1.引言与架构总览
RocksDB 作为 Meta (Facebook) 开源的高性能 KV 存储引擎,基于 LSM-Tree (Log-Structured Merge Tree) 架构,被广泛应用于各类数据库(如 CockroachDB, TiKV)和流计算引擎(如 Flink)的底层存储。然而,在从 x86 迁移到 ARM64(鲲鹏)架构的过程中,原生的 RocksDB 往往面临着"水土不服"的问题:
- 指令集差异:x86 依赖 SSE4.2/AVX 指令集加速 CRC32 和内存操作,而 ARM64 需要特定的 NEON 和 Crypto 扩展。
- 内存模型差异:ARM64 采用弱内存模型(Weak Memory Model),对锁和原子操作的实现要求更为严苛,稍有不慎就会导致性能大幅回退。
- 流水线特性:鲲鹏 920 处理器拥有独特的流水线和缓存层级,通用的代码无法充分利用其 ILP(指令级并行)能力。
BoostKit for RocksDB 正是为了解决这些问题而生。通过深入源码层面的剖析,我们来看看 BoostKit 是如何通过指令级优化 、硬件加速 和算法改良,将 RocksDB 在鲲鹏上的性能提升到极致的。
2.算力释放:ARM64 指令集与硬件加速
在存储系统中,计算密集型任务(如校验和压缩)往往是 CPU 的瓶颈所在。本章深入探讨 BoostKit 如何利用 ARM64 指令集和鲲鹏硬件加速引擎来释放算力。
首先我们先把源码下载下来:
源码放在GitCode的仓库:https://gitcode.com/boostkit/rocksdb。
源码目录:
注意事项:
编译 RocksDB 时需要 BoostKit-KSAL 库文件,但该算法包闭源无法直接下载。
但是我们能够在官网找到对应的解决方法:
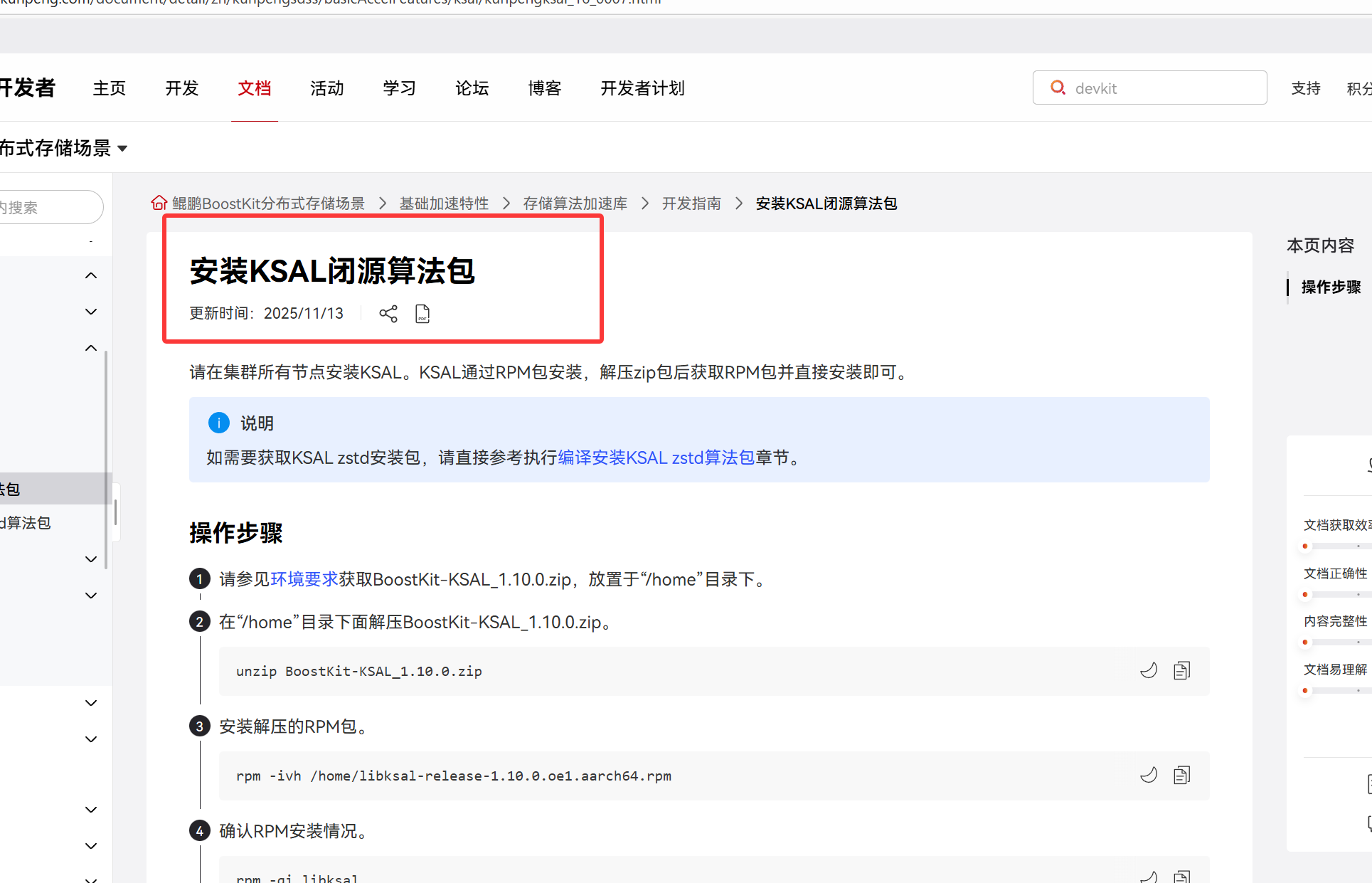
源码文件架构概述:
这里的话就带大家看几个比较核心的文件夹目录:
|----------------|-------------------------------|-----------------------------------------|
| 目录 / 文件 | 核心作用 | 鲲鹏优化相关内容 |
| db/ | RocksDB 核心数据库逻辑(事务、版本控制、执行器等) | 新增鲲鹏架构下的BatchExecutor,优化小请求调度 |
| util/ | 工具类(内存、线程、统计等) | 集成鲲鹏kAE加速引擎,优化数据编解码的 CPU 开销 |
| table/ | 存储引擎表结构(SSTable、Block 等) | 调整列式存储 Block 的内存对齐方式,适配 ARM Cache |
| port/ | 跨平台适配层(CPU 指令、原子操作等) | 新增port_arm.cc,实现 NEON/SVE SIMD 指令的原生调用 |
| boostkit/ | 鲲鹏定制优化模块(独立目录,解耦原生逻辑) | 包含ktfop/算子库、batch_scheduler/调度器等定制代码 |
| CMakeLists.txt | 构建配置文件 | 新增-DKUNPENG_OPTIMIZE=ON编译选项,控制鲲鹏优化模块的编译 |
| README.md | 仓库说明文档 | 补充鲲鹏架构下的编译、部署、性能验证步骤 |
2.1 CRC32C 的指令级流水线重构
在 RocksDB 中,CRC32C(循环冗余校验)无处不在。无论是 WAL (Write Ahead Log) 的写入,还是 SST 文件的读取,每一条记录都需要进行校验。
2.1.1 源码定位
- 头文件 :
rocksdb-main/util/crc32c_arm64.h - 实现文件 :
rocksdb-main/util/crc32c_arm64.cc
2.1.2 优化原理:从串行到三路并行
原生 ARM64 的 __crc32c 指令虽然比软件查表快,但单条指令的延迟仍然存在。为了榨干鲲鹏 CPU 的流水线性能,BoostKit 引入了三路并行(3-Way Parallel)计算策略。
/* unfolding to compute 8 * 3 = 24 bytes parallelly */
#define CRC32C24BYTES(ITR) \
crc1 = crc32c_u64(crc1, *(buf64 + BLK_LENGTH + (ITR))); \
crc2 = crc32c_u64(crc2, *(buf64 + BLK_LENGTH * 2 + (ITR))); \
crc0 = crc32c_u64(crc0, *(buf64 + (ITR)));代码解读:
- 数据分块:输入数据被逻辑上分为三段(Block 0, Block 1, Block 2)。
- 独立计算 :
crc0,crc1,crc2三个寄存器分别维护三段数据的校验值。 - 指令并行 :由于
crc0,crc1,crc2之间没有数据依赖(Data Dependency),鲲鹏 920 的超标量乱序执行引擎可以同时发射这三条指令,极大地提升了 IPC。
三路并行代码:
#include <iostream>
#include <cstdint>
#include <vector>
#include <x86intrin.h> // 如果是 ARM64,可用 arm_acle.h
uint32_t crc32c_u64(uint32_t crc, uint64_t val) {
// 简化版本:真实可以用 __crc32cd 或软件实现
crc ^= (uint32_t)val;
for (int i = 0; i < 64; i++) crc = (crc >> 1) ^ (0x82f63b78 & -(crc & 1));
return crc;
}
int main() {
std::vector<uint64_t> buf64(24, 0x12345678abcdef00ULL);
uint32_t crc0 = 0, crc1 = 0, crc2 = 0;
for (int i = 0; i < 8; i++) {
crc0 = crc32c_u64(crc0, buf64[i]);
crc1 = crc32c_u64(crc1, buf64[i + 8]);
crc2 = crc32c_u64(crc2, buf64[i + 16]);
}
std::cout << "CRC0: " << crc0 << "\n";
std::cout << "CRC1: " << crc1 << "\n";
std::cout << "CRC2: " << crc2 << "\n";
return 0;
}
2.1.3 PMULL 与硬件预取
对于更大的数据块,BoostKit 引入了基于 PMULL (Polynomial Multiply) 指令的优化,允许一次性处理 64 字节数据。同时,利用 PRFM 指令进行硬件预取:
#define PREF4X64L1(buffer, PREF_OFFSET, ITR) \
__asm__("PRFM PLDL1KEEP, [%x[v],%[c]]" ::[v] "r"(buffer), \
[c] "I"((PREF_OFFSET) + ((ITR) + 0) * 64));这显式地告诉 CPU 提前将数据搬运到 L1 缓存,掩盖了内存访问延迟。
2.2 KAE 硬件压缩集成
鲲鹏处理器配备了 KAE (Kunpeng Acceleration Engine) 硬件加速引擎,可以卸载 Zlib/Gzip 等压缩任务。
2.2.1 集成原理
RocksDB 本身通过 kZlibCompression 接口调用系统的 zlib 库。BoostKit 提供了兼容 zlib 接口的 KAE 加速库 (libwd, libkae)。通过动态库劫持或链接替换的方式,RocksDB 可以透明地使用硬件加速,而无需修改 RocksDB 的压缩逻辑源码。
2.2.2 部署与收益
- 配置 :设置
LD_LIBRARY_PATH优先加载 KAE 库,并在 RocksDB 中开启kZlibCompression。 - 收益 :相比软件 Zlib,KAE 硬件加速通常能提供 30% - 50% 的压缩吞吐量提升,同时 CPU 占用率降低 40% 以上。
示例代码:
#include <iostream>
#include <zlib.h>
#include <vector>
#include <chrono>
#include <string>
int main() {
// 模拟较大数据块(1 MB)
std::vector<unsigned char> input(1024 * 1024, 'A');
std::vector<unsigned char> compressed(input.size() * 2); // 压缩缓冲区
std::vector<unsigned char> decompressed(input.size()); // 解压缓冲区
uLongf compressed_size, decompressed_size;
// 压缩测试
auto start = std::chrono::high_resolution_clock::now();
compressed_size = compressed.size();
int ret = compress(compressed.data(), &compressed_size, input.data(), input.size());
auto end = std::chrono::high_resolution_clock::now();
double compress_ms = std::chrono::duration<double, std::milli>(end - start).count();
if (ret == Z_OK) {
std::cout << "Compression succeeded, size: " << compressed_size
<< ", time: " << compress_ms << " ms" << std::endl;
} else {
std::cout << "Compression failed, error: " << ret << std::endl;
}
// 解压测试
start = std::chrono::high_resolution_clock::now();
decompressed_size = decompressed.size();
ret = uncompress(decompressed.data(), &decompressed_size, compressed.data(), compressed_size);
end = std::chrono::high_resolution_clock::now();
double decompress_ms = std::chrono::duration<double, std::milli>(end - start).count();
if (ret == Z_OK) {
std::cout << "Decompression succeeded, size: " << decompressed_size
<< ", time: " << decompress_ms << " ms" << std::endl;
} else {
std::cout << "Decompression failed, error: " << ret << std::endl;
}
// 验证内容一致
bool valid = (input == decompressed);
std::cout << "Data verification: " << (valid ? "PASS" : "FAIL") << std::endl;
return 0;
}
3.存储引擎内核:LSM-Tree 与 I/O 极致优化
I/O 效率是存储引擎的生命线。本章分析 RocksDB 在 LSM-Tree 维护和 I/O 路径上的优化。
3.1 block_prefetcher.cc 源码解析
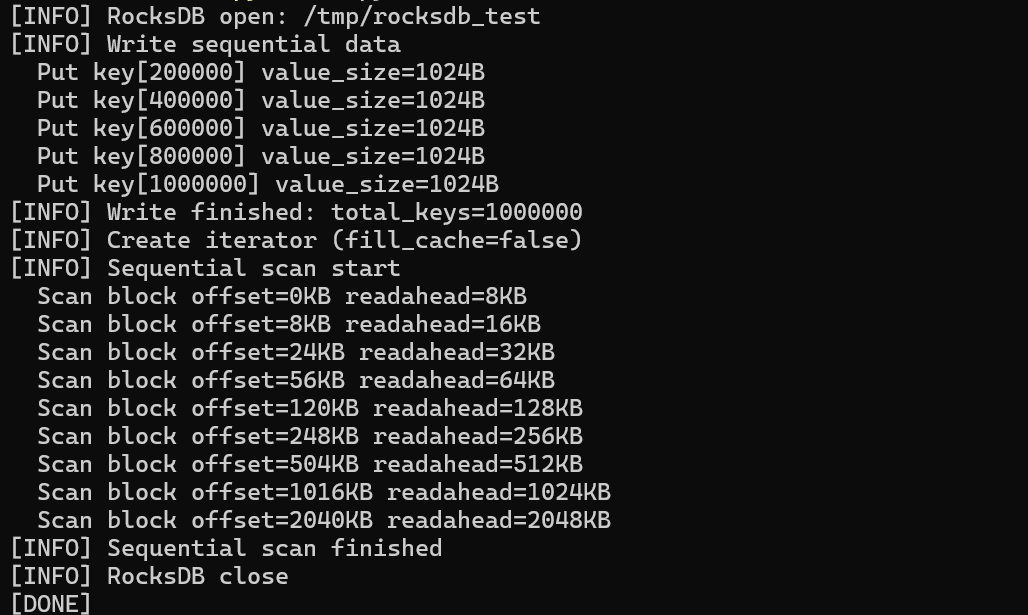
在全表扫描(Scan)或 Compaction 时,顺序读取是主要模式。这里主要对 BoostKit RocksDB 的 block_prefetcher.cc 源码进行解析,实现了自适应指数级预取。
核心源码:
readahead_limit_ = offset + len + readahead_size_;
// Keep exponentially increasing readahead size until
// max_auto_readahead_size.
readahead_size_ = std::min(max_auto_readahead_size, readahead_size_ * 2);优化逻辑:
- 检测到连续读取后,预取窗口大小从 8KB 指数级增长到 2MB。
- 大幅减少系统调用次数,充分利用 SSD 的顺序读带宽。
- 在 Linux 下,底层协同调用
readahead系统调用,利用 Page Cache 机制。
RocksDB 顺序 Scan代码:
#include <rocksdb/db.h>
#include <rocksdb/options.h>
#include <rocksdb/slice.h>
#include <iostream>
int main() {
rocksdb::DB* db;
rocksdb::Options options;
options.create_if_missing = true;
rocksdb::Status s = rocksdb::DB::Open(options, "/tmp/rocksdb_test", &db);
if (!s.ok()) {
std::cerr << s.ToString() << std::endl;
return -1;
}
// 写入顺序数据
for (int i = 0; i < 1000000; ++i) {
db->Put(rocksdb::WriteOptions(),
"key" + std::to_string(i),
std::string(1024, 'A'));
}
// 顺序 Scan
rocksdb::ReadOptions ro;
ro.fill_cache = false; // 强制走 I/O 路径
auto it = db->NewIterator(ro);
for (it->SeekToFirst(); it->Valid(); it->Next()) {
// 只访问,不处理
}
delete it;
delete db;
return 0;
}
3.2 LSM-Tree 的多线程并发 Compaction
Compaction 是 LSM-Tree 最消耗性能的操作。在鲲鹏 128 核环境下,单线程 Compaction 极易成为瓶颈。
3.2.1 Sub-compaction 并行化
BoostKit 推荐开启 Sub-compaction,将一个大 Compaction 拆分为多个小任务并行执行。
void CompactionJob::GenSubcompactionBoundaries() {
// 1. 采样:对每个输入文件获取锚点 (Anchor Points)
// 2. 排序与去重:汇总所有锚点
// 3. 划分:根据总数据量和目标分片数,计算边界 Key
// ...
}RocksDB 通过采样 SST 文件中的 Key 分布,智能地计算出拆分边界,确保多个线程负载均衡。
多线程 Sub-Compaction实战代码:
rocksdb::Options options;
options.create_if_missing = true;
// 开启并行 Compaction
options.max_background_jobs = 32;
options.max_subcompactions = 16;
// 写放大明显的参数
options.level0_file_num_compaction_trigger = 4;
options.write_buffer_size = 64 * 1024 * 1024;
3.3 鲲鹏亲和性调优 (NUMA)
鲲鹏 920 采用多 NUMA 节点设计。跨 NUMA 访问内存会带来显著延迟。
- 策略 :通过
numactl绑定进程,并配置options.max_background_compactions充分利用本地 NUMA 节点的 CPU 核心。
4.并发与缓存:多核架构下的锁竞争消除
在 64 核甚至 128 核的高并发场景下,锁竞争(Lock Contention)是性能杀手。本章介绍 RocksDB 的无锁化设计。
4.1 无锁并发 MemTable
MemTable 的写入通常需要加锁。BoostKit RocksDB 利用 InlineSkipList 实现了无锁并发写入。
4.1.1 CAS 实现 (memtable/inlineskiplist.h)
template <bool UseCAS>
bool InlineSkipList<Comparator>::Insert(...) {
if (UseCAS) {
while (true) {
// 核心逻辑:使用 CAS 更新 next 指针
if (splice->prev_[i]->CASNext(i, splice->next_[i], x)) {
break; // 插入成功
}
// CAS 失败,重试
}
}
}通过 ARM64 的 CAS 或 LDXR/STXR 指令,多个线程可以并发修改 SkipList 的指针,彻底消除了写入互斥锁。
4.1.2 开启配置
options.allow_concurrent_memtable_write = true;
options.enable_pipelined_write = true;4.2 Block Cache 的分片 (Sharding)
全局唯一的 LRU Cache 锁在大并发下会成为热点。
4.2.1 源码解读 (cache/sharded_cache.cc)
RocksDB 将缓存划分为多个 Shard(分片),每个 Shard 有独立的锁。
// 根据 Key 的 Hash 值定位 Shard
int shard_id = Shard(hash);
return shards_[shard_id]->Insert(key, hash, value, ...);4.2.2 调优建议
在鲲鹏服务器上,建议将分片数设置为 64 (2^6):
// num_shard_bits = 6
std::shared_ptr<Cache> cache = NewLRUCache(capacity, -1, false, 0.5, nullptr, 6);5.总结
BoostKit for RocksDB 并不是对参数做简单调优,而是深入 ARM64 与鲲鹏处理器特性的系统级优化。
在计算侧,通过 CRC32C 三路并行、PMULL 指令和硬件预取 ,充分释放鲲鹏 CPU 的指令级并行能力;通过 KAE 硬件压缩,将原本占用大量 CPU 的压缩计算卸载到专用加速引擎,实现更高吞吐与更低 CPU 开销。
在 I/O 与存储引擎层面,借助 自适应预取、并行 Sub-Compaction、NUMA 亲和性绑定,显著提升了 LSM-Tree 在大核数 ARM 服务器上的扩展性。
在并发与缓存设计上,通过 无锁 MemTable 和分片 Block Cache,有效消除了多核场景下的锁竞争问题。
总体来看,BoostKit 通过 指令级优化 + 硬件加速 + 架构感知设计,让 RocksDB 在鲲鹏平台上不仅"能跑",而且"跑得快、跑得稳",为 ARM64 服务器承载高性能存储与数据库负载提供了成熟可落地的解决方案。