🔥 MediaCrawler - 自媒体平台爬虫 🕷️
MediaCrawler 是一款功能强大的多平台自媒体数据采集工具,它能够帮助用户抓取各大自媒体平台如小红书、抖音、快手、B站、微博、贴吧、知乎等的公开信息。无论是进行数据分析、舆情监控还是进行内容创作,这款工具均能派上用场。
📖 项目简介
在当今数据驱动的时代,通过精准的数据抓取来获取信息变得尤为重要。MediaCrawler 旨在简化这一过程,为用户提供高效、灵活和可扩展的爬虫解决方案。其设计基于 Playwright 浏览器自动化框架,可以有效地保存登录态,避免了繁琐的JS逆向过程,大幅降低了使用门槛。
🌟 功能特性
| 平台 | 关键词搜索 | 指定帖子ID爬取 | 二级评论 | 指定创作者主页 | 登录态缓存 | IP代理池 | 生成评论词云图 |
|---|---|---|---|---|---|---|---|
| 小红书 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 抖音 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 快手 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| B 站 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 微博 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 贴吧 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 知乎 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
这些特性使得 MediaCrawler 成为数据科学家、市场分析师和内容创作者的理想工具,您可以通过关键词快速找到相关内容,获取创作者发布的所有帖子以及评论数据。
🔧 技术原理
MediaCrawler 的核心技术是基于 Playwright 浏览器自动化框架,无需进行复杂的 JS 逆向。通过保留登录态的浏览器上下文环境,工具可以利用 JS 表达式获取签名参数,简化了技术的使用和实施过程。
🚀 快速开始
要使用 MediaCrawler,您需要先安装一些依赖项。
1. 前置依赖
uv 安装(推荐)
确保您的电脑上安装了 uv,确保包管理工具的高效性:
bash
# 验证安装
uv --versionNode.js 安装
请下载并安装 Node.js,版本要求为 >= 16.0.0。
Python 包安装
在终端中运行:
bash
# 进入项目目录
cd MediaCrawler
# 保证 python 版本和相关依赖包一致
uv sync浏览器驱动安装
bash
# 安装浏览器驱动
uv run playwright install🚀 运行爬虫程序
要运行爬虫程序,可以使用以下指令从配置文件中读取关键词或帖子ID来爬取数据:
bash
# 爬取关键词相关的帖子信息与评论
uv run main.py --platform xhs --lt qrcode --type search
# 获取指定帖子ID的信息与评论
uv run main.py --platform xhs --lt qrcode --type detail通过配置文件调整需要爬取的内容,随时打开对应APP扫二维码登录。
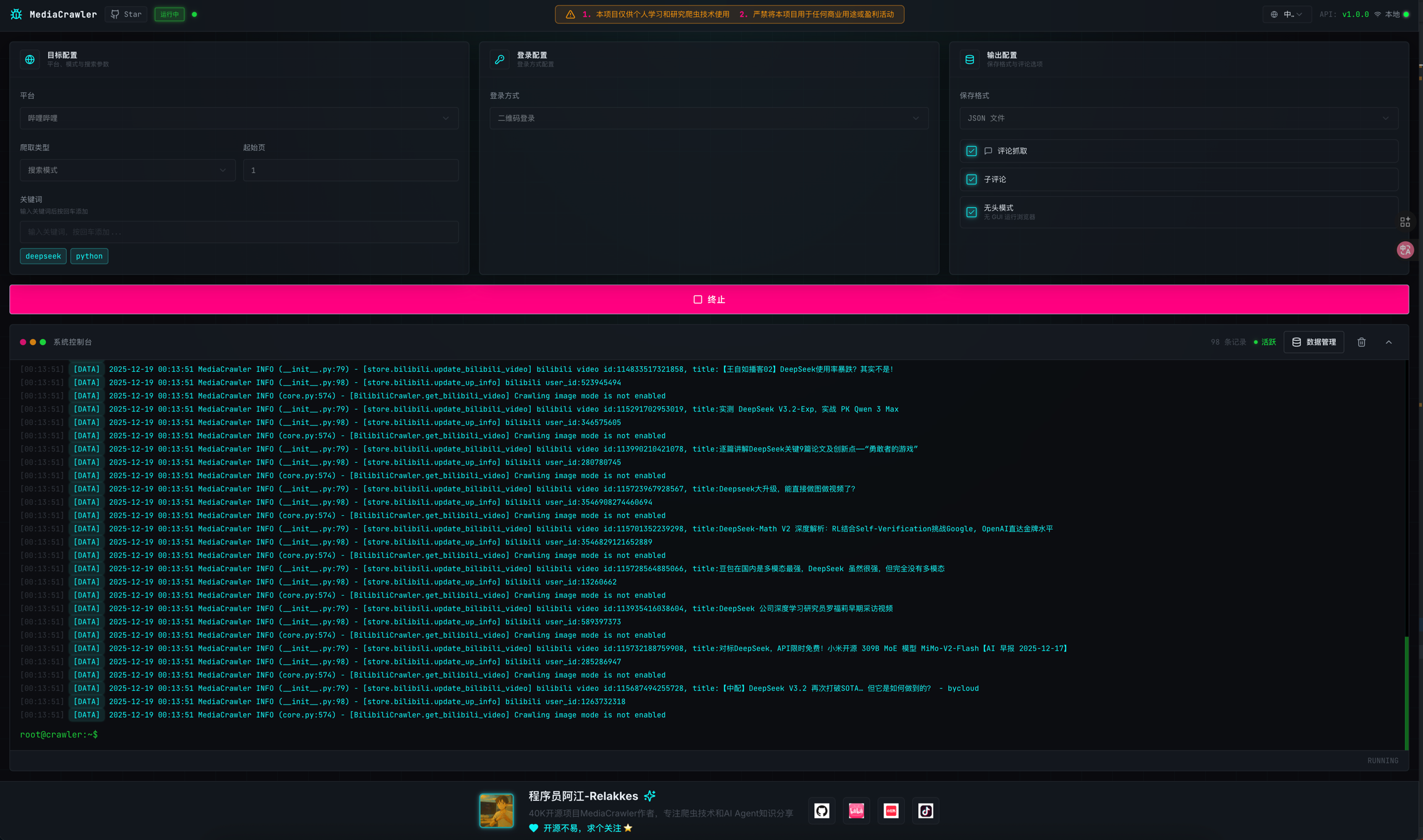
WebUI支持
MediaCrawler 还提供了可视化的 WebUI 界面,用户可以更便捷地进行爬虫操作。
bash
# 启动 WebUI 服务
uv run uvicorn api.main:app --port 8080 --reload然后在浏览器中访问 http://localhost:8080 即可。
💾 数据保存
MediaCrawler 支持多种数据存储方式,包括 CSV、JSON、Excel、SQLite 和 MySQL 数据库。您可以方便地选择合适的格式来保存抓取到的数据。
📚 其他功能介绍
与此同时,MediaCrawlerPro 版本为用户提供了更多的功能增强,包括但不限于:
- 断点续爬功能
- 多账号 + IP代理池支持
- 去除 Playwright 依赖,使用更简单
- 更佳的架构设计,适合构建大型爬虫项目
欲了解更多功能信息,欢迎访问 MediaCrawlerPro 项目主页。
⚖️ 免责声明
在使用 MediaCrawler 之前,请注意阅读并遵守相关法律法规。该项目仅供学习和研究用途,严禁用于任何非法目的。
同类项目对比
除了 MediaCrawler,市场上还存在许多类似的爬虫工具,比如:
- Scrapy:一个强大的开源爬虫框架,支持多种网站的数据抓取,适合复杂的数据抓取需求。
- Beautiful Soup:用于解析 HTML 和 XML 的 Python 库,虽然不具备全面的爬虫功能,但在数据提取和处理方面表现出色。
- Puppeteer:基于 Node.js 的无头 Chrome 浏览器 API,用于自动化网页操作和抓取数据,适合需要复杂交互的场景。
- Octoparse:依赖于可视化界面,让非开发者也能方便地抓取数据,适合追求简单易用的用户。
以上项目各具特色,用户可以根据具体需求选择最合适的工具进行数据采集。