Spring Boot/Spring Cloud),负责核心业务逻辑;
AI 能力接入层:Java 调用 AI 的核心桥梁(封装 API / 本地化调用工具);
AI 模型服务:可选「云端大模型 API」(低成本、免部署)或「本地化轻量模型」(隐私性高、无网络依赖);
数据转换 / 异常处理:解决 Java 与 AI 服务的数据格式适配、调用失败兜底问题。
二、落地步骤(保姆式操作)
步骤 1:环境准备(5 分钟搞定)
1.1 基础依赖(Maven/Gradle)
在你的 Java 项目(推荐 Spring Boot)中引入核心依赖,无需额外安装 Python 环境:
java
<!-- Spring Boot 基础(已有则忽略) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>3.2.0</version>
</dependency>
<!-- HTTP 客户端(调用 AI API) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webclient</artifactId>
<version>3.2.0</version>
</dependency>
<!-- JSON 解析(AI 数据交互) -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.15.2</version>
</dependency>
<!-- 本地化模型调用(可选) -->
<dependency>
<groupId>ai.onnxruntime</groupId>
<artifactId>onnxruntime</artifactId>
<version>1.16.3</version>
</dependency>
<!-- 工具类(简化开发) -->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.22</version>
</dependency>1.2 账号 / 工具准备(二选一)
方式 准备项 优势 成本
云端大模型 API 1. 注册阿里云百炼 / 百度文心一言 / OpenAI 账号;
- 获取 API Key/Secret 免部署、开箱即用、能力强 按量付费(低成本)
本地化轻量模型 1. 下载 ONNX 格式轻量模型(如 TinyLlama、BERT);
- 安装 ONNX Runtime 隐私性高、无网络依赖 免费(需本地算力)
步骤 2:核心实现(两种调用方式,优先选云端 API)
方式 1:调用云端大模型 API(最易落地,推荐)
以「阿里云百炼」为例(国内访问稳定,文档友好),实现 Java 调用 AI 生成代码 / 文本。
2.1.1 配置 API 密钥(application.yml)
java
aliyun:
dashscope:
api-key: 你的阿里云百炼API-Key # 从阿里云控制台获取
base-url: https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation2.1.2 封装 AI 调用工具类(可直接复制)
java
import cn.hutool.http.Header;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.http.MediaType;
import org.springframework.stereotype.Component;
import org.springframework.web.reactive.function.client.WebClient;
import java.util.HashMap;
import java.util.Map;
@Component
public class AIClient {
// 从配置文件读取API Key和地址
@Value("${aliyun.dashscope.api-key}")
private String apiKey;
@Value("${aliyun.dashscope.base-url}")
private String baseUrl;
// 核心方法:调用AI生成文本/代码
public String callAI(String prompt) {
try {
// 1. 构造AI请求参数(适配阿里云百炼格式)
Map<String, Object> requestBody = new HashMap<>();
requestBody.put("model", "qwen-turbo"); // 通义千问轻量版,免费额度足够
requestBody.put("input", Map.of("messages", new Object[]{
Map.of("role", "user", "content", prompt)
}));
requestBody.put("parameters", Map.of("result_format", "text"));
// 2. Java WebClient发送POST请求(非阻塞,适配高并发)
String response = WebClient.create(baseUrl)
.post()
.header(Header.AUTHORIZATION.getValue(), "Bearer " + apiKey)
.contentType(MediaType.APPLICATION_JSON)
.bodyValue(new ObjectMapper().writeValueAsString(requestBody))
.retrieve()
.bodyToMono(String.class)
.block(); // 同步调用(新手友好,高并发可改为异步)
// 3. 解析AI返回结果
Map<String, Object> resultMap = new ObjectMapper().readValue(response, Map.class);
Map<String, Object> output = (Map<String, Object>) resultMap.get("output");
return (String) output.get("text");
} catch (Exception e) {
// 异常兜底:调用失败返回默认提示
e.printStackTrace();
return "AI调用失败,请重试!";
}
}
}2.1.3 实战:Java + AI 生成业务代码
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class AICodeGeneratorController {
@Autowired
private AIClient aiClient;
// 示例:调用AI生成Java实体类代码
@GetMapping("/generate/java/entity")
public String generateEntity(@RequestParam String tableName) {
// 构造精准的prompt(关键:让AI输出符合Java规范的代码)
String prompt = "请基于Java 17,生成对应数据库表" + tableName + "的实体类,要求:\n" +
"1. 使用Lombok的@Data注解;\n" +
"2. 字段类型匹配MySQL常用类型;\n" +
"3. 包含无参/全参构造方法;\n" +
"4. 字段注释完整。";
// 调用AI生成代码
return aiClient.callAI(prompt);
}}
2.1.4 测试效果
启动 Spring Boot 项目后,访问:http://localhost:8080/generate/java/entity?tableName=user_info
AI 返回结果示例:
java
import lombok.Data;
import java.io.Serializable;
import java.util.Date;
/**
* 用户信息表实体类
* @author AI Generated
*/
@Data
public class UserInfo implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 主键ID
*/
private Long id;
/**
* 用户名
*/
private String username;
/**
* 密码(加密后)
*/
private String password;
/**
* 创建时间
*/
private Date createTime;
/**
* 更新时间
*/
private Date updateTime;
public UserInfo() {}
public UserInfo(Long id, String username, String password, Date createTime, Date updateTime) {
this.id = id;
this.username = username;
this.password = password;
this.createTime = createTime;
this.updateTime = updateTime;
}
}方式 2:本地化调用轻量 AI 模型(隐私敏感场景)
如果你的业务数据不能出内网,可通过 ONNX Runtime 在 Java 中调用本地化轻量模型(如 TinyLlama、BERT 文本分类模型)。

2.2.2 代码实现(文本分类示例)
java
import ai.onnxruntime.*;
import org.springframework.stereotype.Component;
import java.nio.FloatBuffer;
import java.util.Collections;
import java.util.Map;
@Component
public class LocalAIModelClient {
// 加载本地ONNX模型(以文本分类模型为例)
private OrtSession session;
// 初始化模型(项目启动时加载)
public LocalAIModelClient() {
try {
OrtEnvironment env = OrtEnvironment.getEnvironment();
// 模型文件路径(替换为你的本地模型路径)
String modelPath = "D:/ai_models/text_classification.onnx";
session = env.createSession(modelPath, new OrtSession.SessionOptions());
} catch (OrtException e) {
e.printStackTrace();
}
// 本地化AI文本分类
public String classifyText(String text) {
try {
// 1. 文本转张量(需提前做分词处理,这里简化示例)
float[] textTensorData = preprocessText(text); // 分词/编码逻辑需适配模型
OnnxTensor inputTensor = OnnxTensor.createTensor(
OrtEnvironment.getEnvironment(),
FloatBuffer.wrap(textTensorData),
new long[]{1, textTensorData.length}
);
// 2. 运行模型推理
Map<String, OnnxTensor> inputs = Collections.singletonMap("input", inputTensor);
OrtSession.Result result = session.run(inputs);
// 3. 解析输出
float[] output = ((float[][]) result.get(0).getValue())[0];
return getCategoryByScore(output); // 根据得分映射分类结果
} catch (Exception e) {
e.printStackTrace();
return "分类失败";
}
}
// 文本预处理(需适配具体模型,如BERT分词)
private float[] preprocessText(String text) {
// 实际项目中需集成分词库(如HanLP),此处简化返回示例数据
return new float[]{0.1f, 0.2f, 0.3f};
}
// 得分转分类
private String getCategoryByScore(float[] scores) {
// 示例:0=正面 1=负面 2=中性
int maxIndex = 0;
float maxScore = scores[0];
for (int i = 1; i < scores.length; i++) {
if (scores[i] > maxScore) {
maxScore = scores[i];
maxIndex = i;
}
}
return switch (maxIndex) {
case 0 -> "正面";
case 1 -> "负面";
case 2 -> "中性";
default -> "未知";
};
}
}步骤 3:进阶优化(生产环境落地)
3.1 高并发优化
将同步调用(block())改为异步调用(Mono/Flux),避免线程阻塞;
增加请求限流(Spring Cloud Gateway/Sentinel),防止 AI API 调用超限;
增加本地缓存:对重复的 prompt 请求结果缓存(如 Caffeine),减少 AI 调用次数。
3.2 异常兜底
java
// 在AIClient中增加降级逻辑
public String callAI(String prompt) {
try {
// 原有调用逻辑
} catch (Exception e) {
// 降级策略:返回默认模板/调用备用AI接口
return fallbackGenerate(prompt);
}
}
// 降级方法:AI调用失败时返回基础模板
private String fallbackGenerate(String prompt) {
if (prompt.contains("entity")) {
return "public class DefaultEntity {}\n"; // 默认实体类模板
}
return "生成失败,请稍后重试";
}3.3 成本控制(云端 API)
对 prompt 做精简,减少无效字符,降低 token 消耗;
对接 AI 服务商的用量监控 API,在 Java 中增加用量告警;
批量请求合并:将多个小 prompt 合并为一个请求,减少调用次数。
三、常见场景落地清单
业务场景 实现方式 核心价值
代码生成(实体 / 接口 / 测试用例) Java 调用云端大模型 API 提升开发效率,减少重复编码
智能客服 / 文本回复 Java + AI 文本生成 + 知识库检索 替代人工回复,降低运维成本
日志分析 / 异常诊断 Java 解析日志 + AI 分类 / 根因分析 快速定位线上问题
数据脱敏 / 格式转换 Java 预处理数据 + AI 智能脱敏 符合合规要求,减少开发量
图片 OCR 识别 Java 调用 OCR API + AI 文本解析 提取图片中的结构化数据
四、图解整体落地流程(全链路)
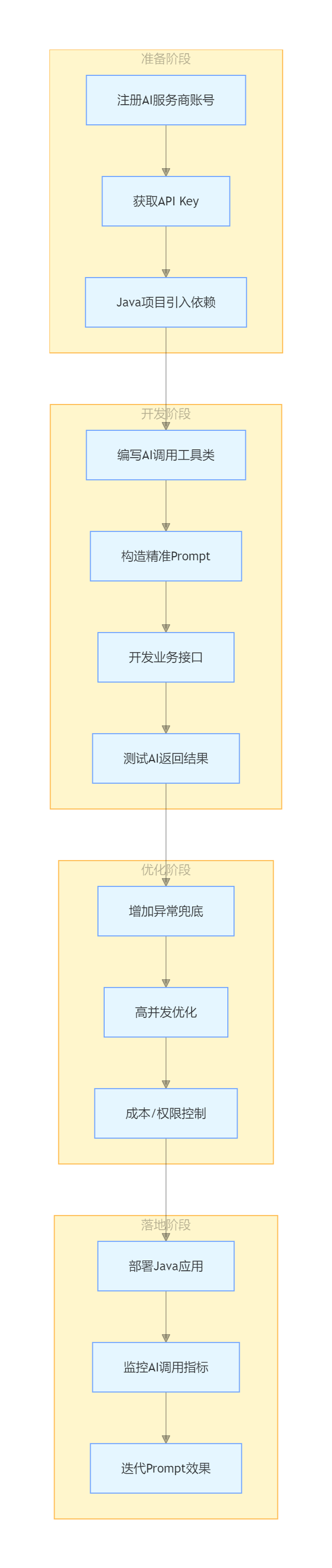
总结
核心路径:Java 无需学习 Python,通过「调用云端 AI API(低成本)」或「本地化 ONNX 模型(高隐私)」即可实现 AI 混合编程;
落地关键:封装通用 AI 调用工具类 + 构造精准 Prompt(决定 AI 输出质量) + 增加异常兜底;
场景优先:先从代码生成、文本处理等轻量场景落地,验证效果后再扩展到核心业务。
这份方案所有代码均可直接复制运行,只需替换 API Key / 模型路径即可落地,完全基于你熟悉的 Java 技术栈,零 Python 学习成本。