大家好!我是大聪明-PLUS!
今天我将继续我们的 Linux 内核系列文章。
在本文中,我们将探讨服务器领域的网络组织方式,以及它如何从使用传统的 Linux 内核网络堆栈演变为使用 OVS 的网络虚拟化,再到使用 NFV 和 SR-IOV 处理电信工作负载。
Linux 网络堆栈
本文将探讨 Linux 内核中基本的 IPv4/TCP 流量流程,在深入探讨流量路径之前,我们应该先熟悉一些辅助工具和概念:
环形缓冲器
当网络适配器启动且其驱动模块被内核加载时,驱动程序首先会在设备内存中分配接收 (Rx) 和发送 (Tx) 队列或缓冲区(称为环形缓冲区),这些内存通常是内核 DMA 内存空间的一部分。您可以查看这些缓冲区的最大大小和已配置的大小:
$ ethtool` `-g` INTERFACE_NAME
Ring parameters `for` INTERFACE_NAME:
Pre-set maximums:
RX: `4096` `<<<<<<<<<<<<<<<`, Max size `in` bytes
RX Mini: `2048`
RX Jumbo: `4096`
TX: `4096` `<<<<<<<<<<<<<<<`, Max size `in` bytes
Current hardware settings:
RX: `1024` `<<<<<<<<<<<<<<<`, Configured size `in` bytes
RX Mini: `128`
RX Jumbo: `512`
TX: `512` `<<<<<<<<<<<<<<<`, Configured size `in` bytes`在早期内核版本中,到达这些缓冲区的数据包会导致 CPU 为每个数据包发出一次硬件中断,这非常具有侵入性,但幸运的是,引入了 NAPI 来帮助解决这个问题,您将在下面了解更多相关信息。
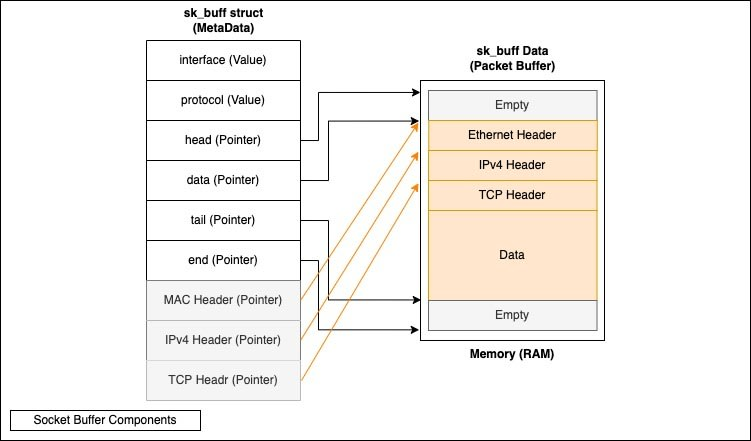
套接字缓冲区(sk_buff)
sk_buff(套接字缓冲区) ,Linux 使用套接字缓冲区 (sk_buff) 与数据包/信元/段或任何其他接收到的网络单元进行交互,每个 sk_buff 的数据和元数据(头部)是分开处理的,因此内核不需要在内存中移动数据包。套接字缓冲区充当一个桶,它存储段数据直到被处理。套接字缓冲区不会随着数据包一起销毁,它们会被释放并重新分配给新的数据包。此外,当它们被用完时,CPU 会创建新的 sk_buff(新的桶)来处理额外的流量。
注意:"sk_buff"和"skb"可以互换使用,但你会发现skb在
构成sk_buff的内核代码中被广泛使用(如下图所示):
-
数据包缓冲区(sk_buff 数据) :实际数据包和数据存储在内核空间内存(DMA 内存空间 - DMA 概念将在下文讨论)中的位置,使用 sk_buff 结构指定,分配的 SKB 大小等于 TCP MSS+Headroom,以允许 MSS 根据连接和用户修改而改变。
-
sk_buff 结构体(套接字缓冲区元数据) :存储在数据包缓冲区(数据)中的数据包元数据,包括指针和值,其结构如下:请注意,这只是 sk_buff 结构体的一部分,
-
接口(input_dev) :指数据包到达的接口的名称。
-
协议 :IPv4、IPv6 等。
-
Head :指向 sk_buff 开头的指针,它实际上以一个空白空间开始,为额外的标头(例如实例的 VLAN 标签)提供空间。
-
数据 :数据指针并不指向数据的开头,而是在堆栈函数中动态地用于获取和推送头部,因此例如在内核中,当你说"推送以太网头部"时,实际发生的只是将数据指针移动到 IP 头部的开头,因此没有头部被物理地放入内存中。
-
尾部 :指示数据部分的结束和 sk_buffer 空部分的开始。同样,由于 sk_buffer 的大小与配置的 MTU 相对应,因此该空部分用于处理不同大小的数据包。
-
End :指向内存中 sk_buff 的末尾。
-
MAC、IP 和 TCP 报头指针 始终存储在 sk_buff 元数据中,因此可以直接调用它们,而无需执行 sk_buff 获取和发送步骤。
-
克隆 :您可以克隆 SKB 标头,但不能克隆数据。
注意:内核中不会复制数据包;实际的数据包数据仍然保留在数据包缓冲区中。每次进行克隆或复制操作时,数据包缓冲区保持不变;而是创建一个新的 sk_buff(也称为 SKB),因此新的元数据指向现有的数据包缓冲区。即使内核中没有复制数据包,数据包也会被复制,到达应用程序,并且 SKB 会被释放。
sk_buff 的基本几何形状
sk_buff--- 是表示数据包的基本网络结构。
struct sk_buff它本身是一个元数据结构,不包含任何数据包。所有数据都存储在链接缓冲区中。
sk_buff.head指向主"头部"缓冲区。头部缓冲区分为两部分:
包含标头和有时包含有效载荷的数据缓冲区;这是 skb 中普通辅助函数(例如
skb_put()或) 所操作的部分skb_pull();共享信息(struct skb_shared_info),其中包含指向只读数据的指针数组,格式为(页,偏移量,长度)。
它还 skb_shared_info.frag_list可以指向另一个 SKB。
基本示意图可能如下所示:
` ---------------
| sk_buff |
---------------
,--------------------------- + head
/ ,----------------- + data
/ / ,----------- + tail
| | | , + end
| | | |
v v v v
-----------------------------------------------
| headroom | data | tailroom | skb_shared_info |
-----------------------------------------------
+ [page frag]
+ [page frag]
+ [page frag]
+ [page frag] ---------
+ frag_list --> | sk_buff |
---------`常见的 skb 和 skb 克隆
sk_buff.users--- 是一个简单的引用计数器,允许多个对象保持存活状态。带有 的 skb 被称为共享 skb(参见"资源")。struct sk_buffsk_buff.users != 1skb_shared()
skb_clone()允许快速复制 skb。数据缓冲区不会被复制,但调用者会收到一个新的元数据结构()。&skb_shared_info.refcount 指定指向同一数据包的 skb 的数量(即克隆)。struct sk_buff
不带头部信息的 dataref 和 skbs
传输层会发送其存储的 skb 有效载荷的副本以供重传。为了允许协议栈的底层添加自己的头部,我们将协议栈分成 skb_shared_info.dataref两部分。低 16 位表示引用总数。高 16 位表示仅包含有效载荷的引用数量。 skb_header_cloned()检查 skb 是否允许添加/写入头部。
skb(例如 TCP)的创建者会将其 skb 标记为已标记 sk_buff.nohdr (通过 __skb_header_release())。任何从已标记的 skb 创建的克隆都将 sk_buff.hdr_len填充可用库存。如果只有一个克隆,它可以随意修改库存。传输层中的调用顺序如下:
`<alloc skb>
skb_reserve()
__skb_header_release()
skb_clone()
// send the clone down the stack
`这种设计并不十分灵活,而且依赖于传输层的正确操作。实际上,通常只有一个仅包含有效载荷的 skb 文件。拥有多个具有不同 hdr_len 长度的仅包含有效载荷的 skb 文件是不可能的。仅包含有效载荷的 skb 文件永远不应该离开其所有者。
校验和信息
用于在协议栈和网络驱动程序之间卸载校验和的接口如下所示......
IP校验和相关功能
驱动程序会在设备函数中声明其校验和卸载功能。从协议栈的角度来看,这些功能是由驱动程序提供的。驱动程序通常只声明它可以传递给设备的那些函数。
|---------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| | 与校验和相关的设备功能 |
| NETIF_F_HW_CSUM | 驱动程序(或其设备)能够为任意协议或协议层组合计算单个 IP 校验和(反码)。校验和的计算和设置在 CHECKSUM_PARTIAL 接口数据包中(见下文)。 |
| NETIF_F_IP_CSUM | 驱动程序(设备)只能验证 IPv4 上简单 TCP 或 UDP 数据包的校验和。这些数据包是未封装的,格式为 IPv4|TCP 或 IPv4|UDP,其中 IPv4 报头中的 Protocol 字段为 TCP 或 UDP。IPv4 报头可能包含 IP 参数。如果设备的函数中同时设置了 NETIF_F_HW_CSUM,则无法设置此功能。此功能已弃用(见下文)。 |
| NETIF_F_IPV6_CSUM | 驱动程序(设备)只能验证 IPv6 上简单 TCP 或 UDP 数据包的校验和。这些数据包是未封装的,格式为 IPv6|TCP 或 IPv6|UDP,其中 IPv6 报头中的下一个报头字段为 TCP 或 UDP。此功能不支持 IPv6 扩展报头。如果设备的某个函数也设置了 NETIF_F_HW_CSUM,则不能设置此功能。此功能已弃用(见下文)。 |
| NETIF_F_RXCSUM | 驱动程序(设备)会卸载接收校验和。此标志仅用于禁用设备的接收校验和功能。无论是否设置了 NETIF_F_RXCSUM,协议栈都会接受设备接收到的数据包中的接收校验和。 |
设备接收到的数据包校验和
校验和验证指示已设置为"是" sk_buff.ip_summed。可能的值:
-
CHECKSUM_NONE设备无法对该数据包进行校验和计算,例如由于缺少相应功能。数据包中包含完整的(但未经验证的)校验和,但 skb->csum 中没有。因此,在这种情况下,skb->csum 未定义。
-
CHECKSUM_UNNECESSARY你使用的硬件无法计算完整的校验和(例如 [
CHECKSUM_COMPLETE[ ...CHECKSUM_UNNECESSARY``sk_buff.csumCHECKSUM_UNNECESSARY适用于以下协议:-
TCP:IPv6 和 IPv4。
-
UDP:IPv4 和 IPv6。设备可以对 IPv4 或 IPv6 的 UDP 校验和为零的情况应用 CHECKSUM_UNNECESSARY,在这种情况下,网络协议栈可以执行额外的验证。
-
GRE:仅当头部信息中存在校验和时才有效。
-
SCTP:表示已验证 SCTP 标头中的 CRC。
-
FCOE:表示 FC 帧中的 CRC 已验证。
sk_buff.csum_level指定数据包中找到的连续校验和的数量,减去一个被验证为无效的校验和CHECKSUM_UNNECESSARY。例如,如果设备收到一个 IPv6->UDP->GRE->IPv4->TCP 数据包,并且该设备可以验证 UDP(可能为零)、GRE(校验和标志已设置)和 TCP 的校验和,则该值sk_buff.csum_level将设置为 2。如果设备只能验证 UDP 校验和而无法验证 GRE 校验和(可能是因为设备不支持 GRE 校验和,或者 GRE 校验和不正确),则 skb->csum_level 将设置为零(在这种情况下,TCP 校验和将被忽略)。 -
-
CHECKSUM_COMPLETE这是最常用的方法。设备会提供一个完整可见的
netif_rx()、已填充的 整个数据包的校验sk_buff.csum和。这意味着硬件无需分析 L3/L4 数据包头部即可实现此功能。笔记:
-
即使设备仅支持某些协议,但能够生成 skb->csum,也必须使用 CHECKSUM_COMPLETE,而不是 CHECKSUM_UNNECESSARY。
-
CHECKSUM_COMPLETE 不适用于 SCTP 和 FCoE 协议。
-
-
CHECKSUM_PARTIAL校验和配置用于上传到设备,如 CHECKSUM_PARTIAL 的输出描述中所述。这可能发生在直接从另一个 Linux 操作系统(例如同一主机上的虚拟化 Linux 内核)接收的数据包中,也可能发生在 GRO 的输入路径中,或通过远程校验和上传进行设置。出于校验和验证的目的,skb->csum_start + skb->csum_offset 中指定的校验和以及数据包中任何先前的校验和均被视为已验证。校验和上传之后数据包中的任何校验和均不被视为已验证。
NGSO传输过程中的校验和
协议栈请求卸载 sk_buff.ip_summed数据包的校验和。值:
-
CHECKSUM_PARTIAL驱动程序必须计算 `hard_start_xmit()` 函数接收到的所有数据包的校验和,直至数据
sk_buff.csum_start包结束,并将校验和写入偏移量为 `sk_buff.csum_start+` 的sk_buff.csum_offset位置。驱动程序可以根据数据包长度和偏移量验证 `csum_start` 和 `csum_offset` 的值是否有效,但不应尝试验证校验和是否指向有效的传输层校验和------此验证是协议栈的职责。请确保 `csum_start` 和 `csum_offset` 设置正确。当协议栈请求对数据包进行校验和卸载时,驱动程序必须确保校验和设置正确。驱动程序可以将校验和计算卸载到设备,或者调用 skb_checksum_help 函数(如果设备不支持特定校验和的卸载)。
NETIF_F_IP_CSUM并且NETIF_F_IPV6_CSUM已被弃用,取而代之的是NETIF_F_HW_CSUM。应使用新设备NETIF_F_HW_CSUM来指示校验和卸载功能。可以调用 skb_csum_hwoffload_help() 来CHECKSUM_PARTIAL根据网络设备的校验和功能进行解析:如果数据包与它们不匹配,则调用 skb_checksum_help() 或 skb_crc32c_help()。 -
CHECKSUM_NONEskb 校验和已经由协议验证,或者不需要校验和。
-
CHECKSUM_UNNECESSARY这与 CHECKSUM_NONE 的含义相同,都是指在输出时卸载校验和。
-
CHECKSUM_COMPLETE输出校验和时不使用此功能。如果驱动程序遇到 skbuff 中设置了此值的包,则应将其视为
CHECKSUM_NONE已设置此值。
无IP的CRC卸载
|--------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| NETIF_F_SCTP_CRC | 此函数表明设备能够卸载数据包中的 SCTP CRC 校验和。为了执行此卸载,协议栈会分别设置 csum_start 和 csum_offset 值,并将 ip_summed 设置为 CHECKSUM_PARTIAL1,同时将 csum_not_inet 设置为 1,以向 skbuff 指示它们 CHECKSUM_PARTIAL指的是 CRC32c 校验和。同时支持 IP 校验和卸载和 SCTP CRC32c 卸载的驱动程序应通过检查 csum_not_inet 的值来确定数据包配置了哪种卸载方式 sk_buff.csum_not_inet;skb_crc32c_csum_help() 函数旨在解析 CHECKSUM_PARTIALcsum_not_inet 设置为 1 的 skbuff 情况。 |
| NETIF_F_FCOE_CRC | 此函数表明设备能够转储数据包中的 FCoE CRC。要执行此转储,协议栈将设置 ip_summed CHECKSUM_PARTIAL,并相应地设置 csum_start 和 csum_offset。请注意,skbuff 未指定哪个 CHECKSUM_PARTIAL指的是 FCoE 校验和,因此,同时支持 IP 校验和和 FCoE CRC 转储的驱动程序必须验证为数据包配置了哪个转储,这可以通过检查数据包头来实现。 |
使用 GSO 输出校验和
对于 GSO 数据包(skb_is_gso() 为真),gso_type 中的 SKB_GSO_* 标志隐含了校验和卸载。显然,如果 gso_type 等于 SKB_GSO_TCPV4或 SKB_GSO_TCPV6,则 TCP 校验和卸载是 GSO 操作的一部分。如果使用 GSO 卸载校验和,则 ip_summed 等于 CHECKSUM_PARTIAL,并且 csum_start 和 csum_offset 都指向最外层的卸载校验和(使用 UDP 封装时,可能存在两个卸载校验和)。
内核中断(IRQ 或 SoftIRQ)
简而言之,中断用于停止处理器当前正在执行的操作,并允许中断器处理该任务。中断模型有很多种,每种模型又包含多种类型,但如下所示,这些中断可以分为两大类。
- 上半部分中断(硬件中断) :这类中断开销非常大,因此中断处理程序会在第一次使用后将其屏蔽,之后网卡驱动程序会开始使用 SoftIRQ(软件中断),SoftIRQ 本身可以被中断,您可以观察这些中断:
$ cat` /proc/interrupts
CPU0 CPU1
`0`: `171` `0` IO-APIC `2-edge` timer
`1`: `0` `9` IO-APIC `1-edge` i8042
`8`: `1` `0` IO-APIC `8-edge` rtc0
`9`: `0` `21` IO-APIC `9-fasteoi` acpi
`16`: `494` `0` IO-APIC `16-fasteoi` snd_hda_intel:card1
`17`: `372236` `1575` IO-APIC `17-fasteoi` ehci_hcd:usb1, ehci_hcd:usb2, ehci_hcd:usb3, ath9k
`18`: `268` `0` IO-APIC `18-fasteoi` ohci_hcd:usb4, ohci_hcd:usb5, ohci_hcd:usb6
`19`: `49197` `4164` IO-APIC `19-fasteoi` ahci[0000:00:11.0]
`25`: `5` `100550` PCI-MSI-0000:00:01.0 `0-edge` radeon
`28`: `0` `28` PCI-MSI-0000:00:01.1 `0-edge` snd_hda_intel:card0
NMI: `0` `0` Non-maskable interrupts
LOC: `1852383` `1696841` Local timer interrupts
SPU: `0` `0` Spurious interrupts
PMI: `0` `0` Performance monitoring interrupts
IWI: `1` `0` IRQ work interrupts
RTR: `0` `0` APIC ICR read retries
RES: `351662` `366757` Rescheduling interrupts
CAL: `689212` `789962` Function call interrupts
TLB: `19390` `18975` TLB shootdowns
TRM: `0` `0` Thermal event interrupts
THR: `0` `0` Threshold APIC interrupts
DFR: `0` `0` Deferred Error APIC interrupts
MCE: `0` `0` Machine check exceptions
MCP: `23` `23` Machine check polls
ERR: `1`
MIS: `0`
PIN: `0` `0` Posted-interrupt notification event
NPI: `0` `0` Nested posted-interrupt event
PIW: `0` `0` Posted-interrupt wakeup event`每个中断(硬件中断)都由一个向量标识 , 该向量是一个 0 到 255 范围内的单字节标识符,其中 0 到 31 是所谓的异常中断(不可屏蔽),范围 32 到 47 是可屏蔽中断,48 到 255 保留用于软件中断(SoftIRQ)。
简而言之,上述输出中会遇到三种类型的硬件中断:MSI-X、MSI 和传统 IRQ。MSI 代表消息信号中断,它取代了过去使用处理器插槽中每个设备一个物理引脚来处理中断的旧方法。
阅读有关 MSI 和其他类型硬件中断的信息。
- 下半部分中断(软中断) :软中断会为每个处理器启动一个队列,您可以在 ps 输出中找到它们,格式为 ksoftiqd/CPU_Number。这些队列轮询设备驱动程序来处理流量,而不是设备硬件(网卡)。通过在处理器每次接收到流量时中断它,您可以查看接收队列和发送队列:
$ ps` aux | `grep` ksoftirqd
root `15` `0`.0 `0`.0 `0` `0` ? S `18`:53 `0`:00 [ksoftirqd/0]
root `23` `0`.0 `0`.0 `0` `0` ? S `18`:53 `0`:00 [ksoftirqd/1]
argentum `5376` `33`.3 `0`.1 `6588` `2176` pts/0 S`+` `20`:58 `0`:00 `grep` `--color=`auto ksoftirqd
`$ watch` `-n1` `grep` RX /proc/softirqs
Every `1`,0s: `grep` RX /proc/softirqs
NET_RX: `396` `337` `0` `0`
`$ watch` `-n1` `grep` TX /proc/softirqs
Every `1`,0s: `grep` TX /proc/softirqs
NET_TX: `1` `1` `0` `0`
`其他概念
-
DMA(直接内存访问) :网卡是 PCIe 设备。以前,写入内存需要中断 CPU。因此,CPU 会将数据包复制到寄存器,然后再写入内存。DMA 允许 CPU 在不中断 CPU 的情况下访问 DMA 资源。例如,当网卡 (NIC) 需要将某个以太网段写入内存时,它使用 DMA 直接写入内存,而不会浪费宝贵的 CPU 周期。这些来自网卡的 DMA 写入调用由主板上的北桥芯片重定向到 RAM,而不是 CPU。
-
环形缓冲区 :网卡驱动程序和网卡共享发送 (TX) 和接收 (RX) 环形缓冲区,这些缓冲区主要包含指向数据包缓冲区内存位置的指针。这些缓冲区不包含数据,而仅仅是内存指针。
-
上半部分和下半部分 :当网络适配器通过 DMA(DMA 是内核内存中的一个位置,网络适配器无需 CPU 即可访问)将数据包传输到内存时,会向网卡发送一个 SoftIRQ(软中断请求),通知 CPU 有新数据包到达并等待处理。上半部分指的是 CPU 首先要执行的操作,因此 CPU 不会立即停止所有操作来处理此数据包(这可能会造成干扰),而是简单地确认中断并将下半部分(处理数据包的其余操作)安排到稍后执行。
-
上下文切换:进程在用户空间上下文和内核空间上下文之间切换的过程,该过程会消耗 CPU 周期。
-
系统调用 。简而言之,系统调用是用户空间中的用户向内核空间请求服务的一种方式。
-
NAPI(接收流量 )是一种网络设备驱动程序扩展,旨在减少接收数据包时的中断次数。当接收到大量数据包时,NAPI 会发挥作用,但仍与正常的中断处理机制协同工作。它还有助于调节网络流量。如果网络适配器接收到过多的流量,NAPI 会在网络适配器级别丢弃数据包,而无需内核发出警报或中断。NAPI 仅对 数据包接收事件有效 。
-
SoftIRQ :Linux 内核中的"softIRQ"系统用于处理设备驱动程序中断请求 (IRQ) 上下文之外的工作。设备驱动程序中断请求 (IRQ) 通常具有最高的 Linux 内核优先级,并会抢占任何其他类型的中断。KsoftIRQ 是一个队列,它在内核早期阶段就以线程的形式为每个处理器启动,用于处理 softIRQ 的排队。您可以使用以下命令查看这些队列的计数器*:*
$ cat /proc/softirqs -
ISR(中断服务例程) :内核中的一个函数,负责确定中断的性质以及需要采取什么操作,之后 CPU 恢复处理先前暂停的进程。
-
网络接口
网络接口是设备与网络之间的通信通道。网络接口可以通过网络接口卡 ( NIC ) 以物理方式实现,也可以通过软件以更抽象的方式实现。您可以同时运行多个网络接口。您可以随时启用(激活)或禁用(停用)特定接口。该实用程序会显示当前活动的网络接口列表 ifconfig。网络配置文件对于确保接口正常运行至关重要。
对于 基于Debian 的系统 ,基本网络配置文件位于 /etc/network/interfaces。对于 基于RedHat 的系统 ,路由和主机信息包含在 中 /etc/sysconfig/network。网络接口配置脚本 eth0位于 /etc/sysconfig/network-scripts/ifcfg-eth0。对于 基于SUSE 的 系统 ,路由和主机信息以及网络接口配置脚本都包含在 /etc/sysconfig/network目录中。
TCP/IP协议栈
网络 究竟 是什么? 网络 是指两台或多台计算机通过 电线 或通信信道连接,或者在更复杂的情况下,通过网络设备连接,并根据特定规则交换信息。这些规则 由 TCP/IP 协议栈决定。
传输控制协议/互联网协议(TCP/IP协议栈) 简单来说,是一组在不同层级上相互作用的协议( 每一层都与其相邻层级相互交互,也就是说,它们彼此互连,因此 称为" 协议栈 ",依我拙见,这样更容易理解),它们共同管理网络上的数据交换。每个 协议 都是一组管理数据交换的规则。简而言之, TCP/IP协议栈 就是 一组规则集。
这里可能会出现一个合理的问题:为什么要有多种协议?我们难道不能使用单一协议与所有事物通信吗?
关键在于,每个协议都描述了严格定义的 规则。此外,协议还被划分为不同的功能层级,这使得网络设备和软件能够更简单、更透明地运行,并执行其特定的任务。
为了将这套协议划分成不同的层, 人们开发了 OSI 模型 ( 开放系统互连基本参考模型, 1978)。OSI 模型 由七个不同的层组成。每一层负责通信系统的特定部分,并且独立于相邻层------它只是提供特定的服务。每一层都根据一组称为协议的规则执行自己的任务。OSI 模型可以用下图来说明:数据是如何传输的?
该图显示 网络交互分为七层 ,分别是 应用层、表示层、会话层、传输层、网络层、数据链路层和物理层。每一层都包含自己的一套协议。维基百科上详细列出了各层的协议:
TCP/IP 协议栈本身是随着 OSI 模型的采用而发展起来的,两者之间并没有"交叉",这导致协议栈和 OSI 模型各层之间存在一些差异。通常,在 TCP/IP 协议栈中, OSI 模型的前三层(应用层、表示层和会话层 )被合并为一个单一的层------ 应用层 。由于这样的协议栈没有提供统一的数据传输协议,数据类型确定功能被委托给应用程序。TCP /IP 协议栈相对于 OSI 模型的简化解释可以表示如下:
解决
在基于 TCP/IP 协议栈的网络中,每个主机(连接到网络的计算机或设备)都会被分配一个 IP 地址 。IP 地址 是一个 32 位二进制数。一种便捷的 IP 地址(IPv4)表示方法是用四个十进制数(0 到 255)组成,数字之间用句点分隔,例如 192.168.0.1。通常, IP 地址分为两部分 : 网络(子网)地址 和 主机地址。
我认为从这些词的含义可以清楚地看出,IP 地址被划分到网络中,而网络又使用 子网掩码 (更准确地说, 主机地址可以被划分到子网)划分成子网。最初,所有 IP 地址都被划分到特定的组(地址类/网络)中。当时存在一种分类寻址方式,根据这种方式,网络被划分成严格定义且相互隔离的网络:
很容易计算出,IP 地址空间包含 128 个网络,其中 16,777,216 个为 A 类地址;16,384 个网络,其中 65,536 个为 B 类地址;2,097,152 个网络,其中 256 个为 C 类地址;此外还有 268,435,456 个组播地址和 134,317,728 个保留地址。随着互联网的发展,这种系统被证明效率低下,并被 CIDR(无类别随机访问寻址)所取代。在 CIDR 中,网络中的地址数量由子网掩码决定。
IP地址也 分为"私有"和"公共"两种类型。以下地址范围保留给私有地址(也称为局域网):
-
10.0.0.0 --- 10.255.255.255 (10.0.0.0/8 或 10/8)
-
172.16.0.0 --- 172.31.255.255 (172.16.0.0/12 或 172.16/12)
-
192.168.0.0 --- 192.168.255.255 (192.168.0.0/16 或 192.168/16)。
-
127.0.0.0 - 127.255.255.255 保留给环回接口(不用于网络节点之间的通信),也就是所谓的本地主机。
除了主机地址之外,TCP/IP 网络还引入了端口的概念。端口是系统资源的一个数值标识。端口分配给运行在网络主机上的应用程序,用于与其他网络主机(包括同一主机上的其他应用程序)上运行的应用程序进行通信。从软件角度来看,端口是由服务控制的内存区域。
对于 TCP 和 UDP 协议,该标准定义了在主机上同时分配最多 65,536 个唯一端口的能力,这些端口用 0 到 65,535 之间的数字标识。所有端口分为三组:
-
0 到 1023,称为特权码或保留码(用于系统和一些常用程序)
-
1024 - 49151 被称为注册端口。
-
49151 - 65535 称为动态端口。
如图所示, IP协议位于协议层次结构中 TCP 和 UDP之下,负责在网络上传输和路由信息。为了实现这一点,IP将每个信息块(TCP或UDP数据包)封装在另一个数据包(IP数据包或IP数据报)中,该数据包包含源地址、目标地址和路由信息的头部。
打个比方,TCP/IP 网络就像一座城市。街道和巷道名称相当于网络和子网。楼号相当于主机地址。在建筑物内,办公室/公寓号相当于端口。更准确地说,端口就像邮箱,收件人(服务)在其中等待通信。因此, 简单来说,流程大致如下......
需要注意的是,IP 协议没有端口的概念;TCP 和 UDP 负责解释端口,同样,TCP 和 UDP 也不处理 IP 地址。
为了避免记住像 IP 地址这样难以理解的数字字符串,而是使用易于理解的机器名称,一种名为 DNS(域名系统) 的服务应运而生。它负责将主机名转换为 IP 地址,并以庞大的分布式数据库的形式运行。我会在以后的文章中详细介绍这项服务,但现在,只需知道,为了确保名称能够正确转换为地址, 指定的DNS 守护进程必须在机器上运行,或者系统必须配置为使用服务提供商的 DNS 服务。
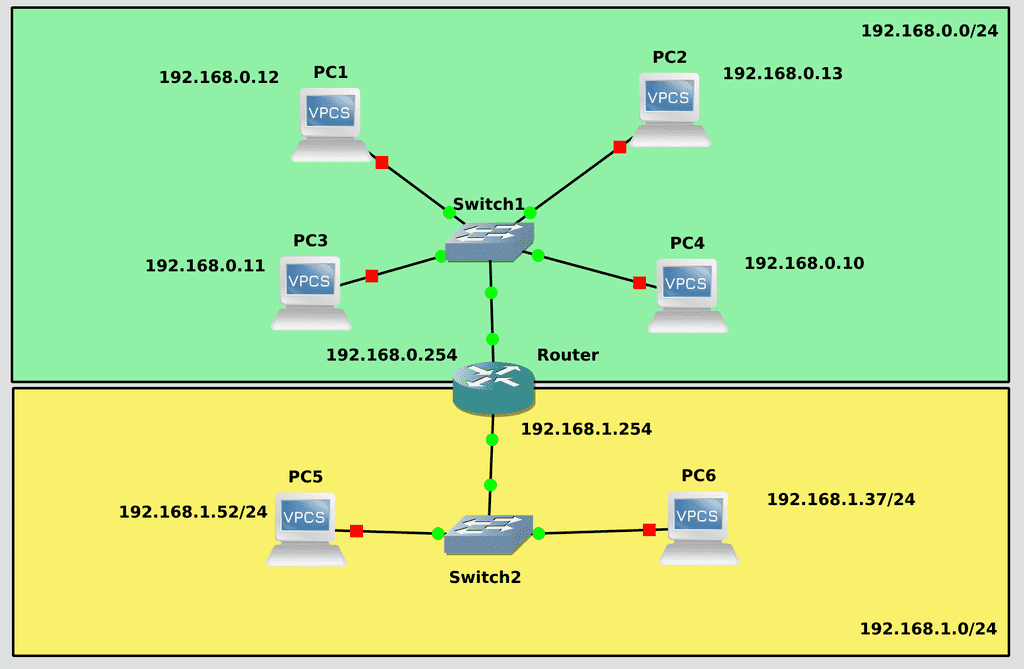
我们来看一个包含多个子网的基础架构示例。你可能会想,一台计算机如何连接到另一台计算机?它如何知道要将数据包发送到哪里?
为了解决这个问题,网络通过网关 (路由器 )连接起来 。 网关 是连接到两个或多个网络的主机,能够在这些网络之间传输信息并将数据包转发到另一个网络。在图中, 菠萝 和 木瓜充当网关,每个网关都有两个接口连接到不同的网络。
为了确定数据包的路由 ,IP 协议使用地址的网络部分(子网掩码 )。网络中的每台机器都有 一个路由表 ,其中存储着网络列表以及这些网络对应的网关。IP 协议会查看数据包中目标地址的网络部分,如果路由表中存在该网络的条目,则将数据包发送到相应的网关。
在 Linux 系统中,内核将路由表存储在 `/proc/net/route`文件中。您可以使用 `netstat -rn`命令 (`r` 代表路由表,`n` 表示不将 IP 地址解析为名称)或 `route`命令查看当前的路由表。`netstat -rn` 输出的第一列 (`Destination` )包含 目标网络(主机)地址。指定网络时,地址通常以零结尾。 第二列(`Gateway`) 是第一列中指定的主机/网络的网关地址。 第三列(`Genmask`) 是路由有效的子网掩码。`Flags` 列 提供有关目标地址的信息(`U` 表示路由已启用,`N` 表示路由针对网络,`H` 表示路由针对主机,等等)。MSS 列 显示一次可以发送的字节数, 窗口 数是在收到确认之前可以发送的帧数, irtt 是路由使用统计信息, Iface指示路由使用的网络接口(eth0、eth1 等)。
如下面的示例所示,第一条路由条目(行)指定了 128.17.75 网络。所有发往该网络的包都将被发送到网关 128.17.75.20,即主机自身的 IP 地址。第二条路由条目是 默认路由 ,它应用于所有发送到此路由表中未指定网络的包。此处,路由经过主机 papaya(IP 地址 128.17.75.98),它可以被视为通往外部世界的入口。128.17.75 网络中所有需要访问其他网络的机器都必须指定此路由。第三条路由条目是为环回接口创建的。如果机器需要使用 TCP/IP 协议连接到自身,则使用此地址。路由表中的最后一个条目是为 IP 地址 128.17.75.20 创建的,并且指向 lo 接口,即当一台机器连接到自身地址 128.17.75.20 时,所有数据包都将发送到接口 127.0.0.1。
如果主机 eggplant 想要向主机 zucchini 发送一个数据包(数据包的发送方为 128.17.75.20,接收方为 128.17.75.37),IP 协议会根据路由表判断这两个主机属于同一个网络,并将数据包直接发送到 zucchini 能够接收到的网络。更详细地说......网卡会广播一个 ARP 请求:"IP 地址 128.17.75.37 是谁?我是 128.17.75.20,正在呼叫?"所有收到此消息的机器都会忽略它,而地址为 128.17.75.37 的主机则会回复:"是我,我的 MAC 地址是......"然后,基于包含IP 地址和 MAC 地址对应关系的ARP 表,建立连接并进行数据交换。"呼叫"意味着该数据包会被发送给所有主机。这是因为接收方的 MAC 地址是广播地址(FF:FF:FF:FF:FF:FF)。网络上的所有主机都会收到此类数据包。
主机eggplant的示例路由表 :
`[root@eggplant ~]# netstat -rn
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
128.17.75.0 128.17.75.20 255.255.255.0 UN 1500 0 0 eth0
default 128.17.75.98 0.0.0.0 UGN 1500 0 0 eth0
127.0.0.1 127.0.0.1 255.0.0.0 UH 3584 0 0 lo
128.17.75.20 127.0.0.1 255.255.255.0 UH 3584 0 0 lo`假设主机 eggplant 想要向主机 pear 甚至更远的地方发送一个数据包。在这种情况下,数据包的目标地址是 128.17.112.21。IP 会尝试在路由表中查找网络 128.17.112 的路由,但该路由不在路由表中。因此, IP会选择 默认路由 ,网关 为papaya (128.17.75.98) 。papaya收到数据包后, 会在其路由表中查找目标地址:
`[root@papaya ~]# netstat -rn
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
128.17.75.0 128.17.75.98 255.255.255.0 UN 1500 0 0 eth0
128.17.112.0 128.17.112.3 255.255.255.0 UN 1500 0 0 eth1
default 128.17.112.40 0.0.0.0 UGN 1500 0 0 eth1
127.0.0.1 127.0.0.1 255.0.0.0 UH 3584 0 0 lo
128.17.75.98 127.0.0.1 255.255.255.0 UH 3584 0 0 lo
128.17.112.3 127.0.0.1 255.255.255.0 UH 3584 0 0 lo`该示例表明, papaya 连接到两个网络:通过 eth0 设备连接到 128.17.75,通过 eth1 设备连接到128.17.112 。 默认路由 通过主机 pineapple,而 pineapple 又是外部网络的网关。
因此,当收到发往梨 的数据包时 , 木瓜路由器会看到目标地址属于 128.17.112 网络,并将根据路由表中的第二个条目路由该数据包。
因此,数据包会从一个路由器传递到另一个路由器,直到到达目的地地址。
值得注意的是,在这些例子中,路线
`128.17.75.98 127.0.0.1 255.255.255.0 UH 3584 0 0 lo
128.17.112.3 127.0.0.1 255.255.255.0 UH 3584 0 0 lo`这些都不是标准配置。在现代 Linux 系统中,你也不会看到类似的东西。
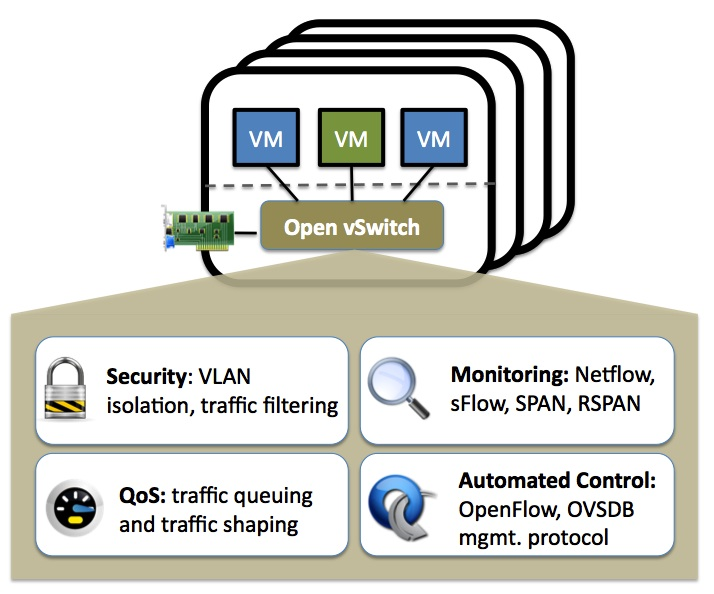
OVS - openvswitch
Open vSwitch (OVS) 是一款多层软件交换机。它旨在通过软件可扩展性实现大规模网络自动化,同时保持对标准接口和管理协议的支持。Open vSwitch 非常适合用作虚拟机环境中的虚拟交换机。
网络运营
关于互联网网络方面的资料可能比Linux要多得多。但我仍然会尝试解释一些基础知识,随着课程的推进,我会逐步讲解与每个主题相关的各种网络细节。我首先要说明的是,我会尽可能简化讲解内容,因为这并非一门网络课程。在这个阶段,我只会讲解我认为必不可少的部分。
过去,人们使用各种各样、难以预测的技巧和工具(例如 tuntap、brctl、vconfig、ebtables 等)将带标签的流量转发到虚拟机管理程序。这导致虚拟机管理程序的宿主操作系统中充斥着大量不必要的虚拟网络接口,ifconfig 输出也变得杂乱无章,管理员们不得不像组装自行车一样,从各种不同的部件中拼凑出一个标准的网络设备(交换机),这令他们感到非常沮丧。事实上,如今的交换机除了支持 802.1q 标准之外,还需要具备许多其他功能。为了满足对功能与现代标准管理型交换机高度匹配的虚拟设备的需求,Open vSwitch(以下简称 OVS)项目应运而生。
Open vSwitch 是一款采用 Apache 2 开源许可证的多层软件交换机。我们的目标是实现一个高质量的交换平台,该平台支持标准管理接口,并开放转发功能,以便进行软件扩展和控制。
Open vSwitch 非常适合用作虚拟机环境中的虚拟交换机。除了提供标准的管理接口和虚拟网络级别的可视性之外,它还支持跨多个物理服务器的分布。Open vSwitch 支持多种基于 Linux 的虚拟化技术,包括 KVM 和 VirtualBox。
大部分代码是用平台无关的 C 语言编写的,因此可以轻松移植到其他环境。当前版本的 Open vSwitch 支持以下功能:
-
标准 802.1Q VLAN 模型,带干线端口和接入端口
-
在上游交换机上启用或禁用 LACP 进行网卡绑定
-
NetFlow、sFlow® 和镜像技术可提高可见性
-
服务质量 (QoS) 配置和策略实施
-
支持 Geneve、GRE、VXLAN、STT、ERSPAN、GTP-U、SRv6、Bareudp 和 LISP 隧道协议。
-
处理 802.1ag 连接错误
-
OpenFlow 1.0 及众多扩展
-
具有 C 和 Python 绑定的事务配置数据库。
-
使用 Linux 内核模块实现高性能转发
Open vSwitch 也可以完全在用户空间运行,无需内核模块的辅助。这种用户空间实现方式比基于内核的交换机更容易移植。用户空间 OVS 可以访问 Linux 或 DPDK 设备。注意:使用用户空间数据通道和非 DPDK 设备的 Open vSwitch 仍处于实验阶段,并且会带来一定的性能损失。
该计划的主要组成部分包括:
-
ovs-vswitchd 是一个实现切换的守护进程,也是一个用于基于线程的切换的 Linux 内核配套模块。
-
ovsdb-server 是一个轻量级数据库服务器,ovs-vswitchd 会查询该服务器以获取其配置。
-
ovs-dpctl 是用于配置交换机内核模块的工具。
-
用于构建 Red Hat Enterprise Linux 的 RPM 包和 Ubuntu/Debian 的 deb 包的脚本和规范。
-
ovs-vsctl 是一个用于查询和更新 ovs-vswitchd 配置的实用程序。
-
ovs-appctl 是一个实用程序,用于向正在运行的 Open vSwitch 守护进程发送命令。
Open vSwitch 还提供了一些工具:
-
ovs-ofctl,一个用于查询和管理 OpenFlow 交换机和控制器的实用程序。
-
ovs-pki 是一个用于创建和管理 OpenFlow 交换机公钥基础设施的实用程序。
-
ovs-testcontroller 是一个简单的 OpenFlow 控制器,可能对测试有用(但不适用于生产环境)。
-
修复了 tcpdump 的问题,使其能够分析 OpenFlow 消息。
虚拟机管理程序需要具备在虚拟机和外部世界之间建立通信桥接的能力。在基于 Linux 的虚拟机管理程序中,这意味着使用内置的二层交换机(Linux 网桥),它速度快、可靠性高。因此,人们不禁要问,为什么还要使用 Open vSwitch 呢?
答案是,Open vSwitch 专为多服务器虚拟化部署而设计,而之前的协议栈并不适合这种环境。这些环境通常具有高度动态的端点、对逻辑抽象的支持,并且(有时)集成或卸载专用交换硬件。
以下特性和设计特点有助于 Open vSwitch 满足上述要求。
与网络对象(例如虚拟机)关联的所有网络状态都应该易于识别,并且可以在不同主机之间传输。这可能包括传统的"软状态"(例如,L2学习表中的条目)、L3转发状态、策略路由状态、ACL、QoS策略、监控配置(例如,NetFlow、IPFIX、sFlow)等。
Open vSwitch 支持实例间慢速(配置)和快速网络状态的配置和迁移。例如,如果将虚拟机从一台终端主机迁移到另一台主机,不仅可以迁移相关的配置(SPAN 规则、ACL、QoS),还可以迁移任何活动的网络状态(包括可能难以恢复的现有状态)。此外,Open vSwitch 的状态由真实数据模型进行类型化和支持,从而能够开发结构化的自动化系统。
响应网络动态
虚拟环境的特点通常是快速变化。虚拟机不断创建和销毁,虚拟机的时间序列也在不断变化,逻辑网络环境也在不断变化,等等。
Open vSwitch 支持多种功能,使网络管理系统能够响应并适应环境变化。这些功能包括简单的流量计费和可视化支持,例如 NetFlow、IPFIX 和 sFlow。然而,Open vSwitch 对网络状态数据库 (OVSDB) 的支持或许更为实用,该数据库支持远程触发。这使得编排软件能够监控网络的各个方面,并在其发生变化时做出响应。目前,该功能已被积极用于响应和跟踪虚拟机迁移等操作。
Open vSwitch 还支持 OpenFlow 作为远程访问导出方法,用于流量管理。这有许多应用场景,包括通过发现流量或链路状态检测(例如 LLDP、CDP、OSPF 等)进行广域网发现。
逻辑标签维护
分布式虚拟交换机(例如 VMware vDS 和 Cisco Nexus 1000V)通常通过在网络数据包中添加或管理标签来维护网络中的逻辑上下文。这可用于唯一标识虚拟机(以防止硬件欺骗),或存储仅在逻辑域内有意义的其他上下文信息。创建分布式虚拟交换机的一大挑战在于如何有效且正确地管理这些标签。
Open vSwitch 包含多种用于指定和维护标记规则的方法,每种方法都可供远程进程访问以进行编排。此外,在许多情况下,这些标记规则以优化形式存储,因此无需与大型网络设备关联。这使得配置、修改和迁移数千条标记或地址重分配规则成为可能。
同样,Open vSwitch 支持 GRE 实现,能够处理数千个并发 GRE 隧道,并支持远程配置,用于创建、配置和禁用隧道。例如,这可用于连接不同数据中心的私有虚拟机网络。
设备集成
Open vSwitch 转发路径(内核内数据路径)旨在将数据包处理卸载到硬件芯片组,无论这些芯片组是位于传统的硬件交换机机箱内,还是位于终端主机的网卡中。这使得 Open vSwitch 控制路径能够同时管理纯软件实现和硬件交换机。
目前正在进行多项尝试,旨在将 Open vSwitch 移植到硬件芯片组上。这些尝试包括几种商用硅芯片组(博通和 Marvell),以及一些厂商特定的平台。文档的"移植"部分讨论了如何实现这种移植。
硬件集成带来的好处不仅限于虚拟化环境中的性能提升。如果物理交换机也提供 Open vSwitch 管理抽象层,那么物理和虚拟化主机环境都可以使用同一个自动化网络管理引擎进行管理。
在许多方面,Open vSwitch 针对的是与以往虚拟机管理程序网络堆栈不同的设计方向,它专注于大规模基于 Linux 的虚拟化环境中自动和动态网络管理的需求。
Open vSwitch 的目标是尽可能精简其内部代码(这对于性能至关重要),并在适用情况下重用现有子系统(例如,Open vSwitch 利用了现有的 QoS 协议栈)。从 Linux 3.3 开始,Open vSwitch 已集成到内核中,并且大多数主流发行版都提供了用户空间实用程序包。
关于VLAN,你需要了解什么
VLAN 是存在于 OSI 模型第二层(网络层)的虚拟网络,由第二层交换机实现。简单来说,VLAN 是将交换机端口分组,划分成逻辑网络段。每个网络段都有自己的标记(PVID 标签)。VLAN 端口组通过这些标签来识别自身所属的特定组。
端口分为两种类型:接入端口和干线端口。接入端口用于连接终端网络设备,而干线端口仅用于连接其他干线端口。当来自计算机的数据包进入接入端口时,交换机会为其添加 VLAN ID (PVID) 标签,然后仅将此数据包转发到具有相同 VLAN ID 的端口或干线端口。当帧发送到终端节点时,标签会被移除,因此终端节点无法感知自身所属的 VLAN。
当数据包到达干线端口时,它会被原样传输,不会移除标签。因此,在同一个干线端口内,可以传输带有多个标签(PVID)的数据包。
值得注意的是,接入端口可以配置为在输出时不清除标签。在这种情况下,终端客户端必须知道它连接到哪个 VLAN 才能接收数据包。并非所有网卡和/或操作系统默认都支持 VLAN。这通常取决于网卡驱动程序。
安装和入门
OpenVSwitch 软件包已包含在标准的 Ubuntu/Debian 软件仓库中,因此安装非常简单。运行以下命令:
`sudo apt install openvswitch-switch`ovs-vsctl 工具用于操作网络接口。让我们检查一下已安装的 OpenVSwitch 版本:
`sudo ovs-vsctl -V`实用程序输出:
`ovs-vsctl (Open vSwitch) 2.9.0
DB Schema 7.15.1`创建虚拟接口
要创建虚拟交换机,首先需要建立与真实网络设备的桥接。真实网络端口实际上将成为虚拟交换机的其中一个端口。
让我们搭建一座桥梁:
`sudo ovs-vsctl add-br bridgeswitch`向网桥添加网络接口:
`sudo ovs-vsctl add-port bridgeswitch eth0`现在您可以继续添加虚拟端口了:
`sudo ovs-vsctl add-port bridgeswitch test-interface -- set interface test-interface type=internal`在上面的命令中,我们指定创建一个名为 test-interface 的虚拟接口,并将其绑定到 bridgeswitch 网桥。在表示新行开始的双斜杠之后,我们指定接口类型。
可以创建无限数量的虚拟交换机,类似于虚拟接口。这些虚拟网络接口随后将连接到虚拟机。
就这样。现在,运行以下命令:
`sudo ovs-vsctl show`您可以查看所有网桥和虚拟接口的列表:
`ovs-vsctl show
8e5433c6-c82d-46b0-8378-543c40e4e9c0
Bridge bridgeswitch
Port test-interface
Interface test-interface
type: internal
Port "enp5s0"
Interface "eth0"
Port bridgeswitch
Interface bridgeswitch
type: internal
ovs_version: "2.9.0"`测试接口虚拟接口可以像普通物理接口一样使用,也就是说,它可以在本地计算机上进行配置。当需要使用单张网卡作为中继链路,使服务器能够在多个 VLAN 上运行时,此功能非常有用。或者,例如,当需要为服务器分配多个 IP 地址时。为此,您可以创建多个虚拟接口并分别进行配置。但是,我不建议这样做。如果遇到上述情况,最好使用 systemd-networkd 或 ip 命令。
要删除端口,请使用以下命令:
`sudo ovs-vsctl del-port bridgeswitch test-interface`拆除桥梁:
`sudo ovs-vsctl del-br bridgeswitch`添加 VLAN
使用 OpenVSwitch 的一大优势在于其对 VLAN 的支持。要实现这一点,您只需标记虚拟端口并将网卡配置为 trunk 接口即可。
让我们创建一个新的虚拟交换机:
`sudo ovs-vsctl add-br vlanswitch`向虚拟交换机添加一张真实的网卡:
`sudo ovs-vsctl add-port vlanswitch eth0`我们将交换机端口配置为干线端口,并描述将通过交换机的标签:
`sudo ovs-vsctl set port eth0 trunks=10,20,300,400,1000`添加虚拟网络接口并为其分配标签:
`sudo ovs-vsctl add-port vlanswitch testvlan20 tag=20 -- set interface testvlan20 type=internal`现在您可以查看配置信息:
`ovs-vsctl show
8e5433c6-c82d-46b0-8378-543c40e4e9c0
Bridge vlanswitch
Port vlanswitch
Interface vlanswitch
type: internal
Port "testvlan20"
tag: 20
Interface "testvlan20"
type: internal
Port "enp5s0"
trunks: [10, 20, 300, 400, 1000]
Interface "enp5s0"
ovs_version: "2.9.0"`在 OpenVSwitch 虚拟交换机上启用 NetFlow
如果需要跟踪通过接口的网络流量,您可以使用一条命令强制 OpenVSwitch 向收集器地址发送 Netflow 数据包:
`ovs-vsctl -- set Bridge vlanswitch netflow=@nf /
-- --id=@nf create NetFlow targets="192.168.1.1:5566" /
active-timeout=30`您只需指定虚拟交换机的名称、IP 地址和目标端口,以及数据发送的时间间隔(以秒为单位)。
要更新或更改上一个命令中指定的参数,请运行:
`ovs-vsctl set Netflow vlanswitch active_timeout=60`要停止向 Netflow 收集器发送数据,只需清除虚拟交换机的 Netflow 设置即可:
`ovs-vsctl clear Bridge vlanswitch netflow`网络基础知识
如果你正在阅读这篇文章,你可能已经了解网络是什么了。值得注意的是,几乎所有公司都有一些内部服务,并为此构建了所谓的局域网 (LAN)。不过我们稍后再详细讨论。为了让运行不同操作系统和程序的计算机能够相互交互,存在一个名为 OSI 的通用网络模型,它定义了相关标准。该模型将交互过程划分为多个步骤,称为"层",每一层都有自己的规则。这些规则定义了交互的具体方式,被称为协议。你可能在其他地方见过一些协议的名称------例如 IP、DNS 和 HTTP。虽然标准的 OSI 模型假定有七层,但管理员通常只使用第二层、第三层和第四层,并将第五层、第六层和第七层合并为一层,通常称为第七层。

第一层是物理层,涉及物理交互的标准和技术。这些技术多种多样,包括以太网、Wi-Fi 和光纤。为了连接到网络,每台计算机都配备了网络适配器------最常见的是以太网适配器,笔记本电脑则配备 Wi-Fi 适配器。

你在工作中很可能会用到以太网。连接电脑时,需要使用特定类型的网线,现在最常用的是五类线(Cat 5)。它由八根铜线组成,用于传输信号。这些网线按照特定标准两两绞合,这样一对线就叫做双绞线。你的工作可能需要将这些网线剪到所需的长度,插入连接器,然后进行压接。你可以搜索"双绞线压接"或者在YouTube上找找相关视频,因为面试中经常会问到这方面的问题。
五类线(Cat 5)支持高达每秒 1 千兆比特 (1 Gbps) 的传输速度。Gbps 代表千兆比特每秒。网络速度以比特为单位,要了解以字节为单位的吞吐量,只需除以 8,因为 1 字节等于 8 比特。因此,理想情况下,五类线可以以每秒 1024/8 = 128 兆字节的速度传输文件。然而,实际速度会略低一些,因为网络环境也会影响传输速度。
在第二层,即数据链路层,计算机可以相互区分。为此,每个网络适配器的每个端口都有一个特殊的 MAC 地址。它由 12 个字母和数字组成,中间用两个冒号分隔------例如 00:1B:44:11:3A:B7。MAC 地址是唯一的,由适配器制造商在工厂设置。由于 MAC 地址可以识别其他计算机,因此可以将更多计算机连接起来。虽然可以拥有很多计算机,但每台计算机都有数百个端口,并在计算机之间铺设数千条电缆是不现实的。
交换机,通常简称为交换机,最常用于将多台计算机连接到同一个网络中。最简单的交换机通常拥有大量的端口------从 4 个到 96 个不等,甚至还有一些特殊的端口。如果端口数量不足,或者设备位于不同的楼层,则可以使用多个交换机相互连接。交换机至少拥有一个 MAC 地址表------交换机会记录每个端口对应的 MAC 地址。当一台计算机想要连接到另一台计算机时,它会访问特定的 MAC 地址;交换机识别到该地址后,会通过其端口连接两台设备。
但这种方法只适用于计算机数量不多的情况------十几台,一百台,仅此而已。如果计算机数量很多,有些计算机的 MAC 地址可能会改变,例如更换网卡后,而直接使用 MAC 地址会很不方便。因此,MAC 地址通常只用于局域网。例如,在家中有多台设备的情况下,或者在小型办公室、大型公司的部门等等。想象一下一座小城市。每栋楼都是一台计算机。局域网就像连接这些楼宇的街道。
所以,OSI模型的第三层是网络层。它引入了IP地址的概念。局域网中的每台计算机都有一个IP地址,就像城市里的每栋建筑都有自己的地址一样。IP地址使得不同网络上的计算机能够通信。实际上,局域网也使用IP地址;计算机只需通过IP地址找到对应的MAC地址即可。IP协议有不同的版本:IPv4和IPv6。更流行、更简单的是IPv4,我们将重点讨论它。

所以,IP 地址由四个用句点分隔的数字组成。这些数字的范围从 0 到 255。因此,严格来说,一个 IP 地址由四个字节组成,每个字节可以容纳八位,每位可以包含两个值。也就是说,IP 地址的数量是 2 的八次方,大约有 40 亿个。但这还不够------一台计算机可以拥有多个地址,每个虚拟机可以拥有自己的地址,电话和其他设备也可以拥有自己的地址------简而言之,很多东西都可以拥有地址。但是,网络允许不同的计算机拥有相同的地址,即使它们不在同一个局域网内。
假设大多数人家里的 IP 地址都相同,比如 192.168.0.100。以城市为例,不同的城市可以拥有相同的地址,比如"列宁大街 20 号"。这在同一个城市里肯定不合适,但在不同的城市里却完全没问题。
为了帮助计算机区分哪些地址位于同一网络,哪些地址位于其他网络,需要使用子网掩码。子网掩码位于 IP 地址旁边,由四个用句点分隔的数字组成,每个数字的值介于 0 到 255 之间。例如,我们来看一个最常见的子网掩码,很可能就是你家里使用的:255.255.255.0。最后一个数字 0 表示你的网络可以有 256 个地址。但是,第一个和最后一个值实际上是保留的。在这个例子中,0 用作网络地址,也就是你所在的城市地址。而 255 是广播地址,用于寻址网络上的所有计算机。假设你的电脑的 IP 地址是 192.168.0.100,子网掩码是 255.255.255.0,那么它的本地网络就是地址从 192.168.0.1 到 192.168.0.254 的电脑,网络地址是 192.168.0.0,广播地址是 192.168.0.255。顺便一提,子网掩码通常写成 /24。这意味着前三个数字是 255,这是 8 位二进制数的最大值。8 + 8 + 8 = 24。今天我们就不深入讨论子网了,继续往下看。
为什么是 192.168?这是一系列预留的 IP 网络,专供家庭和企业内部使用。当您拜访其他人或企业时,会遇到类似的子网和 IP 地址。
假设一台计算机发现某个 IP 地址位于另一个网络上,它是如何访问该地址的呢?这可以通过一种称为路由的机制来实现,通常简称为"路由"。路由器通常用于此目的,例如您家中的路由器。它与您处于同一网络,但也可以访问另一个网络,从而将您网络上的计算机与其他网络上的计算机连接起来。路由器通常会被分配边界 IP 地址(1 或 254),以明确表明它是一台路由器。在计算机上配置 IP 地址时,您还可以指定网关,然后输入路由器的地址。如果您指定了网关,则计算机在需要连接到另一个网络时会联系路由器,然后路由器会与该网络通信。但是,路由器不会传输 MAC 地址,只会传输 IP 地址。
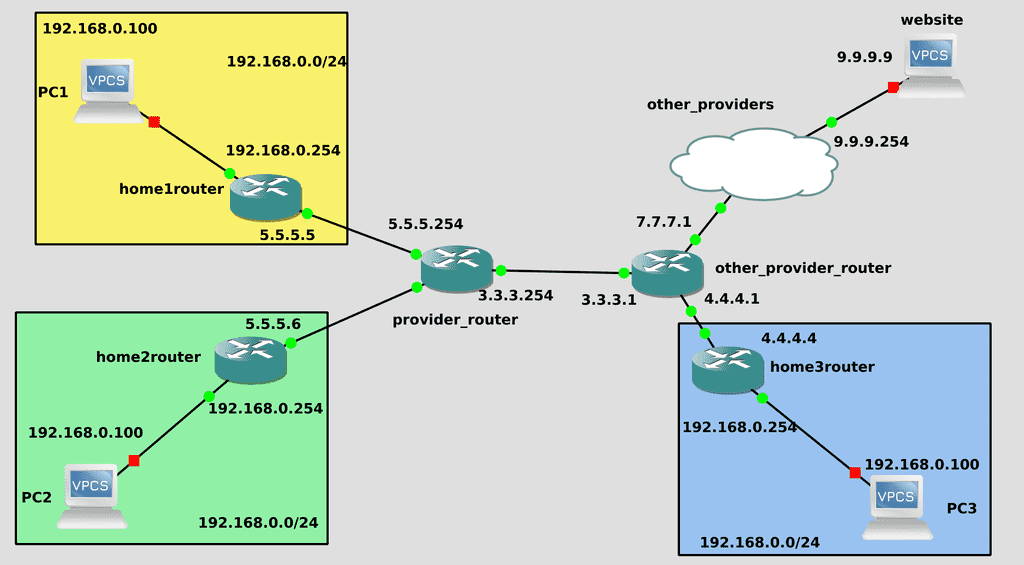
互联网,简单来说,就是由路由器和交换机组成的网络。你家里的路由器连接到你的网络服务提供商(ISP)的路由器,而你的ISP的路由器又连接到其他ISP的路由器。所有这些连接构成了互联网。看看这张图:家用电脑可以拥有相同的IP地址。你无法从互联网访问你的家庭网络(192.168.0.0),因为它是私有的,任何人都可以设置。但是,你的路由器也有一个外部地址,例如5.5.5.5。当你访问互联网时,你的路由器会将你的外部地址替换成它自己的地址,这样你才能收到响应。这项技术叫做NAT------网络地址转换。例如,如果一个网站收到来自192.168.0.100的请求,它就不知道该把响应发送到哪里。但是,当你发出请求时,你的路由器会伪造IP地址,网站看到的是5.5.5.5,并会做出相应的响应。然后路由器会将响应转发给你,因为有了 NAT,它会记住你的请求并等待响应。
同时,任何网站或互联网上的任何其他计算机都无法直接访问您的计算机,原因在于 192.168.0.0 无法从互联网访问。其他计算机可以访问您的外部地址 5.5.5.5,但路由器本身不会将请求转发到您的计算机,因为这样做太危险,互联网上充斥着大量恶意软件。NAT 还允许多台计算机从同一个外部 IP 地址访问互联网。例如,您的手机、电脑、笔记本电脑和电视都使用同一个地址访问互联网。公司通常会在成百上千台计算机上使用这种方法。安全性和 IP 地址保护。
一家公司可能拥有多个网络,例如服务器网络和用户网络。在这种情况下,通常不使用NAT,因为用户能够访问服务器以及服务器能够连接到用户计算机都至关重要。因此,公司不会为公司内部的所有网络使用相同的IP地址。
所以,以上所有内容都属于OSI模型的第三层------第三层,简称L3。前三层构成了一张连接图,就像城市里的道路一样。图中有很多房子,每栋房子都有自己的地址,每栋房子都位于一个城市里。要从一个城市到另一个城市,你需要先到城市的出口,再到下一个城市,最后到达目标房屋。计算机---路由器---另一个路由器---另一台计算机。但是网络的目的不是为了到达某个地方,而是为了传递数据包,或者用计算机术语来说,就是传递信息包。计算机一需要将一个数据包传递给计算机二。
现在我们来到了第四层------运输。包裹的形式多种多样,递送方式也各不相同。例如,在美国电影里,邮递员早上会把报纸送到家家户户。如果风吹走了报纸,或者被狗叼走了------没关系,它只是一份报纸而已。假设网络数据包传输(NTP)的工作原理也是如此。你的电脑可以向服务器请求当前时间,服务器会将响应发送回你的电脑。比如说,这个过程每10分钟发生一次。但如果你的电脑没有收到响应------可能是网络出现了一个小故障------也没关系。你可以在10分钟后再次请求。所以数据包已经发送出去了,但发送方不需要知道它是否已送达。这种传输协议叫做UDP。
但很多时候,数据包可能包含重要信息,丢失这些信息是不可取的。在这种情况下,会使用另一种协议,即 TCP。在 TCP 连接中,发送方必须确保数据包已到达,并等待接收方的确认。如果在一定时间内没有收到响应,发送方会重新发送一份数据包副本。
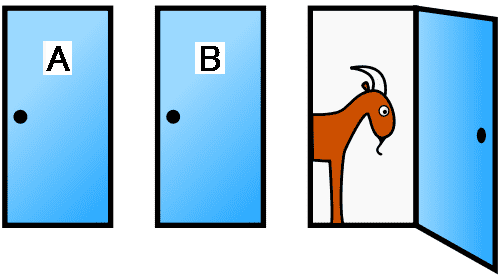
在这个阶段,我们还会学习端口。不是物理端口,而是 TCP 或 UDP 端口。如果把计算机比作一栋房子,那么端口就是这栋房子里的一间公寓。而且所有房子都是多户公寓楼。你不能直接把包裹送到家门口------快递员必须上门取件并送到门口。每扇门后都住着一个特定的人,执行着特定的任务。假设你通过浏览器访问一个网站,你的计算机使用特定的端口发送请求。浏览器知道网站是由一个网络服务器提供的,而这个服务器运行在 80 端口上。所以快递员会找到一个具有特定 IP 地址的特定房子,敲响 80 号门。他会等待一段时间。如果网络服务器确实在那里,它就会响应快递员的请求,把数据包交给他,然后快递员再把响应返回到发送请求的端口。如果80号门没人,失望的快递员就会空手而归,浏览器也会报告无法连接到网络服务器。服务器最多可以有65000个端口,但通常只使用3-4个端口接收数据,而发送端口则是动态分配的,取决于连接数。
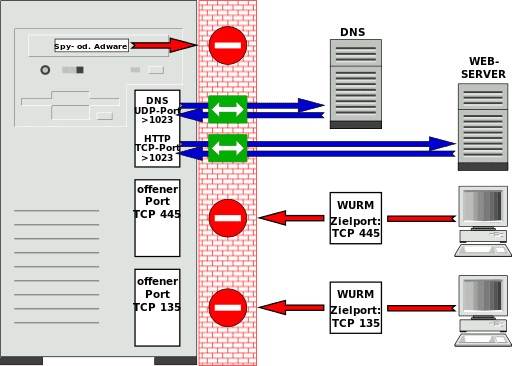
我们先来快速了解一下防火墙的概念。您可能不希望除了您自己或特定人员之外的任何人连接到您服务器上的某些端口。您也可以在家门口安排保安迎接快递员------如果有人不遵守保安的规则,保安就会拒绝其进入。这些规则通常会指定哪些地址可以访问哪些端口,哪些地址不能访问。这些被称为个人防火墙,它们内置于系统本身。网络防火墙通常安装在路由器上------它们就像城市入口处的保安岗亭一样,在网络入口处进行检查。
TCP 和 UDP 端口是应用程序本身所在的位置------通常是在系统上运行的守护进程。它们分别对应 OSI 模型的第 5、6 和 7 层。一个端口对应一个程序,但一个程序可以占用多个端口。例如,一个 Web 服务器可能同时使用 80 和 443 端口。程序使用哪些端口是有标准的。虽然可以更改这些设置,但您必须清楚自己在做什么。例如,如果您更改了 Web 服务器的默认端口,浏览器将无法打开网站,直到您手动在浏览器中指定端口。但普通用户并不了解这一点,他们又如何知道您更改了哪个端口呢?
包括Web服务器和浏览器在内的程序已经在这个层面上运行。这两个程序都使用诸如HTTP之类的协议进行通信。正如浏览器各不相同一样,充当Web服务器的服务器上的程序也各不相同。正是由于使用了单一的HTTP协议,才使得所有人都能相互通信,而无需考虑浏览器、Web服务器或操作系统。
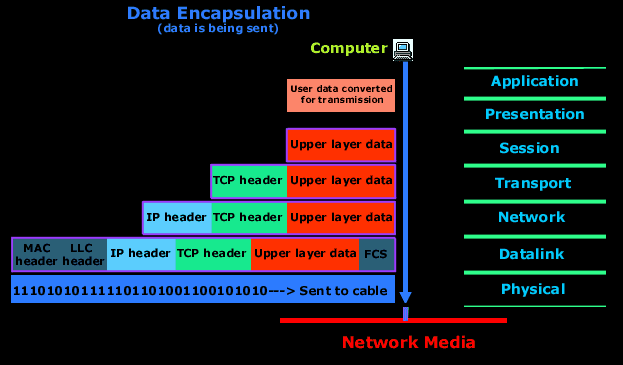
我们已经简要介绍了 OSI 模型。当一台计算机尝试向另一台计算机发送数据时,这个过程类似于打包和发送盒子。例如,你想打开一个网页。你的浏览器会将你的请求打包成一个包含 HTTP 信息的盒子。然后,你的操作系统会接收这个盒子,并在上面贴上另一张标签,添加 TCP 信息:请求的源端口和目标端口。接着,它会添加另一张标签------请求的源 IP 地址和目标 IP 地址。然后,它会添加另一张标签------请求的源 MAC 地址和目标 MAC 地址。之后,计算机将接收到的数据包转换成 0 和 1 组成的二进制数据,并将其发送到交换机。整个过程称为封装。交换机转换数据包的开头部分,并查找要发送的 MAC 地址------路由器。它在 MAC 地址表中找到了路由器的 MAC 地址------端口 12。交换机将数据包发送到路由器。路由器解封装数据包,并查找要发送的地址。假设路由器不知道这个地址,于是它撕下三层标签,换上自己的标签,将你的IP地址替换成自己的地址进行NAT转换,并将你的标签保存在自己的存档中。然后,它将这个地址发送到它的网关------另一个路由器。另一个路由器也展开这个地址,查看后发现无法识别,于是将其发送到它的网关------第三个路由器。在中间的某个节点,还有更多的交换机和路由器,这个过程重复数十次,直到最终到达正确的服务器。最终,它到达了正确的路由器,该路由器在其网络中识别出正确的服务器,将标签替换成MAC地址,然后将其发送到正确的服务器。服务器将0和1转换成数据,识别出自己的MAC地址,并确认这是自己的地址。它开始撕下更多的标签,发现请求发送到了它的IP地址。它撕下另一个标签,发现TCP端口是80。防火墙监控最后两个步骤------是否允许从这个IP地址向端口80发送数据包?如果成功,数据包最终会到达网络服务器。然后,网络服务器准备响应,将其分发到不同的数据包中,开始封装,并将其发送到路由器。整个过程在瞬间完成,用户完全感觉不到,却能跨越陆地和海洋的广阔距离。
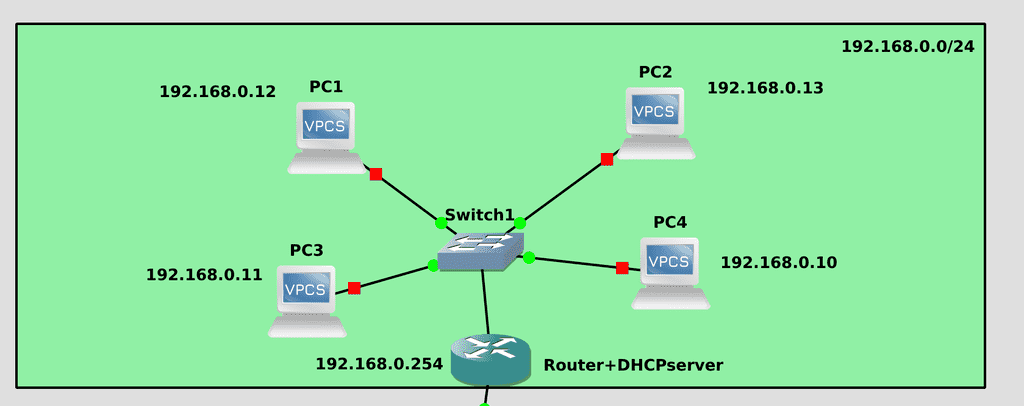
好了,我们已经了解了两台计算机如何通信。现在值得一提的是两个确保易用性的重要协议。虽然没有它们也能工作,但会很困难。我们先来看看 DHCP。该协议允许动态分配 IP 地址。与 MAC 地址不同,IP 地址并非出厂时就已分配;它是在每台计算机上单独配置的。但是,手动为每个用户分配不同的地址是不可行的。首先,这需要特定的知识;其次,当计算机数量庞大时,这样做非常不方便。因此,网络中通常会有一个 DHCP 服务器------它可以是家用路由器、智能交换机,甚至是独立的 Linux 虚拟机。当计算机连接到网络时,它会向网络上的所有设备发送一个特殊请求,询问网络上是否存在 DHCP 服务器。DHCP 服务器收到此请求后会响应用户。DHCP 服务器会从可用的 IP 地址中选择一个分配给用户,并将该地址以及子网掩码、网关地址和其他设置一并发送给用户。在服务器上,IP 地址通常是静态分配的,即手动且永久分配;而在用户的计算机上,IP 地址则是动态分配的,这意味着下次开机时这些地址可能会发生变化。
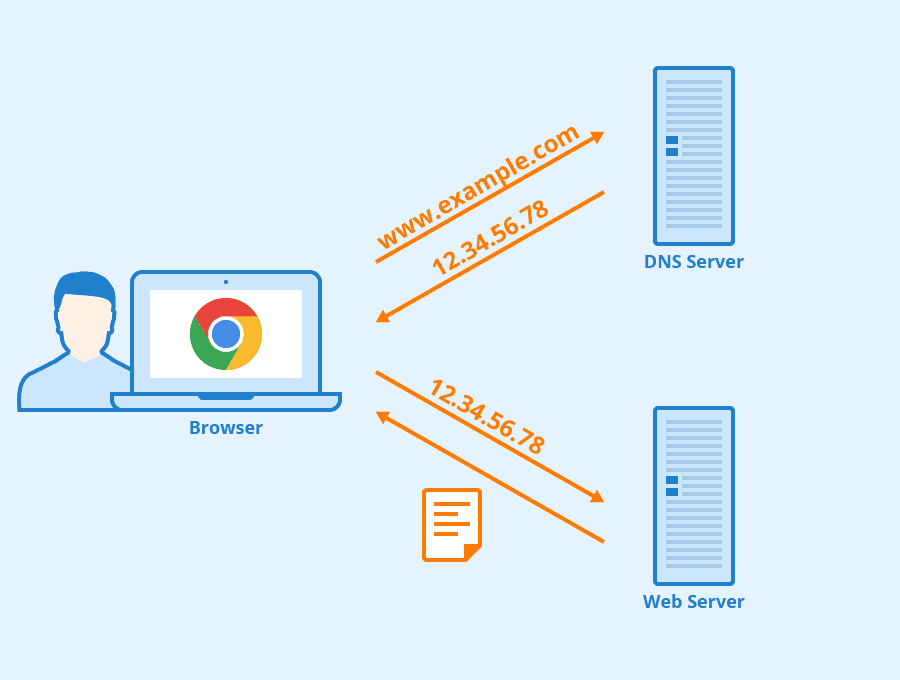
第二个协议是 DNS,它负责将 IP 地址转换为域名,将域名转换为 IP 地址,以此类推。你不会直接在浏览器中输入 Google 的 IP 地址吧?Google 拥有众多服务器,你又怎么知道它们的 IP 地址,又为什么要记住它们呢?在浏览器中,你输入想要连接的域名------google.com。然后,你的浏览器会向特定的 DNS 服务器发送 DNS 请求。这些服务器也是在你设置网络时配置的,并且可以通过 DHCP 服务器分配。所以,如果你在浏览器中输入 google.com,你的浏览器会向系统中注册的 DNS 服务器发送包含该域名的请求。DNS 服务器要么知道这个地址,要么会联系其他 DNS 服务器,而这些服务器可能也会继续联系该服务器,直到找到对应的域名。最终,DNS 会返回 IP 地址,然后你的浏览器会向该地址发送 HTTP 请求。
网络是一个庞大而复杂的机制,但对最终用户来说,它已被简化到如同开关灯一般简单易用。在中大型企业中,网络由专门的网络管理员部门负责管理,这些管理员拥有多年的网络研究经验。
简要介绍网络流量
让我们继续这篇文章。
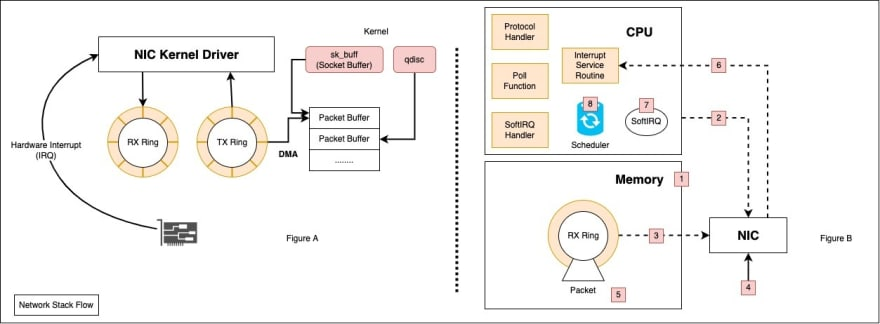
图 B: 内核分配及数据包流经内核的简要说明:
- 在内核启动过程的早期,CPU 分配数据包缓冲区(接收缓冲区和发送缓冲区)并构建文件描述符。2
) CPU 通知网卡已创建新的描述符,网卡可以开始使用。3
) DMA(直接访问内存)检索描述符。4
) 数据包到达网卡。5
) DMA 将数据包写入接收环形缓冲区。6 ) 网卡通知驱动程序,驱动程序再通知 CPU 可以使用硬件中断 (IRQ)
处理新的流量 。8 ) 在第一次硬件中断之后,中断处理程序会屏蔽该中断,驱动程序转而使用 软件中断 (SoftIRQ) ,这对于 CPU 来说开销要小得多(硬件中断无法被中断,这会极大地增加 CPU 的开销)。9 ) SoftIRQ 唤醒 NAPI 子系统,NAPI 子系统调用网卡驱动程序的轮询函数。10 ) CPU 处理传入的数据包。10) 当软中断预算经过一定时间后,NAPI 系统将重新进入睡眠状态。如果软中断预算耗尽,CPU 将转而执行下一个任务,并且 /proc/net/softnet_stats 文件中的time_squeezed 计数器 将加 1。
初始化网络适配器时,驱动程序执行以下操作:
1)在内存(DMA 空间)中分配接收和发送队列。2
)启用默认情况下禁用的 NAPI。3
)注册中断处理程序。4
)启用硬件中断。