1)是什么
✅ RNN(循环神经网络)
- 是一种专门用于处理序列数据的神经网络。
- 核心思想:在时间上重复使用同一个网络单元,并把前一时刻的状态传递给下一时刻。
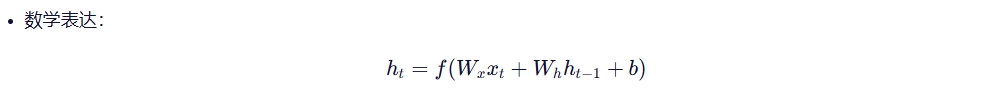
- 输出可为每个时间步(many-to-many),或最终状态(many-to-one)
🧠 类比:像一个边读书边记笔记的学生,每读一句就更新自己的理解。
✅ LSTM(长短期记忆网络)
- 为解决 RNN 的"长期依赖"问题而设计。
-引入门控机制控制信息流动:- 遗忘门(Forget Gate)→ 决定丢弃哪些旧记忆
- 输入门(Input Gate)→ 决定写入哪些新信息
- 输出门(Output Gate)→ 控制输出内容
- 维护一个细胞状态(Cell State) 作为长期记忆主干
🧠 类比:像一个有条理的档案管理员,知道什么该存、什么该删、什么该拿出来用。
✅ GRU(门控循环单元)
- LSTM 的简化版本,只有两个门:
- 重置门(Reset Gate)→ 决定是否忽略过去状态
- 更新门(Update Gate)→ 决定新旧状态如何融合
- 参数更少,训练更快,在中等长度序列上表现接近 LSTM
🧠 类比:高效实习生------不搞复杂流程,但能抓住重点完成任务。
2)为什么
❓ 为什么要用 RNN?
- 因为自然语言是有序列结构的:词序影响语义。
- 传统神经网络(如 CNN)无法直接建模时序依赖。
- RNN 能通过隐藏状态实现对历史信息的记忆。
🎯 举个例子:
"The cat sat on the mat."
如果只看最后一个词 "mat",你不知道它指什么;但 RNN 记住了前面的 "cat" 和 "sat",就能正确理解。
❓ 为什么要用 LSTM/GRU?
- 因为普通 RNN 存在梯度消失/爆炸问题,难以学习长期依赖。
- 比如:"The keys to the cabinet were lost."
主语是复数 "keys",动词应为 "were"。但如果中间插入很多修饰语,RNN 很可能忘了主语是什么。 - LSTM/GRU 通过门控机制解决了这个问题,让模型能记住很久以前的信息。
💡 关键突破:从"被动记忆"到"主动管理记忆"。
3)什么时候用
| 场景 | 推荐模型 | 原因 |
|---|---|---|
| 短文本分类(如情感分析、人名国籍识别) | RNN / GRU | 数据简单,计算资源有限 |
| 语音识别、手写识别 | LSTM | 需要捕捉长时间依赖关系 |
| 机器翻译、摘要生成 | Seq2Seq + LSTM/GRU | 需要编码-解码架构 |
| 时间序列预测(如股价、天气) | LSTM/GRU | 序列数据常见,需记忆趋势 |
| 快速原型开发 | GRU | 结构简单,训练快 |
🔍 特别提示:对于长文本任务(如文档级问答、长对话),LSTM/GRU 仍可用,但 Transformer 更优。
4)什么时候不用
| 场景 | 原因 | 替代方案 |
|---|---|---|
| 超长序列(> 1000 tokens) | 注意力机制效率更高,RNN 时间复杂度 O(n) | Transformer |
| 并行化要求高 | RNN 是串行计算,无法并行处理序列 | Transformer(自注意力可并行) |
| 需要全局依赖建模 | RNN 只能逐步传播信息,难以捕捉远距离依赖 | Transformer + Attention |
| 实时性要求极高(如语音流式处理) | RNN 推理慢,延迟高 | 用轻量级模型(如 TinyBERT)、流式 Transformer |
| 大规模预训练任务(如 BERT、GPT) | RNN 架构不适合海量参数训练 | Transformer 成为主流 |
⚠️ 尽管如此,RNN 在某些嵌入式设备或低功耗场景仍有应用价值。
5)总结
| 模型 | 优点 | 缺点 | 适用范围 |
|---|---|---|---|
| RNN | 简单直观,适合短序列 | 梯度消失,难学长期依赖 | 简单 NLP 任务 |
| LSTM | 记忆能力强,适合长序列 | 结构复杂,训练慢 | 语音、翻译、时间序列 |
| GRU | 简洁高效,训练快 | 稍弱于 LSTM | 快速原型、移动端 |
✅ 核心结论:
- RNN 是 NLP 的"起点",教会我们如何处理序列。
- LSTM/GRU 是"进化版",解决了长期依赖问题。
- 但随着 Transformer 的崛起,RNN 已不再是主流架构。
- 现在更多用于教学、理解序列建模思想,或特定小规模任务。
🧩 所以说:RNN 是"过去",LSTM 是"过渡",Transformer 是"未来"
概念
1. RNN模型
RNN模型会逐个读取句子中的词语,并且在每一步结合当前词和前面的上下文信息,不断更新对句子的理解。通过这种机制,RNN能够持续建模上下文,从而更加准确地把握句子的整体语义。
1.1 基础结构
RNN的核心结构是一个具有循环链接的隐藏层 ,它以时间步 为单位,依次处理输入序列中的每个token
在每个时间步,RNN接受当前token的向量和上一个时间步的隐藏状态,计算并且生成新的隐藏状态,并且将其传递给下一个时间步
1.2 多层结构
为了让模型捕捉更复杂的语言特征,通常将多个RNN层进行堆叠串联,使不同层学习到不同的语义信息。
多层的设计思想是:层数低更容易捕捉到具体的信息(词组、短语),而层数高则更能捕捉到较为抽象的语义信息(句子的情感和语境)
多层RNN网络结构中,每一层的输出序列会作为下一层的输入序列,最底层的RNN接受原始输入序列,顶层的RNN输出作为最终结果用于后续业务处理
1.3 双向结构
基础结构在每个时间步只能输出一个隐藏状态,该状态仅仅包含了来自上文的信息,而无法利用当前词的下文信息
由此引入双向RNN模型,它可以在每个时间步同时利用上下文的信息,从而获得更加全面的上下文表示,更加利于提升序列标注等任务的预测结果
1.4 多层 + 双向结构
这个组合表示的是每一层都是一个双向的RNN,通常通过控制bidirectional=True 来开启双向。这个参数在 1.5标题可以找到
1.5 API回顾
方法
torch.nn.RNN
torch.nn.LSTM
torch.nn.GRU
参数
input_size (必需)
含义:输入特征维度
示例:对于词嵌入维度为100的文本输入,input_size=100
作用:指定每个时间步输入向量的长度
hidden_size (必需)
含义:隐藏状态特征维度
示例:hidden_size=256
作用:决定RNN的记忆容量,也是输出向量的维度
注意:过小会导致信息丢失,过大会增加计算成本
num_layers (默认:1)
含义:RNN层数
示例:num_layers=3
作用:创建堆叠RNN,深层网络可提取更高级特征
注意:深层RNN需要更多训练数据,可能产生梯度问题
nonlinearity (默认:'tanh')
可选项:
'tanh':双曲正切函数,输出范围-1, 1
'relu':修正线性单元,输出范围[0, +∞)
选择建议:
tanh:适合多数序列建模任务
relu:可缓解梯度消失,但需注意初始化
batch_first (默认:False)
含义:控制输入/输出张量的维度顺序
batch_first=False (PyTorch默认):
输入形状:(seq_len, batch_size, input_size)
输出形状:(seq_len, batch_size, hidden_size)
batch_first=True:
输入形状:(batch_size, seq_len, input_size)
输出形状:(batch_size, seq_len, hidden_size)
bidirectional (默认:False)
含义:是否使用双向RNN
单向RNN:只考虑历史信息
双向RNN:同时考虑历史和未来信息
输出维度:双向时,输出特征维度为 hidden_size * 2
适用场景:需要上下文信息的任务(如机器翻译、命名实体识别)
2. 传统RNN模型
RNN单元
3. LSTM模型 -- 带门的"记忆宫殿"
为了治这个"健忘症",1997年提出了 LSTM(Long Short-Term Memory)
🎯 核心思想:用"门"控制信息流,决定哪些记忆保留、哪些丢弃。
LSTM 有三个关键"门":
| 门 | 功能 |
|---|---|
| 遗忘门 | 决定丢掉旧记忆的多少 |
| 输入门 | 决定新信息如何写入记忆 |
| 输出门 | 决定当前输出什么 |
🧠 生动化比喻:
LSTM 就像一个"智能日记本":
- 你每天写日记(输入)
- 它自动决定哪些内容该删(遗忘门),哪些该重点记录(输入门)
- 回答问题时,只翻阅最相关的那几页(输出门)
✅ 效果:能记住很久以前的信息,适合处理长文本!
3.1 阿达玛积(Hadamard Product)

同维度是进行**矩阵加法、减法、Hadamard积(逐元素乘积)**的前提条件。
python
import numpy as np
# 或 torch / tensorflow
A = np.array([[1, 2], [3, 4]])
B = np.array([[0, 5], [2, 1]])
C = A * B # ← 这就是阿达玛积!
# C = [[0, 10],
# [6, 4]]✅ 在 NumPy / PyTorch / TensorFlow 中,* 默认执行逐元素乘 → 即阿达玛积
❗ 矩阵乘法需用 @、np.dot() 或 torch.matmul()
🧠 直观理解
阿达玛积不是"混合信息",而是"局部调光开关":
- 把一个矩阵当作内容(如图像、记忆),
- 另一个当作控制信号(如门、注意力权重),
- 相乘后实现按位置调节强度。
阿达玛积和矩阵乘法的本质区别:
- 阿达玛积:局部操作 ------ 两个矩阵"对位相乘",不混合不同位置的信息。
- 矩阵乘法:全局交互 ------ 行与列做点积,实现信息的跨位置融合与变换。
计算方式对比

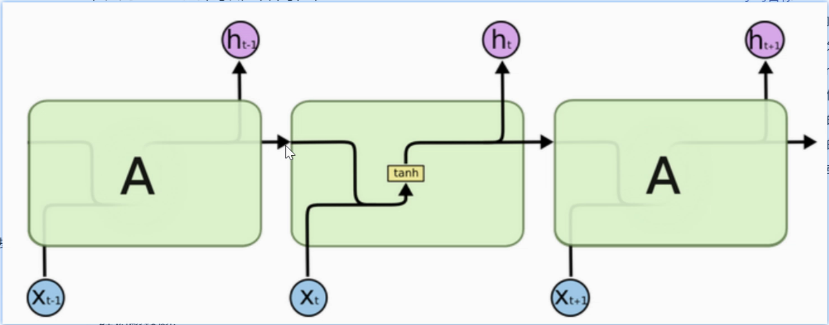
3.2 门结构(阀门)
- "门"是一种可学习的控制机制 ,用于决定在某一时刻保留多少旧信息、更新多少新信息、输出多少当前状态。
- 它的核心是 sigmoid 激活函数,配合逐元素乘法(Hadamard product)实现对信息流的精细调控。
sigmoid 门的作用:
- 输出一个 (0,1) 之间的值,代表"开放程度"
- 输出值 ≈ 0:门基本关闭,信息被阻断(抑制)
- 输出值 ≈ 1:门完全打开,信息自由通过(允许)
- 它本身不改变向量大小,而是作为一个"权重"去乘上某个向量,从而按比例保留或屏蔽信息
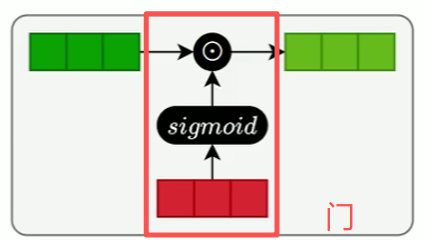
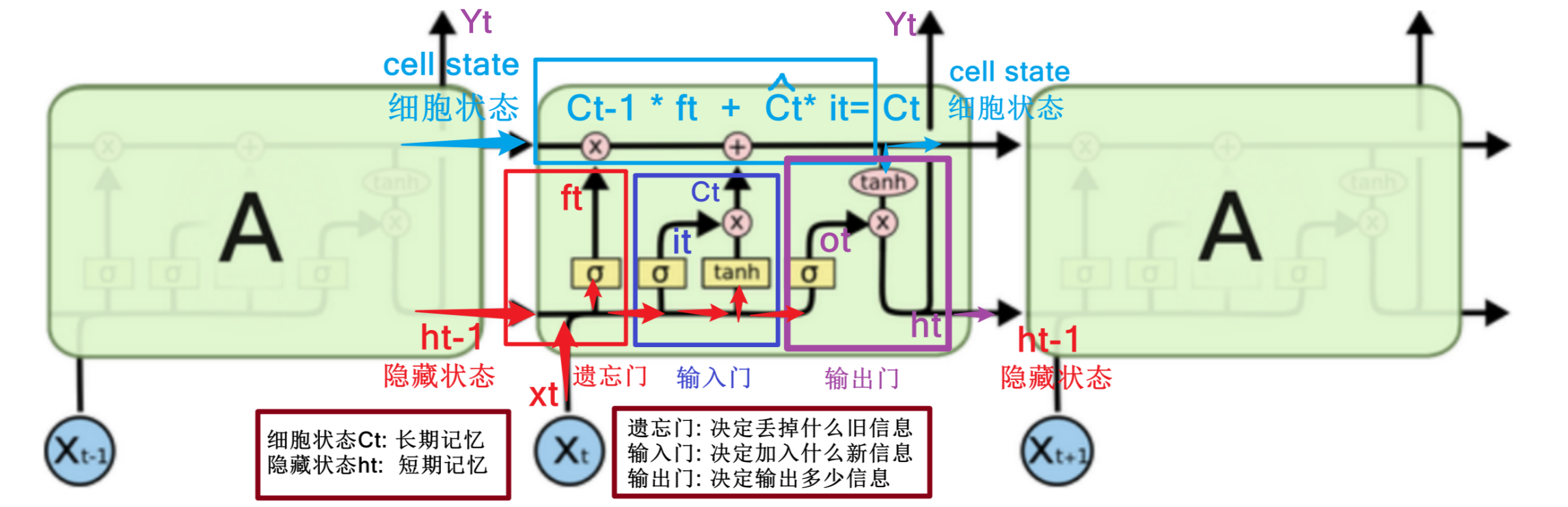
3.3 记忆单元(Memory Cell)
记忆单元负责在序列中长期保存关键信息。它相当于一条"信息通道",在多个时间步之间直接传递信息(记忆单元是缓解梯度消失和梯度爆炸问题的核心),而负责保存短期记忆的就是隐藏状态
记忆单元是 LSTM(长短期记忆网络)的核心组件,其主要功能是在序列处理过程中长期保存关键信息,并允许信息在多个时间步之间稳定地流动。
核心结构
记忆单元由以下部分构成:
- 细胞状态(Cell State):一条贯穿时间的"信息通道",用于存储长期依赖信息,通常用c进行表示。
- 三个门控机制 :
- 遗忘门(Forget Gate):决定哪些旧信息从Ct中丢弃。
- 输入门(Input Gate):决定哪些新信息将被加入到 Ct。
- 输出门(Output Gate) :决定 Ct的哪些部分将输出为隐藏状态 ht。
- 细胞状态 c_t 在时间步间直接传递(如图中橙色水平线所示),不受激活函数压缩影响,因此能有效缓解梯度消失/爆炸问题
- 信息通过门控机制进行精细调控,实现对历史信息的"选择性记忆"
- 隐藏状态 h_t 是基于 c_t 和当前输入计算出的输出,反映当前时刻的"短期上下文"
3.4 遗忘门
遗忘门是 LSTM 中用于决定哪些信息应该从细胞状态中丢弃 的关键组件。
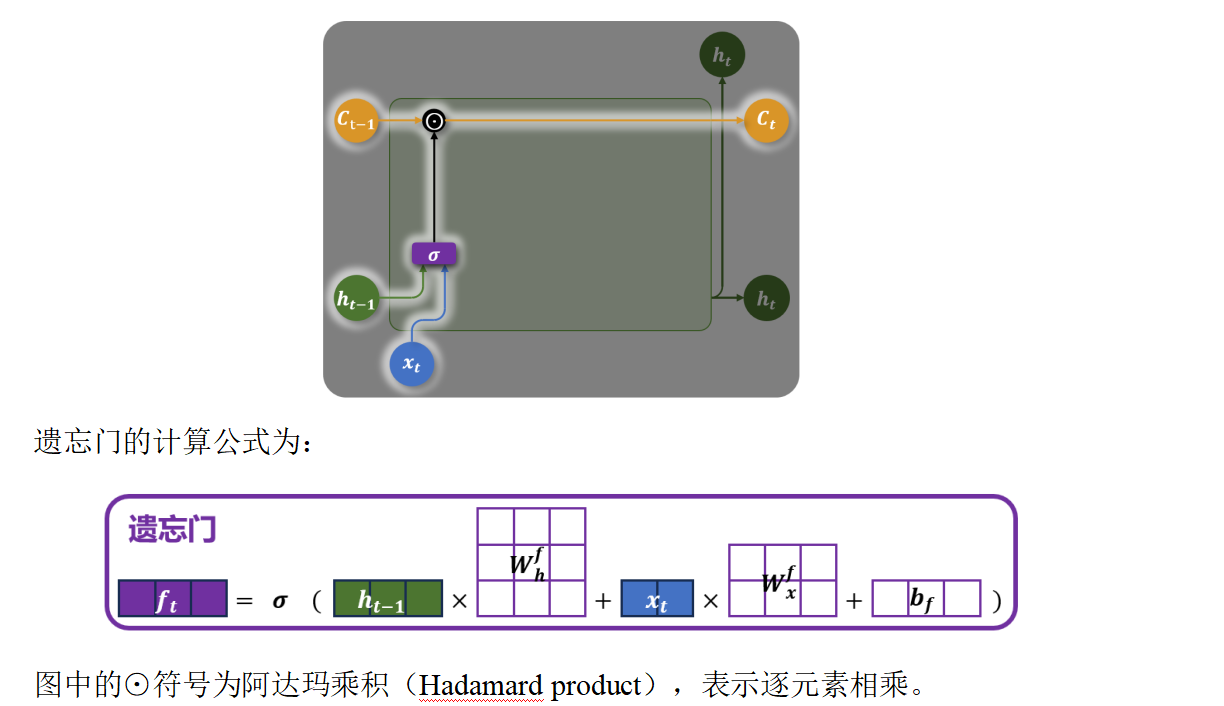
- 控制前一时刻的细胞状态 c_{t-1} 有多少信息被保留。
- 通过一个 sigmoid 激活函数输出一个介于 0 到 1 之间的值:
- 接近 0:表示"完全遗忘"该部分信息;
- 接近 1:表示"完全保留"该部分信息。

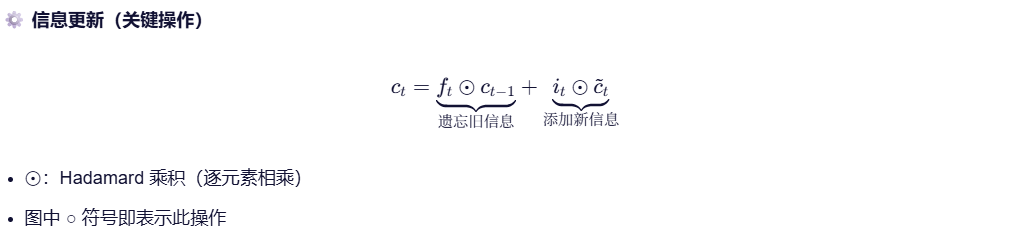

💡 核心思想:不是硬删除,而是用"软权重"控制记忆衰减,从而实现长期依赖建模。
3.5 输入门

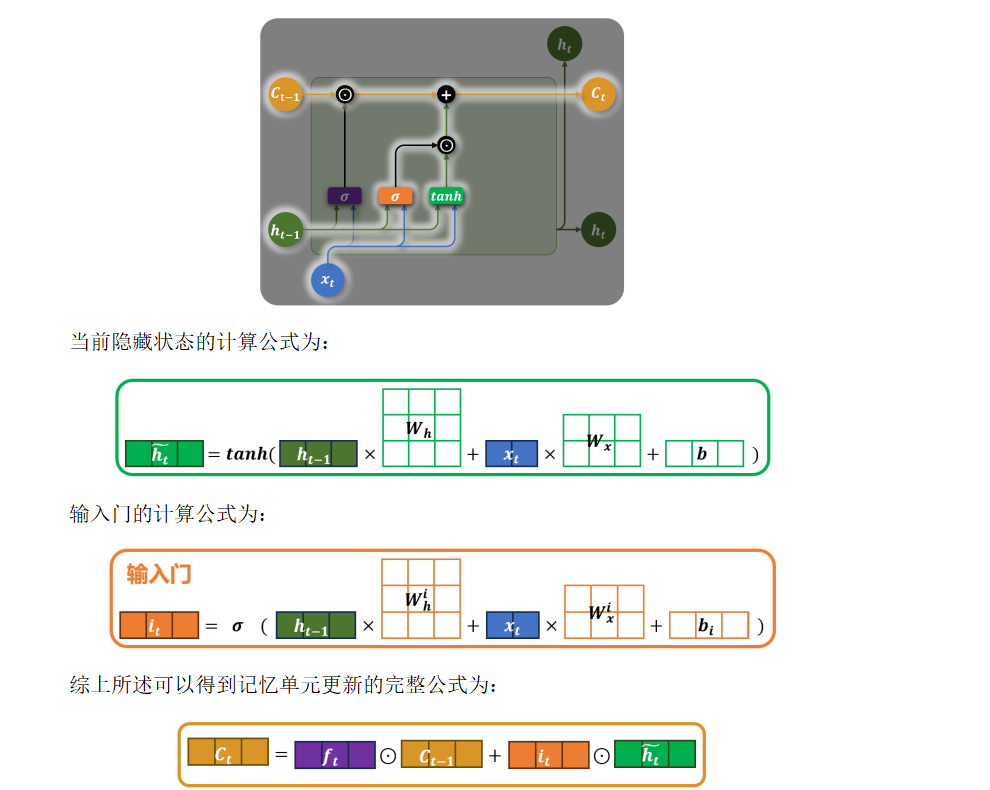



💡 核心思想:通过输入门和候选记忆单元的协同工作,实现对细胞状态的选择性更新。输入门决定哪些部分应该被更新,而候选记忆单元提供新的候选信息来替换旧的信息。
3.6 输出门

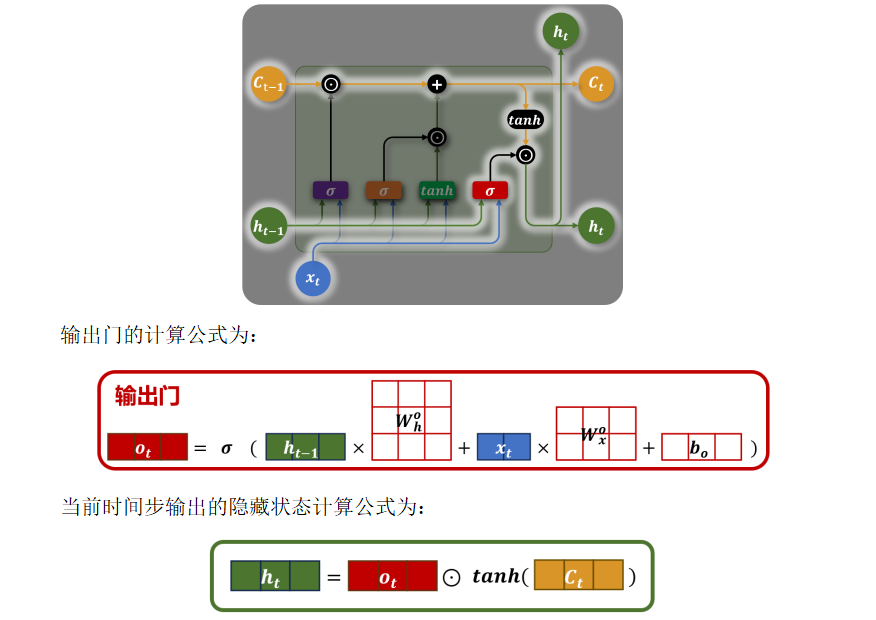




💡 核心思想:
输出门不直接暴露原始细胞状态,而是通过一个"可控滤镜"决定哪些长期记忆对当前任务有用,从而实现有选择地表达记忆。
3.7 总体流程图
3.1 Bi - LSTM
...
4. GRU模型
GRU(Gated Recurrent Unit)是 LSTM 的"轻量级兄弟",结构更简单,但效果接近。
它把 LSTM 的三个门合并成两个:
- 更新门:决定保留多少旧状态 + 加入多少新信息
- 重置门 :决定是否忽略之前的隐藏状态
🧠 生动化比喻:
GRU 就像是一个"极简主义作家",不搞复杂结构,直接说:"我只要记住重要的事,其他都扔掉。"
⚡ 优点:训练快、参数少,适合资源有限场景。
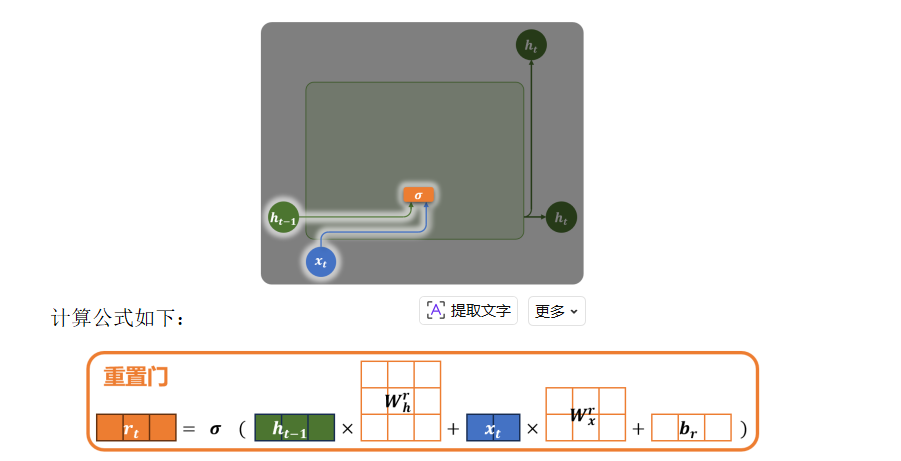
4.1 重置门

💡 相当于决定"是否忽略过去的信息来计算新状态"。
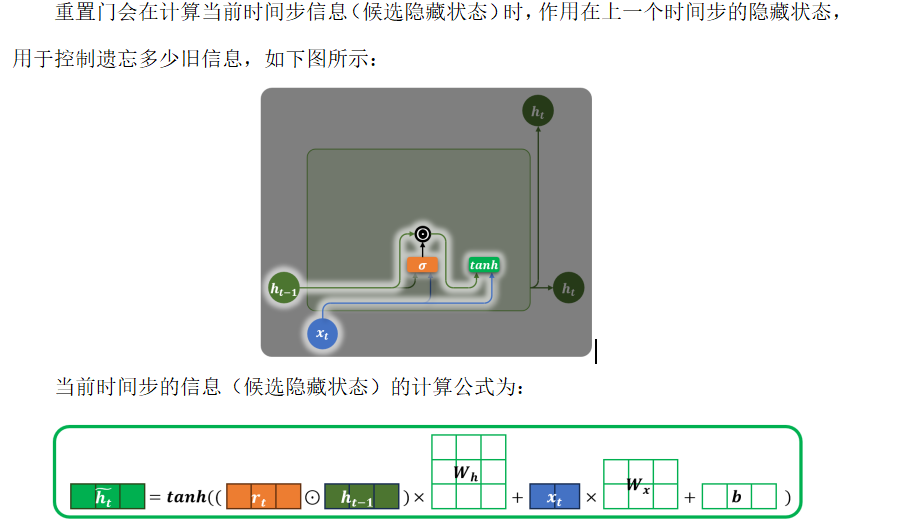


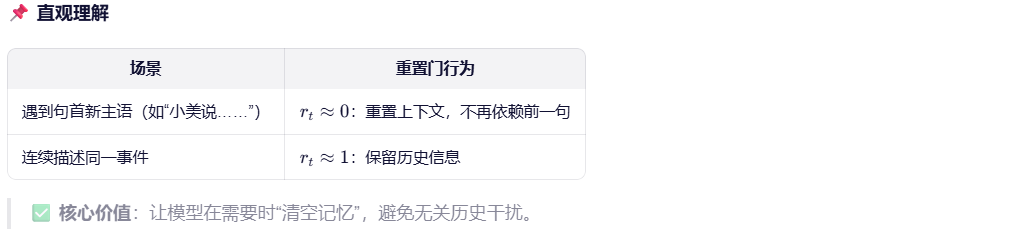
4.2 更新门

💡 类比:像一个"记忆滑动条"------
滑向 0 → 完全保留旧状态(忽略新输入)
滑向 1 → 完全用新候选状态更新(遗忘过去)
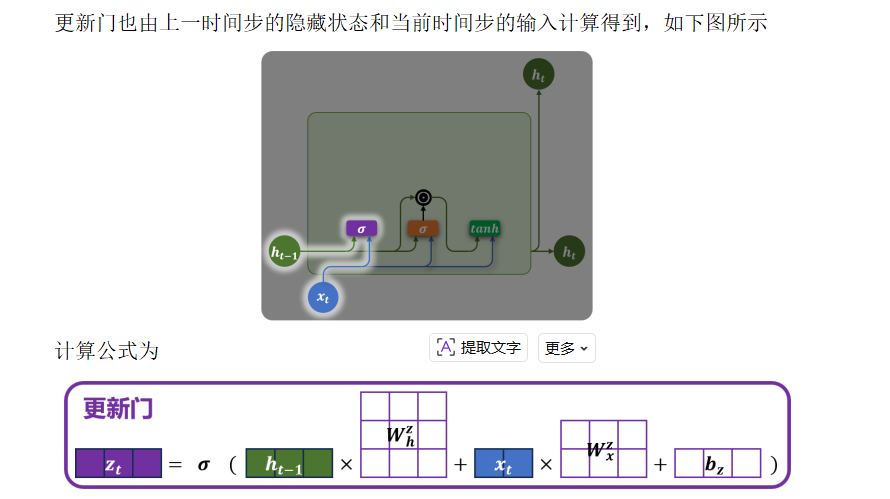
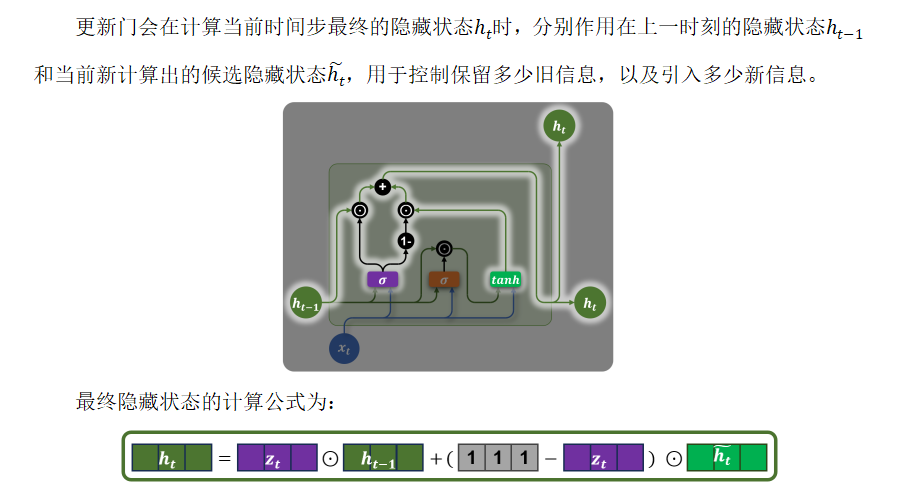
🔢 计算公式

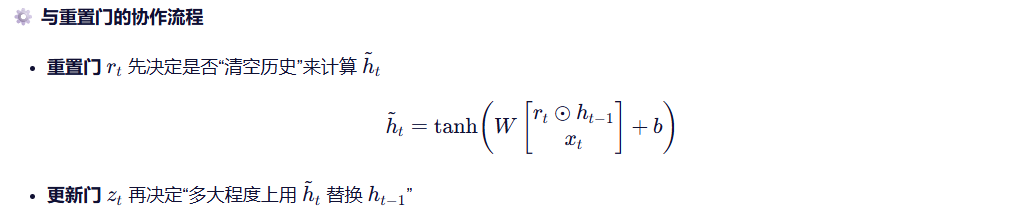

4.3 总体流程图
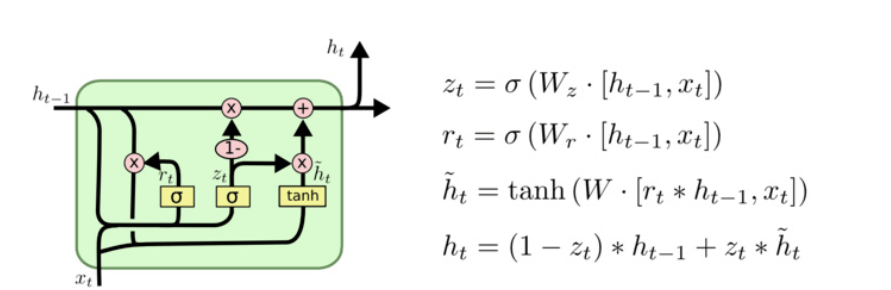
4.3 Bi - GRU
...