在大模型狂飙突进的今天,高质量、结构化的数据已成为决定 AI 能力的核心基建。而现实中,海量知识却沉睡在PDF、扫描件、报告等非结构化文档中。
如何将这座富矿高效、精准地转化为大模型可理解、可训练的数据燃料,是整个产业面临的关键瓶颈。
OCR(光学字符识别)技术正是打通这一瓶颈的数据管道。但传统OCR主要停留在「字符识别」层面,面对包含图表、公式、代码以及复杂版式的文档时,往往会产出混乱的文本流,难以支撑后续理解、检索等等需求。
因此,在大模型时代,这一能力已远远不够。一个真正可用的文档解析方案,必须提供端到端的文档智能解析能力:不仅「看得准」,更要「懂得清」。
它需要在识别文本的同时,理解文档的语义结构和版式逻辑,将原始文档精准还原为包含标题、段落、表格、图表描述、公式 LaTeX、代码块等语义信息的标准化表示形式(如 Markdown / JSON)。
只有当非结构化文档被转化为高质量、可直接消费的结构化数据,才能真正成为大模型训练、知识库构建、RAG 检索与智能问答中的可靠数据原料,从而发挥它应有的价值。
今天,这个关键的「数据管道」迎来了它里程碑式产品化升级------PaddleOCR 官网(www.paddleocr.com)正式版上线了!
这不仅是其强大开源能力的直观展现,更通过丝滑的体验与海量API,将文档结构化能力推向了普惠化应用。
熟悉我的老粉都知道,过去如果我要推荐 OCR 或文档解析工具,基本只会提到 PaddleOCR。原因很简单:我希望为大家提供一条最高效、最直接的"生产力路径",而不是让大家在众多项目中反复试错。
这不仅是我的推荐逻辑,也是各大模型厂商在开源选型时的共识------PaddleOCR 几乎是文档解析领域唯一被广泛引用的开源方案。
今年 10 月 17 日 PaddleOCR-VL 刚刚发布,仅用 16 小时就登顶 HuggingFace Trending 全球榜首。
短短两个月内,项目的 Star 数从 57k 飙升至接近 67k。要知道,一个开源项目在五年之后还能保持这样的增长速度,背后一定是它切中了真实且迫切的用户需求。
01、关键特性:三大模型,覆盖全场景文档解析
打开官网,你会看到三个核心入口:GitHub 开源地址、MCP 接口、API 接口。下方支持直接上传图像或 PDF,体验 PaddleOCR 的三大模型方案:
- PP-OCRv5:轻量级 OCR,适合纯文本提取
- PP-StructureV3:基于pipeline架构的文档解析,支持印章、表格、标题等还原,零幻觉
- PaddleOCR-VL(默认):基于视觉-语言模型的文档解析,支持图文、公式、代码等多模态解析,当前全球最高精度
如果你还不清楚这些模型能力的区别,PaddleOCR 官方文档(www.paddleocr.ai)提供了清晰的说明,支持搜索与评论,非常友好。

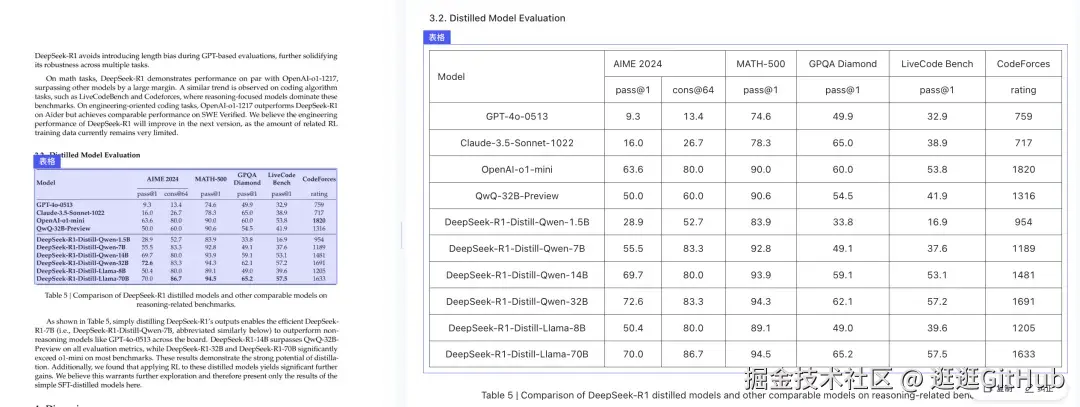
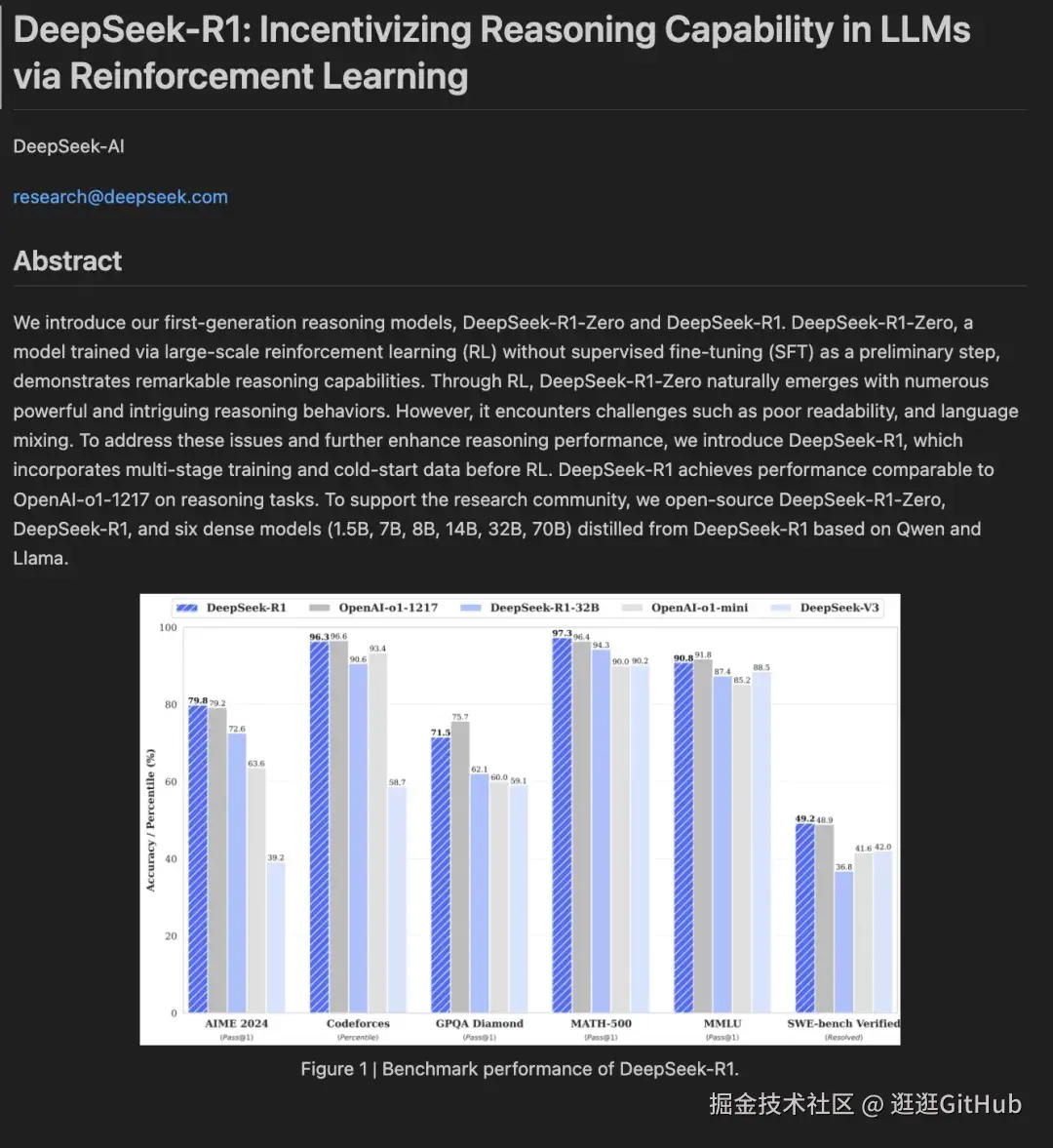
我这里以 PaddleOCR-VL 为例,上传了一篇 DeepSeek-R1 的论文 PDF。
几秒后,解析结果清晰呈现:不管是文字、图像、代码、表格还是公式,PaddleOCR都能精准还原,相关内容,可以左右一一对应。
在右侧,你也可以复制所有的解析结果,也可以复制其中的某一个block的结果,还可以基于某一个block进行内容纠正。下边是一些关键场景的可视化。
·文字场景
一级标题、二级标题、正文层次分明,还原精准。

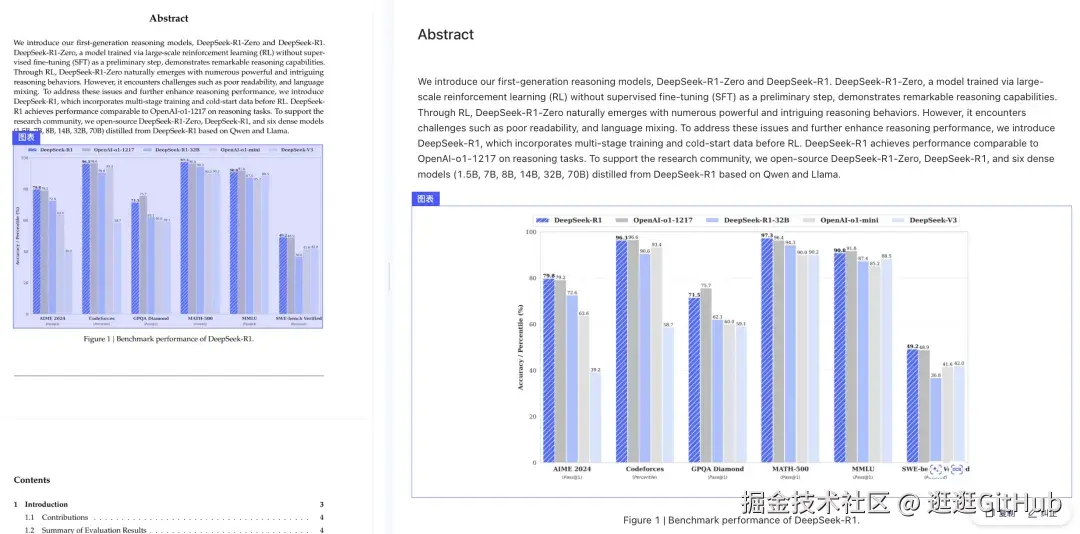
·图像/图表场景
支持图表转表格,对科研与数据分析工作者极其友好。关闭图表识别功能:
打开图表识别功能:
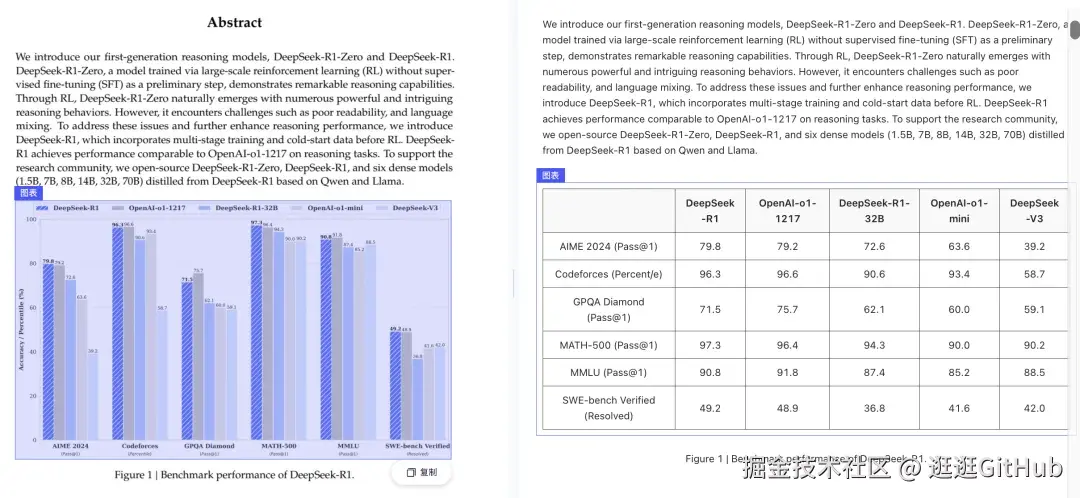
这项功能极其实用,能够将图表等非结构化数据转换为结构化表格,对于科研人员以及日常需要处理图表数据的工作者而言,是一项极具价值的工具。
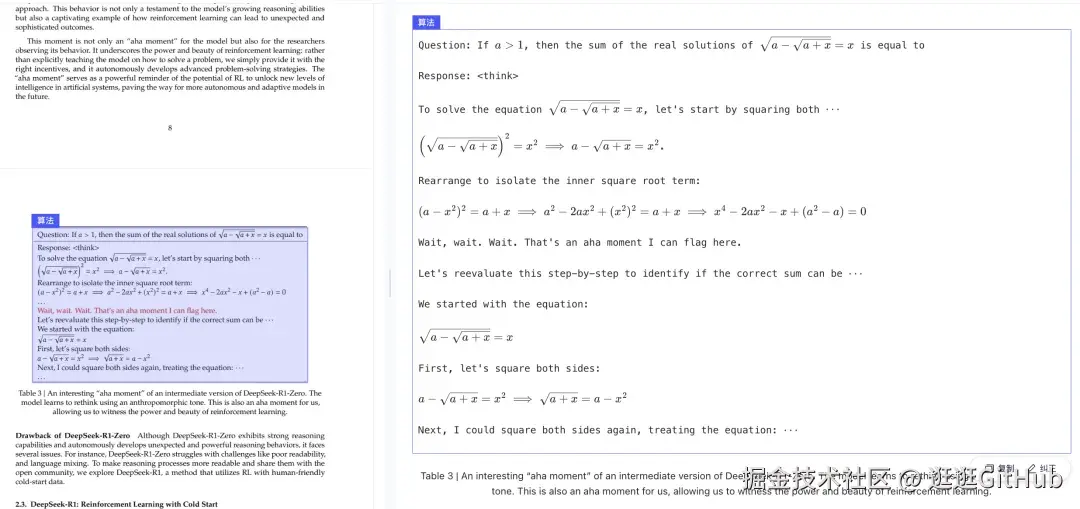
·代码场景
代码区域被转换为等宽字体,代码的格式与内嵌公式保留完整,恢复完美。
·表格场景
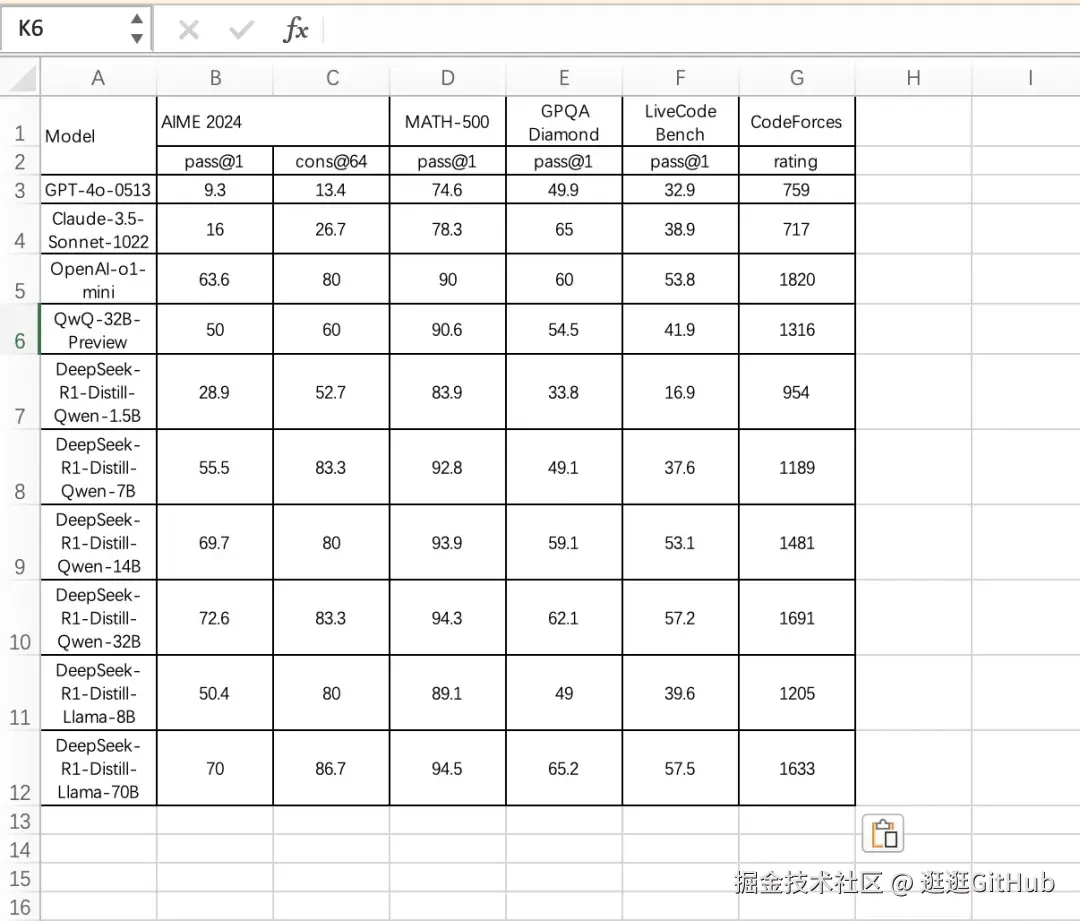
合并单元格也能准确预测,精准还原表格中的各项指标。点击"复制"可直接粘贴至 Excel,格式无损。
此外,在表格应用场景中,我还发现了一个小惊喜:点击右侧下方表格区块的复制按钮后,可以将表格内容无损地粘贴到Excel中,原有格式能够完整保留。这个功能对我日常整理数据非常有帮助,没想到能够如此完美地实现。
不过,官方似乎并未特别宣传这项小功能,看来还有许多实用细节有待用户进一步发掘。
·公式场景
LaTeX 格式输出,右侧实时渲染,复杂公式也无错漏。

公式内容会被自动识别并转换为LaTeX格式的代码,随后在右侧的Markdown区域被正确渲染。经过对比验证,即使是较为复杂的公式也能够准确无误地显示,未发现任何错误。
·更多功能
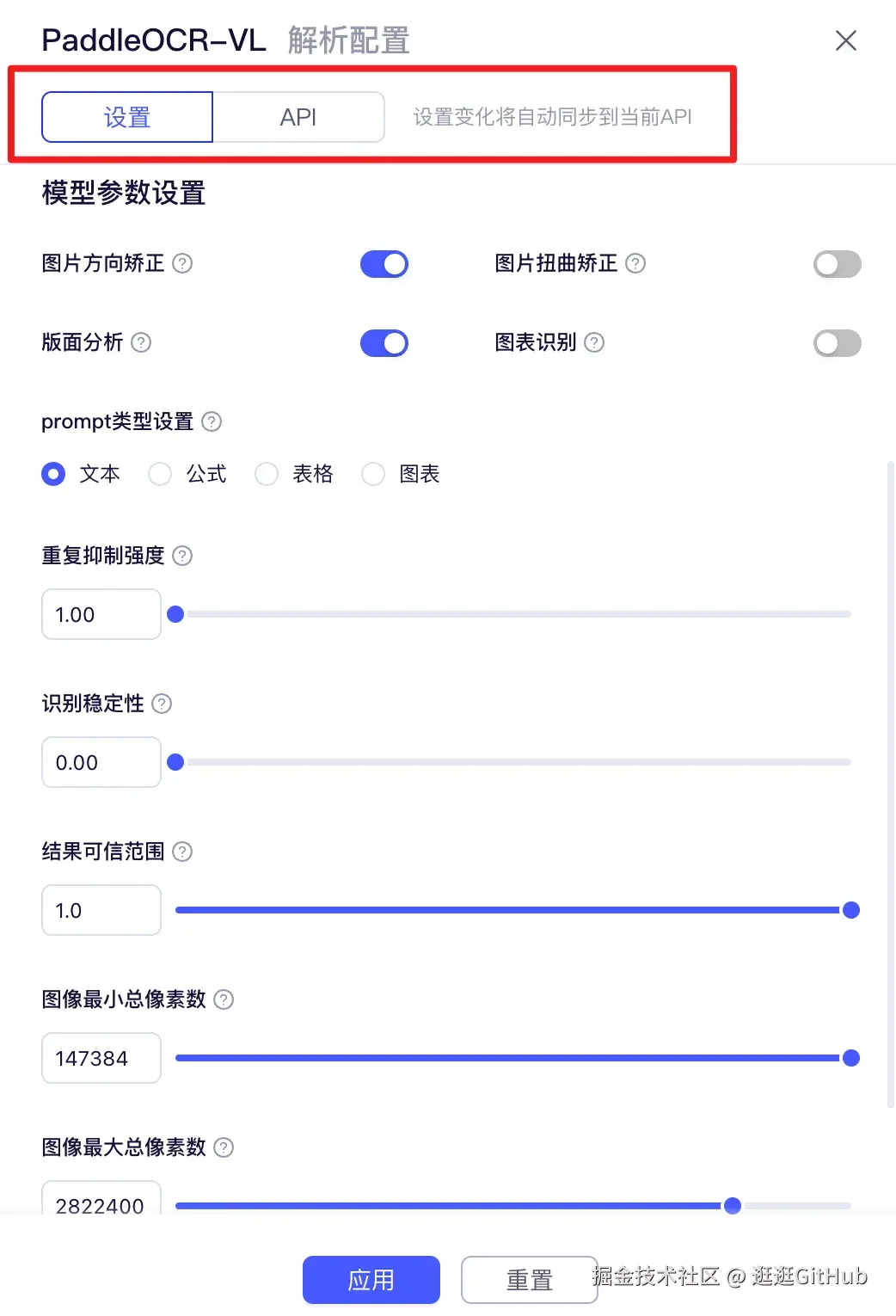
此外,官网还支持批量上传(最多 20 个文件),并提供了超参数设置面板,除了默认的结果,还有一个设置超参数的按钮,用户可根据需求设置很多超参数,关于超参数的解释,也在旁边隐藏的部分有解释。
比如上边的图表识别的功能,我就是打开了这个超参数中的图表识别的开关,灵活度很高。


02
API 调用:数据基建的"普惠管道"
PaddleOCR官网首页已直接提供了 API 和 MCP 的调用示例,点击就可以有对应的弹窗,亲测带上token,复制可以跑。这里以 API 为例,MCP类似。
基础跑通三步走:
- 点击首页的API:
- 复制代码到本地
在本地电脑新建一个名为 test.py 的文件,并将复制的代码粘贴进去(此时你的账号 token 也会被自动复制)。然后,在代码中的 file_path 参数填写你要预测的文件名。这里需要注意的是:如果是 PDF 文件,fileType 应设置为 0;如果是图像文件,fileType 则需要设置为 1。

- 运行代码
大约在20多秒可以返回一个21页的PDF结果,包含了每一页的Markdown的结果、对应的插图等。基本上每秒一页,速度还不错。本地可视化如图所示,和网页端完全一致。
进阶玩法三步走:
进一步体验PaddleOCR官网,会发现一些我认为非常重要的细节。
- API和效果联动
这次 PaddleOCR 官网的一个重要变化,是前端整体把体验优化得非常友好了,不再只是"展示效果",而是围绕 参数配置 → 效果验证 → API 接入 这条完整路径来设计。
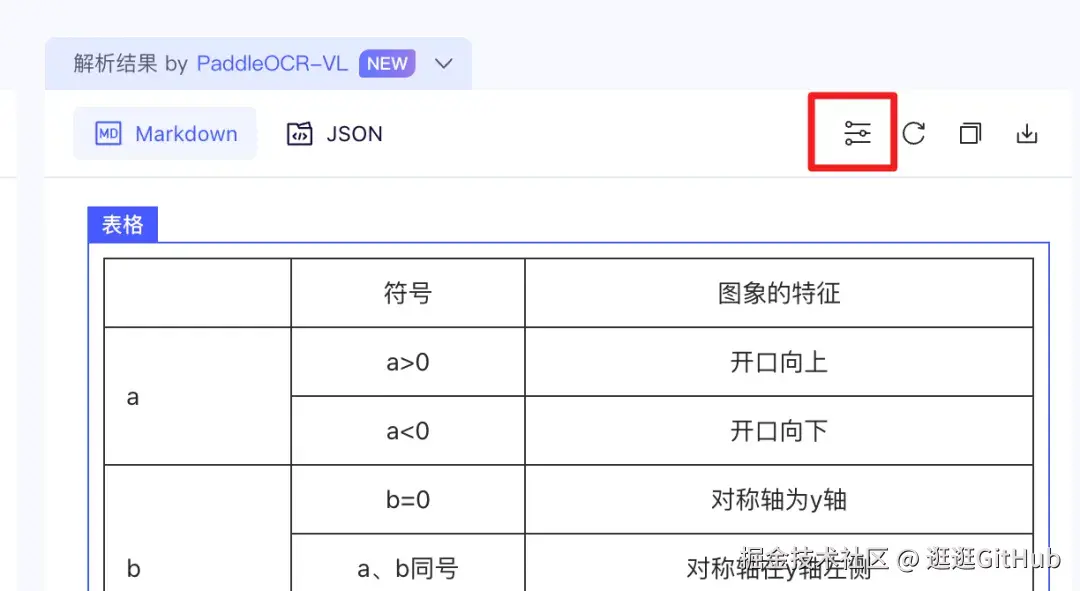
在网页端,你可以直接调整解析参数,比如是否开启图表识别、是否需要方向矫正、不同结构化策略等,每一次参数变化,解析结果都会即时刷新返回。图像或 PDF 的结构化结果几乎是秒级可见,非常适合快速对比不同参数组合下的效果差异,而不是靠猜。
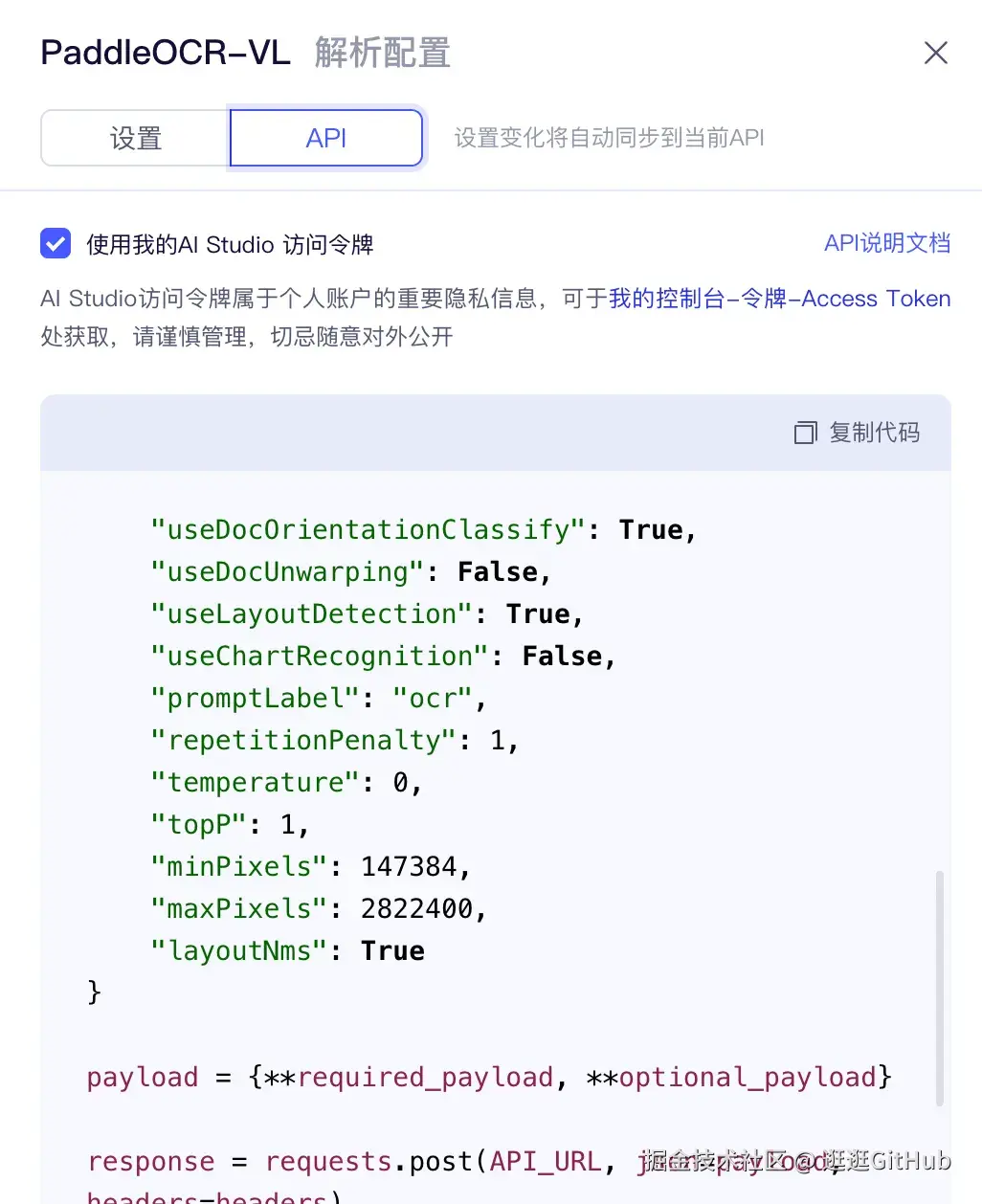
更关键的是,这些在网页端调过、验证过的参数,并不会停留在「试用层」。当你确认某一套配置满足你的业务需求后,可以直接一键复制对应的 API 调用代码,包括参数、模型类型和调用方式,拿到本地或直接接入业务系统即可使用。
整个过程非常顺滑:
你不需要先搭环境、不需要翻文档对着字段一个一个找参数含义,先在网页上把效果跑通,再把同一套配置"原封不动"搬进工程里。哪怕完全没有本地部署过,也可以先把解析效果看清楚、想明白,再决定是否以及如何在真实业务中使用。
一句话总结就是:
不用写一行代码,也能把PaddleOCR的能力验证到位;一旦要上线,代码已经帮你准备好了。
2.更多的 API 调用
在 API 文档页有一行关键说明:"每位用户每日对同一模型的解析上限为 3000 页,超出会返回 429 错误。如需更高额度,可通过问卷申请白名单。"
🔗申请链接为:paddle.wjx.cn/vm/mePnNLR....
我填写了问卷中四个常规问题留下联系方式后,很快就有官方人员联系我,了解使用场景后直接开通了白名单。随后我测试了约 1 万份 PDF(共 3 万多页),开了一个后台的访问服务的进程挂机运行一夜,第二天一早,全部解析成功。这意味着,现阶段个人、团队或初创企业完全可以借助此额度,启动大规模的数据清洗与知识库构建工作,成本几乎为零。
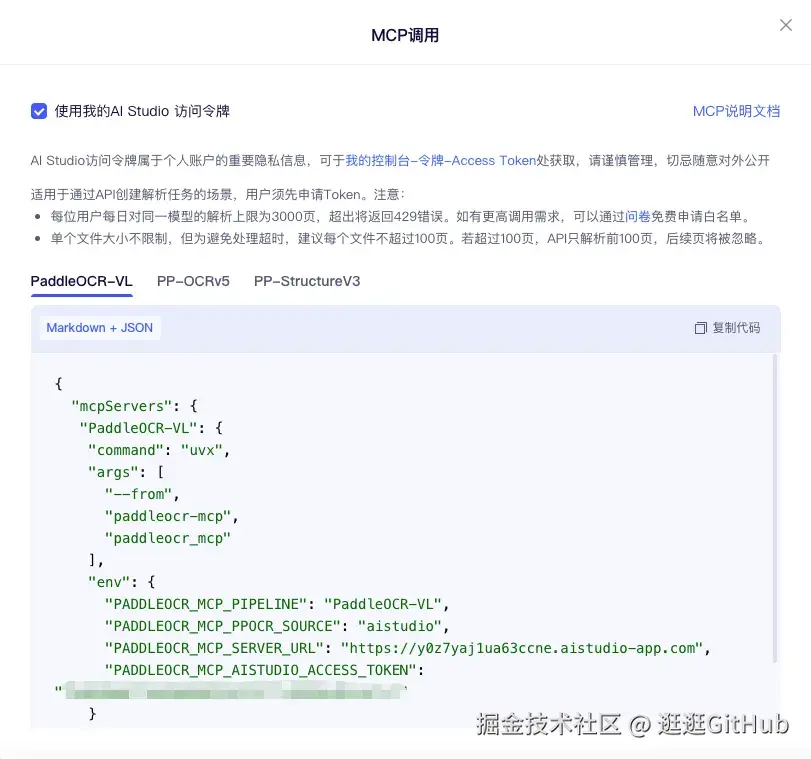
3.不容错过的MCP
作为 AI 时代的 Type-C 接口,MCP 正逐渐成为各类 AI 产品的基础能力配置。PaddleOCR 官网也提供了开箱即用的 MCP server:只需复制官网给出的配置示例,并在 MCP host 应用中完成简单配置,即可让大模型直接调用 PaddleOCR 的文字识别与文档解析能力。
我也在 Cherry Studio 里试了试效果。花了不到一分钟复制粘贴 MCP 配置,然后使用 PaddleOCR 官网提供的 PP-OCRv5 MCP server 来识别图像中的酒店名称:

03、项目相关链接
官网虽已足够强大,但如果你有私有化部署需求,仍可基于开源项目自行部署。
bash
·PaddleOCR GitHub:https://github.com/PaddlePaddle/PaddleOCR·官方文档:https://www.paddleocr.ai·Hugging Face 模型:https://huggingface.co/PaddlePaddlePaddleOCR 再一次没有让人失望。从开源项目到产品化官网,从模型迭代到这波 API 的开放,它正在把文档智能从"技术能力"推向"普及工具"。大模型时代,数据是石油,而 OCR 则是开采与提炼的核心装备。PaddleOCR 这一次的升级,不仅提升了开采效率,还让更多人用上了这把利器。
期待大家亲自体验,也欢迎在评论区分享你的使用场景与发现。