ParallelAgent 实战:用并行工作流做一个「多主题 Web 调研」Agent
- [一、ParallelAgent 是什么?适合什么场景?](#一、ParallelAgent 是什么?适合什么场景?)
- [二、示例:Parallel Web Research](#二、示例:Parallel Web Research)
- [三、项目结构 & 环境准备](#三、项目结构 & 环境准备)
-
- [3.1 安装依赖](#3.1 安装依赖)
- [3.2 配置环境变量 .env](#3.2 配置环境变量 .env)
- 四、agent.py:按步骤拆解
-
- [4.2 第一步:定义 3 个 Researcher 子 Agent](#4.2 第一步:定义 3 个 Researcher 子 Agent)
-
- [4.2.1 可再生能源研究员](#4.2.1 可再生能源研究员)
- [4.2.2 电动车技术研究员](#4.2.2 电动车技术研究员)
- [4.2.2 电动车技术研究员](#4.2.2 电动车技术研究员)
- [4.3 第二步:定义 ParallelAgent(并行调度器)](#4.3 第二步:定义 ParallelAgent(并行调度器))
- [4.4 第三步:定义 Merger Agent(合并报告)](#4.4 第三步:定义 Merger Agent(合并报告))
- [4.5 第四步:用 SequentialAgent 串成完整 pipeline(根 Agent)](#4.5 第四步:用 SequentialAgent 串成完整 pipeline(根 Agent))
- [五、Web UI 会话](#五、Web UI 会话)
- [六、run_parallel.py:用 InMemoryRunner 跑一轮](#六、run_parallel.py:用 InMemoryRunner 跑一轮)
- [七、小结:ParallelAgent 在这个例子里做了什么?](#七、小结:ParallelAgent 在这个例子里做了什么?)
前面我们实战过:
- 《AI - SequentialAgent 实战:用 ADK 把「写代码 → 审查 → 重构」串成一条流水线》:SequentialAgent 一个接一个按顺序跑子 agent
- 《AI - LoopAgent 实战:用 ADK 做一个 "写作-批改-再写" 的迭代写作智能体》:LoopAgent 在一组子 agent 上反复循环,直到满足条件
这篇轮到最后一个 workflow agent:ParallelAgent。
它做的事情很简单:
把一组子 Agent 同时跑起来,并行完成任务。
一、ParallelAgent 是什么?适合什么场景?
官方文档定义:
- ParallelAgent 是一个 workflow agent,
- 会并行执行它的 sub_agents 列表中的所有子 agent;
- 自身不调用 LLM,只负责调度;
- 执行顺序是 确定性的(deterministic):
- 哪些 sub_agents 要跑,是你在代码里写好的。
非常适合这类场景:
- 多个任务彼此独立,不互相依赖:
- 多主题 Web 调研
- 同时拉不同 API / 不同数据库
- 你很在乎整体耗时:
- 顺序做三件事:总耗时 ≈ t1 + t2 + t3
- 并行做三件事:总耗时 ≈ max(t1, t2, t3)
一句话:能拆开的独立任务,就扔给 ParallelAgent 一起跑。
二、示例:Parallel Web Research
官方文档给了一个完整例子叫 Parallel Web Research:
-
3 个 LlmAgent:
- RenewableEnergyResearcher:查「可再生能源」
- EVResearcher:查「电动车技术」
- CarbonCaptureResearcher:查「碳捕获方法」
-
一个 ParallelAgent:并行运行以上 3 个 researcher
-
一个 MergerAgent:读取这 3 个结果,合并成一份结构化报告
-
再用 SequentialAgent 把 "并行调研 → 合并总结" 串成两步 pipeline
下面我们就按项目搭建的顺序,一步步把代码拆开讲。
三、项目结构 & 环境准备
建议目录结构是这样:
text
parallel_web_research/
├─ agent.py # 定义所有 Agent(3 个 researcher + parallel + merger + root)
└─ run_parallel.py # 用 InMemoryRunner 跑一轮 demo (可选)
└─ .env # 配置 google API Key 或 proxy gateway3.1 安装依赖
bash
pip install google-adk google-genai python-dotenv3.2 配置环境变量 .env
text
GOOGLE_API_KEY="你的_API_Key"
# proxy: Model access endpoints configurations
# AI_GATEWAY_ENDPOINT="your endpoint"
# AI_GATEWAY_TENANT_KEY="your tenant key"
# AGENT_MODEL = "your model"四、agent.py:按步骤拆解
先写一个最小的 agent.py 头部:
python
# agent.py
# Part of agent.py --> 官方示例也是这么写的:完整项目搭建参考 Python Quickstart
from google.adk.agents import LlmAgent, ParallelAgent, SequentialAgent
from google.adk.tools import google_search # 内置的 Google Search 工具
# 模型名:用 Gemini 2.x 系列即可
# GEMINI_MODEL = "gemini-2.0-flash"
# 我这里是使用公司代理,这样提供方由网关自动推断
litellm.use_litellm_proxy = True
endpoint = os.getenv("AI_GATEWAY_ENDPOINT")
tenant_key = os.getenv("AI_GATEWAY_TENANT_KEY")
agent_model = os.getenv("AGENT_MODEL")
proxy_model = LiteLlm(
model=agent_model,
api_base=endpoint,
api_key=tenant_key
)⚠️ 注意:google_search 工具需要你这边有 Google Search Grounding 的权限。 没有的话,你可以先把
tools=google_search 注释掉,让模型单靠自己知识回答,练习 ParallelAgent 的结构没问题。
4.2 第一步:定义 3 个 Researcher 子 Agent
先定义三个 LlmAgent,分别研究三个主题,有几个共同点:
- 都是 LlmAgent
- 都是基于主题调研
- 每个都有不同的 output_key,写进 同一份 session.state 中的不同 key,给后面的合并 Agent 使用
4.2.1 可再生能源研究员
python
# --- 1. 定义并行运行的"研究子 Agent" ---
# 研究员 1:可再生能源
researcher_agent_1 = LlmAgent(
name="RenewableEnergyResearcher",
model=proxy_model,
instruction="""你是一名专注于能源领域的 AI 研究助理。
请基于你已有的知识,总结近几年"可再生能源技术"的主要进展和趋势。
用 1--2 句话,简洁概括关键要点。
只输出总结内容,不要添加解释性前后缀。
""",
description="基于模型自身知识,概括可再生能源相关进展。",
# 将结果写入 state,供汇总 Agent 使用
output_key="renewable_energy_result"
)4.2.2 电动车技术研究员
python
# 研究员 2:电动车
researcher_agent_2 = LlmAgent(
name="EVResearcher",
model=proxy_model,
instruction="""你是一名专注于交通运输领域的 AI 研究助理。
请基于你已有的知识,总结近几年"电动汽车技术"的主要发展(例如电池、充电基础设施、智能驾驶等)。
用 1--2 句话,简洁概括关键要点。
只输出总结内容,不要添加解释性前后缀。
""",
description="基于模型自身知识,概括电动汽车技术相关进展。",
# 将结果写入 state,供汇总 Agent 使用
output_key="ev_technology_result"
)4.2.2 电动车技术研究员
python
# 研究员 3:碳捕集
researcher_agent_3 = LlmAgent(
name="CarbonCaptureResearcher",
model=proxy_model,
instruction="""你是一名专注于气候解决方案的 AI 研究助理。
请基于你已有的知识,概括当前"碳捕集技术/方法"的整体状况(例如主要路线、应用场景或挑战)。
用 1--2 句话,简洁概括关键要点。
只输出总结内容,不要添加解释性前后缀。
""",
description="基于模型自身知识,概括碳捕集方法的现状。",
# 将结果写入 state,供汇总 Agent 使用
output_key="carbon_capture_result"
)4.3 第二步:定义 ParallelAgent(并行调度器)
研究员有了,现在写 ParallelAgent,把他们三位并行起来:
python
# --- 2. 创建 ParallelAgent(并行运行多个研究 Agent) ---
# 该 Agent 会并发运行上述三个"研究员",待它们都把结果写入 state 后结束。
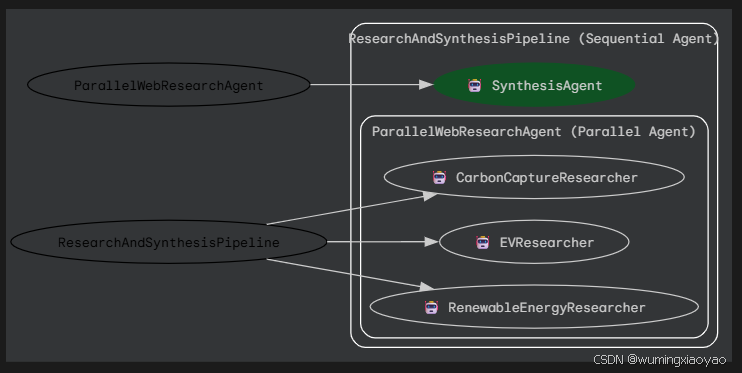
parallel_research_agent = ParallelAgent(
name="ParallelWebResearchAgent",
sub_agents=[researcher_agent_1, researcher_agent_2, researcher_agent_3],
description="并行运行多个研究 Agent,用于收集不同主题的信息。"
)它自己:
- 不做 LLM 推理;
- 不生产最终文本;
- 只是「发令」:三位 researcher 同时启动,各自在自己的 "branch" 上跑;
- 跑完之后,他们的输出已经写进了 state:
- renewable_energy_result
- ev_technology_result
- carbon_capture_result
我们可以把 ParallelAgent.run_async() 的流程,拆成三步:
-
同时启动所有 sub_agents
- 对 sub_agents 列表里的每个子 Agent 调 run_async()
- 在 Runtime 里,这些子 Agent 在各自的「分支(branch)」上并行执行
-
独立的分支(branch)+ 共享的 Session State
- 每个子 Agent 会运行在不同的 InvocationContext.branch 下,像:
- ParallelWebResearchAgent.RenewableEnergyResearcher
- ParallelWebResearchAgent.EVResearcher
- 但它们共用同一个 session.state:
- 都可以读同一份会话状态
- 都可以写入状态(必须用不同的 key,防止互相覆盖)
- 每个子 Agent 会运行在不同的 InvocationContext.branch 下,像:
-
收集结果
- ParallelAgent 会等待所有子 Agent 结束
- 它本身通常不会生成自己的文本响应,而是通过:
- 会话状态里的多个 key(例如 renewable_energy_result)
- 交给后续的某个 Agent(比如一个汇总 Agent)去使用
- ParallelAgent 结束,交回控制权给上层 Workflow(这里是 SequentialAgent)
文档里也特别强调:
ParallelAgent 会为每个并行子 Agent 修改 InvocationContext.branch,
同时所有子 Agent 共享同一个 session.state,
用不同的 key 写入结果是推荐的做法。
4.4 第三步:定义 Merger Agent(合并报告)
ParallelAgent 跑完后,state 里有三份小摘要。
现在写一个 LlmAgent 把这三份合并成一份结构化报告。
python
# --- 3. 定义汇总 Agent(在并行研究完成之后运行) ---
# 该 Agent 从会话 state 中读取三个研究员的结果,并整合成一份结构化报告。
merger_agent = LlmAgent(
name="SynthesisAgent",
model=proxy_model, # 如有需要,也可以在此使用更强模型做汇总
instruction="""你是一名负责"汇总与写作"的 AI 助手,需要将多位研究员的总结整合成一份结构化报告。
你的主要任务:
- 只基于下面给出的三段"研究总结"撰写报告;
- 清晰区分每个主题的来源;
- 使用标题分段,保证语句通顺、逻辑清晰;
- **严禁**引入这些总结中没有出现的额外事实或细节。
**输入总结:**
* **可再生能源:**
{renewable_energy_result}
* **电动汽车:**
{ev_technology_result}
* **碳捕集:**
{carbon_capture_result}
**输出格式(请严格遵守以下结构):**
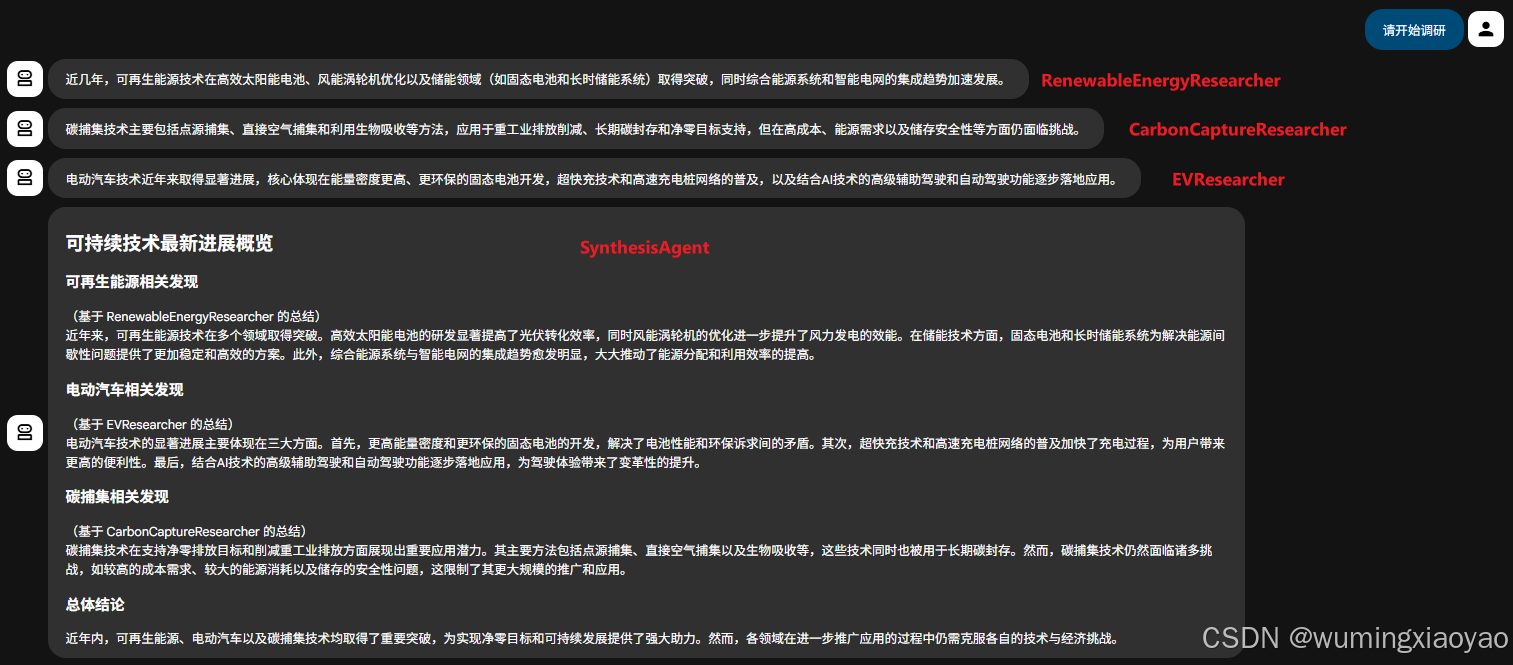
## 可持续技术最新进展概览
### 可再生能源相关发现
(基于 RenewableEnergyResearcher 的总结)
[仅基于上面的"可再生能源"输入总结进行整合和展开。]
### 电动汽车相关发现
(基于 EVResearcher 的总结)
[仅基于上面的"电动汽车"输入总结进行整合和展开。]
### 碳捕集相关发现
(基于 CarbonCaptureResearcher 的总结)
[仅基于上面的"碳捕集"输入总结进行整合和展开。]
### 总体结论
[用 1--2 句话做一个简短结论,只连接并概括以上各部分已给出的信息。]
只输出按照以上格式生成的报告正文,不要额外添加其它说明性文字。
""",
description="读取并行研究 Agent 写入 state 的结果,生成一份结构化的中文汇总报告,只基于给定输入。",
# 汇总阶段不需要再调用工具,直接返回最终结果
)注意这里的 {renewable_energy_result} / {ev_technology_result} / {carbon_capture_result}:
- 就是从 session.state 中取值;
- 因为前面的三个 researcher 已经用 output_key 把结果写进去了;
- ADK 会在调用 LLM 之前,先把这些模板占位符替换成真正的 state 内容。
4.5 第四步:用 SequentialAgent 串成完整 pipeline(根 Agent)
最后一步,把"并行调研 + 合并报告"串起来:
python
# --- 4. 创建 SequentialAgent(编排整体流程) ---
# 主 Agent 先运行并行研究,再运行汇总 Agent 生成最终输出。
sequential_pipeline_agent = SequentialAgent(
name="ResearchAndSynthesisPipeline",
# 先并行研究,再进行结果合并
sub_agents=[parallel_research_agent, merger_agent],
description="先并行收集多领域研究结果,再将其综合为结构化报告。"
)
# 为了兼容 ADK 工具,根 Agent 的变量名必须为 `root_agent`
root_agent = sequential_pipeline_agent执行顺序就是:
- parallel_research_agent
- 内部并行跑 3 个 researcher
- 写入 state 3 个 key
- merger_agent
- 从 state 读 3 个 key
- 生成一份 Markdown 报告
- 返回这份报告给调用方(Runner / Web UI / API 等)
五、Web UI 会话
直接启动 ADK Web server,执行命令:
bash
adk web --port 8001等 web server 启动了,就可以访问 http://127.0.0.1:8001/ 选择 parallel_agent
输入:"请开始调研"
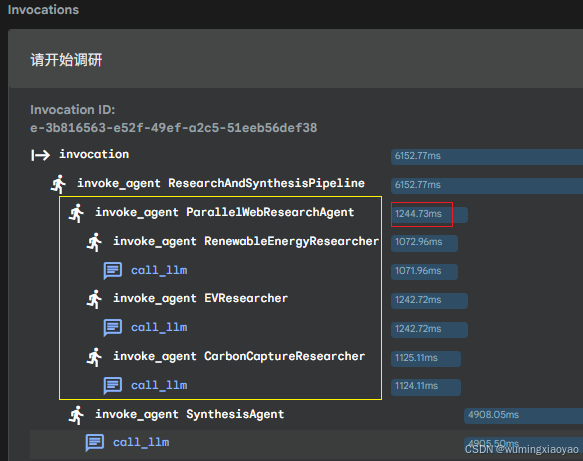
你会发现 Parallel Agent 调用时间通常接近于三次搜索中最慢的那一个,而不是三者之和
六、run_parallel.py:用 InMemoryRunner 跑一轮
agent.py 定义了整个 Agent 树,还需要一个小脚本来调用它。
这里用 InMemoryRunner,最适合本地调试。
python
# run_parallel.py
import asyncio
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.genai import types
from pathlib import Path
from dotenv import load_dotenv, find_dotenv
# 优先从当前目录加载 .env(用于 AI_GATEWAY_ENDPOINT / AGENT_MODEL 等)
try:
_env_path = Path(__file__).parent / ".env"
if _env_path.exists():
load_dotenv(dotenv_path=_env_path)
else:
found = find_dotenv(usecwd=True)
if found:
load_dotenv(found)
else:
load_dotenv()
except Exception:
# dotenv 是可选依赖,加载失败也继续
pass
from agent import root_agent
# 固定一个示例用户和会话 ID
USER_ID = "demo_user"
SESSION_ID = "parallel_session_1"
APP_NAME = "parallel_research_app"
async def main():
"""使用 Runner + InMemorySessionService 运行一次并行研究 + 汇总流水线。"""
# 1. 创建基于内存的 SessionService 和会话
session_service = InMemorySessionService()
session = await session_service.create_session(
app_name=APP_NAME,
user_id=USER_ID,
session_id=SESSION_ID,
state={}, # 本示例暂不需要初始 state
)
print(f"✅ session created: {session.id}")
# 2. 创建 Runner
runner = Runner(
agent=root_agent,
app_name=APP_NAME,
session_service=session_service,
)
# 3. 构造用户消息(这里只是占位,真正逻辑写在各个 instruction 里)
user_content = types.Content(
role="user",
parts=[types.Part(text="请帮我并行调研可再生能源、电动车和碳捕获,并给出结构化总结。")],
)
print(">>> 开始执行并行研究 + 汇总 pipeline...\n")
# 4. 运行一次对话,收集最终回复
async for event in runner.run_async(
user_id=USER_ID,
session_id=SESSION_ID,
new_message=user_content,
):
if event.is_final_response() and event.content and event.content.parts:
print("=== 最终报告 ===\n")
for part in event.content.parts:
if getattr(part, "text", None):
print(part.text)
print("\n================")
break
if __name__ == "__main__":
asyncio.run(main())跑起来:
bash
python run_parallel.py顺利的话,你会看到一份类似这样的输出:
bash
✅ session created: parallel_session_1
>>> 开始执行并行研究 + 汇总 pipeline...
=== 最终报告 ===
**可再生能源**: 可再生能源主要包括太阳能、风能、水能和生物质能等,当前技术集中于提升转换效率与储能能力,突破瓶颈在于间歇性供应问题和大规模储能技术限制。
**电动车**: 电动车正快速普及,技术改进聚焦在电池能量密度、充电速度及续航能力,同时充电基础设施建设和电池回收问题仍是重要挑战。
**碳捕集**: 以点源捕集、直接空气捕集(DAC)和自然解决方案(如植树造林)为主要途径,技术应用于工业排放和分布广泛场景,但面临高成本、能源需求 和存储安全性等问题。
================七、小结:ParallelAgent 在这个例子里做了什么?
再用一句话梳理一遍:
-
Researcher Agents(3 个 LlmAgent)
- 各自负责一个主题
- 每个都基于某个注意调研
- 通过不同的 output_key 写入 session.state
-
ParallelAgent
- 一次性并发启动 3 个 researcher
- 等所有 researcher 都结束才返回
- 自己不产出文本,只负责"并行调度"
-
Merger Agent(LlmAgent)
- 从 session.state 里读 3 个 key:
- {renewable_energy_result} / {ev_technology_result} / {carbon_capture_result}
- 严格基于这三段摘要生成结构化报告
- 从 session.state 里读 3 个 key:
-
SequentialAgent(root_agent)
- 先执行并行调研,再执行合并
- 把整个流程拼成一个两步的 pipeline
掌握了这个示例,你就完全可以把 ParallelAgent 模式迁移到自己的业务场景:
- 并行调用多个内部服务 → 再统一汇总给用户;
- 并行分析多份文档 / 多个数据库表 → 再做总体报告;
- 并行生成多种版本候选(不同风格文案 / 不同方案草稿)→ 再用一个 Agent 帮你评估和选择。