一、数据验证背景
在前两篇文章中,我们分别从宏观层面梳理了离线大数据迁移的整体流程与关键挑战(《货拉拉离线大数据跨云迁移-综述篇》),并详细介绍了实际数据迁移过程中的策略、步骤与注意事项(《货拉拉离线大数据跨云迁移 - 数据迁移篇》)。然而,云迁移工作并不在"数据搬运完成"这一刻画上句号------迁移后的数据是否完整、准确、一致,直接决定了业务系统能否平稳切换、分析结果能否可靠可信。
迁移 ≠ 成功,数据验证才是闭环。验数是迁移质量的"守门人",也是业务信任的基石
本篇将围绕离线大数据迁移后双跑阶段的数据验证展开,涉及公司近 20 个部门、数万张Hive表的数据,探讨验证的目标与原则、常见的验证方法与工具、不同场景下的验证策略,以及在实际落地中需要关注的性能与成本平衡。通过系统化的数据验证流程,我们不仅能够发现并修正迁移过程中的问题,还能为后续的数据治理与质量管理奠定坚实基础。
二、数据验证挑战
- 挑战 1:跨云双跑验数难
- 问题背景:
- 双跑阶段,源端不封网,每日都有大量的任务SQL变更、Hive上万表新增/修改分区数据。需要对双跑结果进行校验,包括表分区级 COUNT 校验 和 行级明细比对。校验过程需同时从两朵云查询数据,涉及跨云访问。
- 主要挑战:
- 网络瓶颈: 跨云链路带宽有限(约 100Gb),直接跨云读取数据会导致高延迟与传输开销。
- 计算压力: 每日需处理数万张表及行级数据,计算量大,容易占用生产集群资源,影响业务运行。
- 动态数据干扰多:抽数难对齐,源端写入与目标端双跑并行,数据版本易错乱(如 ETL 逻辑变更)
- 应对思路:
- 采用"云内比对 + 分层验证(粗验 / 精验)"策略,构建自动化验数工具,支持多维度比对(行级、字段级、聚合级)
- 问题背景:
- 挑战 2:错误归因与修复难
- 差异可能源于工具、源端/目标端异常或业务变更,排查链路长。
- 应对思路 :自动化验数报告+闭环跟踪机制。
- 挑战 3:业务验收协同难
- 涉及部门多且数据准确性要求多样化,核心表需 100%一致,非核心表允许合理误差。
- 应对思路 :分级验证(P0/P1)+专家精验,匹配业务优先级,责任到人。
三、验数方案设计
1. 整体方案
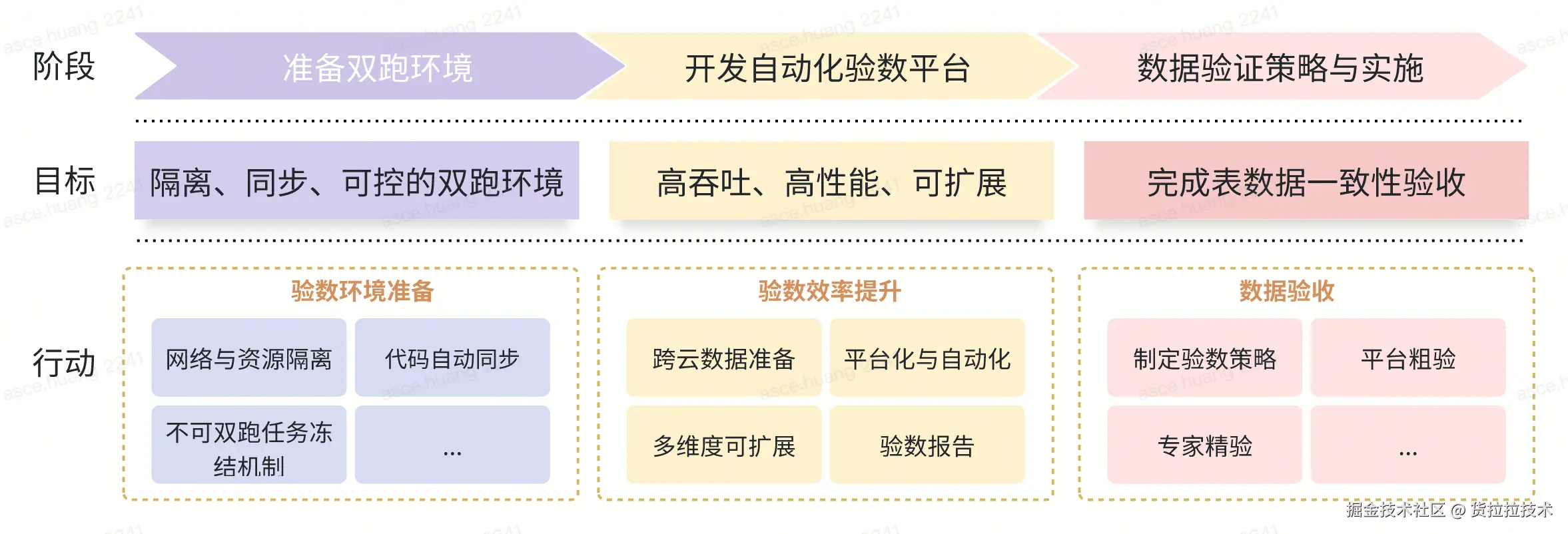 存量数据迁移完成后进入链路双跑期,这期间源端集群不封网,每天都有大量的任务代码变更和新数据生成,数据验收通过才能保障业务系统平稳切换。我们主要通过如下步骤做到在业务运行无感的情况下完成稳定、高效的数据验证:
存量数据迁移完成后进入链路双跑期,这期间源端集群不封网,每天都有大量的任务代码变更和新数据生成,数据验收通过才能保障业务系统平稳切换。我们主要通过如下步骤做到在业务运行无感的情况下完成稳定、高效的数据验证:
- 准备链路双跑环境 :准备双跑环境,网络隔离、任务代码自动同步、冻结不可双跑任务,防止双跑链路污染线上数据,搭建了一套隔离、同步、可控的双跑环境
- 高效数据对比工具 :跨云表数据自动对比,支持表行级和列级的粗验(数据量)和精验(明细,支持设定浮点数精度);自动生成对比报告,记录表和列的数据不一致占比以及不一致的明细数据,大幅提升验数效率
- 数据验证策略与实施 :按照分层、分级、分阶段、分部门的策略对20万+的Hive表进行验数,归因分析数据不一致原因并修复,协助业务部门完成表数据一致性验收
四、 验数实施
1. 双跑环境准备
在存量数据迁移基本完成后,系统正式进入链路双跑阶段 ------这是数据验证最关键的窗口期。此阶段,源端集群保持完全开放 ,业务任务照常运行,ETL 代码持续迭代,每日仍有 500TB+增量数据写入。为确保验证过程不影响线上稳定性,同时又能真实模拟切换后的运行状态,我们构建了一套隔离、同步、可控的双跑环境。
1.1 网络与资源隔离
- 物理隔离:目标云环境独立部署 Hive Metastore、YARN 集群、调度系统,与源端无共享存储或元数据服务,避免交叉污染。
- 网络策略:通过 VPC 对等连接或专线打通跨云通道,限制目标端仅允许 Kirk迁移 工具和双跑任务写入,禁止外部访问 。
- 资源保障 :为双跑任务分配独立 YARN 队列和计算资源,避免与生产任务争抢资源,确保验证过程不影响核心链路 SLA。
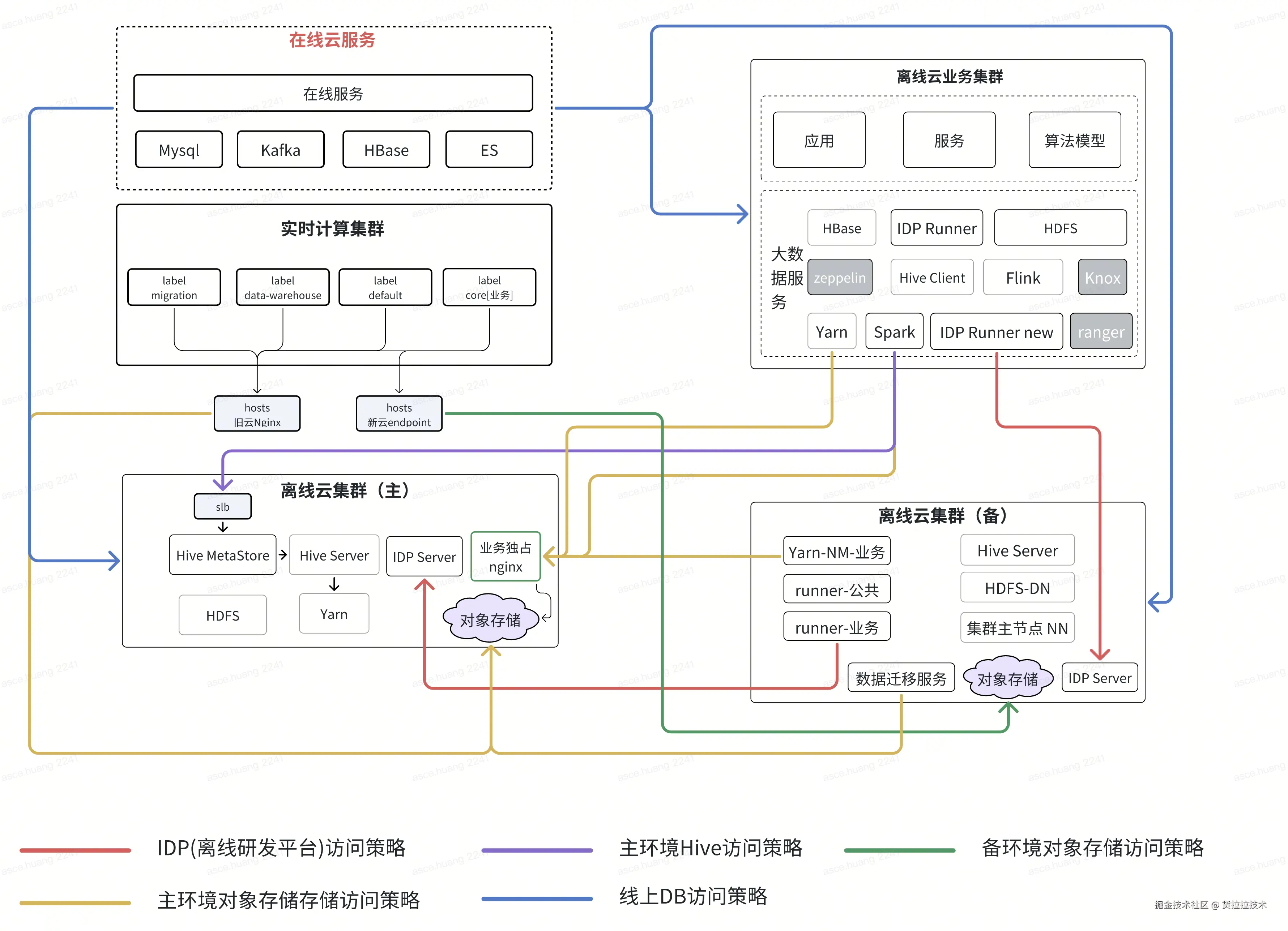
1.2 任务代码自动同步
为确保计算任务代码、数据及元数据在多环境间的高度一致性,数据平台自主研发了自动同步功能。该功能实现了主环境到备环境的实时双向同步,当用户在主环境进行代码修改、数据更新或配置调整时,系统会自动、精准地将变更内容同步至备环境。 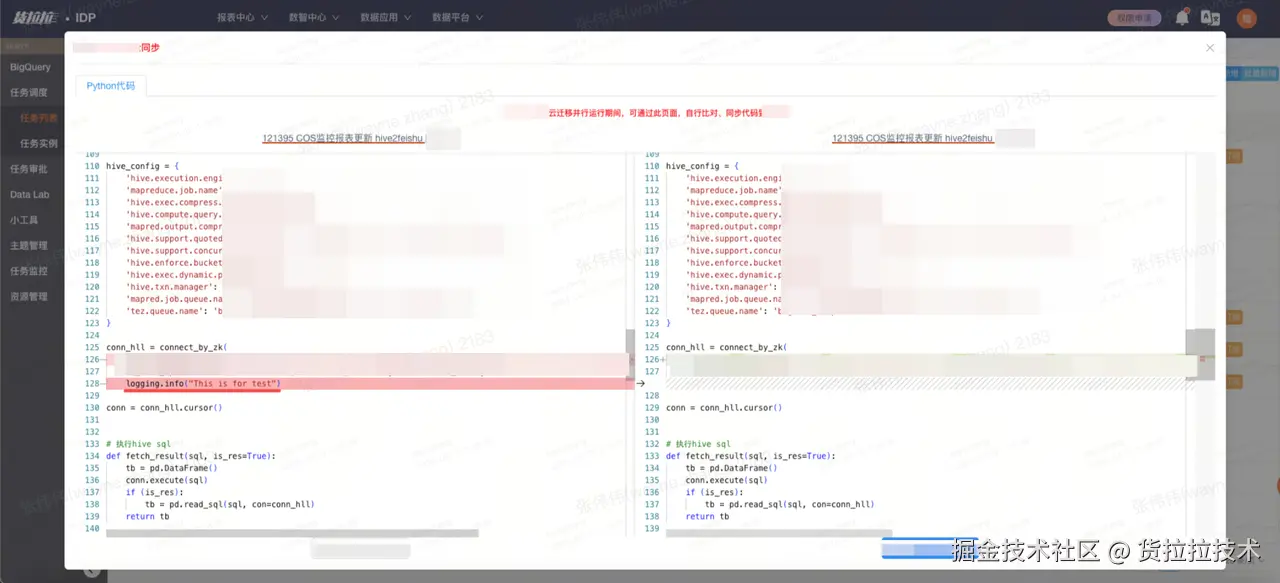
1.3 不可双跑任务冻结机制
并非所有任务都适合双跑。例如:
- 强依赖源端特定组件(如自定义 UDF、本地缓存);
- 涉及外部系统写入(如 DB、MQ),双跑会导致重复写入;
- 任务本身具有幂等破坏性(如 delete、drop 操作)。
双跑期间不打开的任务:
- 一次性任务
- 所有Doris相关任务,包含Doris SQL、ShellDoris、Hive2doris等类型不打开
- Hive to Any任务
对此类任务,在双跑启动前会冻结,避免对目标端或外部系统造成干扰。同时,对关键冻结任务提供 Mock 数据或空跑策略,保障下游链路完整性。
通过上述措施,我们构建了一个高保真、低干扰、可回溯 的双跑环境,为后续大规模、自动化数据验证奠定了坚实基础。在整个双跑周期(约 2--3 周)内,系统平稳运行,未发生因验证导致的生产事故,真正实现了"业务运行无感,验证有理有据"。
2. 验数平台
为了保障双跑验数工作高效推进,我们基于 Kirk 系统自研了一套高吞吐、高性能、可扩展的自动化验数平台。平台设计遵循以下核心思路:
- 平台化与自动化 将繁琐的验数操作(如调度对比任务、收集结果、生成报告)整合为标准化、自动化的平台流程,减少人工干预,提升效率与一致性。
- 多维度可扩展 支持多种验数策略的选择,如比计数、比关键字段哈希、比全字段等,支持验收阈值配置,还支持高度定制化的验数逻辑,如自定义SQL。
- 面向业务协同 提供清晰的验数报告,按部门、表重要性分类,输出比对结果,差异率,差异明细等,用户可快速找到不一致的原因,实现责任到人,过程透明。
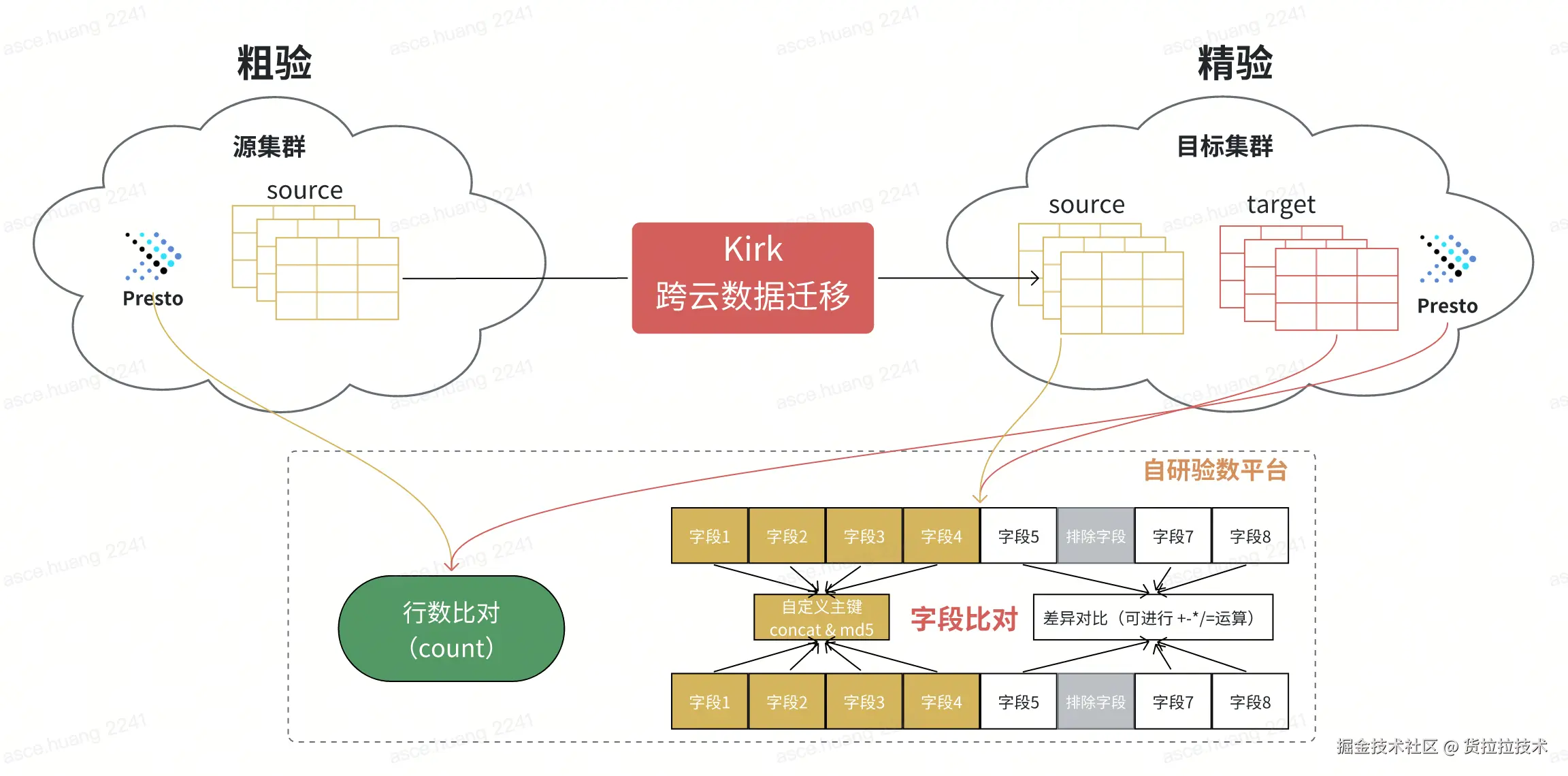
2.1 跨云数据验证
链路双跑完成之后,待验证数据分别在两朵云,为了避免频繁重复的跨云传输,我们设计了数据集中验证策略------将源端数据预先迁移到目标端,在单一云环境内完成全部验证工作。
2.1.1 数据准备
要把数据迁移到同一朵云上,首先要解决的第一个问题就是数据放哪里怎么放的问题,无论验数结果是否通过,最终都会以源端数据为基准去覆盖目标端的数据,因此在验数的准备过程中,第一步先将目标端待验证的数据移动到比对库中避免被源端覆盖(rename操作,不会产生数据读写),第二步使用Kirk(自研数据迁移工具)把源端数据搬迁到目标端正式目录上,通过这两个步骤,既完成了数据迁移任务,又为云内比对做好了数据准备。 这个过程中需要注意非分区表的特殊处理,通常非分区表的大小都比较小(主要是维表),由于非分区表每天都会自行覆盖,为了实现历史状态的回溯,需要专门针对于非分区表保留历史状态的快照,数据准备过程如下:
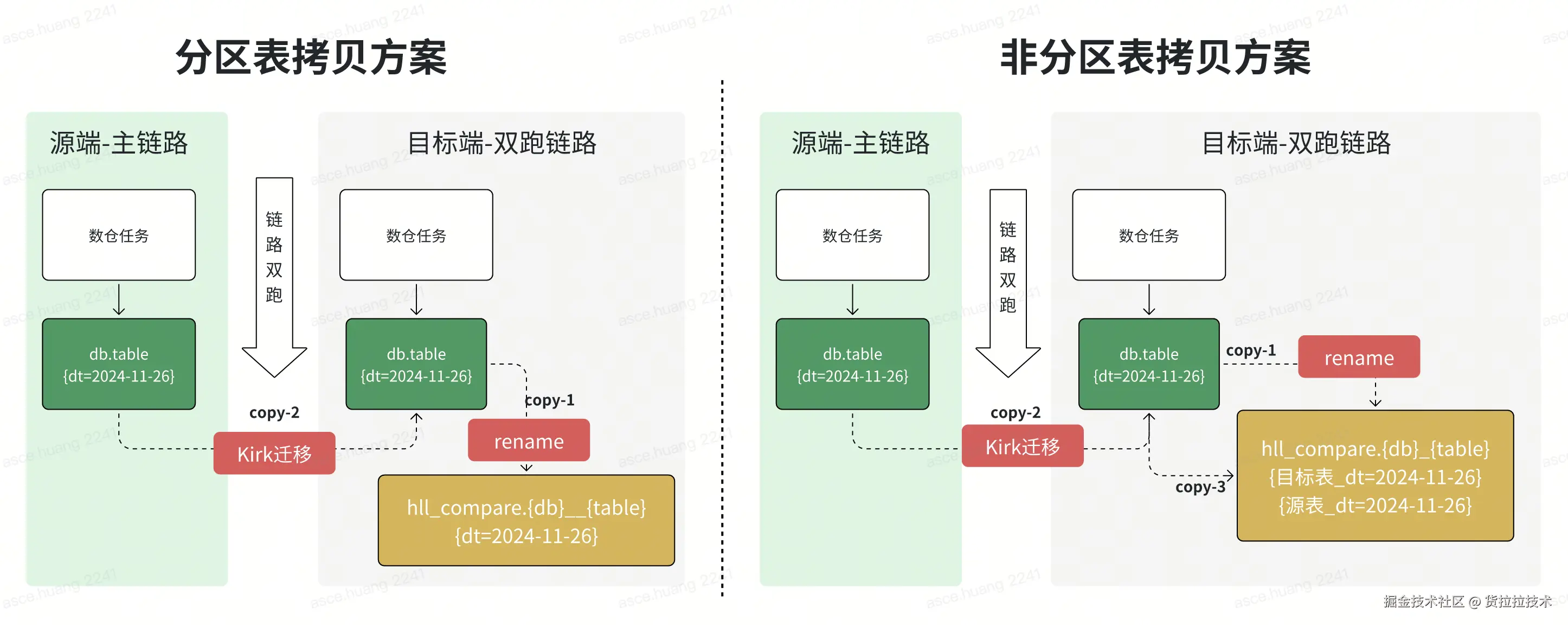
2.1.2 比对方案
| 类型 | 方法 | 说明 |
|---|---|---|
| 粗验 | 对比源端与腾讯云两条链路产出的表行数(COUNT) | 快速判断数据完整性,是精验的前提条件 |
| 精验 | 对每张表的每行数据计算 MD5 值,逐行比对一致性 | 确保内容级 100% 一致,用于核心表验证 |
2.2 验数平台介绍
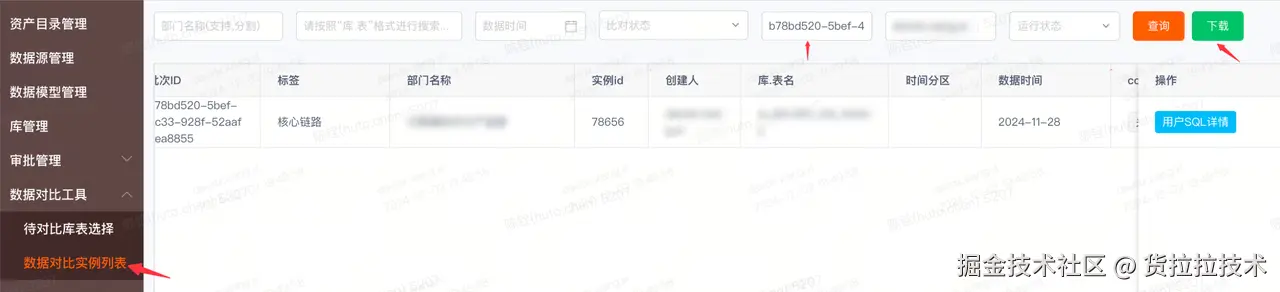
2.2.1 创建比对任务
支持单个/批量创建数据比对任务
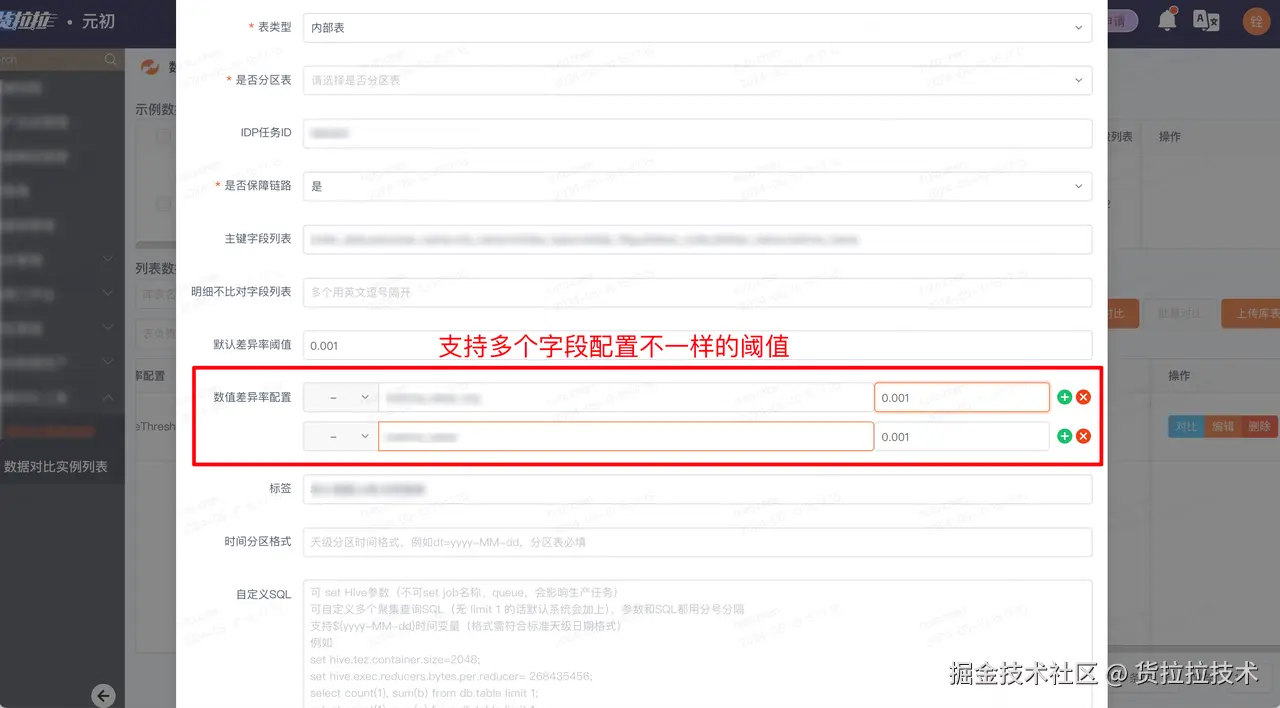
2.2.2 配置比对逻辑
- count验数:对比华为云和腾讯云表count行数
- 自定义SQL验数:count,sum,按维度聚合
- 明细比对:对比整行数据的差异,可以指定主键和排除字段
- 数值差异比对:将数值字段按照 +-*/ 等规则计算差异率,并可单独指定每个字段的差异率阈值
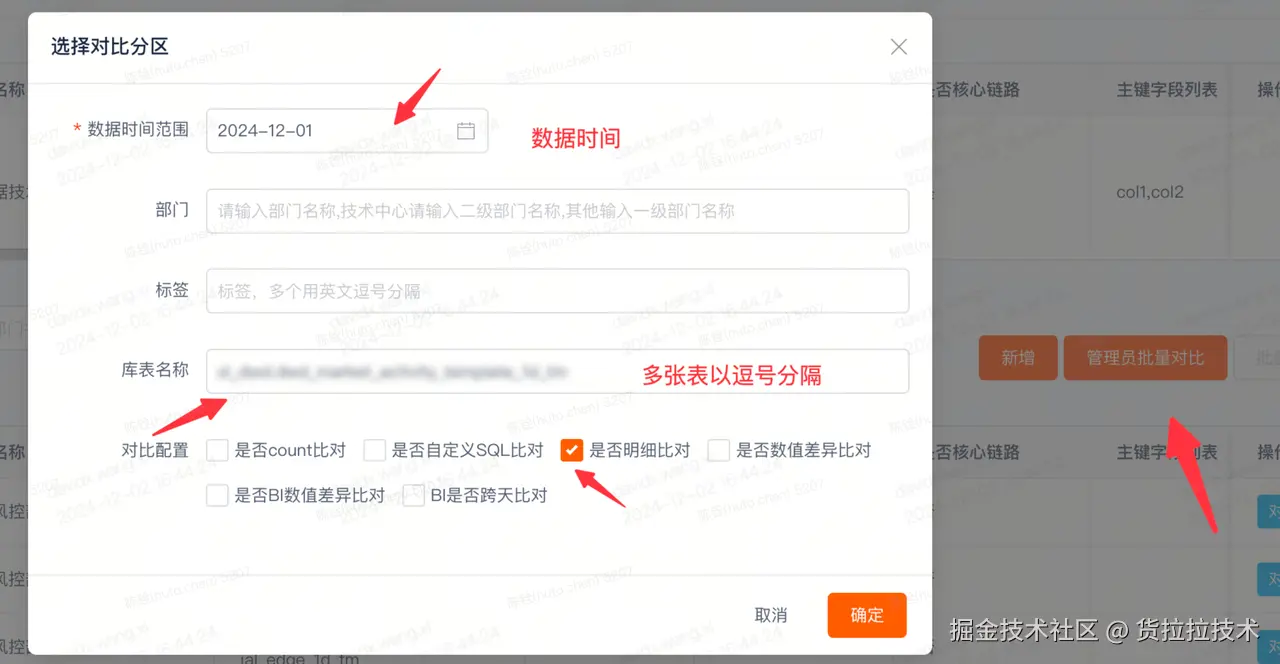
2.2.3 运行比对任务
用户可以根据需求,选择自动执行或者定时执行比对逻辑,功能介绍如下:
| 对比项 | 说明 |
|---|---|
| 是否count比对 | 执行行数一致性校验 |
| 是否自定义SQL比对 | 执行用户自定义SQL校验 |
| 是否明细比对 | 执行字段级一致性验证 |
| 是否数值差异比对 | 执行数值字段四则运算一致性验证 |
| 是否BI数值差异比对 | 执行数值波动率一致性验证 |
| BI是否夸天比对 | 执行数值波动率一致性验证并且可自定义同环比日期 |
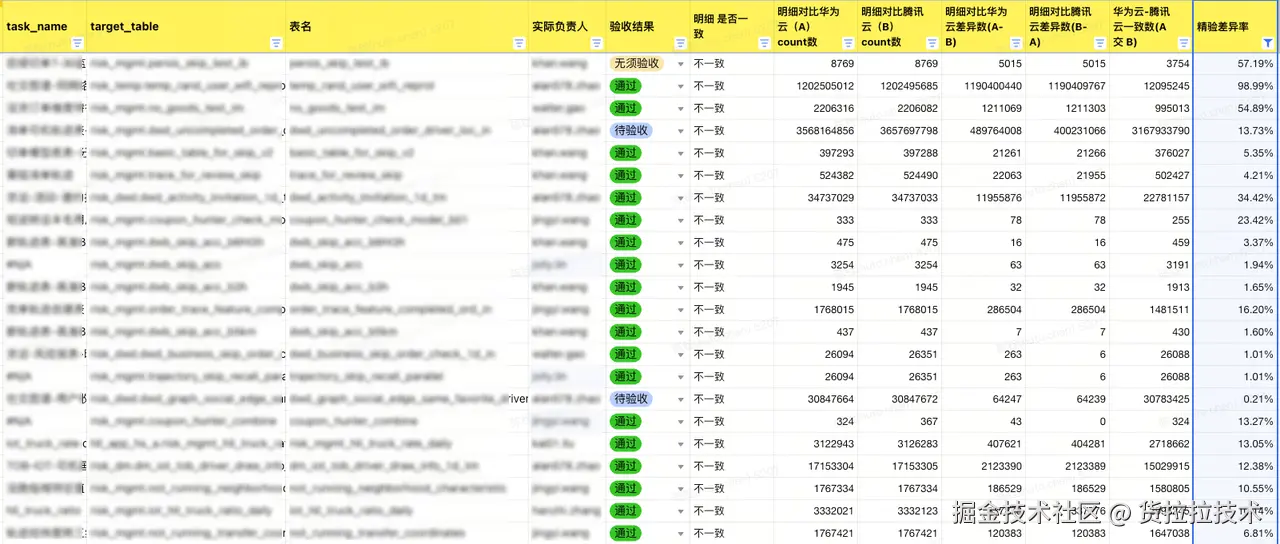
2.2.4 下载比对报告
| 对比项 | 说明 |
|---|---|
| 全局比对结果 | 该 task 最终的比对状态,分为:未知(系统比对 SQL 和用户自定义 SQL 运行异常),一致(系统比对 SQL 和用户自定义 SQL 都一致),不一致(系统比对 SQL 或用户自定义 SQL 不一致) |
| 系统比对结果 | 系统生成的 Count SQL 比对结果是否一致 |
| 用户SQL比对结果 | 用户自定义的 SQL 执行的结果是否一致 |
| 源链路count | 主链路执行 SQL Count 结果 |
| 腾讯云count | 腾讯云执行 SQL Count 结果 |
| count差异率 | 主链路和腾讯云 Count 差异((腾讯云 Count - 主链路 Count)/ 主链路 Count) |
| 系统异常信息 | 系统的异常日志,有则点击并显示 |
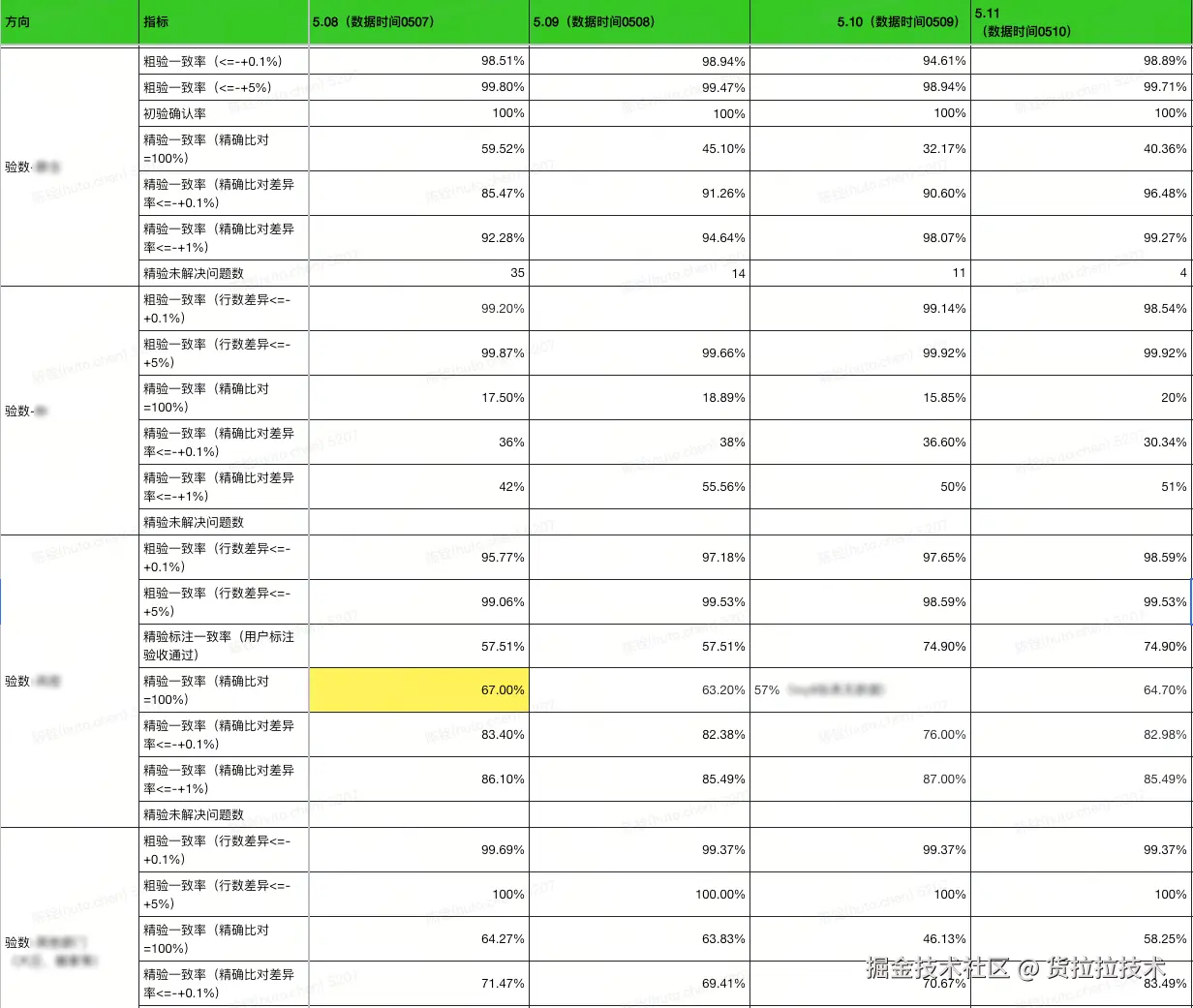
3. 数据验证策略与实施
面对横跨近20个部门、涵盖数万张Hive表的庞大数据体系,我们构建了一套贯穿双跑周期的系统性验数方案。该方案以"平台化工具自动巡检"与"专家团队精准核验"双轨并进,通过层次化、场景化的验证流程,为核心数据的一致性保驾护航,为业务切换筑牢信任根基。
3.1 核心策略
3.1.1 分层、分级、分阶段
为应对数据规模与复杂性的挑战,我们摒弃了单一维度的验证方式,确立了以下核心策略 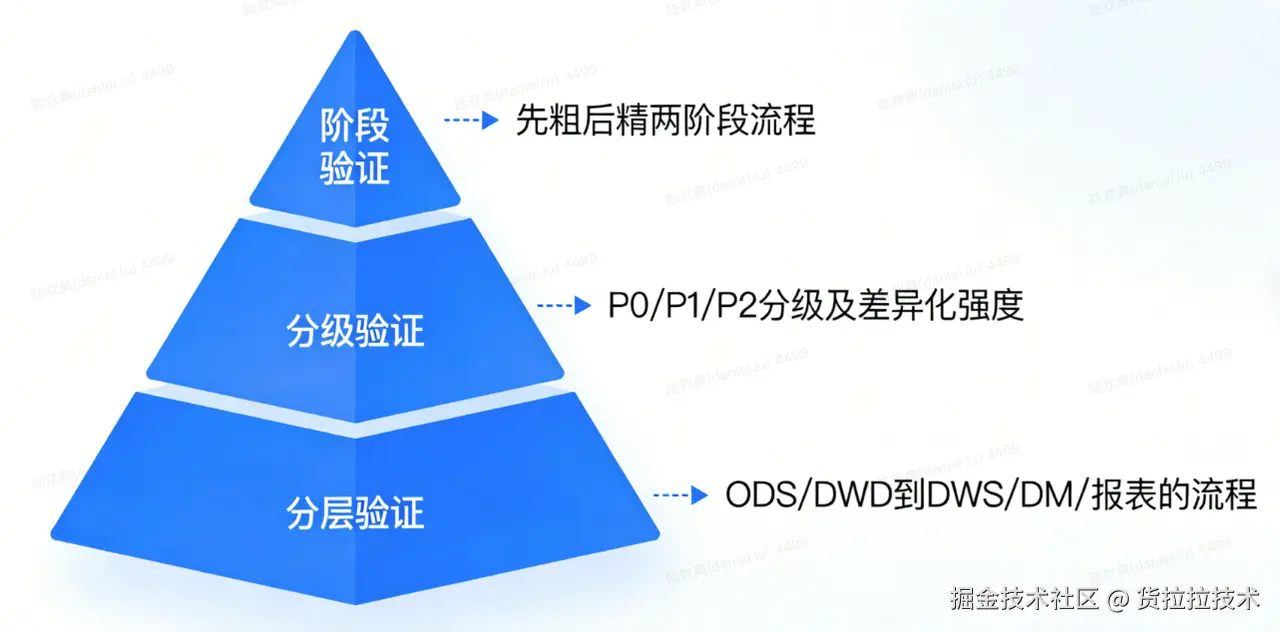
- 分层验证(从数据产生的技术流程和依赖关系入手)从基础数据层(ODS/DWD)到应用数据层(DWS/DM/报表)依次验证,确保验证流程符合数据加工逻辑,系统性阻断底层错误向上蔓延。
- 分级验证(从数据的重要性和影响面入手),对数据表进行P0(核心)/P1(重要)/P2(一般)分级,实施差异化的验证强度,确保资源精准投放。
- 分阶段验证(从验证工作的实施步骤和精细度入手)采用"先粗后精"的两阶段流程,先行数快速筛查,再内容深度比对,构建高效的验证流水线。
3.2 方案实施
为确保验证的全面性与深度,我们采用了平台化工具 与专家精准核验的双轨制策略。
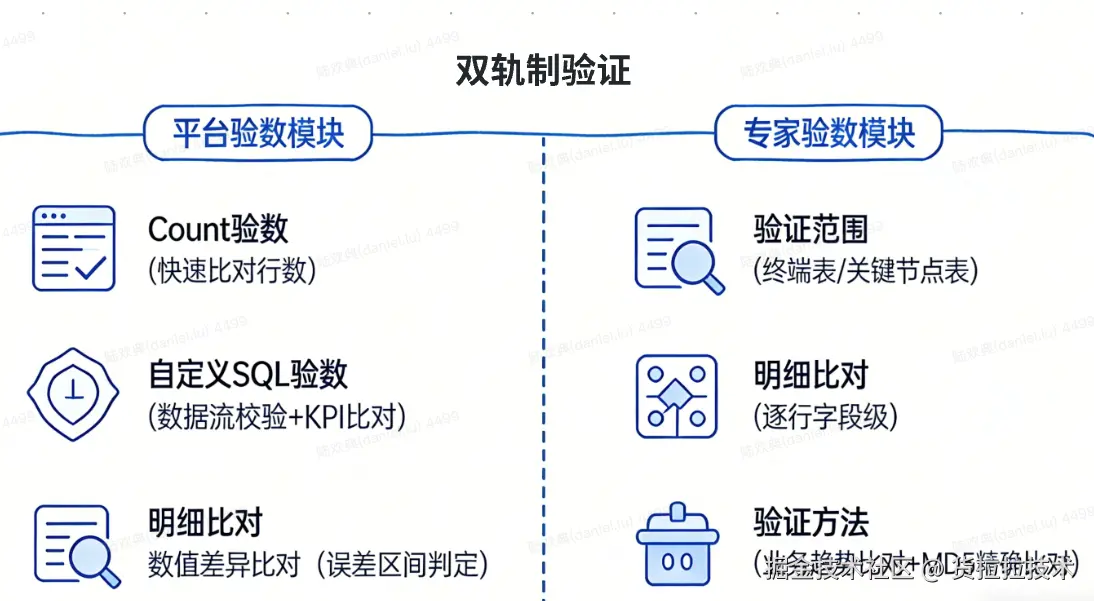
3.2.1 平台验数
为提升验证效率,我们使用了元初平台的验数工具,覆盖基础场景,实现规模化效率
- Count验数:快速比对源端和腾讯云表或分区的行数,是"分阶段"策略中"粗验"的核心手段,能快速定位宏观差异。
- 自定义SQL验数 :
- 数据流完整性验证:验证从ODS源头到DM应用层的数据加工链是否准确。例如,编写SQL检查DM层的"用户总消费金额"是否等于对DWD层所有相关明细订单金额的汇总。
- 关键KPI比对:如"当日GTV"、"活跃用户数"、"平均响应时长"等。需要编写承载了完整、一致业务口径的SQL(涉及多表关联、去重、过滤、聚合)
- 明细比对:基于主键或唯一键的逐行字段级精准比对,是"精验"阶段验证数据明细一致性的关键手段。
- 数值差异比对:针对数值型字段,设置误差容忍区间,科学地判定在合理波动范围内的数据一致性,有效解决了报表层因微小时间差导致匹配不上的经典难题。
3.2.2 专家验数:攻坚复杂场景,确保业务深度可信
对于元初验数平台无法覆盖的复杂、定制化场景,我们依赖数据开发者的领域知识与经验进行深度验证。
- 验证范围 :聚焦于核心链路表与各部门认定的重要表。
- 终端表优先验证:优先验证直接面向业务应用的终端产出表。若终端表数据准确,则其上游数据处理链路在大概率上是正确的,这是一种高效的逆向验证思路。
- 关键节点表验证:对承上启下的关键宽表、重度聚合表等进行重点核查,确保核心数据加工节点的准确性。
- 验证方法 :
- 领域专业验证:结合业务语义,对重要维度(如地区、渠道)、关键指标(如GMV、转化率)进行聚合统计与趋势比对,从业务视角判断数据合理性。
- 标准逐行比较验证:对于要求绝对一致的核心表,利用我们提供的深度验数工具(支持在腾讯云侧进行数据比对),可对每一行数据的所有字段或部分关键字段计算MD5值,进行无损的精确比对,确保数据100%一致。
3.2.3 标准化运营流程
我们建立了专职的验数小组,驱动验证工作闭环: 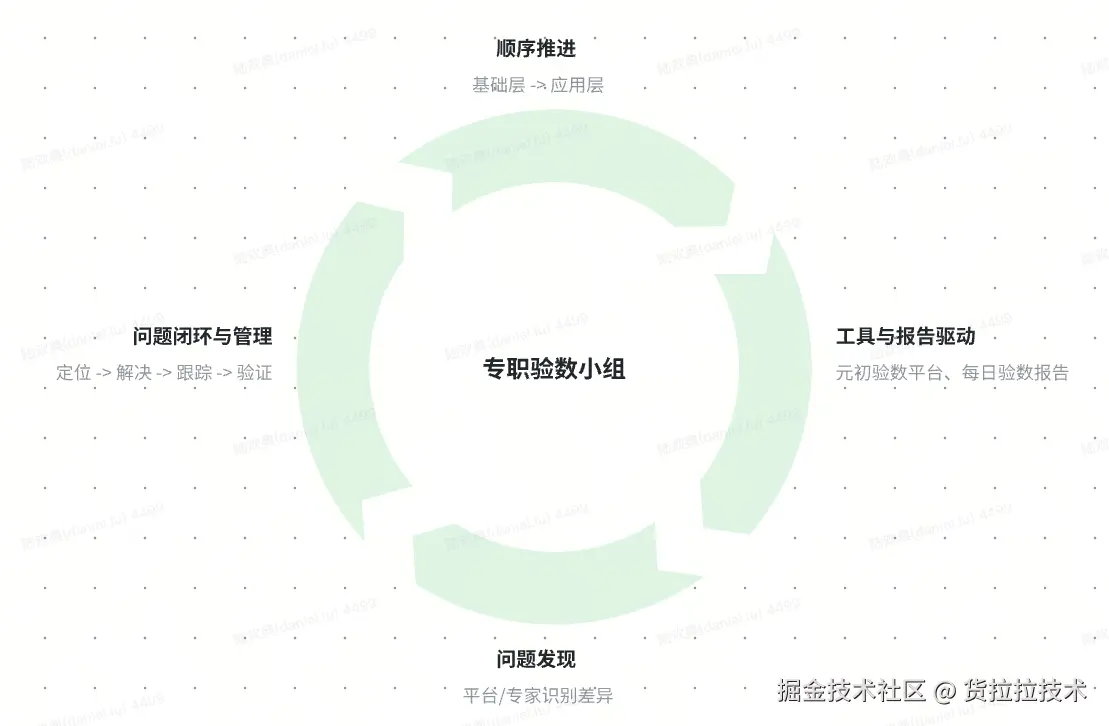
- 顺序推进:严格执行"先基础层,后应用层"的验证顺序。
- 工具与报告驱动:以元初验数平台为核心调度工具,每日自动产出验数报告,透明化展示验证进度与不一致项。
- 问题闭环管理:对平台发现及专家识别的不一致问题,执行"定位、解决、跟踪、验证"的全程闭环管理,确保所有问题被根除。
五、总结
离线大数据跨云迁移是一项系统性工程,从前期规划、数据迁移到后期验证,每个环节都环环相扣、缺一不可。数据验证作为迁移闭环的最后一环,不仅是对迁移结果的质量把关,更是对整个迁移体系的信任背书。通过科学的验证目标设定、合理的验证策略设计以及高效的工具与流程落地,我们能够在保障数据完整性、一致性与可用性的同时,平衡性能与成本,确保业务平稳过渡。 在本次迁移与验证过程中,来自多个团队的同事共同参与了验数工作。他们在验证方案设计、工具开发、数据比对、问题定位与修复等环节中密切协作,确保了整个迁移过程的高效与可靠。正是这种跨团队的协同与专业投入,构筑了数据验证工作的坚实底座,也为项目的顺利收官提供了有力保障。 在此,也向所有参与本次迁移与验数工作的团队与同事致以诚挚的感谢------正是大家的专业、耐心与协作,让复杂的跨云迁移项目得以高质量落地。
作者简介:
- 杨秋吉:大数据专家,负责大数据离线计算引擎、OLAP引擎的研发与维护
- 陆欢典:资深数据仓库工程师,货拉拉公共数据组负责人,致力于公共数据层的顶层设计与统筹建设
- 陈铨:高级大数据工程师,专注于大数据存储方向,主要负责大数据离线存储、向量存储的研发和维护