文字只是七拼八凑,知识却饱含智慧!
哨兵这个词很接地气,放哨 多形象,主要是监控redis实例节点,保证集群高可用
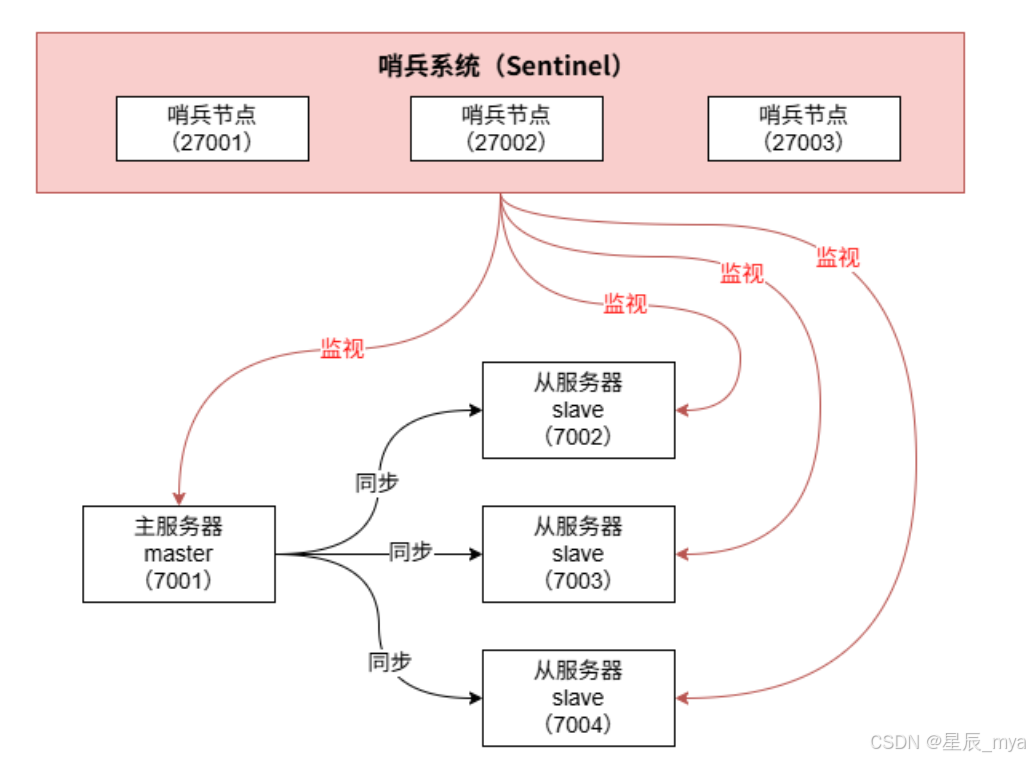
1、client客户从哨兵集群中找一个帅气的哨兵,通过**"询问"找到redis主**节点
2、结果主节点更帅,而且资源丰富,那就不需要再麻烦💂哥哥了,后面咱们就直接访问redis主节点
3、虽然client不需要哨兵,但是作为一名合格的战士,哨兵一直在"关心着"redis集群,当主节点年老色衰,当然话不能说得这么直白,反正当主节点发生变化,我们哨兵会马上感知到,并且将新主通知给client(这就是给了小费的益处),当然也是咱们client想得全面,知道订阅节点变动消息不,需要自己随时盯着,像一个怨妇一样(金钱的力量)
#让哨兵在后台运行
daemonize yes
sentinel monitor <master‐redis‐name> <master‐redis‐ip> <master‐redis‐port> <quorum>
# quorum数字:当有多少个sentinel认为master失效(值一般为:sentinel总数/2 +
1),master才算真正失效当然玩笑归玩笑,sentinel的作用远不止此,如果主节点挂了,哨兵集群会重新选主,同时修改all哨兵节点配置文件的集群元信息(自己感知到后主动追加 ;看、多机智!)这个设计很巧妙,化被动为主动:
定期ping判断数据节点和其他哨兵节点是否可达,不可达主观下线,多个正直的哨兵判断为不可达则客观下线(所以至少要3个人,要不双方人数一样,容易打架不是),然后国不可一日无君,更何况咱们redis一秒都等不了,马上选主!故障转移 新主出来之后 就到了我们从表现的时候了,立即向新的主节点表忠心:我把我所有数据都丢弃,像您重新申请数据,劳烦您赏脸 复制给我数据,rdb aof 混合双打只要给数据 怎么着都行,统统接受!
#定期PING判断Redis数据节点和其Sentinel节点是否可达,如超30000毫秒没回复,则不可达
sentinel down-after-milliseconds mymaster 30000
#一次只能1个从节点发起复制请求
sentinel parallel-syncs mymaster 1
#故障转移超时时间为180000毫秒
sentinel failover-timeout mymaster 180000通过上面配置文件,咱们发现其实哨兵sentinel本质上还是一个redis服务器,只不过功能侧重点不同,简单来说你可以先简单把他当成redis服务器,只是他不会初始化
1、数据库和键值对命令:set del flushdb
2、事务 multi watch、脚本命令 eval
3、rdb和aof持久化:save bgsave bgrewriteaof
咱们细说一下选主的事情
其实也细说不了多少
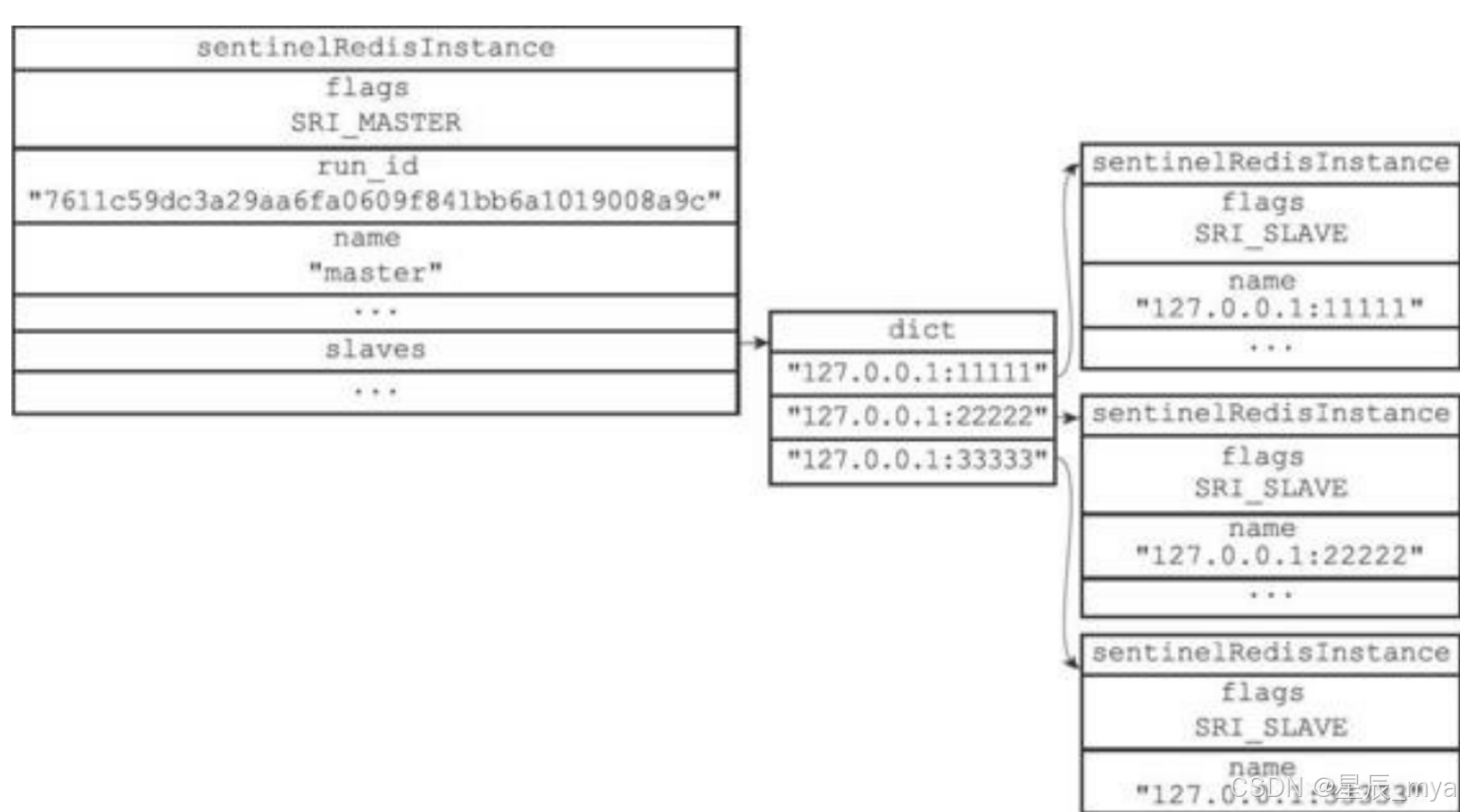
sentinel初始化会创建与主数据节点的网络连接,这样一顿操作猛如虎,摇身一变成为客户端
1、可以发号施令info(10s一次,可设)并接收回复pong/-loading/-masterdown类消息
2、或向主从数据节点发起订阅__sentinel__:hello(2s一次,可设),对于集群中其他哨兵来说,其中一个接收到消息就意味着都接收到了消息(因为他们一家会互通消息),然后更新本地的元信息,这就是咱们常说的pub和sub
#发送,s代表哨兵,m代表主数据节点
PUBLISH __sentinel__:hello "<s_ip>,<s_port>,<s_runid>,<s_epoch>,<m_name>,<m_ip>,<m_port>,<m_epoch>"
SUBSCRIBE __sentinel__:hello这样哨兵可以获取到对数据节点的监控信息,从而达到对数据节点的监控,掌握他们的核心科技,比如数据复制到哪里了(偏移量slave_repl_offset),这个点就很重要、前面后面360度都要考;当然数据节点的一些元信息也是记下来牺牲一些空间来达到效率(微不足道)
比如哨兵发现了新的从服务器,除了记录下来也会创建命令连接和订阅连接从而获取从的信息和健康情况
当哨兵a发现master挂了,发送**SENTINEL is-master-down-by-addr** 开始让大家伙投票,并要求将自己设置为他们的局部领头Sentinel;其他哨兵根据参数中的元数据信息检查主节点是否挂了,然后返回MultiBulk(leader_epoch和leader_runid),然后发送的那个哨兵a接收到回复信息,统计他们同意主节点下线的数量是否超过设置的quorum值,如果下线则修改主节点实例标识,客观下线,很遗憾
下线之后就要选举了,怎么说呢,更新换代总是令人很兴奋,so咱们使用raft算法选主
1、主节点客观下线之后,哨兵们会商量选出自己的老大(leader_epoch和leader_runid),让老大去故障转移
故障转移
1、选出新的主服务器:在线的数据完整的从服务器翻身把歌唱,当家作主!
最近没有回复info命令的从服务器肯定排除在外:剩下的都是可以通信的
删除与前主断开链接超过down-after-milliseconds*10mm的从:数据比较新
不要忘记从服务器可以配置优先级,多个相同优先级的从服务器,那就要从复制偏移量选出最大的从服务器
这个时候如果还没有选出来,则看运行id,越小则优先级最高
2、新主出现之后,领头哨兵----大将军则从新的主获取configuration epoch(也就是常说的version:唯一),发送slaveof命令,让all的从服务器要去复制新的主,如果这个过程失败,则等待failover-timeout后其他一个哨兵会接替重新获取新的version执行换主
3、换主成功之后,领头兵会本地更新新主的配置,然后pub、sub订阅链接同步给其他哨兵,上传下达做到了极致
4、下线的旧主重新上线,变成从服务器
只要勤勤恳恳 永不下线,就能从小兵当成大将军,在朝代更替中起着不可获取的作用
小角色往往关乎到事态的发展,因为小角色也很重要