目录
[1.1 架构图及工作原理](#1.1 架构图及工作原理)
[1.2 langgraph4j与langchain4j关联和区别](#1.2 langgraph4j与langchain4j关联和区别)
[2.1 RAG产生的背景](#2.1 RAG产生的背景)
[2.2 概念及工作流程](#2.2 概念及工作流程)
一、langgraph4j工作原理
1.1 架构图及工作原理
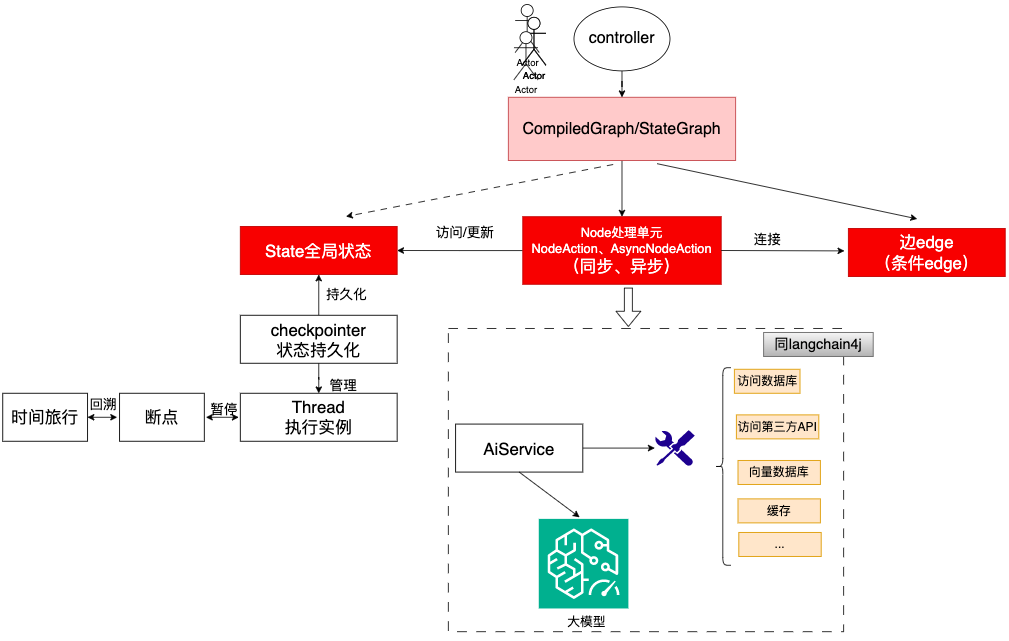
注: Node处理单元可以作为一个Agent存在;
注: Node处理单元可以访问DB,第三方API,甚至可以是一个函数等等;
整体交互流程:
1.2 langgraph4j与langchain4j关联和区别
LangGraph4j 和 LangChain4j相同点: 都是LangChain生态系统的Java实现,旨在帮助开发者利用大型语言模型(LLM)构建应用程序。本质上都是用于开发由大型语言模型LLM驱动的应用程序的框架。
LangGraph4j 和 LangChain4j差异:
|--------|-----------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 对比特性 | LangGraph4j | LangChain4j |
| 含义 | 专注于构建有状态的多智能体系统,即非常适合构建多个智能体相互协作的场景,比如,任务管理、事件驱动的监控系统。 | 核心是"链"(Chain),即将多个LLM调用和工具调用链接在一起,形成一个有序的任务序列。其架构遵循有向无环图(DAG)结构,任务按单一方向流动,不形成循环 注: LangChain4j是LangChiain的java版本, LangChain的Lang取自Large Language Model,代表大语言模型, Chain是链式执行,即把语言模型应用中的各功能模块化,串联起来,形成一个完整的工作流 |
| 设计目的 | LangGraph4j则侧重于支持复杂、有状态的多智能体系统,通过有向图模型实现高级工作流控制 注: Multi-Agent框架 | LangChain4j专注于提供模块化的组件来构建基于大模型的简单应用 注:LangChain4j有顺序/并行等工作流来实现工作流控制 |
| 主要关注点 | 多智能体系统和非线性工作流 | 顺序任务执行(链) |
| 核心关系 | LangGraph4j是LangChain4j的扩展: LangGraph4j构建在LangChain4j之上,旨在解决单智能体在处理复杂任务时的局限性,通过引入状态管理、条件分支、循环和并行执行等能力,扩展了LangChain4j的基础功能 | LangChain4j有顺序/并行等工作流来实现工作流控制(更倾向于实现单智能体) |
| 架构 | 图: 支持循环和动态转换 LangGraph4j采用有向图结构,节点代表智能体或函数,边定义执行逻辑,支持动态控制流和多智能体协作 | DAG: 有向任务,无循环 LangChain4j采用线性链式调用模式,适合预定义顺序的工作流程,如数据获取和总结任务 |
| 状态管理 | 强大,对所有都可访问上下文 | 有限: 依赖记忆组件维持上下文 |
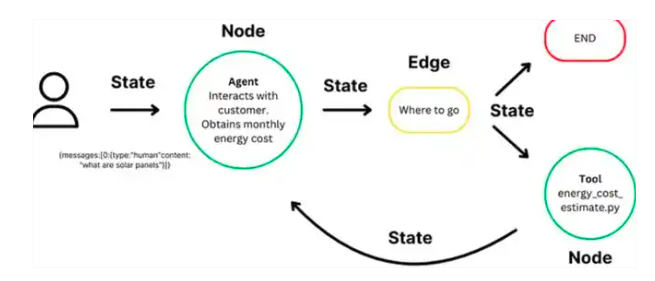
| 组件 | node edge state | Tool AiService |
| 功能实现上 | LangGraph4j允许将复杂任务分解为子任务,由不同智能体并行处理并通过共享状态图传递信息 | LangChain4j更倾向于直接模块化调用 |
| 使用场景上 | 复杂应用: 适合需要持久状态、人机协作或多智能体交互的复杂应用,如自动化运维或研究代理。 在技术实现中,LangGraph4j通过检查点支持断点续跑和时间旅行,增强了调试和可观测性 | 简单应用: LangChain4j适合需要直接、模块化框架的场景,如简单任务编排 |
[LangGraph4j 和 LangChain4j 区别对比]
二、RAG概念
2.1 RAG产生的背景
- 无法回答实时性问题: 大模型如chatGPT是预训练模型, 直接导致了它所学习的知识不会是最新的,也就是它可能是根据半年前的数据训练的, 无法回答实时性问题。
- 无法基于企业/单位内部私有知识回答问题;RAG可以让聊天机器人访问公司内部资料,或来自权威来源的事实信息
2.2 概念及工作流程
RAG(Retrieval-Augmented Generation)的核心思想是:将传统的信息检索(IR)技术与现代的生成式大模型(如chatGPT)结合起来。
注: RAG = 生成式大模型 + 信息检索技术
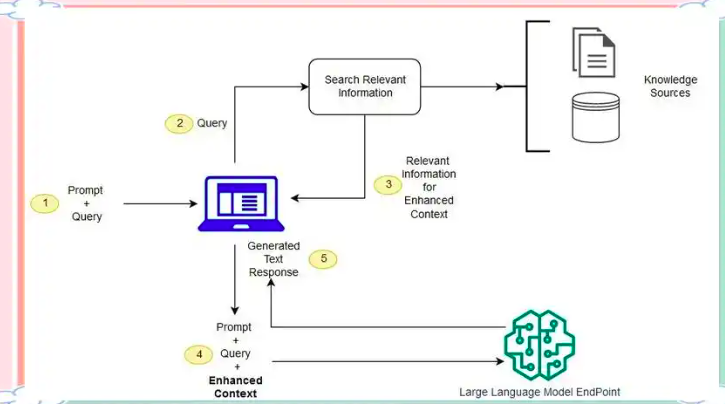
RAG的工作流程主要包括三个阶段:
- 首先,「++数据预处理及形成存储索引++」在索引构建阶段,系统将企业或特定领域的非结构化私有知识(如文档、数据库记录)进行预处理,包括分块、向量化(使用嵌入模型转换为向量表示),并存储到向量数据库中,形成可快速检索的索引;
- 其次,「++在检索增强阶段++」,当用户提出问题时,系统会将查询同样转换为向量,并在向量数据库中通过语义搜索(如余弦相似度匹配)找到最相关的知识片段(目标是找到那些可能包含答案或相关信息的文档),此阶段可能包含重排序组件以优化结果精度;
注意:不一定必须使用向量数据库,可以是关系型数据库(如MySQL)或全文搜索引擎(如Elasticsearch, ES)。但RAG中一般是向量数据库,因为RAG主要涉及要查询相似度高的某几个文档,而不是精确查询。
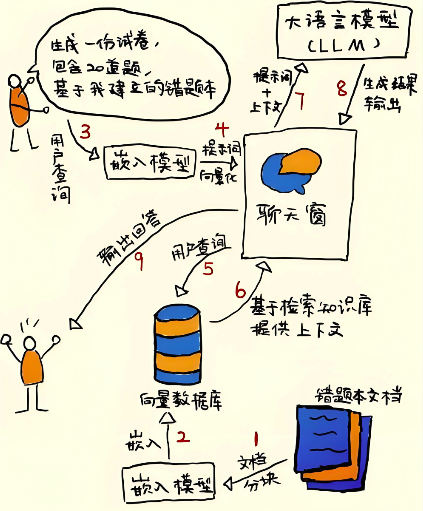
- 最后,「++在生成输出阶段++」,系统将检索到的上下文与用户问题组合成提示词,输入给大语言模型生成答案,模型严格基于提供的事实进行推理以减少幻觉,并可能添加引用标注以确保透明度。注意使用合适的提示词,比如,问题是X, 检索增强查询到的结果是Y,给大模型的输入类似: 请基于Y回答X.
提示词大致长这样:"基于如下信息进行回答: "{{context}}," + "回答提问问题{{question}}"
上述三个过程如图所示:
例子,