前言:
归一化(Normalization) 的本质是对神经网络的输入 / 中间特征进行「标准化处理」,核心目标有 4 点。
- 缓解梯度消失 / 爆炸:避免特征值过大或过小导致梯度趋近于 0 或无穷大(尤其深层网络如 ResNet);
- 加速训练收敛:减少特征分布的波动(Internal Covariate Shift,内部协变量偏移),让模型更快找到最优解;
- 降低初始化敏感度:无需过度精细调整权重初始化,提升模型稳定性;
- 正则化效果:轻微抑制过拟合(如 BN 对 batch 内样本的统计平均相当于微弱的噪声注入)
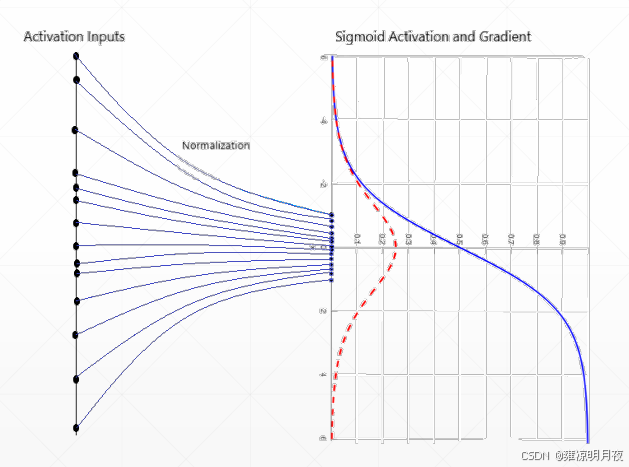
常见的有很多归一化的方法,所有归一化的方法核心差异在于归一化的维度(即对哪个维度的特征计算均值和方差),在不同维度上进行归一化。
接下来以常见的CNN中常用的
4D 特征张量 (N, C, H, W)(N=batch size,C = 通道数,H = 高度,W = 宽度)
为基础进行详解。
1.Batch Normalization (BN)
核心思想:跨样本、按通道归一化。
在整个 batch 的所有样本(N 个)和空间位置(H×W 个像素)上计算均值和方差,实现「通道内全局标准化」。
数学原理:
其本质上就是在原本的归一化基础上添加了可学习参数也就是缩放系数和平移系数。


其以batch为基础单位,将γ(缩放因子)和β(平移因子)也作为w一样通过反向传播算法更新梯度,找到最合适的值进行缩放平移。
⭐关键细节:
- 训练时:均值和方差是当前单批次数据中,按特征维度独立计算的局部统计量(每个维度用自己的 batch 均值 / 方差);
- 推理时:均值和方差是训练阶段通过指数移动平均累积的全局统计量(running_mean/running_var),而非所有批次统计量的简单算术平均。
- BN只改变张量的数值分布,不改变张量的形状,输入输出维度完全一致。
- 常见的batch取值取决于电脑显存,常见的8,16,32,64。不要超过64。
拓展:
- 算术平均需要记录所有批次的统计量,训练结束后再统一计算,内存开销大;
- 指数移动平均是 "实时累积",只需维护两个变量(running_mean/running_var),内存高效,且能动态跟踪统计量的变化(前期批次的权重会随训练推进逐渐降低,更侧重后期稳定的批次统计量)。
| 优点 | 缺点 |
|---|---|
| 加速训练收敛效果最明显 | 对 batch size 敏感(N<8 时统计量不准,性能下降) |
| 有效缓解梯度消失(尤其深层网络) | 测试时依赖移动平均,需谨慎处理训练 / 测试切换 |
| 自带轻微正则化效果 | 不适合序列长度不固定的任务(如 NLP 变长句子) |
实例:
python
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Project :Pytorch
@File :BN.py
@IDE :PyCharm
@Author :wjj
@Date :2025/12/25 13:48
@Description:BN
"""
# 导入PyTorch核心库和神经网络模块库
import torch
import torch.nn as nn
# 1. 独立 BN 模块使用
bn = nn.BatchNorm2d(num_features=64) # num_features = 通道数 C
# 2.创建测试输入张量x
x = torch.randn(16, 64, 32, 32) # (N=16, C=64, H=32, W=32)
y = bn(x)
#BN只改变张量的数值分布,不改变张量的形状,输入输出维度完全一致
print(f"BN 输入形状: {x.shape}, 输出形状: {y.shape}") # 输出形状与输入一致
class BasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
# 主路径:Conv → BN → ReLU → Conv → BN
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
# shortcut 路径(残差连接):处理通道数/步长不匹配
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels) # shortcut 也需 BN 保持分布一致
)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out) # 卷积后立即 BN
out = nn.functional.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += self.shortcut(x) # 残差相加
out = nn.functional.relu(out)
return out
# 测试残差块
res_block = BasicBlock(in_channels=64, out_channels=64, stride=1)
x = torch.randn(16, 64, 32, 32)
y = res_block(x)
print(f"残差块输出形状: {y.shape}") # (16, 64, 32, 32)2. Layer Normalization (LN)
**核心思想:**跨通道、按样本归一化
对每个样本 N_i,在所有通道(C 个)和空间位置(H×W 个像素)上计算均值和方差,实现「样本内全局标准化」。
数学原理:

关键细节
- 无 batch 依赖:统计量仅来自单个样本,不受 batch size 影响(即使 N=1 也能正常工作);
- 训练 / 测试一致:无需移动平均,直接用当前样本的统计量,实现更简单。
适用场景
- NLP 任务(如 Transformer、RNN):序列长度不固定(如句子长度差异大),batch 维度统计不稳定;
- 小 batch 场景(如医学图像,N=2~4):BN 统计量不准,LN 更稳健;
| 优点 | 缺点 |
|---|---|
| 与 batch size 无关,稳定性强 | CNN 中收敛速度和精度通常低于 BN |
| 训练 / 测试逻辑一致,无额外开销 | 缺乏跨样本的统计信息,正则化效果较弱 |
| 适合变长序列(NLP)和小 batch 任务 | 通道间共享缩放平移参数,灵活性略低 |
案例:
python
import torch
import torch.nn as nn
# 1. NLP 场景(输入形状:(N, seq_len, d_model),d_model=通道数)
ln_nlp = nn.LayerNorm(normalized_shape=512) # normalized_shape = 最后一维(d_model)
x_nlp = torch.randn(32, 10, 512) # (N=32, seq_len=10, d_model=512)
y_nlp = ln_nlp(x_nlp)
print(f"LN(NLP) 输入形状: {x_nlp.shape}, 输出形状: {y_nlp.shape}")
# 2. CNN 场景(输入形状:(N, C, H, W),normalized_shape=(C, H, W))
ln_cnn = nn.LayerNorm(normalized_shape=(64, 32, 32)) # 需指定最后三维(C, H, W)
x_cnn = torch.randn(16, 64, 32, 32)
y_cnn = ln_cnn(x_cnn)
print(f"LN(CNN) 输入形状: {x_cnn.shape}, 输出形状: {y_cnn.shape}")
# 3. Transformer 中的 LN 应用(Pre-LN 结构:LN → Attention → Add → LN → FFN → Add)
class TransformerLayer(nn.Module):
def __init__(self, d_model=512, nhead=8):
super().__init__()
self.ln1 = nn.LayerNorm(d_model)
self.self_attn = nn.MultiheadAttention(d_model, nhead, batch_first=True)
self.ln2 = nn.LayerNorm(d_model)
self.ffn = nn.Sequential(
nn.Linear(d_model, 2048),
nn.ReLU(),
nn.Linear(2048, d_model)
)
def forward(self, x):
# 自注意力模块
out = self.ln1(x) # Pre-LN:先归一化再计算
out, _ = self.self_attn(out, out, out)
x = x + out # 残差连接
# 前馈网络
out = self.ln2(x)
out = self.ffn(out)
x = x + out
return x
# 测试 Transformer 层
trans_layer = TransformerLayer()
x = torch.randn(32, 10, 512)
y = trans_layer(x)
print(f"Transformer 层输出形状: {y.shape}") # (32, 10, 512)3.Instance Normalization (IN)
核心思想
单样本、单通道归一化 :对每个样本 N_i 的每个通道 C_j,仅在该通道的空间位置(H×W 个像素)上计算均值和方差,实现「样本 - 通道内局部标准化」。
数学原理

关键细节
- 完全独立于 batch:统计量仅来自单个样本的单个通道,与其他样本无关;
- 保留样本特异性:适合需要保持单个样本风格 / 特征独立性的任务(如风格迁移中,每个图像的风格需独立归一化)。
适用场景
- 图像风格迁移(如 CycleGAN、StyleGAN):归一化单个图像的每个通道,避免 batch 内样本风格混淆;
- GAN 生成器:生成样本时保持独立性,提升生成质量;
- 医学图像分割:单个样本(如 CT 切片)的通道特征需独立标准化。
| 优点 | 缺点 |
|---|---|
| 完全独立于 batch,稳定性极强 | CNN 分类任务中精度低于 BN/GN |
| 保留样本 - 通道特异性,适合风格迁移 | 缺乏跨样本 / 跨通道的统计信息,泛化能力较弱 |
案例:
python
import torch
import torch.nn as nn
# 1. 独立 IN 模块使用
in_norm = nn.InstanceNorm2d(num_features=3) # num_features = 通道数(如 RGB 图像 C=3)
x = torch.randn(8, 3, 256, 256) # (N=8, C=3, H=256, W=256) 风格迁移常用 RGB 图像
y = in_norm(x)
print(f"IN 输入形状: {x.shape}, 输出形状: {y.shape}")
# 2. 风格迁移生成器中的 IN 应用(Conv → IN → ReLU)
class StyleGeneratorBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.in_norm = nn.InstanceNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
out = self.conv(x)
out = self.in_norm(out) # 卷积后 IN 归一化,保留风格特征
out = self.relu(out)
return out
# 测试生成器块
gen_block = StyleGeneratorBlock(3, 64)
x = torch.randn(8, 3, 256, 256)
y = gen_block(x)
print(f"风格生成器块输出形状: {y.shape}") # (8, 64, 256, 256)4.Group Normalization (GN)
核心思想
单样本、按通道分组归一化 :将通道 C 分成 G 个组(每组 C/G 个通道),对每个样本 N_i 的每个组 G_j,在组内通道和空间位置(H×W)上计算均值和方差,实现「样本 - 组内标准化」。
数学原理

关键细节
- 分组策略 :PyTorch 中
num_groups需整除num_features(如 C=64 可分 8 组,每组 8 通道); - BN 与 IN 的特例 :
- 当
G=1时,GN 等价于 LN(所有通道为一组,样本内全局归一化); - 当
G=C时,GN 等价于 IN(每个通道为一组,样本 - 通道内归一化)。
- 当
适用场景
- 小 batch CNN 任务(如目标检测、语义分割):batch size 通常为 2~8,BN 统计量不准,GN 性能更优;
- 残差网络小 batch 场景:替代 BN 避免训练不稳定;
| 优点 | 缺点 |
|---|---|
| 与 batch size 无关,小 batch 性能优于 BN | 分组数需手动调整(通常设为 8/16,需验证) |
| 兼顾跨通道(组内)和样本独立性,泛化能力强 | 计算量略高于 BN/IN(但可忽略) |
| 无需移动平均,训练 / 测试一致 | 大 batch 场景下精度略低于 BN |
案例:
python
import torch
import torch.nn as nn
# 1. 独立 GN 模块使用
gn = nn.GroupNorm(num_groups=8, num_features=64) # 64 通道分 8 组,每组 8 通道
x = torch.randn(4, 64, 64, 64) # (N=4 小 batch,C=64,H=64,W=64) 检测任务常用输入
y = gn(x)
print(f"GN 输入形状: {x.shape}, 输出形状: {y.shape}")
# 2. 检测网络(如 Faster R-CNN)中的 GN 应用
class DetectorBlock(nn.Module):
def __init__(self, in_channels, out_channels, num_groups=8):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.gn1 = nn.GroupNorm(num_groups, out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.gn2 = nn.GroupNorm(num_groups, out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
out = self.conv1(x)
out = self.gn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.gn2(out)
out += x # 残差连接
out = self.relu(out)
return out
# 测试检测块
det_block = DetectorBlock(64, 64)
x = torch.randn(4, 64, 64, 64)
y = det_block(x)
print(f"检测块输出形状: {y.shape}") # (4, 64, 64, 64)*5.Spectral Normalization (SN)
核心思想
对权重矩阵做谱归一化 :不直接归一化特征,而是对神经网络的权重矩阵 W 进行标准化,限制其「谱范数(Spectral Norm)」≤1,从而控制模型的 Lipschitz 常数,避免 GAN 训练中的模式崩溃。
数学原理

适用场景
- GAN 模型(如 DCGAN、WGAN-GP):稳定生成器和判别器的训练,避免模式崩溃;
- 生成任务(图像生成、文本生成):提升生成样本的多样性和质量。
| 优点 | 缺点 |
|---|---|
| 有效稳定 GAN 训练,减少模式崩溃 | 仅对权重归一化,对特征分布无直接优化 |
| 计算开销小(幂迭代法效率高) | 不适用于分类 / 回归等判别任务(增益有限) |
代码案例:
python
import torch
import torch.nn as nn
import torch.nn.utils.spectral_norm as sn
# GAN 判别器(使用谱归一化)
class GANDiscriminator(nn.Module):
def __init__(self, in_channels=3):
super().__init__()
self.model = nn.Sequential(
# 对卷积层权重应用谱归一化
sn(nn.Conv2d(in_channels, 64, kernel_size=4, stride=2, padding=1, bias=False)),
nn.LeakyReLU(0.2, inplace=True),
sn(nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1, bias=False)),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
sn(nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1, bias=False)),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2, inplace=True),
sn(nn.Conv2d(256, 1, kernel_size=4, stride=1, padding=0, bias=False)),
nn.Sigmoid()
)
def forward(self, x):
return self.model(x)
# 测试判别器
disc = GANDiscriminator()
x = torch.randn(8, 3, 64, 64) # (N=8, C=3, H=64, W=64)
y = disc(x)
print(f"GAN 判别器输出形状: {y.shape}") # (8, 1, 1, 1) (每个样本的真实/伪造概率)总结
1.归一化图像
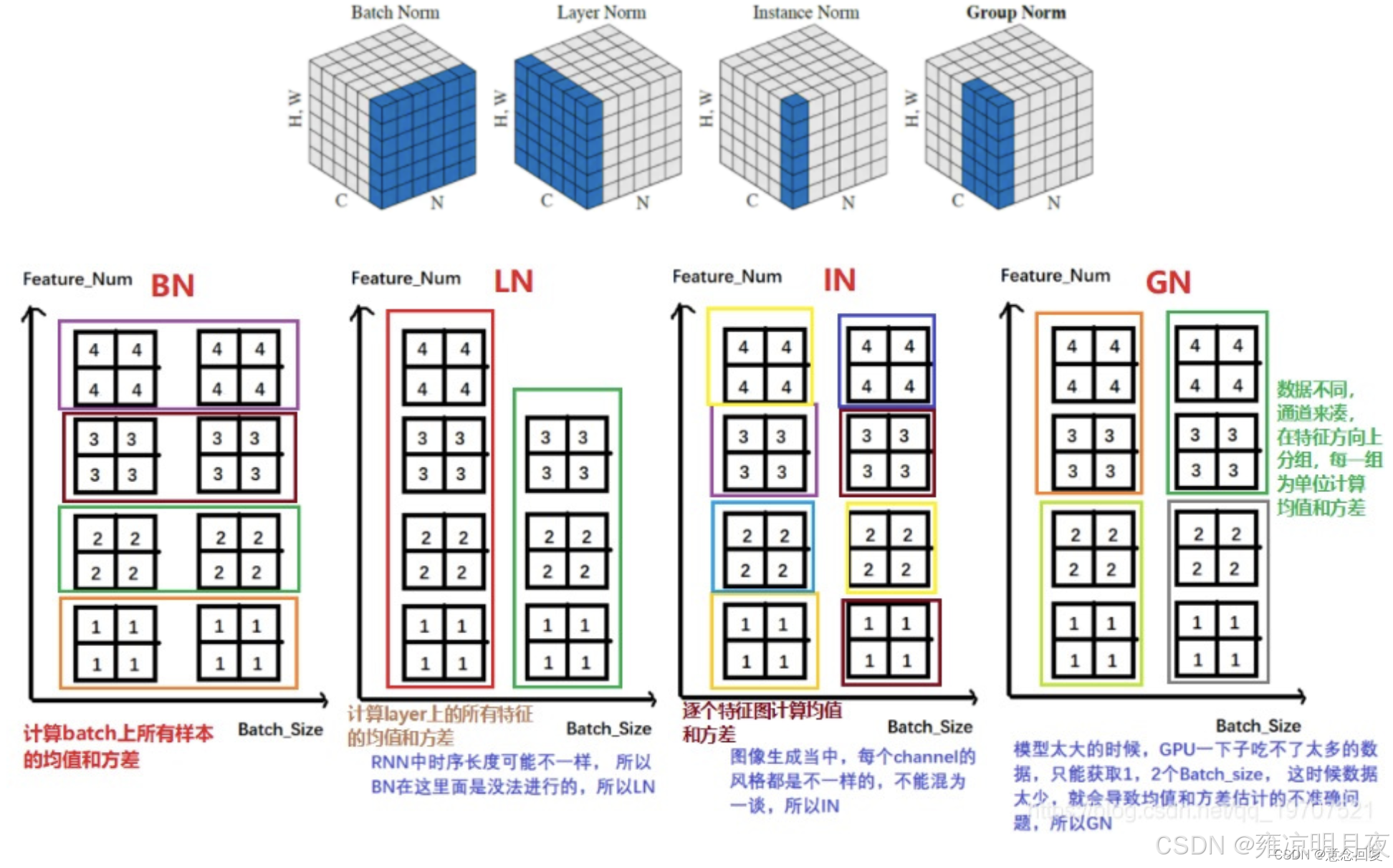
| 归一化方法 | 归一化维度(输入 N,C,H,W) | 统计量来源 | 训练 / 测试差异 | 核心适用场景 | batch 敏感性 |
|---|---|---|---|---|---|
| BN | 通道内(N×H×W) | 跨样本 + 通道 | 有(移动平均) | CNN、残差网络、大 batch | 高(N≥16 最优) |
| LN | 样本内(C×H×W) | 单样本 + 跨通道 | 无 | NLP、Transformer、小 batch | 无 |
| IN | 样本 - 通道内(H×W) | 单样本 + 单通道 | 无 | 风格迁移、GAN | 无 |
| GN | 样本 - 组内(C_g×H×W) | 单样本 + 组内通道 | 无 | 检测 / 分割(小 batch)、残差网络 | 无 |
| SN | 权重矩阵(无特征维度) | 权重奇异值 | 无 | GAN 生成 / 判别器 | 无 |
2.工程实践选择指南(关键!)
- CNN 分类任务(如 ResNet、VGG) :
- 优先用 BN(batch size ≥16 时,收敛最快、精度最高);
- 若 batch size ≤8(如显存不足),改用 GN(num_groups=8 为默认最优值)。
- NLP/Transformer 任务 :
- 强制用 LN(Pre-LN 结构已成为主流,收敛更稳定)。
- 风格迁移 / GAN 任务 :
- 生成器用 IN 或 GN(保留样本风格独立性);
- 判别器用 SN(稳定训练,避免模式崩溃)。
- 残差网络 :
- 优先 BN(Conv→BN→ReLU 顺序);
- 小 batch 场景替换为 GN(保持残差连接的分布一致性)。
3.核心总结
归一化的核心是「选择合适的维度进行统计标准化」:
- 跨样本(多图单通道)统计 → BN(大 batch CNN);
- 单样本跨通道(单图多通道)统计 → LN(NLP);
- 单样本单通道(单图单通道)统计 → IN(风格迁移);
- 单样本组内通道(单图分组组内通道)统计 → GN(小 batch CNN);
- 权重统计(仅和网络权重的通道) → SN(GAN)。
本章笔者主要总结了常见的几种归一化方法,帮助大家学习和理解每种归一化的区分和相似之处,并进一步归结了各种归一化的适用场景。