最近我跳槽了,虽然我进了新公司,从原先公司(滨江某安防公司)离职了,但是我个人认为还是要好好的对之前的工作做一个总结,以避免自己在未来再犯同样的错误,以下是我整理的几个在线上的时候遇到的问题与解决,包含背景、分析、解决、规避方案等方面。
很多时候,那种可以预见到的问题,最好不要犯两次,一个可以预见的问题犯两次,可能领导不会说,但是实际上第二次就属于低级错误了,避免的方式就是第一次排查的时候就发现根因问题,并通过提升能力,固化流程等方式解决。这些是我遇到的问题以及解决思路,如果有更好的欢迎讨论,不吝赐教。
第一部分主要用于展示云存储业务产生的线上问题以及解决
1、云存储业务经常出现拒绝策略问题
背景
如图所示,我们这边会有云存储(cloud storage)业务,设备会把资源上报到上报到存储桶里,我们这边也会有对应的微服务队设备的云存储功能进行编排,以下是这个系统大概的一个流程。
可以看到,只有几块流程需要对通过线程池进行操作:比如对设备云存储套餐进行续费、关闭、开通、下发token(因和网页cookie一样,过期即失效,所以需要定时下发),但是随着业务量的增加,线程池经常触发拒绝策略
虽然拒绝策略是CallersRunPolicy,但是对于运维,系统稳定性是一个痛点(当然如果任务量超过线程池量,我们的池化策略会失效,同时业务稳定性肯定有影响)
同时如果更新线程池参数,但是因为没有对应API更新线程池参数,导致还需要重启服务才能生效,不合理
调试验证的周期延长了,因为修改文件,重启服务都是线上操作,需要走流程
根因分析
目前缺少一个合适的方式对线程池进行监控,运维,编排,并且这个也是其他的组会遇到的问题,其他的组没有对应的解决方案,我这边便通过引入动态线程池(Dynamic-TP)解决了这个问题。对应的一些文章为已经写过了,我把文章内容在这里
后续维护
生成动态线程池Util包进行接入使用
对于重要业务进行线程池更新,对于其他新增非网关类pod也使用线程池,也通过私有仓库的二开dynamic-tp动态线程池包进行开发
2、云存储业务线程池资源一直增加问题
背景
在接入动态线程池动之后,我们后续的业务也遇到了问题,线上其中一个环境中。
-
当前的线程池告警持续触发拒绝策略(调度线程处理任务),增加资源量快于业务增长量,导致运维要求我们进行排查
-
线程池资源告警则增加资源,环境中云存储微服务已经增加到了6台,但是仍然线程的队列容量稳步上升,增加资源并不能解决问题
-
因为任务队列容量较多,导致大量云存储设备下发云存储都是在初始化的5-6h以后了,涉及设备面广,影响较大
根因分析
-
使用 jstack 1查看当前的线程池开头的线程状态与堆栈
-
发现初始化任务的线程池的线程状态都是WATING状态,这个是Java线程主动挂起等待的状态。
查看堆栈,都是在等待Redisson的锁释放
-
查看了下对应线程池设计的流程,发现在下发license时确实会通过lock方法加锁
-
查看 云存储的 日志,发现同一台设备在日志中频繁向设备下发初始化,10s一次,正常流程应当至少2min才初始化下发一次
所以我怀疑是代码问题+设备问题,导致的线程池资源占用。具体的问题原因可能如下
除了使用lock方式永久等待,redisson看门狗给错误的key进行续期也是个问题。
解决方式
-
不能使用lock方法而是tryLock,等待一段时间后释放掉锁;一般会有重试机制,redisson锁一般是800ms以内,足够调用侧接收到异常并重试了
-
删除对应占用资源的redisson锁
-
排查redisson锁机制,避免出现重启仍然续期的问题。
3、分库分表定时任务OOM问题
背景
还是云存储,某个环境中云存储服务一直不健康;原因是pod.yml中没有配置liveness,导致服务没有被容器重启;
随后查看日志发现服务触发了OOM异常。
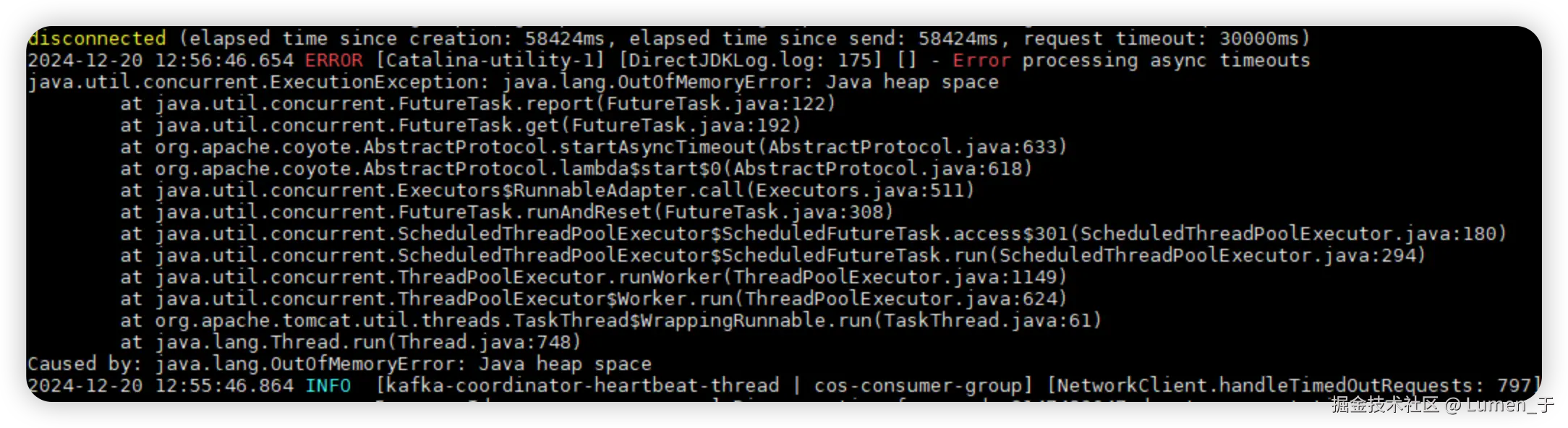
根因分析
使用jmap命令(jmap -dump:format=b,file=heapdump.hprof 1)打印出服务的内存dump文件;
使用MemoryAnalyzer分析dump文件;
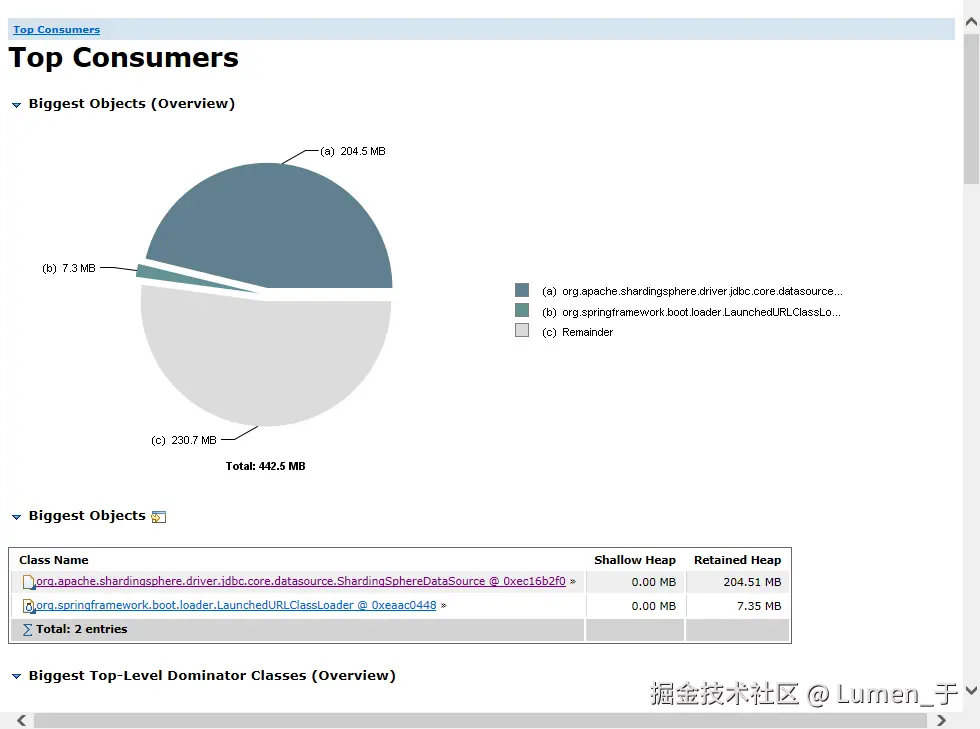
发现大对象是ShardingSphereDataSource,查看这个对象的外引用发现是数据库表实例;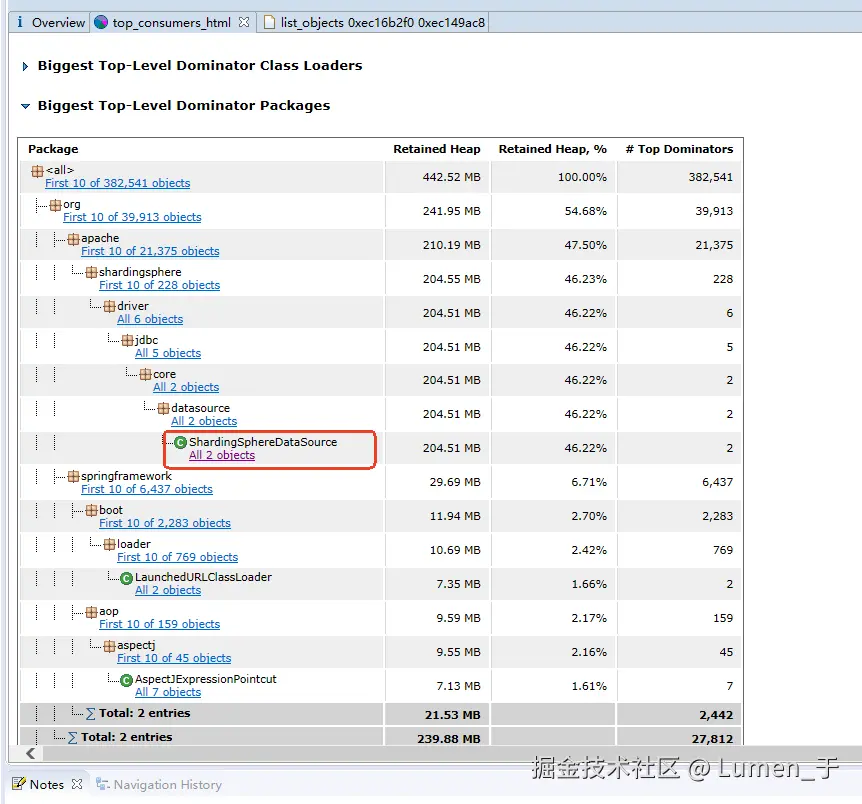
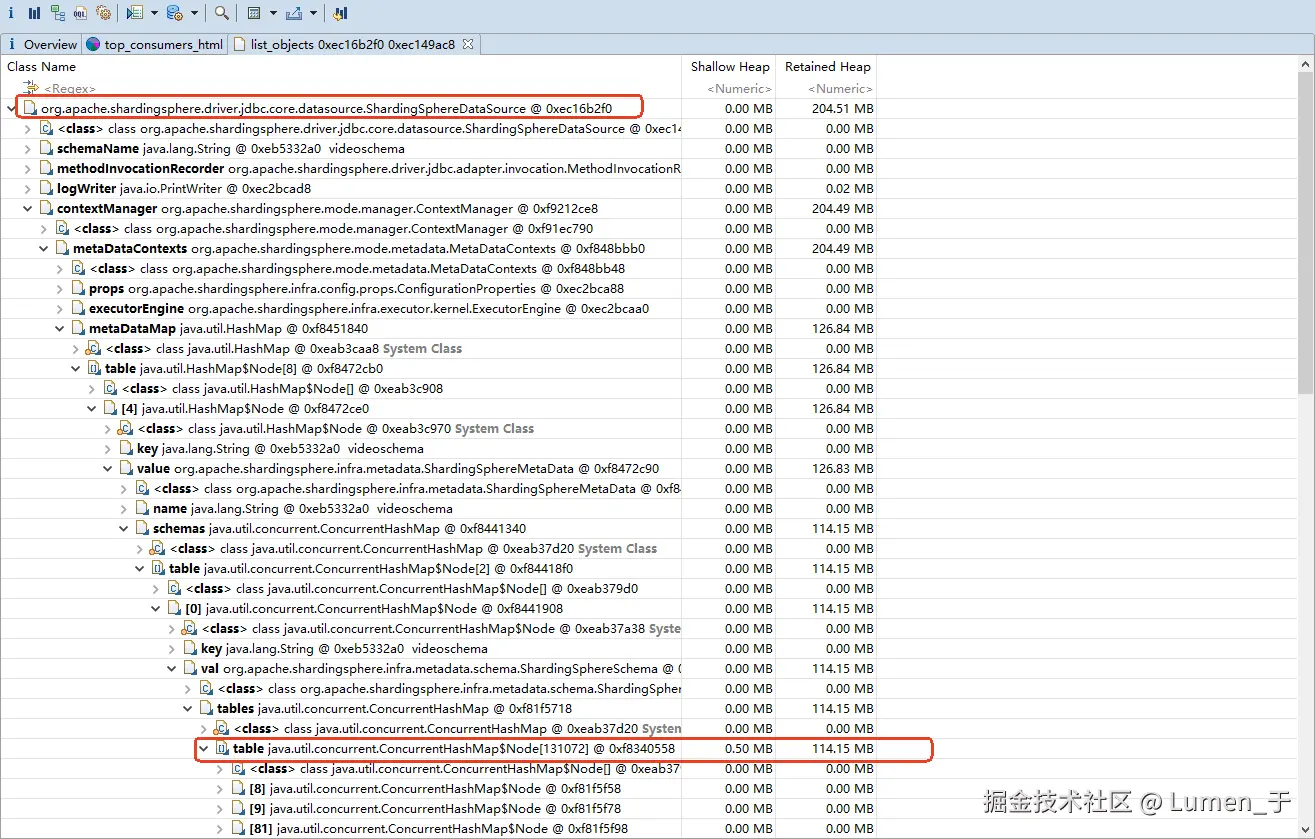
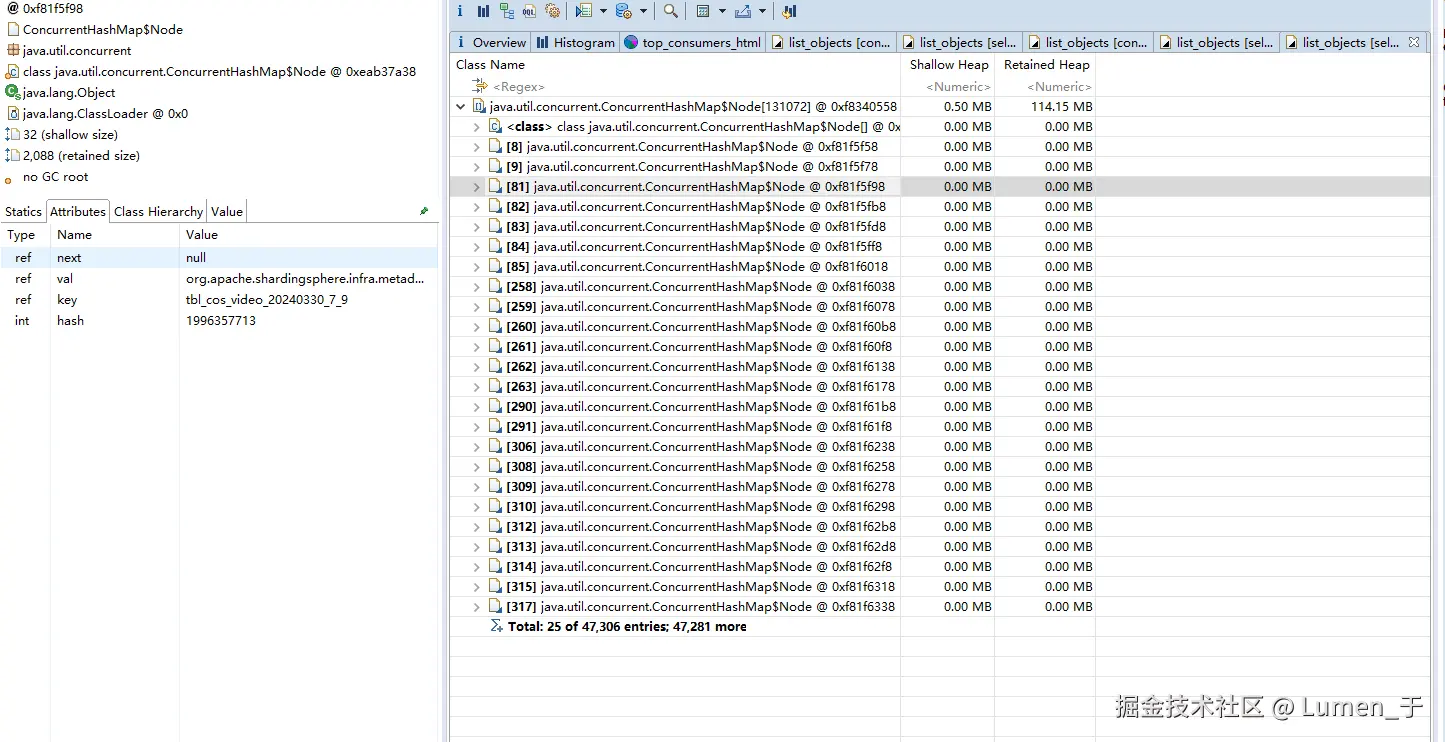
最终发现table元数据存在47256个结点;查看node中的value发现数据是表名,但是环境内的表最多存在5632张表,很明显47256是异常的;
应该是环境内每日清理过期表的任务执行失败或者没有执行导致的;
解决方案
- 定时任务删除失败,并且没有记录,导致后续定时任务删除时,一次性获取过多的shardingJDBC导致问题,失败的定时任务需要及时通知开发人员进行介入